
When building an index of the web, companies have to make many choices around crawling, parsing, and indexing data. While there’s going to be a lot of overlap between indexes, there’s also going to be some differences depending on each company’s decisions.
In the name of transparency, we want to let people know more about Ahrefs’ link index.
Links take users from one webpage to another when clicked. There are many ways to create them, with the most common method being the classic HTML <a> element with an href attribute.
<a href="url">link text</a>
However, it’s possible to create links with other elements, including:
- Onclick
- Button
- Ng-click
- Option/value
- And more…
In an ideal world, anything that functions as a link would be stored. Unfortunately, we don’t live in an ideal world. Neither Ahrefs nor Google stores all types of links because it’s not an efficient process to load each page and click every link. That’s exactly what you’d have to do if you want to find all of the links that work for users.
Instead, crawlers typically fetch pages, possibly render them, then extract and store various types of links. All crawlers work differently, so let’s talk about how we do things here at Ahrefs.
Links we store
Here are the types of links we store in our index.
External links
Links from one website to another created using the classic HTML <a> element with an href attribute.
Internal links
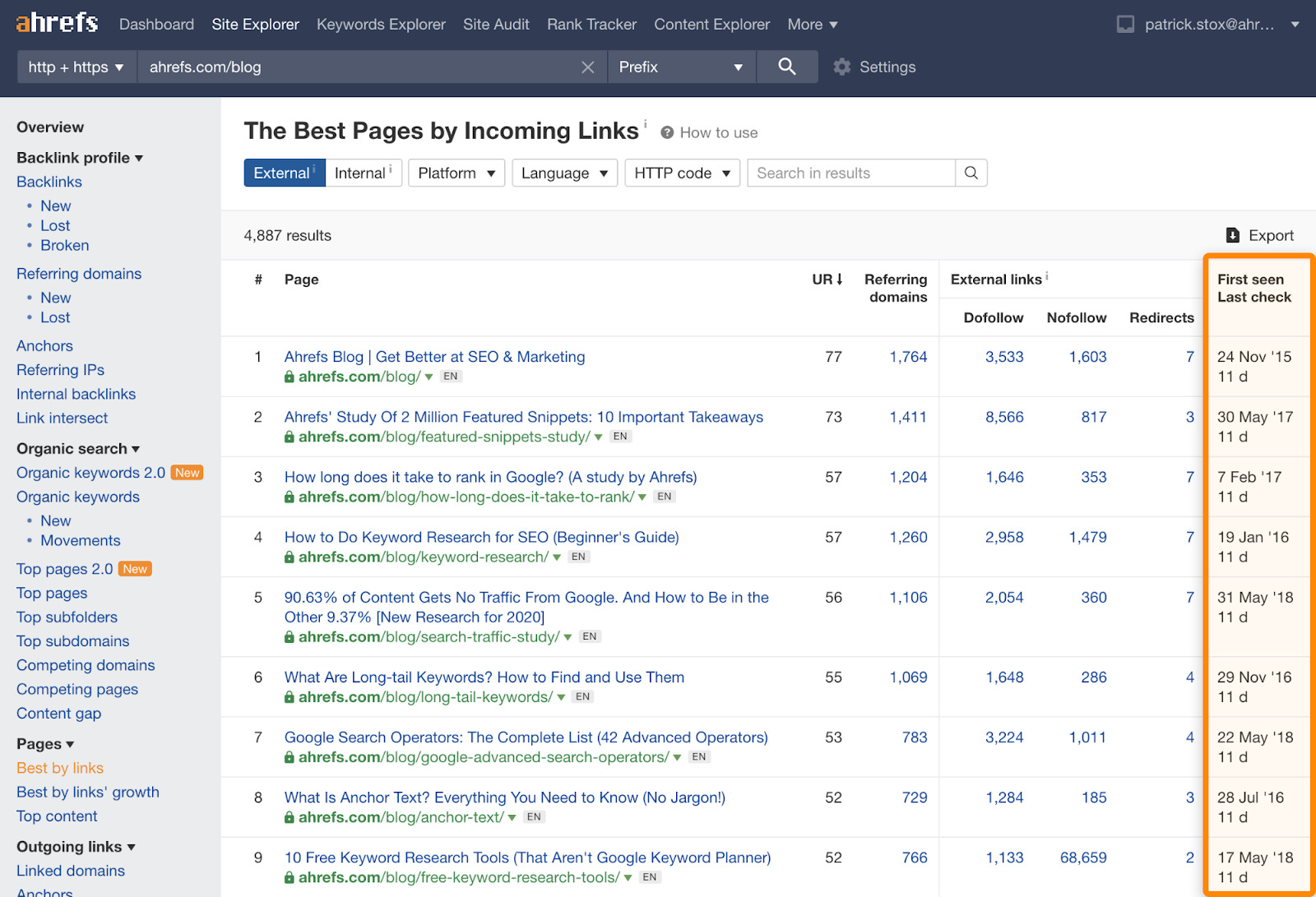
Links from one page on a website to another page on the same website. There are 22.21 trillion internal backlinks in our index. That’s far more extensive than our live external link count. We’re the only SEO tool where you can access this data without a custom website crawl. We use the internal link data in the URL Rating (UR) calculation, similar to how Google would use it in their PageRank calculation.
If you want to see when we first and last crawled a URL, you can check the “Best by links” report in Site Explorer. There are tabs for both External and Internal Links.
Links we may store
Here are all the links we store under some circumstances.
Links inserted with JavaScript
Because Google renders all pages, they can count links that are inserted with JavaScript but aren’t in the HTML code. Rendering at scale takes a lot more resources than just downloading the HTML of pages. At Ahrefs, we render around 80 million pages per day. That’s why we will have some of these links inserted by JavaScript, but not all of them. We’re currently the only SEO tool that renders during our regular crawling of the web, so we have some link data that other tools don’t have.
However, we only count links inserted with JavaScript if they are in the format of an HTML <a> element with an href attribute. You’ll see these links tagged in the backlinks report as “JS,” like this:

Links from pages with URL parameters
URL parameters are additions to a URL like ?tag=something. You may see some of these URLs in our index, but they’re usually parameters that show different content. In many cases, pages with parameters can show the same content. We have many systems in place to consolidate URLs to canonical versions and additional protection for infinite crawl paths. Other tools may not make the same decisions or have the same protections in place. As a result, they may count essentially the same link many times.
Links we try not to store
Here are the links we do our best not to store.
Links from pages with URL parameters
As mentioned above, there are good and bad types of parameters. We try not to store the ones that are duplicated.
Links from pages in infinite crawl paths
These paths create an infinite number of possible URLs. Parameters are one way they could form but so are filters, dynamic content, and broken relative paths for links. As mentioned before, we have many protections in place for links on these types of pages so that they’re less likely to show up in our reports. Respecting canonicalization and the way we prioritize crawling pages are just two of those protections. Every index will have to deal with these infinite spaces, but there’s potential for these pages to inflate link counts.
Links we don’t store
Here are all the links we never store.
Links in PDFs or other documents
Google converts many document formats to HTML and indexes them as they would any other page. This means that they count links in these documents. I don’t believe that any SEO tool currently indexes these links, but we probably should. I think that one day we will, but I’m also concerned that the effort and resources required for this won’t be worth it. According to Google Webmaster Trends Analyst John Mueller, links in PDFs don’t have any practical effect in web search.
Links in iframes
Iframes allow another page to show inside of a page. Because of this, Ahrefs doesn’t count links in iframes. However, they are shown to users, so other tools may count them even though the content technically belongs to a different page. Google may or may not count these links.
Links from pages not indexed
We drop these links. There are mixed messages from Google representatives on whether they use these in link calculations or not. Different tools may make different decisions.
something with noindex will never reach the serving index, but we will have the fetched copy for things like link graph calculation.— Gary 鯨理/경리 Illyes (@methode) December 17, 2020
Same links from multiple IPs
One fun fact about the web is that sites may serve the same page from multiple IP addresses. If this is the case, a link index may count the same link multiple times. We don’t do this. We associate links with the pages they are on.
Multiple links to the same page from a single page
Currently, we only record one version of a link on a page. If you link to a page in the menu and then again in the body content, we will only count one of these links. We may change this in the future to give users more data, but this is the current state. Google will count all versions of links for passing PageRank but may only use one version’s anchor text.
Other link related items that impact the index
Understanding how we count links is one thing, but many other things can affect what does and doesn’t get counted.
Number of links per page
I don’t believe we have a limit for the number of links we count per page, but we do have a page size limit that may eventually impact the number of links we see. Google recommends no more than a few thousand links per page.
Redirected or canonicalized
At Ahrefs, we trust all redirects and canonical tags and consolidate links where websites tell us to. For Google, this is more complicated as they have many canonicalization signals that determine which page is the lead in a canonical cluster. We keep things simple because it’s impossible to know how Google views every situation, and it would confuse our users if we treated canonicals and redirects differently every time.
These links are tagged in our reports with “301”, “302”, or “Canonical,” such as:
In Ahrefs, we have the Referring domains report that shows all the domains linking to a website or webpage.
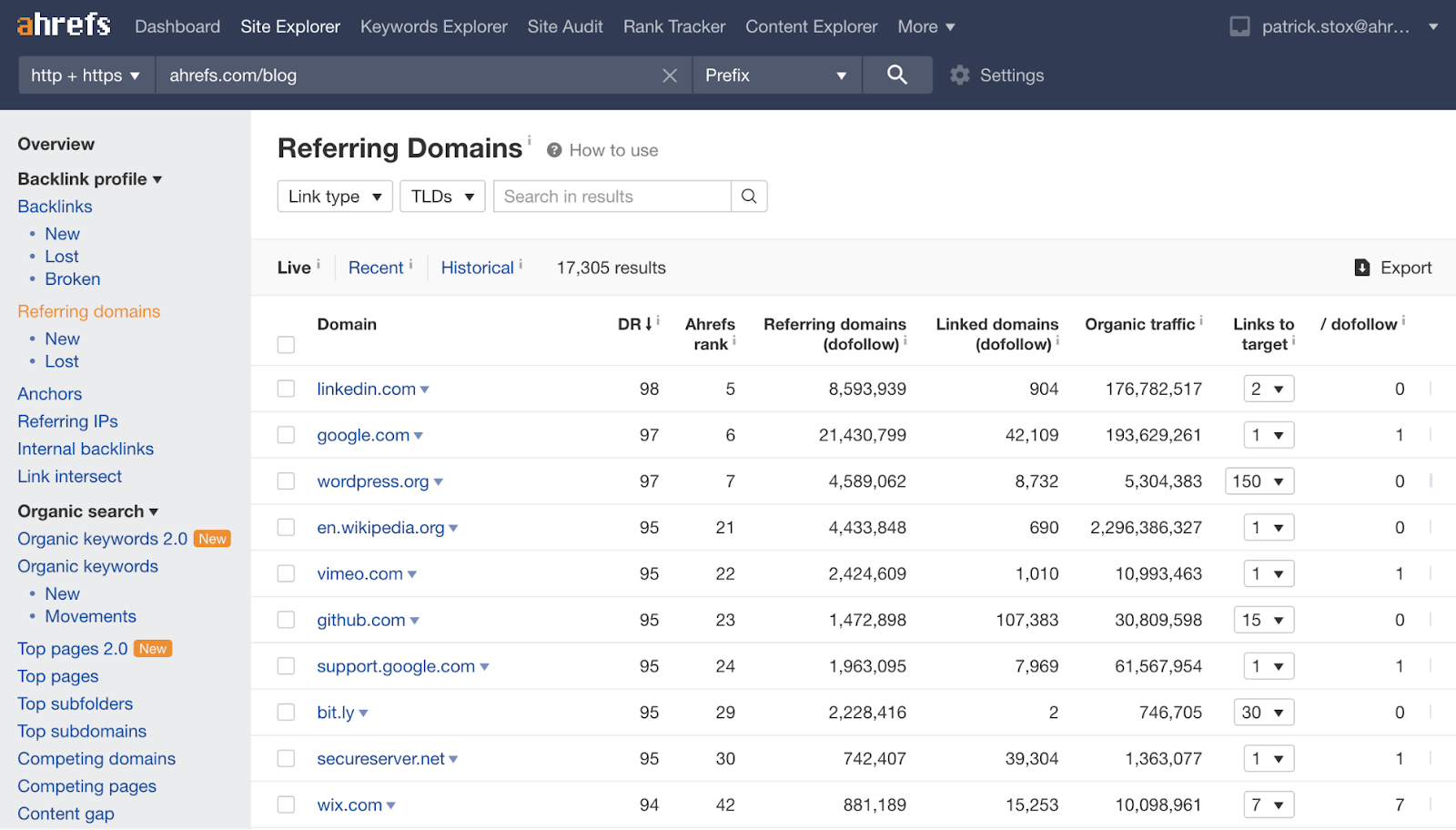
But how exactly do we count domains?
You would think this would be an easy question to answer. It’s just domain.com, right? Unfortunately, things are a little more complex as there are many ways to count domains. One option is to treat every registered domain as a domain—which seems to be how Google aggregates them in Google Search Console. Another is to treat every subdomain as a different domain. You could also aggregate some sections of a site and not others (what Google does), go by every section on a different tech stack, etc. There are many options.
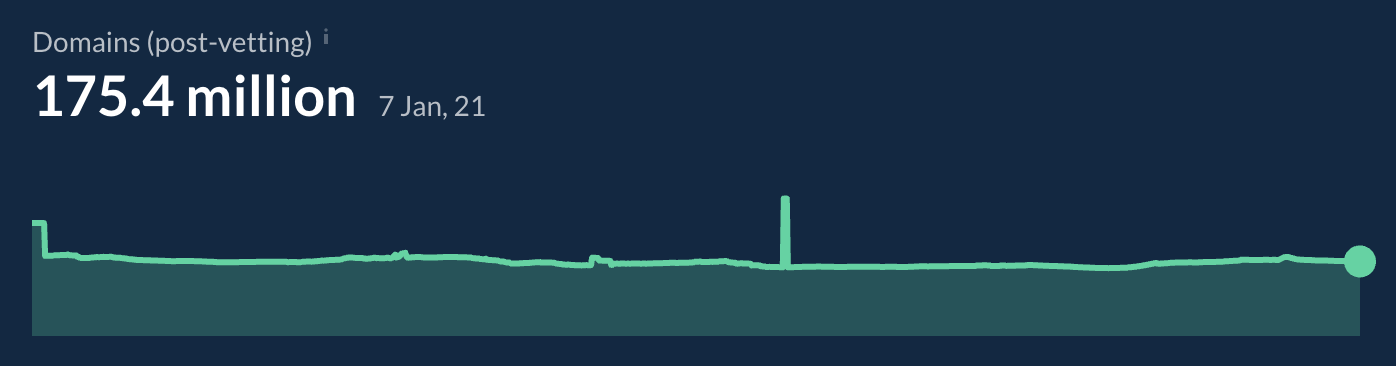
At Ahrefs, we have ~175 million domains post-vetting. The vetting process includes removing spam domains and breaking out some subdomains where we’ve determined that different users control the different areas. We use a custom list for this, but there’s a somewhat similar public list at https://publicsuffix.org/list/.
It is important to note that different domain definitions can result in large variations of referring domains. Here are some examples of things that others, not Ahrefs, may count as separate domains:
- Mobile versions subdomains (m.domain.com, mobile.domain.com, etc.)
- Country/Language subdomains (en.domain.com, fr.domain.com, de.domain.com, jp.domain.com, etc). There may be exceptions to this in our index, such as wikipedia.org, but this is not standard practice.
- Random subdomains (support.domain.com, images.domain.com, etc.)
Another decision backlink tool providers have to make is whether they should count some subfolders as different domains. For instance, I think most link indexes would count different blogs on well-known platforms (e.g., user1.blogspot.com, user2.blogspot.com) as different domains because different users control them. But why not do the same for sites like medium.com/user1 or github.com/user1? At Ahrefs, we don’t currently do this, but there’s a chance we may in the future where we know different people control each subfolder on a site.
The point here is that there are many ways to count domains. That’s obvious when you look at the varying figures from companies that count sites on the internet. According to Verisign, there are 370.7 million registered domains in Q3 2020 across all TLDs. According to Netcraft, there are 1,229,948,224 sites across 263,787,870 unique domains with 193.8 million active sites in November 2020. According to Internet Live Stats, there are roughly 1.8 billion websites with less than 200 million currently active. Each company clearly has a different methodology for counting domains.
To recap, what we do at Ahrefs is take all the sites we know about and remove many spam and inactive domains, then add some for subdomains on sites like blogspot.com. That’s how we come to our total domain count of ~175 million. Other indexes may do this differently and come up with different counts.
As we find backlinks by crawling the web, we can only do so on sites we’re allowed to crawl. If site owners block AhrefsBot in their robots.txt file, we can’t crawl their site. For example, if you get a backlink from website.com and website.com blocks AhrefsBot, we can’t crawl their site and your backlink won’t show up in Ahrefs. IP blocks, user-agent blocks from servers (different from robots.txt), server timeouts, bot protection, and many other things can also affect our ability to crawl some websites. Crawling the web at scale isn’t easy.
We have multiple link indexes
Each tool has to make decisions about data storage and retrieval. At Ahrefs, we split our data into multiple indexes.
- Live - the links we see that are still active on the web. This best represents the current state of the web and is what many of our users will find most useful.
- Recent - links we have seen active on the web in the past 3-4 months.
- Historical - all the links we have ever seen. This is going to be the most comprehensive list, but with many links that no longer exist.
You can switch between indexes in our backlink and referring domain reports.
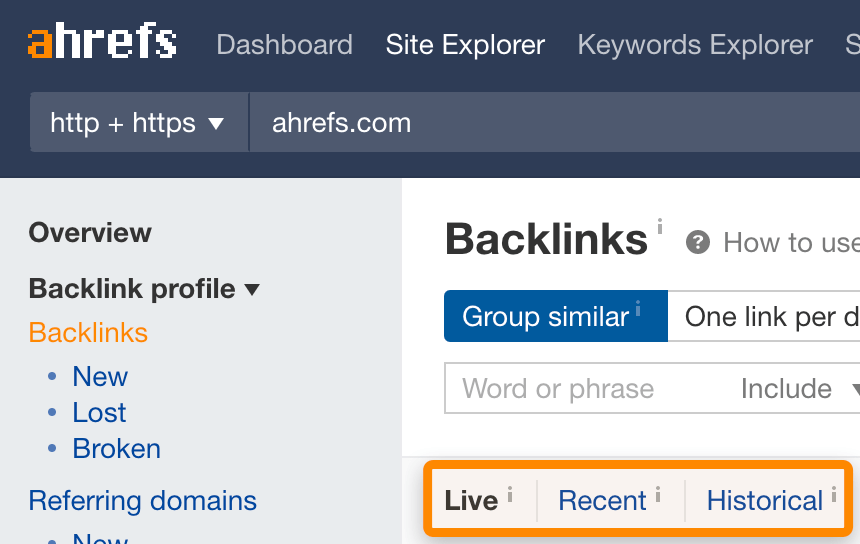
Other indexes may choose to show all the data they have ever seen, and while this means they may show a lot of links, many of those links may not exist anymore.
Final thoughts
We wanted you, our users, to have more information on our index so that you can make informed decisions. We also want you to let us know if you think we should change things and why.
If you’re currently comparing link indexes or have questions about our data, feel free to reach out to us with any questions or for clarifications.



