Patrick Stox est conseiller produit, spécialiste SEO technique et ambassadeur à Ahrefs. Il co-organise divers évènements comme le Raleigh SEO Meetup, Raleigh SEO Conference, Beer & SEO Meetup et Findability Conference. Il est aussi modérateur sur /r/TechSEO.
Le SEO technique est la partie la plus importante du SEO… jusqu’à un certain point. Les pages doivent être explorables et indexables pour avoir ne serait-ce que la chance de pouvoir se positionner dans les moteurs de recherche. Mais d’autres ajustements n’auront qu’un faible impact par rapport au contenu et aux liens.
Nous avons rédigé ce guide du débutant pour vous aider à comprendre les bases et vous permettre d’optimiser votre temps de travail. Il existe beaucoup de ressources complémentaires pour lesquelles nous vous donnons des liens dans cet article, et encore plus de suggestions de lectures à la toute fin pour aller plus loin.
Comme nous sommes dans un guide du débutant, commençons par les bases.
Qu’est-ce que le SEO technique ?
Le SEO technique c’est le processus d’optimisation de site pour aider les moteurs de recherche comme Google à trouver, explorer, comprendre et indexer vos pages. Le but est d’être visible dans les résultats de recherche et améliorer le ranking (le positionnement dans les résultats).
Est-ce que le SEO technique est compliqué ?
Cela dépend. Les fondamentaux ne sont pas vraiment complexes à maîtriser, mais le SEO technique peut entrer dans des subtilités difficiles à comprendre. Nous allons rester aussi simples que possible avec ce guide.
Part 2
Comprendre le crawling
Nous verrons dans cette partie les méthodes pour s’assurer que les moteurs de recherche puissent explorer (crawler) votre contenu de manière efficace.
Comment fonctionne le crawling (l’exploration)
Les crawlers (bots informatiques) vont consulter le contenu des pages et suivre les liens qui s’y trouvent pour découvrir d’autres pages. C’est comme cela qu’ils découvrent le contenu du web. Il y a plusieurs étapes dans ce processus dont nous allons parler.
Les crawlers doivent commencer quelque part. En règle générale, ils créent une liste des URLs qu’ils trouvent via les liens sur d’autres pages. Une autre méthode est de se servir des sitemaps qui sont générés par les utilisateurs des différents systèmes de création de sites, qui contiennent une liste des pages.
File d’attente de crawl
Toutes les URL qui doivent être explorées ou re-explorées sont classées par ordre de priorité et ajoutées dans la file d’attente de crawl. Ce n’est ni plus ni moins qu’une liste ordonnée des URLs que Google veut explorer.
Crawler
Le programme qui va récupérer le contenu des pages.
Systèmes de traitement
Il existe plusieurs systèmes de traitement qui peuvent prendre en charge la canonisation, dont nous allons parler un peu plus bas, et envoyer ces pages à un système de rendu qui va charger la page comme le ferait un navigateur. Ensuite cette page sera traitée pour trouver plus d’URLs à explorer.
Rendu
Le processus de rendu va charger la page comme le ferait un navigateur avec le JavaScript et le CSS. Google procède ainsi pour “voir” la page comme le ferait un utilisateur.
Index
Ce sont les pages stockées que Google va proposer à ses utilisateurs.
Contrôler le crawl
Il existe quelques méthodes pour contrôler ce qui va être exploré (crawlé) sur votre site. Voici quelques options.
Robots.txt
Un fichier robots.txt va dire aux moteurs de recherche où ils peuvent ou ne peuvent pas aller sur votre site.
Une remarque cependant. Google peut tout de même indexer des pages qu’il n’est pas censé pouvoir explorer si des liens pointent vers les pages en question. Cela peut sembler confus, mais si vous voulez empêcher ces pages d’être indexées, examinez ce guide et schéma qui vont vous guider dans la manœuvre.
Fréquence de crawl
Vous pouvez mettre dans le robots.txt une directive qui va déterminer à quelle fréquence il faut explorer la page que beaucoup de crawlers respectent. Malheureusement ce n’est pas le cas de Google, pour changer sa fréquence de crawl, il faut passer par la Google Search Console comme c’est expliqué ici.
Restriction d’accès
Si vous voulez que certaines pages ne soient accessibles qu’à quelques utilisateurs et pas aux moteurs de recherche, vous aurez à recourir à l’une de ces trois options :
Une whitelist d’IP (qui ne va permettre qu’à certaines adresses IP d’accéder aux pages)
Ce genre de configuration est idéale pour des réseaux internes, du contenu réservé à des membres, ou pour tester et développer des sites. Cela permet à un groupe d’utilisateurs d’accéder aux pages, mais pas aux moteurs de recherche qui ne pourront alors pas les indexer.
Comment voir l’activité des crawlers
Pour Google spécifiquement, la manière la plus simple pour voir ce qu’il est en train d’explorer est d’utiliser le Rapport de couverture de la Google Search Console qui vous donnera des informations sur la manière dont votre site est exploré.
Si vous voulez voir toute l’activité d’exploration de votre site, vous allez devoir accéder aux logs de votre serveur et sans doute utiliser un outil pour analyser les données. Cela peut être relativement compliqué, mais si votre hébergeur à un système de contrôle comme cPanel, vous devriez pouvoir accéder à quelques logs de crawl et des agrégateurs comme Awstats et Webalize.
Ajustement de crawl
Tous les sites vont avoir des “budgets de crawl” différents, c’est-à-dire une combinaison de fréquence de passage du bot et de quantité d’exploration que votre site permet. Les pages les plus populaires et celles qui changent le plus souvent seront explorées le plus régulièrement, celles qui n’attirent pas beaucoup de visites ou ne reçoivent pas beaucoup de liens seront explorées moins souvent.
Si le crawler rencontre des problèmes dans le chargement du site, il va ralentir son exploration voire la stopper en attendant que les conditions s’améliorent.
Une fois les pages explorées, elles sont rendues et envoyées à l’index. L’index est la grande liste de l’intégralité des pages qui peuvent remonter dans les résultats de recherche. Parlons maintenant de l’index.
Nous allons parler dans cette partie de la manière de vous assurer que vos pages sont indexées et de vérifier comment elles le sont.
Directives des robots
Une meta tag de robots est un petit code HTML qui donne des instructions aux moteurs de recherche sur la manière d’explorer et indexer certaines pages. On le trouve dans la section <head> d’une page web, et ça ressemble à ça :
<meta name="robots" content="noindex" />
URL canonique
Lorsqu’il existe plusieurs versions d’une même page, Google va en sélectionner une à stocker dans son index. Ce processus s’appelle la canonisation, l’URL définie comme canonique (canonical en anglais) sera celle qui apparaîtra dans les résultats de recherche. Il existe plusieurs signaux pour déterminer si une URL est canonique ou non :
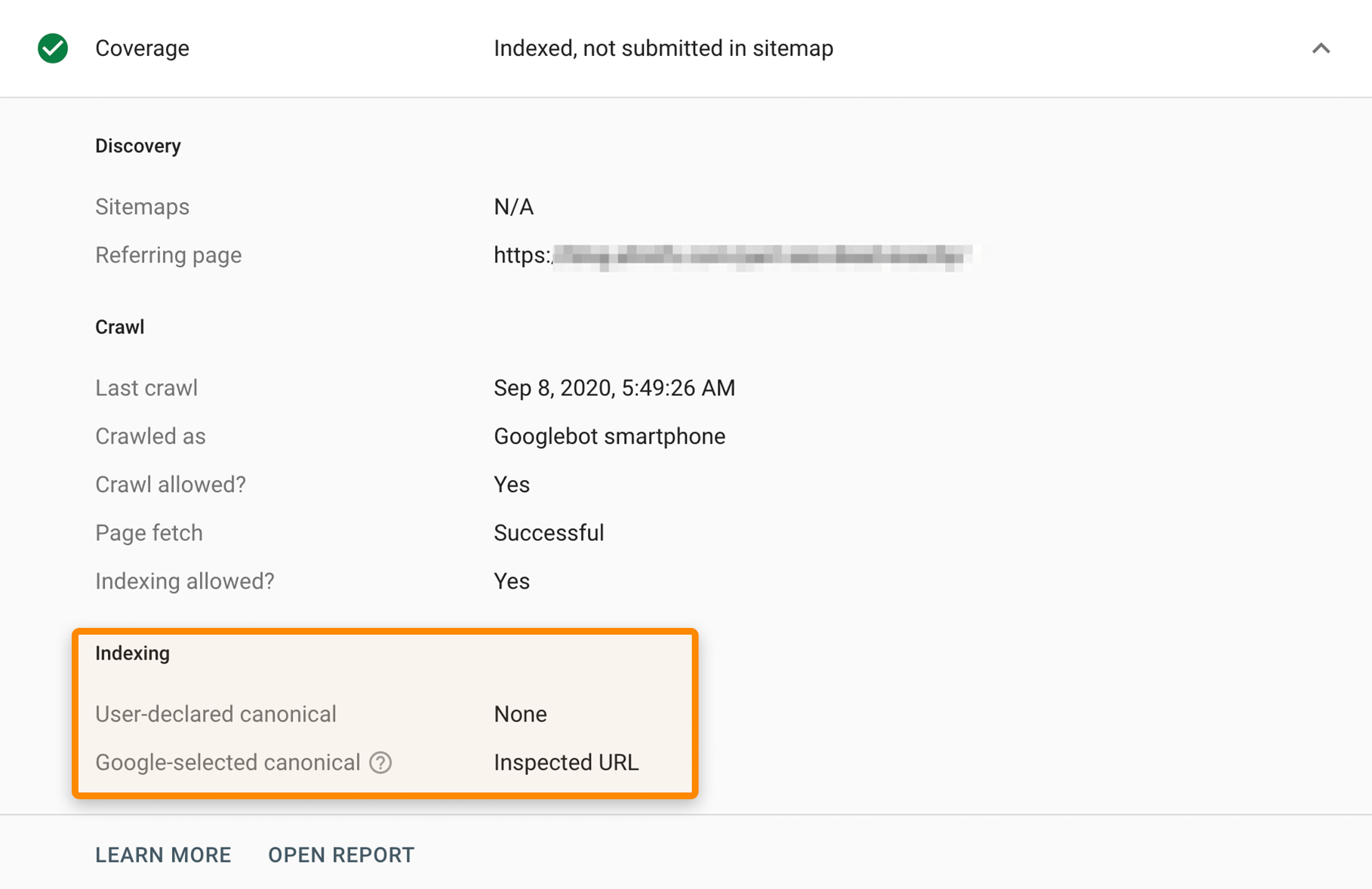
La méthode la plus simple pour voir ce que Google a indexé est d’utiliser l’outil d’inspection d’URL dans la Google Search Console. Cela va vous montrer ce que Google a sélectionné comme URL canonique.
L’une des choses les plus difficiles en SEO est la priorisation des tâches. Il y a beaucoup de bonnes pratiques, mais certaines auront plus d’impact sur votre ranking et votre trafic que d’autres. Voici quelques étapes que je vous recommande d’entreprendre en priorité.
Vérifier l’indexation
Assurez-vous que les pages que vous voulez que les gens trouvent soient bien indexées par Google. Les deux parties précédentes parlaient de crawling et d’indexation, ce n’est pas par hasard.
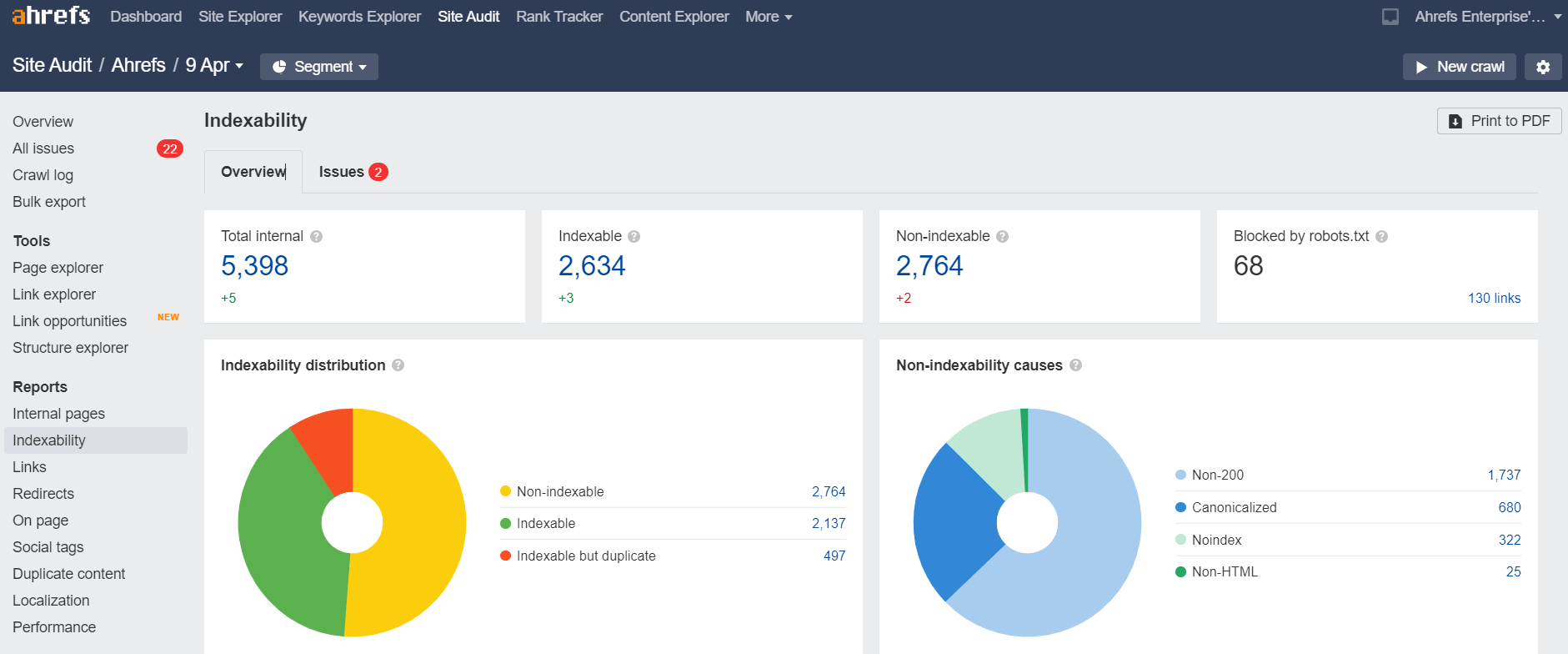
Vous pouvez vérifier le rapport d’indexation dans l’Audit de site pour voir les pages qui ne peuvent pas être indexées et pourquoi. C’est gratuit dans les outils de webmaster de Ahrefs.
Réclamer les liens perdus
Les sites ont tendance à changer leurs URL au fil des années. Bien souvent, ces vieilles URLs fournissaient du backlink de la part d’autres sites. Si elles ne sont pas redirigées vers les pages actuelles, ces liens sont perdus et ne comptent plus pour votre site. Il n’est pas trop tard pour mettre en place des redirections pour rapidement récupérer cette valeur. Voyez cela comme la stratégie de link building la plus rapide que vous puissiez faire.
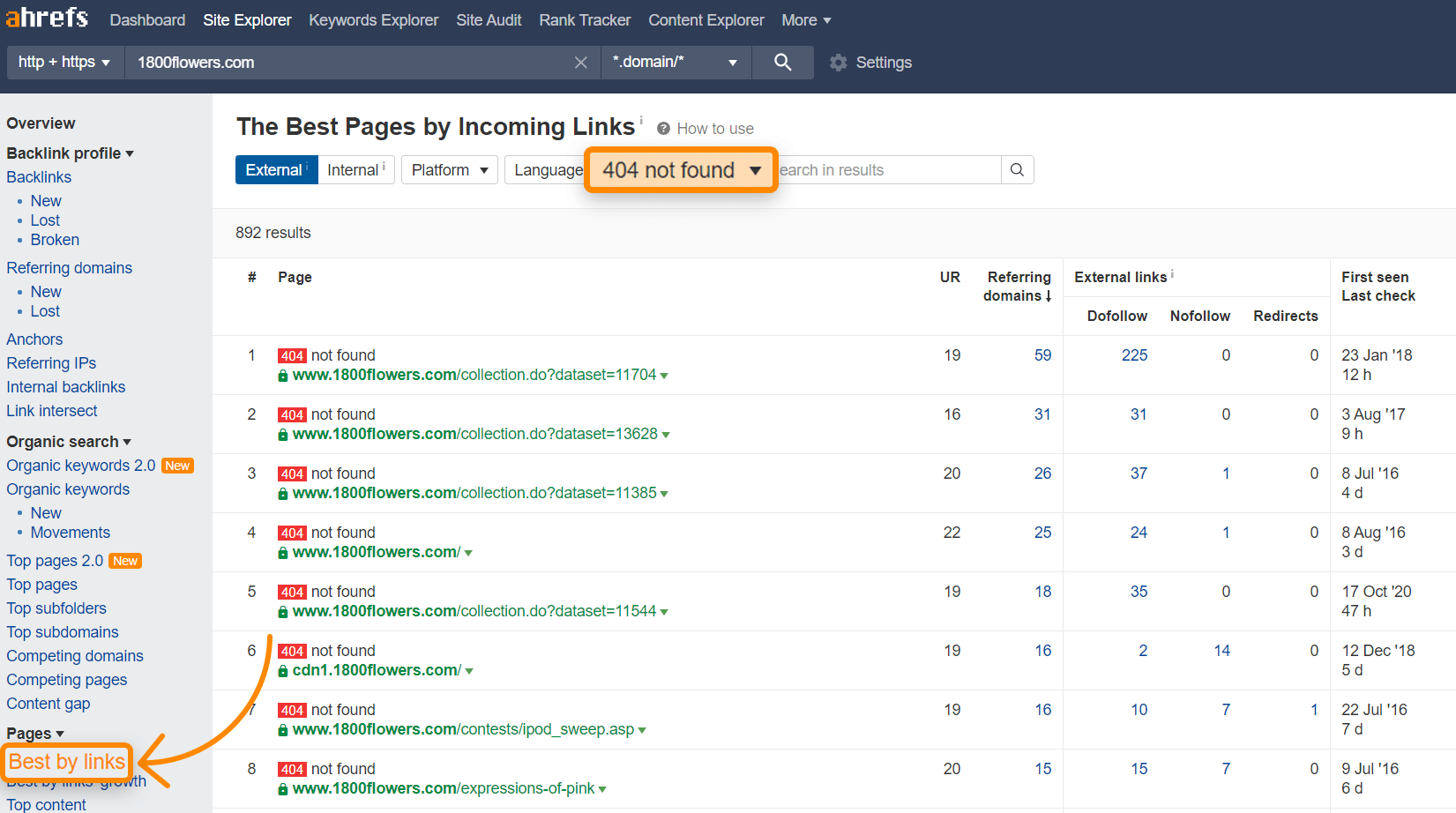
Explorateur de site -> votredomaine.com -> Pages -> Meilleures par liens -> ajouter “404 not found” dans le filtre HTTP. Je trie généralement par “domaines référents”.
Voici ce que ça donne pour 1800flowers.com :
En regardant les premières URL dans archive.org, je vois que c’était à la base une page sur la fête des Mères. En mettant en place une redirection vers la nouvelle version, on peut réclamer 225 liens issus de 59 sites différents. Et il y a encore beaucoup d’autres opportunités.
Il faudra mettre en place une redirection 301 sur toutes les vieilles URLs vers leur nouvel emplacement pour récupérer la valeur des backlinks.
Ajouter des liens internes
Les liens internes sont des liens entre les pages de votre site. Ils aident à faire trouver vos pages et donc à mieux les positionner. Nous avons beaucoup d’outils au sein de l’Audit de site appelé opportunités de liens qui pourront vous aider à mieux réaliser le maillage interne de votre site.
Ajouter des données structurées (schema markup)
Les données structurées sont un code qui aide les moteurs de recherche à mieux comprendre votre contenu et qui lui permettent de sortir du lot dans les résultats de recherche. Google dispose d’une galerie de recherche qui montre les différentes possibilités offertes et comment les mettre en place pour votre site.
Les étapes dont nous allons parler dans cette partie sont toujours intéressantes à développer, mais demandent plus de travail et auront moins d’impact que celles de la partie précédente. Cela ne veut pas dire qu’il ne faut pas les suivre, juste que ce ne sont pas les premières choses à faire. L’idée est de correctement prioriser vos tâches.
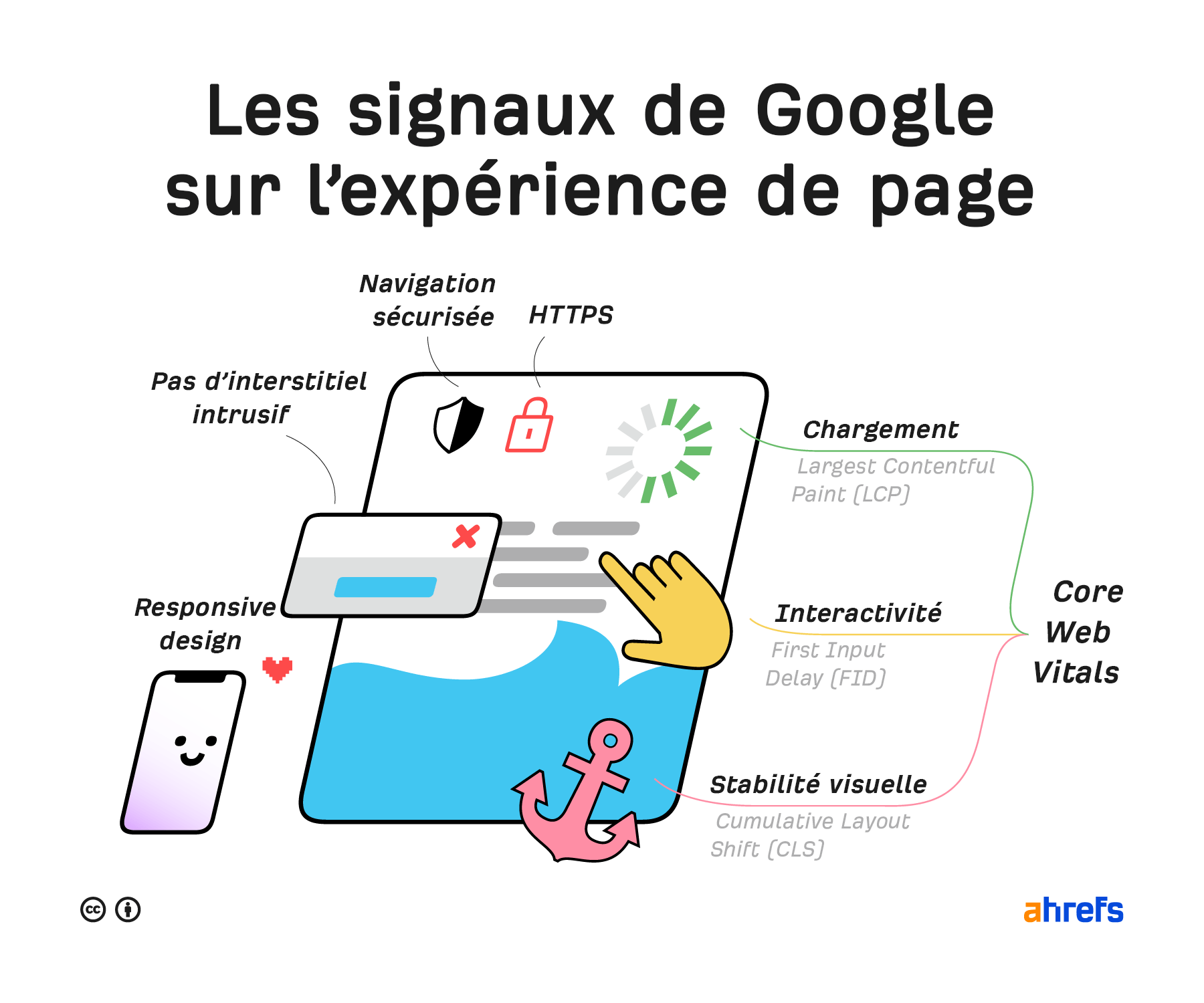
Signaux d’expérience de page
Ce sont des facteurs de ranking moins importants, mais qu’il est bon de vérifier pour le bien de vos utilisateurs. Cela couvre l’expérience utilisateur de votre site (UX).
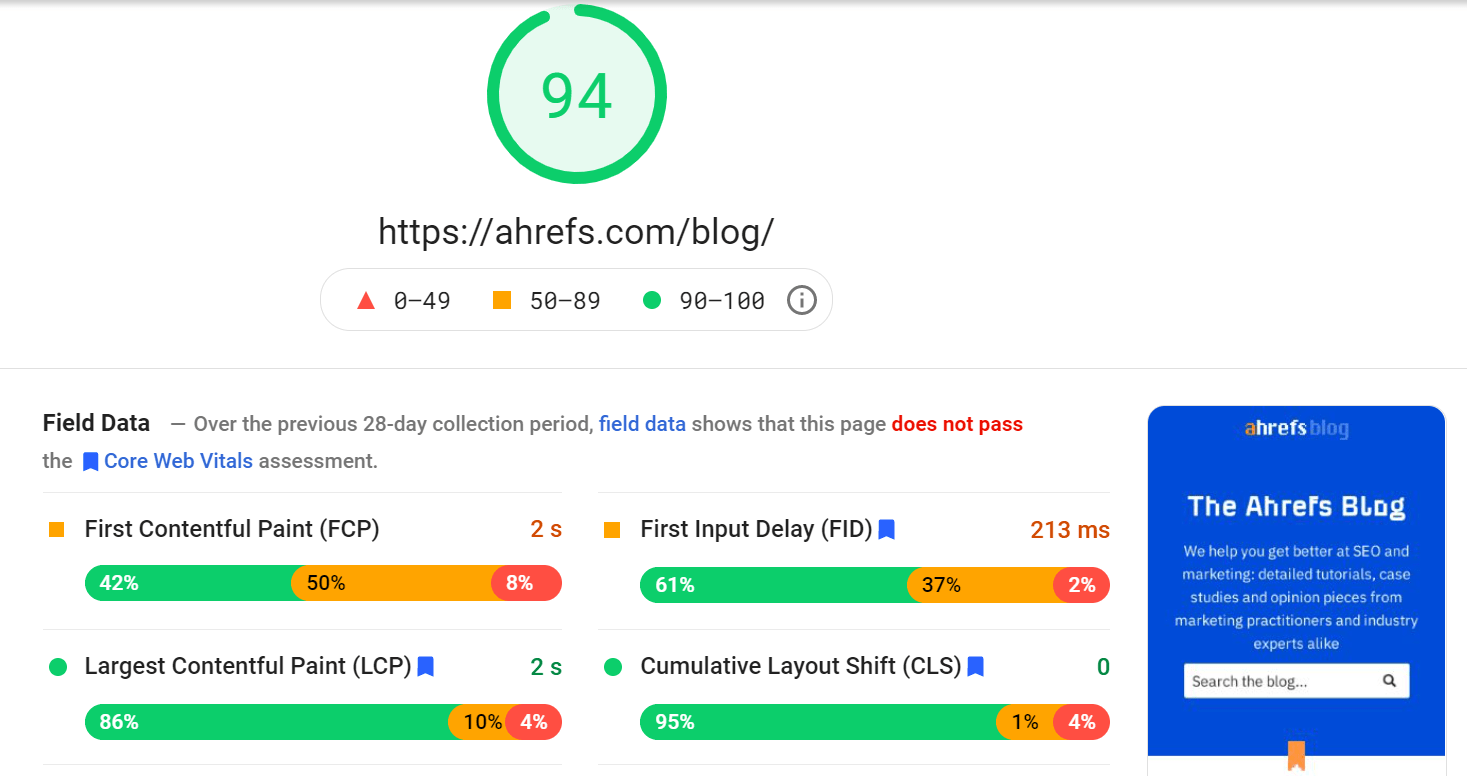
Core Web Vitals
Les Core Web Vitals (parfois appelé Signaux Web Essentiels en français) sont des signaux de vitesse qui font partie des facteurs de l’Expérience de Page Google. Ils servent à mesurer l’expérience utilisateur. Ces mesures prennent en compte le chargement visuel avec Largest Contentful Paint (LCP), la stabilité visuelle avec Cumulative Layout Shift (CLS) et l’interactivité de la page avec First Input Delay (FID)
HTTPS
Le protocole HTTPS empêche les communications entre un navigateur et un serveur d’être interceptées ou modifiées par des attaques informatiques. Cela assure la confidentialité, l’intégrité et l’authenticité de la majeure partie du trafic du web. Il faut que vos pages chargent en HTTPS et pas en HTTP.
Tout site qui montre un petit cadenas fermé dans la barre d’adresse utilise HTTPS.
Responsive design (mobile-friendly)
Pour faire simple, c’est la vérification que les pages s’affichent correctement et sont faciles d’utilisation pour les personnes naviguant sur mobile.
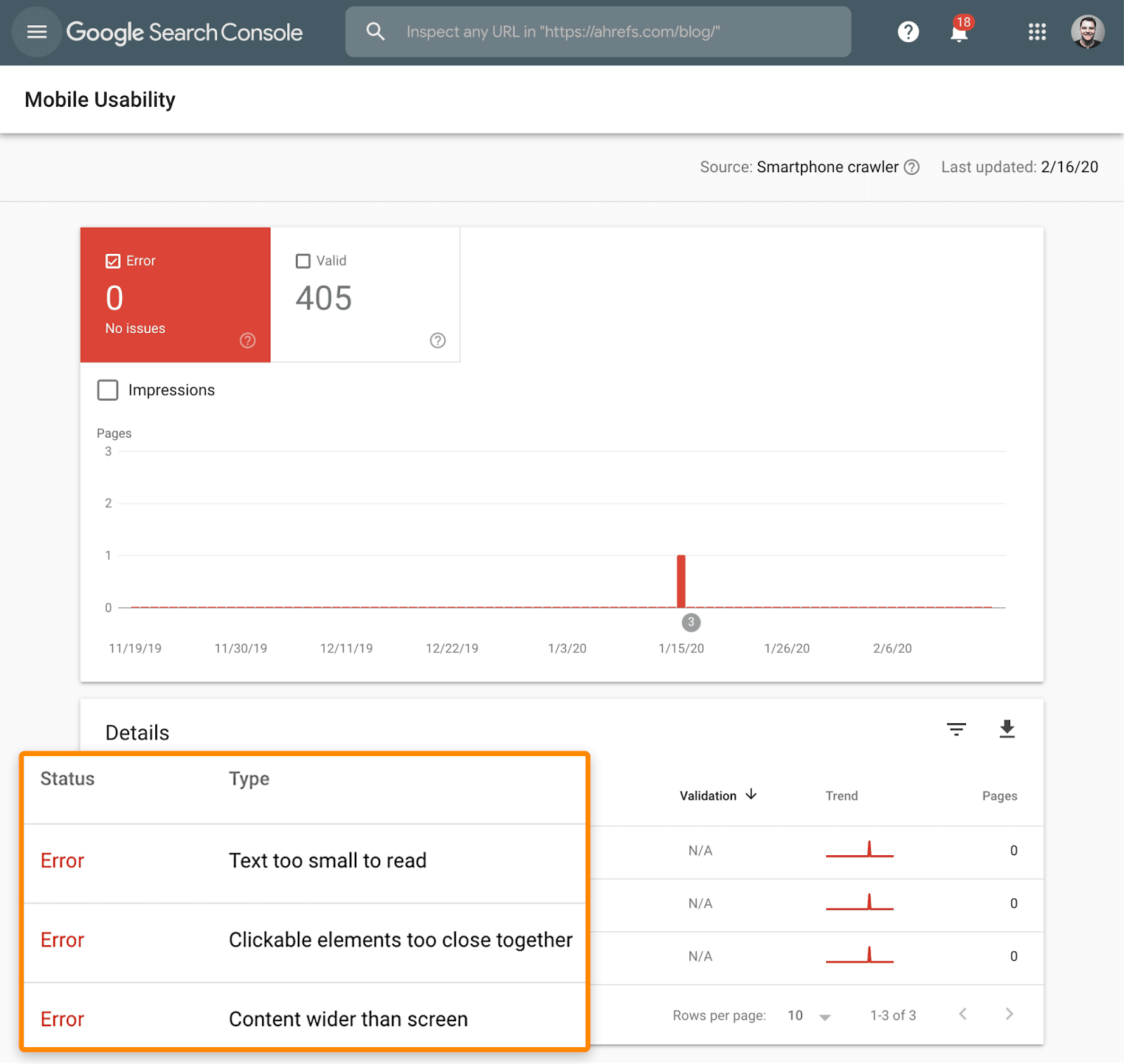
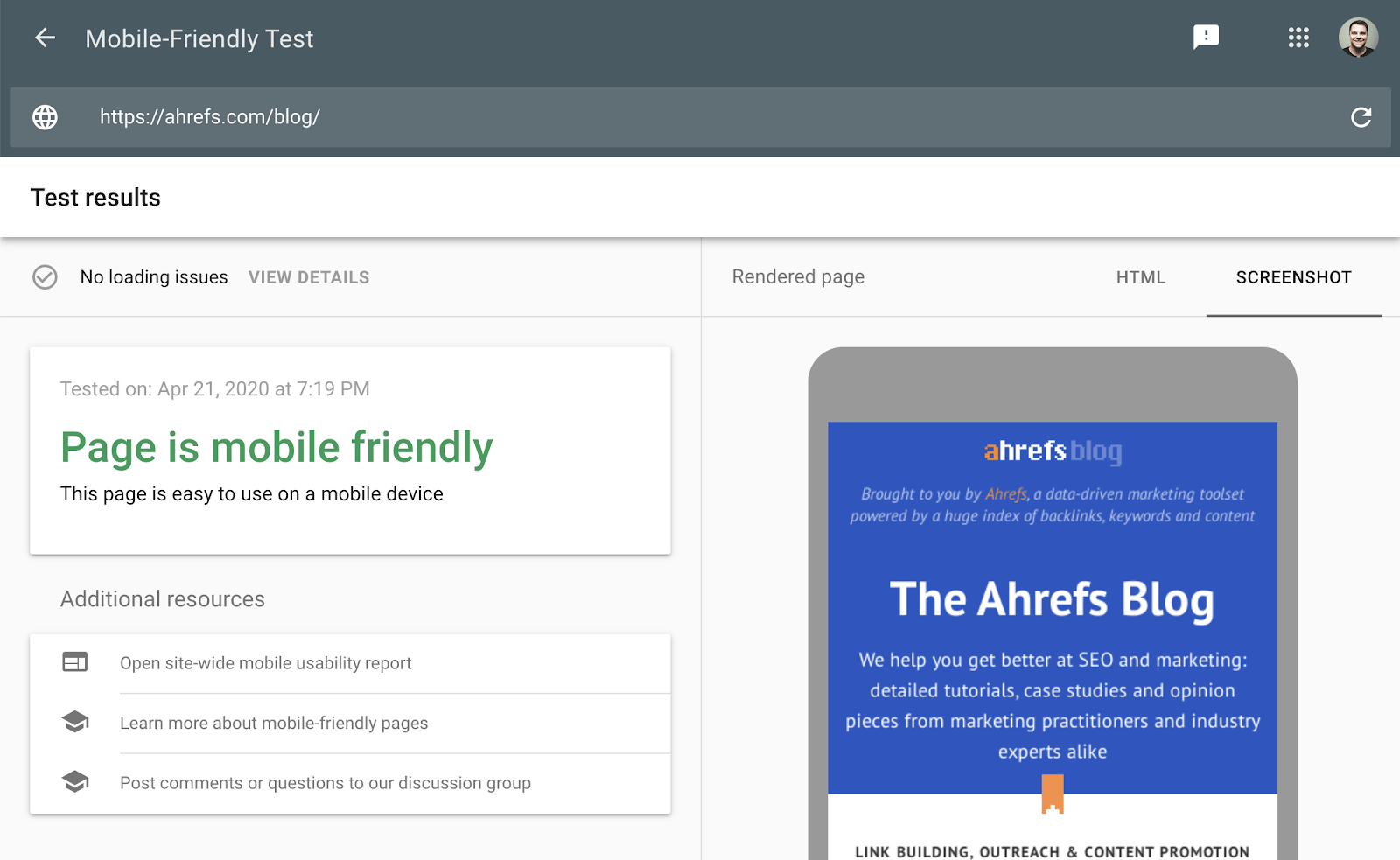
Vous voulez savoir si votre site est mobile-friendly ? Vérifiez le rapport “Ergonomie mobile” dans la Google Search Console.
Ce rapport va vous dire si certaines de vos pages présentent des problèmes de navigation sur mobile.
Navigation sécurisée
Ce sont des vérifications pour confirmer que vos pages ne sont pas trompeuses, ne contiennent pas de malwares ou de téléchargement potentiellement dangereux.
Éléments interstitiels
On appelle élément interstitiel ce qui cache votre contenu. Ça peut être des pop-up qui recouvrent le contenu principal avec lesquels les utilisateurs doivent interagir avant de pouvoir partir.
Hreflang - pour plusieurs langues
Hreflang est un attribut HTML utilisé pour préciser la langue et l’emplacement géographique visé pour une page. Si vous avez plusieurs versions d’une même page en plusieurs langues, vous pouvez utiliser ce code pour indiquer ces variations aux moteurs de recherche comme Google. Cela va les aider à proposer la bonne version à leurs utilisateurs.
Maintenance générale / santé du site
Ces étapes de vérification n’auront pas beaucoup d’impact sur votre positionnement, mais elles peuvent être importantes pour améliorer l’expérience utilisateur.
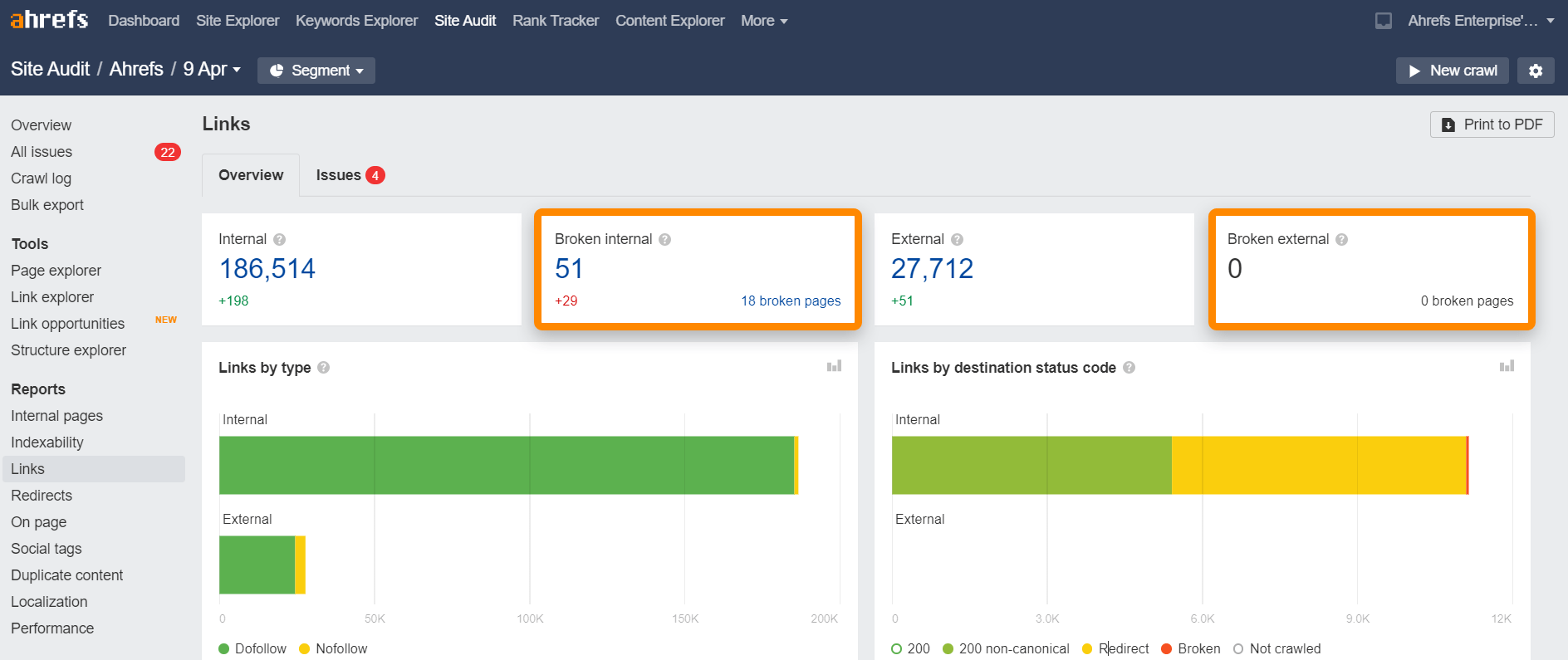
Liens morts
Les liens morts sont des liens qui pointent vers une ressource qui n’existe pas. Ça peut être interne (d’autres pages ou images de votre domaine) ou externe (des pages ou éléments d’un autre domaine)
Vous pouvez trouver les liens morts de votre site très rapidement grâce au rapport de liens de l’Audit de Site. C’est gratuit avec les Outils de webmaster Ahrefs.
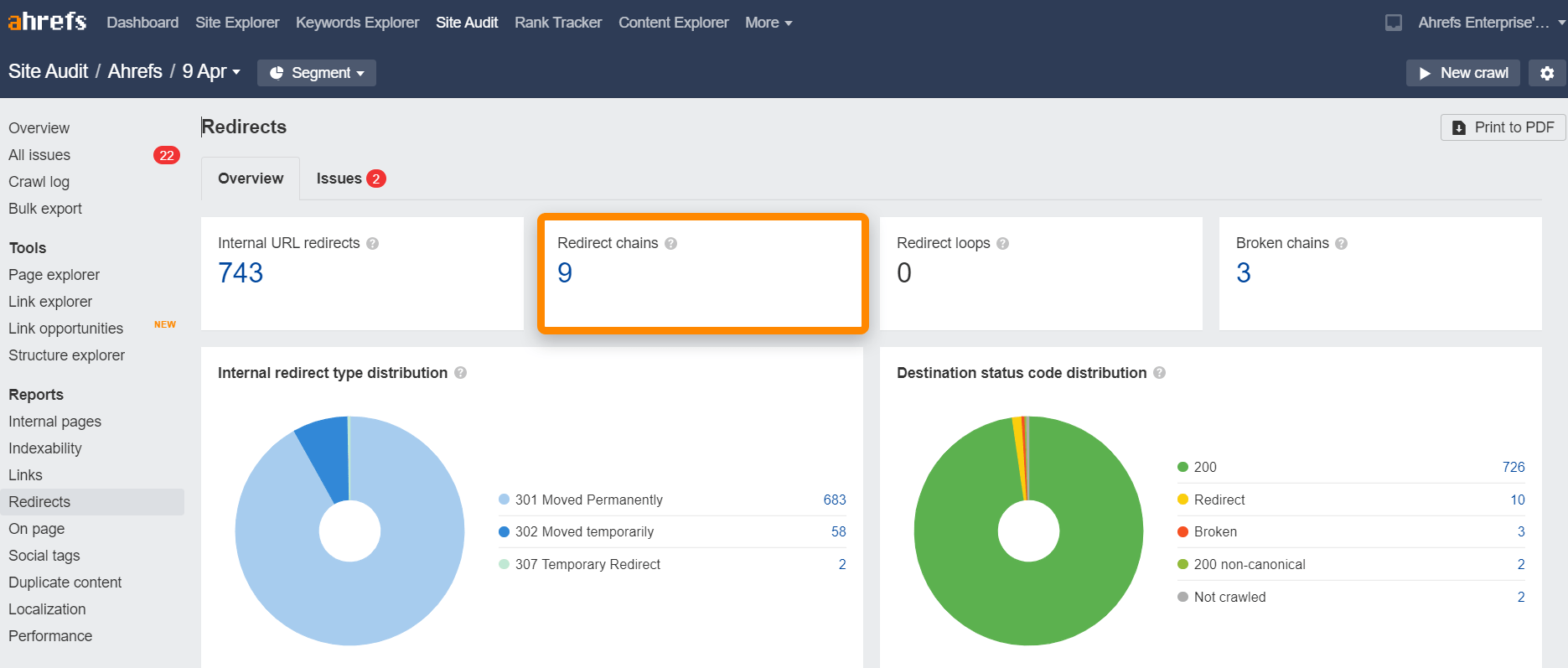
Chaînes de redirection
Les chaînes de redirection sont une série de redirections entre l’URL initiale et celle de destination.
Vous pouvez trouver les chaînes de redirection de votre site très rapidement grâce au rapport de redirection de l’Audit de Site. C’est gratuit avec les Outils de webmaster Ahrefs.
La Google Search Console (qui s’appelait Google Webmaster Tools auparavant) est un service gratuit de Google qui va vous aider à suivre et corriger l’apparence de votre site dans les résultats de recherche.
Utilisez-la pour dénicher et corriger les problèmes techniques, soumettre des sitemaps, voir les problèmes de données structurées et bien plus encore.
Bing et Yandex disposent de leurs propres versions de cet outil, tout comme Ahrefs. Les Outils de Webmaster de Ahrefs sont gratuits et vous aideront à améliorer les performances SEO de votre site. Ils vous permettent de :
Suivre la santé SEO de votre site
Suivre plus de 100 problèmes fréquents en SEO
Voir vos backlinks
Voir les mots-clés sur lesquels vous êtes positionné
Le Mobile Friendly Test de Google vérifie si un utilisateur de mobile aura une bonne expérience sur votre site. Il va également identifier les problèmes potentiels : texte trop petit pour la lecture, éléments cliquables trop proches, plugins incompatibles, etc.
Ce test de compatibilité mobile montre ce que Google voit lorsqu’il explore la page. Vous pouvez aussi utiliser le Rich Results Test pour voir le contenu comme Google le perçoit sur mobile comme sur ordinateur.
Le Chrome DevTools est un outil directement inclus dans le navigateur qui sert à détecter et corriger les bugs. Utilisez-le pour en apprendre plus sur vos problèmes de vitesse, chargement, améliorer la performance de votre page et bien plus encore.
En termes de SEO technique, il est extrêmement utile.
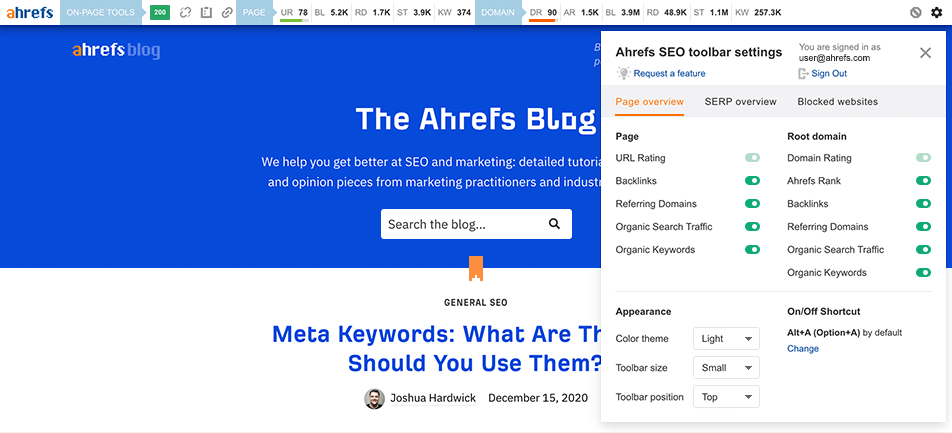
La barre d’outils SEO Ahrefs est une extension gratuite pour Chrome et Firefox qui vous fournit des données SEO utiles sur les pages et sites que vous visitez.
Dans sa version gratuite, vous aurez :
Rapport de SEO on-page
Tests de redirection avec les headers HTTP
Vérificateur de liens morts
Surlignement de liens
Position dans le SERP (page de résultats de recherche)
En plus de cela, si vous êtes un client Ahrefs, vous aurez aussi accès à :
Mesures SEO pour tous les sites ou pages que vous visitez et les résultats de recherche Google.
Données de mots-clés, comme le volume de recherche et la difficulté de mot-clé directement dans le SERP
L’outil PageSpeed Insight analyse la vitesse de chargement des pages web. En plus des scores de performance, vous obtiendrez un grand nombre de recommandations pour vous aider à optimiser le temps de chargement.
Pour conclure
Nous n’avons fait qu’effleurer la surface de ce qu’est le SEO technique. Mais cela devrait vous aider à comprendre les bases, avec des liens vers d’autres guides pour aller plus loin. Il y a beaucoup d’autres sujets que nous n’avons pas couverts dans ce guide, je vous ai donc compilé une autre liste si vous voulez en apprendre plus.