But how do you know if your site’s in Google’s index, and how do you get it there if not?
Google only indexes the pages it considers valuable—not everything it discovers. To get your site indexed:
✅ Request indexing for your homepage and other important pages
✅ Submit your sitemap in Google Search Console
✅ Optimize site structure and add internal links to important pages
✅ Get some backlinks to establish authority
Timeline: New sites: days to weeks. Established sites: hours to days.
Not working? Jump to troubleshooting technical issues, crawl problems, or content quality concerns.
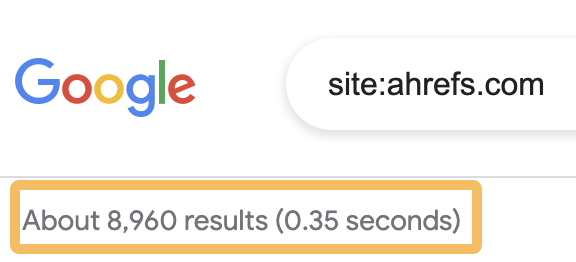
If you want a rough idea of how many pages on your website Google has indexed, go to Google, search for site:yourwebsite.com and look at the number of results below the search bar.
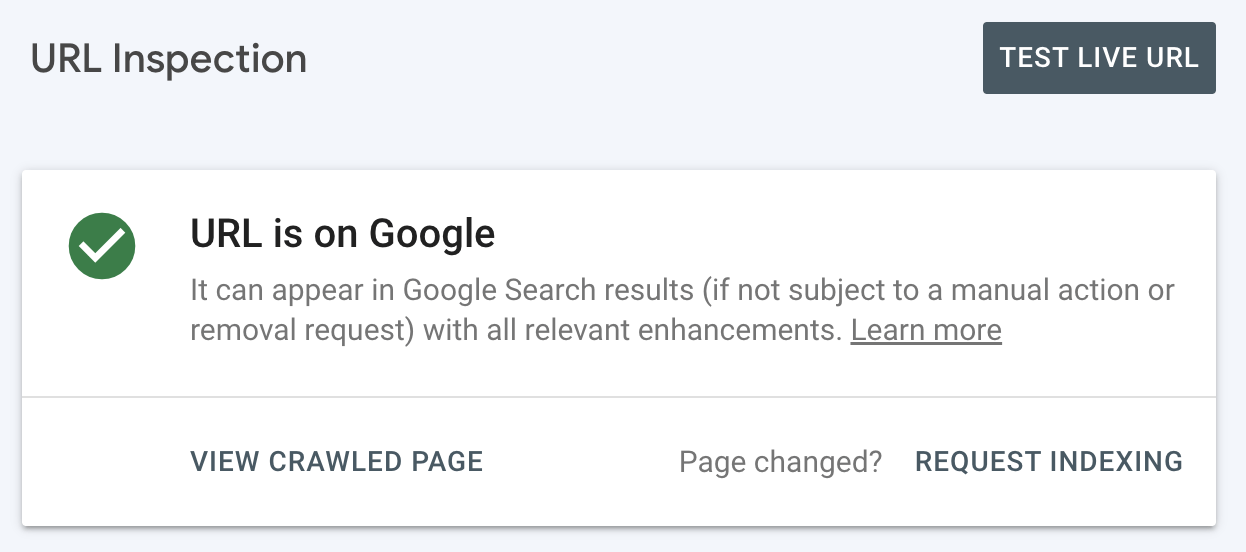
If you want to check whether a particular page is indexed, you’ll get the most accurate results using the URL Inspection tool in Google Search Console.
For indexed pages, you’ll see this:
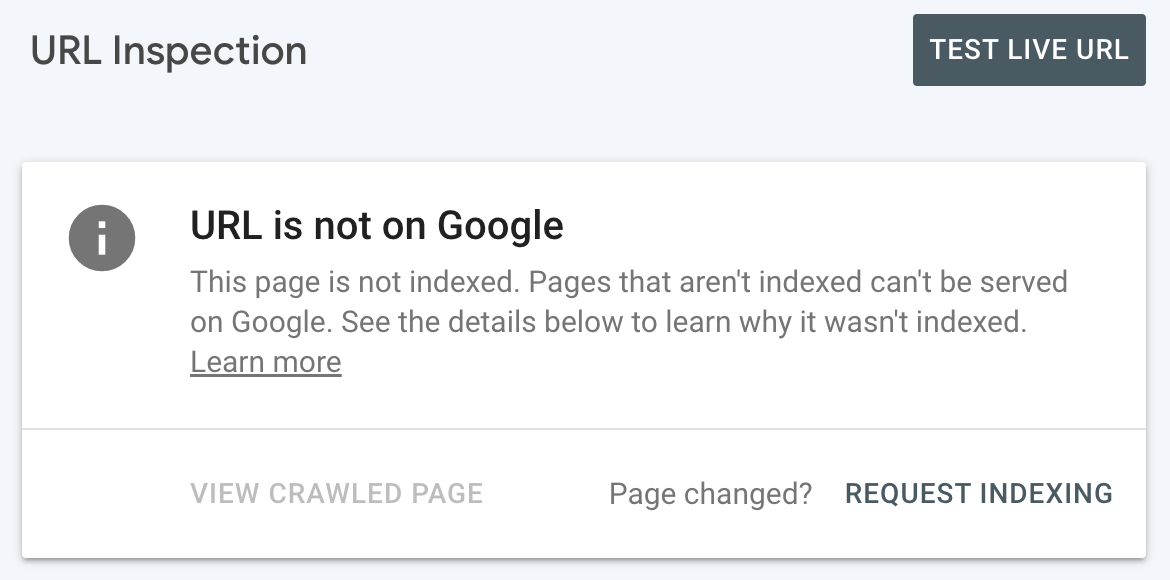
For pages that aren’t indexed, you’ll see this:
Does Google automatically index all pages?
No. Google crawls billions of pages but doesn’t index everything it finds.
It only indexes pages it considers valuable enough to show in search results. Even if Googlebot discovers your page, it may choose not to crawl and index it if the content is:
- Low quality or thin
- Duplicates or near-duplicates of other pages
- Unhelpful to searchers
- Part of a low-authority site with limited crawl budget
If you have valuable content for searchers, getting indexed tends to be easy enough. You just need to make sure Google can find your pages, and that you’re signaling their importance. Here are four steps you can take to do that.
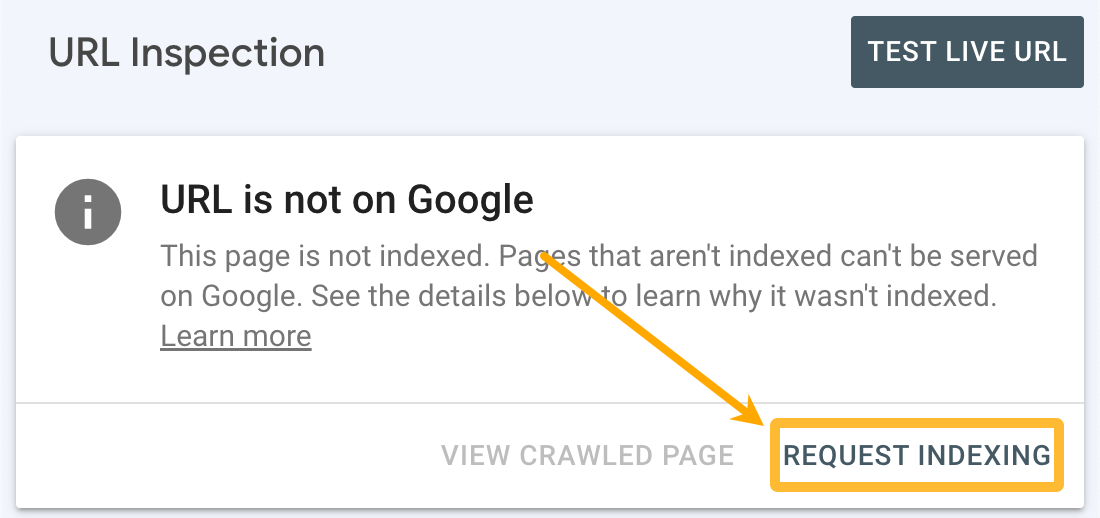
1. Request indexing for your homepage
Sign up for Google Search Console, add your property, plug your homepage into the URL Inspection tool, and hit “Request indexing.” As long as your site structure is sound (more on this shortly), Google will be able to find (and hopefully index) all the pages on your site.
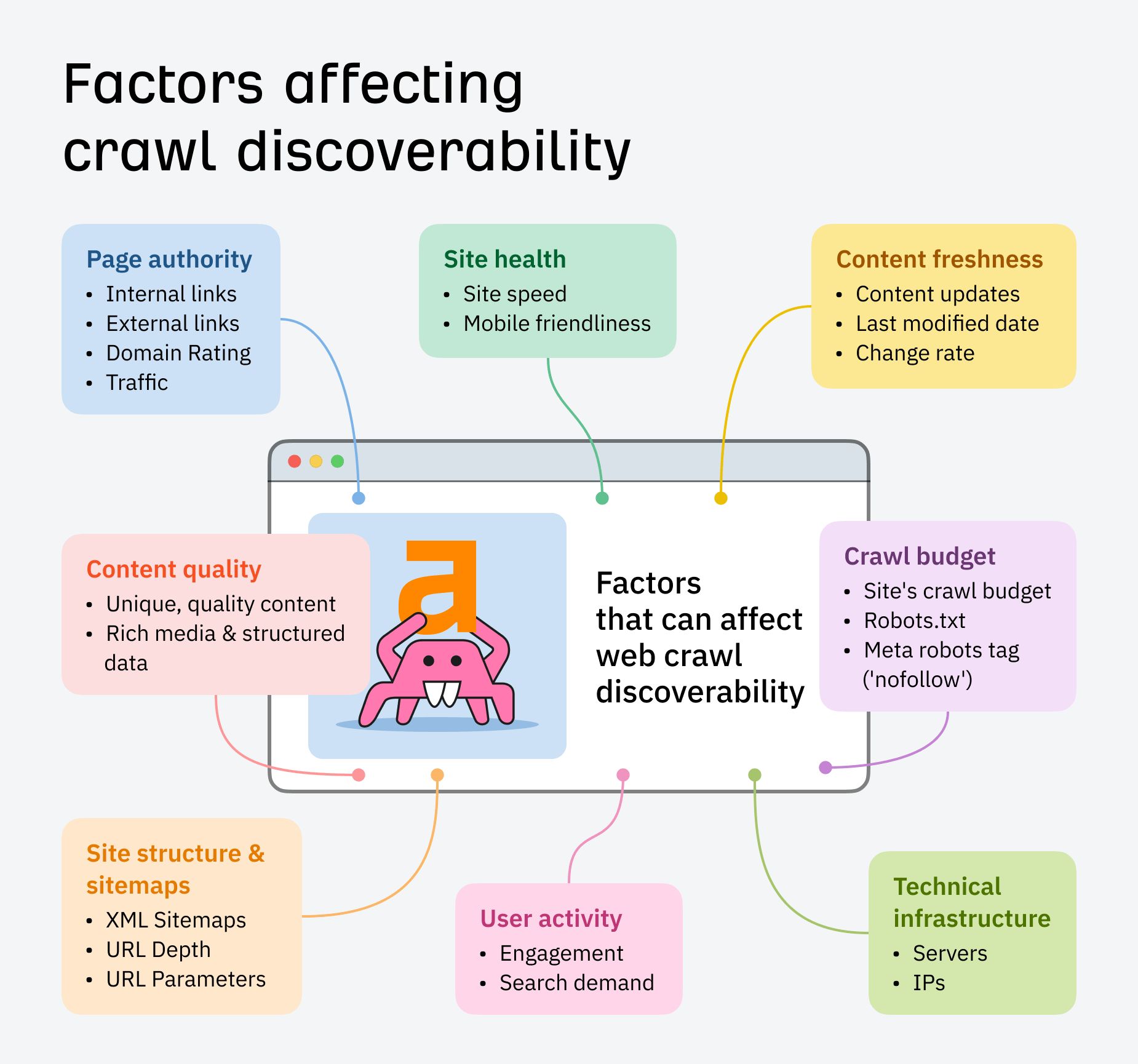
How long does it take to get indexed?
For a new website, it can take anywhere from a few days to several months for Google to index your content, while new pages on an established site can be indexed in hours.
Factors like your website’s popularity, authority, content quality, structure, and technical SEO all play a part in how quickly your page gets indexed.
Google’s crawler, Googlebot, also tends to crawl fresh pages more often than it does static pages.
But, it’s important not to manipulate this by updating timestamps without making genuine content improvements.
Google has been known to penalize sites that do this.
2. Create and submit a sitemap to Google
A sitemap tells Google where to find the pages you consider important on your site.
Most website platforms like Wix, Squarespace, and Shopify create a sitemap for you automatically. You can usually find this at yourdomain.com/sitemap.xml or yourdomain.com/sitemap_index.xml. If it’s not there, see if its location is listed in your robots.txt file at yourdomain.com/robots.txt.
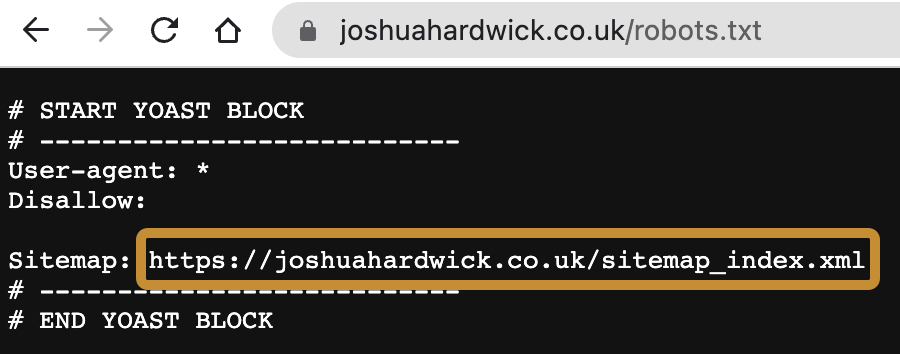
If you’re using WordPress, use a plugin like Yoast or Rank Math to create a sitemap. Don’t use the default sitemap created by WordPress as it tends to include a bunch of unimportant stuff you don’t want in there.
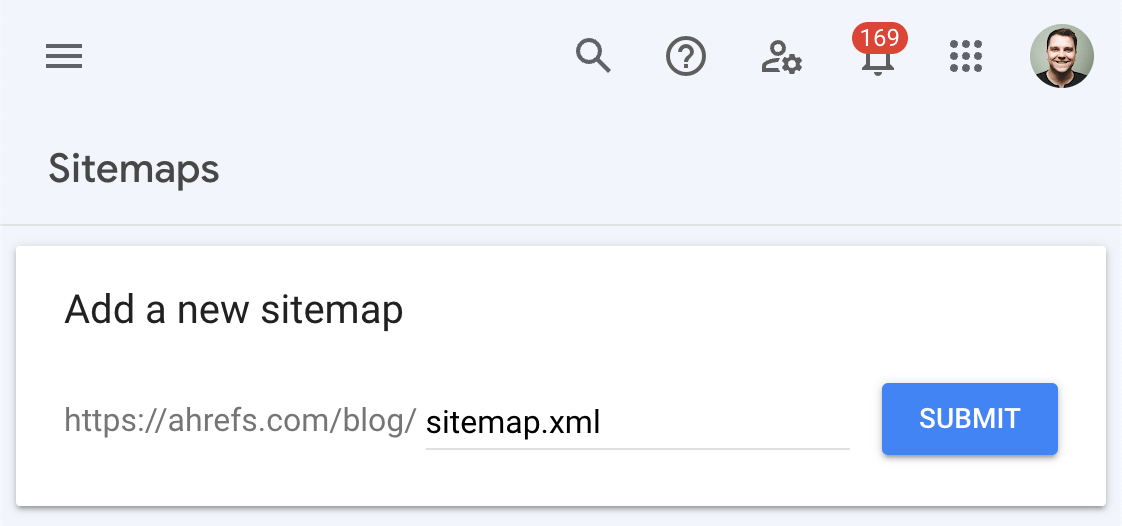
Once you have a sitemap created, go to the Sitemaps tab in Google Search Console, enter the sitemap URL, and hit “Submit.”
3. Structure your site properly
Search engines should be able to reach every important page on your website through internal links. If that’s not possible for a page, it’s known as an orphan page. Google is less likely to index these as they’re harder to find and have fewer signals that they’re important.
It’s up to you how you want to structure your site, but it’s common to use a pyramid structure:
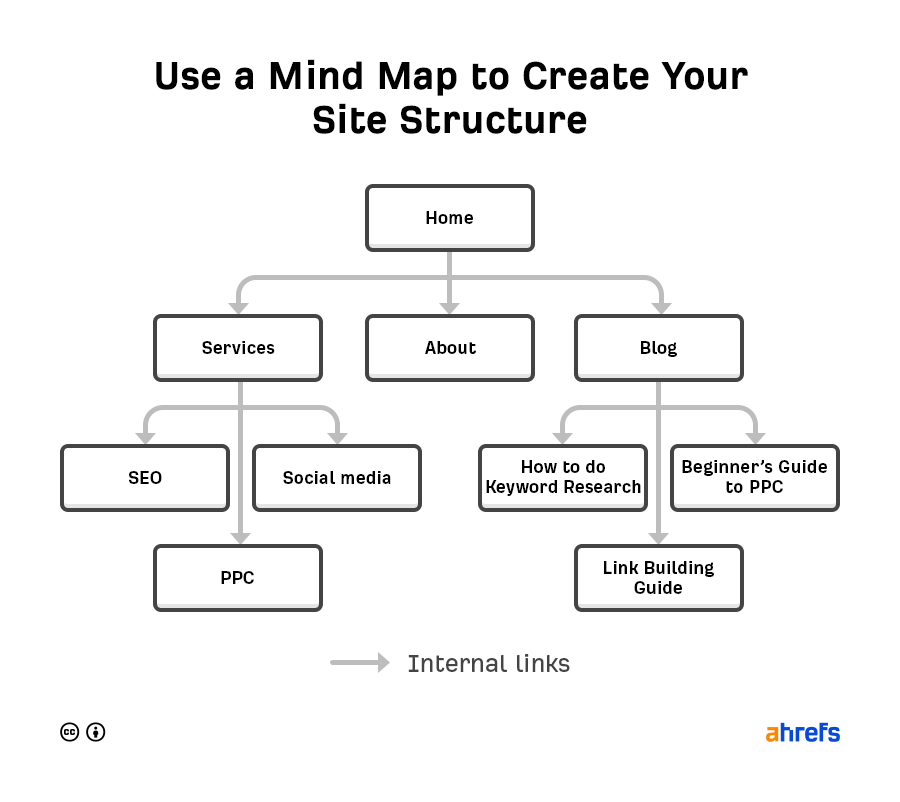
With this kind of site structure, each page has an internal link from at least one page above it in the pyramid. As long as your website platform automatically adds links to new content, no page should end up orphaned.
That said, mistakes can happen, so it’s worth setting up regular audits to check your site for orphan pages. Assuming that all your important pages are in your sitemap, it’s free and easy to do this with an Ahrefs Webmaster Tools (AWT) account.
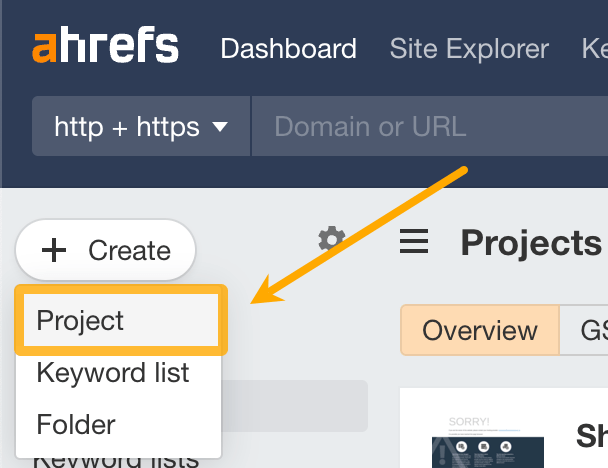
First, create a new project from your Ahrefs Dashboard:
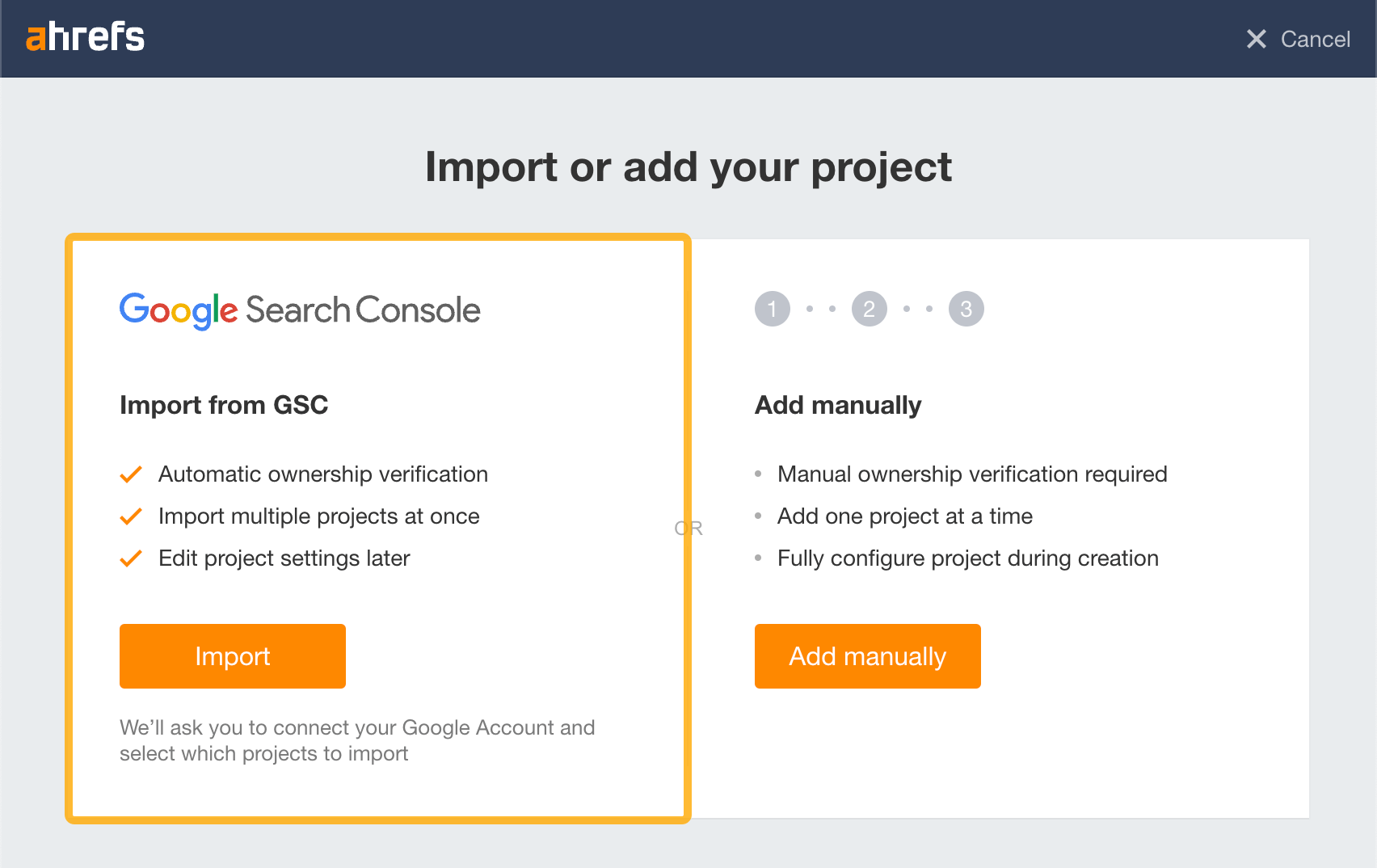
Second, click the option to import from Google Search Console:
Finally, choose your site and import the project with the default settings:
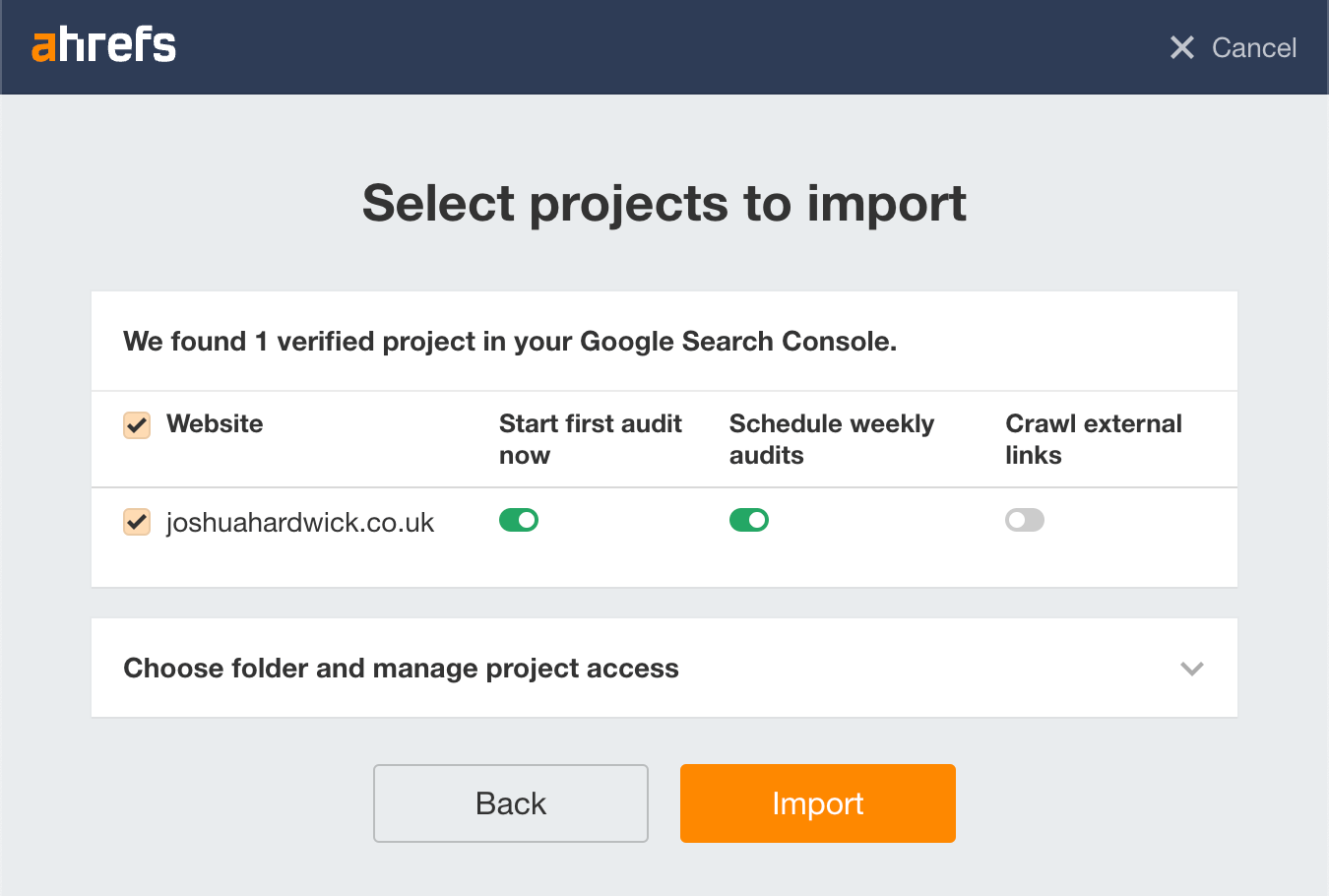
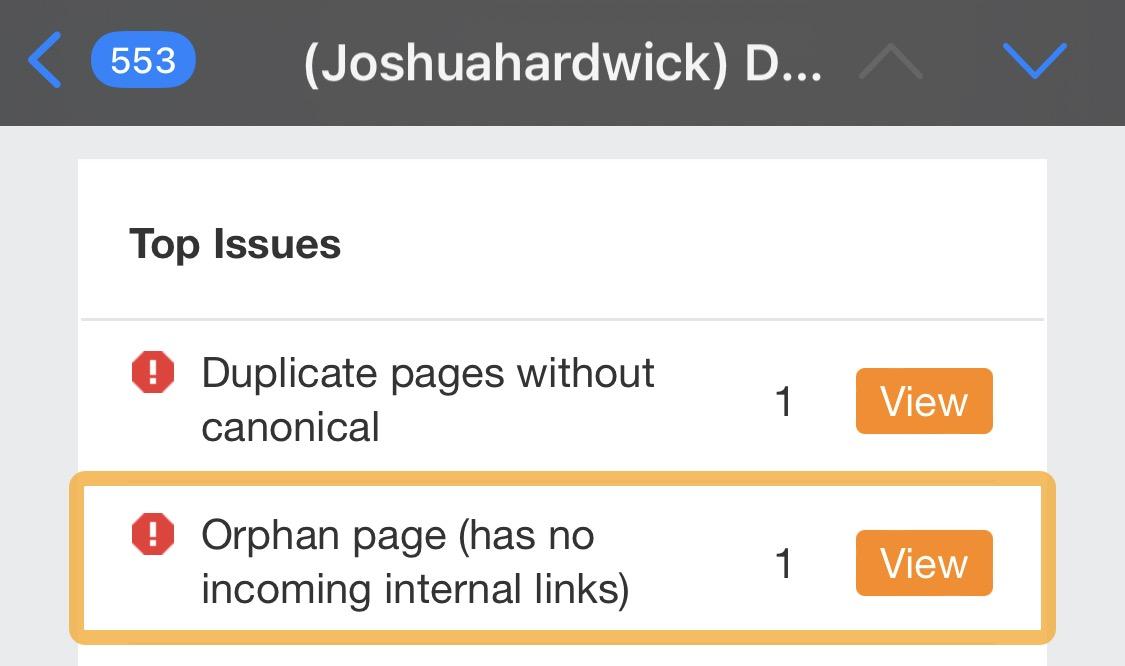
Ahrefs will now begin crawling your website and email you the results when complete. If you see the “Orphan page (has no incoming internal links)” error in that email, there are pages on your site lacking internal links that need to be incorporated into your site structure.
4. Build backlinks to your site
Backlinks signal to Google that the content on a website is valuable and deserves indexing.
If your website is new, the best starting point is to find your competitors’ backlinks and replicate the ones you can. These are typically links from:
- Directories
- Listicles that mention multiple competitors, but not you
- Guest posts, interviews and podcasts
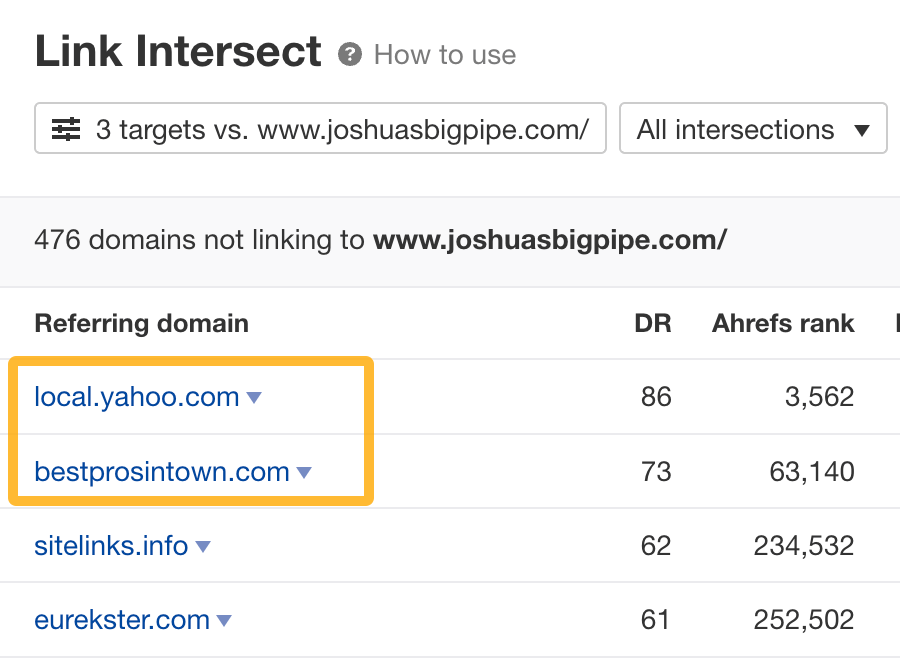
You can use the Link Intersect report in Ahrefs’ Site Explorer to find these.
For example, say you’re a plumber in New York City. If you plug in your website and a few competitors, it’ll show sites linking to one or more of them but not you. You can usually spot directories on this list quite easily.
Replicating these links is usually as straightforward as creating a free listing on the directory.
Learn more ways to replicate and build backlinks in the linked guides below.
If you’ve done everything above and Google still isn’t indexing some or all of the pages you’d expect them to, there’s probably a bigger issue so you need to run some checks.
Check for rogue noindex tags
Google can’t index pages that you tell them they’re not allowed to. You do this with a noindex robots meta tag or x-robots-tag HTTP header.
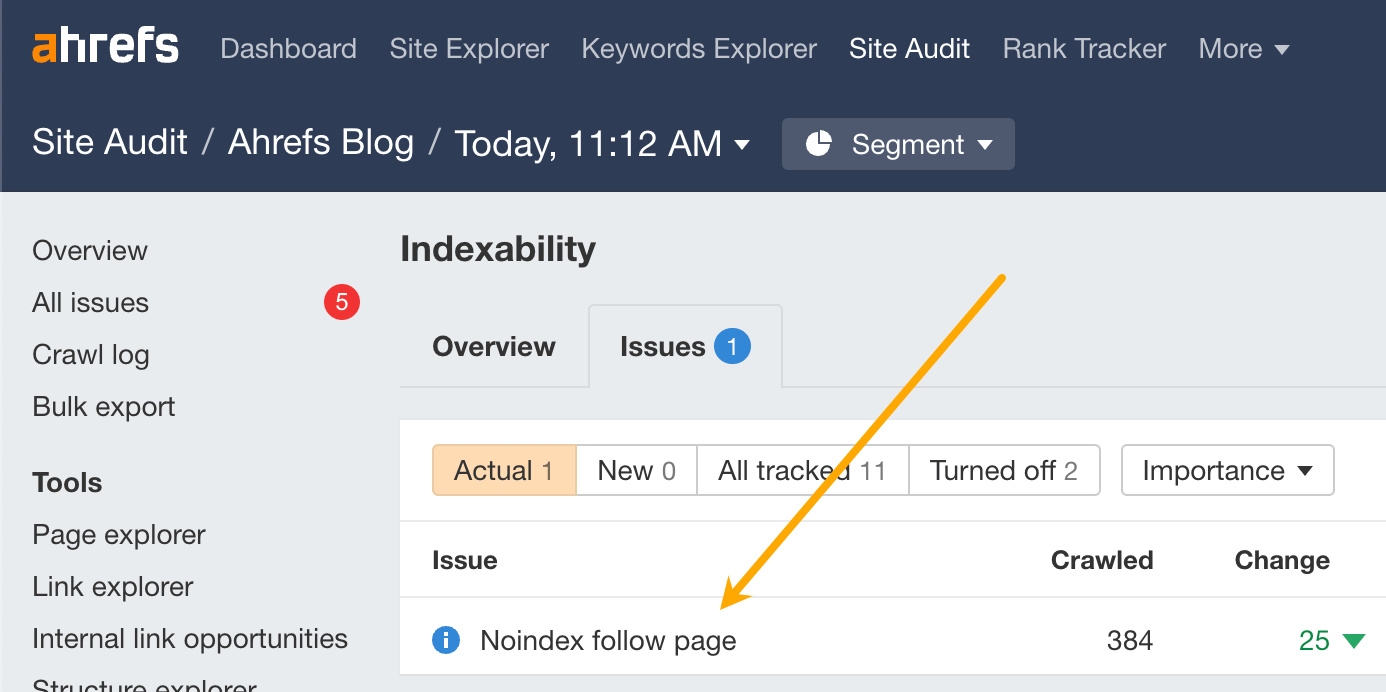
Don’t worry if you have no idea what any of that means. You can check for this issue in Site Audit with a free Ahrefs Webmaster Tools (AWT) account. Just head to the “Indexability” report and look for these issues:
- Noindex in HTML and HTTP header
- Noindex follow page
- Noindex and nofollow page
Google won’t be able to index any pages with these issues.
To see which pages they affect, click the number in the “Crawled” column. If you want any of these URLs indexed, you’ll need to remove the noindex directive from the HTML or HTTP header.
Check for manual actions and security issues
If your website or web page has a manual action or security issue, Google might not show it in the search results. You can check both of these things in Google Search Console. Just go to the Manual Actions report and Security Issues report.
Here’s what you want to see in both reports:

If you see anything different to that, seek expert help.
Check that your content is actually valuable for searchers
Google’s John Mueller is on record saying that the search engine never indexes all known URLs. They need to be “awesome and inspiring.”
You can find more potentially low-quality pages that might not be indexed using Site Audit.
Here’s the process:
- Go to the Page Explorer
- Filter for Indexable pages
- Click the Advanced filter
- Filter for pages with no keyword rankings and fewer than 300 words
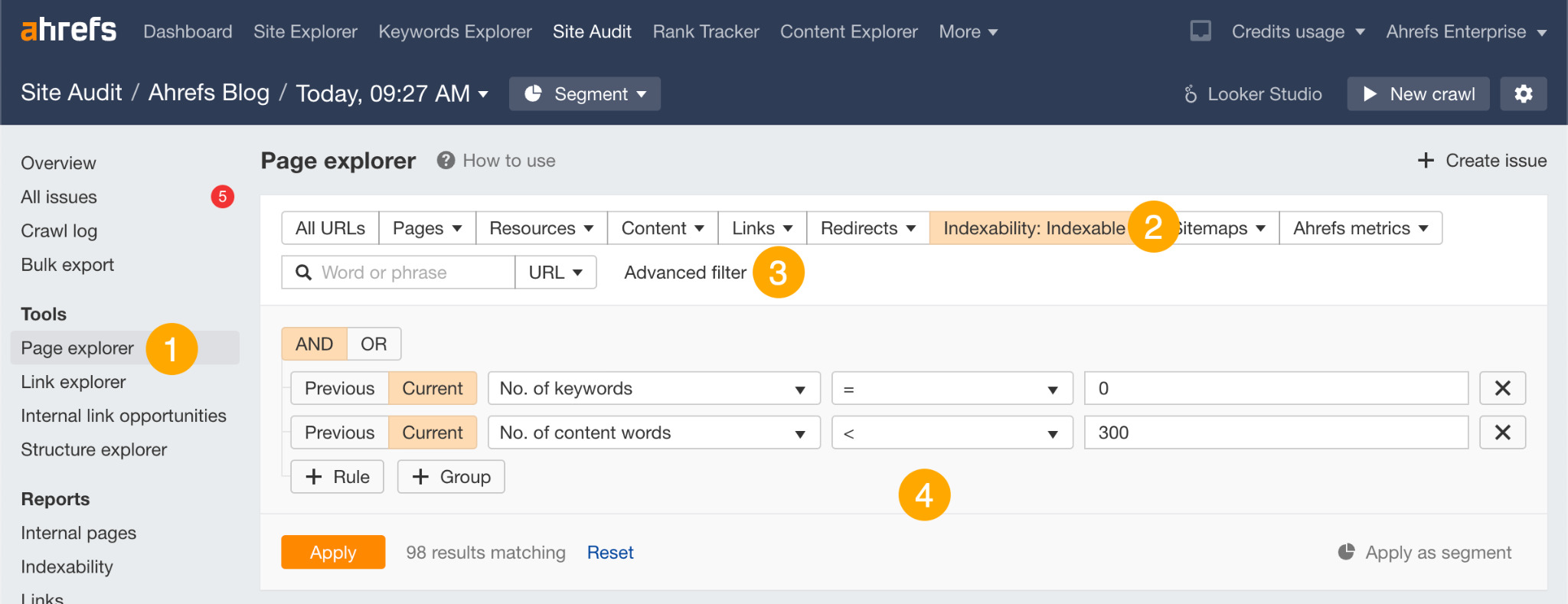
This will return “thin,” indexable pages that don’t rank for any keyword in the top 100.
Although it’s possible that some of these pages are indexed, they may as well not be because they’re not ranking for anything. This means that Google clearly doesn’t see them as valuable enough to send traffic.
If any of these pages are about topics with search volume, you’ll need to make them more valuable to get Google to show them in search results.
Check for indexable pages not in your sitemap
Sitemaps are one of the signals Google uses to understand which pages are important.
Excluding pages you want indexed from your sitemap is unlikely to be the only reason for Google not indexing them, but it’s still not a positive signal. You can find these pages in Site Audit. Just look for the “Indexable page not in sitemap” notice in the “All issues” report.

Fixing this issue depends on whether you want the affected pages indexed or not.
If you want them indexed, adjust your sitemap settings to include these pages. If you don’t want them indexed, add a noindex directive.
Check for crawl blocks in your robots.txt file
Google rarely indexes pages that it can’t crawl so if you’re blocking some important pages in robots.txt, they probably won’t get indexed.
To check if a page is blocked, you can use Google’s robots.txt tester. Just plug in your URL and hit “Test.”
If it’s all good, it’ll say “Allowed.”

If a page is blocked, it’ll say “Blocked” and highlight the line in your robots.txt file that’s causing the block.
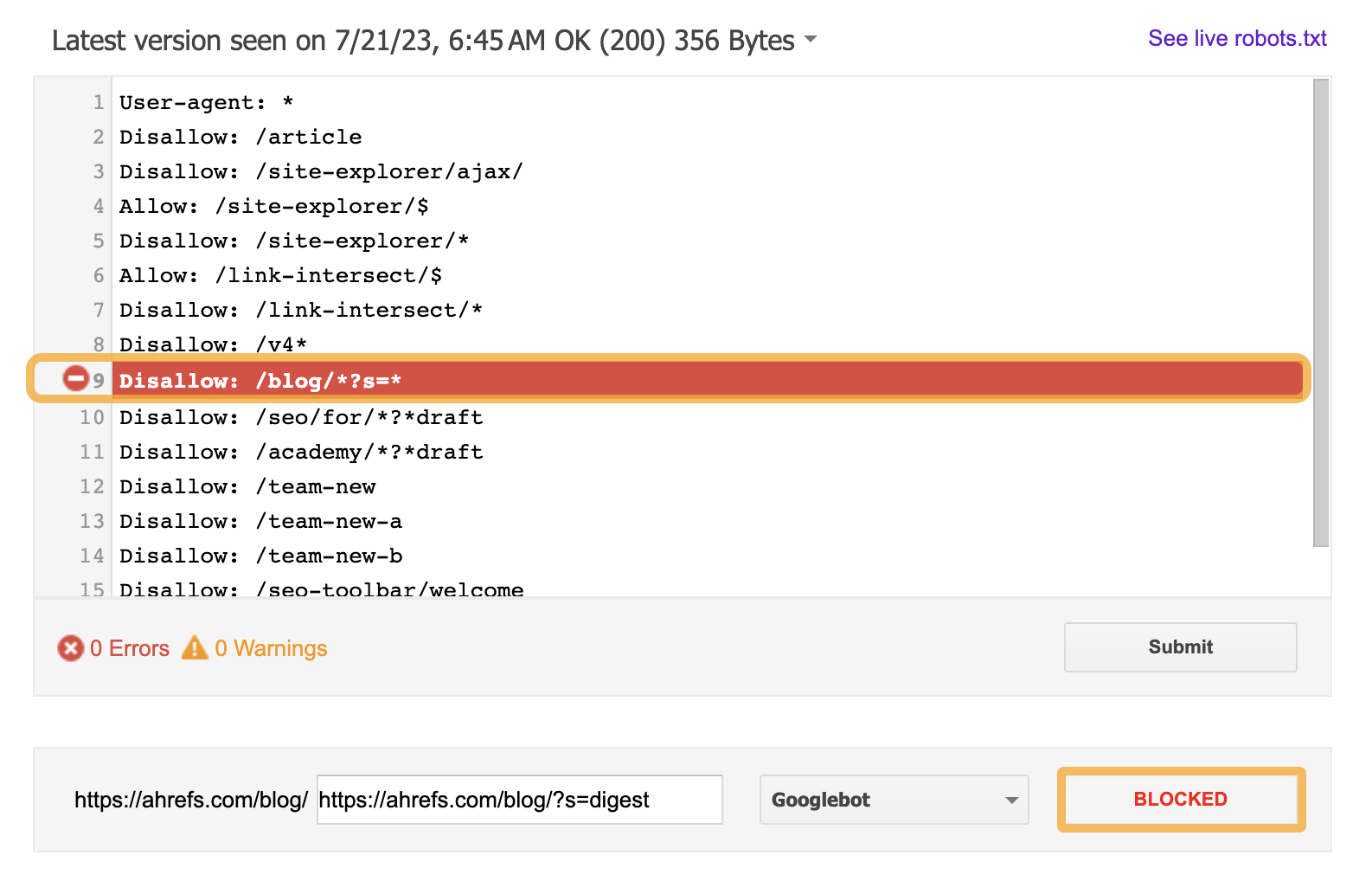
If you want a blocked page indexed, you should edit the directive in your robots.txt file to allow Google to crawl the page.
Check for rogue canonical tags
A canonical tag tells Google which version of a group of similar pages it should index. It looks something like this:
<link rel=“canonical” href=“/page.html”/>Most pages either have no canonical tag, or what’s called a self-referencing canonical tag. That tells Google the page itself is the preferred and probably the only version. In other words, you want this page to be indexed.
However, if your page has a rogue canonical tag, then it could be telling Google about a preferred version that doesn’t exist or that you don’t want indexed.
To check for a rogue canonical, use the URL inspection tool in Google Search Console. You’ll see an “Alternative page with canonical tag” warning if the canonical points to another page.
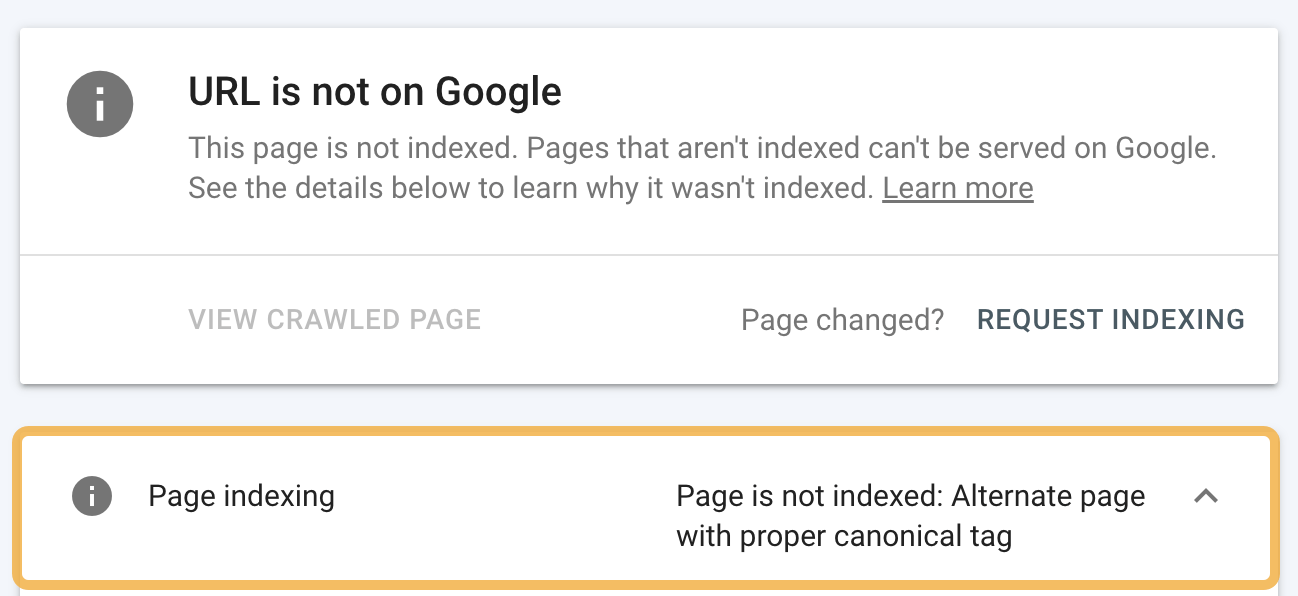
If this shouldn’t be there, and you want to index the page, remove the canonical tag.
Another trick is to look for the “Non-canonical page in sitemap” error in Ahrefs’ Site Audit. In these cases, you’re sending conflicting signals to Google. That’s not good if you want pages indexed.

You should also aim to fix issues with duplicate content because Google is unlikely to index duplicate or near-duplicate pages. Use the Duplicates report in Site Audit to check for these issues.
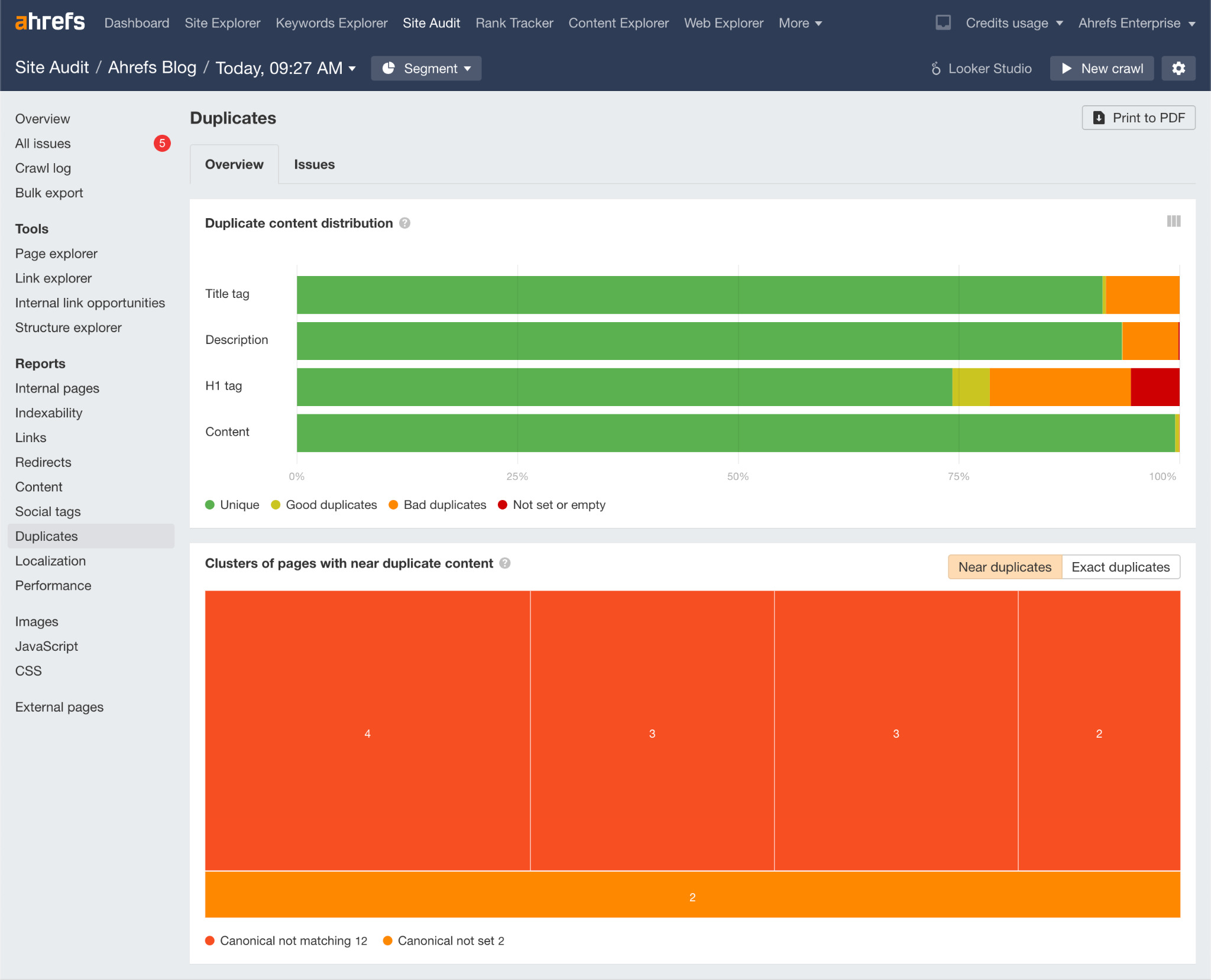
Learn more about how to fix these issues in our guide to duplicate content.
Check for nofollow internal links
Nofollow links are links with a rel=“nofollow” tag. Google may or may not crawl them, so it’s best not to use them.
Finding them is easy enough. Just go to the Links report in Site Audit and look for the “Page has nofollow incoming internal links only” warning.

Remove the nofollow tag from these internal links, assuming that you want Google to index the page. If not, either delete the page or noindex it.
Check for internal link opportunities
Internal links do more than help Google discover new pages. They also help to boost their PageRank and signal their importance. By adding more relevant internal links to important pages, you may be able to improve your chances of Google indexing (and ranking) them.
Here’s a super quick way to find opportunities:
- Head to the Internal Link Opportunities report in Site Audit
- Drop your URL into the search bar, and make sure the drop down is set to “Target page”
- Find internal link opportunities from “Source pages” that don’t already link to your target page
- Publish them instantly, without dev support, using Ahrefs’ Patches feature
For example, if we search for mentions of “SEO tips” on pages that don’t already link to our list of SEO tips, we get 67 results:
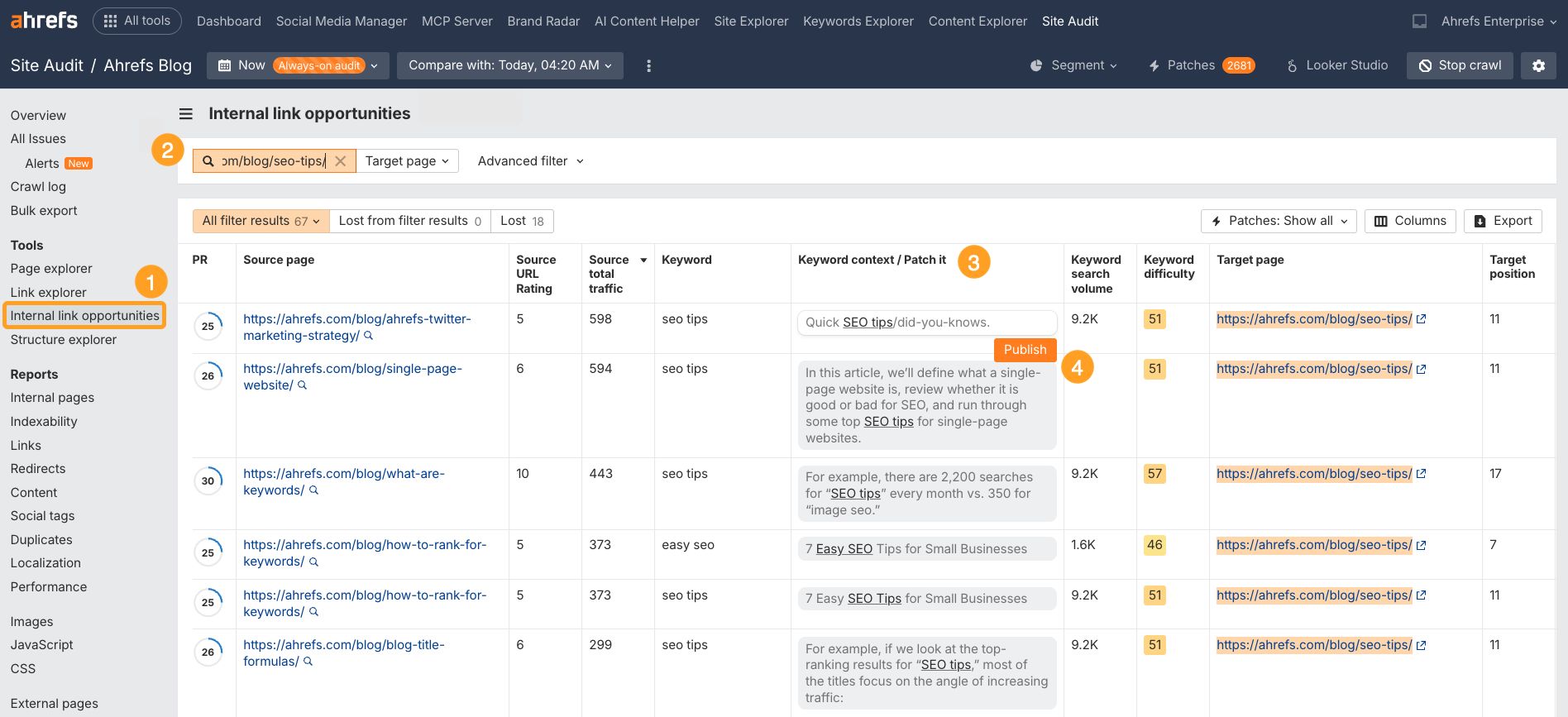
If we open one of these results and search for this mention on the page, here’s what we see:

This is a perfect place to add an internal link to our list of SEO tips.
If you add internal links to a page, it’s worth plugging it into the URL Inspection tool in Google Search Console and clicking “Request indexing”. This tells Google something on the page has changed and prompts them to recrawl.
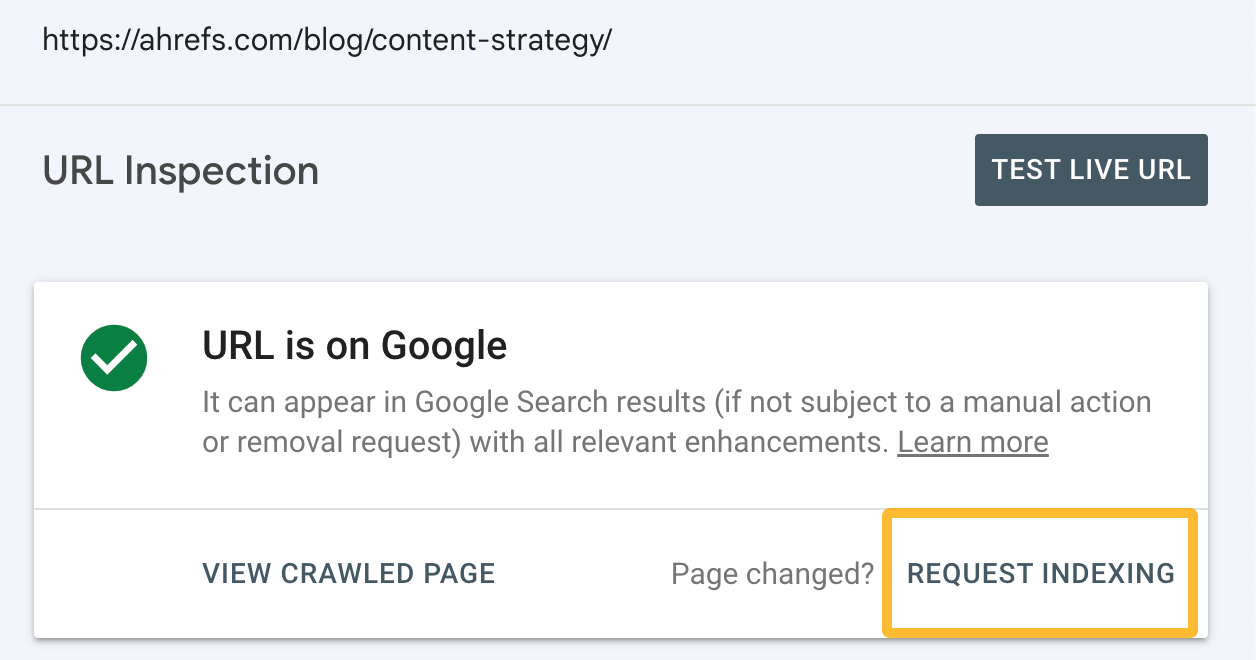
This may speed up the process of them discovering the internal link and consequently, the page you want indexing.
Check for crawl budget issues
Crawl budget is how fast and how many pages a search engine wants to crawl on your site. If this number exceeds your crawl budget, some won’t get crawled or indexed. This is why you need to keep the number of low-quality pages on your site to a minimum.
Here’s what Google says on the matter:
Wasting server resources on [low-value-add pages] will drain crawl activity from pages that do actually have value, which may cause a significant delay in discovering great content on a site.
Google does state that “crawl budget […] is not something most publishers have to worry about,” and that “if a site has fewer than a few thousand URLs, most of the time it will be crawled efficiently.”
Still, removing low-quality pages from your website is never a bad thing. It can only have a positive effect on your site’s crawl budget.
You can use our content audit template to find potentially low-quality pages that can be deleted.
Final thoughts
Every website needs to be indexed to stand any chance of getting traffic from Google. But being indexed doesn’t automatically mean you’ll rank for anything. It simply means that you’re in the game, not that you’re anywhere close to winning.
That’s where SEO comes in—the art of optimizing your website to rank for specific keywords.
In short, SEO involves:
- Finding what your customers are searching for (keyword research)
- Creating content about those topics (SEO content)
- Optimizing the pages (on-page SEO)
- Getting backlinks from other sites (link building)
- Keeping your site technically sound (technical SEO)
If you’re new to SEO, read our SEO guide for beginners or watch this video.