


The Beginner’s Guide to Technical SEO

By Patrick Stox
Technical SEO at Ahrefs


Technical SEO is the most important part of SEO until it isn’t. Pages need to be crawlable and indexable to even have a chance at ranking, but many other activities will have minimal impact compared to content and links.
We wrote this beginner’s guide to help you understand some of the basics and where your time is best spent to maximize impact.
Technical SEO basics
What is technical SEO?
Technical SEO is the practice of optimizing your website to help search engines find, crawl, understand, and index your pages. It helps increase visibility and rankings in search engines. It matters for AI search, too.
How complicated is technical SEO?
It depends. The fundamentals aren’t really difficult to master, but technical SEO can be complex and hard to understand. I’ll keep things as simple as I can with this guide.
Does technical SEO matter for AI search?
Yes. AI search still depends on crawlable, well-structured, trustworthy web pages. Technical SEO ensures your site is fast, accessible, and indexable, all of which improve the chances your content is used in AI-driven answers as well as traditional search.
Understanding crawling
In this chapter, we’ll cover how to make sure search engines can efficiently crawl your content.
How crawling works
Crawling is where search engines grab content from pages and use the links on them to find even more pages. There are a few ways you can control what gets crawled on your website. Here are a few options.
Robots.txt
A robots.txt file tells search engines and AI platforms where they can and can’t go on your site.
Most search engines and AI crawlers respect your robots.txt settings. If you explicitly disallow them, they’ll obey and won’t crawl your content or include it in training data. But if you block search engines and LLMs from using your website as training material, you also limit your chances of becoming visible in their responses.
Did you know?
Google and some LLMs may index pages that they can’t crawl if links are pointing to those pages. This can be confusing, but if you want to keep pages from being indexed, check out this guide and flowchart which can guide you through the process.
LLMs.txt
LLMs.txt is a voluntary standard for telling large language models (LLMs) how they can use your content, but as we explain in our guide to LLMs.txt, it’s not especially effective and likely not worth the effort.
There’s no evidence yet that LLMs.txt improves AI retrieval, boosts traffic, or enhances model accuracy.
Crawl rate
Access restrictions
If you want the page to be accessible to some users but not search engines, then what you probably want is one of these three options:
- Some kind of login system
- HTTP authentication (where a password is required for access)
- IP whitelisting (which only allows specific IP addresses to access the pages)
This type of setup is best for things like internal networks, member-only content, or for staging, test, or development sites. It allows for a group of users to access the page, but search engines will not be able to access the page and will not index it.
How to see crawl activity
For Google specifically, the easiest way to see what it’s crawling is with the ”Crawl stats” report in Google Search Console, which gives you more information about how it’s crawling your website.
If you want to see all crawl activity on your website, including from AI crawlers, then you will need to access your server logs and possibly use a tool to better analyze the data. This can get fairly advanced. But if your hosting has a control panel like cPanel, you should have access to raw logs and some aggregators like AWstats and Webalizer.
Crawl adjustments
Each website is going to have a different crawl budget, which is a combination of how often Google wants to crawl a site and how much crawling your site allows. More popular pages and pages that change often will be crawled more often, and pages that don’t seem to be popular or well linked will be crawled less often.
If crawlers see signs of stress while crawling your website, they’ll typically slow down or even stop crawling until conditions improve.
After pages are crawled, they’re rendered and sent to the index. The index is the master list of pages that can be returned for search queries. Let’s talk about the index.
Understanding indexing
In this chapter, we’ll talk about how to make sure your pages are indexed and check how they’re indexed.
Robots directives
A robots meta tag is an HTML snippet that tells search engines how to crawl or index a certain page. It’s placed into the <head> section of a webpage and looks like this:
<meta name="robots" content="noindex" />
Canonicalization
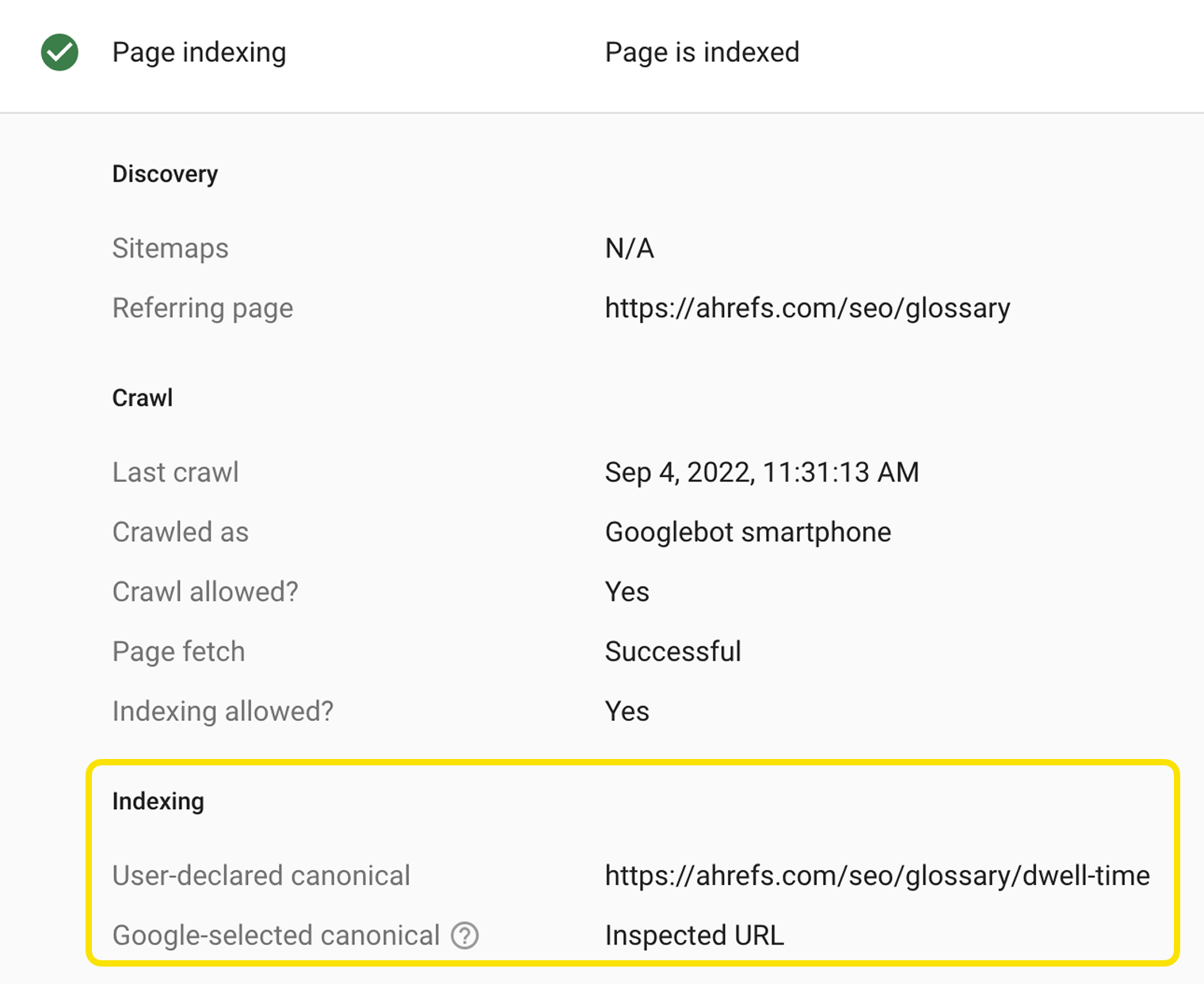
When there is duplicate content creating multiple versions of the same page, Google will select one to store in its index. This process is called canonicalization and the URL selected as the canonical will be the one Google shows in search results. There are many different signals it uses to select the canonical URL including:
The easiest way to see how Google has indexed a page is to use the URL Inspection tool in Google Search Console. It will show you the Google-selected canonical URL.
Technical SEO quick wins
One of the hardest things for SEOs is prioritization. There are a lot of best practices, but some changes will have more of an impact on your rankings and traffic than others. Here are some of the projects I’d recommend prioritizing.
Check indexing
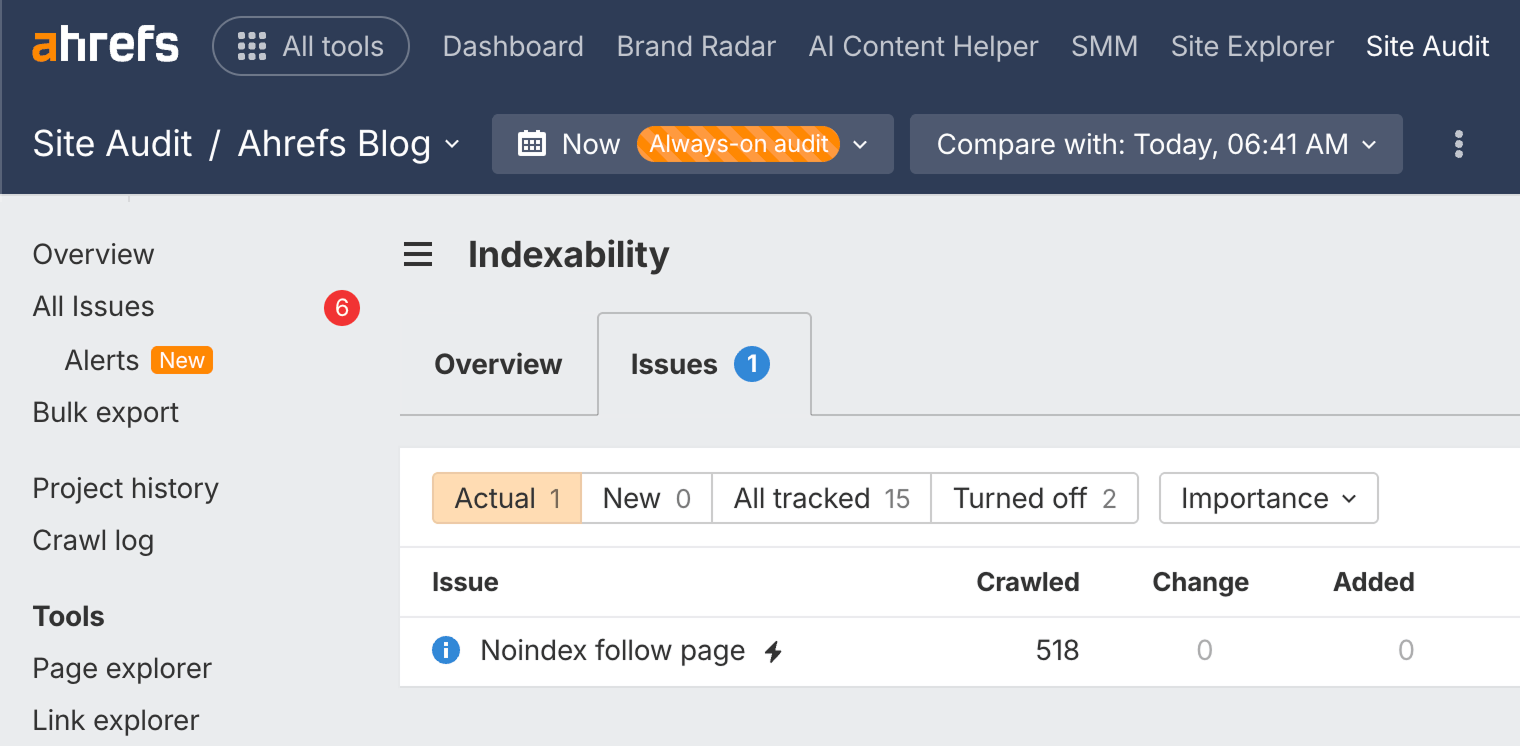
Make sure pages you want people to find can be indexed in Google. The two previous chapters were all about crawling and indexing, and that was no accident.
You can check the Indexability report in Site Audit to find pages that can't be indexed and the reasons why. It's available in Ahrefs Free.
Run a free technical SEO audit
Signing up here gives you access to Ahrefs Free ↗
Reclaim lost links
Websites tend to change their URLs over the years. In many cases, these old URLs have links from other websites. If they’re not redirected to the current pages, then those links are lost and no longer count for your pages. It’s not too late to do these redirects, and you can quickly reclaim any lost value. Think of this as the fastest link building you will ever do.
You can find opportunities to reclaim lost links using Ahrefs’ Site Explorer. Enter your domain, go to the Best by Links report, and add a ”404 not found” HTTP response filter. I usually sort this by ”Referring Domains”.
This is what it looks like for 1800flowers.com:
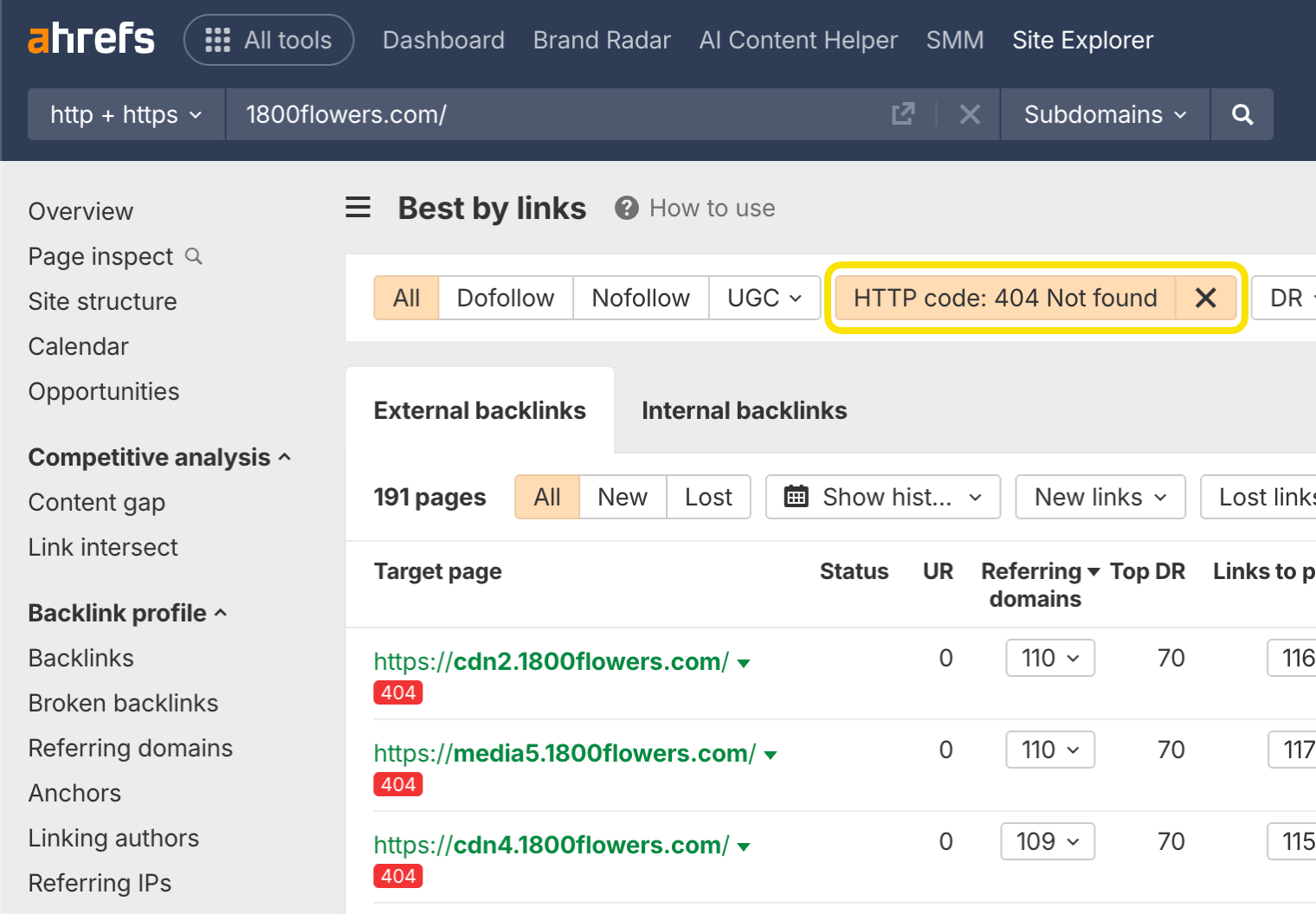
Looking at the first URL in archive.org, I see that this was previously the Mother’s Day page. By redirecting that one page to the current version, you’ll reclaim 225 links from 59 different websites—and there are plenty more opportunities.
I even created a script to help you match redirects. Don’t be scared away; you just have to download a couple of files and upload them. The Colab notebook walks you through it and takes care of the heavy lifting for you.
You’ll want to 301 redirect any old URLs to their current locations to reclaim this lost value.
Did you know?
A 301 redirect is a permanent redirect. Any links pointing to the redirected URL will count toward the new URL in Google’s eyes.[3]
Add internal links
Internal links are links from one page on your site to another page on your site. They help your pages be found and also help the pages rank better. We have a tool within Site Audit called Internal Link Opportunities that helps you quickly locate these opportunities.
This tool works by looking for mentions of keywords that you already rank for on your site. Then it suggests them as contextual internal link opportunities.
For example, the tool shows a mention of “faceted navigation” in our guide to duplicate content. As Site Audit knows we have a page about faceted navigation, it suggests we add an internal link to that page.

Add schema markup
Schema markup is code that helps search engines understand your content better and powers many features that can help your website stand out from the rest in search results. It may also help LLMs correctly interpret your page content. Google has a search gallery that shows the various search features and the schema needed for your site to be eligible.
Technical SEO for AI search
AI has changed how content is found and displayed to searchers, but it still depends on a foundation of crawlable, well-structured, and trustworthy web pages. It’s also changing how we create and optimize content.
Paying attention to a few AI-specific technical factors can help you stay visible wherever people search for information.
Make your site accessible to LLMs
Like search engines, LLMs need to be able to crawl your website and access its content. However, they work a little differently from search engine crawlers.
For instance, most LLMs don’t render JavaScript, a common coding language used to build websites. If key content or navigation only appears after JavaScript loads, there’s a risk some AI crawlers won’t see it. So, it’s best to avoid using it for any mission-critical content that you want visible in AI search.
It’s also worth checking whether third-party tools are blocking AI crawlers from accessing your website.
For instance, Cloudflare introduced new features allowing website owners to control whether AI platforms can scrape content for their training datasets.
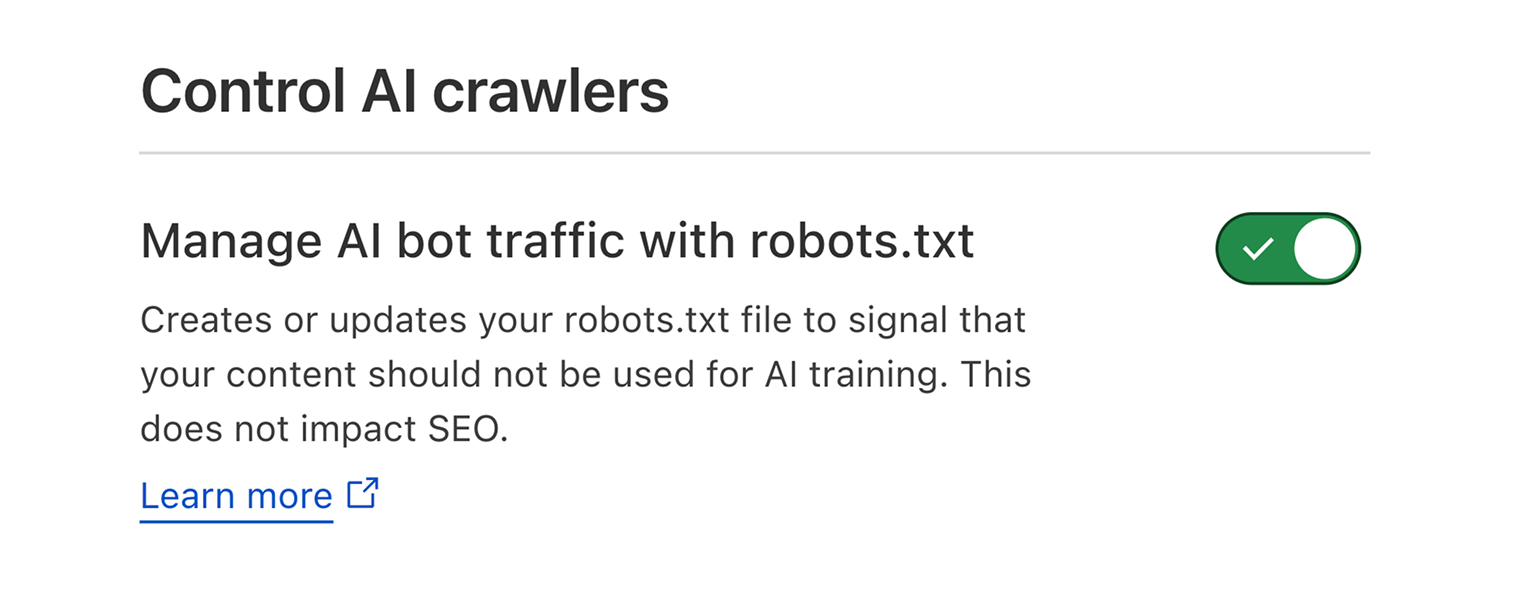
The default setting blocks AI crawlers from accessing content. However, you’ll need to switch it off if you want your content to maximize your visibility in AI search results.
Redirect hallucinated URLs
AI search systems may cite URLs on your domain that don’t exist. You can discover these in Ahrefs’ Web Analytics by looking at pages that receive AI search traffic:
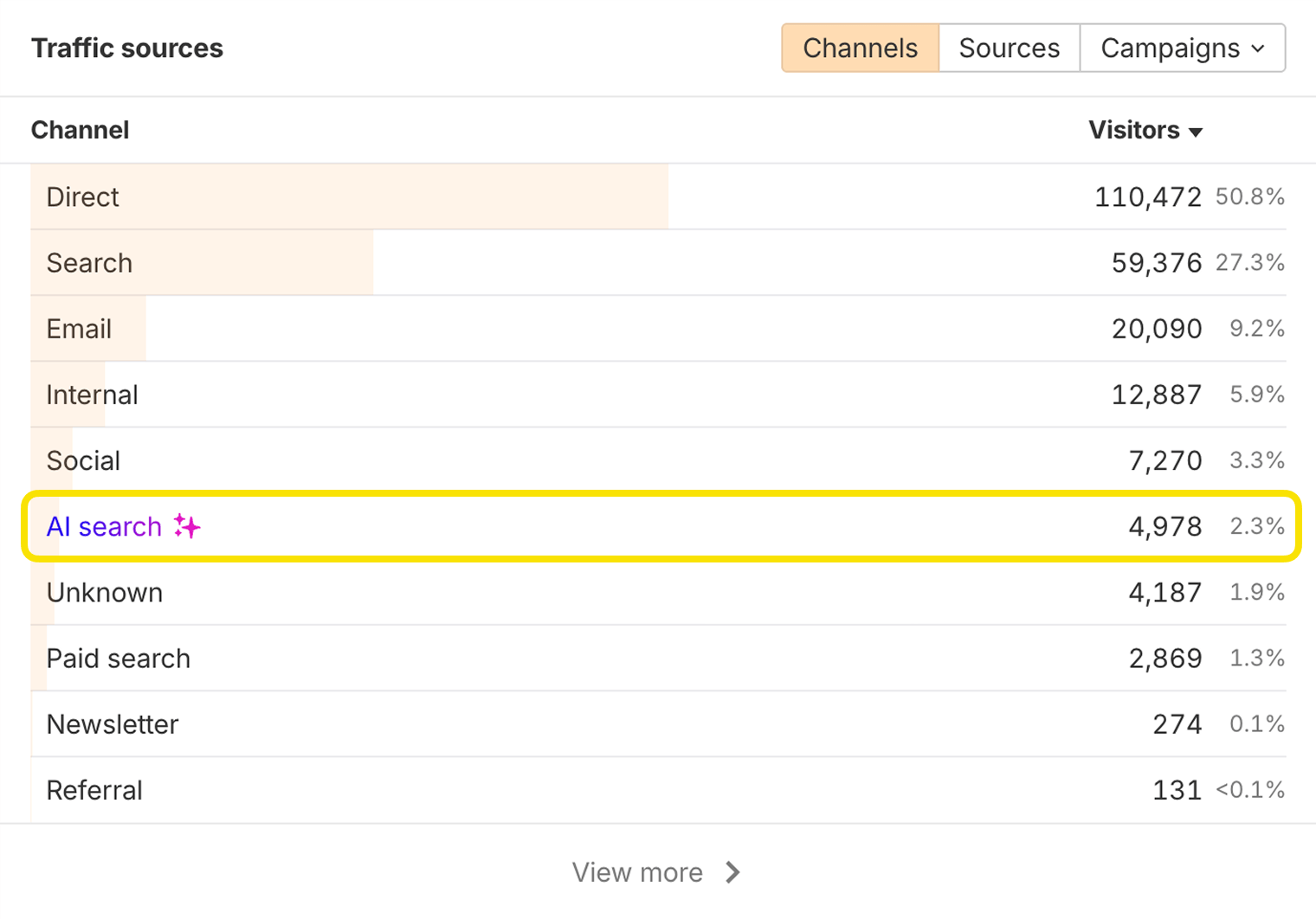
If any of these pages resolve to a 404 error, the AI system may have hallucinated the URL. To avoid losing traffic, you can redirect that URL to a relevant live page.
Regular monitoring prevents user frustration and protects brand authority.
AI content detection
Although it is fine to use AI to create content for your website, too much AI content can be seen as a spam signal that limits your content’s visibility in traditional and AI search systems.
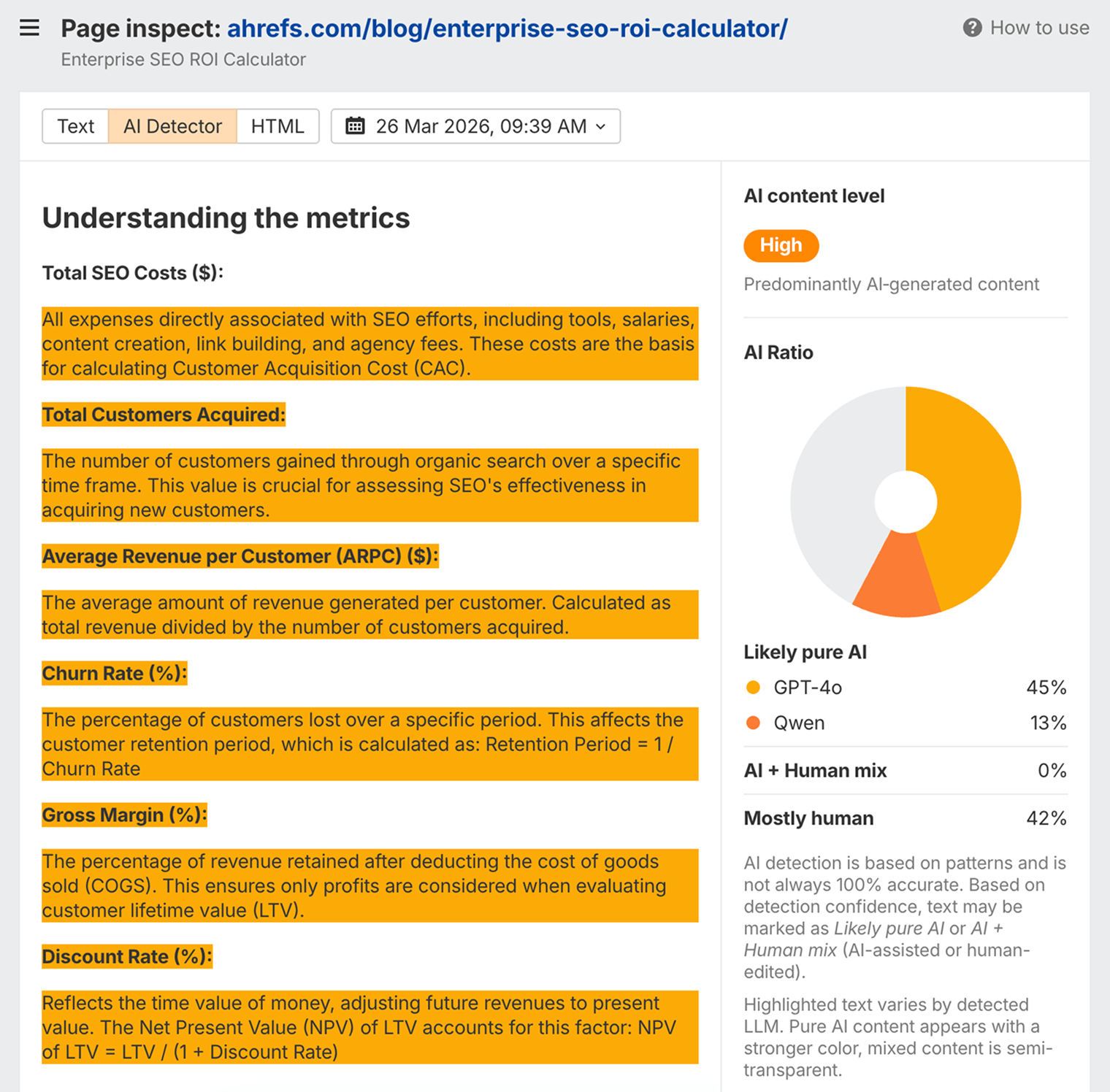
You can use Ahrefs’ AI detector within Site Explorer > Page Inspect to see how machines may interpret the level of AI used in your content.
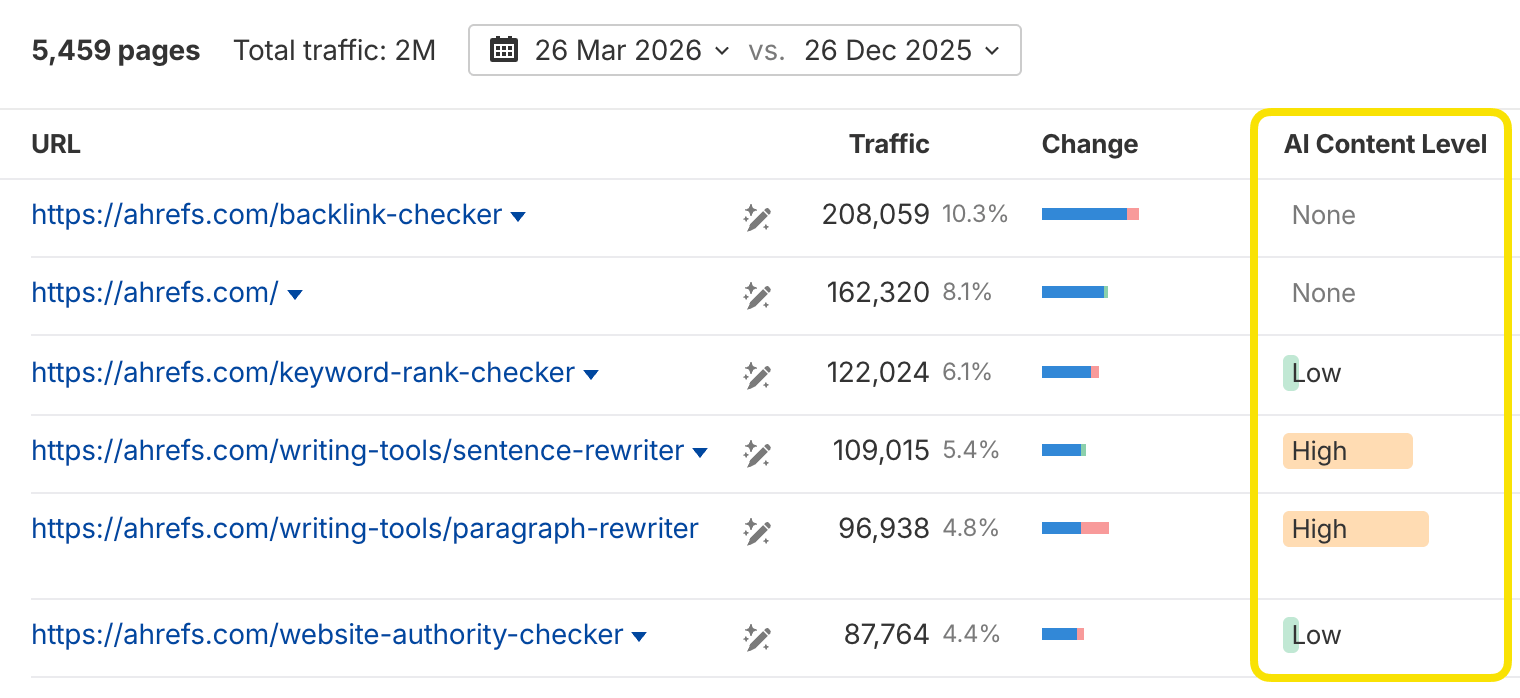
You can also check this in bulk in the Top Pages report to spot existing pages that may need to be rewritten:
Code injected by AI tools
If you’ve used AI to help build your website or add new features to it, they may add extra HTML code that reveals AI was used.
In one case, a Yoast SEO bug inserted hidden AI-related classes into pages, making it obvious to search engines that AI was involved.

If you use AI tools to make on-page changes, check your site’s source code to ensure nothing unexpected is being added. Hidden “fingerprints” like this can be avoided with regular code reviews and testing before publishing updates.
Additional technical SEO projects
The projects we’ll talk about in this chapter are all good things to focus on, but they may require more work and have less benefit than the "quick win" projects from the previous part. That doesn’t mean you shouldn’t do them. This is just to help you get an idea of how to prioritize various projects.
Page experience signals
These are lesser ranking factors, but still things you want to look at for the sake of your users. They cover aspects of the website that impact user experience (UX).
Google’s Search Signals for Page Experience
https://ahrefs.com/blog/core-web-vitals/
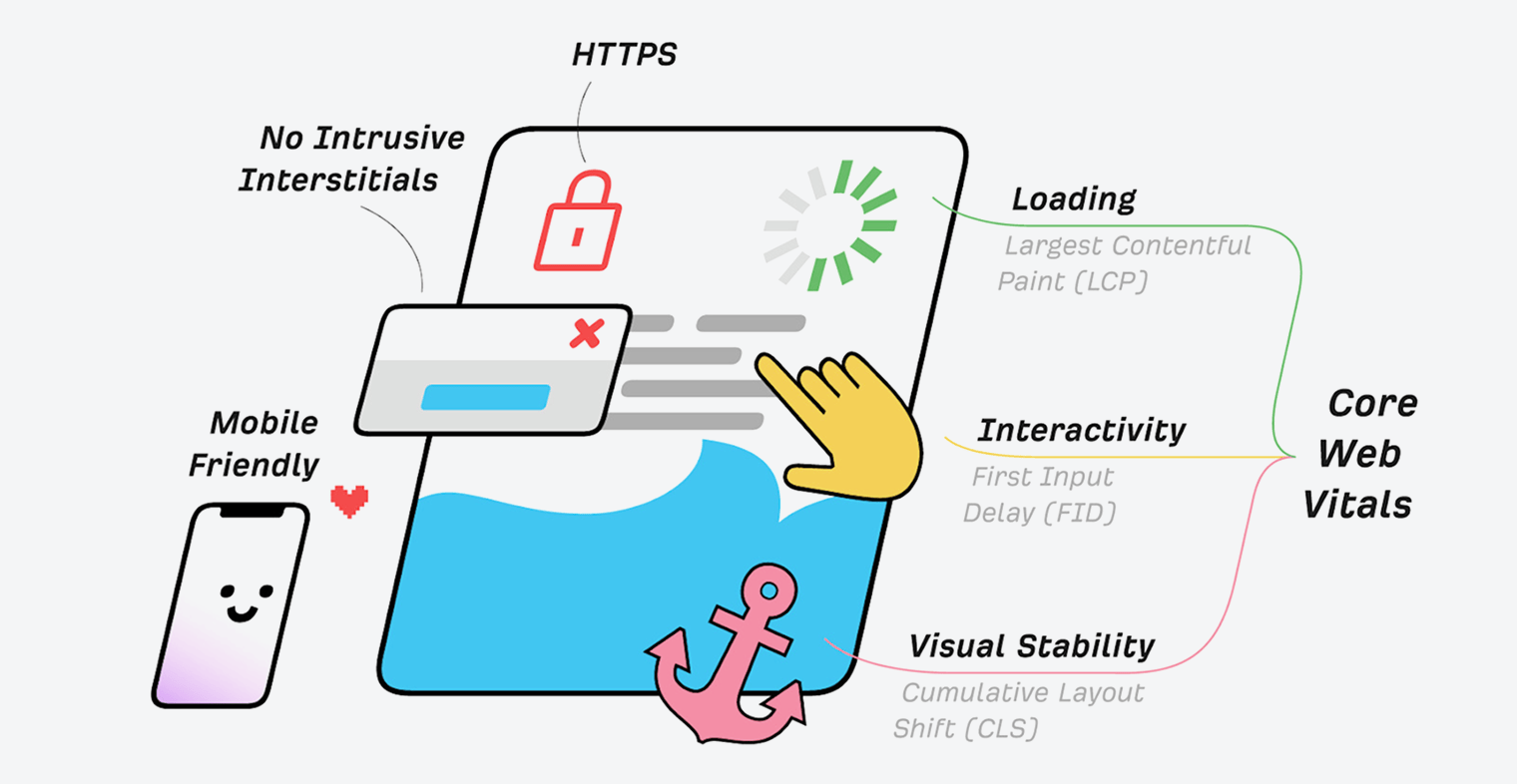
Core Web Vitals
Core Web Vitals are the speed metrics that are part of Google’s Page Experience signals used to measure user experience. The metrics measure visual load with Largest Contentful Paint (LCP), visual stability with Cumulative Layout Shift (CLS), and interactivity with First Input Delay (FID).
HTTPS
HTTPS protects the communication between your browser and server from being intercepted and tampered with by attackers. This provides confidentiality, integrity, and authentication to the vast majority of today’s WWW traffic. You want your pages loaded over HTTPS and not HTTP.
Any website that shows a “lock” icon in the address bar is using HTTPS.

Mobile-friendliness
Simply put, this checks if webpages display properly and are easily used by people on mobile devices.
How do you know how mobile-friendly your site is? Check the ”Mobile Usability” report in Google Search Console.
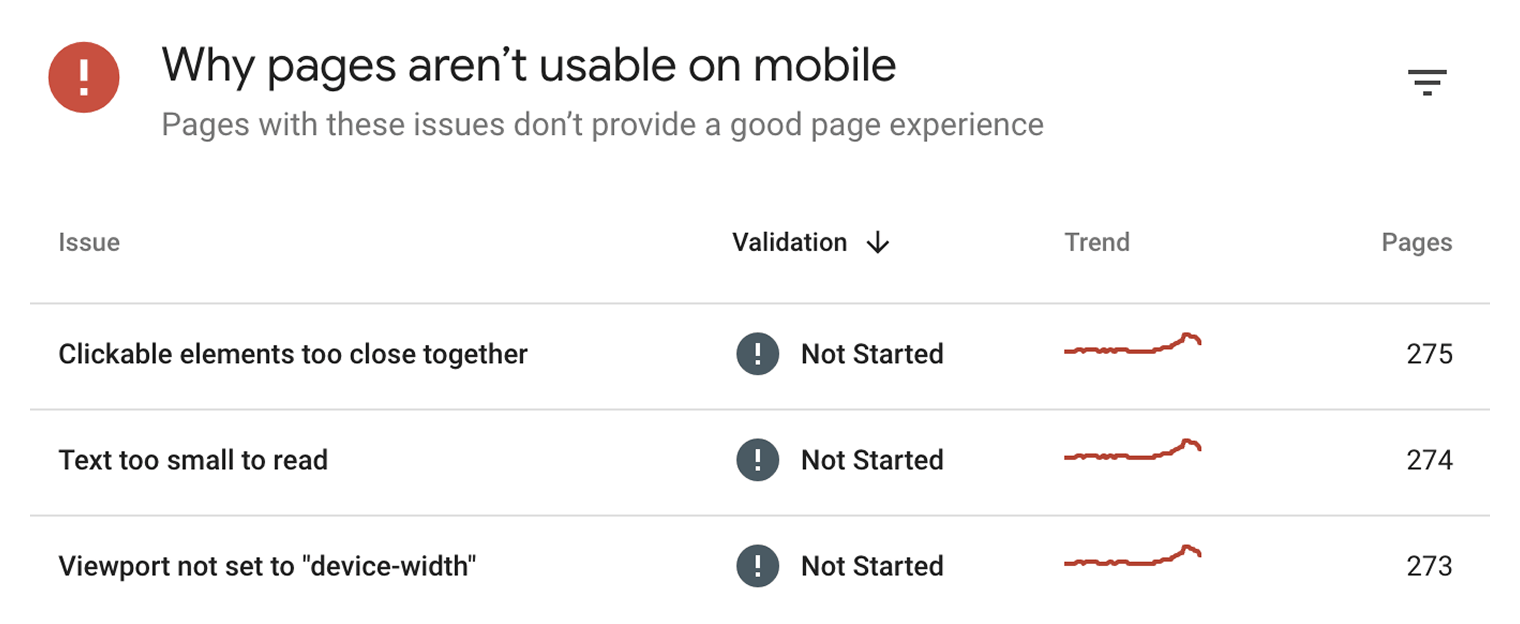
This report tells you if any of your pages have mobile-friendliness issues.
Interstitials
Interstitials block content from being seen. These are popups that cover the main content and that users may have to interact with before they go away.
Hreflang — For multiple languages
Hreflang is an HTML attribute used to specify the language and geographical targeting of a webpage. If you have multiple versions of the same page in different languages, you can use the hreflang tag to tell search engines like Google about these variations. This helps them to serve the correct version to their users.
Ahrefs now helps make hreflang implementation easier with a visual hreflang link graph in Site Audit.
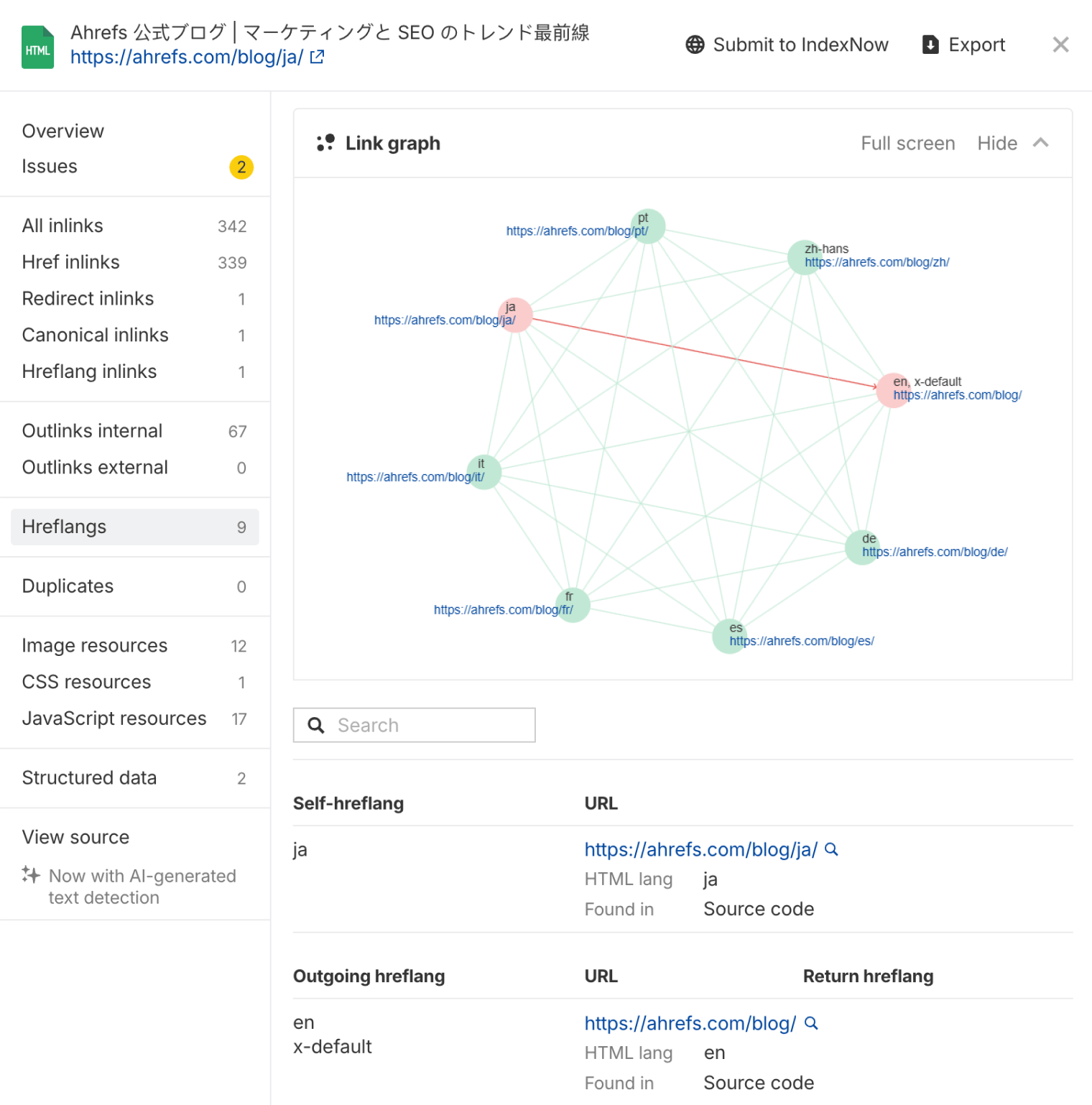
This hreflang graph shows all language variants of a page and highlights any configuration issues. Plus, it flags errors like invalid language codes, missing self-links, and a lack of reciprocal tags and gives clear guidance on how to fix them.
General maintenance/website health
These tasks aren’t likely to have much impact on your rankings but are generally good things to fix for user experience.
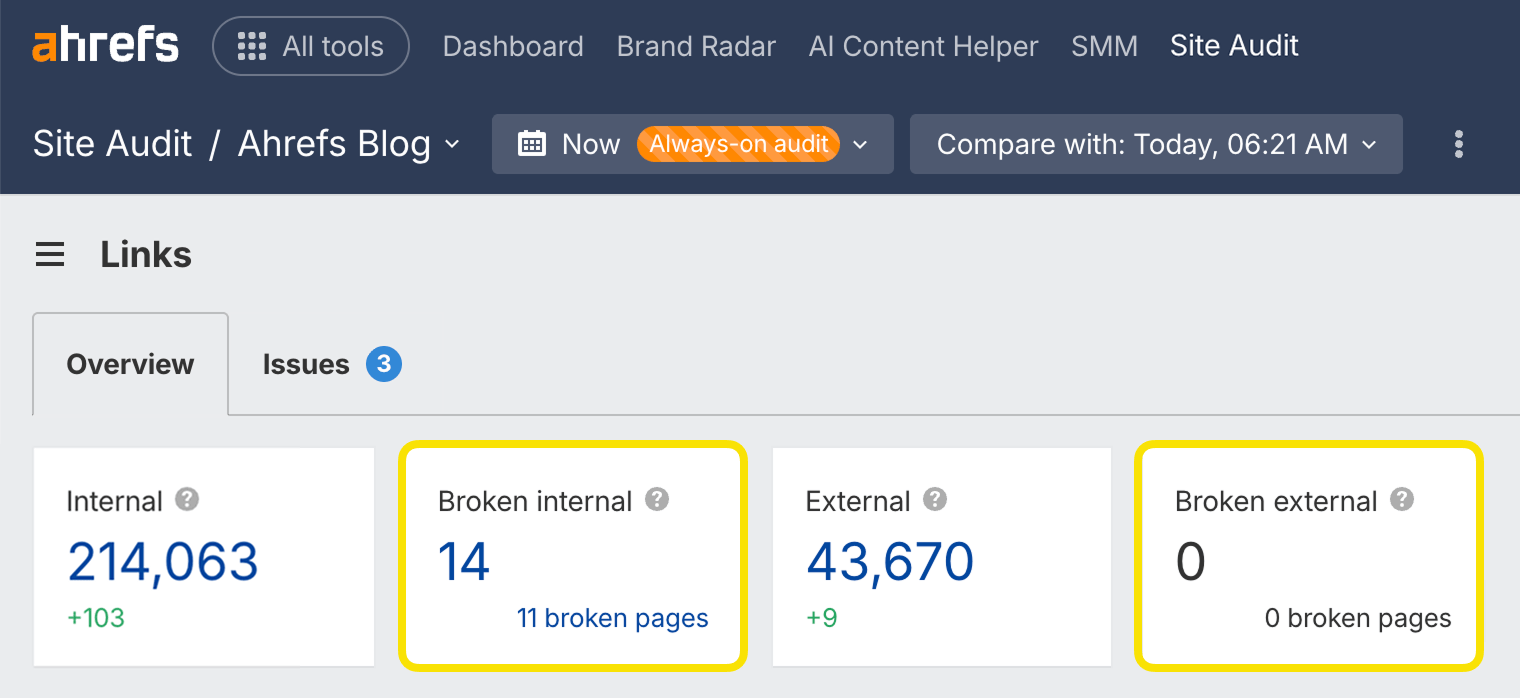
Broken links
Broken links are links on your site that point to non-existent resources. These can be either internal (i.e., to other pages on your domain) or external (i.e., to pages on other domains).
You can find broken links on your website quickly with Site Audit in the Links report. It's available in Ahrefs Free.
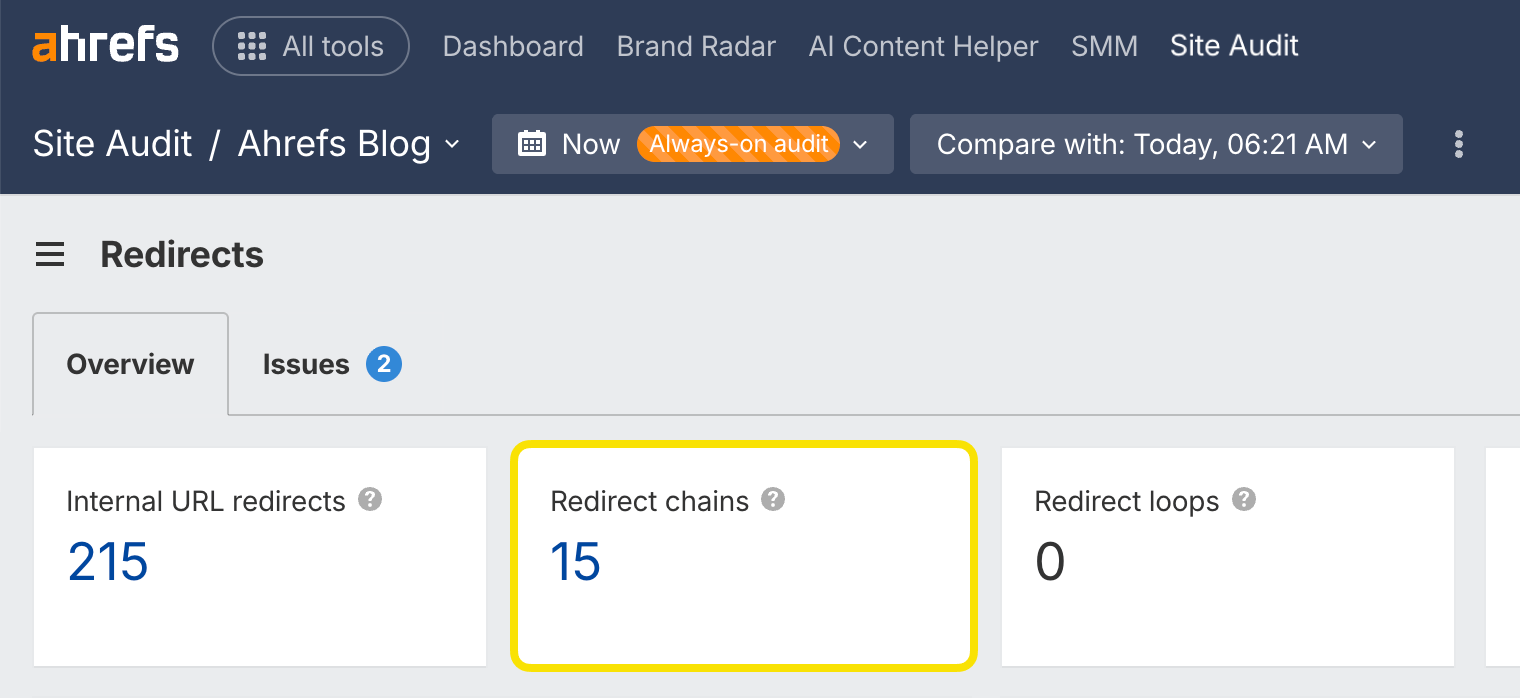
Redirect chains
Redirect chains are a series of redirects that happen between the initial URL and the destination URL.
You can find redirect chains on your website quickly with Site Audit in the Redirects report. It's available in Ahrefs Free.
Technical SEO tools
These tools help you improve the technical aspects of your website.
Google Search Console (previously Google Webmaster Tools) is a free service from Google that helps you monitor and troubleshoot your website’s appearance in its search results.
Use it to find and fix technical errors, submit sitemaps, see structured data issues, and more.
Bing and Yandex have their own versions, and so does Ahrefs. Ahrefs Free helps you improve your website's SEO performance. It allows you to:
- Monitor your website’s SEO health.
- Check for 100+ SEO issues.
- View all your backlinks.
- See all the keywords you rank for.
- Find out how much traffic your pages are receiving.
- Find internal linking opportunities.
It’s our answer to the limitations of Google Search Console.
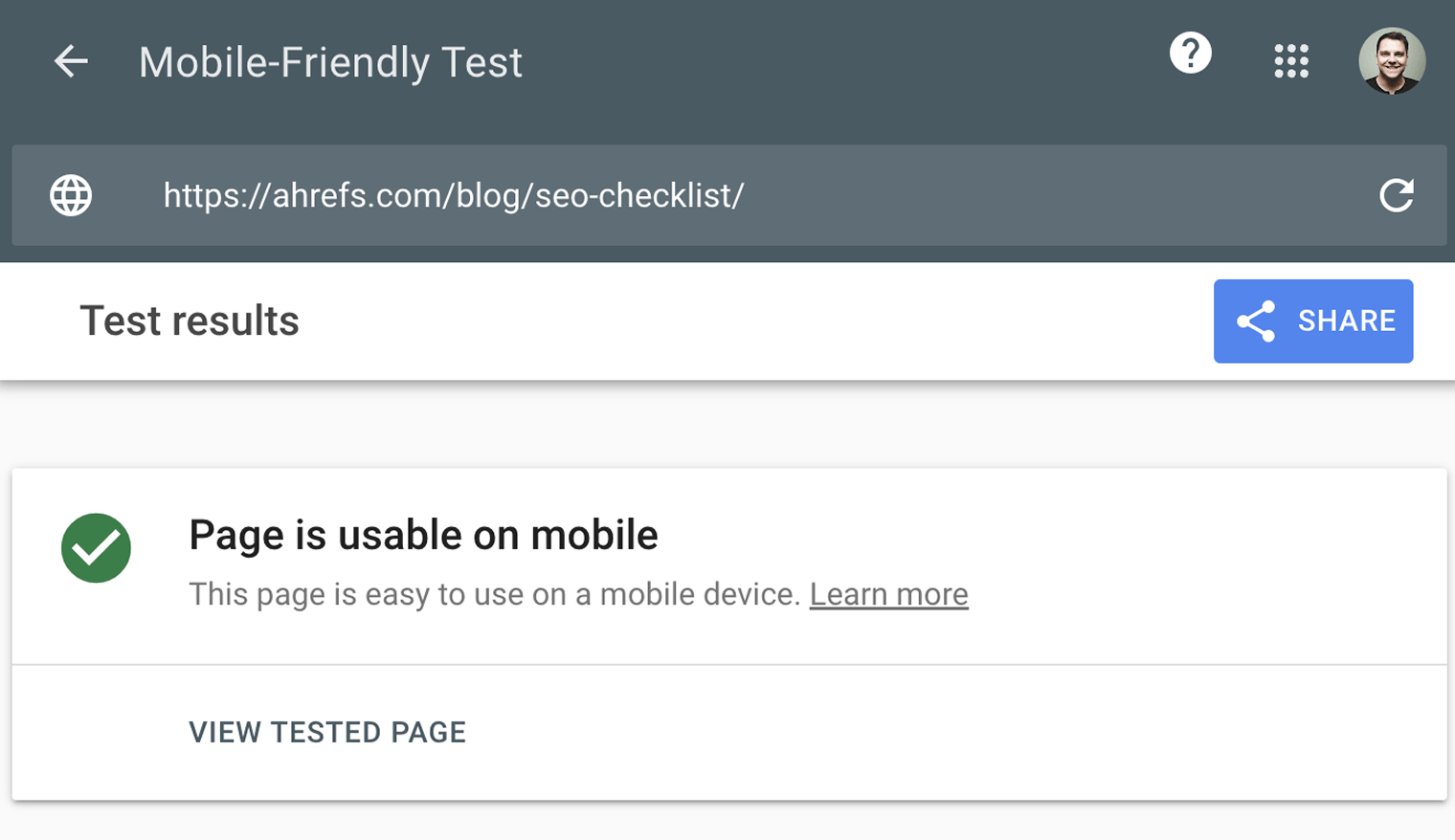
Google’s Mobile-Friendly Test checks how easily a visitor can use your page on a mobile device. It also identifies specific mobile-usability issues like text that’s too small to read, the use of incompatible plugins, and so on.
The Mobile-Friendly Test shows what Google sees when it crawls the page. You can also use the Rich Results Test to see the content Google sees for desktop or mobile devices.
Chrome DevTools is Chrome’s built-in webpage debugging tool. Use it to debug page speed issues, improve webpage rendering performance, and more.
From a technical SEO standpoint, it has endless uses.
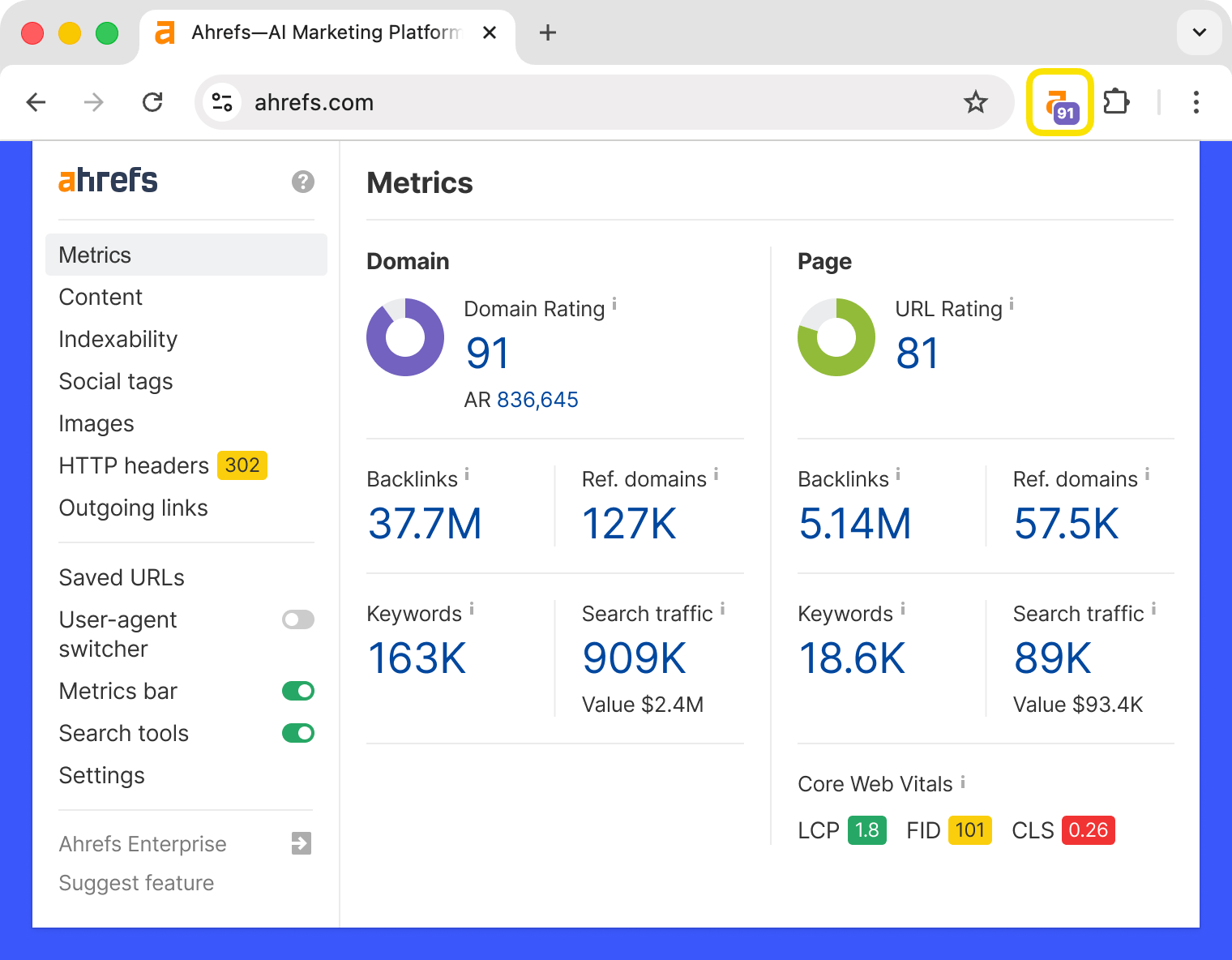
Ahrefs’ SEO Toolbar is a free extension for Chrome and Firefox that provides useful SEO data about the pages and websites you visit.
Its free features are:
- On-page SEO report
- Redirect tracer with HTTP headers
- Broken link checker
- Link highlighter
- SERP positions
In addition, as an Ahrefs user, you get:
- SEO metrics for every site and page you visit and for Google search results
- Keyword metrics, such as search volume and Keyword Difficulty, directly in the SERP
- SERP results export
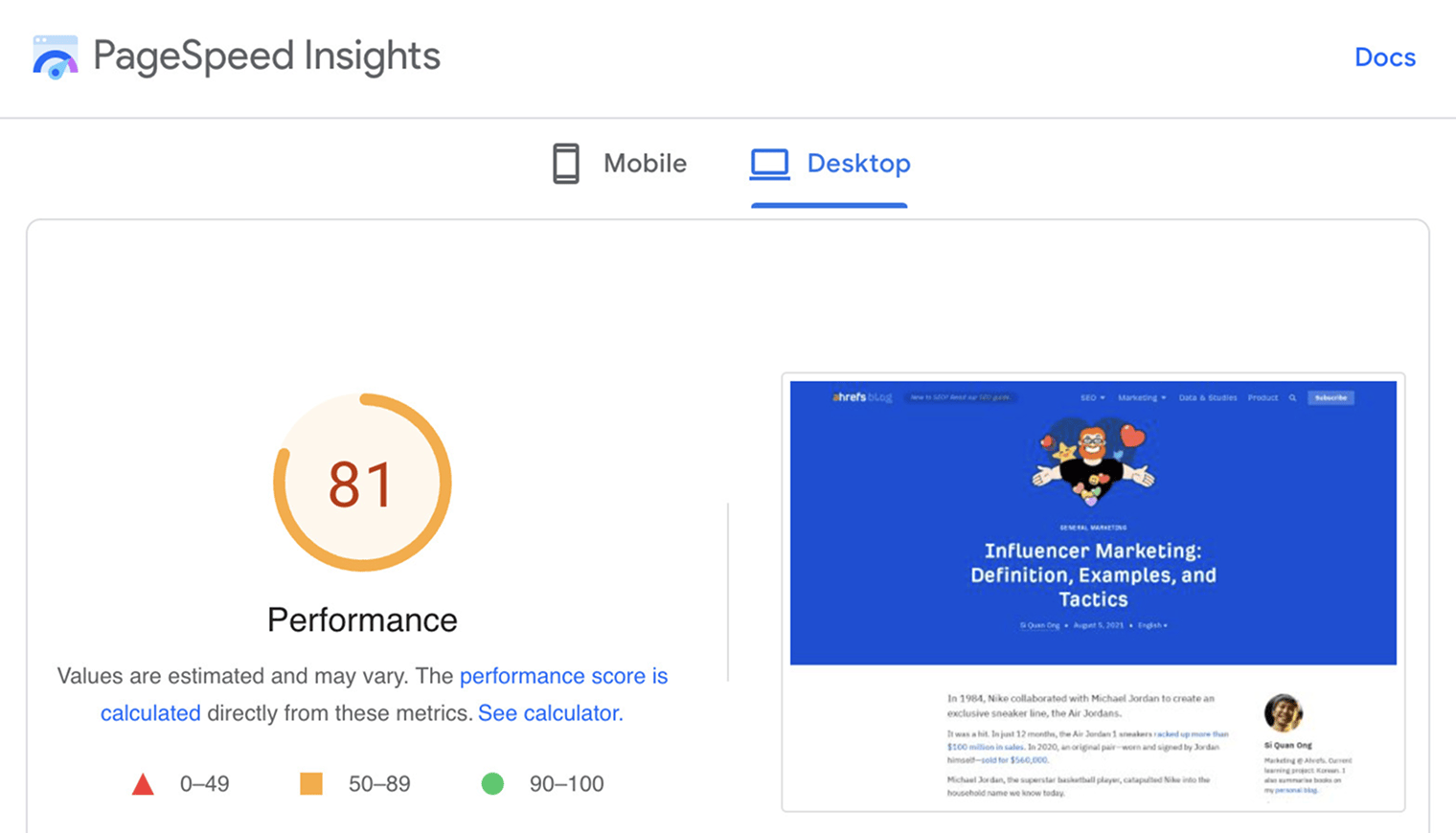
PageSpeed Insights analyzes the loading speed of your webpages. Alongside the performance score, it also shows actionable recommendations to make pages load faster.
Key takeaways
- If your content isn’t indexed, then it won’t be found in search engines.
- When something is broken that impacts search traffic, it can be a priority to fix. But for most sites, you’re probably better off spending time on your content and links.
- Many of the technical projects that have the most impact are around indexing or links.
- Technical SEO still matters for AI search. Well-structured, crawlable pages help AI systems find, understand, and surface your content.
References
- "Is a crawl-delay rule ignored by Googlebot?". Google Search Central. 21st December 2017
- "Change Googlebot crawl rate". Google. Retrieved 9th September 2022
- "30x redirects don’t lose PageRank anymore". Gary Illyes. 26th July 2016
Patrick Stox is a Product Advisor, Technical SEO, & Brand Ambassador at Ahrefs. He was the lead author for the SEO chapter of the 2021 Web Almanac and a reviewer for the 2022 SEO chapter. He also co-wrote the SEO Book For Beginners by Ahrefs and was the Technical Review Editor for The Art of SEO 4th Edition. He’s an organizer for the Triangle SEO Meetup, the Tech SEO Connect conference, he runs a Technical SEO Slack group, and is a moderator for /r/TechSEO on Reddit.
Master SEO Step by Step
How Search Engines Work
Before you start learning SEO, you need to understand how search engines work.
SEO Basics
Learn how to set your website up for SEO success, and get to grips with the four main facets of SEO.
Keyword Research
The starting point in SEO is to understand what your target customers are searching for.
SEO Content
Learn how to create content that ranks in search engines.
On-Page SEO
This is where you optimize your pages to help search engines understand them.
Link Building
Learn how to create content that ranks in search engines.
Technical SEO
Prevent technical problems that stop Google from accessing and understanding your website.
Local SEO
Learn how to improve your visibility in local search results and get more customers from your area.
What AI Means for SEO
You can’t talk about SEO today without mentioning generative AI.
How AI Search Engines Work
Learn exactly how AI search engines like ChatGPT generate their answers and choose which brands and products to mention.