
Más rastreo no quiere decir que vayas a posicionar mejor, pero si tus páginas no son rastreadas e indexadas, no vas a posicionar de ninguna forma.
La mayoría de sitios no tienen que preocuparse por el crawl budget, pero hay unos pocos casos en los que puede que quieras echarle un vistazo. Veamos algunos de estos casos.
- ¿Cuándo deberías preocuparte por el crawl budget?
- Cómo comprobar la actividad de rastreo
- ¿Qué contabiliza frente al crawl budget?
- ¿Cómo ajusta Google su crawling?
- ¿Cómo puedo hacer que Google rastree más rápido?
- ¿Cómo puedo hacer que Google rastree más lento?
Normalmente no tienes que preocuparte por tu crawl budget en páginas populares. Habitualmente son las páginas más nuevas y que no están bien enlazadas o que no cambian mucho las que no son rastreadas a menudo.
El crawl budget puede ser una preocupación para sitios nuevos, especialmente para aquellos con muchas páginas. Tu servidor puede ser capaz de soportar más crawling (rastreo), pero como tu sitio es nuevo y, probablemente, no muy popular todavía, puede que un motor de búsqueda no quiera rastrear mucho tu sitio. Esto es más que nada una desconexión con las expectativas. Quieres que tus páginas sean rastreadas e indexadas, pero Google no sabe si merece la pena indexar tus páginas y puede que no quiera rastrear tantas páginas como tú querrías.
El crawl budget también puede ser una preocupación para sitios más grandes con millones de páginas que se actualizan con frecuencia. En general, si tienes muchas páginas que no están siendo rastreadas o actualizadas tanto como te gustaría, entonces puede que quieras estudiar cómo acelerar el crawling. Hablaremos sobre cómo hacerlo más adelante en el artículo.
Si quieres ver una vista general de la actividad de rastreo de Google y cualquier problema que hayan identificado, el mejor sitio en que mirar es el informe de Estadísticas de Rastreo o (Crawl Stats report en inglés) en Google Search Console.
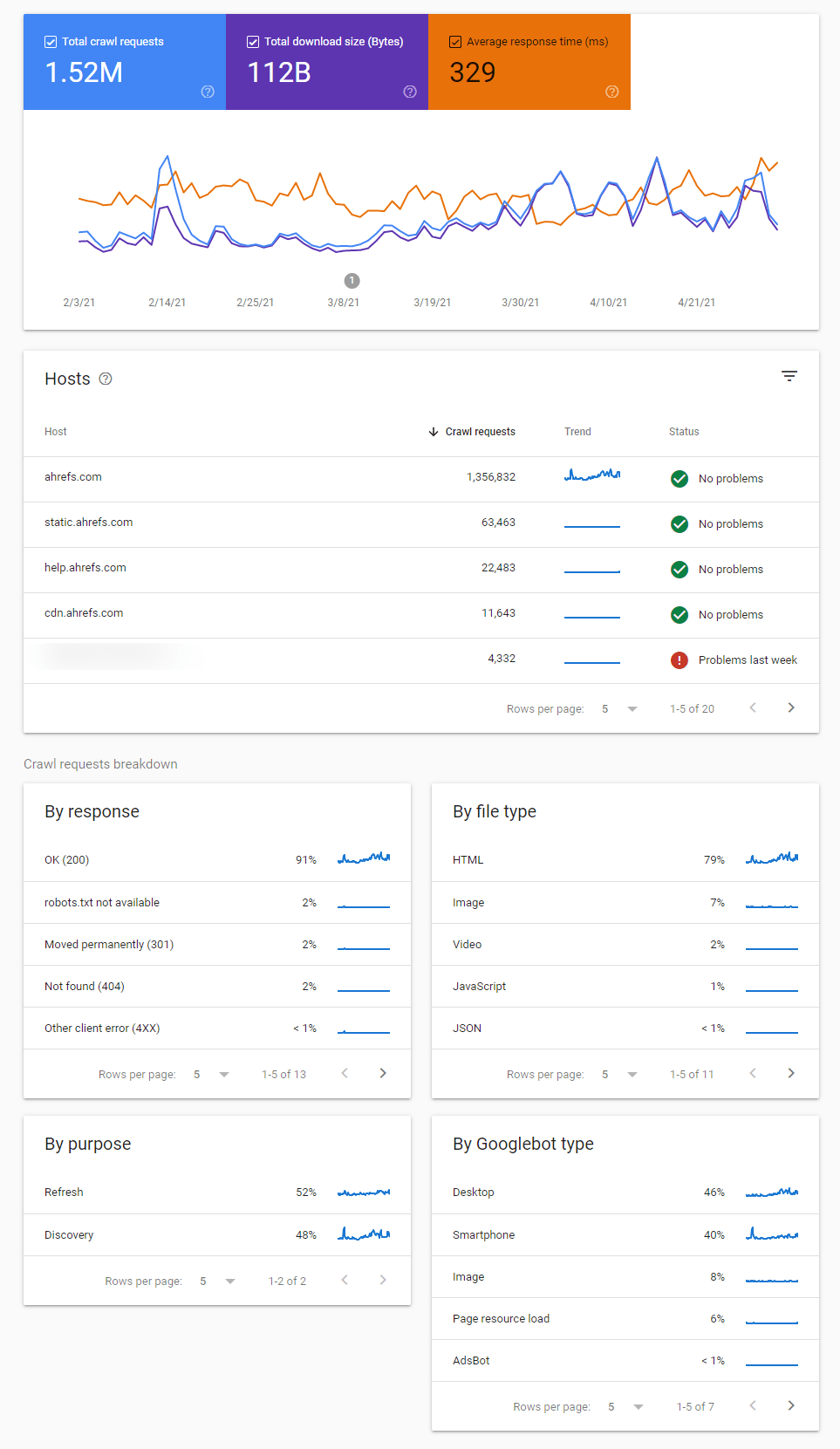
Hay varios informes aquí que te ayudan a identificar cambios en el comportamiento de rastreo, problemas con el rastreo y te dan más información sobre cómo Google está rastreando tu sitio.
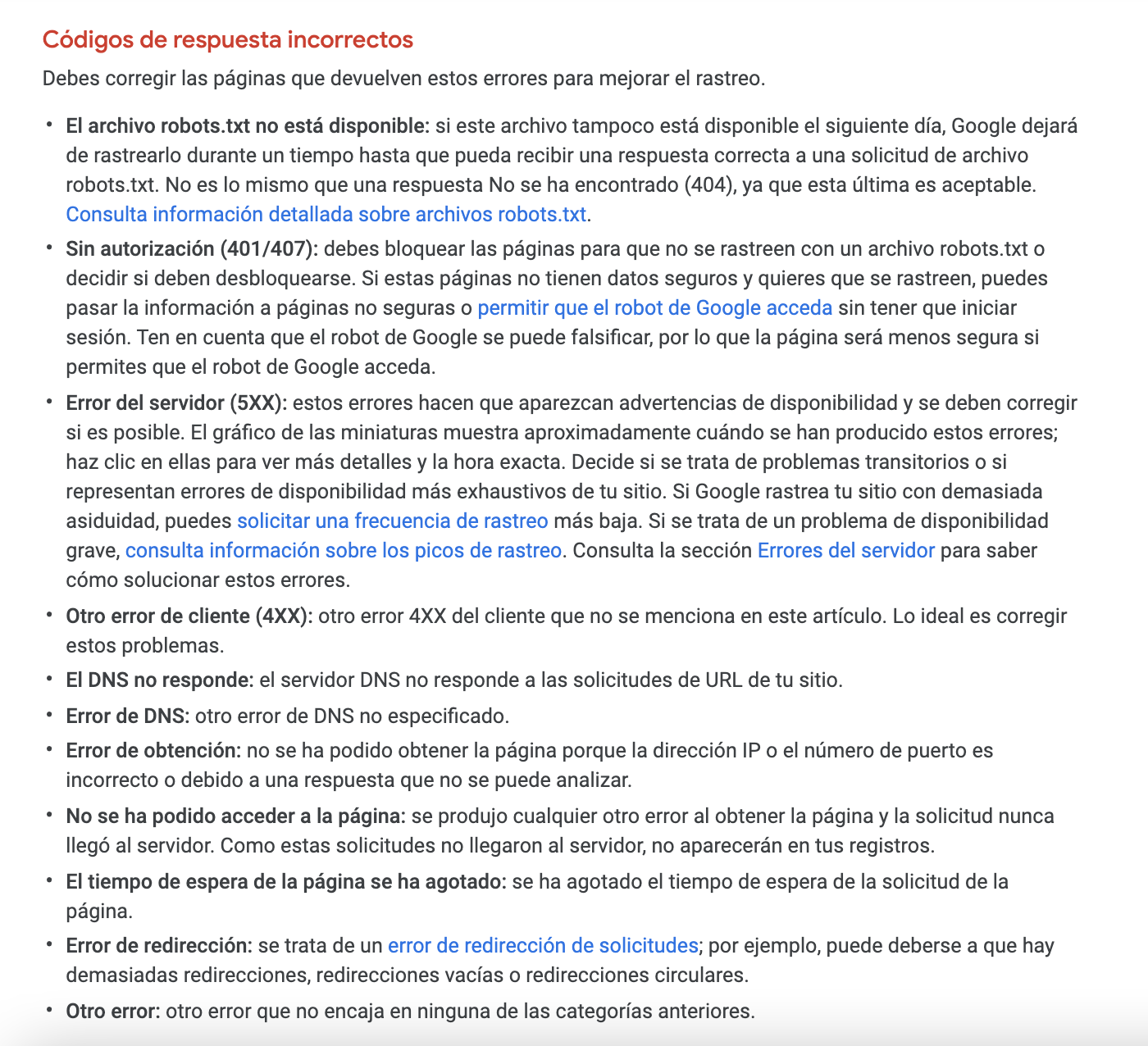
Definitivamente quieres revisar cualquier estado de rastreo marcado como los que se muestran aquí:
Hay también marcas temporales de cuándo las páginas fueron rastreadas por última vez.
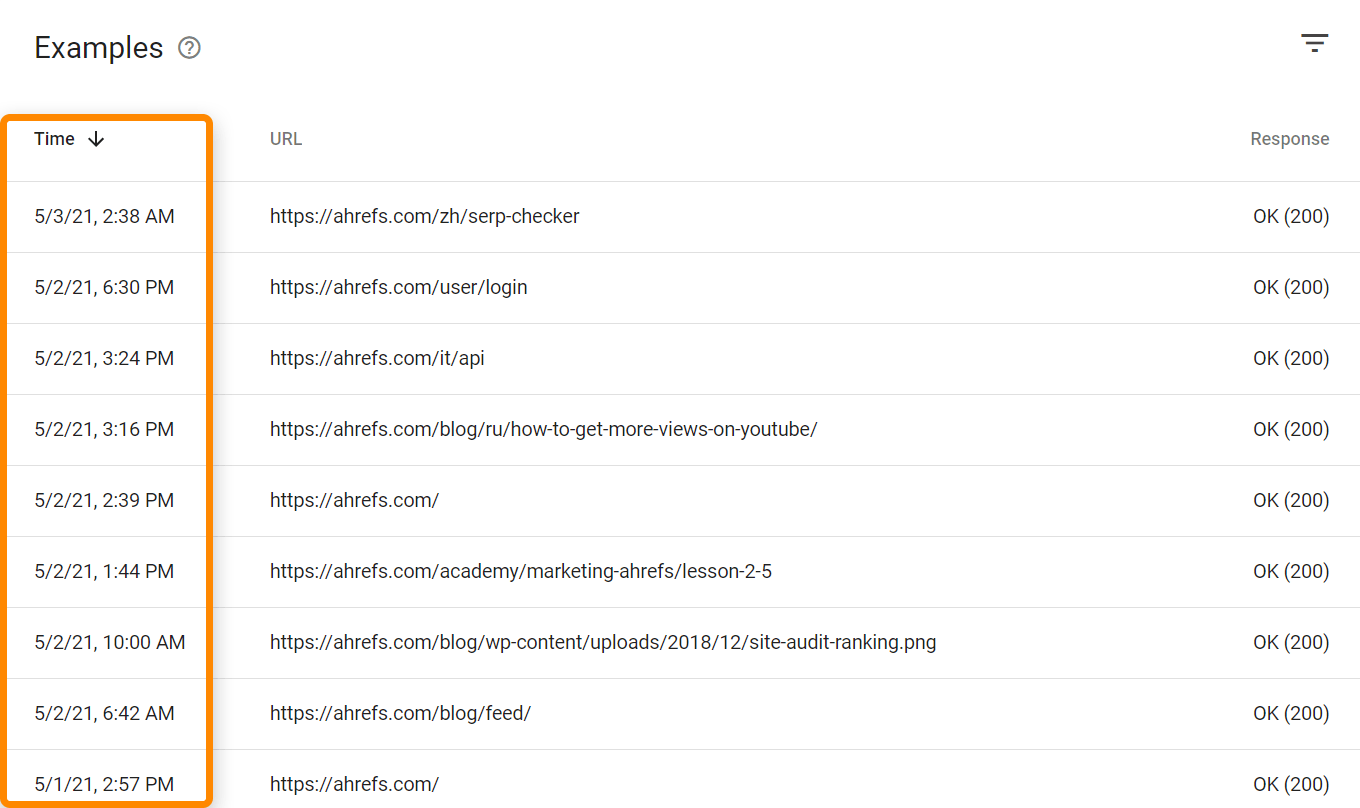
Si quieres ver visitas (hits) de todos los bots y usuarios, necesitarás acceder a tus archivos de log. Dependiendo del hosting y configuración, puedes acceder a herramientas como Awstats y Webalizer como se ve aquí en un hosting compartido con cPanel. Estas herramientas muestran algunos datos agregados desde tus archivos de registro.

Para configuraciones más complejas, tendrás que conseguir acceso y almacenar los archivos de logs en bruto, posiblemente de varias fuentes. Puede que también necesites herramientas especializadas para proyectos más grandes como un stack ELK (elasticsearch, logstash, kibana) que te permita almacenar, procesar y visualizar archivos log. También hay herramientas de análisis de log como Splunk.
Todas las URLs y peticiones cuentan en lo que respecta a tu crawl budget. Esto incluye URLs alternativas como AMP o páginas m-punto, hreflang, CSS, y JavaScript, incluyendo peticiones XHR.
Estas URLs pueden encontrarse al rastrear y parsear páginas o desde otras fuentes diversas, incluyendo sitemaps, feeds RSS, envíos de URLs para su indexación en Google Search Console, o usando la indexing API.
También hay varios Googlebots que comparten el crawl budget. Puedes encontrar una lista de los distintos Googlebots que rastrean tu sitio en el informe de Estadísticas de Rastreo en GSC.
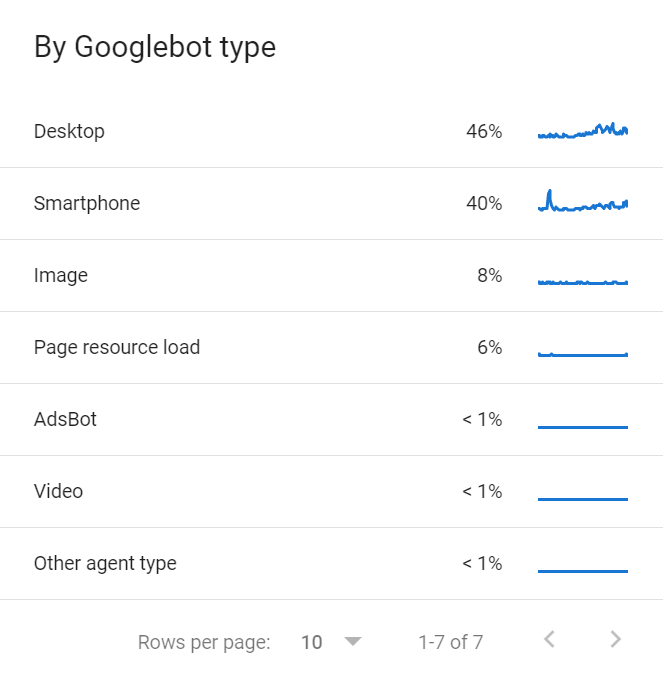
Cada sitio web tendrá un crawl budget distinto que se compone de unos pocos inputs.
Demanda de Rastreo
La demanda de rastreo o crawl es simplemente cuántas ganas tiene Google de rastrear tu sitio web. Las páginas más populares y páginas que experimenten cambios significativos serán rastreadas más a menudo.
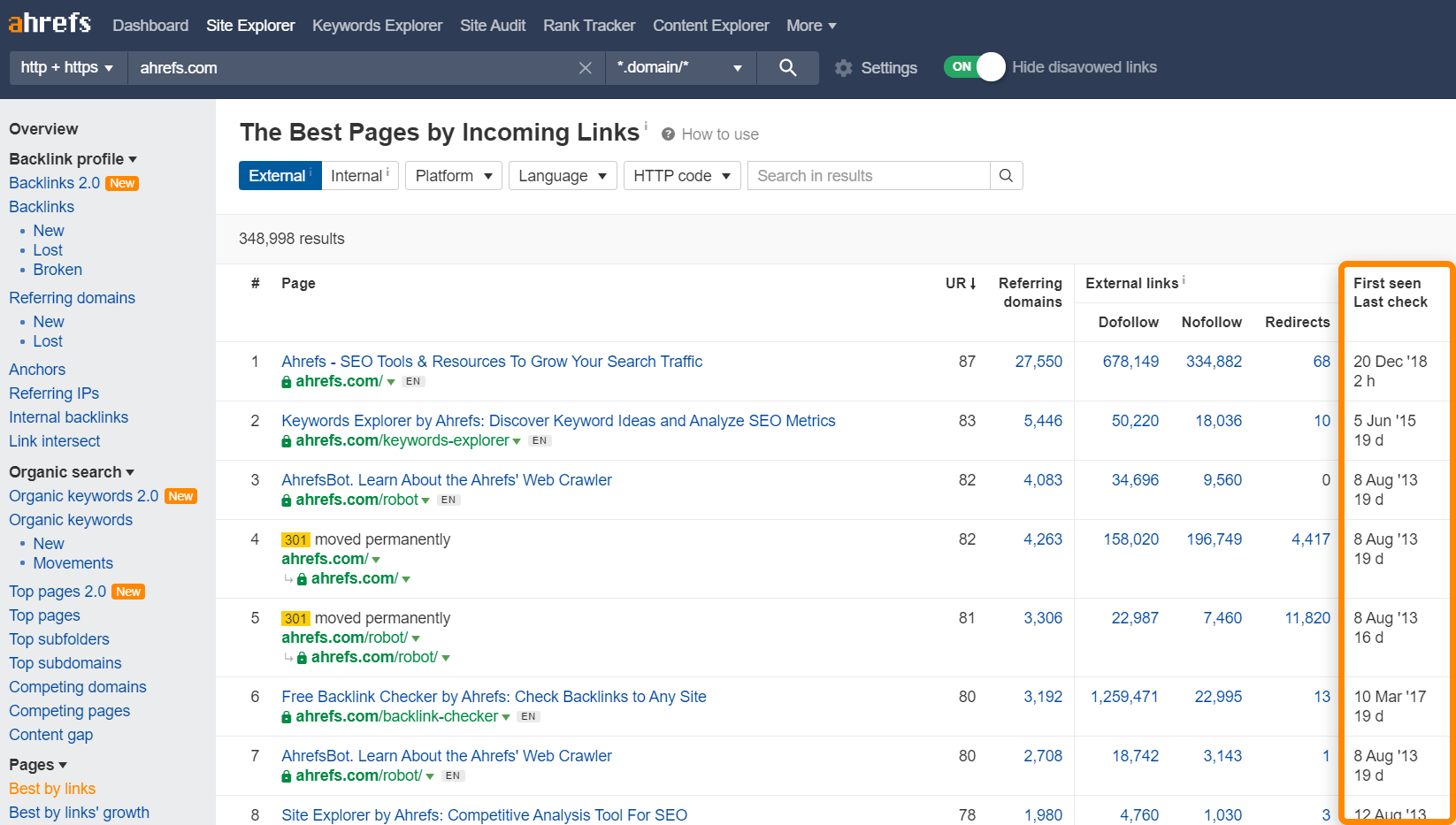
Las páginas populares, o aquellas con más enlaces apuntándolas, generalmente recibirán prioridad sobre otras páginas. Recuerda que Google tiene que priorizar tus páginas para rastrearlas algún día, y los enlaces son una forma fácil de determinar qué páginas en tu sitio son más populares. No es solo tu sitio, Google tiene que ver cómo priorizar todas las páginas de todos los sitios de Internet.
Puedes usar el informe Best by links (mejor por enlaces) en Site Explorer como un indicativo de qué páginas tienen más probabilidades de ser rastreadas más a menudo. También te muestra cuándo Ahrefs rastreó tus páginas por última vez.
También existe un concepto de caducidad. Si Google ve que una página no está cambiando, la rastrearán con menor frecuencia. Por ejemplo, si rastrean una página y no ven cambios después de un día, pueden esperar tres días antes de rastrear de nuevo, diez días la próxima vez, 30 días, 100 días, etc. No hay un período de tiempo establecido de lo que esperarán entre rastreos, pero pasará a ser menos frecuente a lo largo del tiempo. Sin embargo, si Google ve grandes cambios en el sitio en general o un sitio se migra, normalmente incrementarán la tasa de rastreo, al menos de forma temporal.
Frecuencia límite de rastreo
La frecuencia límite de rastreo es el rastreo que tu web puede soportar. Los sitios web tienen una cierta cantidad de rastreo que pueden tomar antes de tener problemas con la estabilidad del servidor, como ralentizaciones o errores. La mayoría de los rastreadores se retirarán si comienzan a ver estos problemas para no dañar el sitio.
Google se ajustará en base a la salud de rastreo del sitio. Si el sitio aguanta más rastreo, subirá el límite. Si el sitio tiene problemas, Google ralentizará la tasa a la que rastrean.
Hay unas pocas cosas que puedes hacer para asegurarte de que tu sitio pueda soportar rastreo adicional e incrementar la demanda de rastreo de tu sitio. Veamos algunas de estas opciones.
Acelera tu servidor / incrementa recursos
La forma en que Google rastrea páginas consiste básicamente en descargar recursos para después procesarlos por su lado. Tu velocidad de página tal y como la percibe un usuario no es exactamente la misma. Lo que impactará el crawl budget es la rapidez a la que Google puede conectarse y descargar recursos, algo que está más relacionado con el servidor y los recursos.
Más enlaces, externos e internos
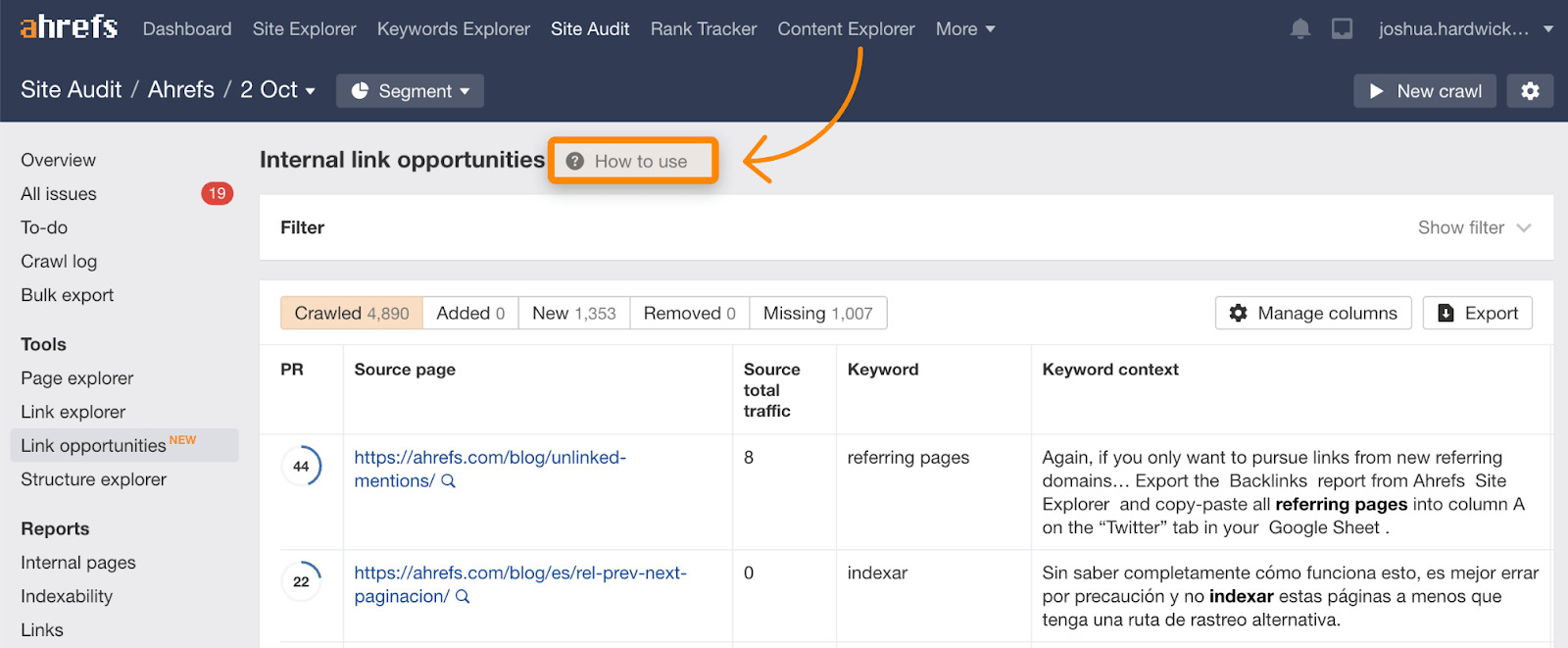
Recuerda que la demanda de rastreo se basa en general en la popularidad o enlaces. Puedes incrementar tu presupuesto incrementando la cantidad de links externos y/o links internos. Los enlaces internos son más fáciles ya que controlas el sitio. Puedes encontrar enlaces internos sugeridos en el informe de Link Opportunities (oportunidades de enlaces) en Site Audit, que también incluye un tutorial explicando cómo funciona.
Arregla enlaces rotos y redirigidos
Mantener enlaces rotos o a páginas redirigidas activos en tu sitio solo tendrá un impacto pequeño en el crawl budget. Típicamente, las páginas enlazadas aquí tendrán una prioridad bastante baja porque probablemente no han cambiado en algo de tiempo, pero limpiar cualquier problema es bueno para el mantenimiento del sitio web en general y ayudará un poco a tu crawl budget.
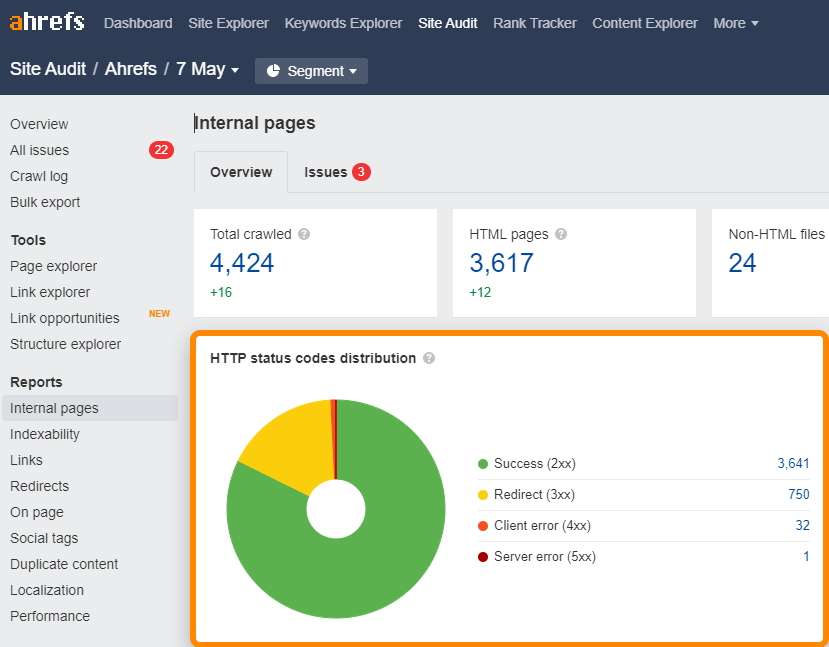
Puedes encontrar enlaces rotos (4xx) y redirigidos (3xx) en tu sitio con facilidad en el informe de Internal pages (páginas internas) en Site Audit.
Para enlaces rotos o redirigidos en el sitemap, comprueba el informe All issues (todos los problemas) en busca de problemas tipo “3XX redirect in sitemap” (redirecciones 3XX en sitemap) y “4XX page in sitemap” (páginas 4XX en sitemap).
Usa GET en lugar de POST donde puedas
Esto es un poco más técnico ya que involucra métodos de peticiones HTTP. No uses peticiones POST cuando puedes usar GET. Básicamente se trata de GET (tirar) vs POST (empujar). Las peticiones POST no se cachean, por lo que impactan en el crawl budget, pero las peticiones GET pueden cachearse.
Usa la Indexing API
Si necesitas que las páginas se rastreen más rápido, comprueba si eres elegible para la Indexing API de Google. Actualmente esto solo está disponible para unos pocos casos de uso como las publicaciones de empleos o vídeos en vivo.
Bing también tiene una Indexing API que está disponible para cualquiera.
Lo que no funcionará
Hay unas pocas cosas que la gente a veces intenta que en realidad no ayudarán con tu crawl budget.
- Pequeños cambios en el sitio. Hacer pequeños cambios como actualizar fechas, espacios o puntuación en espera de conseguir que las páginas se rastreen más a menudo. Google es bastante bueno determinando si los cambios son o no significativos, así que los cambios pequeños no es probable que tengan ningún impacto en el rastreo.
- Directiva crawl-delay en robots.txt. Esta directiva ralentizará muchos bots. Sin embargo, Googlebot no la usa así que no tendrá impacto. En Ahrefs sí respetamos esto, así que si alguna vez quieres que ralenticemos nuestro rastreo puedes añadir una directiva crawl delay en tu archivo robots.txt.
- Eliminar scripts de terceros. Los scripts de terceros no cuentan en tu crawl budget, así que eliminarlos no ayudará.
- Nofollow. Vale, esto es dudoso. En el pasado, los enlaces nofollow no habrían usado crawl budget. Sin embargo, nofollow se usa ahora como una pista, por lo que Google puede elegir rastrear estos sitios.
Hay solo un par de buenas formas de hacer que el rastreo de Google sea más lento. Hay unos pocos otros ajustes que técnicamente podrías hacer, como ralentizar tu sitio, pero no son métodos que recomendaría.
Ajuste lento, pero garantizado
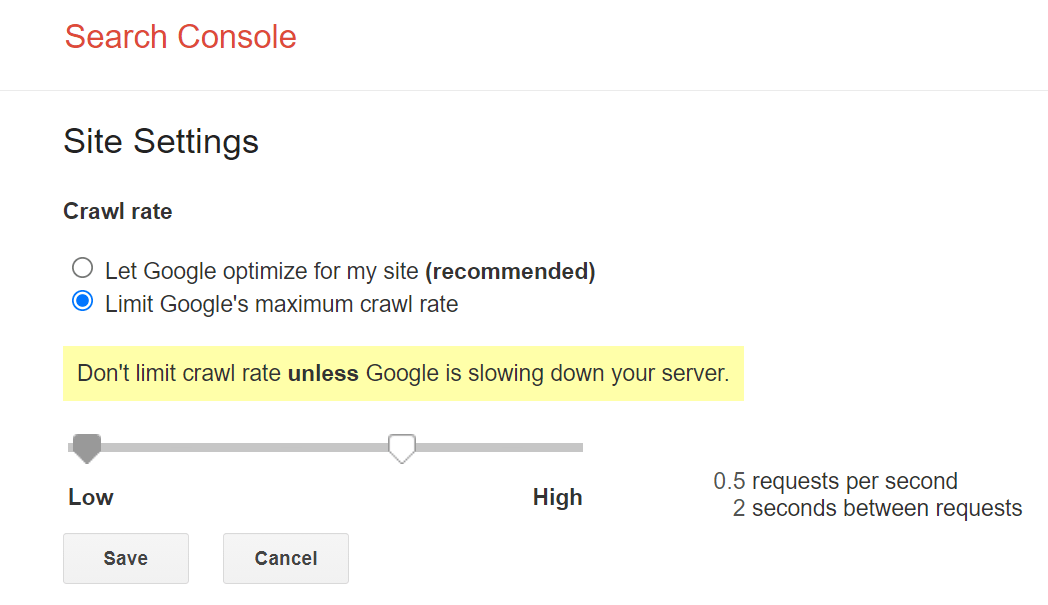
El control principal que Google nos da para rastrear más despacio es un limitador de frecuencia de rastreo dentro de Google Search Console. Puedes ralentizar la frecuencia de rastreo con la herramienta, pero puede tardar dos días en hacerse efectivo.
Ajuste rápido, pero con riesgos
Si necesitas una solución más inmediata, puedes aprovecharte de los ajustes de la frecuencia de rastreo relacionadas con la salud de tu sitio. Si sirves a Googlebot un código de estado “503 Service Unavailable” (servicio no disponible) o “429 Too Many Requests” (demasiadas peticiones), empezarán a rastrear más despacio o puede que paren el rastreo temporalmente. No quieres hacer esto más que unos pocos días o puede que empiecen a retirar páginas de su índice.
Reflexiones finales
Una vez más, quiero reiterar que el crawl budget no es algo por lo que la mayoría de la gente tenga que preocuparse. Si tienes preocupaciones, espero que esta guía haya sido útil.
Típicamente solo lo reviso cuando hay problemas con páginas que no están siendo rastreadas e indexadas, necesito explicar por qué alguien no debería preocuparse por ello o me encuentro con algo que me preocupa en el informe de estadísticas de rastreo de Google Search Console.
¿Tienes preguntas? Dímelas por Twitter.
Traducido por Iván Fanego, que en sus ratos libres analiza herramientas y tendencias en marketing y software en AppCritic. Aquí puedes leer su guía sobre WhatsApp Multiagente.


