


Comment les moteurs de recherche fonctionnent-ils ?

Par Joshua Hardwick
Ancien chef du contenu chez Ahrefs


Les moteurs de recherche fonctionnent en explorant des milliards de pages à l’aide de crawlers web. Aussi appelés spiders ou bots, les crawlers explorent le web et suivent des liens pour trouver de nouvelles pages. Ces dernières sont ensuite ajoutées à un index dans lequel les moteurs de recherche (et même les assistants IA, comme ChatGPT) puisent leurs résultats.
Il est essentiel de comprendre comment fonctionnent les moteurs de recherche si vous faites du SEO. Après tout, on ne peut pas optimiser efficacement ce qu’on ne comprend pas.
C’est ce que vous apprendrez dans ce guide.
Notions de base des moteurs de recherche
Commençons par découvrir ce que sont les moteurs de recherche, pourquoi ils existent et comment ils gagnent de l’argent.
Que sont les moteurs de recherche ?
Les moteurs de recherche sont des bases de données consultables de contenu web. Ils sont composés de deux parties principales :
Quel est l’objectif des moteurs de recherche ?
Chaque moteur de recherche vise à fournir aux utilisateurs les meilleurs résultats et les plus pertinents. C’est en partie ainsi qu’ils gagnent des parts de marché.
Comment les moteurs de recherche gagnent-ils de l’argent ?
Les moteurs de recherche comportent deux types de résultats de recherche :
Chaque fois que quelqu’un clique sur un résultat de recherche payant, l’annonceur paie le moteur de recherche. C’est ce qu’on appelle de la publicité au paiement par clic (PPC), et c’est pourquoi la part de marché est essentielle. Plus il y a d’utilisateurs, plus il y a de clics sur les publicités et de revenus.
Les moteurs de recherche gagnent de l’argent grâce aux publicités

Comment les moteurs de recherche conçoivent-ils leurs index ?
Chaque moteur de recherche a son propre processus pour concevoir un index de recherche. Une version simplifiée du processus utilisé par Google est présentée ci-dessous.1
Comment Google conçoit-il son index de recherche ?

Voyons cela en détail.
URL
Pour commencer, Google découvre une liste d’URL connues de nombreuses manières, mais les trois plus courantes sont :
- À partir des backlinks. Google possède un index de centaines de milliards de pages web.2 Si quelqu’un crée un lien vers une nouvelle page depuis une page connue, Google peut la repérer.
- À partir des sitemaps. Les sitemaps permettent à Google de savoir quelles pages et quels fichiers de votre site vous jugez importants.3
- À partir des soumissions d’URL. Google permet aux propriétaires de sites de demander l’exploration d’URL individuelles dans Google Search Console.
Exploration
Traitement et rendu
Le traitement est l’étape où Google s’efforce de comprendre et d’extraire les informations clés des pages explorées. Pour cela, il doit rendre la page, c’est-à-dire exécuter le code de la page pour comprendre comment elle apparaît aux utilisateurs.
Personne en dehors de Google ne connaît tous les détails de ce processus, mais ce n’est pas important. Tout ce que nous devons vraiment savoir, c’est qu’il implique d’extraire des liens et de stocker du contenu pour l’indexation.
Indexation
L’indexation consiste à ajouter à l’index de recherche les informations traitées à partir des pages explorées sur le web.
L’index de recherche est ce que vous consultez lorsque vous utilisez un moteur de recherche. Les assistants IA comme ChatGPT, Claude et Gemini utilisent aussi des index de recherche pour trouver des pages web. C’est pourquoi il est si important d’être indexé dans les principaux moteurs de recherche comme Google et Bing. Les utilisateurs ne peuvent pas vous trouver si vous n’êtes pas présent dans l’index.
Le saviez-vous ?
Google détient 91,43 % du marché des moteurs de recherche. Il peut vous envoyer plus de trafic que les autres moteurs de recherche, puisque c’est celui que la plupart des internautes utilisent.5
Comment les moteurs de recherche classent-ils les pages ?
Découvrir, explorer le web et indexer du contenu ne constituent que la première partie du puzzle. Les moteurs de recherche doivent aussi pouvoir classer les résultats correspondants lorsqu’un utilisateur lance une recherche. C’est le rôle des algorithmes de recherche.
Que sont les algorithmes de recherche ?
Les algorithmes de recherche sont des formules qui associent et classent les résultats pertinents issus de l’index. Google utilise de nombreux facteurs dans ses algorithmes.
Principaux facteurs de classement de Google
Personne ne connaît tous les facteurs de classement de Google, car il ne les a pas divulgués. Cependant, nous en connaissons quelques-uns, essentiels. Examinons-en certains.
Backlinks
Les backlinks sont des liens d’une page sur un site web vers un autre. Il s’agit de l’un des facteurs de classement les plus importants de Google.6 C’est probablement pourquoi nous avons constaté une forte corrélation entre les domaines référents et le trafic organique dans notre étude portant sur plus d’un milliard de pages.7
La corrélation entre les domaines référents et le trafic de recherche
Basé sur une étude de plus d’un milliard de pages dans l’index Content Explorer d’Ahrefs.
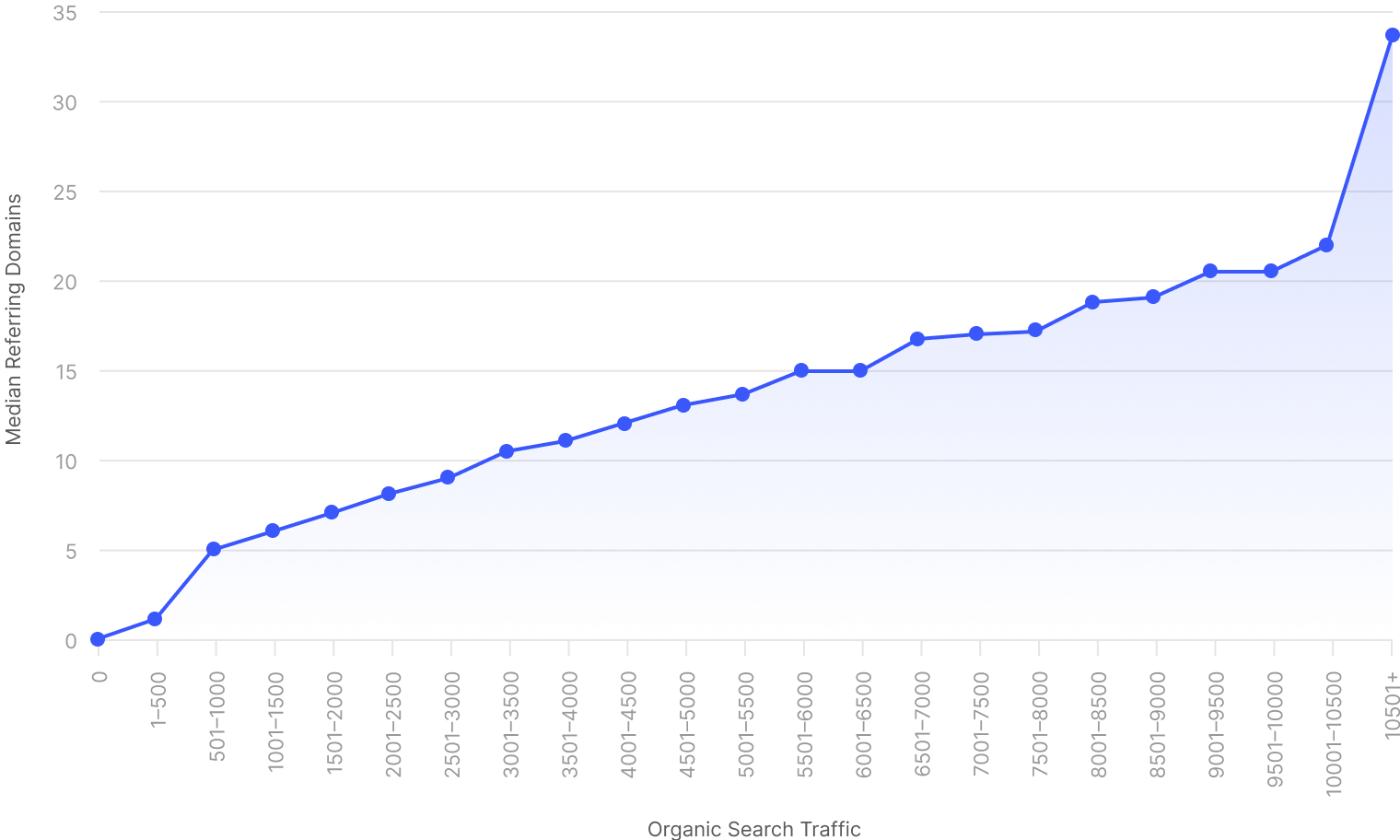
Ce n’est pas seulement une question de quantité, la qualité compte aussi. Les pages qui comportent quelques backlinks de haute qualité surpassent souvent celles qui ont de nombreux backlinks de faible qualité.
Vous pouvez vérifier les backlinks vers votre site web dans Ahrefs.
Créez un compte Ahrefs Gratuit, saisissez votre domaine dans Site Explorer, puis consultez le rapport Backlinks.
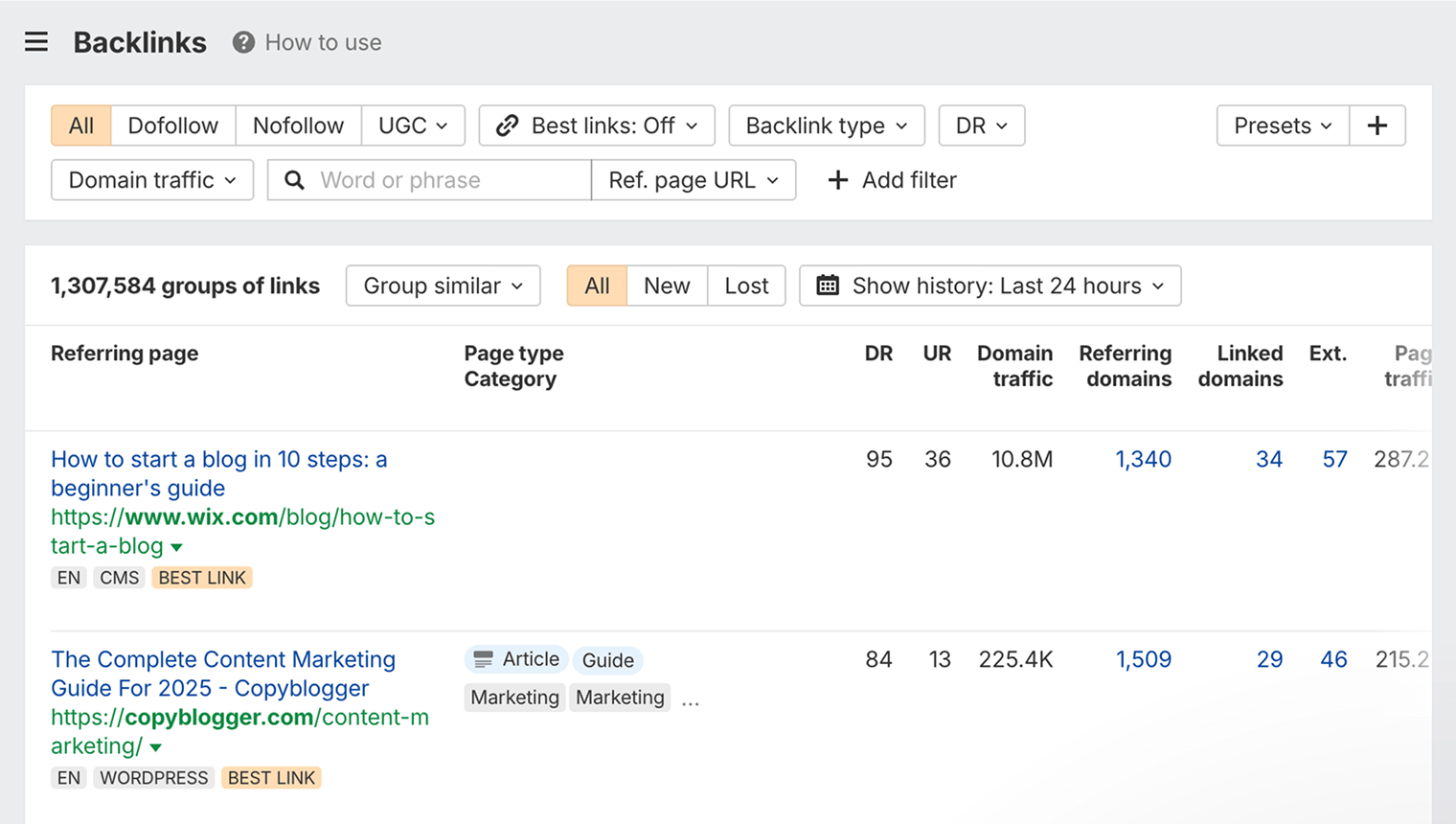
Notre crawler est le cinquième plus actif sur le web,8 vous verrez donc ici une vue assez complète de vos backlinks.
Pertinence
La pertinence correspond à l’utilité d’un résultat donné pour l’internaute. Google a de nombreuses façons de la déterminer. Au niveau le plus basique, il recherche des pages contenant les mêmes mots-clés que la requête de recherche. Il examine également les données d’interaction pour voir si d’autres personnes ont trouvé le résultat utile.9
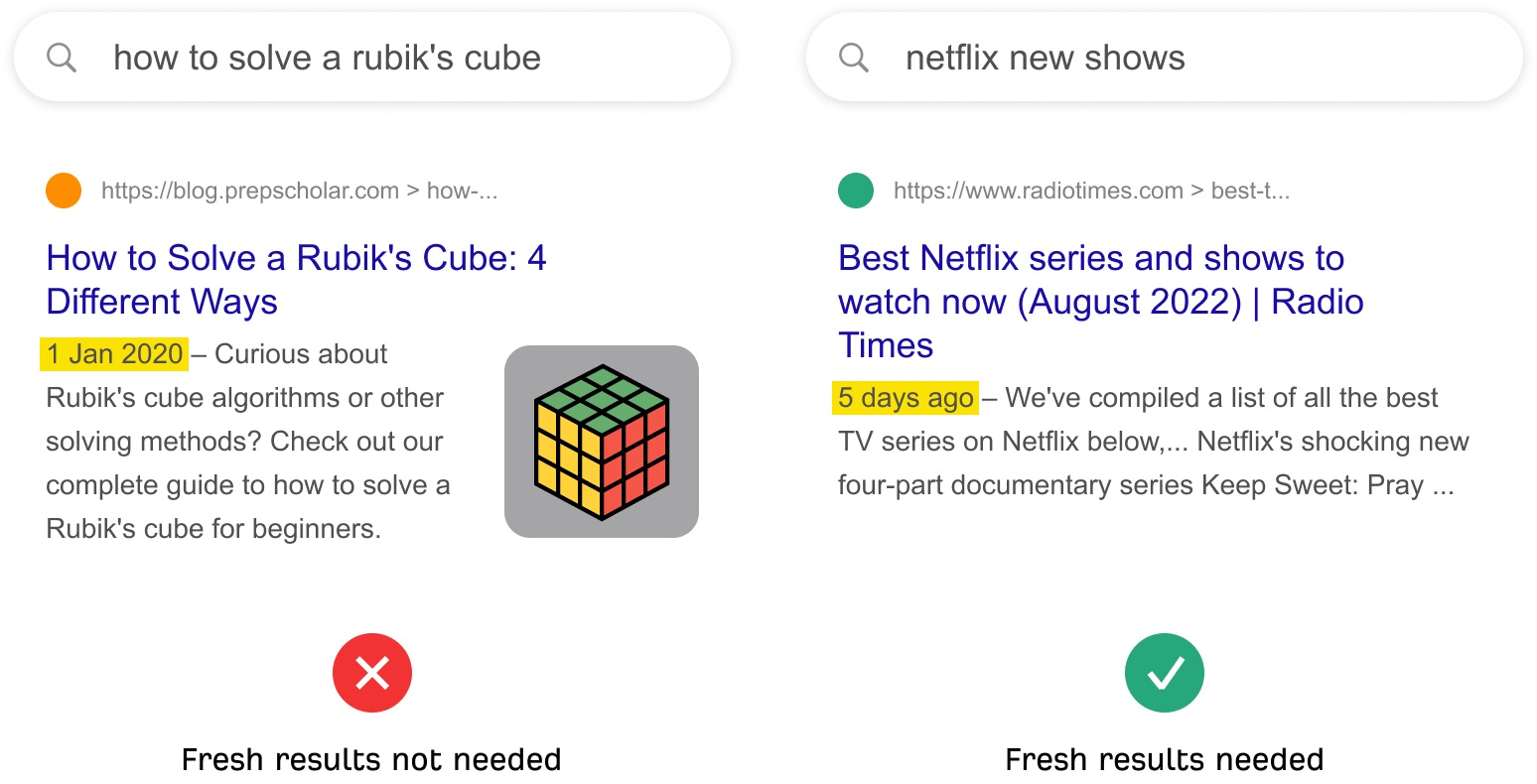
Actualisation
L’actualisation est un facteur de classement qui dépend de la requête. Elle est plus importante pour les recherches qui nécessitent des résultats récents.9 C’est pourquoi vous voyez un résultat en tête récemment publié pour « nouvelle série netflix », mais pas pour « comment résoudre un rubik’s cube ».
L’actualisation est un facteur de classement qui dépend de la requête
Vitesse des pages
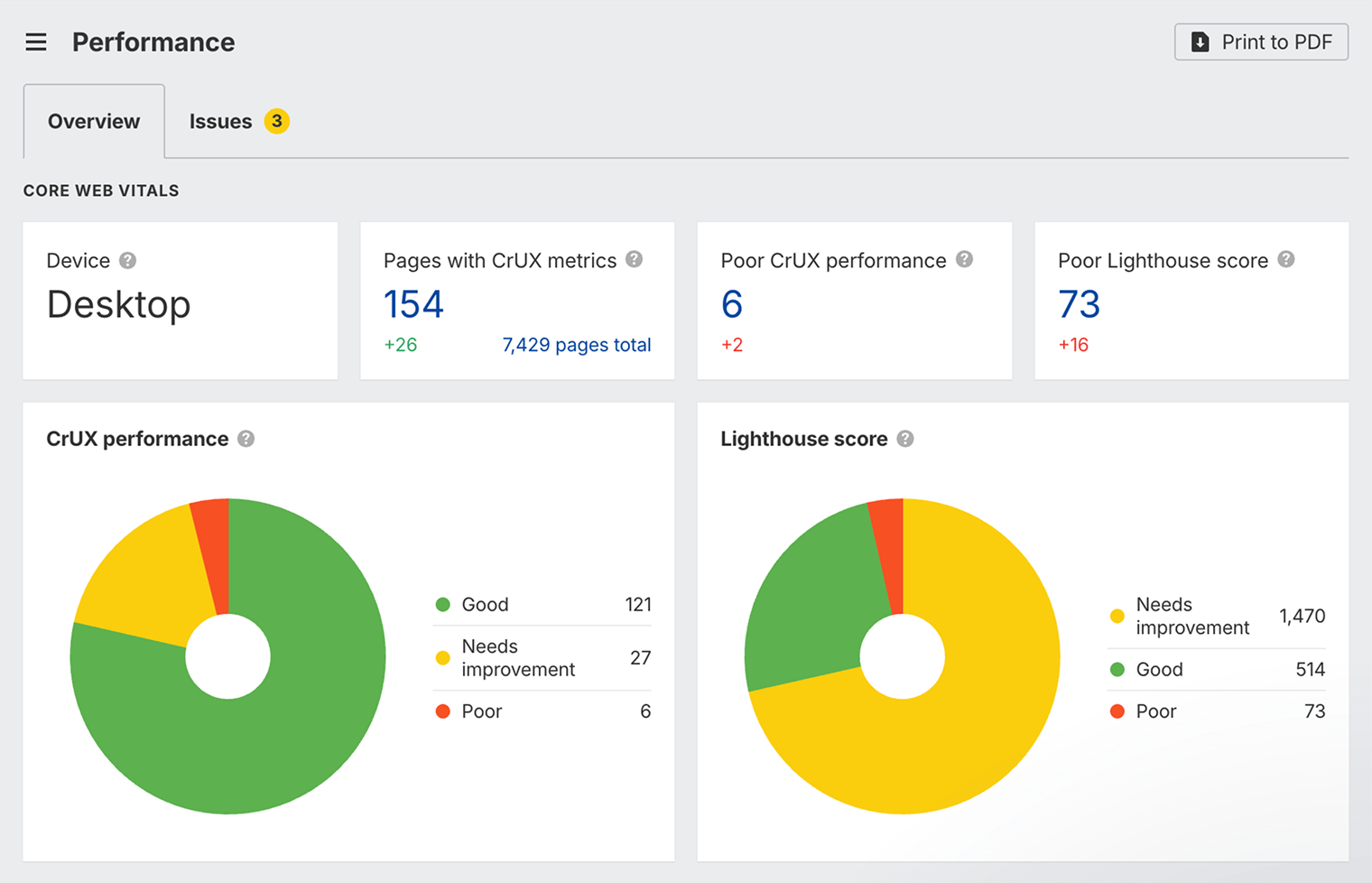
La vitesse de page est un facteur de classement sur ordinateur et mobile.10 11 Mais il s’agit davantage d’un facteur de classement négatif que positif. En effet, elle pénalise surtout les pages les plus lentes plutôt que d’avantager les pages très rapides.
Vous pouvez consulter la vitesse de votre page dans Ahrefs.
Créez un compte Ahrefs Gratuit, explorez votre site web avec Site Audit d’Ahrefs, puis consultez le rapport Performances. En général, moins vous voyez de rouge, mieux c’est.
Compatibilité mobile
La compatibilité mobile est un facteur de classement sur mobile et sur ordinateur depuis le passage de Google à l’indexation orientée mobile en 2019.12
Comment les moteurs de recherche personnalisent-ils les résultats ?
Google adapte les résultats de recherche à chaque utilisateur. Pour cela, il utilise des informations telles que votre localisation, votre langue et votre historique de recherche.9 Regardons cela de plus près.
Emplacement
Google utilise votre localisation pour personnaliser les résultats de recherche avec une intention locale. C’est pourquoi tous les résultats pour « restaurant italien » proviennent de restaurants locaux ou les concernent. Google sait que vous avez peu de chances de prendre l’avion jusqu’à l’autre bout du monde juste pour déjeuner.
Langue
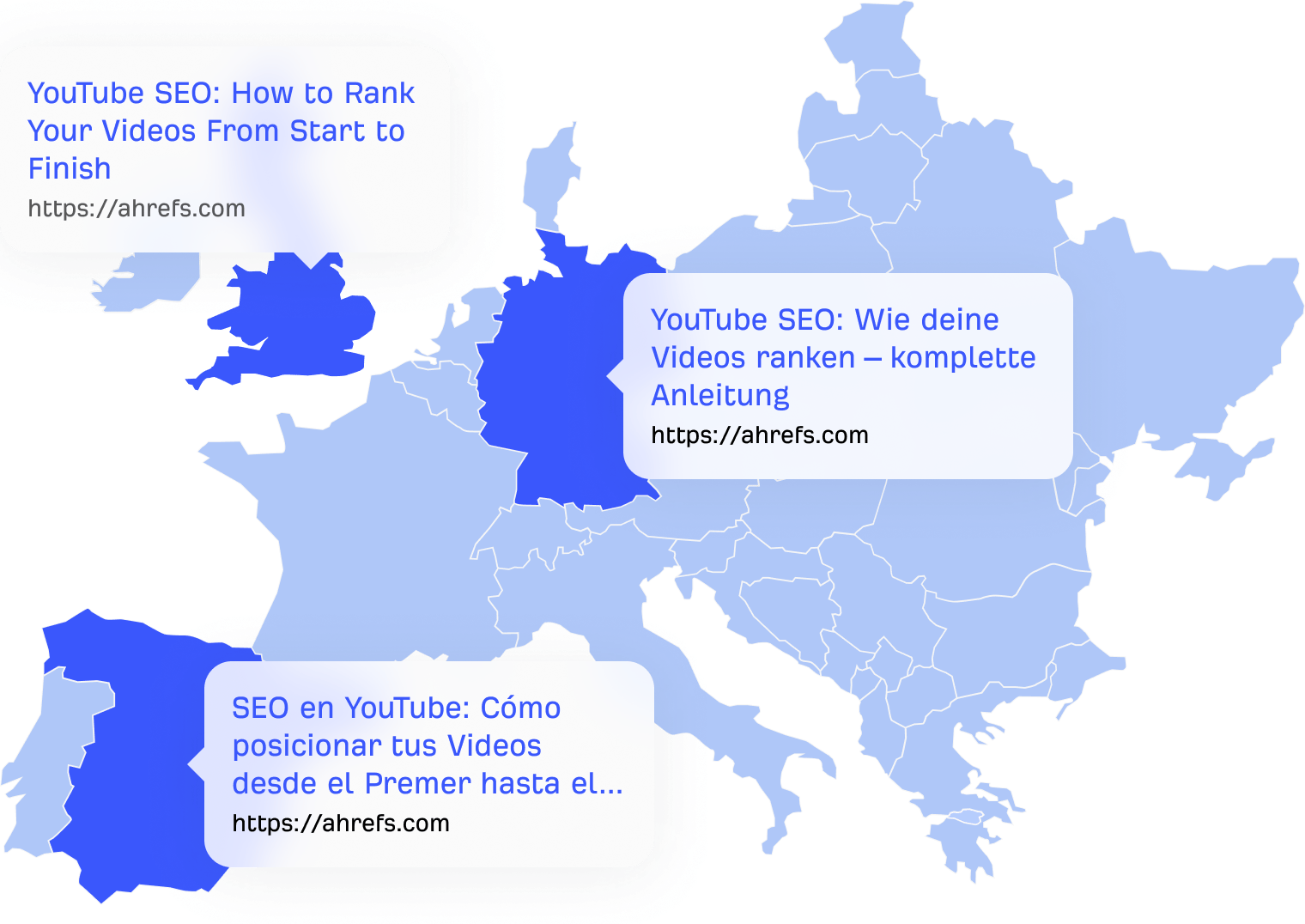
Google sait qu’il ne sert à rien d’afficher des résultats en anglais à des utilisateurs espagnols. C’est pourquoi il classe des versions localisées du contenu (si elles sont disponibles) pour les utilisateurs qui parlent différentes langues.
Google classe différentes versions de résultats pour différentes langues
Historique de recherche
Google enregistre ce que vous faites et les endroits où vous allez afin de vous offrir une expérience de recherche plus personnalisée.13 Vous pouvez désactiver cette option, mais la plupart des personnes ne le font probablement pas.
Points clés à retenir
- Un moteur de recherche comporte deux parties principales : l’index et les algorithmes.
- Pour concevoir son index, il explore des pages connues et suit les liens pour en trouver de nouvelles.
- L’objectif des algorithmes de recherche est de renvoyer les meilleurs résultats et les plus pertinents.
- La qualité des résultats de recherche est importante pour développer votre part de marché.
- Personne ne connaît tous les facteurs de classement de Google pour les résultats organiques.
- Les principaux facteurs de classement incluent les backlinks, la pertinence et l’actualisation.
- Google personnalise ses résultats en fonction de votre localisation, de votre langue et de votre historique de recherche.
Références
- « Comprendre les bases du SEO JavaScript ». Google. Consulté le 16 août 2022.
- « Organisation de l’information — Comment la recherche Google fonctionne-t-elle ? ». Google. Consulté le 16 août 2022.
- « En savoir plus sur les sitemaps ». Google. Consulté le 16 août 2022.
- « Googlebot ». Google. Consulté le 16 août 2022.
- « Part de marché des moteurs de recherche dans le monde ». Statcounter. Consulté le 16 août 2022.
- « Google Q&R+ #Mars ». YouTube. Consulté le 16 août 2022.
- « 96,55 % du contenu ne reçoit aucun trafic de Google. Voici comment faire partie des 3,45 % restants ». Ahrefs. Consulté le 1er décembre 2023.
- « CloudFlare Radar ». CloudFlare. Consulté le 16 août 2022.
- « Classement des résultats de recherche — Comment la recherche Google fonctionne-t-elle ? ». Google. Consulté le 16 août 2022.
- « Utiliser la vitesse du site dans le classement de recherche sur le web ». Google. Consulté le 16 août 2022.
- « Utiliser la vitesse de page dans le classement de recherche sur mobile ». Google. Consulté le 16 août 2022.
- « Bonnes pratiques de l’indexation orientée mobile ». Google. Consulté le 16 août 2022.
- « Trouver et contrôler votre activité sur le web et les applications ». Google. Consulté le 16 août 2022.
Ancien chef du contenu chez Ahrefs (ou, en d’autres termes, je dois m’assurer que chaque article de blog que nous publions est ÉPIQUE).
Maîtriser le SEO étape par étape
Comment les moteurs de recherche fonctionnent-ils ?
Avant de commencer à apprendre le SEO, vous devez comprendre le fonctionnement des moteurs de recherche.
SEO de base
Apprenez à configurer votre site Web pour le succès du SEO et à vous familiariser avec les quatre principales facettes du SEO.
Recherche de mots-clés
Le point de départ du SEO est de comprendre ce que recherchent vos clients cibles.
Contenu SEO
Apprenez à créer du contenu qui se classe dans les moteurs de recherche.
SEO on-page
C'est là que vous optimisez vos pages pour aider les moteurs de recherche à les comprendre.
Link Building
Apprenez à créer du contenu qui se classe dans les moteurs de recherche.
SEO technique
Prévenez les problèmes techniques qui empêchent Google d’accéder à votre site web et de le comprendre.
Référencement local
Découvrez comment améliorer votre visibilité dans les résultats de recherche locale et attirer plus de clients dans votre zone.
L’impact de l’IA sur le SEO
Vous ne pouvez pas parler de SEO aujourd’hui sans mentionner l’IA générative.
Comment les moteurs de recherche IA fonctionnent-ils ?
Découvrez précisément comment les moteurs de recherche IA comme ChatGPT génèrent leurs réponses et choisissent les marques et produits à mentionner.