
Esta es la razón por la que los errores de configuración de robots.txt son extremadamente comunes, incluso entre los profesionales SEO con experiencia.
En esta guía aprenderás:
- Qué es un archivo robots.txt
- Cómo se ve un archivo robots.txt
- User-agents y directivas para robots.txt
- Si necesitas un archivo robots.txt o no
- Cómo encontrar tu archivo robots.txt
- Cómo crear un archivo robots.txt
- Las mejores prácticas del archivo robots.txt
- Ejemplo de archivos robots.txt
- Cómo auditar tu archivo robots.txt
¿Qué es un archivo robots.txt?
Un archivo robots.txt le dice a los motores de búsqueda por dónde pueden y por donde no pueden ir dentro de tu sitio.
En primer lugar, enumera todo el contenido que deseas bloquear de los motores de búsqueda como Google. También le puedes indicar a algunos motores de búsqueda (no a Google) cómo pueden rastrear el contenido accesible.
La mayoría de los motores de búsqueda son obedientes. No tienen el hábito de ignorar una restricción. Dicho esto, algunos no son tímidos a la hora de obviar dichas restricciones.
Google no es uno de esos motores de búsqueda, obedece las instrucciones de un archivo robots.txt.
Sólo tienes que saber que algunos motores de búsqueda lo ignoran por completo.
¿Cómo se ve un archivo robots.txt?
Este es el formato básico de un archivo robots.txt:
Sitemap: [URL ubicación de sitemap] User-agent: [identificador de bot] [directiva 1] [directiva 2] [directiva ...] User-agent: [otro identificador de bot] [directiva 1] [directiva 2] [directiva ...]
Si nunca has visto uno de estos archivos antes puede parecer desalentador. Sin embargo, la sintaxis es bastante simple. En resumen, tienes que asignar reglas a los robots indicando su user-agent seguido de las directivas.
Exploremos estos dos componentes con más detalle.
User-agents
Cada motor de búsqueda se identifica con un user-agent diferente. Puedes establecer instrucciones personalizadas para cada uno de ellos en el archivo robots.txt. Hay cientos de user-agents, pero aquí hay algunos útiles en relación al SEO:
- Google: Googlebot
- Google Images: Googlebot-Image
- Bing: Bingbot
- Yahoo: Slurp
- Baidu: Baiduspider
- DuckDuckGo: DuckDuckBot
También puedes utilizar el asterisco (*) para asignar directivas a todos los user-agents.
Por ejemplo, supongamos que deseas bloquear todos los bots excepto Googlebot para que no rastree tu sitio. Así es como lo harías:
User-agent: * Disallow: / User-agent: Googlebot Allow: /
Tienes que saber que tu archivo robots.txt puede incluir directivas para tantos user-agents como desees. Dicho esto, cada vez que declares un nuevo user-agent, éste ignorará las directivas declaradas anteriormente para otros user-agents. En otras palabras, si añades directivas para múltiples user-agents, las directivas declaradas para el primer user-agent no se aplicarán al segundo, o al tercero, o al cuarto, y así sucesivamente.
La excepción a esta regla es cuando se declara el mismo user-agent más de una vez. En ese caso, se combinan y se cumplen todas las directivas pertinentes.
Los rastreadores sólo siguen las reglas declaradas bajo el (los) user-agent(s) que se se aplican a ellos de la forma más específica posible. Es por eso que el archivo robots.txt bloquea a todos los bots excepto a Googlebot (y a otros robots de Google) para que no puedan rastrear el sitio, Googlebot ignora la declaración de user-agent menos específica.
Directivas
Las directivas son las reglas que quieres que los user-agents declarados sigan.
Directivas admitidas
Aquí están las directivas que Google admite actualmente, junto con sus usos.
Disallow
Utiliza esta directiva para indicar a los motores de búsqueda que no accedan a archivos y páginas que se encuentren bajo una ruta específica. Por ejemplo, si deseas bloquear el acceso de todos los motores de búsqueda a tu blog y a todos sus mensajes, el archivo robots.txt puede verse así:
User-agent: * Disallow: /blog
Allow
Utiliza esta directiva para permitir a los motores de búsqueda rastrear un subdirectorio o una página, incluso en un directorio que de otro modo no estaría permitido. Por ejemplo, si deseas evitar que los motores de búsqueda accedan a todas las entradas de tu blog excepto a una, el archivo robots.txt puede tener este aspecto:
User-agent: * Disallow: /blog Allow: /blog/post-permitido
En este ejemplo, los motores de búsqueda pueden acceder a: /blog/post-permitido. Pero no pueden acceder a:
/blog/otro-post
/blog/y-otro-post
/blog/descarga.pdf
Tanto Google como Bing admiten esta directiva.
A menos que seas cuidadoso, las directivas allow y disallow pueden fácilmente entrar en conflicto entre sí. En el siguiente ejemplo no se le permite el acceso a /blog/ y se permite el acceso a /blog.
User-agent: * Disallow: /blog/ Allow: /blog
En este caso, la URL/blog/post-title/ parece tener ambas directivas. Entonces ¿cuál gana?
Para Google y Bing, la regla es que gana la directiva con más caracteres. Esa es la directiva disallow.
Disallow: /blog/ (6 caracteres)
Allow: /blog (5 caracteres)
Si las directivas allow y disallow tienen la misma longitud, entonces gana la directiva menos restrictiva. En este caso, esa sería la directiva allow.
/blog (sin la barra) sigue siendo accesible y rastreable. Es importante mencionar que esto sólo aplica para el caso de Google y Bing. Otros motores de búsqueda obedecen a la primera directiva coincidente. En este caso sería disallow.
Sitemap
Utiliza esta directiva para especificar la ubicación de tu(s) sitemap(s) en los motores de búsqueda. Si no estás familiarizado con los sitemaps, generalmente incluyen las páginas que deseas que los motores de búsqueda rastreen e indexen.
A continuación se muestra un ejemplo de un archivo robots.txt que utiliza la directiva sitemap:
Sitemap: https://www.dominio.com/sitemap.xml User-agent: * Disallow: /blog/ Allow: /blog/titulo-post/
¿Qué importancia tiene incluir tu(s) sitemap(s) en tu archivo robots.txt? Si ya lo has enviado a través de Search Console entonces es algo redundante para Google. Sin embargo, le dicen a otros motores de búsqueda como Bing dónde encontrar tu sitemap, por lo que sigue siendo una buena práctica.
Ten en cuenta que no es necesario repetir la directiva sitemap varias veces para cada user-agent, éste aplica para todos. Por lo tanto, lo mejor es incluir las directivas del sitemap al principio o al final del archivo robots.txt. Por ejemplo:
Sitemap: https://www.dominio.com/sitemap.xml User-agent: Googlebot Disallow: /blog/ Allow: /blog/titulo-post/ User-agent: Bingbot Disallow: /servicios/
Google admite la directiva sitemap, así como Ask, Bing, y Yahoo.
Directivas no admitidas
Estas son las directivas que ya no son admitidas por Google—algunas de las cuales nunca lo fueron, técnicamente.
Crawl-delay
Anteriormente podías utilizar esta directiva para especificar un retardo del rastreo en segundos. Por ejemplo, si quisieras que Googlebot espere 5 segundos después de cada acción de rastreo, debías establecer el retardo de rastreo en 5:
User-agent: Googlebot Crawl-delay: 5
Google ya no admite esta directiva pero Bing y Yandex sí.
Dicho esto, ten cuidado al establecer esta directiva, especialmente si tienes un sitio grande. Si estableces un retardo de rastreo de 5 segundos, entonces estarás limitando a los bots a rastrear un máximo de 17.280 URLs al día. Eso no es muy útil si tienes millones de páginas, pero podría ahorrar ancho de banda si tienes un sitio web pequeño.
Noindex
Esta directiva nunca fue apoyada oficialmente por Google. Sin embargo, hasta hace poco, se pensaba que Google tenía algún “código que maneja reglas no admitidas y no publicadas (como el noindex)”. Así que si quieres evitar que Google indexe todas las entradas de tu blog, puedes usar la siguiente directiva:
User-agent: Googlebot Noindex: /blog/
Sin embargo, el 1 de septiembre de 2019, Google dejó claro que esta directiva no está admitida. Si deseas excluir una página o un archivo de los motores de búsqueda, utiliza en su lugar la etiqueta meta robots o el encabezado HTTP x-robots.
Nofollow
Esta es otra directiva que Google nunca apoyó oficialmente y fue usada para indicar a los motores de búsqueda que no siguieran enlaces en páginas y archivos bajo una ruta específica. Por ejemplo, si quieres evitar que Google siga todos los enlaces de tu blog, puedes utilizar la siguiente directiva:
User-agent: Googlebot Nofollow: /blog/
Google anunció que esta directiva no tiene soporte oficial desde el 1 de septiembre de 2019. Si deseas no seguir todos los enlaces de una página ahora, debes utilizar la meta tag robots o el encabezado x-robots. Si deseas indicar a Google que no siga enlaces específicos de una página, utiliza el atributo de enlace rel=“nofollow”.
¿Necesitás un archivo robots.txt?
Tener un archivo robots.txt no es crucial para muchos sitios web, especialmente para los más pequeños.
Dicho esto, no hay ninguna buena razón para no tener uno. Te dará más control sobre dónde los motores de búsqueda pueden y no pueden entrar en tu sitio web, y esto podría ayudarte con cosas como:
- Prevenir el rastreo de contenido duplicado;
- Mantener secciones de un sitio web como privadas (por ejemplo, tu sitio de pruebas);
- Prevenir el rastreo de páginas de resultados de búsqueda interna;
- Prevenir la sobrecarga del servidor;
- Prevenir que Google desperdicie su “crawl budget.”
- Prevenir que imágenes, videos, y archivos de recursos aparezcan en los resultados de búsqueda de Google.
Ten en cuenta que aunque Google no suele indexar las páginas web que están bloqueadas por robots.txt, no hay forma de garantizar la exclusión en los resultados de búsqueda mediante el archivo robots.txt.
Como Google dice, si el contenido está enlazado desde otros lugares en la web, puede llegar a aparecer en los resultados de búsqueda de Google.
Cómo encontrar tu archivo robots.txt
Si ya tienes un archivo robots.txt en tu sitio web, podrás acceder a él mediante dominio.com/robots.txt. Navega hasta la URL de tu navegador. Si ves algo como esto, entonces tienes un archivo robots.txt:

Cómo crear un archivo robots.txt
Si aún no tienes un archivo robots.txt, crear uno es fácil. Simplemente abre un documento .txt en blanco y comienza a escribir directivas. Por ejemplo, si deseas impedir que todos los motores de búsqueda rastreen tu directorio /admin/ se debería ver algo así:
User-agent: * Disallow: /admin/
Continúa redactando las directivas hasta que estés satisfecho con lo que tienes. Guarda tu archivo como “robots.txt”.
Alternativamente, también puedes utilizar un generador robots.txt como este.
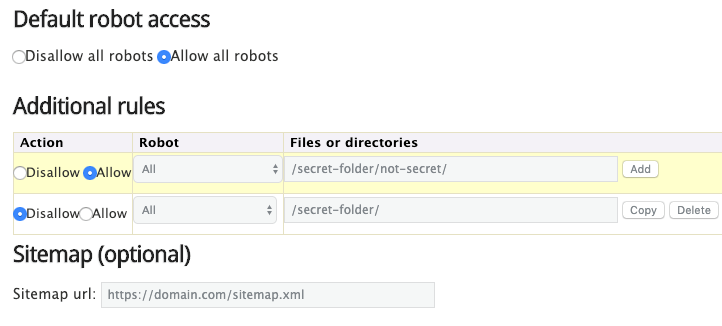
La ventaja de utilizar una herramienta como esta es que minimiza los errores de sintaxis. Esto es bueno porque un error podría resultar en una catástrofe SEO para tu sitio, por lo que vale la pena ir por el lado de la precaución.
La desventaja es que son algo limitados en términos de personalización.
Dónde ubicar tu archivo robots.txt
Ubica el archivo robots.txt en el directorio raíz del subdominio al que se aplique. Por ejemplo, para controlar el comportamiento de rastreo en un dominio.com, el archivo robots.txt debe estar accesible en dominio.com/robots.txt.
Si deseas controlar la rastreabilidad en un subdominio como blog.dominio.com, el archivo robots.txt debe estar accesible en blog.dominio.com/robots.txt.
Buenas prácticas para el archivo robots.txt
Tenlos en cuenta para evitar errores comunes.
Usa una nueva línea para cada directiva
Cada directiva debería ir en una nueva línea. De lo contrario confundirá a los motores de búsqueda.
Incorrecto:
User-agent: * Disallow: /directorio/ Disallow: /otro-directorio/
Correcto:
User-agent: * Disallow: /directorio/ Disallow: /otro-directorio/
Utiliza asteriscos para simplificar las instrucciones
No sólo puedes usar asteriscos (*) para aplicar directivas a todos los user-agents sino también para que coincidan con los patrones de URL al declarar directivas. Por ejemplo, si deseas evitar que los motores de búsqueda accedan a las URLs de las categorías de productos parametrizadas en tu sitio, puedes enumerarlas de la siguiente manera:
User-agent: * Disallow: /productos/camisetas? Disallow: /productos/pantalones? Disallow: /productos/chaquetas? …
Pero no es muy eficiente. Sería mejor si simplificáramos las cosas con un asterisco, de la siguiente manera:
User-agent: * Disallow: /productos/*?
Este ejemplo bloquea a los motores de búsqueda para que no rastreen todas las URLs bajo la subcarpeta /productos/ que contengan un signo de interrogación. En otras palabras, cualquier URL parametrizada de la categoría “producto”.
Usa “$” para especificar el final de una URL
Incluye el símbolo “$” para marcar el final de una URL. Por ejemplo, si deseas evitar que los motores de búsqueda accedan a todos los archivos .pdf de tu sitio, el archivo robots.txt debería verse así:
User-agent: * Disallow: /*.pdf$
En este ejemplo, los motores de búsqueda no pueden acceder a ninguna URL que termine en.pdf. Esto significa que no pueden acceder a /archivo.pdf, pero pueden acceder a /archivo.pdf?id=68937586 porque no termina con “.pdf”.
Usa cada user-agent sólo una vez
A Google no le importa si especificas el mismo user-agent varias veces. Simplemente combinará todas las reglas de las diversas declaraciones en una sola y las seguirá todas. Por ejemplo, si tienes los siguientes user-agents y directivas en tu archivo robots.txt.…
User-agent: Googlebot Disallow: /a/ User-agent: Googlebot Disallow: /b/
… Googlebot no dejaría de rastrear ninguna de las dos subcarpetas.
Dicho esto, tiene sentido declarar a cada user-agent sólo una vez porque es menos confuso. En otras palabras, es menos probable que cometas errores críticos al mantener las cosas ordenadas y simples.
Sé específico para evitar errores involuntarios
La falta de instrucciones específicas a la hora de establecer directivas puede dar lugar a errores fáciles que pueden tener un impacto catastrófico en el SEO. Por ejemplo, supongamos que tienes un sitio multilingüe y que estás trabajando en una versión en alemán que estará disponible en el subdirectorio /de/.
Debido a que no está listo para funcionar, quieres evitar que los motores de búsqueda accedan a él.
El archivo robots.txt que se muestra a continuación evitará que los motores de búsqueda accedan a esa subcarpeta y a todo lo que contiene:
User-agent: * Disallow: /de
Pero también evitará que los motores de búsqueda rastreen páginas o archivos que empiecen con /de.
Por ejemplo:
/decoracion/
/delivery-informacion.html
/depeche-mode/camisetas/
/definitivamente-no-para-ser-visto-en-publico.pdf
En este caso, la solución es simple: añadir una barra.
User-agent: * Disallow: /de/
Use comentarios para explicar tu archivo robots.txt a humanos
Los comentarios ayudan a explicar el archivo robots.txt a los desarrolladores, e incluso potencialmente a tu futuro yo. Para incluir un comentario, comienza la línea con un numeral (#).
# Esto le indica a Bing que no rastree nuestro sitio.
User-agent: Bingbot Disallow: /
Los rastreadores ignorarán todo lo que haya en las líneas que empiecen con un numeral.
Usa un archivo robots.txt separado para cada subdominio
Robots.txt sólo controla el comportamiento de rastreo en el subdominio donde esté alojado. Si deseas controlar el rastreo en un subdominio diferente, necesitarás un archivo robots.txt separado.
Por ejemplo, si tu sitio principal se encuentra en dominio.com y tu blog en blog.dominio.com, necesitarás dos archivos robots.txt. Uno debe ir en el directorio raíz del dominio principal, y el otro en el directorio raíz del blog.
Ejemplos de archivos robots.txt
A continuación se muestran algunos ejemplos de archivos robots.txt. Estos son principalmente para inspirarse, pero si uno de ellos se ajusta a tus necesidades, cópialo y pégalo en un documento de texto, guárdalo como “robots.txt” y cárgalo en el directorio apropiado.
Acceso total para todos los bots
User-agent: * Disallow:
Sin acceso para todos los bots
User-agent: * Disallow: /
Bloquear un subdirectorio para todos los bots
User-agent: * Disallow: /carpeta/
Bloquear un subdirectorio para todos los bots (con un archivo interno permitido)
User-agent: * Disallow: /carpeta/ Allow: /carpeta/pagina.html
Bloquear un archivo para todos los bots
User-agent: * Disallow: /esto-es-un-archivo.pdf
Bloquear un tipo de archivo (PDF) para todos los bots
User-agent: * Disallow: /*.pdf$
Bloquear todas las URLs parametrizadas sólo para Googlebot
User-agent: Googlebot Disallow: /*?
¿Cómo auditar tu archivo robots.txt en busca de errores?
Los errores de robots.txt se pueden deslizar por la red con bastante facilidad, por lo que vale la pena estar atento a los problemas.
Para hacerlo, busca regularmente cuestiones relacionadas al robots.txt en el reporte de “Cobertura” de Search Console. Aquí debajo tienes algunos de los errores que podrías ver, qué significan y cómo podrías solucionarlos.
Pega la URL en la herramienta de inspección de URLs de Google en Search Console. Si está bloqueado por robots.txt, deberías ver algo como esto:
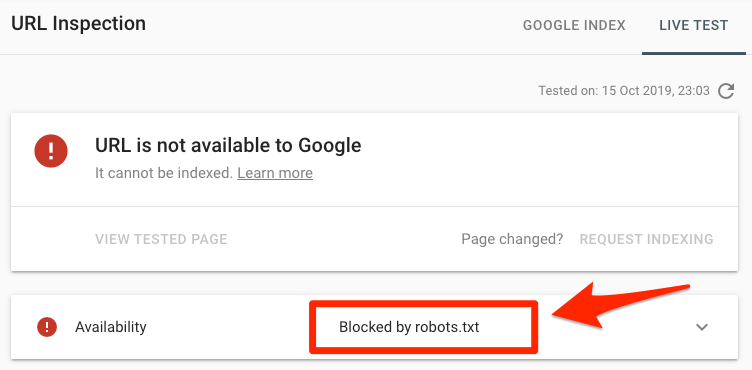
URL presentada bloqueada por robots.txt
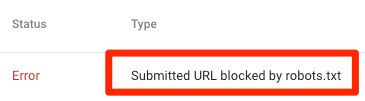
Esto significa que al menos una de las URL de los sitemaps presentados está bloqueada por robots.txt.
Si tú creaste tu sitemap correctamente y excluiste páginas canonicalizadas, noindexadas, y redirigidas, entonces ninguna página presentada debería ser bloqueada por robots.txt. Si es así, investiga qué páginas están afectadas y a continuación ajusta el archivo robots.txt en consecuencia para eliminar el bloqueo de esa página.
Puedes usar el tester de robots.txt de Google para ver qué directiva bloquea el contenido. Sólo ten cuidado al hacer esto, es fácil cometer errores que afectan a otras páginas y archivos.
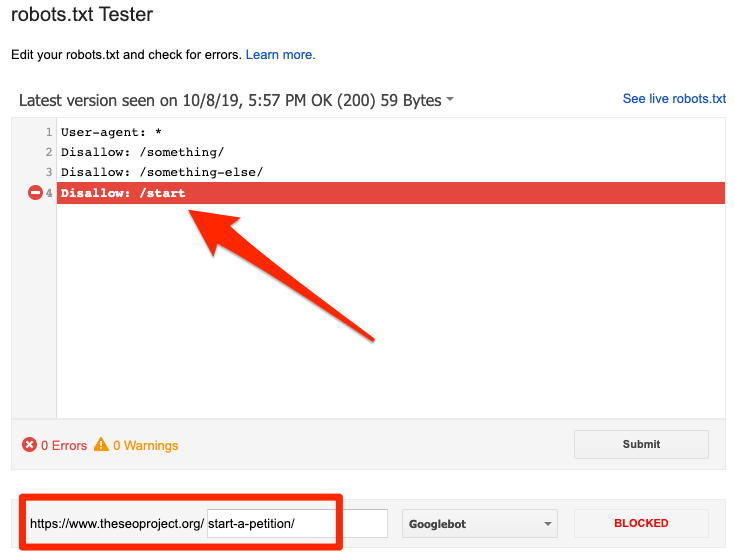
Bloqueado por robots.txt
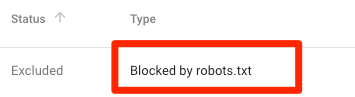
Esto significa que tienes contenido bloqueado por robots.txt que no está indexado actualmente en Google.
Si este contenido es importante y debe ser indexado, elimina el bloqueo de rastreo en robots.txt. Si has bloqueado contenido en robots.txt con la intención de excluirlo del índice de Google, elimina el bloqueo y utiliza una meta etiqueta de robots o un encabezado x-robots. Esa es la única manera de garantizar la exclusión de contenido del índice de Google.
Indexada, aunque bloqueada por robots.txt
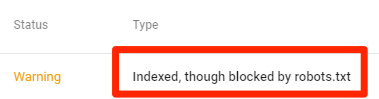
Esto significa que parte del contenido bloqueado por robots.txt sigue estando indexado en Google.
Una vez más, si estás intentando excluir este contenido de los resultados de búsqueda de Google, robots.txt no es la solución correcta. Quita el bloqueo de rastreo y en su lugar utiliza una meta etiqueta robots o encabezado HTTP x-robots para prevenir la indexación.
Si has bloqueado este contenido por accidente y deseas mantenerlo en el índice de Google, elimina el bloqueo del rastreo en robots.txt. Esto puede ayudar a mejorar la visibilidad del contenido en la búsqueda de Google.
FAQs
Aquí están algunas de las preguntas más frecuentes que no encajaban de forma natural en otra parte de nuestra guía: haznos saber en los comentarios si falta algo, y actualizaremos la sección en consecuencia.
¿Cuál es el tamaño máximo de un archivo robots.txt?
500 kilobytes (aproximadamente).
¿Dónde está robots.txt en WordPress?
En el mismo lugar: dominio.com/robots.txt.
¿Cómo puedo editar robots.txt en WordPress?
De forma manual o utilizando alguno de los muchos plugins SEO de WordPress como Yoast que te permite editar robots.txt desde el backend de WordPress.
¿Qué sucede si no permito el acceso a contenido no-indexado en robots.txt?
Google nunca verá la directiva noindex porque no puede rastrear la página.
DYK blocking a page with both a robots.txt disallow & a noindex in the page doesn’t make much sense cos Googlebot can’t “see” the noindex? pic.twitter.com/N4639rCCWt
— Gary “鯨理” Illyes (@methode) February 10, 2017
“¿Sabías que bloquear una página con un robots.txt disallow y un noindex en la página no tiene mucho sentido porque Googlebot no puede “ver” el noindex?”
Conclusiones
Robots.txt es un archivo simple pero poderoso. Utilízalo sabiamente, y puede tener un impacto positivo en el SEO. Úsalo al azar y, bueno, vivirás para arrepentirte.
¿Tienes más preguntas? Deja un comentario o búscame en Twitter.
Traducido por Agencia Eleven. Desde Argentina, hacemos que te encuentren.


