


How AI Search Engines Work

By Ryan Law
Director of Content Marketing at Ahrefs
When you ask ChatGPT to recommend the best over-ear headphones for working out, what actually happens?
How do AI search engines generate their answers and pick their product recommendations? How are they different from traditional search engines like Google (and where do they overlap)?
And crucially, how can you help your website, brand, and products to show up?
Thanks to Gianluca Fiorelli and Mark Williams-Cook for reviewing and contributing to this chapter.
What are AI search engines?
AI search engines are question-answering systems that use large language models (LLMs) to find information and generate responses.
There are some key differences between traditional search engines and AI search engines (although these differences are shrinking as traditional search engines incorporate more AI features):
- Instead of entering one-off queries, users can ask follow-up questions and keep the conversation going.
- Instead of returning a ranked list of links, AI search engines provide direct answers and recommendations (and these answers can change regularly).
- Instead of sending searchers to visit your website, users have their queries answered directly in the chat interface (resulting in fewer clicks back to your website).
Here’s what an archetypal AI search interface looks like, similar to what you would see in ChatGPT, Claude, or AI Mode:

- Conversational prompt: The user’s question.
- Grounding message: A message showing that the LLM has decided to search for extra information to use in its response.
- Response: The AI-generated answer to the user’s prompt.
- Mention: An entity (like your brand or product) mentioned inline in the response text.
- Citations: Source URLs used in the response generation, typically listed at the end.
To help you show up in answers like these, you first need to understand the core processes that make AI search engines work.
How training works
LLMs are trained on huge amounts of content. They have effectively “read” all of Wikipedia, all of the Common Crawl Dataset, all of Google Books, and many millions upon millions of pages of web content.
This training data helps provide the LLM with its “understanding” of the world. If your headphone company appears many times in its training data, in relevant contexts and alongside positive descriptors (“best value”, “great for the gym”, and so on), there’s a good chance your company will be mentioned in the LLM’s responses to headphone-related prompts.
Did you know?
This training process is more involved than explained here. There are pre-training stages to strip out HTML, remove personally-identifiable information, exclude blocklist words and filter the data to particular languages. There are also post-training stages to train the language model to behave more like a helpful chat assistant (and not just a next-token predictor). To learn more, watch Andrej Karpathy’s video, Deep Dive into LLMs like ChatGPT.


This is where entity-based SEO becomes critical. If your brand consistently appears in Knowledge Graphs, is properly structured with schema markup, and co-occurs with relevant entities in high-quality content across the web, you’re building a stronger ‘entity signal’ in training data.

Gianluca Fiorelli, Strategic and International SEO/AI Search Consultant
Crucially, LLMs have many quirks:
- They are probabilistic: you can use the same prompt and get different responses each time. This probabilistic nature means you can’t “optimize for a prompt” the way you optimize for a keyword. Instead, think in distributions: what’s the probability your brand appears across 100 similar prompts? This is why tracking average visibility over many prompts is better than fixating on a handful of prompts.
- Their knowledge has a cut-off: by default, an LLM’s knowledge is limited to what was contained in the dataset when that specific model was trained. Each model is trained once on a snapshot of data up to a certain date. New models with more recent knowledge cutoffs are released periodically (historically every six months or so).
- They hallucinate: they can confidently state things that aren’t true. LLMs generate text by predicting what words are likely to come next, not by verifying facts. While they’re trained to be helpful and accurate, they have no built-in fact-checking mechanism, which is why grounding through web search is so important.
A common misconception is that LLMs get ‘knowledge updates’ like software patches. In reality, each model is trained once on a fixed dataset. When you see a new model release with a fresher knowledge cutoff, that’s an entirely new model trained from scratch, not an update to the existing one.
Gianluca Fiorelli, Strategic and International SEO/AI Search Consultant
A search engine that hallucinates and shares old information doesn’t sound very useful. For that reason, LLMs overcome some of these limitations through a process known as grounding.
How grounding and RAG work
LLMs can verify and improve their answers in two ways: using tools (like calculators or other data APIs), or by retrieving additional information from external sources. This second process is technically known as Retrieval-Augmented Generation (RAG).
When a user enters a question, the LLM asks itself: “Do I already know the answer, or should I fetch additional information?” If the LLM can predict the next token with high certainty (for example, questions that don’t change much, like “what do red blood cells do?”), it’s likely to answer from its base knowledge. With low certainty (for questions that are more prone to change, like “what is the best budget coffee grinder?”), it can use its search tool to find relevant information from other sources on the internet.
The LLMs are fine-tuned to recognize query types that might benefit from additional information, like:
- Topics outside the models’ training scope: “What are the internal ranking factors used by Ahrefs’ Keywords Explorer?”
- Topics that require fresh or time-sensitive information: “What was Google’s most recent core update and when did it roll out?”
- Topics that explicitly request a web search: “Search the internet for popular link-building tactics in 2026.”
- Prompts that request sources and evidence: “Provide sources confirming Google uses user engagement signals in its algorithm.”
Some LLM models are also very likely to trigger additional searches (for example, “deep research” models are specifically configured to trigger multiple RAG searches).
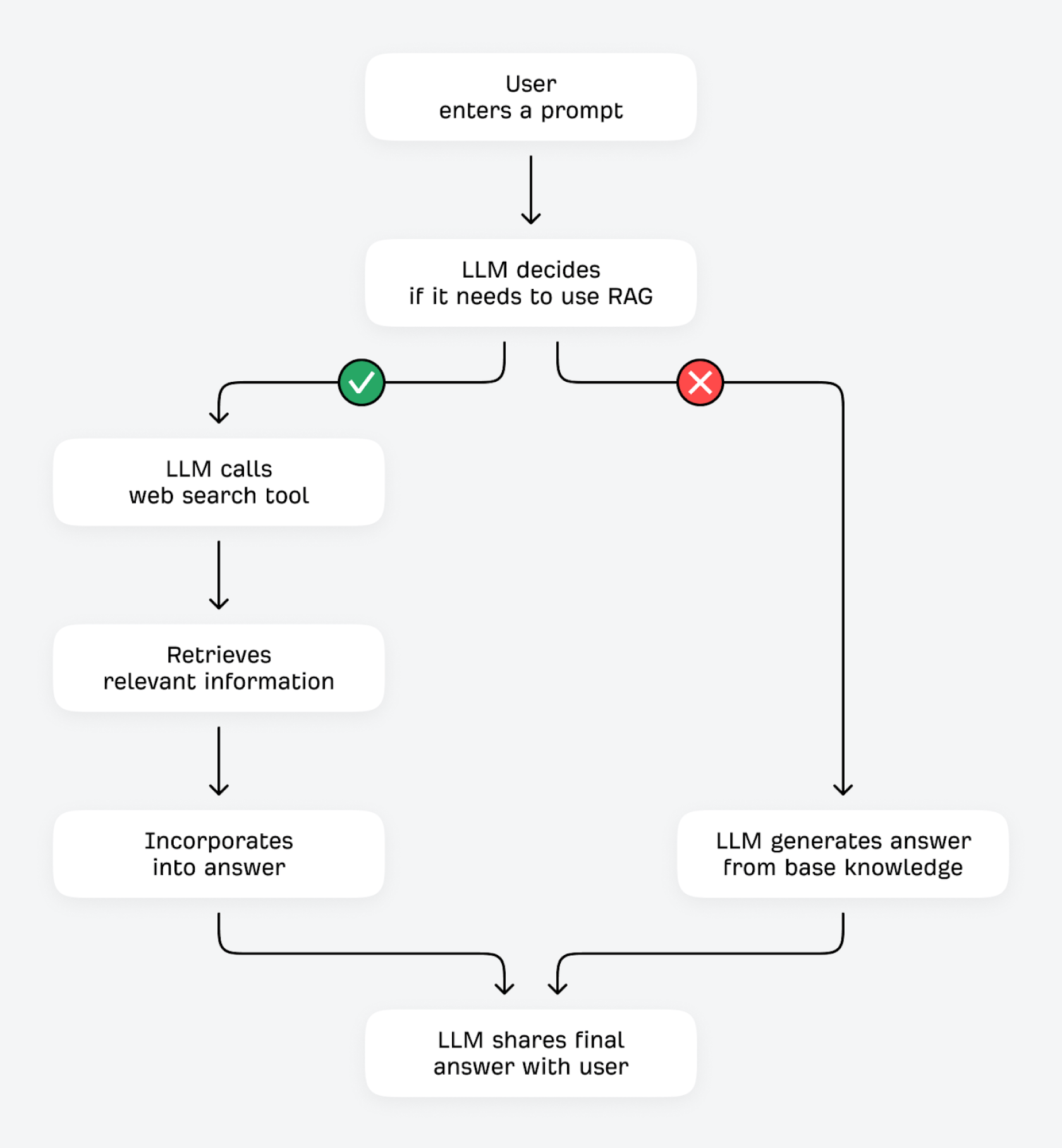
This process of finding ground truth through RAG (often referred to as “grounding”) offers several benefits. The LLM can improve factual accuracy and reduce hallucinations by checking its responses against third-party sources. It can retrieve and share up-to-date information, even if its training data is relatively outdated. It can share more detailed, comprehensive answers and offer better transparency and attribution for everything it shares.
AI search engines conduct this grounding using a process known as query fan-out.
How query fan-out works
Crucially, query fan-out explains why traditional SEO is critical for AI visibility.
AI assistants like ChatGPT, Gemini, and Perplexity use search indexes such as Google, Bing, and Brave to retrieve up-to-date information.
The search provider matters because each has different ranking algorithms, indexes, and coverage: making your brand visible in Google Search might help your visibility in AI Mode more than ChatGPT, which depends more heavily on Bing.
| AI search engine | Search indexes used for grounding |
|---|---|
ChatGPT | Bing, Google |
Claude | Brave |
Gemini | Google |
Copilot | Bing |
Perplexity | In-house |
AI Mode | Google |
AI Overviews | Google |
When a web search is triggered, the LLM requests relevant results from its search index. The search index returns a list of results, and the LLM selects the most relevant pages to crawl by evaluating information such as the page title, the contents of the returned page snippet, and its freshness (how recently it was published).
Why SEO is crucial for AI Search
That’s worth repeating: traditional search engines like Google and Bing play a crucial role in helping AI search engines decide which content to mention and cite in their answers.
Or put another way, ranking highly in traditional search will improve your visibility in AI search.
But what exactly does the LLM search for?
LLMs use a process called query fan-out. Many prompts entered into ChatGPT and other AI search engines are extremely long, conversational, and often completely unique. Googling these exact prompts won’t always return useful content.
So instead of running a web search with the user’s exact query…
“I’m planning a 6-month content strategy for a mid-sized B2B SaaS company that sells an analytics product to ecommerce brands. The company…”

…LLMs use that initial prompt to generate a series of shorter, related queries to help retrieve relevant information.
These fan out queries are also generated by the large language model and are therefore non-deterministic: they may change regularly, even for the same search.

Mark Williams-Cook, Founder, AlsoAsked
This process should feel familiar to SEOs: these related queries are very similar to long-tail keywords, sub-intents, and People Also Ask questions:
- Common B2B SaaS content strategy frameworks
- TOFU vs BOFU content examples for SaaS
- Content refresh and internal linking best practices
- Metrics for content-driven demo growth
In fact, only 12% of links cited by ChatGPT, Gemini, and Copilot appear in Google’s top 10 results for the original user prompt. However, this doesn’t mean traditional ranking is irrelevant. AI search engines retrieve content by generating multiple search queries—and those fan-out queries are often more traditional, keyword-focused searches where your existing SEO work matters enormously.

Query fan-out is liberating: you don’t need to guess what conversational prompts people will use. Instead, optimize for the decomposed queries, aka the semantic components that LLMs will naturally generate. These look remarkably like traditional keyword research: [topic] + [qualifier], comparison queries, definitional queries, and ‘best practices’ content. Your existing SEO research probably already covers the fan-out space.
Gianluca Fiorelli, Strategic and International SEO/AI Search Consultant
How retrieval, chunking, and answer synthesis work
Once an LLM retrieves relevant pages from a search index, it doesn’t read them in full. Instead, pages are split into small text “chunks”, with the model prioritizing (and sometimes expanding) the sections of text that seem most relevant to the query.
These chunks are typically a few hundred to a few thousand words each, a small fraction of most web pages. The LLM also operates under strict context-window limits: it can process a limited amount of text, including the user’s prompt, all retrieved chunks, and its own response. This means it must be highly selective about what content it retrieves and includes.
Here’s an example:
| Full page content | “Grounding is a workflow where the model retrieves external sources, extracts relevant facts, and uses those extracts to reduce hallucinations and increase freshness.… It then scans multiple sources, compares information, and synthesizes a response rather than copying text verbatim. This synthesis step helps avoid over-reliance on any single source.” |
| Snippet | “Explains how assistants use web search to retrieve external sources and reduce hallucinations by grounding responses in retrieved facts.” |
| Expansion (lines 1–2) | “Grounding is a workflow where the model retrieves external sources, extracts relevant facts, and uses those extracts to reduce hallucinations and increase freshness. The model evaluates whether a query requires up-to-date or verifiable information before initiating a web search.” |
| Expansion (lines 33–34) | “It then scans multiple sources, compares information, and synthesizes a response rather than copying text verbatim. This synthesis step helps avoid over-reliance on any single source.” |
Make it easy for LLMs to understand your content
This is important: when AI search engines retrieve your content from the internet, they can only see partial excerpts, and not the whole page. To maximize the chances of being cited in the LLM’s answer, the relevance and value of your page need to be easy for LLMs to understand, even without access to the whole page.
The AI search engine then integrates this text into its response generation process.
The raw web content is grounded into the model’s answer: the snippets of text or data extracted in the previous step are added to the model’s context, essentially saying, “Here is some context from the web that might be useful, now answer the user’s question using this information.”
How citations are chosen
From there, the model generates an answer by combining its innate knowledge with retrieved content and shares it with the user. The response will usually include citations: clickable URLs linking to the sources used during the grounding process.
Not every page the AI search engine retrieves will receive a citation in the final answer. The model selects which sources to cite based on several factors:
- Relevance: How directly the retrieved content contributed to specific claims in the response.
- Freshness: How recent the source appears.
- Diversity: How diverse the citation sources are (with AI search engines often preferring to cite multiple different sources rather than repeatedly citing the same one).
This means that even if your content is retrieved and read, there’s no guarantee of receiving a visible citation; the content must be deemed directly relevant to a specific claim in the answer.
How personalization works
This is the core of how AI search engines work, but there’s an extra level of complexity: personalization.
ChatGPT and other AI search engines can personalize their results to individual users, meaning the same prompt can generate different results for different people. Personalization can be influenced in several ways, including:
- Current conversation context: Previous messages in the same chat will influence the response to the current prompt. Mention that you value “durability” in your hiking gear, and you can expect ChatGPT to include this criterion in its search when you ask for “backpack recommendations” later in the chat.
- Memory: Many LLMs have a memory feature that lets the system retain certain facts or preferences across chats. For example, with memory enabled, ChatGPT will infer and remember details you’ve shared (like your name or interests) and include them in future conversations to personalize its responses.
- Location, time, date: Many AI search engines can infer information about you and tailor their responses with it, from using your IP address for approximate location (for queries like “brunch near me”), to the date and time (“camping packing list” might suggest a 4-season tent in Winter and a 3-season tent in Summer).
- System prompts: Any specific preferences shared in the system message will influence your conversations (adding “remember I’m vegan” to the system prompt will influence responses to prompts like “healthy breakfast ideas”).
Here’s an analogy for understanding system prompts. If you were playing soccer, the ‘training data’ is all of the practise you had over the years, the long-term muscle memory. The system prompt is what your coach tells you just before you get on the field. It is the powerful, short-term powerful memory that is more likely to impact output.
Mark Williams-Cook, Founder, AlsoAsked

For this reason, it’s a good idea to track the average visibility of your brand and website over time and across many prompts, instead of obsessing over any single prompt response.
Final thoughts
Every AI search engine (from ChatGPT to Perplexity to Google AI Mode) is slightly different, but the core processes remain the same. Importantly for SEOs and marketers, traditional search engines like Google and Bing provide much of the infrastructure required for AI search engines to function. Optimizing for AI search depends a great deal on traditional SEO best practices.
Ryan Law is the Director of Content Marketing at Ahrefs. Ryan has 13 years experience as a writer, content strategist, team lead, marketing director, VP, CMO, and agency founder. He’s helped dozens of companies improve their content marketing and SEO, including Google, Zapier, GoDaddy, Clearbit, and Algolia. He’s also a novelist and the creator of two content marketing courses.
Master SEO Step by Step
How Search Engines Work
Before you start learning SEO, you need to understand how search engines work.
SEO Basics
Learn how to set your website up for SEO success, and get to grips with the four main facets of SEO.
Keyword Research
The starting point in SEO is to understand what your target customers are searching for.
SEO Content
Learn how to create content that ranks in search engines.
On-Page SEO
This is where you optimize your pages to help search engines understand them.
Link Building
Learn how to create content that ranks in search engines.
Technical SEO
Prevent technical problems that stop Google from accessing and understanding your website.
Local SEO
Learn how to improve your visibility in local search results and get more customers from your area.
What AI Means for SEO
You can’t talk about SEO today without mentioning generative AI.
How AI Search Engines Work
Learn exactly how AI search engines like ChatGPT generate their answers and choose which brands and products to mention.