


Comment les moteurs de recherche IA fonctionnent-ils ?

Par Ryan Law
Directeur du marketing de contenu chez Ahrefs
- Que sont les moteurs de recherche IA ?
- Comment l’entraînement fonctionne-t-il ?
- Comment la vérification et la RAG fonctionnent-elles ?
- Comment la diffusion de requêtes fonctionne-t-elle ?
- Comment la récupération, la division en extraits et la synthèse des réponses fonctionnent-elles ?
- Comment les citations sont-elles choisies ?
- Comment la personnalisation fonctionne-t-elle ?
Que se passe-t-il réellement lorsque vous demandez à ChatGPT de vous recommander le meilleur casque circum-aural pour faire du sport ?
Comment les moteurs de recherche IA génèrent-ils leurs réponses et choisissent-ils leurs recommandations de produits ? En quoi diffèrent-ils des moteurs de recherche traditionnels comme Google (et sur quels points se recoupent-ils) ?
Et surtout, comment pouvez-vous favoriser l’apparition de votre site web, votre marque et vos produits ?
Merci à Gianluca Fiorelli et Mark Williams-Cook pour la relecture et leur contribution à ce chapitre.
Que sont les moteurs de recherche IA ?
Les moteurs de recherche IA sont des systèmes de questions-réponses qui utilisent des grands modèles de langage (LLM) pour trouver des informations et générer des réponses.
Il existe quelques différences clés entre les moteurs de recherche traditionnels et les moteurs de recherche IA (même si elles se réduisent à mesure que les moteurs de recherche traditionnels intègrent davantage de fonctionnalités IA) :
- Au lieu de saisir des requêtes ponctuelles, les utilisateurs peuvent poser des questions de suivi et poursuivre la conversation.
- Au lieu de renvoyer une liste de liens classés, les moteurs de recherche IA fournissent des réponses et des recommandations directes (et ces réponses peuvent changer régulièrement).
- Au lieu de diriger les internautes vers votre site web, les utilisateurs obtiennent des réponses directement dans l’interface de la conversation (ce qui génère moins de clics vers votre site web).
Voici à quoi ressemble une interface de recherche IA typique, similaire à ce que vous verriez dans ChatGPT, Claude ou Mode IA :

- Prompt conversationnel : la question de l’utilisateur.
- Message de vérification : un message indiquant que le LLM a décidé de rechercher des informations supplémentaires à utiliser dans sa réponse.
- Réponse : la réponse générée par l’IA au prompt de l’utilisateur.
- Mention : une entité (comme votre marque ou votre produit) citée directement dans la réponse.
- Citations : URL sources utilisées dans la génération de la réponse, généralement indiquées à la fin.
Pour vous aider à apparaître dans des réponses comme celles-ci, vous devez d’abord comprendre les processus fondamentaux qui permettent aux moteurs de recherche IA de fonctionner.
Comment l’entraînement fonctionne-t-il ?
Les LLM sont entraînés sur d’énormes volumes de contenu. En pratique, ils ont « lu » l’intégralité de Wikipédia, tout l’ensemble de données Common Crawl, l’ensemble de Google Livres, ainsi que des millions et des millions de pages de contenu web.
Ces données d’entraînement aident le LLM à « comprendre » le monde. Si votre entreprise de casques audio apparaît de nombreuses fois dans ses données d’entraînement, dans des contextes pertinents et aux côtés de qualificatifs positifs (« meilleur rapport qualité-prix », « parfait pour le sport », etc.), il y a de fortes chances qu’elle soit mentionnée dans les réponses du LLM pour des prompts liés aux casques audio.
Le saviez-vous ?
Ce processus d’entraînement est plus complexe que ce qui est décrit ici. Il existe des étapes de pré-entraînement pour supprimer le HTML, retirer les données d’identification, exclure des mots de listes de blocage et filtrer les données selon des langues spécifiques. Il existe aussi des étapes de post-entraînement pour entraîner le modèle de langage à se comporter davantage comme un assistant conversationnel utile (et pas seulement comme un prédicteur du prochain jeton). Pour en savoir plus, regardez la vidéo d’Andrej Karpathy, Analyse approfondie des LLM comme ChatGPT.


C’est là que le SEO basé sur les entités devient essentiel. Si votre marque apparaît de manière cohérente dans les Knowledge Graphs, est correctement structurée avec du balisage schéma et co-apparaît auprès d’entités pertinentes dans des contenus de haute qualité sur le web, vous construisez un « signal d’entité » plus fort dans les données d’entraînement.

Gianluca Fiorelli, Consultant en SEO stratégique et international/recherche IA
Il est important de noter que les LLM comportent de nombreuses bizarreries :
- Ils sont probabilistes : vous pouvez utiliser le même prompt et obtenir des réponses différentes à chaque fois. Cette nature probabiliste signifie que vous ne pouvez pas « optimiser un prompt » comme vous optimisez un mot-clé. Pensez plutôt en termes de distributions : quelle est la probabilité que votre marque apparaisse sur 100 prompts similaires ? C’est pourquoi il est préférable de suivre la visibilité moyenne sur de nombreux prompts plutôt que de se focaliser sur quelques prompts.
- Leurs connaissances ont une date de coupure : par défaut, les connaissances d’un LLM sont limitées à ce qui était inclus dans l’ensemble de données au moment où ce modèle spécifique a été entraîné. Chaque modèle est entraîné une seule fois sur un instantané des données jusqu’à une certaine date. De nouveaux modèles, avec des dates de coupure de connaissances plus récentes, sont déployés périodiquement (historiquement, environ tous les six mois).
- Ils hallucinent : ils peuvent affirmer avec assurance des choses fausses. Les LLM génèrent du texte en prédisant quels mots sont susceptibles de suivre, et non en vérifiant les faits. Bien qu’ils soient entraînés pour être utiles et précis, ils ne disposent d’aucun mécanisme intégré de vérification des faits, d’où l’importance de la vérification via la recherche sur le web.
Une idée reçue courante est que les LLM reçoivent des « mises à jour de connaissances » comme des correctifs logiciels. En réalité, chaque modèle est entraîné une seule fois sur un ensemble de données fixe. Quand vous voyez une nouvelle version de modèle avec une date de coupure des connaissances plus récente, il s’agit d’un tout nouveau modèle entraîné à partir de zéro, et non d’une mise à jour du modèle existant.
Gianluca Fiorelli, Consultant en SEO stratégique et international/recherche IA
Un moteur de recherche qui hallucine et partage des informations obsolètes ne semble pas très utile. C’est pourquoi les LLM surmontent certaines de ces limites grâce à un processus appelé vérification.
Comment la vérification et la RAG fonctionnent-elles ?
Les LLM peuvent vérifier et améliorer leurs réponses de deux façons : en utilisant des outils (comme des calculatrices ou d’autres API de données) ou en récupérant des informations supplémentaires depuis des sources externes. Ce deuxième processus est techniquement appelé Génération augmentée par récupération (RAG).
Lorsqu’un utilisateur pose une question, le LLM se demande : « Est-ce que je connais déjà la réponse, ou dois-je récupérer des informations supplémentaires ? ». Si le LLM peut prédire le prochain jeton avec une grande certitude (par exemple, des questions qui ne changent pas beaucoup, comme « à quoi servent les globules rouges ? »), il est probable qu’il réponde à partir de ses connaissances de base. Avec une faible certitude (pour des questions plus susceptibles d’évoluer, comme « quel est le meilleur moulin à café pas cher ? »), il peut utiliser son outil de recherche pour trouver des informations pertinentes issues d’autres sources sur Internet.
Les LLM sont affinés pour reconnaître des types de requêtes susceptibles de bénéficier d’informations supplémentaires, comme :
- Sujets en dehors du périmètre d’entraînement des modèles : « Quels sont les facteurs de classement internes utilisés par Keywords Explorer d’Ahrefs ? »
- Sujets qui nécessitent des informations récentes ou sensibles au facteur temps : « Quelle a été la plus récente mise à jour principale de Google et quand a-t-elle été déployée ? »
- Sujets qui demandent explicitement une recherche sur le web : « Recherche sur Internet des tactiques populaires de netlinking en 2026. »
- Prompts qui demandent des sources et des éléments probants : « Donne-moi des sources confirmant que Google utilise des signaux d’engagement des utilisateurs dans son algorithme. »
Certains modèles de LLM sont aussi très susceptibles de déclencher des recherches supplémentaires (par exemple, les modèles « Deep Research » sont spécifiquement configurés pour déclencher plusieurs recherches RAG).
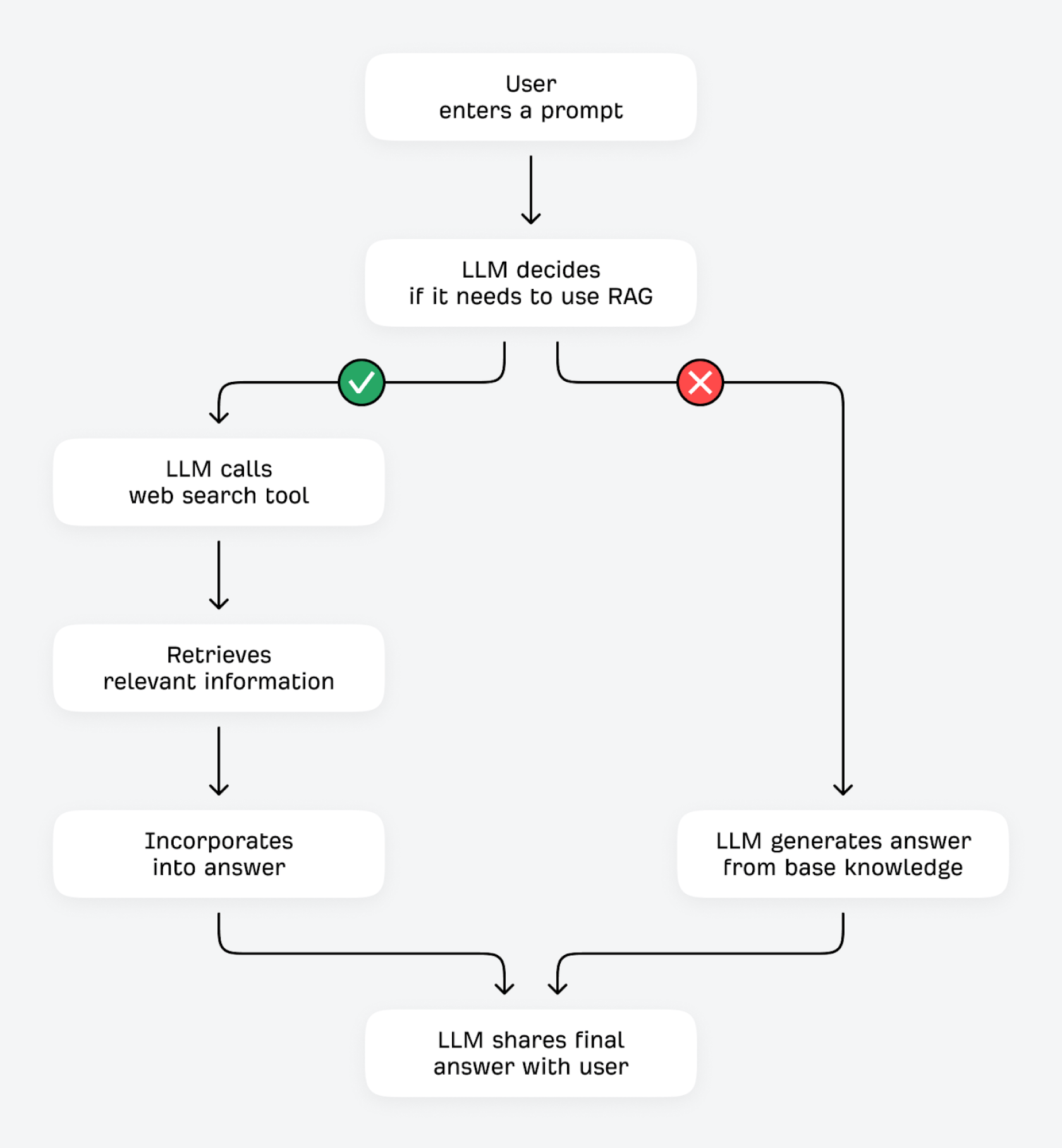
Ce processus, qui consiste à trouver une vérité terrain grâce à la RAG (souvent appelée « vérification »), offre plusieurs avantages. Le LLM peut améliorer l’exactitude factuelle et réduire les hallucinations en vérifiant ses réponses auprès de sources tierces. Il peut récupérer et partager des informations à jour, même si ses données d’entraînement sont relativement obsolètes. Il peut fournir des réponses plus détaillées et complètes, et offrir une meilleure transparence et une attribution plus claire pour tout ce qu’il partage.
Les moteurs de recherche IA effectuent cette vérification à l’aide d’un processus appelé « diffusion de requêtes ».
Comment la diffusion de requêtes fonctionne-t-elle ?
Il est important de noter que la diffusion des requêtes explique pourquoi le SEO traditionnel est essentiel pour la visibilité IA.
Les assistants IA comme ChatGPT, Gemini et Perplexity utilisent des index de recherche tels que Google, Bing et Brave pour récupérer des informations à jour.
Le fournisseur de recherche est important, car chacun comporte des algorithmes de classement, des index et une couverture différents : rendre votre marque visible dans la recherche Google peut améliorer votre visibilité dans Mode IA plus que dans ChatGPT, qui dépend davantage de Bing.
| Moteur de recherche IA | Index de recherche utilisés pour la vérification |
|---|---|
ChatGPT | Bing, Google |
Claude | Brave |
Gemini | Google |
Copilot | Bing |
Perplexity | In-house |
AI Mode | Google |
AI Overviews | Google |
Lorsqu’une recherche sur le web est déclenchée, le LLM demande des résultats pertinents à son index de recherche. L’index de recherche renvoie une liste de résultats et le LLM sélectionne les pages les plus pertinentes à explorer en évaluant des informations telles que le titre de la page, le contenu de l’extrait de page renvoyé et son actualisation (sa date de publication).
Pourquoi le SEO est-il essentiel pour la recherche IA ?
Cela mérite d’être répété : les moteurs de recherche traditionnels comme Google et Bing jouent un rôle crucial en aidant les moteurs de recherche IA à décider quels contenus mentionner et citer dans leurs réponses.
Autrement dit, un bon classement dans la recherche traditionnelle améliorera votre visibilité dans la recherche IA.
Mais que recherche exactement le LLM ?
Les LLM utilisent un processus appelé diffusion de requêtes. De nombreux prompts saisis dans ChatGPT et d’autres moteurs de recherche IA sont très longs, conversationnels et souvent totalement uniques. Effectuer une recherche Google avec ces prompts exacts n’apportera pas toujours de contenu utile.
Ainsi, au lieu d’effectuer une recherche sur le web avec la requête exacte de l’utilisateur…
« Je prépare une stratégie de contenu sur 6 mois pour une entreprise SaaS B2B de taille intermédiaire qui vend un produit d’analyse de données à des marques e-commerce. L’entreprise… »

…les LLM utilisent ce prompt initial pour générer une série de requêtes plus courtes et connexes afin de récupérer des informations pertinentes.
Ces requêtes de diffusion sont également générées par le grand modèle de langage et sont donc non déterministes, c’est-à-dire qu’elles peuvent changer régulièrement, y compris pour une même recherche.

Mark Williams-Cook, Fondateur, AlsoAsked
Ce processus devrait être familier aux SEO : ces requêtes associées ressemblent beaucoup aux mots-clés de longue traine, aux sous-intentions et aux questions « People Also Ask » :
- Cadres courants de stratégie de contenu B2B SaaS
- Exemples de contenu TOFU vs BOFU pour le SaaS
- Bonnes pratiques de mise à jour de contenu et de liens internes
- Métriques de croissance des demandes de démo générées par le contenu
En réalité, seuls 12 % des liens cités par ChatGPT, Gemini et Copilot apparaissent dans le top 10 des résultats Google pour le prompt initial de l’utilisateur. Toutefois, cela ne signifie pas que le classement traditionnel n’a plus d’importance. Les moteurs de recherche IA récupèrent du contenu en générant plusieurs requêtes de recherche, et ces requêtes de diffusion sont souvent des recherches plus traditionnelles et axées sur les mots-clés, pour lesquelles votre travail SEO existant a une grande importance.

La diffusion de requêtes est libératrice : vous n’avez pas besoin de deviner quels prompts conversationnels les internautes vont utiliser. Au lieu de cela, optimisez les requêtes décomposées, c’est-à-dire les composantes sémantiques que les LLM génèreront naturellement. Cela ressemble beaucoup à une recherche de mots-clés traditionnelle : [sujet] + [qualificatif], requêtes de comparaison, requêtes définitionnelles et contenus de « bonnes pratiques ». Votre recherche SEO existante couvre très probablement déjà l’espace de diffusion.
Gianluca Fiorelli, Consultant en SEO stratégique et international/recherche IA
Comment la récupération, la division en extraits et la synthèse des réponses fonctionnent-elles ?
Une fois qu’un LLM a récupéré des pages pertinentes depuis un index de recherche, il ne les lit pas intégralement. Les pages sont plutôt divisées en petits « extraits » de texte, le modèle priorisant (et parfois développant) des sections qui semblent les plus pertinentes pour la requête.
Ces extraits comportent généralement de quelques centaines à quelques milliers de mots chacun, soit une petite fraction de la plupart des pages web. Le LLM est aussi soumis à des limites strictes de fenêtre de contexte : il ne peut traiter qu’une quantité limitée de texte, y compris le prompt de l’utilisateur, tous les extraits récupérés et sa propre réponse. Cela signifie qu’il doit être très sélectif quant au contenu qu’il récupère et inclut.
Voici un exemple :
| Contenu de la page entière | « La vérification est un flux de travail dans lequel le modèle récupère des sources externes, en extrait des faits pertinents et utilise ces extraits pour réduire les hallucinations et améliorer l’actualisation.… Il analyse ensuite plusieurs sources, compare les informations et synthétise une réponse plutôt que de copier le texte mot pour mot. Cette étape de synthèse permet d’éviter une dépendance excessive à une seule source. » |
| Extrait | « Explique comment les assistants utilisent la recherche sur le web pour récupérer des sources externes et réduire les hallucinations en fondant les réponses sur des faits récupérés. » |
| Développement (lignes 1–2) | « La vérification est un flux de travail dans lequel le modèle récupère des sources externes, en extrait des faits pertinents et utilise ces extraits pour réduire les hallucinations et améliorer l’actualisation. Le modèle évalue si une requête nécessite des informations à jour ou vérifiables avant de lancer une recherche sur le web. » |
| Développement (lignes 33–34) | « Il analyse ensuite plusieurs sources, compare les informations et synthétise une réponse plutôt que de copier le texte mot pour mot. Cette étape de synthèse permet d’éviter une dépendance excessive à une seule source. » |
Facilitez la compréhension de votre contenu par les LLM
Point important : lorsque les moteurs de recherche IA récupèrent votre contenu sur Internet, ils ne peuvent consulter que des extraits partiels, et non la page entière. Pour maximiser les chances d’être cité dans la réponse du LLM, la pertinence et la valeur de votre page doivent être faciles à comprendre pour les LLM, même sans avoir accès à la page entière.
Le moteur de recherche IA intègre ensuite ce texte à son processus de génération de réponses.
Le contenu web brut est vérifié dans la réponse du modèle : les extraits de texte ou de données obtenus à l’étape précédente sont ajoutés au contexte du modèle, ce qui revient à dire : « Voici un contexte issu du web qui pourrait être utile ; maintenant, réponds à la question de l’utilisateur en t’appuyant sur ces informations. »
Comment les citations sont-elles choisies ?
À partir de là, le modèle génère une réponse en associant ses connaissances intrinsèques avec le contenu récupéré, puis la partage avec l’utilisateur. La réponse inclut généralement des citations : des URL cliquables menant aux sources utilisées pendant le processus de vérification.
Toutes les pages récupérées par le moteur de recherche IA ne feront pas forcément l’objet d’une citation dans la réponse finale. Le modèle sélectionne les sources à citer en fonction de plusieurs facteurs :
- Pertinence : dans quelle mesure le contenu récupéré a contribué directement à des affirmations précises dans la réponse.
- Actualisation : à quel point la source est récente.
- Diversité : degré de diversité des sources citées (les moteurs de recherche IA préférant souvent citer plusieurs sources différentes plutôt que de citer la même source à répétition).
Cela signifie que même si votre contenu est récupéré et lu, rien ne garantit l’obtention d’une citation visible ; le contenu doit être jugé directement pertinent pour étayer une affirmation précise dans la réponse.
Comment la personnalisation fonctionne-t-elle ?
Il s’agit de la base du fonctionnement des moteurs de recherche IA, mais il y a un niveau de complexité supplémentaire : la personnalisation.
ChatGPT et d’autres moteurs de recherche IA peuvent personnaliser leurs résultats pour chaque utilisateur : un même prompt peut donc générer des résultats différents selon les personnes. La personnalisation peut être influencée de plusieurs façons, notamment :
- Contexte actuel de la conversation : les messages précédents dans la même conversation influenceront la réponse au prompt actuel. Mentionnez que vous accordez de l’importance à la « durabilité » de votre équipement de randonnée, et vous pouvez vous attendre à ce que ChatGPT inclue ce critère dans sa recherche lorsque vous demanderez des « recommandations de sacs à dos » plus tard dans la conversation.
- Mémoire : de nombreux LLM disposent d’une fonctionnalité de mémoire qui permet au système de conserver certains faits ou certaines préférences d’une conversation à l’autre. Par exemple, avec la mémoire activée, ChatGPT déduira et retiendra des détails que vous avez partagés (comme votre nom ou vos centres d’intérêt) et les reprendra dans de futures conversations afin de personnaliser ses réponses.
- Lieu, heure, date : de nombreux moteurs de recherche IA peuvent déduire des informations vous concernant et adapter leurs réponses en conséquence : de l’utilisation de votre adresse IP pour estimer votre localisation (pour des requêtes comme « brunch à proximité ») à la date et à l’heure (« liste de matériel pour le camping » pourrait recommander une tente 4 saisons en hiver et une tente 3 saisons en été).
- Prompts système : toute préférence spécifique partagée dans le message système influencera vos conversations (ajouter « rappelle-toi que je suis vegan » au prompt système influencera les réponses à des prompts comme « idées de petit-déjeuner sain »).
Voici une analogie pour comprendre les prompts système. Si vous jouez au football, les « données d’entraînement » sont tout l’entraînement que vous avez accumulé au fil des années, la mémoire musculaire à long terme. Le prompt système représente ce que votre entraîneur vous dit juste avant d’entrer sur le terrain. Il s’agit d’une mémoire puissante à court terme qui est le plus susceptible d’influencer le résultat.
Mark Williams-Cook, Fondateur, AlsoAsked

C’est pourquoi il est conseillé de suivre la visibilité moyenne de votre marque et de votre site web au fil du temps et sur de nombreux prompts, plutôt que de se focaliser sur la réponse à un prompt unique.
Conclusion
Chaque moteur de recherche IA (de ChatGPT à Perplexity en passant par Mode IA de Google) est légèrement différent, mais les processus principaux restent les mêmes. De plus, point important pour les SEO et les professionnels du marketing, les moteurs de recherche traditionnels comme Google et Bing fournissent une grande partie de l’infrastructure nécessaire au fonctionnement des moteurs de recherche IA. L’optimisation pour la recherche IA dépend fortement des meilleures pratiques du SEO traditionnel.
Pour aller plus loin
Ryan Law est le directeur du marketing de contenu chez Ahrefs. Il a 13 ans d’expérience en tant que rédacteur, stratège de contenu, chef d’équipe, vice-président, directeur marketing et fondateur d’agence. Il a aidé des dizaines d’entreprises à améliorer leur marketing de contenu et leur SEO, notamment Google, Zapier, GoDaddy, Clearbit et Algolia. Il est aussi romancier et le créateur de deux cours sur le marketing de contenu.
Maîtriser le SEO étape par étape
Comment les moteurs de recherche fonctionnent-ils ?
Avant de commencer à apprendre le SEO, vous devez comprendre le fonctionnement des moteurs de recherche.
SEO de base
Apprenez à configurer votre site Web pour le succès du SEO et à vous familiariser avec les quatre principales facettes du SEO.
Recherche de mots-clés
Le point de départ du SEO est de comprendre ce que recherchent vos clients cibles.
Contenu SEO
Apprenez à créer du contenu qui se classe dans les moteurs de recherche.
SEO on-page
C'est là que vous optimisez vos pages pour aider les moteurs de recherche à les comprendre.
Link Building
Apprenez à créer du contenu qui se classe dans les moteurs de recherche.
SEO technique
Prévenez les problèmes techniques qui empêchent Google d’accéder à votre site web et de le comprendre.
Référencement local
Découvrez comment améliorer votre visibilité dans les résultats de recherche locale et attirer plus de clients dans votre zone.
L’impact de l’IA sur le SEO
Vous ne pouvez pas parler de SEO aujourd’hui sans mentionner l’IA générative.
Comment les moteurs de recherche IA fonctionnent-ils ?
Découvrez précisément comment les moteurs de recherche IA comme ChatGPT génèrent leurs réponses et choisissent les marques et produits à mentionner.