
Mehr Crawling bedeutet nicht, dass du besser rankst, aber wenn deine Seiten nicht gecrawlt und indexiert werden, werden sie überhaupt nicht ranken.
Die meisten Seiten müssen sich keine Sorgen um das Crawl-Budget machen, aber es gibt ein paar Fälle, in denen du einen Blick darauf werfen solltest. Schauen wir uns einige dieser Fälle an.
- Wann solltest du dir Gedanken um dein Crawl-Budget machen?
- Wie man die Crawl-Aktivität überprüft
- Was wird dem Crawl-Budget gegengerechnet?
- Wie passt Google sein Crawling an?
- Wie kann ich Google dazu bringen, schneller zu crawlen?
- Wie kann ich Google dazu bringen, langsamer zu crawlen?
Auf beliebten Seiten musst du dir normalerweise keine Gedanken über das Crawl-Budget machen. Seiten, die nicht oft gecrawlt werden, sind meist neuer, nicht gut verlinkt oder werden nicht oft verändert.
Das Crawl-Budget kann ein Problem für neuere Websites darstellen, vor allem für solche mit einer großen Anzahl von Seiten. Dein Server kann vielleicht mehr Crawling unterstützen, aber weil deine Seite neu und wahrscheinlich noch nicht sehr populär ist, will eine Suchmaschine deine Seite vielleicht nicht sehr oft crawlen. Hier hat man oft zu hohe Erwartungen. Du möchtest, dass deine Seiten gecrawlt und indexiert werden. Doch Google weiß nicht, ob es sich lohnt, deine Seiten zu indexieren und möchte vielleicht nicht so viele Seiten crawlen, wie du es dir wünschst.
Das Crawl-Budget kann auch ein Problem für größere Websites mit Millionen von Seiten oder Websites, die häufig aktualisiert werden, sein. Generell gilt: Wenn du viele Seiten hast, die nicht so oft gecrawlt oder aktualisiert werden, wie du es gerne hättest, dann solltest du dir überlegen, wie du das Crawling beschleunigen kannst. Wir werden später im Artikel darüber sprechen, wie man das macht.
Wenn du einen Überblick über die Crawl-Aktivitäten von Google und die von ihnen identifizierten Probleme sehen möchtest, dann ist der Crawl-Statistikbericht in der Google Search Console dafür am besten geeignet.
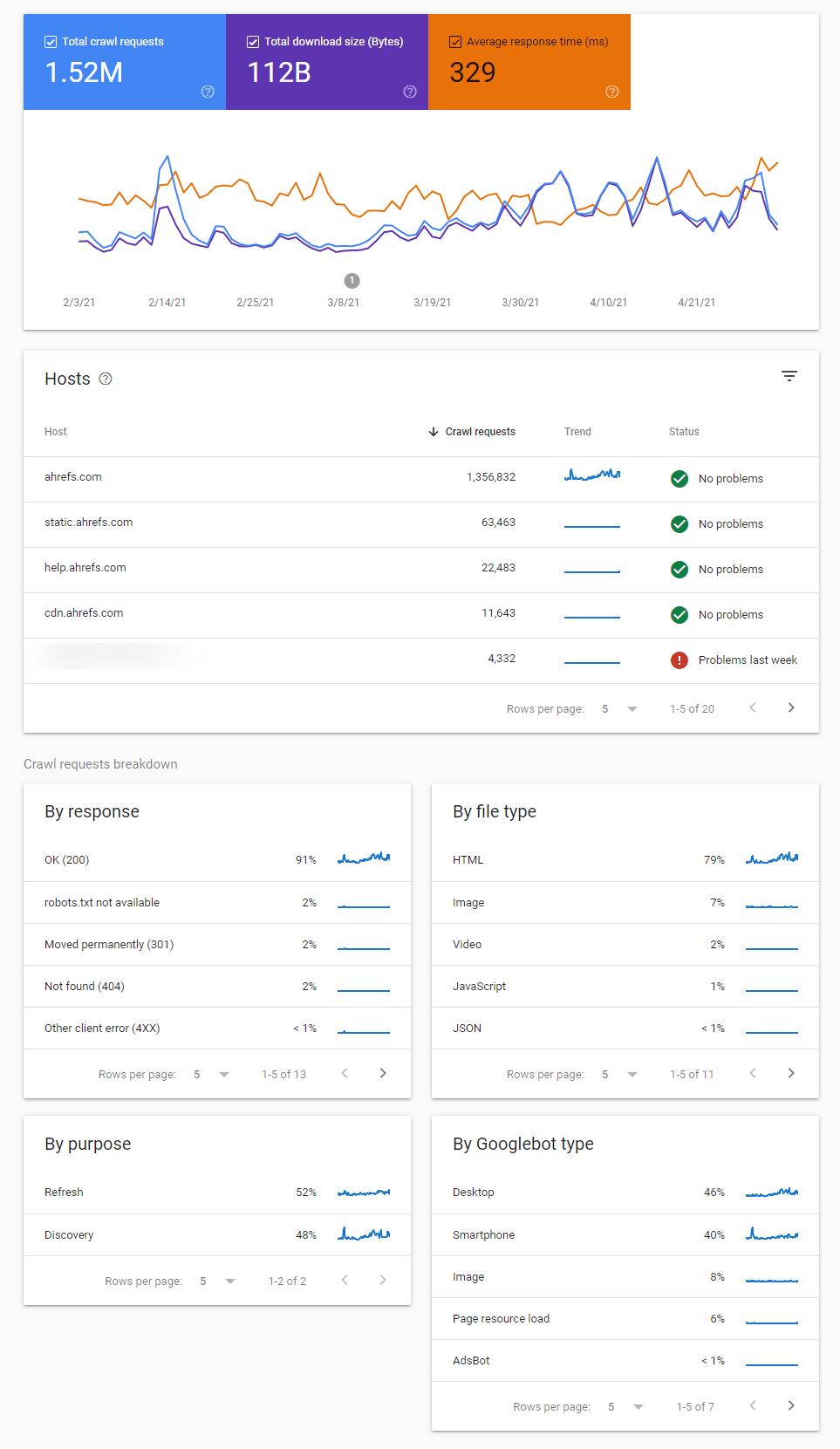
Hier gibt es verschiedene Berichte, die dir dabei helfen, Veränderungen im Crawling-Verhalten und Probleme beim Crawling zu erkennen und dir mehr Informationen darüber geben, wie Google deine Seite crawlt.
Du solltest dir auf jeden Fall alle markierten Crawl-Status wie diese hier ansehen:

Es gibt auch Zeitstempel, wann die Seiten zuletzt gecrawlt wurden.
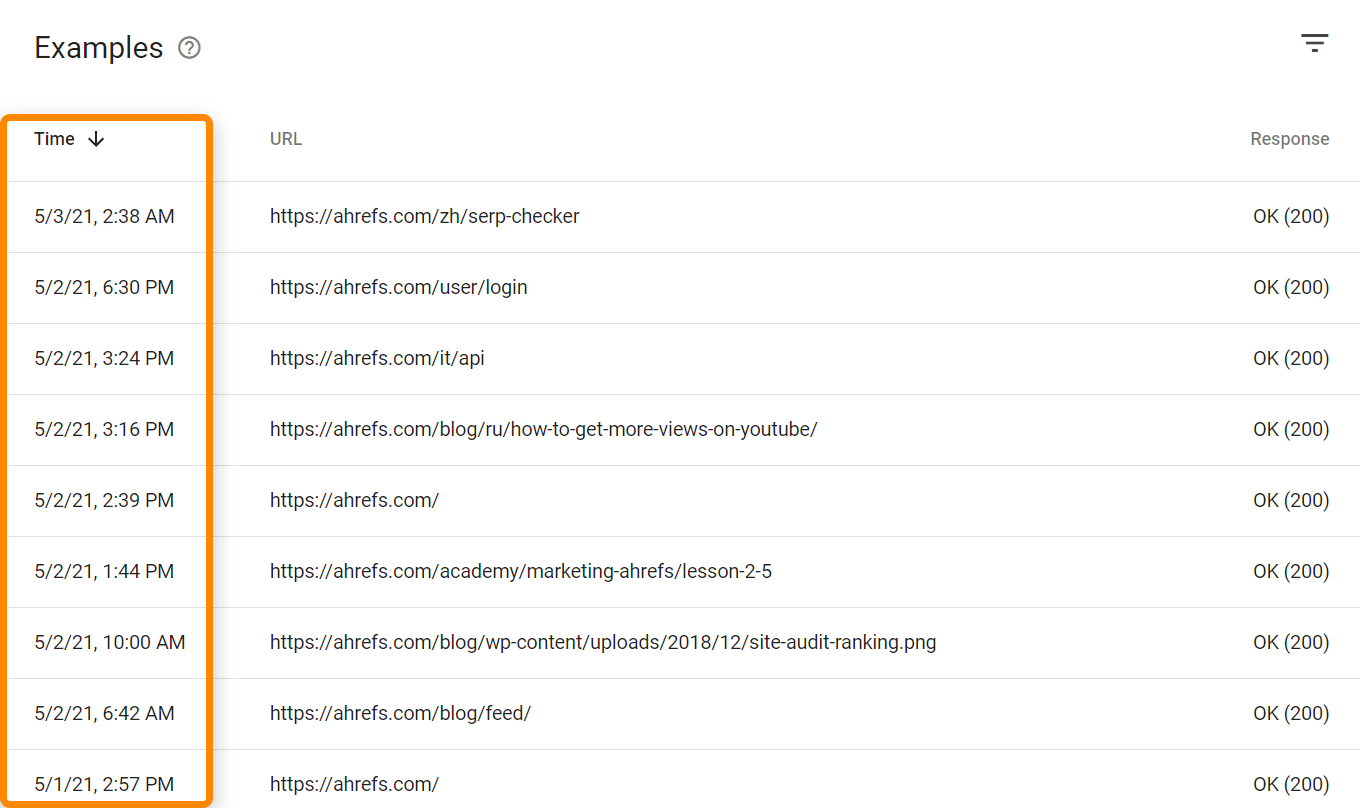
Wenn du die Zugriffe von allen Bots und Usern sehen willst, brauchst du Zugang zu deinen Logdateien. Je nach Hosting und Setup hast du Zugriff auf Tools wie Awstats und Webalizer, wie hier auf einem Shared Host mit cPanel zu sehen ist. Diese Tools zeigen einige gesammelte Daten aus deinen Logdateien an.

Für komplexere Setups musst du Zugriff auf die Rohdaten der Logdateien erhalten und diese speichern, möglicherweise aus mehreren Quellen. Für größere Projekte benötigst du möglicherweise auch spezielle Tools wie einen ELK (elasticsearch, logstash, kibana) Stack, der die Speicherung, Verarbeitung und Visualisierung von Logdateien ermöglicht. Außerdem gibt es Log-Analyse-Tools wie Splunk.
Alle URLs und Anfragen werden deinem Crawl-Budget zugerechnet. Dies schließt alternative URLs wie AMP oder m‑dot Seiten, hreflang, CSS und JavaScript einschließlich XHR Anfragen ein.
Diese URLs können durch das Crawlen und Parsen von Seiten gefunden werden oder aus einer Vielzahl anderer Quellen wie Sitemaps, RSS-Feeds, dem Einreichen von URLs zur Indexierung in der Google Search Console oder der Nutzung der Indexierungs-API.
Es gibt auch mehrere Googlebots, die sich das Crawl-Budget teilen. Eine Liste der verschiedenen Googlebots, die deine Website crawlen, findest du im Bericht Crawl-Statistiken in der GSC.
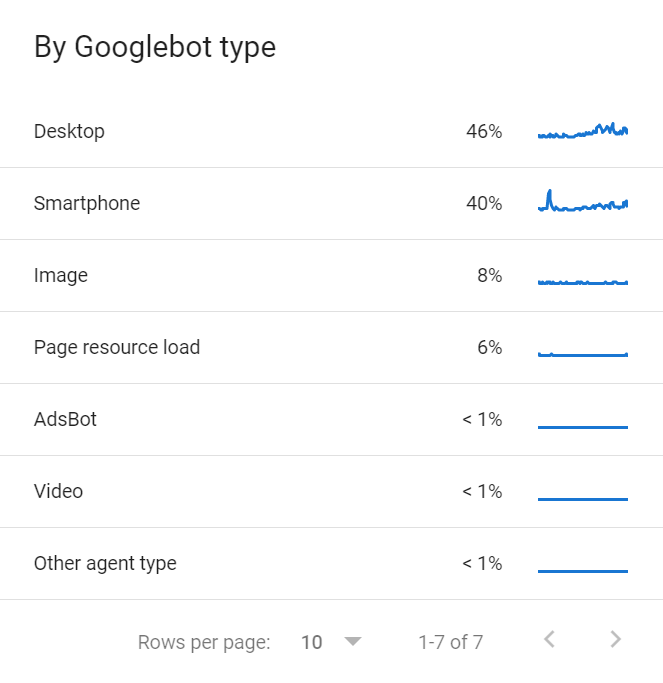
Jede Website hat ein anderes Crawl-Budget, das sich aus verschiedenen Faktoren zusammensetzt.
Crawl demand
Der Crawl-Bedarf gibt einfach an, wie viel Google von deiner Website crawlen möchte. Beliebtere Seiten und Seiten, die sich stark verändern, werden mehr gecrawlt.
Beliebte Seiten, oder jene mit mehr Links zu solchen, werden generell Priorität vor anderen Seiten erhalten. Denke daran, dass Google deine Seiten für das Crawling auf irgendeine Weise priorisieren muss und Links sind eine einfache Möglichkeit, um zu bestimmen, welche Seiten auf deiner Website beliebter sind. Es geht aber nicht nur um deine Seite, sondern um alle Seiten auf allen Websites im Internet, bei denen Google herausfinden muss, wie sie zu priorisieren sind.
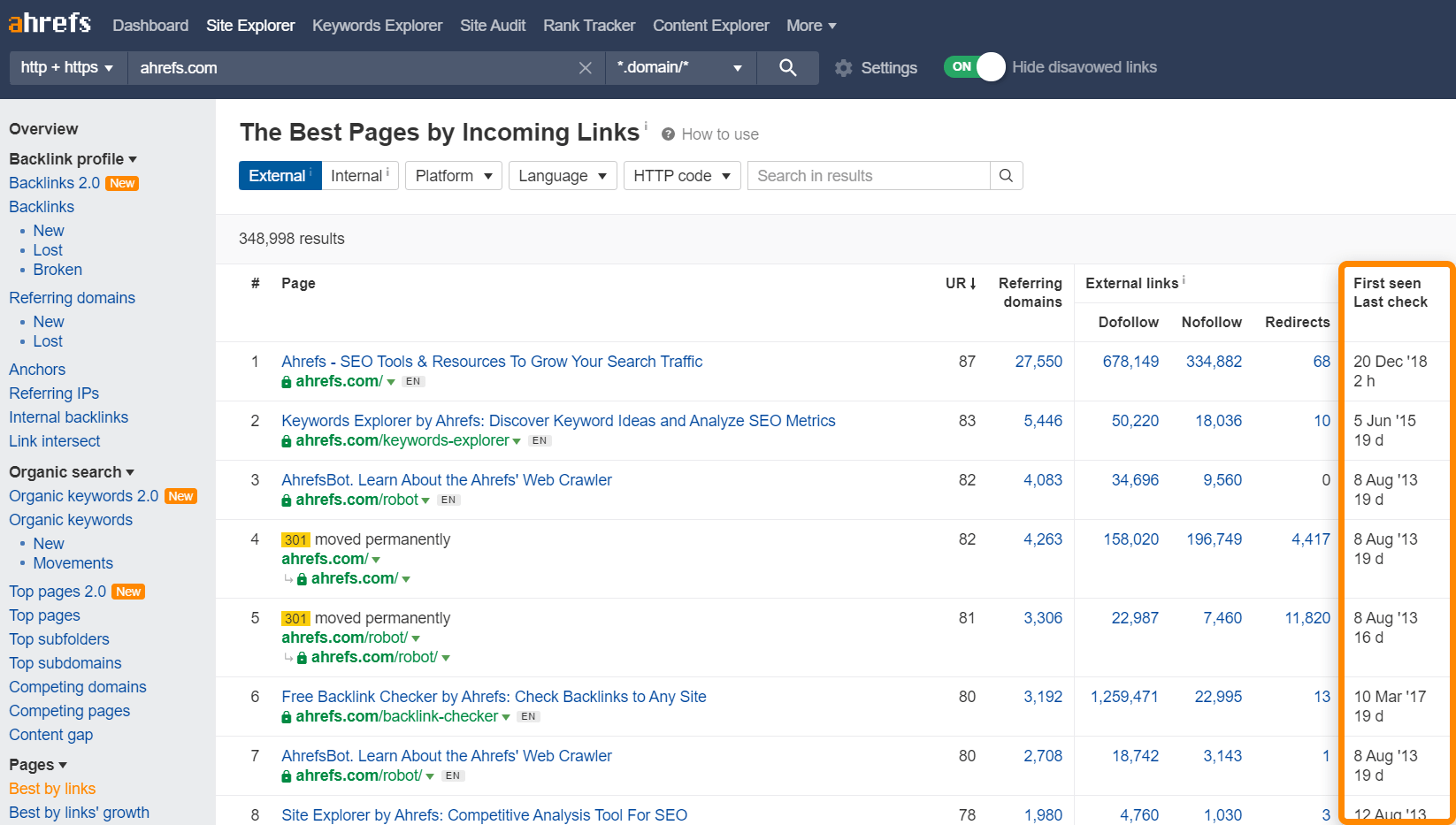
Du kannst den Bericht “Best by Links” im Site Explorer als Hinweis darauf nutzen, welche Seiten wahrscheinlich häufiger gecrawlt werden. Er zeigt dir auch, wann Ahrefs deine Seiten zuletzt gecrawlt hat.
Es gibt auch das Phänomen der Beständigkeit. Wenn Google sieht, dass sich eine Seite nicht verändert, wird sie weniger häufig gecrawlt. Wenn sie zum Beispiel eine Seite crawlen und nach einem Tag keine Änderungen sehen, warten sie vielleicht drei Tage, bevor sie wieder crawlen, zehn Tage beim nächsten Mal, 30 Tage, 100 Tage, usw. Es gibt keine festgelegte Zeitspanne, die sie zwischen den Crawls warten, aber es wird mit der Zeit immer seltener. Wenn Google jedoch große Veränderungen auf der Seite als Ganzes oder einen Umzug der Seite sieht, wird die Crawl-Rate normalerweise erhöht, zumindest vorübergehend.
Crawl rate limit
Das Crawl-Rate-Limit gibt an, wie viel Crawling deine Webseite aushält. Websites haben eine bestimmte Menge an Crawling, die sie aushalten können, bevor es zu Problemen mit der Stabilität des Servers wie Verlangsamungen oder Fehlern kommt. Die meisten Crawler werden das Crawlen zurückfahren, wenn sie diese Probleme bemerken, um die Seite nicht zu beschädigen.
Google wird die Anzahl der Crawler basierend auf dem Gesundheitszustand der Seite anpassen. Wenn die Seite in Ordnung ist und mehr gecrawlt wird, dann wird das Limit erhöht. Wenn die Seite Probleme hat, dann wird Google die Crawling-Rate verlangsamen.
Es gibt ein paar Dinge, die du tun kannst, um sicherzustellen, dass deine Seite zusätzliches Crawling unterstützt und die Crawl-Anforderung deiner Seite erhöht. Schauen wir uns einige dieser Optionen an.
Beschleunige deinen Server / erhöhe die Kapazitäten
Die Art und Weise, wie Google Seiten crawlt, besteht grundsätzlich darin, Ressourcen herunterzuladen und sie dann auf ihrer Seite zu verarbeiten. Deine Seitengeschwindigkeit, wie sie ein Nutzer wahrnimmt, ist nicht ganz dasselbe. Was sich auf das Crawl-Budget auswirkt, ist, wie schnell Google sich verbinden und Ressourcen herunterladen kann, was mehr mit dem Server und den Ressourcen zu tun hat.
Mehr Links — externe & interne
Denke daran, dass der Crawl-Bedarf generell auf der Popularität oder den Links basiert. Du kannst dein Budget erhöhen, indem du die Anzahl der externen Links und/oder der internen Links erhöhst. Interne Links sind einfacher, da du die Kontrolle über die Seite hast. Vorgeschlagene interne Links findest du im Link-Opportunities-Bericht im Site Audit, der auch ein Tutorial enthält, das erklärt, wie es funktioniert.
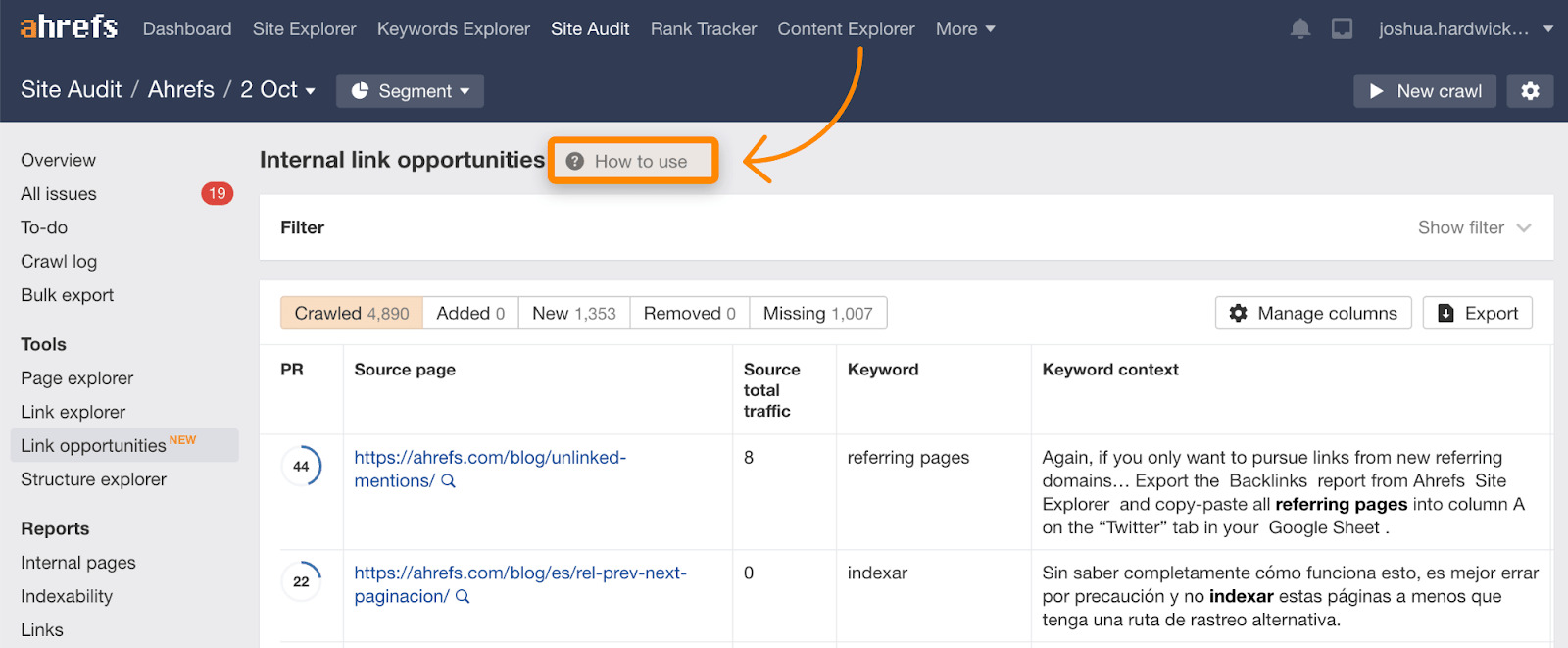
Repariere defekte und umgeleitete Links
Links zu defekten oder umgeleiteten Seiten auf deiner Seite aktiv zu halten, wird einen kleinen Einfluss auf dein Crawl-Budget haben. Typischerweise haben die Seiten, die hier verlinkt sind, eine ziemlich niedrige Priorität, da sie sich wahrscheinlich schon eine Weile nicht mehr verändert haben, aber die Beseitigung von Problemen ist gut für die Wartung der Website im Allgemeinen und hilft deinem Crawl-Budget ein wenig.
Du kannst kaputte (4xx) und umgeleitete (3xx) Links auf deiner Seite leicht imInternen-Seiten-Berichtin Site Audit finden.
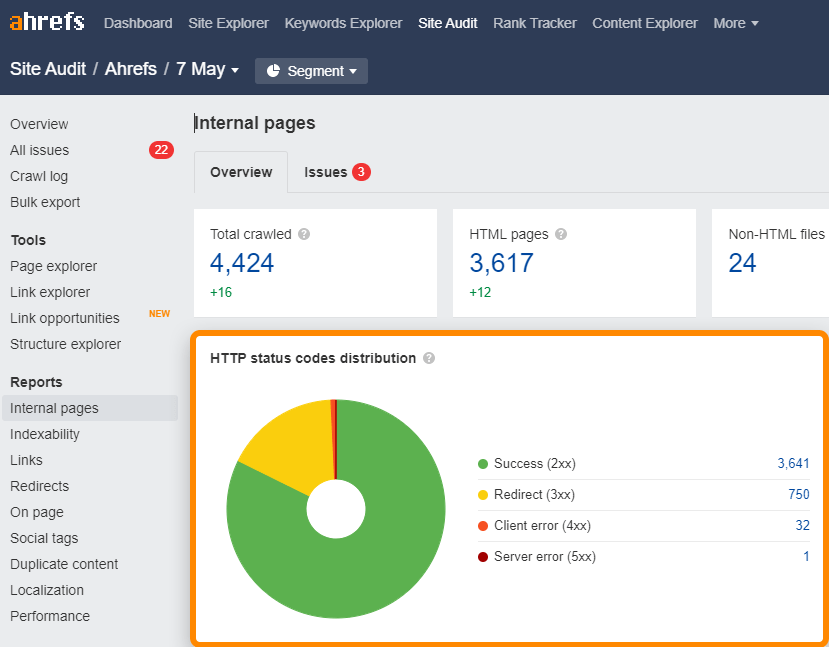
Für kaputte oder umgeleitete Links in der Sitemap, überprüfe den Alle-Probleme-Bericht auf “3XX redirect in sitemap” und “4XX page in sitemap” Probleme.
Verwende GET statt POST, wo es möglich ist
Dieser Punkt ist etwas technischer, da er die HTTP-Request-Methoden betrifft. Verwende keine POST-Anfragen, wo GET-Anfragen funktionieren. Es gilt grundsätzlich GET (pull) vs. POST (push). POST-Anfragen werden nicht gecached und haben daher Auswirkungen auf das Crawl-Budget, aber GET-Anfragen können gecached werden.
Nutze die Indexierungs-API
Wenn du Seiten schneller gecrawlt haben möchtest, prüfe, ob du für die Indexierungs-API von Google qualifiziert bist. Momentan ist diese nur für einige wenige Anwendungsfälle wie Stellenanzeigen oder Live-Videos verfügbar.
Bing hat auch eine Indexierungs-API, die für jeden verfügbar ist.
Was nicht funktionieren wird
Es gibt ein paar Dinge, die von manchen Leuten ausprobiert werden, die aber für das Crawl-Budget nicht wirklich hilfreich sind.
- Kleine Veränderungen an der Seite. Kleine Änderungen auf den Seiten, wie das Aktualisieren von Daten, Zwischenräumen oder der Zeichensetzung, in der Hoffnung, dass die Seiten öfter gecrawlt werden. Google ist ziemlich gut darin zu erkennen, ob Änderungen signifikant sind oder nicht, daher werden diese kleinen Änderungen wahrscheinlich keinen Einfluss auf das Crawling haben.
- Anweisung zur Crawl-Verzögerung in der robots.txt. Diese Anweisung wird viele Bots ausbremsen. Der Googlebot benutzt sie jedoch nicht, so dass sie keinen Einfluss haben wird. Wir bei Ahrefs respektieren dies, wenn du also unser Crawling verlangsamen möchtest, kannst du eine Crawl-Verzögerung in deiner robots.txt-Datei hinzufügen.
- Skripte von Drittanbietern entfernen. Skripte von Drittanbietern werden deinem Crawl-Budget nicht gegengerechnet, also hilft es auch nicht, sie zu entfernen.
- Nofollow. Okay, dieser Punkt ist fraglich. In der Vergangenheit haben Nofollow-Links kein Crawl-Budget verbraucht. Allerdings wird nofollow jetzt als Hinweis angesehen, so dass Google diese Links möglicherweise crawlen wird.
Es gibt nur ein paar gute Möglichkeiten, um Google langsamer crawlen zu lassen. Du könntest noch ein paar andere technische Anpassungen vornehmen, wie z.B. die Verlangsamung deiner Website, aber das sind keine Methoden, die ich empfehlen würde.
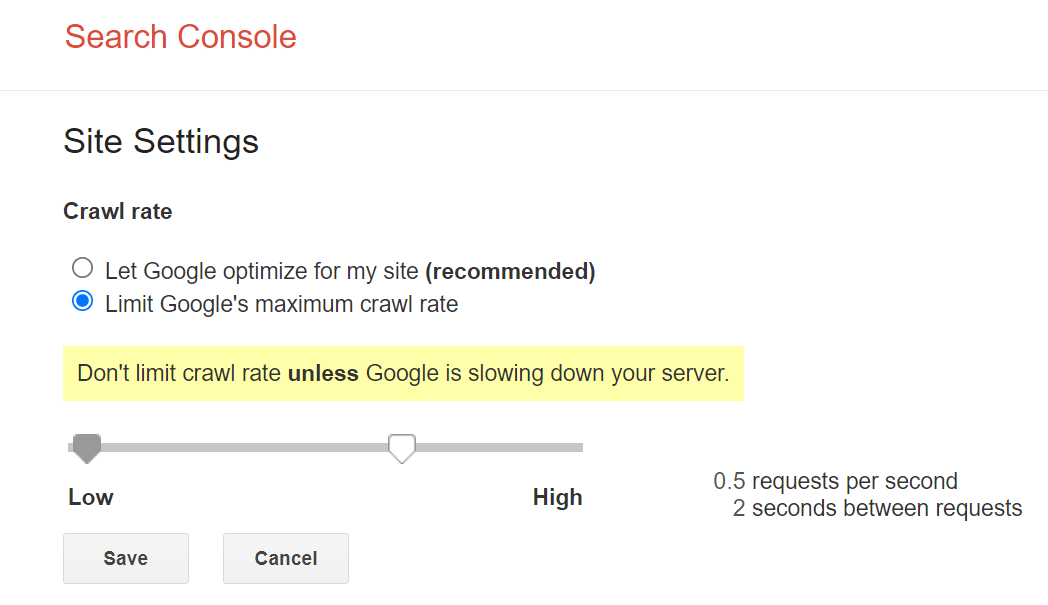
Langsame Anpassung, aber dafür sicher
Die Hauptkontrolle, die Google uns gibt, um langsamer zu crawlen, ist eine Art Geschwindigkeitsbegrenzer innerhalb der Google Search Console. Du kannst das Crawl-Tempo mit dem Tool verlangsamen, aber es kann bis zu zwei Tage dauern, bis es wirkt.
Schnelle Anpassung, aber dafür mit Risiken
Wenn du eine schnellere Lösung brauchst, kannst du dir die Crawl-Frequenz-Anpassungen von Google zunutze machen, die sich auf den Zustand deiner Seite beziehen. Wenn du dem Googlebot einen ‘503 Service Unavailable’ oder ‘429 Too Many Requests’-Statuscode auf einer Seite lieferst, wird er anfangen langsamer zu crawlen oder kann das Crawlen vorübergehend einstellen. Du solltest dies jedoch nicht länger als ein paar Tage tun, da es sonst dazu führen kann, dass Seiten aus dem Index entfernt werden.
Fazit
Ich möchte noch einmal betonen, dass das Crawl-Budget für die meisten Leute kein Grund zur Sorge ist. Falls du dir doch Sorgen machst, hoffe ich, dass dieser Leitfaden nützlich war.
Normalerweise schaue ich mir das Budget nur an, wenn es Probleme mit Seiten gibt, die nicht gecrawlt und indexiert werden, wenn ich erklären muss, warum sich jemand keine Sorgen machen sollte, oder wenn ich in den Crawl-Statistiken in der Google Search Console etwas sehe, das mir Sorgen bereitet.
Hast du Fragen? Lass es mich auf Twitter wissen.


