Add a top 1% marketer to your team

Duplicate Content
What is Duplicate Content?
Duplicate content is exact or near-exact content that appears in multiple places across the web. It can happen on a single website as well as on different websites.
For example, if you publish a blog post on your website and decide to submit it as a guest post to another website, that is duplicate content.
There is a lot of controversy around duplicate content in the webmaster’s community. The main concern is that Google will penalize their websites if they have duplicate content.
Why is duplicate content bad for SEO?
There are several reasons why duplicate content is bad from an SEO perspective.
1. Undesirable page version ranking in the search results
If you have the same content appearing on different URLs, Google can end up ranking the version you didn’t intend to rank. That’s because Google will choose which version to rank based on what it considers the best for the user. You can avoid this by properly managing duplicate content, as explained further below in this article.
2. Link equity dilution
Each URL with duplicate content can attract different backlinks and have its own PageRank. Keep in mind that PageRank is still a ranking factor which means that the URL you didn’t intend to rank may end up with a better link profile than the URL you’re actually trying to rank.
A common example is when the same page or content is available at both www and non-www versions of your website and/or via both HTTP and HTTPS protocols.
When this happens, Google will try to group those URLs into one cluster and consolidate link signals. But there’s no guarantee.
3. Wasted crawl budget
If you have a large website or if you update content frequently on your website, duplicate content is a waste of the crawl budget. Instead of crawling new and updated pages, search engines will crawl and re-crawl all the duplicate content versions. As a result, your new content may take longer to appear in search engine results.
4. Syndicated or scraped content outranking your original
The last reason why duplicate content is bad for SEO is that, in rare cases, syndicated or scraped content can outrank your original content. While it doesn’t happen often, it’s been reported in different SEO communities.
Will you be punished for duplicate content?
According to Google, most duplicate content is not deceptive in origin. In other words, if you don’t intend to manipulate search rankings with the duplicate content, Google won’t penalize your website.
There is, however, a penalty (manual action) for “thin content with no added value,” which includes scraped content.
How to find duplicate content on your site?
You can find duplicate content on your site using Ahrefs Site Audit or Ahrefs Webmaster Tools.
When you run an audit of your website, you’ll notice a section that’s dedicated to duplicate content. Within that section, you’ll find a report on duplicate pages on your website that don’t have proper canonical tags.
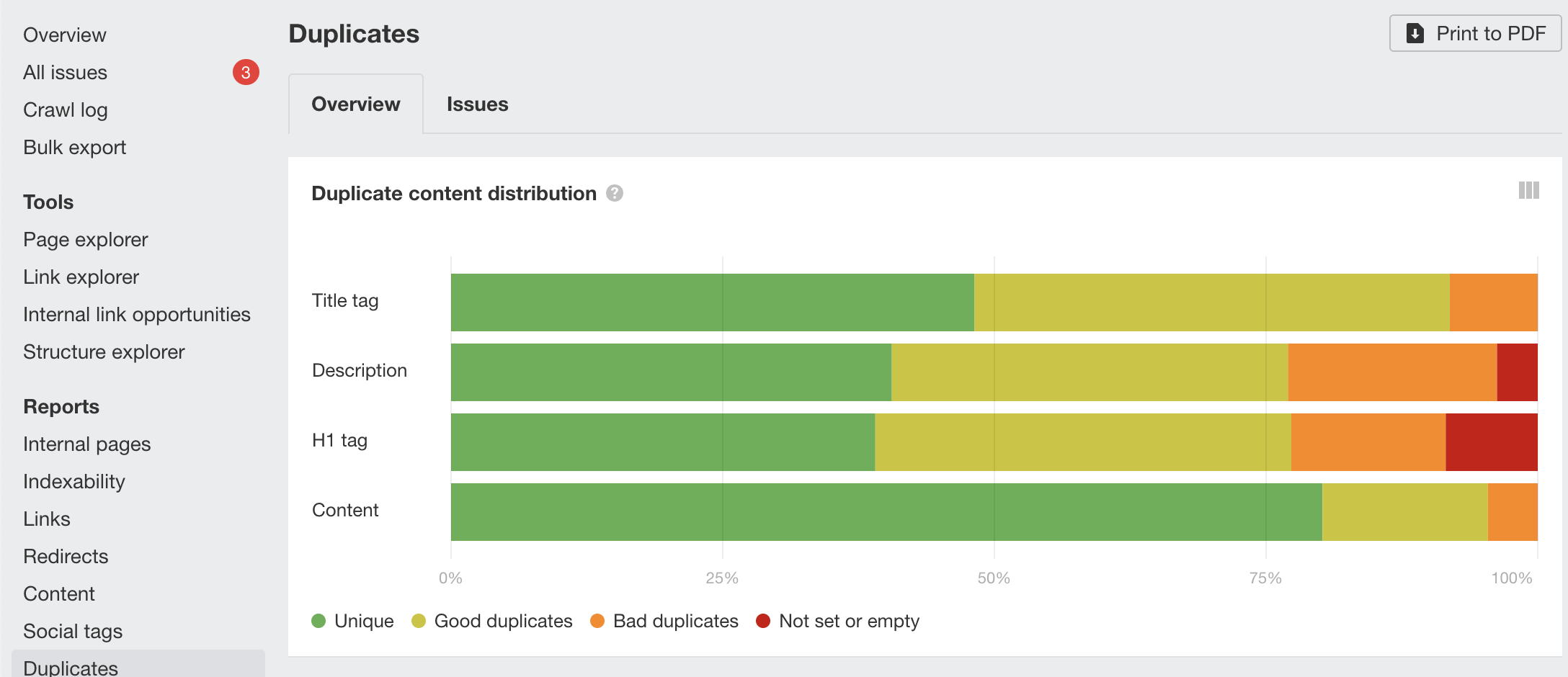
Besides, it will show you the pages that use the same titles and descriptions.
1. Use one standard for all URLs on your site
First, make sure that each page on your site is accessible as either the www or non-www version. You also need to apply the same principle to the trailing slash at the end of the URL and ensure that each page is only accessible over the HTTPS protocol. All other versions should be redirected to the standard URL you’ve decided on.
Here’s an example from our blog:
All these URLs redirect to:
2. Use canonical tags for consolidation
Duplicate or near-duplicate pages on your website must point to a single, canonical version by using canonical tags. A canonical tag tells Google which version is the main and should be indexed.
On top of that, proper canonicalization will also consolidate all link signals to that single canonical page.
3. Use a self-referential canonical tag
A self-referential canonical tag is a tag that is added to the main version of the page; regardless of other duplicate pages. They’re not mandatory but are recommended. This is helpful when you’re dealing with URLs that have various URL parameters attached to them.
For example, when a self-referential canonical is used, a URL like https://ahrefs.com/blog/?utm_source=facebook will automatically have a canonical tag that points to https://ahrefs.com/blog/.
If you’re using WordPress and have Yoast or a similar SEO plugin installed, self-referential canonical tags will be added automatically. If you have a custom-coded website or using a custom CMS, you will need to contact your developer to implement self-referential canonical tags.
FAQ
Is there a penalty from Google for duplicate content?
There is no such thing as a duplicate content penalty. However, scraped/stolen content falls under Googles’ “Thin content with little or no added value” manual action.
What is near-duplicate content?
Near-duplicate content is content that differs from other content to a minimal extent. For example, product pages of the same product for the US and UK visitors where only currencies are different are near-duplicates.

