


Cos’è il Crawl Budget e Quando un Tecnico SEO Dovrebbe Preoccuparsene?

di Patrick Stox
SEO tecnica in Ahrefs
Un volume maggiore di scansioni non significa che ti posizionerai meglio, ma se le tue pagine non vengono scansionate e indicizzate non sarai in grado di posizionarti.
La maggior parte dei siti non ha bisogno di preoccuparsi del crawl budget, ma esistono alcune casistiche delle quali dovresti essere a conoscenza. Diamo uno sguardo ad alcune di queste.
Quando devi preoccuparti del crawl budget?
Solitamente non devi preoccuparti del crawl budget per quanto riguarda le tue pagine più visitate. Al contrario, le pagine nuove, non molto fornite di link o che non cambiano spesso, non vengono scansionate di frequente.
Il crawl budget è un motivo di preoccupazione per i siti nuovi, specialmente quelli con molte pagine. Il tuo server potrebbe essere in grado di supportare un maggior numero di scansioni, ma dato che il tuo sito è nuovo e non ben conosciuto, i motori di ricerca potrebbero non essere intenzionati a scansionarlo più di tanto. Questo può andare contro le aspettative. Quello che tu vuoi infatti è che le pagine del sito vengano scansionate e indicizzate, ma dato che Google non sa se queste siano meritevoli o meno, potrebbe decidere di non scansionare molte pagine.
Il crawl budget può essere una preoccupazione anche i siti più grandi con milioni di pagine, o quelli che vengono aggiornati molto frequentemente. In generale, se hai molte pagine che non vengono scansionate o aggiornate con la frequenza da te desiderata, dovresti cercare di velocizzare e aumentare il numero di scansioni. Vedremo come farlo più avanti nell’articolo.
Come monitorare l'attività dei crawler
Se vuoi vedere le attività di scansione sul tuo sito da parte di Google ed eventuali problemi riscontrati, il modo migliore di farlo è analizzare il report chiamato Statistiche di Scansione all’interno di Google Search Console.
Al suo interno ci sono diversi avvisi che possono aiutarti ad identificare variazioni sulle scansioni, eventuali problematiche e fornirti dettagli aggiuntivi su come Google sta scansionando il tuo sito.
Dovresti sicuramente approfondire la presenza di eventuali errori di scansione come quelli mostrati qui sotto:

Sono anche presenti i dettagli di quando una pagina è stata scansionata l’ultima volta.
Se vuoi invece analizzare tutte le visite sia dai bot che dagli utenti, avrai bisogno dell’accesso ai tuoi file di log. A seconda del tuo hosting e del relativo setup, potresti aver accesso a strumenti come Awstats e Webalizer, come mostrato qui sotto nel pannello di controllo cPanel di un hosting condiviso. Questi strumenti mostrano alcuni dati aggregati a partire dai file di log.

Sui setup più complessi avrai invece bisogno di accedere e salvare dati dai cosiddetti file di log raw, solitamente da diverse fonti. Sui progetti più grandi, avrai anche bisogno di strumenti specializzati come un ELK (elasticsearch, logstash, kibana) stack che consente di salvare, processare e visualizzare i file di log. Esistono poi anche strumenti per l’analisi dei log come Splunk.
Cosa influisce negativamente sul crawl budget?
Tutte le URL e le richieste di scansione vengono scalate dal tuo crawl budget. Questo include anche le versioni alternative delle URL come AMP, pagine su domini m.dominio, hreflang, CSS e Javascript, incluse le richieste XHR.
Queste URL vengono trovate scansionando e facendo il parsing delle pagine, o da una serie di altre fonti come sitemap, feed RSS, l’invio di nuove URL a fini di indicizzazione attraverso Google Search Console, o anche tramite l’utilizzo della API di indicizzazione.
Esistono anche versioni multiple dei Googlebots che condividono fra di loro il crawl budget. Puoi trovare una lista dei vari Googlebot che scansionano il tuo sito all’interno del report sulle Statistiche di Scansione in GSC.
In che modo Google regola le attività di scansione?
Ogni sito web ha un diverso crawl budget, che viene definito da diversi input.
Volume richiesto di scansione
Il volume richiesto di scansione rappresenta semplicemente quanto Google vuole scansionare il tuo sito. Le pagine più visitate e quelle che vengono modificate in maniera significativa verranno scansionate di più.
Le pagine più visitate, o quelle con un maggior numero di link, generalmente vengono prioritizzare rispetto alle altre pagine. Ricorda che Google deve assegnare una priorità alle pagine in qualche modo, ed i link sono un metodo semplice per determinare quali pagine sono più apprezzate. Non parlo però solo del tuo sito. Google deve infatti assegnare una priorità a tutte le pagine di tutti i siti che si trovano su internet.
Puoi utilizzare il report Migliore per link all’interno del Site Explorer come indicazione per capire quali saranno le pagine del sito che verranno scansionate più di frequente. Mostra anche quando la pagina è stata scansionata l’ultima volta da Ahrefs.
Esiste anche un concetto di invecchiamento. Se Google nota che una pagina non cambia, questa verrà scansionata con poca frequenza. Ad esempio se una pagina viene scansionata e non sono presenti modifiche dopo un giorno, potrebbero passare tre giorni prima della scansione successiva, poi dieci, poi 30, poi 100 e così via. Non esiste in effetti un periodo definito che i crawler attendono prima di compiere la successiva scansione, ma queste diventeranno meno frequenti nel corso del tempo. Se però Google nota molta attività e cambiamenti in generale sul sito, o se questo viene spostato, la frequenza delle scansioni verrà incrementata, almeno temporaneamente.
Limite sulla velocità di scansione
I limiti sulla velocità di scansione rappresentato quante scansioni il tuo sito è in grado di supportare. Alcuni siti hanno uno specifico limite sulle scansioni prima di cominciare a presentare problematiche relative alla stabilità del server, come rallentamenti o errori. La maggior parte dei crawler rallenterà le attività se inizia a notare problematiche del genere, in modo da non produrre danni al sito.
Google regola le attività di scansione in base allo stato di salute del sito. Se nota infatti che questo riesce tranquillamente a gestire più scansioni, il limite verrà incrementato. Al contrario, se il sito inizia a presentare problemi, Google rallenterà la frequenza con la quale compie le scansioni.
Come far sì che Google scansioni più velocemente?
Esistono una serie di azioni che puoi intraprendere per far sì che il tuo sito supporti un maggior numero di scansioni e in generale aumentare le richieste di scansione da parte dei bot. Diamo uno sguardo ad alcune di queste.
Velocizza il tuo server / aumenta le risorse
Il modo in cui Google scansiona le pagine consiste in pratica nel download delle risorse e nel processare poi queste dal loro lato. La tua velocità di pagina come percepito dagli utenti non è esattamente la stessa cosa. Quello che avrà un impatto sul crawl budget, è quanto velocemente Google riesce a connettersi al sito e scaricare le relative risorse: una questione che ha a che fare principalmente con il server e le risorse stesse.
Più link, interni & esterni
Ricorda che il volume di scansione richiesto dipende dalla popolarità della pagina o dai suoi link. Puoi aumentare il crawl budget aumentando il numero di link esterni e/o link interni. I link interni sono più semplici da ottenere in quanto hai controllo sul sito. Puoi trovare delle opportunità di inserimento dei link interni attraverso il report Link Opportunities nel Site Audit, che include anche una guida su come questo funziona.
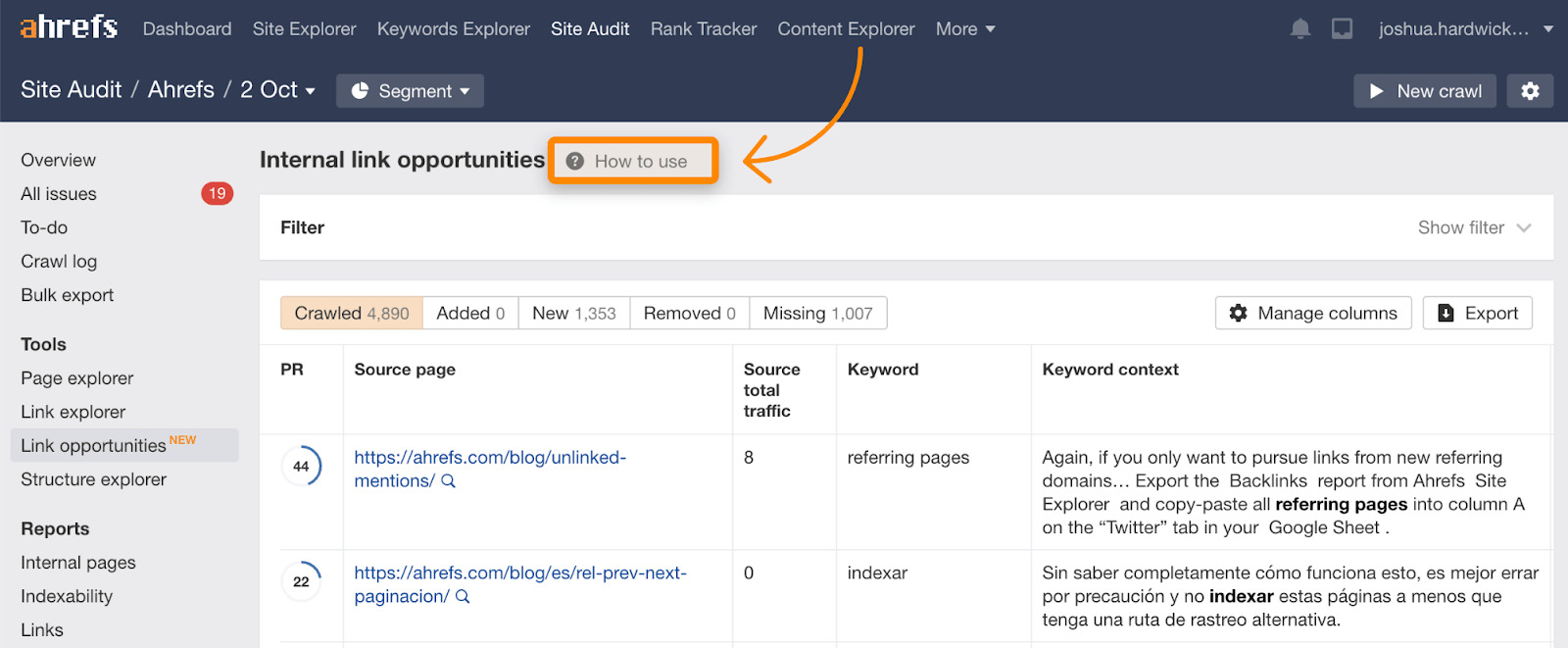
Correggi i link rotti e quelli in redirect
Avere link verso pagine non esistenti o in redirect sul suo sito ha un piccolo impatto sul crawl budget. Tipicamente, le pagine con link in questo modo hanno una priorità più bassa, in quanto probabilmente non hanno subito cambiamenti da un po’ di tempo. Correggere questi errori fa parte però di una buona manutenzione del sito e aiuterà, anche se in minima parte, il tuo crawl budget.
Puoi identificare i link rotti (4xx) e quelli in redirect (3xx) in maniera molto semplice attraverso il report Internal pages presente all’interno del Site Audit.
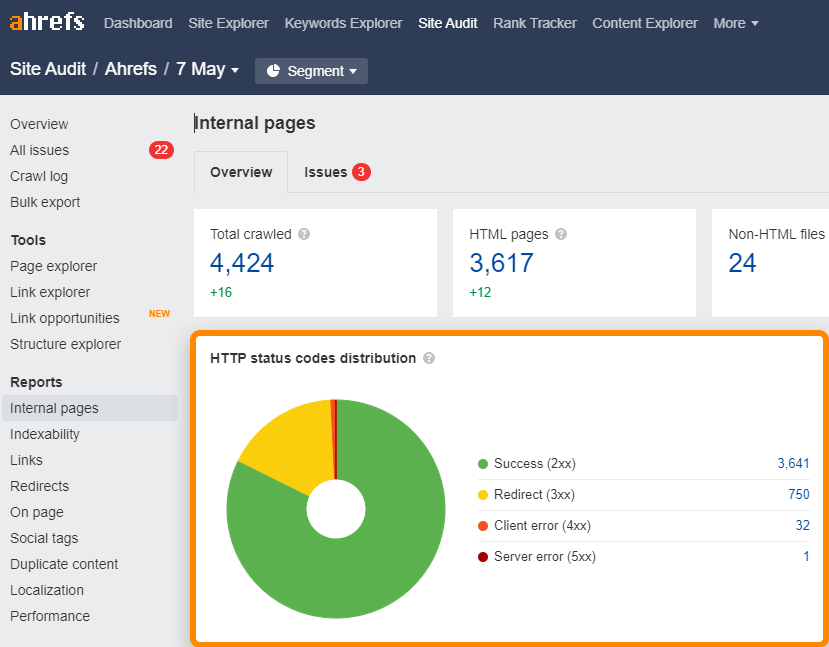
Per i link rotti o in redirect all’interno della sitemap, verifica il report chiamato All issues alla ricerca di errori del tipo “3XX redirect in sitemap” e “4XX page in sitemap”.
Utilizza GET invece di POST dove possibile
Questa è una questione un pò più tecnica che riguarda i metodi con cui vengono fatte le Richieste HTTP. Non utilizzare richieste di tipo POST dove va bene GET. In pratica si tratta di GET (pull) contro POST (push). Le richieste POST non vanno in cache e quindi impattano il crawl budget, mentre le GET finiscono nella cache.
Utilizza le API di indicizzazione
Se vuoi che le tue pagine vengano scansionate più velocemente, verifica se puoi utilizzare le API di indicizzazione di Google. Al momento queste sono disponibili solo per alcune casistiche, come il caricamento di annunci di lavoro o video live.
Anche Bing ha delle API di indicizzazione aperte a tutti.
Cosa non funziona
Ci sono alcune cose che le persone talvolta provano ma che in realtà non hanno alcun effetto sul crawl budget.
- Piccole modifiche al sito. Apportare piccoli cambiamenti alle pagine come aggiornare le date, inserire uno spazio o della punteggiatura sperando di far scansionare le pagine con una maggiore frequenza. Google è molto bravo a determinare se le modifiche sono o meno significative, quindi queste piccole modifiche non hanno, con molta probabilità, alcun effetto sulle scansioni.
- Direttive del controllo di scansione all’interno di robots.txt. Queste direttive rallentano molti bot. Googlebot però non le rispetta, e di conseguenza non viene impattato. Ad Ahrefs, seguiamo tali direttive, di conseguenza se hai bisogno di rallentare le nostre scansioni puoi farlo attraverso il file robots.txt.
- Rimuovere script di terze parti. Gli script di terze parti non vengono conteggiati in relazione al tuo crawl budget, di conseguenza rimuoverli non è di nessun aiuto.
- Nofollow. Okay, questa questione è incerta. In passato i link nofollow non consumavano crawl budget. Ora però il nofollow viene solo trattato come un consiglio, di conseguenza Google può scegliere o meno se scansionare tali link.
Come far sì che Google scansioni più lentamente?
Esistono solo una paio di metodi effettivi per far sì che Google scansioni il sito più lentamente. In realtà ci sono anche altri aggiustamenti tecnici che potresti fare, come rallentare il caricamento del tuo sito, ma non sono metodi che consiglio di adottare.
Piccoli aggiustamenti, garantiti
Il controllo principale che Google mette a disposizione per la scansione del sito, è un limite sulla velocità di scansione all’interno di Google Search Console. Puoi rallentare la velocità di scansione attraverso lo strumento, ma potrebbero volerci un paio di giorni per apprezzarne gli effetti.
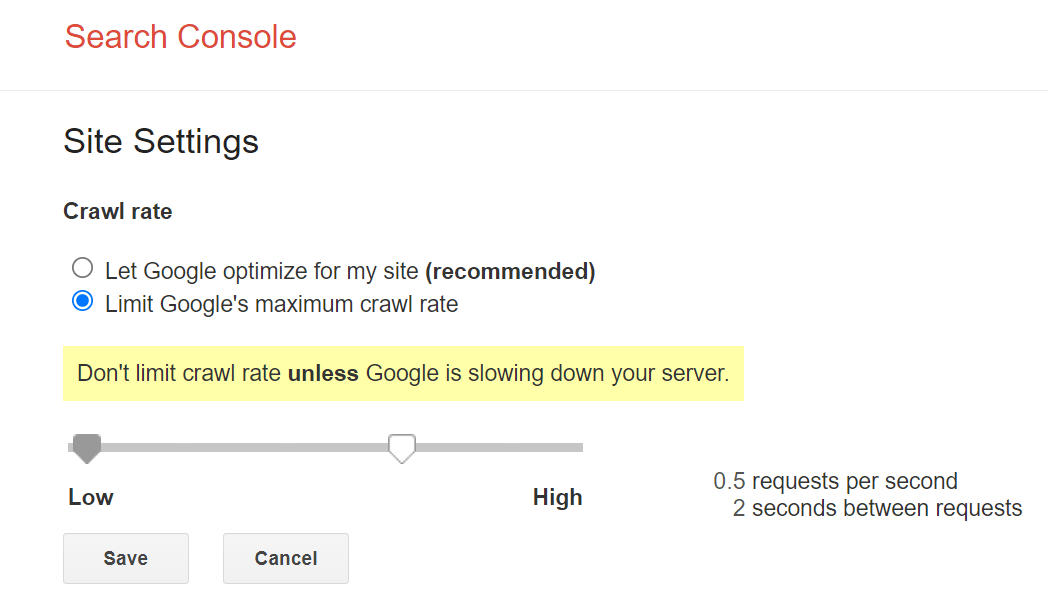
Aggiustamenti rapidi, ma con dei rischi
Se hai bisogno di una soluzione immediata, puoi sfruttare gli aggiustamente correlati allo stato di salute del sito per fare in modo che Google rallenti le scansioni. Se rispondi a Googlebot con uno status code '503 Service Unavailable' o '429 Too Many Requests', questo rallenterà le scansioni o addirittura le fermerà temporaneamente. Non farlo però per più di qualche giorno, o Google potrebbe iniziare a escludere le pagine dall’indice.
Conclusione
Di nuovo, il crawl budget non è un qualcosa del quale la maggior parte delle persone dovrebbero preoccuparsi. Se hai delle preoccupazioni a riguardo, spero che questa guida ti sia stata utile.
Solitamente si tratta di un qualcosa che analizzo quando ci sono problemi relativi a pagine che non vengono scansionate o indicizzate, devo spiegare a qualcuno perchè non dovrebbe preoccuparsi, o magari noto qualcosa che desta in me preoccupazione all’interno del rapporto sulle statistiche di scansione in Google Search Console.
Hai domande? Fammelo sapere su Twitter.
Patrick Stox è Product Advisor, Technical SEO e Brand Ambassador presso Ahrefs. È stato l'autore principale del capitolo sulla SEO del Web Almanac 2021 e revisore del capitolo sulla SEO del 2022. È stato anche co-redattore del libro della SEO per principianti di Ahrefs ed è stato Technical Review Editor per The Art of SEO 4th Edition. È un organizzatore del Triangle SEO Meetup, della conferenza Tech SEO Connect, gestisce un gruppo Slack di SEO tecnica ed è moderatore di /r/TechSEO su Reddit.