


Le guide du débutant en SEO technique

Par Patrick Stox
SEO technique chez Ahrefs


Le SEO technique est la partie la plus importante du SEO jusqu’à ce qu’il ne le soit plus. Les pages doivent être explorables et indexables pour avoir ne serait-ce qu’une chance de se positionner, mais de nombreuses autres activités auront un impact minimal comparé au contenu et aux liens.
Nous avons rédigé ce guide du débutant pour vous permettre de comprendre certaines bases et de savoir où concentrer votre temps pour maximiser l’impact.
Les bases du SEO technique
Qu’est-ce que le SEO technique ?
Le SEO technique est la pratique qui consiste à optimiser votre site web pour aider les moteurs de recherche à trouver, explorer, comprendre et indexer vos pages. Il permet d’améliorer la visibilité et les classements dans les moteurs de recherche. Il est également important pour la recherche IA.
À quel point le SEO technique est-il compliqué ?
Ça dépend. Les fondamentaux ne sont pas vraiment difficiles à maîtriser, mais le SEO technique peut être complexe et difficile à comprendre. Je ferai en sorte que ce guide soit aussi simple que possible.
Le SEO technique est-il important pour la recherche IA ?
Oui. La recherche IA dépend toujours de pages web explorables, bien structurées et fiables. Le SEO technique garantit que votre site est rapide, accessible et indexable, ce qui augmente les chances que votre contenu soit utilisé dans des réponses générées par l’IA ainsi que dans la recherche traditionnelle.
Comprendre l’exploration du web
Dans ce chapitre, nous allons voir comment nous assurer que les moteurs de recherche peuvent explorer efficacement votre contenu.
Comment fonctionne l’exploration du web
L’exploration du web consiste à ce que les moteurs de recherche récupèrent le contenu des pages et utilisent les liens qu’elles contiennent pour trouver encore plus de pages. Il existe plusieurs façons de contrôler ce qui est exploré sur votre site web. Voici quelques options.
Robots.txt
Un fichier robots.txt indique aux moteurs de recherche et aux plateformes IA où ils peuvent et ne peuvent pas aller sur votre site.
La plupart des crawlers des moteurs de recherche et d’IA respectent vos paramètres robots.txt. Si vous les interdisez explicitement, ils obéiront, n’exploreront pas votre contenu et ne l’incluront pas dans les données d’entraînement. Cependant, si vous empêchez les moteurs de recherche et les LLM d’utiliser votre site web comme contenu d’entraînement, vous limitez aussi vos chances d’apparaître dans leurs réponses.
Le saviez-vous ?
Google et certains LLM peuvent indexer des pages qu’ils ne peuvent pas explorer si des liens pointent vers ces pages. Cela peut être déroutant, mais si vous voulez éviter que des pages soient indexées, consultez ce guide et cet organigramme qui peut vous accompagner tout au long du processus.
LLMs.txt
LLMs.txt est un format volontaire permettant d’indiquer aux modèles de langage à grande échelle (LLM) comment ils peuvent utiliser votre contenu, mais comme nous l’expliquons dans notre guide sur LLMs.txt, il n’est pas particulièrement efficace ni très utile.
Il n’existe encore aucune preuve que LLMs.txt améliore la récupération par l’IA, augmente le trafic ou améliore la précision du modèle.
Vitesse d’exploration du web
Il existe une directive crawl-delay que vous pouvez utiliser dans robots.txt et que de nombreux crawlers prennent en charge. Elle vous permet de définir la fréquence à laquelle ils peuvent explorer des pages. Malheureusement, Google ne la respecte pas.[1] Pour Google, vous devrez la modifier dans Google Search Console.[2]
Restrictions d’accès
Si vous souhaitez que la page soit accessible à certains utilisateurs, mais pas aux moteurs de recherche, l’une de ces trois options est probablement ce qu’il vous faut :
- Une sorte de système de connexion
- Authentification HTTP (où un mot de passe est requis pour l’accès)
- Liste blanche d’IP (qui n’autorise que certaines adresses IP à accéder aux pages)
Ce type de configuration est idéal pour des éléments comme des réseaux internes, du contenu réservé aux membres ou des sites de staging, de test ou de développement. Elle permet à un groupe d’utilisateurs d’accéder à la page, mais les moteurs de recherche ne pourront pas y accéder et ne l’indexeront pas.
Comment voir l’activité d’exploration du web
Pour Google en particulier, la façon la plus simple de voir ce qu’il explore est d’utiliser le rapport « Statistiques sur l’exploration » dans Google Search Console, qui vous fournit davantage d’informations sur la manière dont votre site web est exploré.
Si vous souhaitez voir toute l’activité d’exploration sur votre site web, y compris celle des crawlers d’IA, vous devrez accéder aux journaux de votre serveur et éventuellement utiliser un outil pour mieux analyser les données. Cela peut devenir assez technique, mais si votre hébergement dispose d’un panneau de contrôle comme cPanel, vous devriez avoir accès aux journaux bruts et à certains outils d’agrégation comme AWstats et Webalizer.
Ajustements de l’exploration du web
Chaque site web aura un budget d’exploration différent, qui combine la fréquence à laquelle Google veut explorer un site et le volume d’exploration que votre site autorise. Les pages plus populaires et celles qui évoluent souvent seront explorées plus fréquemment, et les pages qui ne semblent pas populaires ou bien liées seront explorées moins souvent.
Si les crawlers détectent des signes de surcharge lors de l’exploration de votre site web, ils ralentiront généralement leur activité, voire cesseront complètement l’exploration jusqu’à ce que la situation s’améliore.
Une fois les pages explorées, elles sont rendues et envoyées à l’index. L’index est la liste principale des pages qui peuvent être retournées pour des requêtes de recherche. Parlons de l’index.
Comprendre l’indexation
Dans ce chapitre, nous verrons comment vous assurer que vos pages sont indexées et comment vérifier la manière dont elles le sont.
Instructions pour les robots
Une balise meta robots est un extrait HTML qui indique aux moteurs de recherche comment explorer ou indexer une certaine page. Elle est placée dans la section <head> d’une page web et ressemble à ceci :
<meta name="robots" content="noindex" />
Canonisation
Lorsque du contenu dupliqué crée plusieurs versions de la même page, Google en sélectionnera une à stocker dans son index. Ce processus s’appelle la canonisation et l’URL sélectionnée comme canonique sera celle que Google affichera dans les résultats de recherche. Il existe de nombreux signaux qu’il utilise pour sélectionner l’URL canonique, notamment :
Pour voir en toute simplicité comment Google a indexé une page, il suffit d’utiliser l’outil d’inspection d’URL dans Google Search Console. L’URL canonique sélectionnée par Google s’affichera.
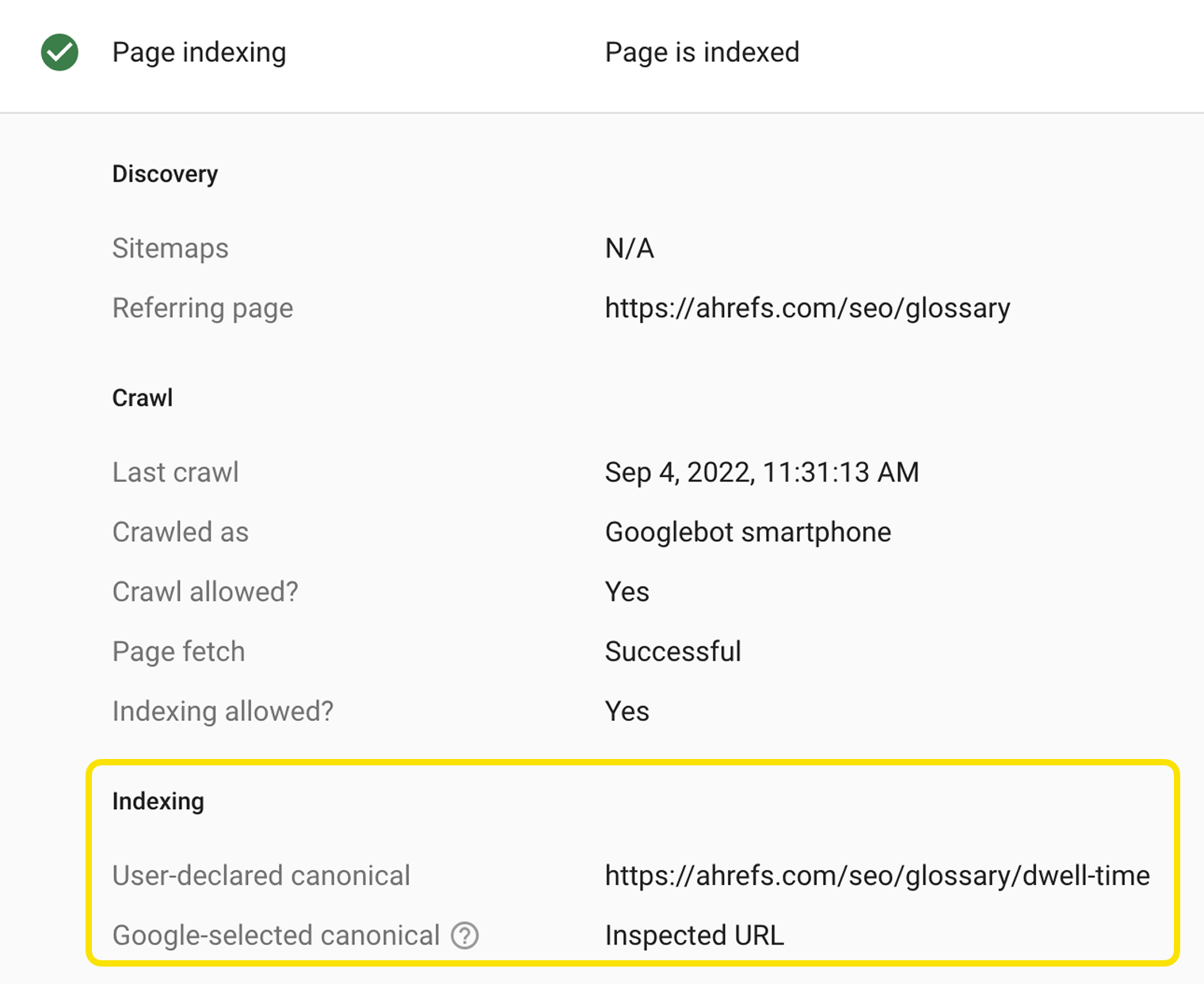
Gains rapides en SEO technique
La priorisation est l’une des choses les plus difficiles en SEO. Il existe beaucoup de bonnes pratiques, mais certains changements auront plus d’impact sur vos classements et votre trafic que d’autres. Voici quelques projets que je recommande de prioriser.
Vérifier l’indexation
Assurez-vous que les pages que vous voulez faire apparaître peuvent être indexées par Google. Les deux chapitres précédents portaient entièrement sur l’exploration du web et l’indexation, et ce n’était pas un hasard.
Vous pouvez consulter le rapport Indexabilité dans Site Audit pour trouver les pages qui ne peuvent pas être indexées et les raisons connexes (gratuitement dans Ahrefs Gratuit).
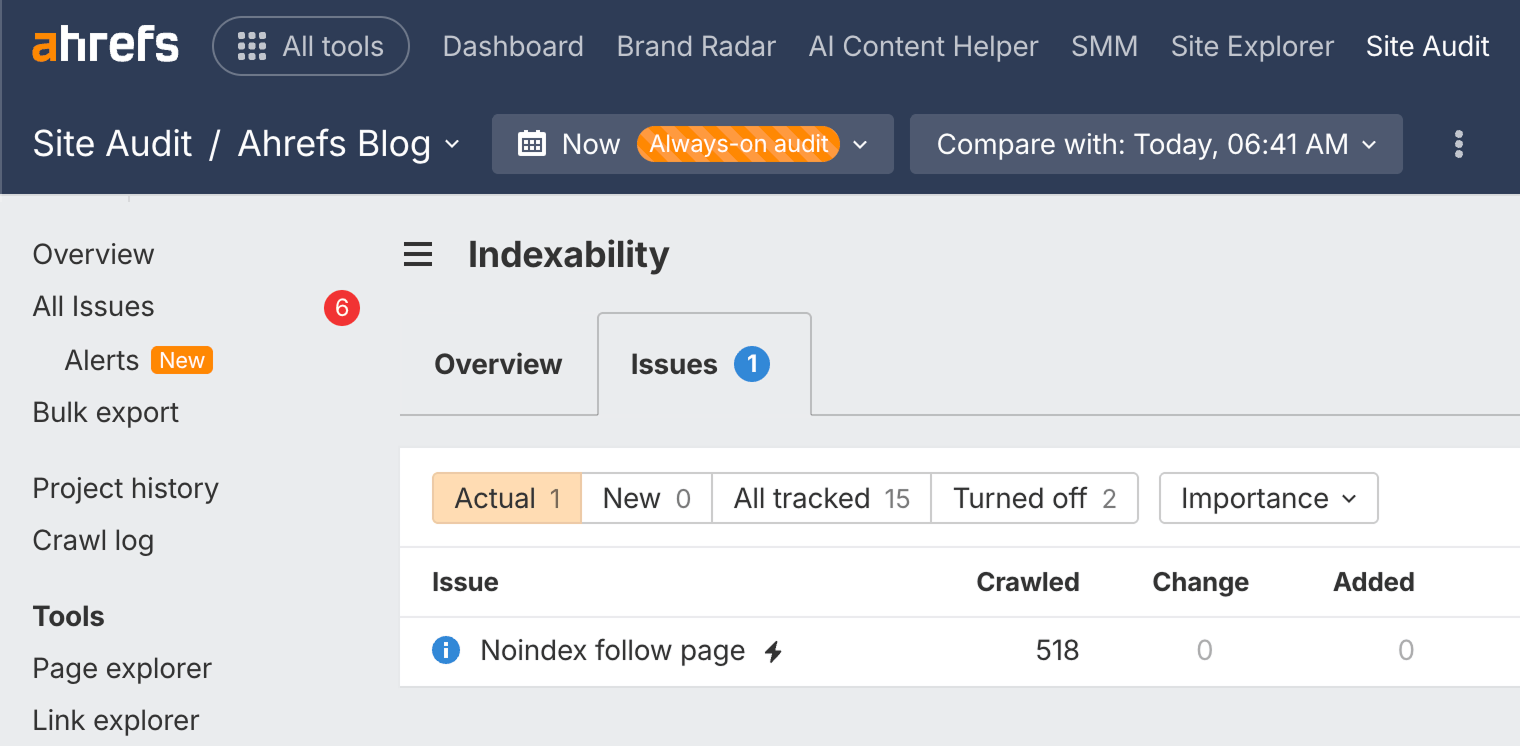
Lancer un audit SEO technique gratuit
En vous inscrivant ici, vous aurez accès à Ahrefs Gratuit ↗
Récupérer les liens perdus
Les sites web ont tendance à changer leurs URL au fil des années. Dans de nombreux cas, ces anciennes URL comportent des liens provenant d’autres sites web. Si elles ne sont pas redirigées vers les pages actuelles, ces liens sont perdus et ne comptent plus pour vos pages. Il n’est pas trop tard pour mettre en place ces redirections, et vous pouvez rapidement récupérer toute valeur perdue. Voyez cela comme le netlinking le plus rapide de votre vie.
Vous pouvez trouver des opportunités pour récupérer des liens perdus en utilisant Site Explorer d’Ahrefs. Saisissez votre domaine, allez dans le rapport Best by Links et ajoutez un filtre de réponse HTTP « 404 introuvable ». En général, je trie cela par « Domaines référents ».
Voici à quoi cela ressemble pour 1800flowers.com :
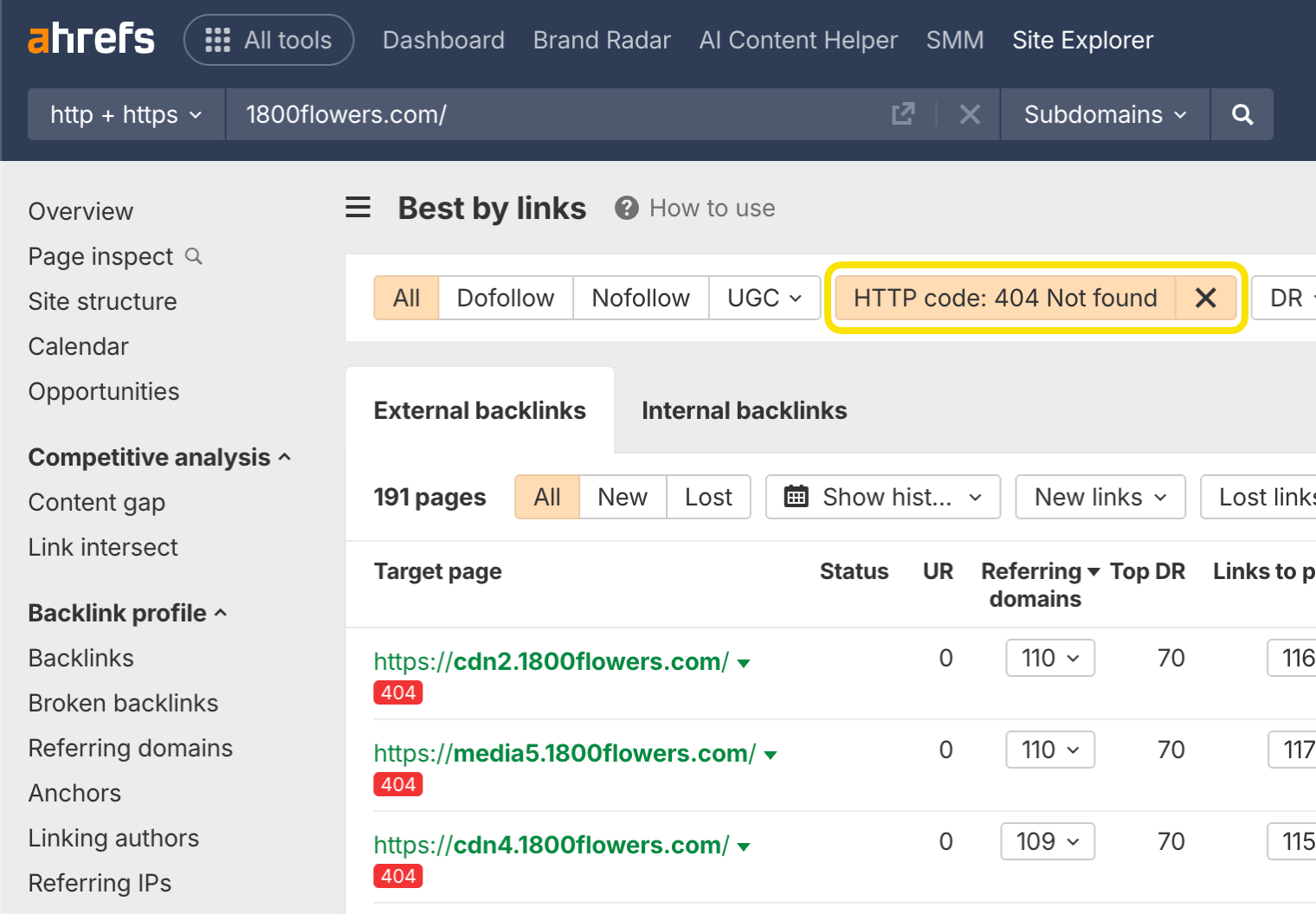
En regardant la première URL dans archive.org, je vois qu’il s’agissait auparavant de la page de la fête des Mères. En redirigeant cette page unique vers la version actuelle, vous récupérerez 225 liens provenant de 59 sites web différents, et il y a encore bien plus d’opportunités.
J’ai même créé un script pour vous aider à faire correspondre les redirections. N’ayez pas peur : il vous suffit de télécharger quelques fichiers et de les importer. Le notebook Colab vous guide pas à pas et s’occupe du gros du travail pour vous.
Vous devrez mettre en place une redirection 301 de toutes les anciennes URL vers leurs emplacements actuels afin de récupérer cette valeur perdue.
Le saviez-vous ?
Une redirection 301 est une redirection permanente. Tous les liens pointant vers l’URL redirigée seront attribués à la nouvelle URL aux yeux de Google.[3]
Ajouter des liens internes
Les liens internes sont des liens d’une page de votre site vers une autre page de votre site. Ils permettent de trouver vos pages et contribuent aussi à mieux les positionner. Nous avons un outil dans Site Audit appelé Opportunités de liens internes qui vous aide à localiser rapidement ces opportunités.
Cet outil fonctionne en recherchant des mentions de mots-clés pour lesquels vous êtes déjà positionné sur votre site. Il vous les suggère ensuite comme des opportunités contextuelles de liens internes.
Par exemple, l’outil détecte une mention de « navigation à facettes » dans notre guide sur le contenu dupliqué. Comme Site Audit sait que nous avons une page sur la navigation à facettes, il suggère d’ajouter un lien interne vers cette page.

Ajouter le balisage Schéma
Le balisage Schéma correspond à du code qui permet aux moteurs de recherche de mieux comprendre votre contenu et qui alimente de nombreuses fonctionnalités pouvant aider votre site web à se démarquer du reste des résultats de recherche. Il peut également aider les LLM a interpréter correctement le contenu de votre page. Google dispose d’une galerie de recherche qui présente les différentes fonctionnalités de recherche et le schéma requis pour que votre site soit éligible.
SEO technique pour la recherche IA
L’IA a changé la façon dont le contenu est découvert et présenté aux internautes, mais elle repose toujours sur une base de pages web explorables, bien structurées et fiables. Elle transforme également notre manière de créer et d’optimiser le contenu.
Prêter attention à quelques facteurs techniques spécifiques à l’IA peut vous aider à rester visible partout où les internautes recherchent des informations.
Rendez votre site accessible aux LLM
Comme les moteurs de recherche, les LLM doivent pouvoir explorer votre site web et accéder à son contenu. Cependant, ils fonctionnent un peu différemment des crawlers des moteurs de recherche.
Par exemple, la plupart des LLM ne rendent pas le JavaScript, un langage de code courant utilisé pour créer des sites web. Si le contenu clé ou la navigation n’apparaît qu’après le chargement du JavaScript, il y a un risque que certains crawlers d’IA ne le voient pas. Il est donc préférable de ne pas l’utiliser pour du contenu crucial que vous souhaitez rendre visible dans la recherche IA.
Il vaut également la peine de vérifier si des outils tiers bloquent les crawlers d’IA pour accéder à votre site web.
Par exemple, Cloudflare a introduit de nouvelles fonctionnalités permettant aux propriétaires de sites web de contrôler si les plateformes d’IA peuvent extraire du contenu pour leurs ensembles de données d’entraînement.
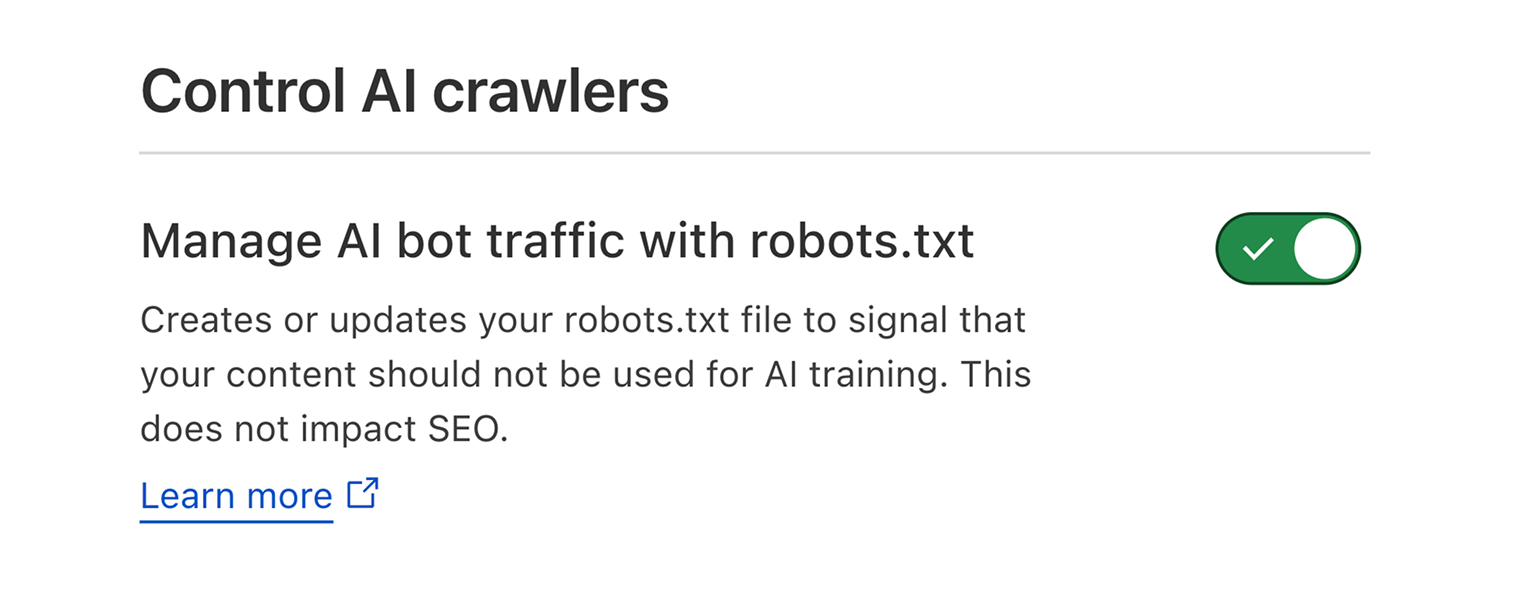
Le paramètre par défaut empêche les crawlers d’IA d’accéder au contenu. Vous devrez alors le désactiver si vous souhaitez que votre contenu maximise votre visibilité dans les résultats de recherche IA.
Rediriger les URL hallucinées
Les systèmes de recherche IA peuvent citer des URL sur votre domaine qui n’existent pas. Vous pouvez les identifier dans Ahrefs Web Analytics en examinant les pages qui reçoivent du trafic de recherche IA :
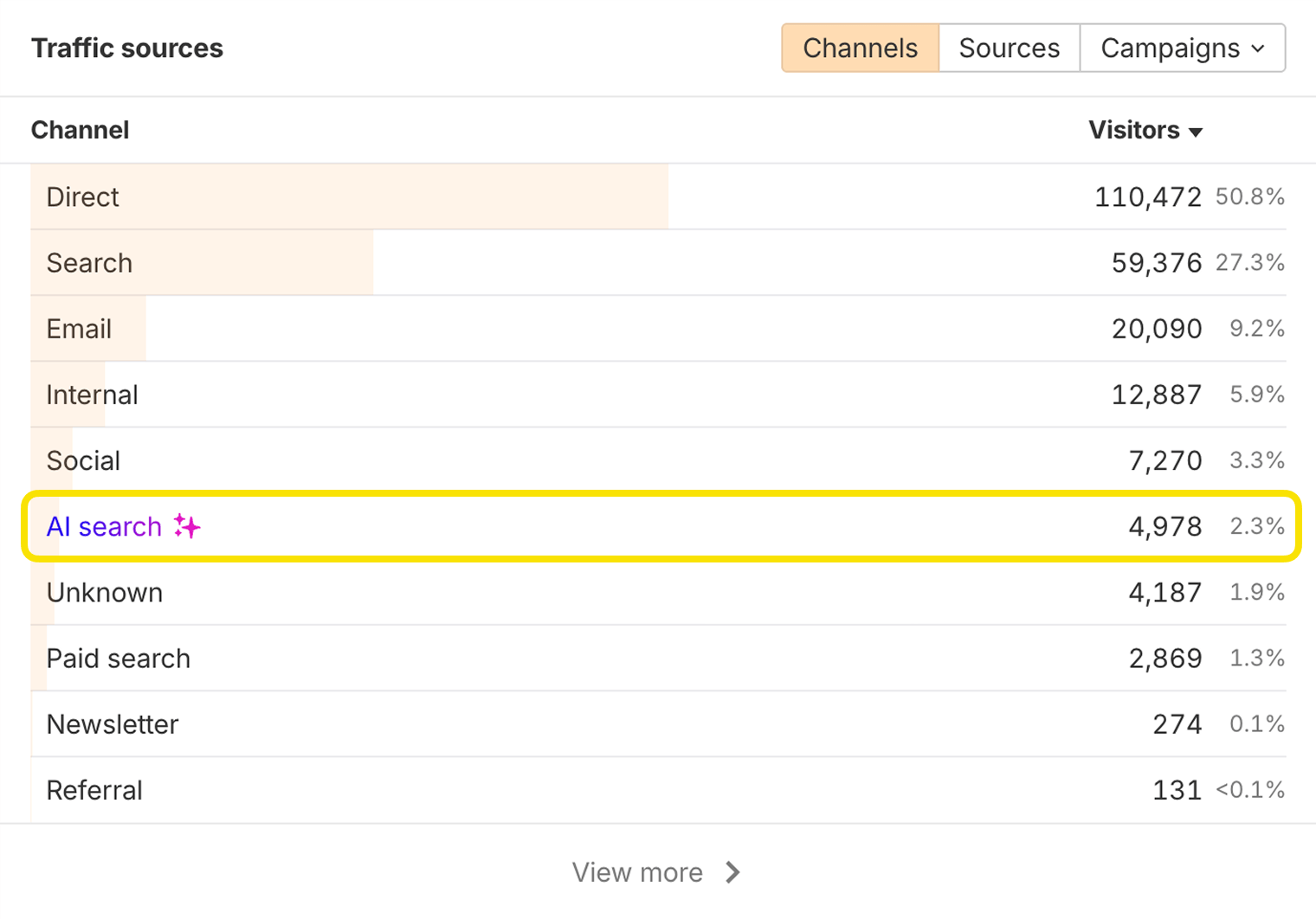
Si l’une de ces pages renvoie une erreur 404, le système IA a peut-être halluciné l’URL. Pour éviter de perdre du trafic, vous pouvez rediriger cette URL vers une page pertinente et en ligne.
Une surveillance régulière évite la frustration des utilisateurs et protège l’autorité de la marque.
Détection de contenu IA
Même s’il est possible d’utiliser l’IA afin de créer du contenu pour votre site web, trop de contenu généré par l’IA peut être considéré comme un signal de spam qui limite la visibilité de votre contenu dans les systèmes de recherche traditionnels et d’IA.
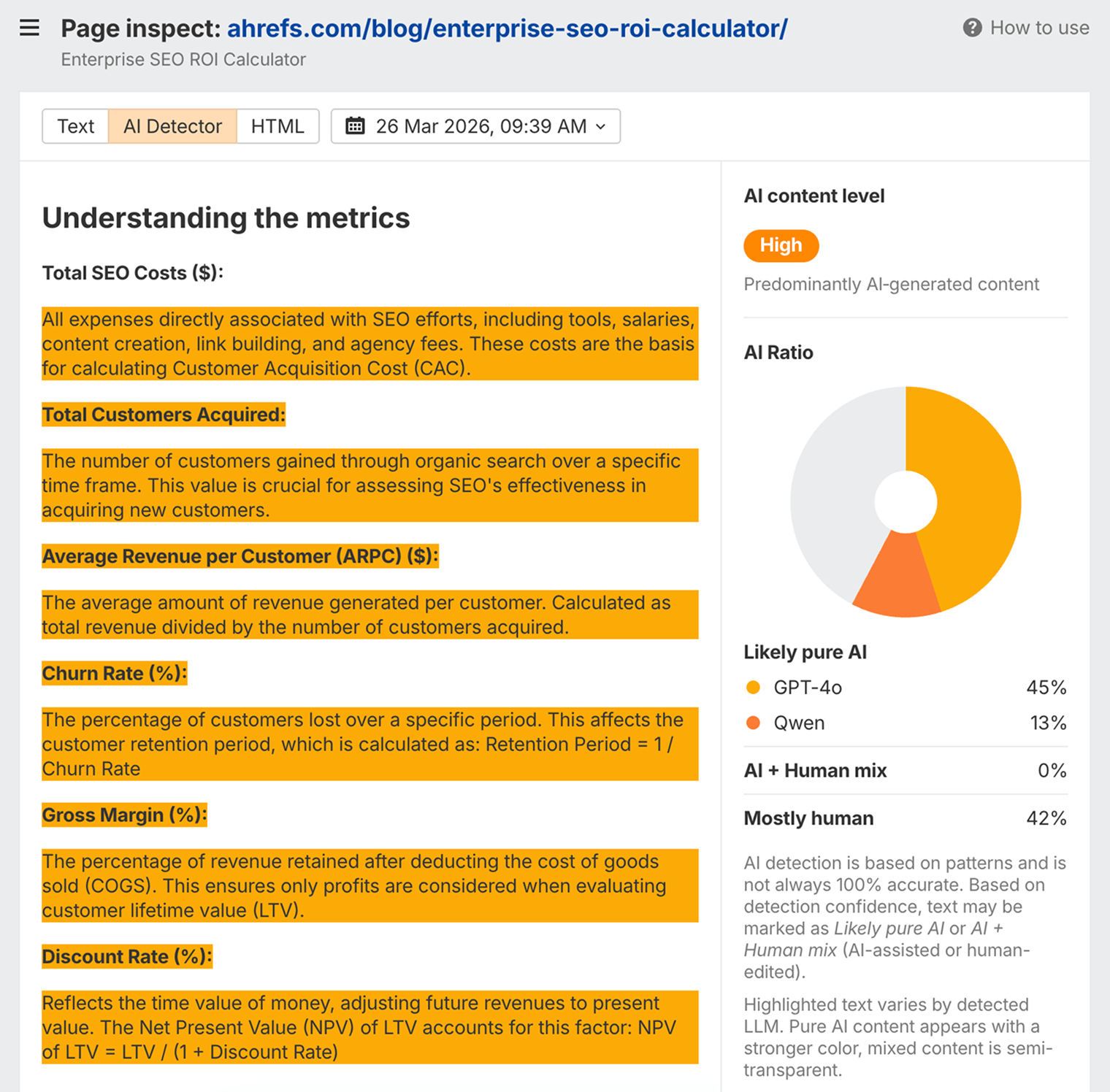
Vous pouvez utiliser le détecteur d’IA d’Ahrefs dans Site Explorer > Inspecter la page pour voir comment les machines peuvent évaluer le niveau d’IA présent dans votre contenu.
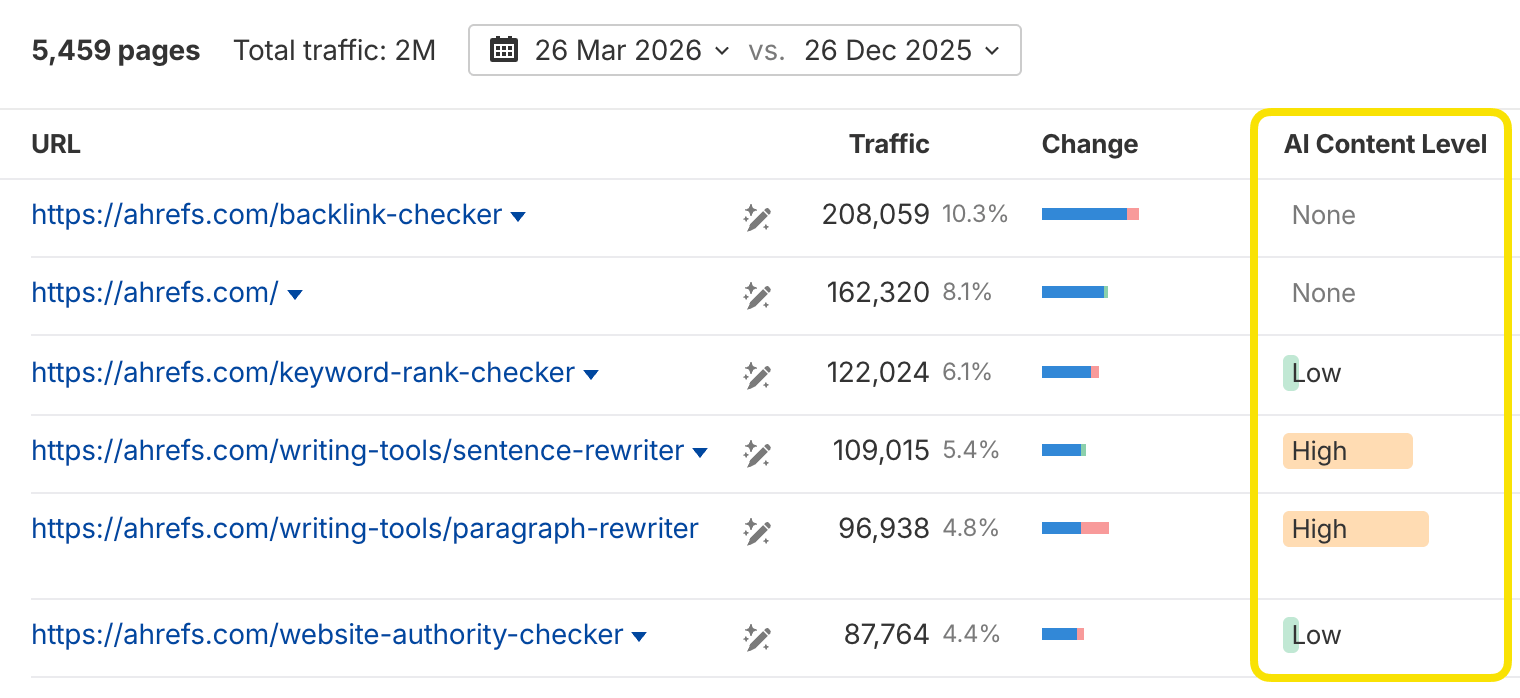
Vous pouvez aussi le vérifier en masse dans le rapport Meilleures pages pour repérer des pages existantes qui pourraient nécessiter une réécriture :
Code injecté par des outils d’IA
Si vous avez utilisé l’IA pour créer votre site web ou y ajouter de nouvelles fonctionnalités, du code HTML supplémentaire révélant que l’IA a été utilisée a pu être inséré.
Dans un cas, un bug de Yoast SEO a inséré des classes cachées liées à l’IA dans des pages, ce qui rendait évident pour les moteurs de recherche que l’IA était impliquée.

Si vous utilisez des outils d’IA pour effectuer des modifications on-page, vérifiez le code source de votre site pour vous assurer qu’aucun élément inattendu n’est ajouté. Des « empreintes » cachées comme celle-ci peuvent être évitées grâce à des revues de code régulières et à des tests avant la publication des mises à jour.
Projets supplémentaires de SEO technique
Les projets dont nous parlerons dans ce chapitre sont tous dignes d’attention, mais ils peuvent demander plus de travail et apporter moins de bénéfices que les projets à « gains rapides » de la partie précédente. Cela ne veut pas dire que vous ne devez pas les mettre en place. Ceci a pour but de vous donner une idée de la manière de prioriser vos différents projets.
Signaux d’expérience sur la page
Ce sont des facteurs de classement moins importants, mais ce sont tout de même des éléments à examiner dans l’intérêt de vos utilisateurs. Ils couvrent des aspects du site web qui ont un impact sur l’expérience utilisateur (UX).
Signaux de recherche de Google pour l’expérience sur la page
https://ahrefs.com/blog/core-web-vitals/
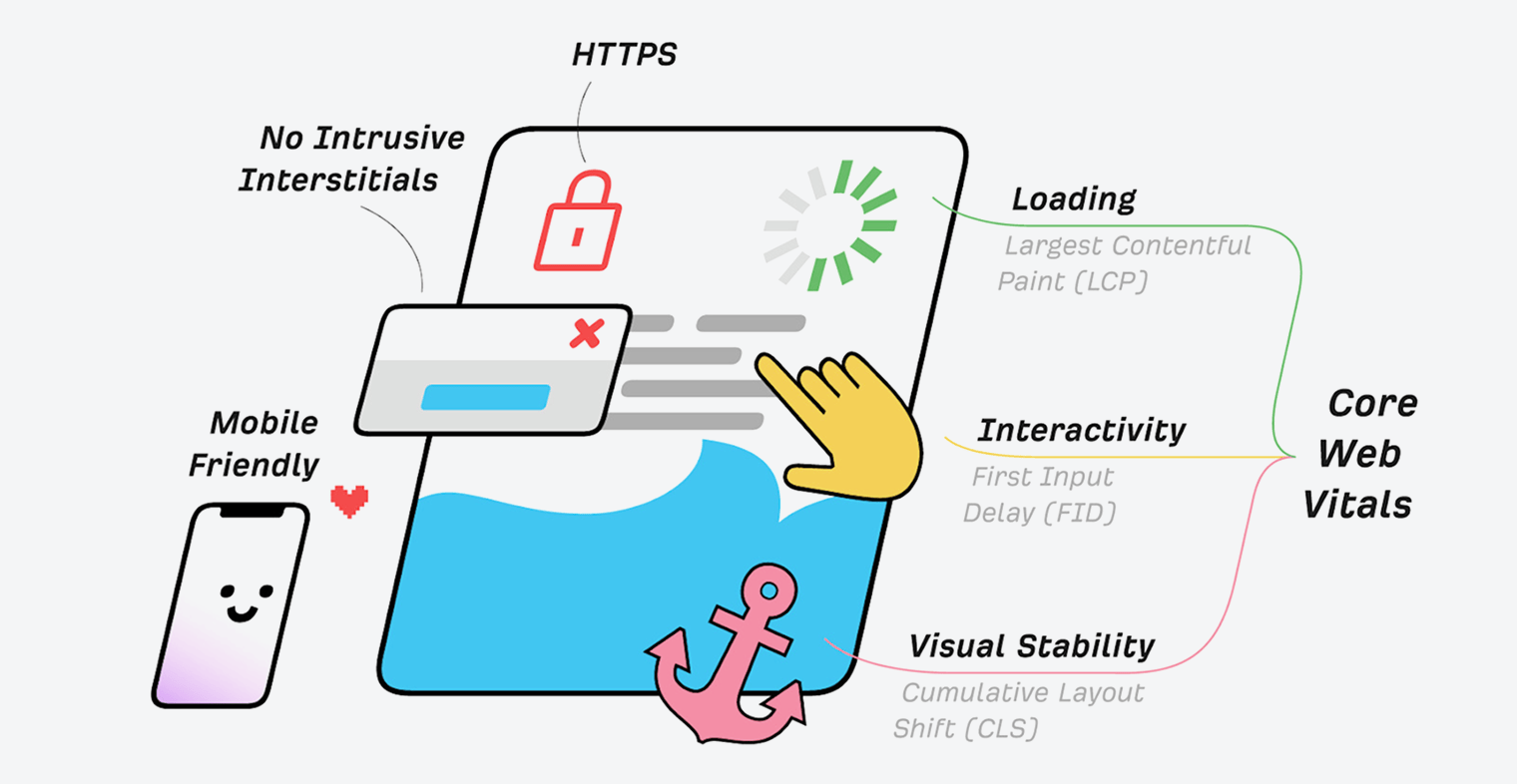
Core Web Vitals
Les Core Web Vitals sont des métriques de vitesse qui font partie des signaux d’expérience sur la page de Google utilisés pour mesurer l’expérience utilisateur. Les métriques mesurent le chargement visuel avec le Largest Contentful Paint (LCP), la stabilité visuelle avec le Cumulative Layout Shift (CLS) et l’interactivité avec le First Input Delay (FID).
HTTPS
HTTPS protège la communication entre votre navigateur et le serveur contre toute interception ou modification par des attaquants. Il garantit la confidentialité, l’intégrité et l’authentification pour la grande majorité du trafic web actuel. Vous devez veiller à ce que vos pages soient chargées en HTTPS et non en HTTP.
Tout site web qui affiche une icône de « cadenas » dans la barre d’adresse utilise HTTPS.

Compatibilité mobile
En bref, cela permet de vérifier si les pages web s’affichent correctement et sont faciles à utiliser sur des appareils mobiles.
Comment savoir si votre site est adapté aux mobiles ? Consultez le rapport « Ergonomie mobile » dans Google Search Console.
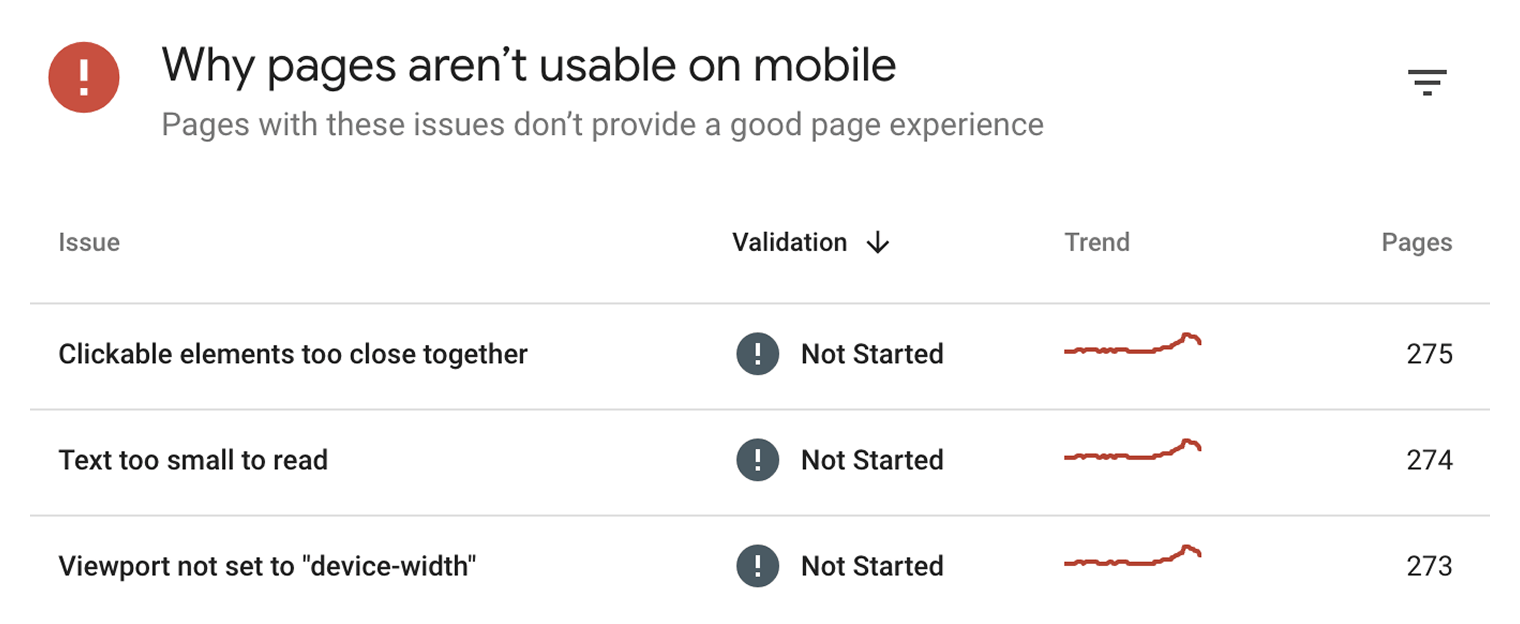
Ce rapport vous indique si l’une de vos pages présente des problèmes de compatibilité mobile.
Interstitiels
Les interstitiels empêchent le contenu d’être vu. Il s’agit de fenêtres contextuelles qui couvrent le contenu principal et avec lesquelles les utilisateurs peuvent devoir interagir avant qu’elles ne disparaissent.
Hreflang — Pour plusieurs langues
Hreflang est un attribut HTML utilisé pour spécifier la langue et le ciblage géographique d’une page web. Si vous avez plusieurs versions de la même page dans différentes langues, vous pouvez utiliser la balise hreflang pour informer des moteurs de recherche comme Google de ces variantes. Cela les aide à montrer la bonne version à leurs utilisateurs.
Ahrefs facilite désormais la mise en œuvre de hreflang grâce à un graphique visuel des liens hreflang dans Site Audit.
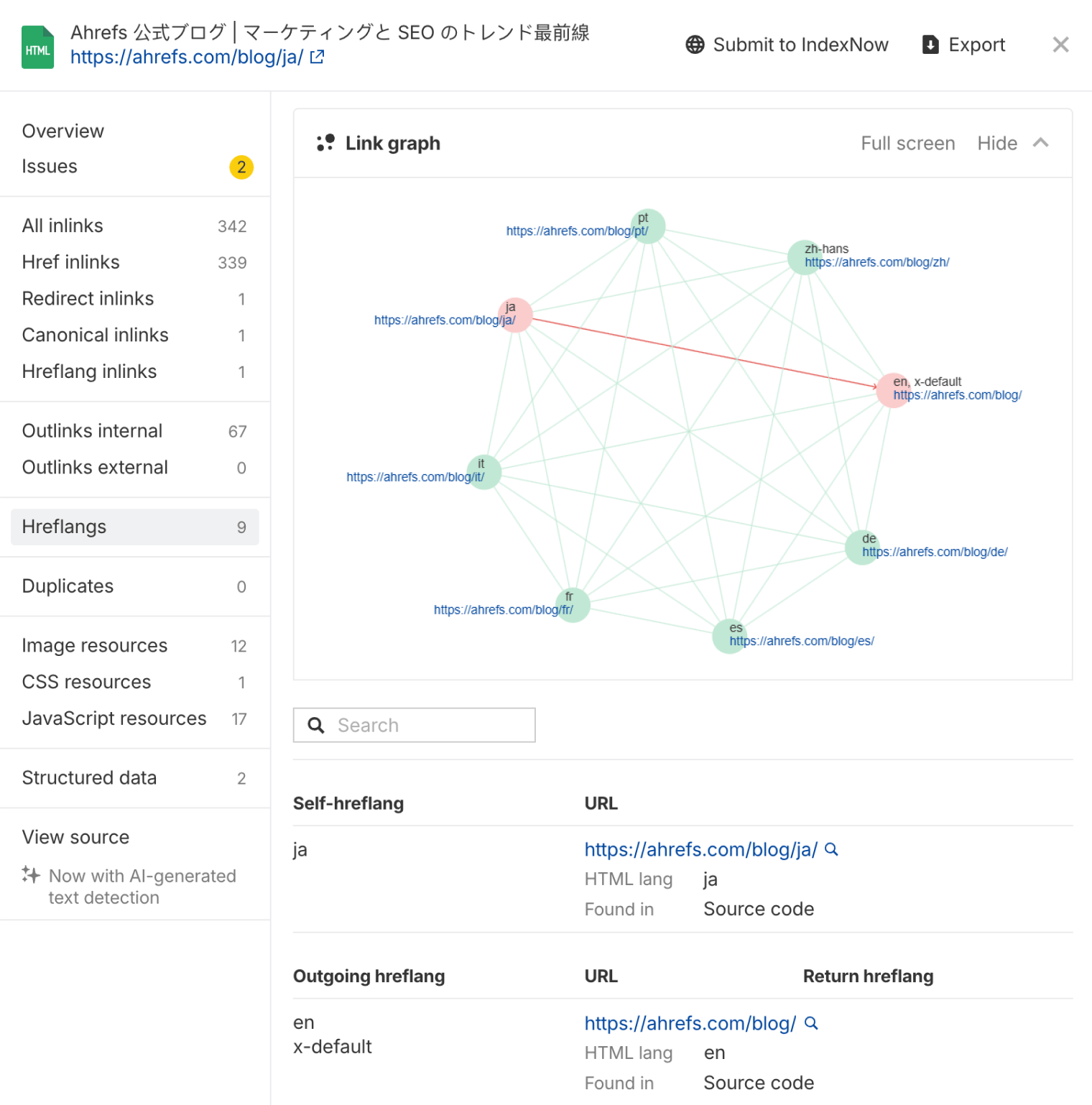
Ce graphique hreflang montre toutes les variantes linguistiques d’une page et met en évidence tout problème de configuration. De plus, il signale des erreurs comme des codes de langue invalides, des auto-liens manquants ou l’absence de balises réciproques, et fournit des indications claires pour les corriger.
Maintenance générale/santé du site web
Ces tâches n’auront probablement pas beaucoup d’impact sur votre classement, mais il est généralement recommandé de les corriger pour améliorer l’expérience utilisateur.
Liens brisés
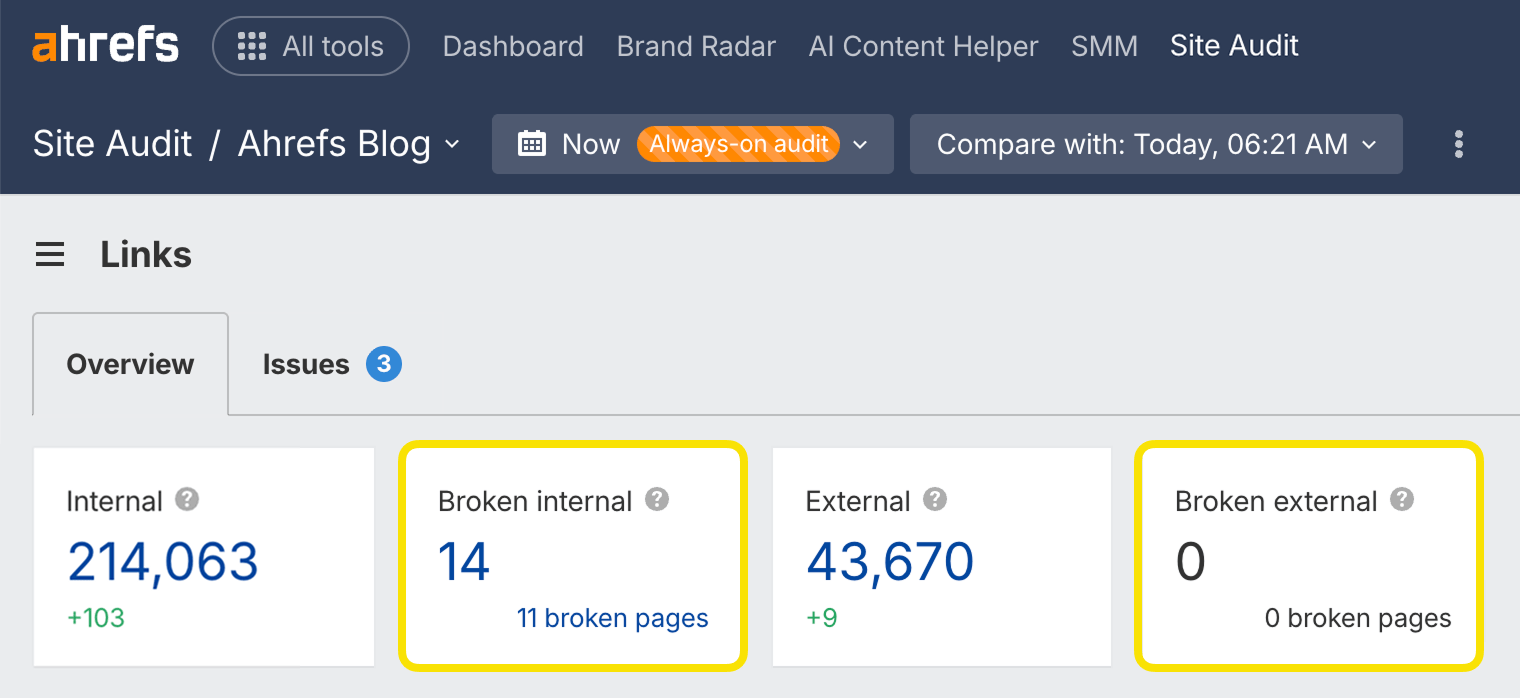
Les liens brisés sont des liens sur votre site qui pointent vers des ressources inexistantes. Ils peuvent être internes (c’est-à-dire vers d’autres pages de votre domaine) ou externes (c’est-à-dire vers des pages sur d’autres domaines).
Trouvez rapidement des liens brisés sur votre site web grâce à Site Audit dans le rapport Liens (disponible dans Ahrefs Gratuit).
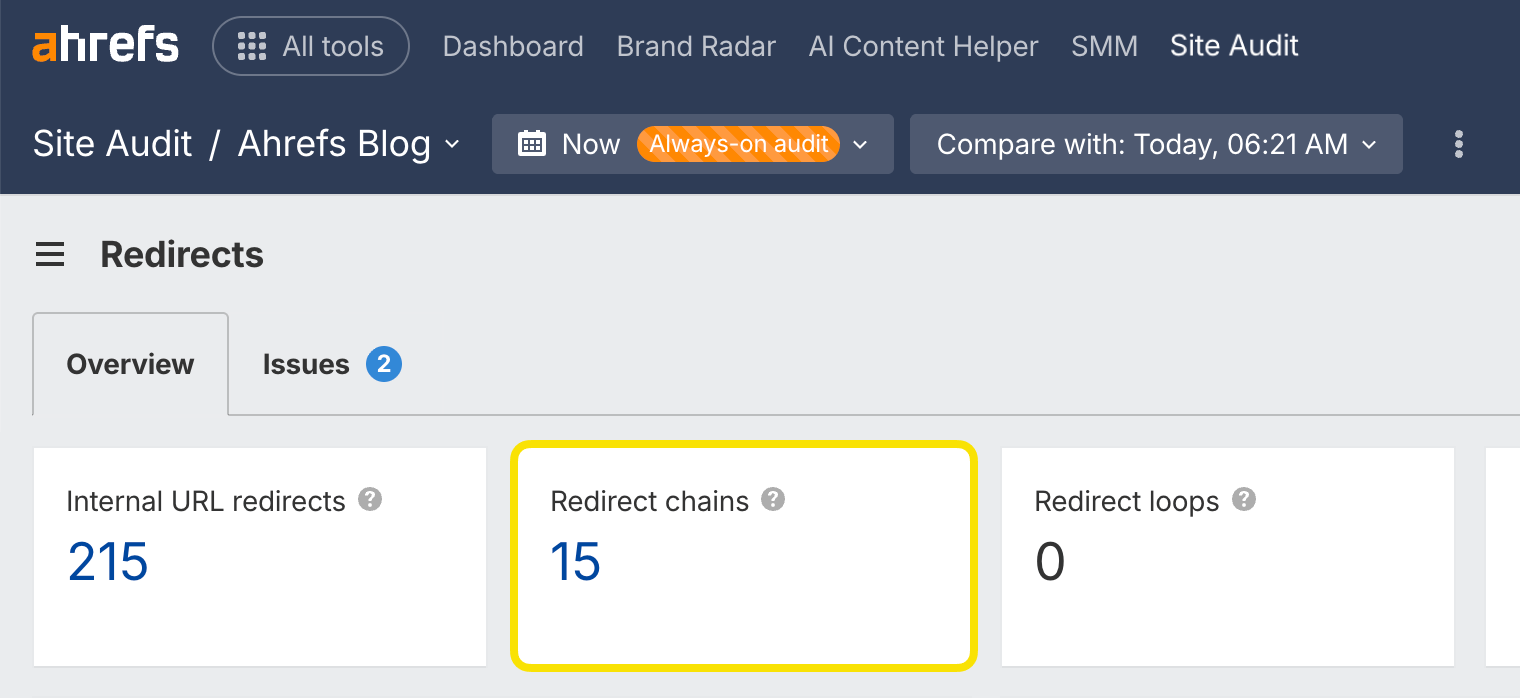
Chaînes de redirection
Les chaînes de redirection sont une série de redirections qui se produisent entre l’URL initiale et l’URL de destination.
Vous pouvez trouver rapidement les chaînes de redirection sur votre site web grâce à Site Audit dans le rapport Redirection (disponible dans Ahrefs Gratuit).
Outils de SEO technique
Ces outils vous aident à améliorer les aspects techniques de votre site web.
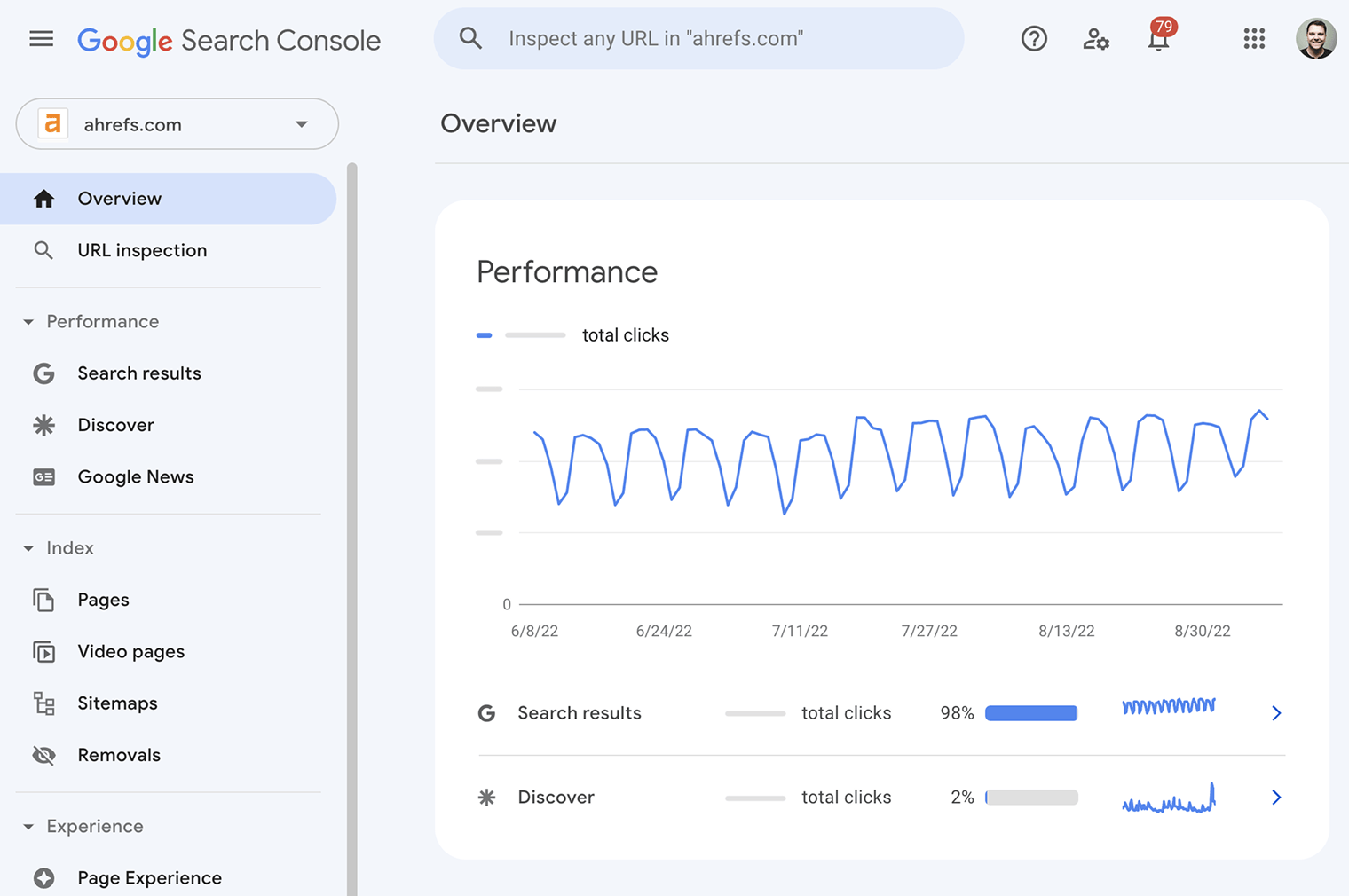
Google Search Console (anciennement Google pour les webmasters) est un service gratuit de Google qui vous aide à surveiller et à résoudre les problèmes liés à l’apparence de votre site web dans les résultats de recherche.
Utilisez-le pour identifier et corriger des erreurs techniques, soumettre des sitemaps, connaître les problèmes de données structurées, et plus encore.
Bing et Yandex ont leurs propres versions, et Ahrefs aussi. Ahrefs Gratuit vous aide à améliorer les performances SEO de votre site web. Il vous permet de :
- Surveillez la santé SEO de votre site web.
- Vérifiez plus de 100 problèmes SEO.
- Consultez tous vos backlinks.
- Découvrez tous les mots-clés pour lesquels vous vous positionnez.
- Découvrez le volume de trafic que reçoivent vos pages.
- Trouvez des opportunités de liens internes.
C’est notre réponse aux limites de Google Search Console.
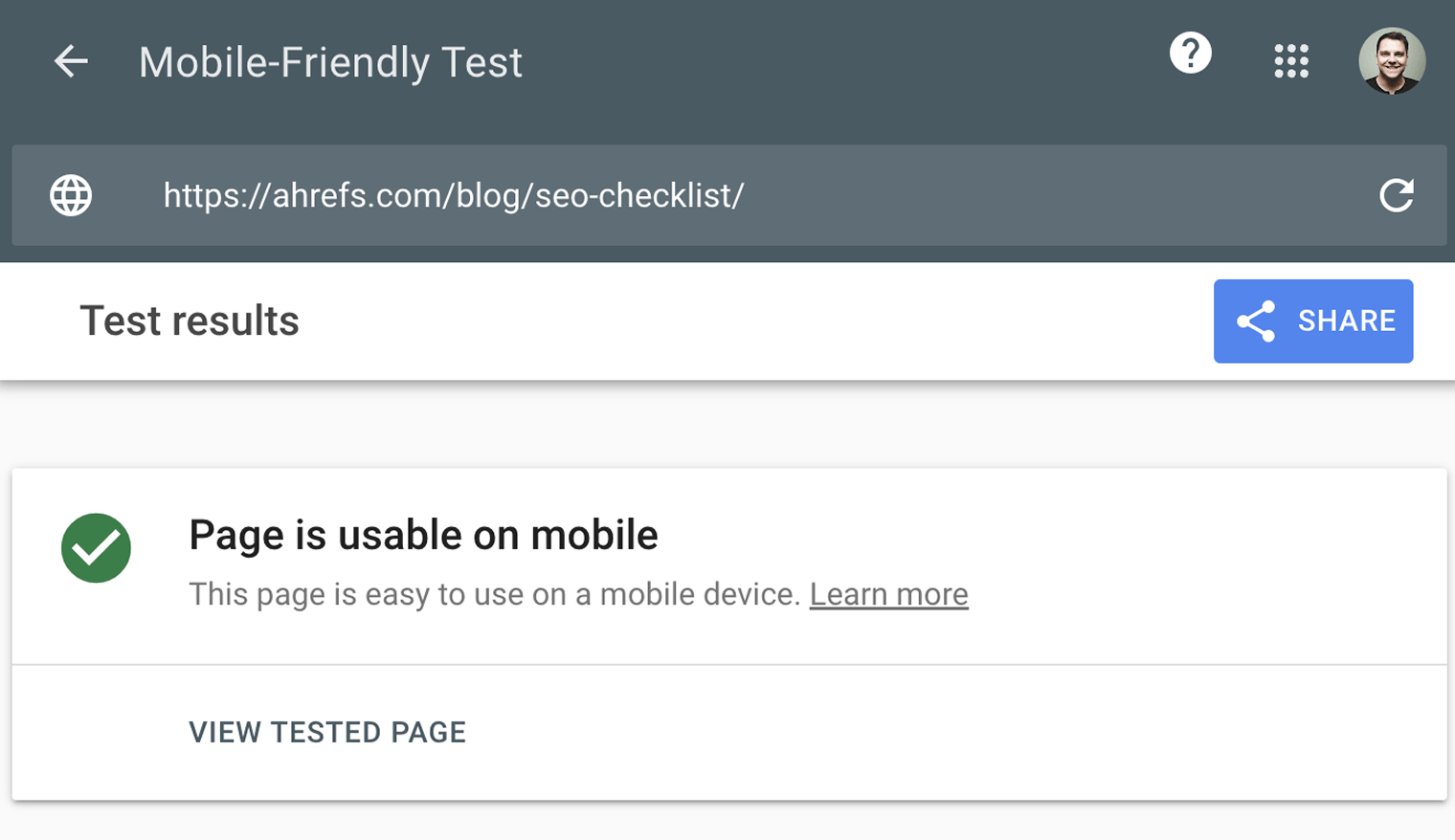
Le test d’optimisation mobile de Google vérifie à quel point un visiteur peut facilement utiliser votre page sur un appareil mobile. Il identifie également des problèmes spécifiques liés à l’utilisation de ce type de support, comme un texte trop petit pour être lu, l’utilisation de plugins incompatibles, etc.
Le test d’optimisation mobile montre ce que Google voit lorsqu’il explore la page. Vous pouvez aussi utiliser le test avec résultats enrichis pour voir le contenu que Google voit sur un ordinateur ou sur des appareils mobiles.
Chrome DevTools est l’outil de débogage de pages web intégré à Chrome. Utilisez-le pour identifier et résoudre les problèmes de vitesse de page, améliorer les performances de rendu des pages et bien plus encore.
D’un point de vue SEO technique, il présente une infinité d’utilisations.
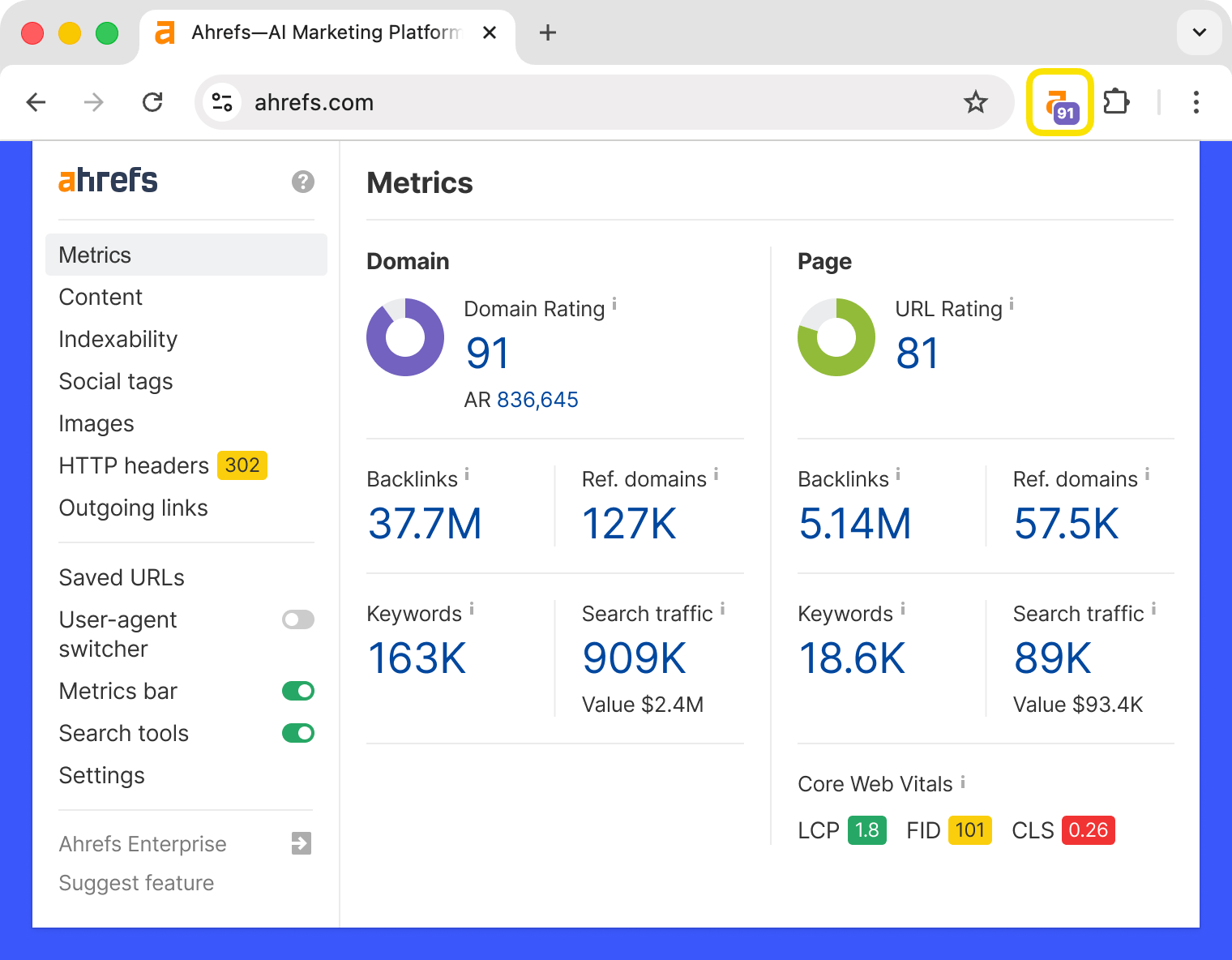
La barre d’outils SEO d’Ahrefs est une extension gratuite pour Chrome et Firefox qui vous fournit des données SEO utiles sur les pages et les sites web que vous visitez.
Voici ses fonctionnalités gratuites :
- Rapport SEO on-page
- Traceur de redirection avec en-têtes HTTP
- Vérificateur de liens brisés
- Outil de surbrillance de liens
- Positions SERP
De plus, en tant qu’utilisateur d’Ahrefs, vous obtenez :
- Métriques SEO pour chaque site et page que vous visitez, ainsi que pour les résultats de recherche Google
- Des métriques de mots-clés, comme le volume de recherche et la difficulté du mot-clé, directement dans la SERP
- Exportation des résultats SERP
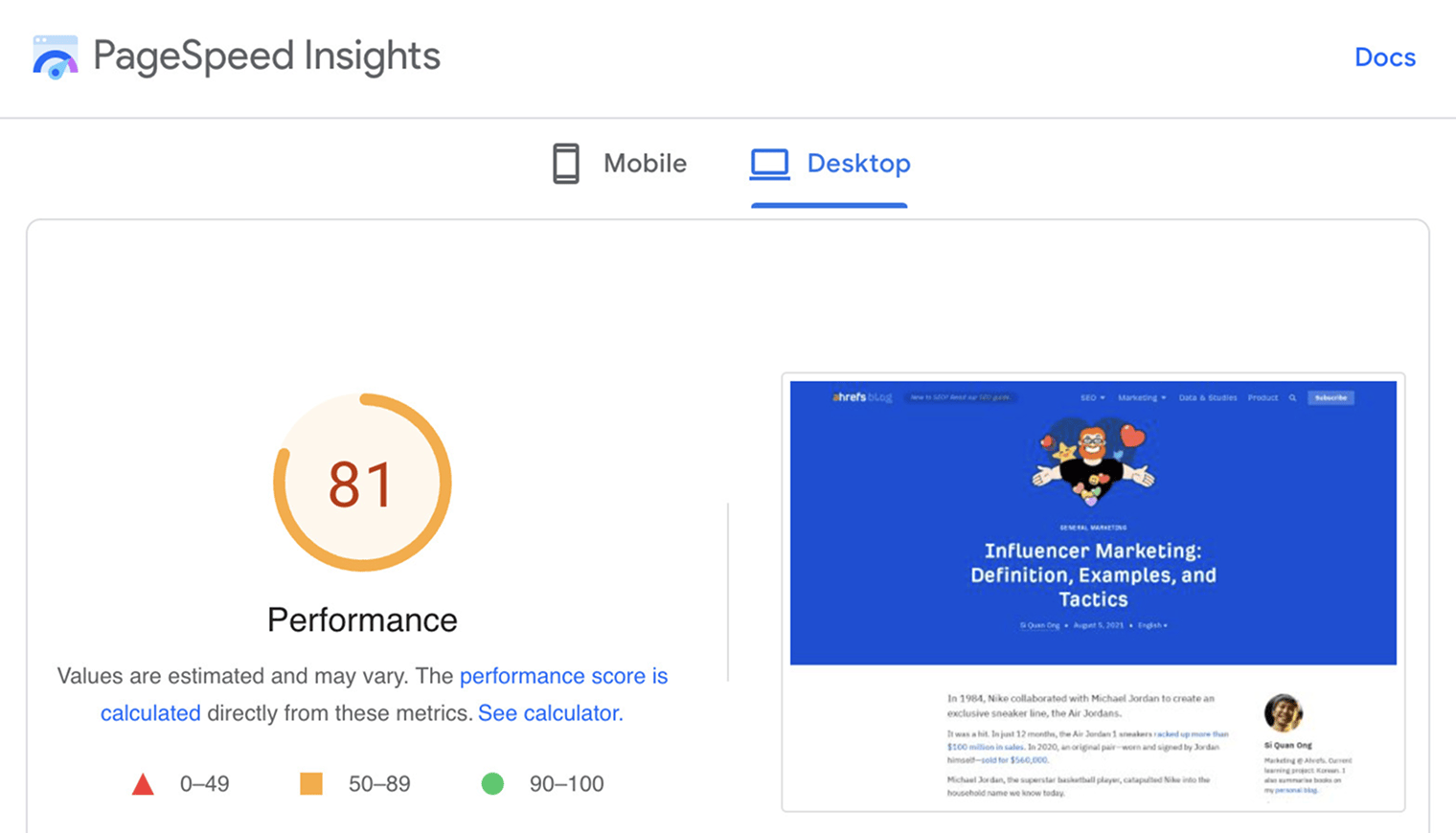
PageSpeed Insights analyse la vitesse de chargement de vos pages web. En plus du score de performance, il affiche aussi des recommandations concrètes pour accélérer le chargement des pages.
Points clés à retenir
- Sans indexation, votre contenu n’apparaîtra pas dans les résultats des moteurs de recherche.
- Lorsqu’un élément est brisé et affecte le trafic de recherche, il peut être prioritaire de le réparer. Mais pour la plupart des sites, il est généralement plus judicieux de consacrer votre temps à votre contenu et à vos liens.
- Bon nombre des projets techniques ayant le plus d’impact concernent l’indexation ou les liens.
- Le SEO technique compte toujours pour la recherche IA. Des pages bien structurées et explorables aident les systèmes d’IA à trouver, comprendre et mettre en avant votre contenu.
Références
- « Une règle de crawl-delay est-elle ignorée par Googlebot ? ». Google Search Central. 21 décembre 2017
- « Changer la vitesse d’exploration de Googlebot ». Google. Consulté le 9 septembre 2022
- « Les redirections 30x ne font plus perdre de PageRank ». Gary Illyes. 26 juillet 2016
Patrick Stox est conseiller produit, professionnel du SEO technique et ambassadeur de marque chez Ahrefs. Il a été l’auteur principal du chapitre sur le SEO du Web Almanac 2021 et relecteur pour le chapitre sur le SEO 2022. Il a également coécrit le Livre SEO pour les débutants d’Ahrefs et a été relecteur technique pour The Art of SEO, 4ᵉ édition. Il est organisateur du Triangle SEO Meetup et de la conférence Tech SEO Connect. Il anime également un groupe Slack dédié au SEO technique et est modérateur de /r/TechSEO sur Reddit.
Maîtriser le SEO étape par étape
Comment les moteurs de recherche fonctionnent-ils ?
Avant de commencer à apprendre le SEO, vous devez comprendre le fonctionnement des moteurs de recherche.
SEO de base
Apprenez à configurer votre site Web pour le succès du SEO et à vous familiariser avec les quatre principales facettes du SEO.
Recherche de mots-clés
Le point de départ du SEO est de comprendre ce que recherchent vos clients cibles.
Contenu SEO
Apprenez à créer du contenu qui se classe dans les moteurs de recherche.
SEO on-page
C'est là que vous optimisez vos pages pour aider les moteurs de recherche à les comprendre.
Link Building
Apprenez à créer du contenu qui se classe dans les moteurs de recherche.
SEO technique
Prévenez les problèmes techniques qui empêchent Google d’accéder à votre site web et de le comprendre.
Référencement local
Découvrez comment améliorer votre visibilité dans les résultats de recherche locale et attirer plus de clients dans votre zone.
L’impact de l’IA sur le SEO
Vous ne pouvez pas parler de SEO aujourd’hui sans mentionner l’IA générative.
Comment les moteurs de recherche IA fonctionnent-ils ?
Découvrez précisément comment les moteurs de recherche IA comme ChatGPT génèrent leurs réponses et choisissent les marques et produits à mentionner.