
More crawling doesn’t mean you’ll rank better, but if your pages aren’t crawled and indexed they aren’t going to rank at all.
Most sites don’t need to worry about crawl budget, but there are few cases where you may want to take a look. Let’s look at some of those cases.
- When should you worry about crawl budget?
- How to check crawl activity
- What counts against crawl budget?
- How does Google adjusts its crawling?
- How can I make Google crawl faster?
- How can I make Google crawl slower?
SEOs usually don’t have to worry about crawl budget on popular pages. It’s usually pages that are newer, that aren’t well linked, or don’t change much that are not crawled often.
Crawl budget can be a concern for newer sites, especially those with a lot of pages. Your server may be able to support more crawling, but because your site is new and likely not very popular yet, a search engine may not want to crawl your site very much.
This is mostly a disconnect in expectations. You want your pages crawled and indexed but Google doesn’t know if it’s worth indexing your pages and may not want to crawl as many pages as you want them to.
Crawl budget can also be a concern for larger sites with millions of pages or sites that are frequently updated. In general, if you have lots of pages not being crawled or updated as often as you’d like, then you may want to look into speeding up crawling. We’ll talk about how to do that later in the article.
If you have a lot of pages in Google Search Console marked as Discovered - currently not indexed, that means that Google hasn’t crawled them yet and you may have crawl budget issues. Check the Page Indexing report and you’ll see this.
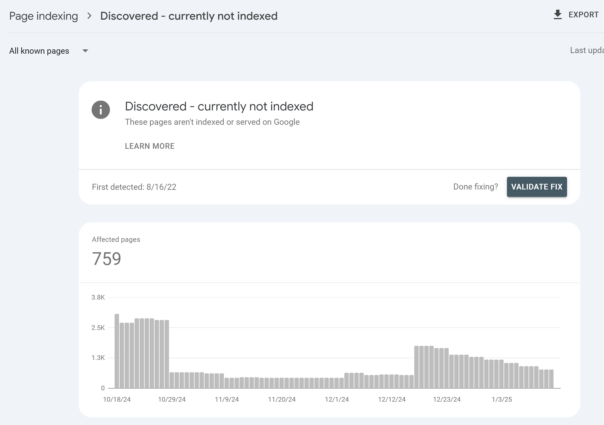
If you want to see an overview of Google crawl activity and any issues they identified, the best place to look is the Crawl Stats report in Google Search Console.
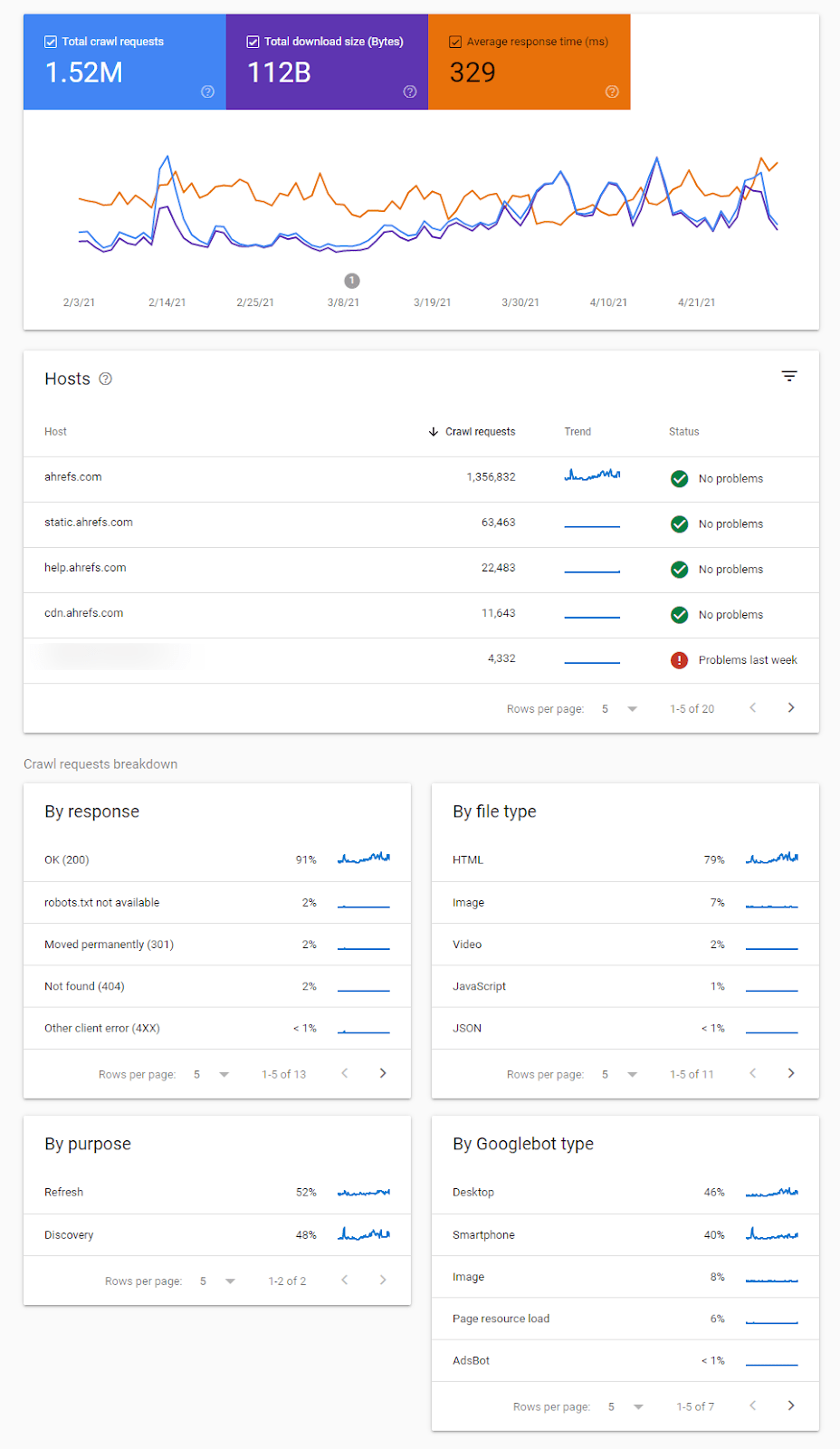
There are various reports here to help you identify changes in crawling behavior, issues with crawling, and give you more information about how Google is crawling your site.
You definitely want to look into any flagged crawl statuses like the ones shown here:

There are also timestamps of when pages were last crawled.
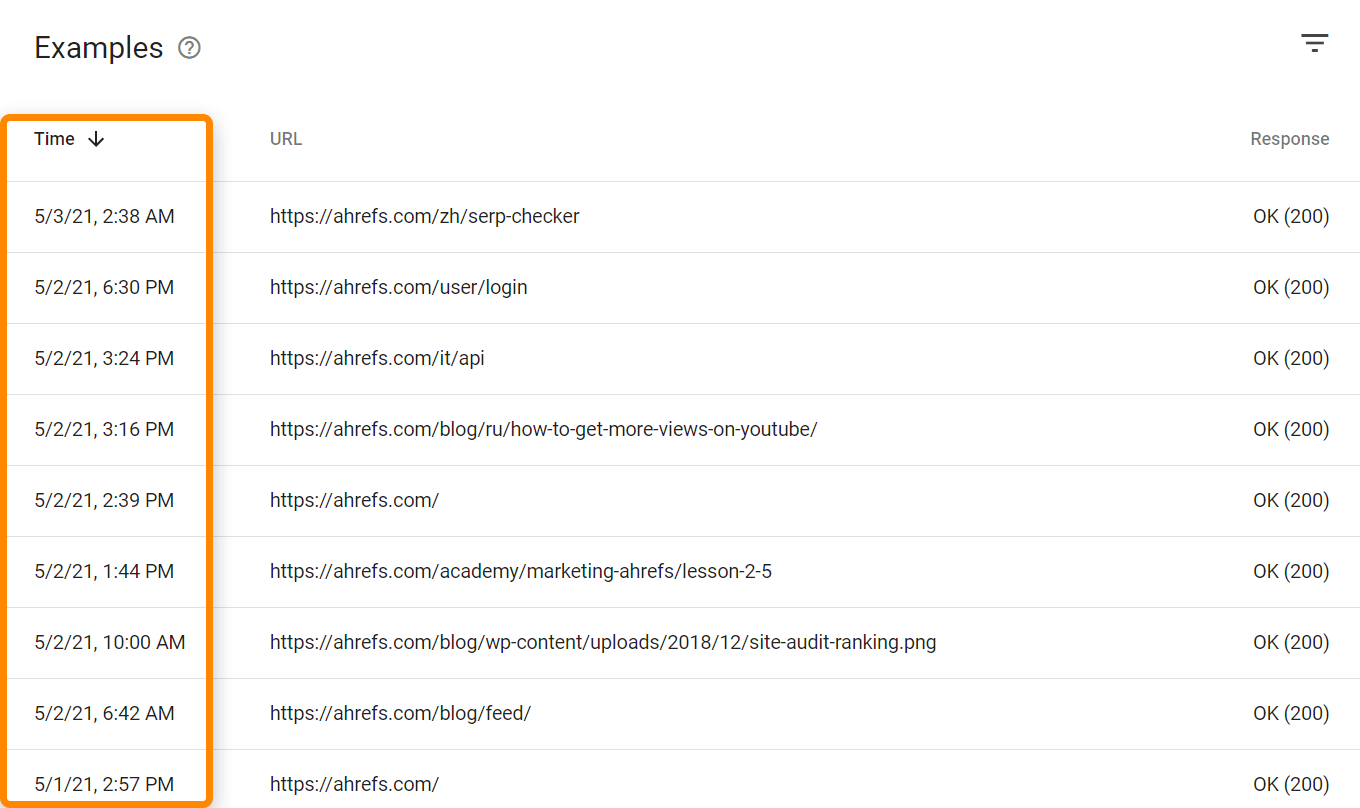
If you want to see hits from all bots and users, you’ll need access to your log files. Depending on hosting and setup, you may have access to tools like Awstats and Webalizer as is seen here on a shared host with cPanel. These tools show some aggregated data from your log files.

For more complex setups you’ll have to get access to and store data from the raw log files, possibly from multiple sources. You may also need specialized tools for larger projects such as an ELK (elasticsearch, logstash, kibana) stack which allows for storage, processing, and visualization of log files. There are also log analysis tools such as Splunk.
All URLs and requests count against your crawl budget. This includes alternate URLs like AMP or m-dot pages, hreflang, CSS, embedded content, and JavaScript including XHR requests. XHR requests aren’t cached like other files so you will see significantly more requests on those for sites build on JavaScript frameworks. There are more details about this in our JavaScript SEO Guide.
These URLs may be found by crawling and parsing pages, or from a variety of other sources including canonical link elements, links on the pages, sitemaps, RSS feeds, submitting URLs for indexing in Google Search Console, or using the indexing API.
There are also multiple Googlebots that share the crawl budget. You can find a list of the various Googlebots crawling your website in the Crawl Stats report in GSC.
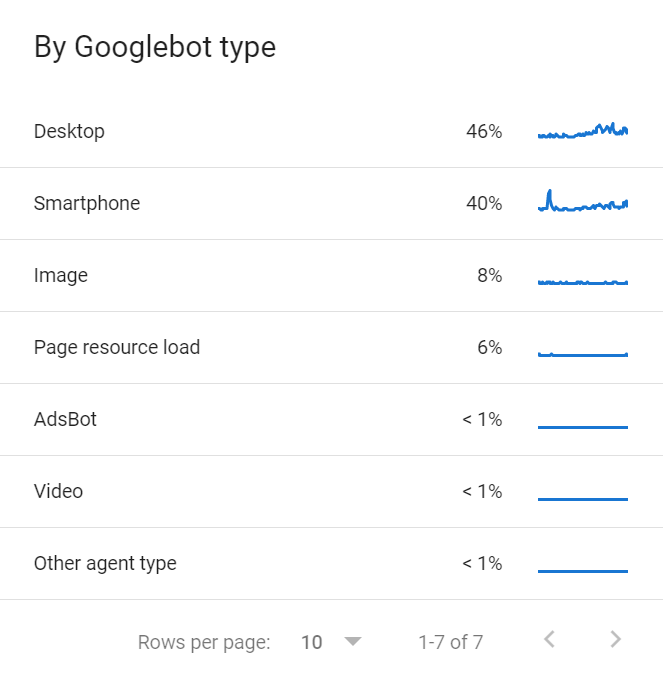
Each website will have a different crawl budget that’s made up of a few different inputs.
Crawl demand
Crawl demand is simply how much Google wants to crawl on your website. More popular pages and pages that experience significant changes will be crawled more.
Popular pages, or those with more links and PageRank, will generally receive priority over other pages. Remember that Google has to prioritize your pages for crawling in some way, and links are an easy way to determine which pages on your site are more popular. It’s not just your site though, it’s all pages on all sites on the internet that Google has to figure out how to prioritize.
You can use the Best by links report in Site Explorer as an indication of which pages are likely to be crawled more often. It also shows you when Ahrefs last crawled your pages.
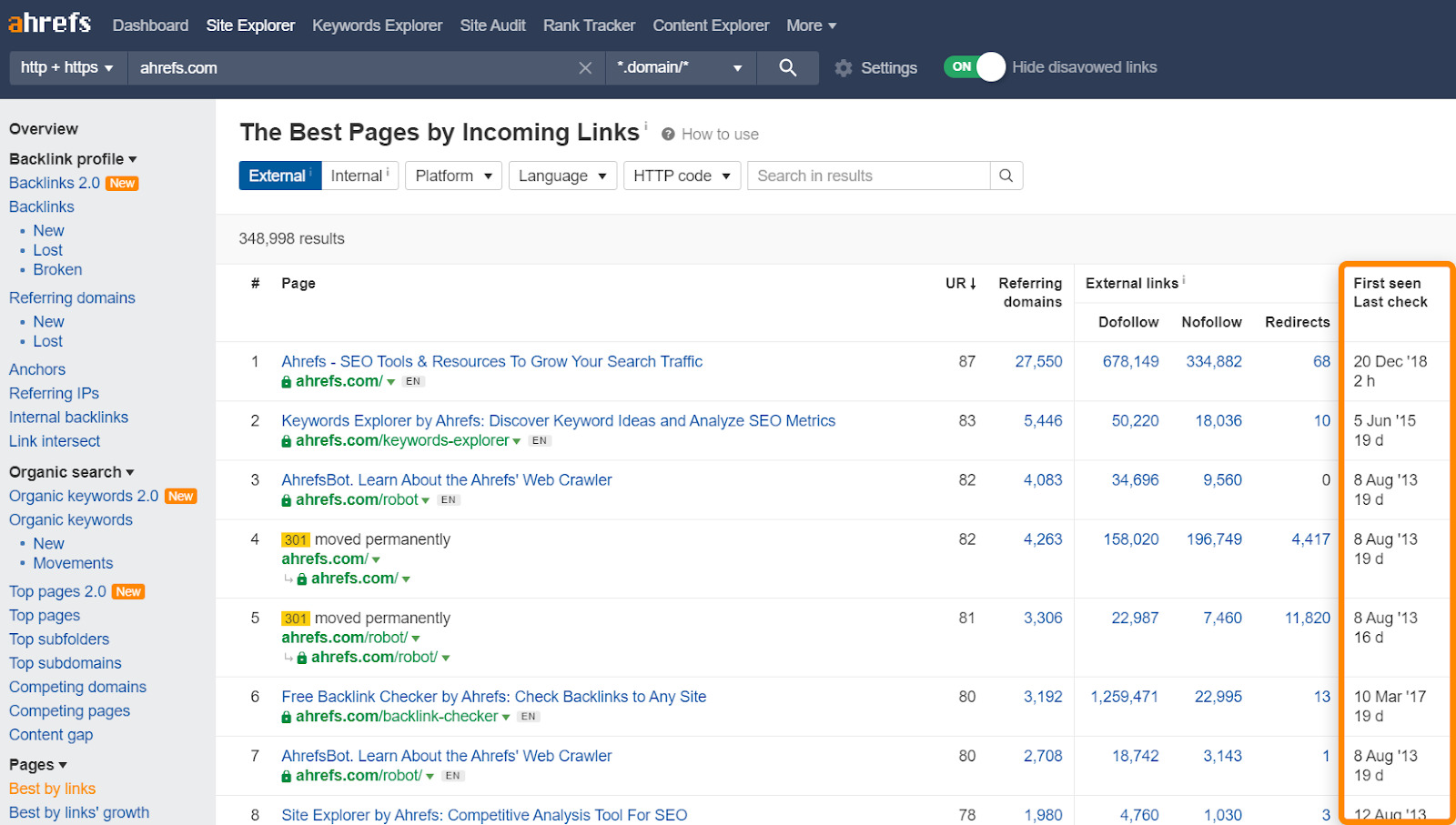
Google also looks at which pages they are serving in their index the most often when determining crawl demand. They want to crawl pages they have to serve more often to make sure they’re up to date.
According to Google Webmaster Trends Analyst Gary Illyes, ~60% of the internet is duplicate content.
Google’s crawling process is highly focused on removing duplication because 60% of the internet is duplicate @methode #seodaydk pic.twitter.com/OJ9OkP74DU
— Lily Ray (@lilyraynyc) March 30, 2022
Most of these duplicates are technical in nature, and they can waste crawl budget. Here are some examples.
- HTTP and HTTPS variants – Examples: http://www.example.com and https://www.example.com.
- Non-www and www variants – Examples: http://example.com and http://www.example.com.
- URLs with and without trailing slashes – Examples: https://example.com/page/ and https://example.com/page.
- URLs with and without capital letters – Examples: https://example.com/page/ and https://example.com/Page/.
- Default versions of the page, such as index pages – Examples: https://www.example.com/, https://www.example.com/index.htm, https://www.example.com/index.html, https://www.example.com/index.php, https://www.example.com/default.htm, etc.
- URL parameters – Examples: example.com?parameter=whatever. These may exist because of tracking codes, faceted navigation, sorting content, session IDs, etc.
There’s also a concept of staleness. If Google sees that a page isn’t changing, they will crawl the page less frequently. For instance, if they crawl a page and see no changes after a day, they may wait three days before crawling again, ten days the next time, 30 days, 100 days, etc. There’s no actual set period they will wait between crawls, but it will become more infrequent over time. However, if Google sees large changes on the site as a whole or a site move, they will typically increase the crawl rate, at least temporarily.
Crawl rate limit
Crawl rate limit is how much crawling your website can support. Websites have a certain amount of crawling they can take before having issues with the stability of the server like slowdowns or errors. Most crawlers will back off crawling if they start to see these issues so they do not harm the site.
Google will adjust based on the crawl health of the site. If the site is fine with more crawling, then the limit will increase. If the site is having issues, then Google will slow down the rate at which they crawl.
Google will slow down their crawling if they receive too many 5xx (server errors) or 429 (too many requests) HTTP status codes. They’ll also slow down if the connect times for the server slow down
There are a few things you can do to make sure your site can support additional crawling and increase your site’s crawl demand. Let’s look at some of those options.
Speed up your server / increase resources
The way Google crawls pages is basically to download resources and then process them on their end. Your page speed as a user perceives it isn’t quite the same. What will impact crawl budget is how fast Google can connect and download resources which has more to do with the server and resources. Check your logs for any 5xx or 429 errors.
Add important pages to sitemaps
Make sure that any page that you want crawled and indexed is included in your sitemap.
Get rid of duplicate content
Earlier, we talked about how the web is 60% duplicate and that many of those extra pages are technical in nature. If you remove these duplicates, Google can focus on crawling unique URLs. For instance, you may want to block faceted navigation URLs with robots.txt or use a # instead of a ? for the parameter since the # is typically ignored by servers and crawlers.
Get more links, external & internal
Remember that crawl demand is generally based on popularity or links. You can increase your budget by increasing the amount of external links and/or internal links. Internal links are easier since you control the site. You can find suggested internal links in the Link Opportunities report in Site Audit, which also includes a tutorial explaining how it works.
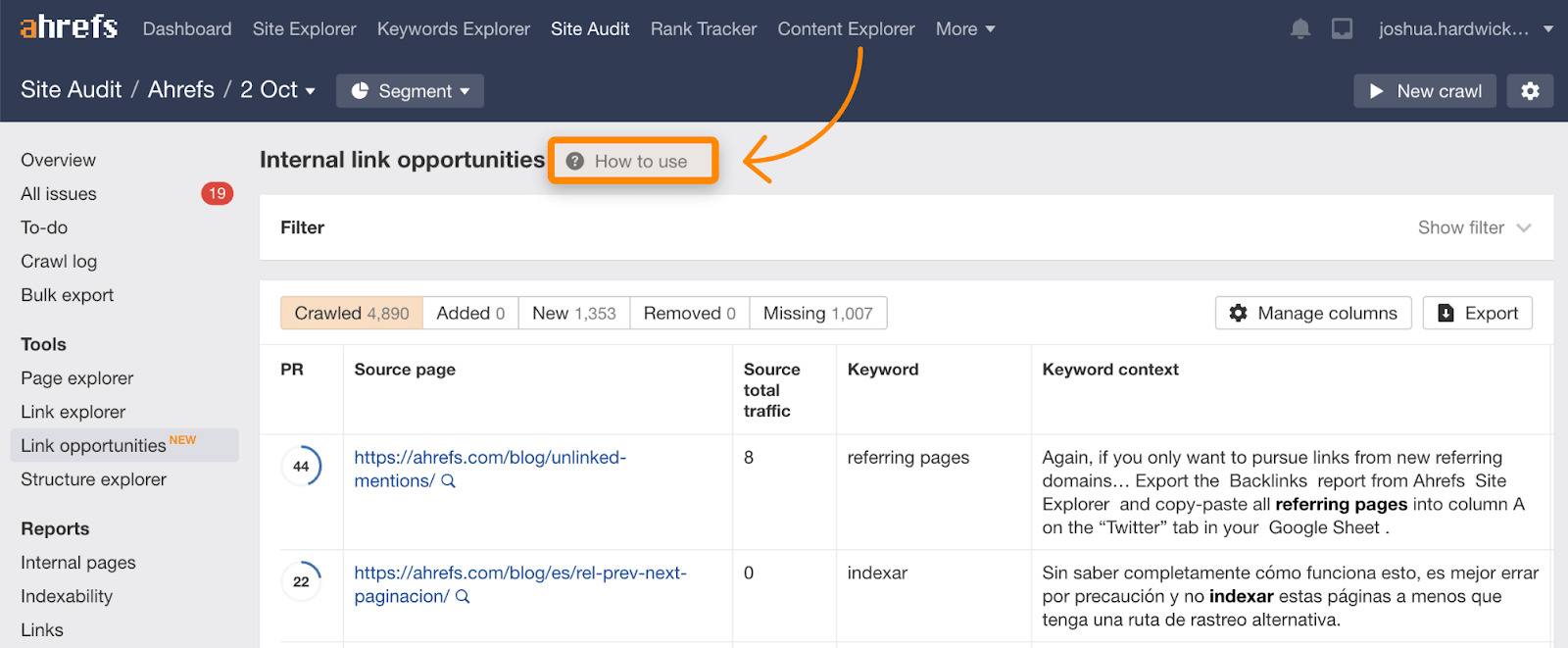
Fix redirected links
Keeping links to redirected pages on your site active will have a small impact on crawl budget. Typically, the pages linked here will have a fairly low priority because they probably haven’t changed in a while, but cleaning up any issues is good for website maintenance in general and will help your crawl budget a bit.
You can find redirected (3xx) links on your site easily in the Internal pages report in Site Audit.
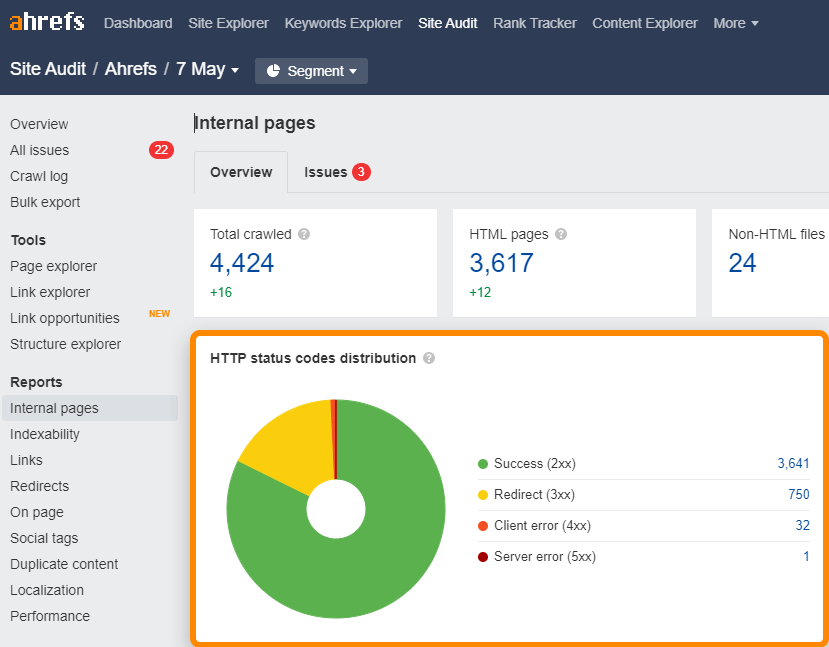
For redirected links in the sitemap, check the All issues report for the “3XX redirect in sitemap” issue.
Host resources on a different hostname
If you use a different subdomain or a CDN to host your resources, this shifts crawl budget concerns to the place that is hosting the resources. It can take the burden off your own server resources and free up crawl budget.
Use GET instead of POST where you can
This one is a little more technical in that it involves HTTP Request methods. Don’t use POST requests where GET requests work. It’s basically GET (pull) vs POST (push). POST requests aren’t cached so they do impact crawl budget, but GET requests can be cached.
Use the Indexing API
If you need pages crawled faster, check if you’re eligible for Google’s Indexing API. Currently this is only available for a few use cases like job postings or live videos.
Bing also has an Indexing API that’s available to everyone.
304 (Not Modified)
Googlebot doesn’t always send an If-Modified-Since or If-None-Match HTTP request header. If they do send it and your server responds with a 304 (Not Modified) response with no body content, then Google will reuse the content from the last time they crawled.
This will use a bit less server resources, meaning Google may be able to crawl your site more. However, it is a technically complex setup and it just doesn’t feel like it’s worth it. You’re likely better off working on your caching setup rather than even attempting this approach.
What may work
This is a bit iffy as to whether it will help your crawl budget or not.
- Nofollow. In the past nofollow links wouldn’t have used crawl budget. However, nofollow is now treated as a hint so Google may choose to crawl these links. They also may find the links as followed on other pages on the web.
What won’t work
There are a few things people sometimes try that won’t actually help with your crawl budget.
- Small changes to the site. Making small changes on pages like updating dates, spaces, or punctuation in hopes of getting pages crawled more often. Google is pretty good at determining whether changes are significant or not, so these small changes aren’t likely to have any impact on crawling.
- Noindex. Google still has to crawl pages to see the noindex tag. Unless you were already hitting the crawl limit for your site, Google won’t reallocate the crawl budget to other pages.
- Crawl-delay directive in robots.txt. This directive will slow down many bots. However Googlebot doesn’t use it so it won’t have an impact. We do respect this at Ahrefs, so if you ever need to slow down our crawling you can add a crawl delay in your robots.txt file.
- Removing third-party scripts. Third-party party scripts don’t count against your crawl budget, so removing them won’t help.
There are just a couple good ways to make Google crawl slower. There are a few other adjustments you could technically make like slowing down your website, but they’re not methods I would recommend.
Slow adjustment, but guaranteed (deprecated)
The main control Google gave us to crawl slower was a rate limiter within Google Search Console, but this is now deprecated. You used to be able to slow down the crawl rate with the tool, but it took up to two days to take effect.
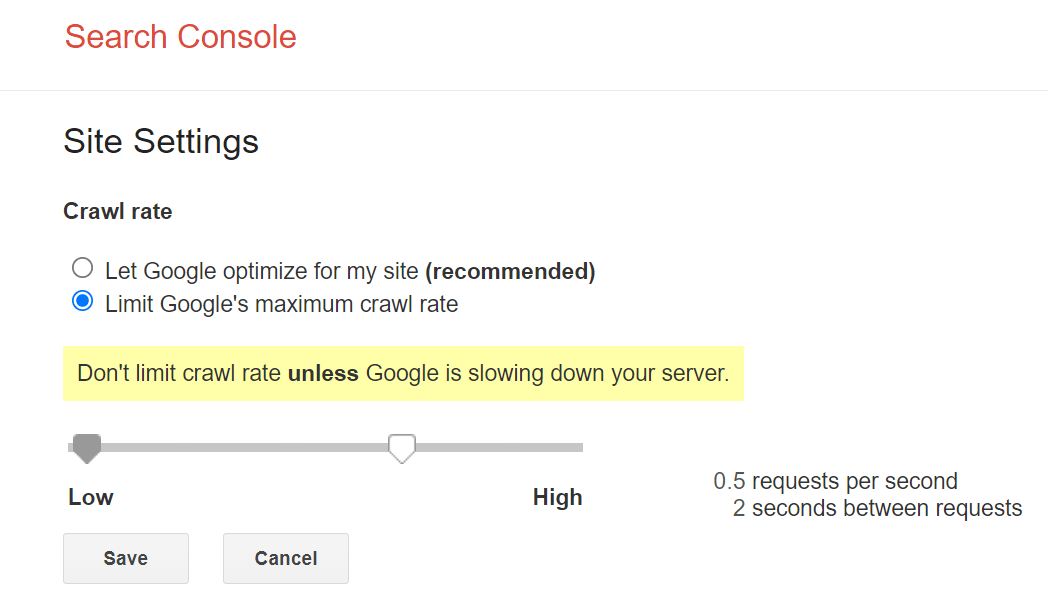
Fast adjustment, but with risks
If you need a more immediate solution, you can take advantage of Google’s crawl rate adjustments related to your site health. If you serve Googlebot a ‘503 Service Unavailable’ or ‘429 Too Many Requests’ status codes on pages, they will start to crawl slower or may stop crawling temporarily. You don’t want to do this longer than a few days though or they may start to drop pages from the index.
Sometimes large changes to a site can also trigger Google to crawl faster. Changes come with risks, so it’s not something I’d typically recommend if your only reason is that you want Google to re-crawl some pages.
Final thoughts
The rate of crawling isn’t going to impact your rankings. I want to reiterate that crawl budget isn’t something for most people to worry about. If you do have concerns, I hope this guide was useful.
I typically only look into it when there are issues with pages not getting crawled and indexed, I need to explain why someone shouldn’t be worried about it, or I happen to see something that concerns me in the crawl stats report in Google Search Console.
Have questions? Let me know on Twitter.


