
Da du gerade diesen Artikel liest, denke ich, dass dies für dich nichts Neues ist. Kommen wir also gleich zum Punkt.
Dieser Artikel zeigt dir, wie man die folgenden Probleme löst:
- Deine gesamte Website ist nicht im Index.
- Einige deiner Seiten sind im Index, aber andere nicht.
- Neu veröffentlichte Seiten kommen nicht schnell genug in den Index.
Aber zuerst stellen wir sicher, dass wir vom Gleichen reden, bevor wir uns in das Indexierungswirrwar stürzen.
Google entdeckt neue Webseiten, indem es das Web durchsucht und dann die gefundenen Seiten hinzufügt. Sie tun das mit Hilfe einer Webspinne namens Googlebot.
Verwirrt? Lass uns ein paar Schlüsselbegriffe definieren.
- Crawling: Der Prozess, Hyperlinks im Web zu folgen, um neue Inhalte zu entdecken.
- Indexing: Der Prozess der Speicherung jeder Webseite in einer umfangreichen Datenbank.
- Web spider: Eine Software, die entwickelt wurde, um den Crawling-Prozess maßstabsgetreu durchzuführen.
- Googlebot: Google’s Webspinne (orig.: web spider).
Hier ist ein Video von Google das den Prozess detailiert erklärt:
Wenn Du etwas googlest, bittest Du Google, alle relevanten Seiten aus dem Index anzuzeigen. Da es oft Millionen von Seiten gibt, die der Anfrage entsprechen, tut der Ranking-Algorithmus von Google sein Bestes, um die Seiten so zu sortieren, dass Du zuerst die besten und relevantesten Ergebnisse siehst.
Der kritische Punkt, den ich hier anführe ist, dass Indexierung und Ranking zwei verschiedene Dinge sind.
Die Indexierung ist die Grundlage, die Rangliste das Ergebnis. In einem Formel 1 Rennen würde man sagen: Die Indexierung ist das Rennen, die Rangliste zeigt, wer gewinnt.
Du kannst nicht gewinnen, ohne überhaupt zum Rennen anzutreten.
Suche in Google nach site:deinewebseite.com
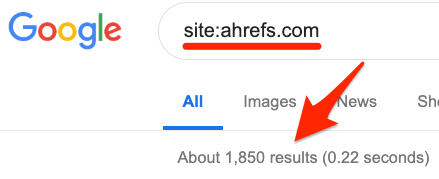
Die Anzahl zeigt ungefähr, wie viele Seiten Google indexiert hat.
Wenn Du den Index-Status einer spezifischen URL prüfen möchtest, dann nutze denselben site:deinewebseite.com/web-page-slug Operator.
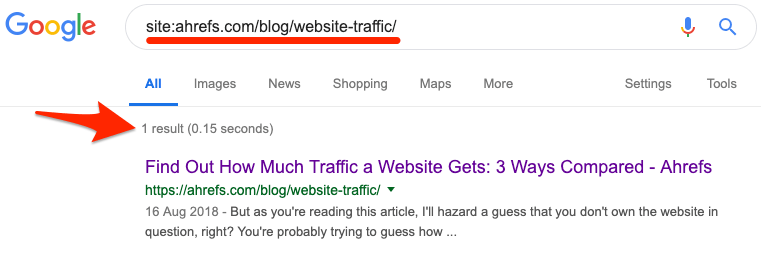
Wenn Du kein Ergebnis siehst, ist die Seite nicht indexiert.
Nun ist wichtig zu erwähnen, dass wenn du die Google Search Console nutzt, du den Coverage Report ansehen kannst, um einen exakten Einblick in den Status der Indexierung der Website zu erhalten. Gehe dazu einfach hierhin:
Google Search Console > Index > Coverage
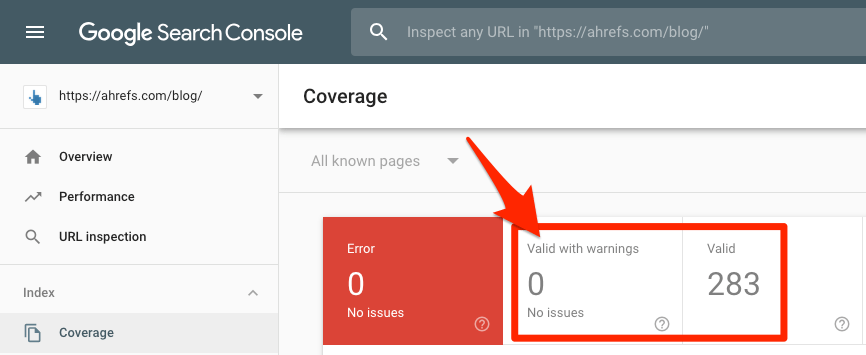
Schau dir die Anzahl von gültigen Seiten an (mit und ohne Fehler-Warnungen).
Wenn diese Zahlen größer sind als Null, dann hat Google zumindest irgendetwas im Index. Wenn nicht, dann hast Du ein größeres Problem, denn keine deiner Webseiten sind indexiert.
Du kannst die Search Console auch dazu nutzen zu prüfen, ob eine spezifische Seite indexiert ist. Dazu kopierst du einfach die betreffende URL in das URL Inspection tool.
Wenn die Seite im index ist, erhältst du die Antwort “URL is on Google.”
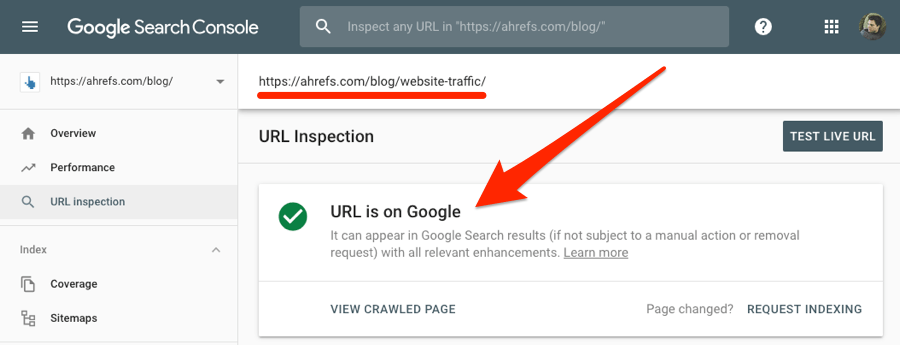
Wenn nicht, dann steht da “URL is not on Google.”
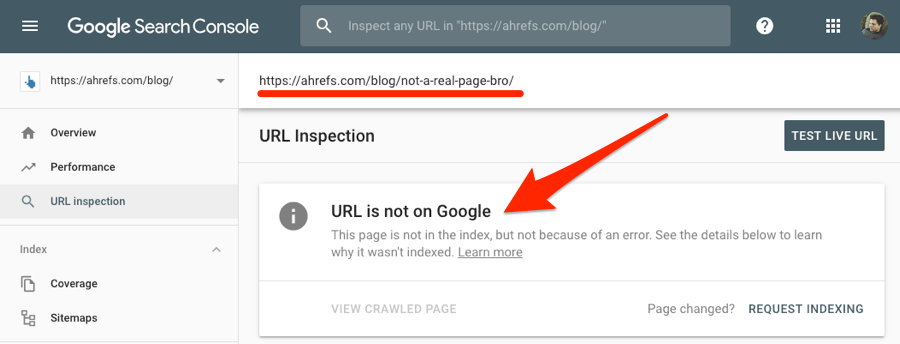
Hast du herausgefunden, dass deine Webseiten nicht von Google indexiert wurden? Dann versuche das hier:
- Gehe zur Google Search Console
- Navigiere zum URL inspection tool
- Kopiere die URL, von der du möchtest, dass sie im Index landet in das Suchfeld.
- Warte bis Google die URL geprüft hat
- Klicke den “Request indexing” Knopf
Dieser Prozess ist eine gute Vorgehensweise, wenn Du einen neuen Beitrag oder eine neue Seite veröffentlichst. Du sagst Google effektiv, dass Du etwas Neues zu deiner Website hinzugefügt hast und dass sie einen Blick darauf werfen sollten.
Es ist jedoch unwahrscheinlich, dass die Anforderung einer Indexierung die zugrundeliegenden Probleme löst, die Google daran hindern, alte Seiten zu indexieren. Wenn dies der Fall ist, folge der folgenden Checkliste, um das Problem zu diagnostizieren und zu beheben.
Hier sind einige Schnelllinks zu jeder Taktik — falls Du bereits welche ausprobiert hast:
- Beseitige Crawl Blocks in der robots.txt Datei
- Beseitige unerwünschte noindex tags
- Nimm die Seite in Sitemap auf
- Beseitige unterwünschte canonical tags
- Prüfe, ob die Seite verwaist ist
- Fixe nofollow internal links
- Füge “starke” interne Links hinzu
- Versicher dich, dass die Seite wertvoll und einzigartig ist
- Beseitige minderwertige Seiten (damit das Crawl Budget optimiert wird)
- Baue hochwertige Backlinks auf
1) Beseitige Crawl Blocks in deiner robots.txt Datei
Indexiert Google nicht deine ganze Website? Es könnte an einem Crawlblock in einer so genannten robots.txt-Datei liegen.
Um nach diesem Problem zu suchen, gehe zu yourdomain.com/robots.txt.
Suche nach einem dieser beiden Codeausschnitte:
User-agent: Googlebot Disallow: /
User-agent: * Disallow: /
Beide sagen Googlebot, dass sie keine Seiten auf deiner Website durchsuchen dürfen. Um das Problem zu beheben, entferne sie. So einfach ist das.
Ein Crawlblock in der robots.txt könnte auch der Täter sein, wenn Google nicht eine einzige Webseite indiziert. Um zu überprüfen, ob dies der Fall ist, füge die URL in das URL-Inspektionswerkzeug in der Google Search Console ein. Klicke auf den Block Abdeckung, um weitere Details anzuzeigen, und suche dann nach dem Punkt “Crawl allowed? Nein: blockiert durch den Fehler robots.txt”.
Dies bedeutet, dass die Seite in der robots.txt blockiert ist.
Wenn dies der Fall ist, überprüfe die Datei robots.txt erneut auf “verbotene” Regeln in Bezug auf die Seite oder den zugehörigen Unterabschnitt.

Wichtige Seite in der robots.txt für die Indexierung gesperrt.
Bei Bedarf entfernen.
2) Beseitige unerwünschte noindex tags
Google wird keine Seiten indizieren, wenn man ihnen sagt, dass sie es nicht tun sollen. Dies ist nützlich, um einige Webseiten privat zu halten. Es gibt zwei Möglichkeiten, dies zu tun:
Methode 1: meta tag
Seiten mit einem dieser meta tags im <head> Bereich werden von Google nicht indexiert:
<meta name=“robots” content=“noindex”>
<meta name=“googlebot” content=“noindex”>
Das ist ein meta robots tag, welches den Suchmaschinen sagt, ob die Seite indexiert werden kann oder nicht.
Um alle Seiten mit einem Noindex-Meta-Tag auf der Website zu finden, führst du einen Crawl mit dem Ahrefs’ Site Audit durch. Gehe zum Bericht Indexierbarkeit und suche dort nach den Warnung “Noindex Page”.
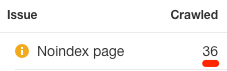
Klicke dich durch, um alle betroffenen Seiten zu finden. Entferne das noindex meta tag auf den Seiten, wo du es nicht hingehört.
Methode 2: X‑Robots-Tag
Crawler respektieren auch den X‑Robots-Tag HTTP Response Header. Man kann dies mit einer serverseitigen Skriptsprache wie PHP, in der .htaccess-Datei oder durch Ändern der Serverkonfiguration implementieren.
Das URL-Inspektionstool in der Search Console zeigt dir an, ob Google aufgrund dieses Headers vom Crawlen einer Seite abgehalten wird. Gib einfach deine URL ein und suche nach dem “Indizierung erlaubt? Nein: ‘noindex’ erkannt im ‘X‑Robots-Tag’ http header”.

Wenn du das für deine gesamte Website prüfen willst, nutze den Crawl im Ahrefs’ Site Audit Tool. Dann nutze “Robots information in HTTP header” als Filter im Page Explorer:
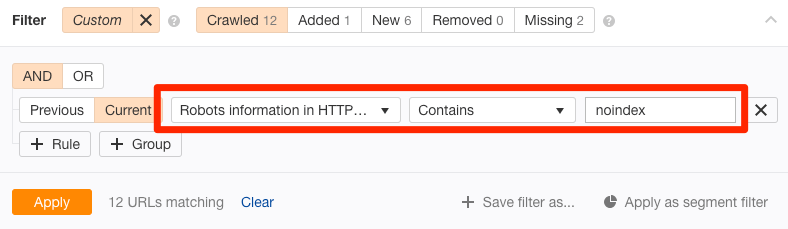
Sag deinem Entwickler, dass er Seiten die du indexieren möchtest, von der Rückgabe dieses Headers ausschließen soll.
Empfohlene Lektrüre: Using the X‑Robots-Tag HTTP Header Specifications in SEO: Tips and Tricks
3) Nimm die Seite in Sitemap auf
Eine Sitemap sagt Google, welche Seiten auf deiner Website wichtig sind und welche nicht. Es kann auch eine Anleitung geben, wie oft sie neu gecrawlt werden sollten.
Google sollte in der Lage sein, Seiten auf deiner Website zu finden, unabhängig davon, ob sie sich in deiner Sitemap befinden, aber es ist immer noch eine gute Praxis, sie aufzunehmen. Schließlich macht es keinen Sinn, Google das Leben schwer zu machen.
Um zu überprüfen, ob sich eine Seite in deiner Sitemap befindet, verwende das URL-Inspektionswerkzeug in der Suchkonsole. Wenn du den Fehler “URL ist nicht bei Google” und “Sitemap: N/A” entdeckst, dann ist es nicht in deiner Sitemap oder indiziert.
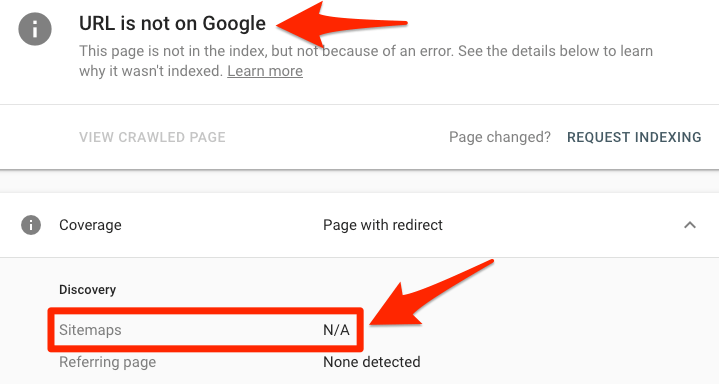
Du benutzt Search Console nicht? Springe zu deiner sitemap URL—normalerweise, yourdomain.com/sitemap.xml—und suche nach dieser Seite.

Oder wenn du alle durchsuchbaren und indizierbaren Seiten finden möchtest, die sich nicht in der Sitemap befinden, führe einen Crawl aus mit dem Ahrefs’ Site Audit. Gehe dann zum Page Explorer und setze diese Filter:
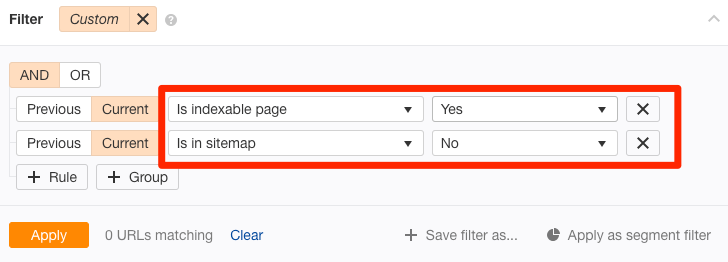
Diese Seiten sollten in der Sitemap sein, also füge sie hinzu. Danach lässt du Google wissen, dass du die Sitemap editiert hast und springst zu dieser Seite:
http://www.google.com/ping?sitemap=http://deinewebseite.com/sitemap_url.xml
Ersetze den hinteren Teil mit deiner Sitemap-URL. Du solltest dann das hier lesen:

Das sollte dabei helfen, dass Google die Seiten indexiert.
4) Beseitige unterwünschte canonical tags
Ein kanonisches Tag sagt Google, welche die bevorzugte Version einer Seite ist. Es sieht ungefähr so aus:
<link rel="canonical” href="/page.html/">
Die meisten Seiten haben entweder kein kanonisches Tag, oder ein so genanntes selbstreferenzierendes kanonisches Tag. Das sagt Google, dass die Seite selbst die bevorzugte und wahrscheinlich die einzige Version der Seite ist. Mit anderen Worten, du möchtest, dass diese Seite indiziert wird.
Aber wenn deine Seite ein fehlerhaftes kanonisches Tag hat, dann könnte es sein, dass du Google von einer bevorzugten (anderen) Version dieser Seite erzählst, die nicht existiert. In diesem Fall wird deine Seite nicht indiziert werden.
Um nach einem Canonical zu suchen, verwendst du das URL-Inspektionstool von Google. Dort gibt es eine “Alternative Seite mit kanonischem Tag” Warnung, wenn das Canonical Tag auf eine andere Seite verweist
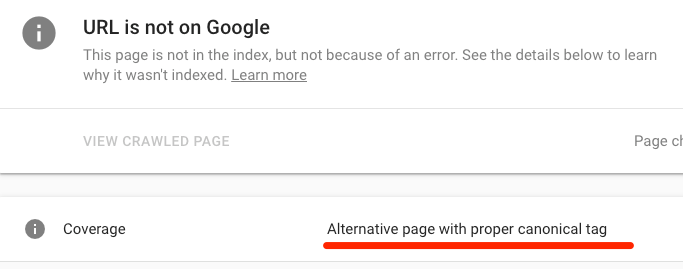
Wenn dieser Fall unerwünscht ist und du die Seite gerne im Index hättest, dann entferne das Canonical Tag.
Canonical-Tags sind nicht immer schlecht. Die meisten Seiten mit diesen Tags werden diese aus einem bestimmten Grund haben. Wenn Du feststellst, dass deine Seite ein Canonical hat, dann überprüfe die kanonische Seite. Wenn dies tatsächlich die bevorzugte Version der Seite ist und es nicht notwendig ist, auch die betreffende Seite zu indizieren, dann sollte das kanonische Tag bleiben.
Wenn du einen schnellen Weg willst, um fehlerhafte kanonische Tags auf deiner gesamten Website zu finden, führe einen Crawl in Ahrefs’ Site Audit Tool aus. Rufe den Page-Explorer auf. Verwende diese Einstellungen:
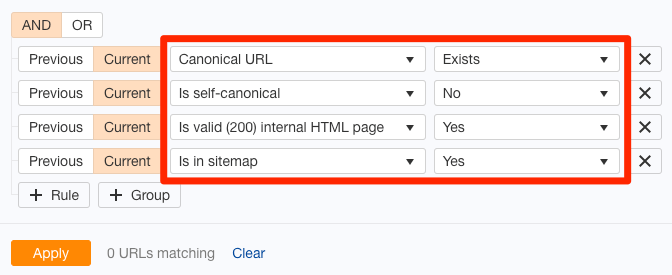
Dies sucht nach Seiten in deiner Sitemap mit nicht selbstreferenzierenden kanonischen Tags. Da du die Seiten in deiner Sitemap mit ziemlicher Sicherheit indizieren möchtest, solltest du weiter untersuchen, ob dieser Filter irgendwelche Ergebnisse liefert.
Es ist sehr wahrscheinlich, dass diese Seiten entweder einen kanonischen Fehler haben oder gar nicht in deiner Sitemap stehen sollten.
5) Prüfe, ob die Seite verwaist ist
Orphan pages are those without internal links pointing to them.
Orphan Pages sind solche ohne interne Links, die auf sie verweisen.
Da Google durch das Crawlen des Internets neue Inhalte entdeckt, können sie durch diesen Prozess keine verwaisten Seiten entdecken. Auch Website-Besucher werden sie nicht finden können.
Um nach verwaisten Seiten zu suchen, durchsuche deine Website mit Ahrefs’ Site Audit. Überprüfe anschließend den Bericht Eingehende Links auf “Orphan Page (hat keine eingehenden internen Links)” Fehler:

Hier werden alle Seiten angezeigt, die sowohl indizierbar als auch in deiner Sitemap vorhanden sind, aber keine internen Links haben, die auf sie verweisen.
Dieser Prozess funktioniert nur, wenn diese beiden Punkte mit “richtig” beantwortet werden können:
- Alle Seiten, die du indizieren möchtest, befinden sich in deinen Sitemaps
- Du hast das Kontrollkästchen aktiviert, um die Seiten in deinen Sitemaps als Ausgangspunkt für das Crawlen beim Einrichten des Projekts in Ahrefs’ Site Audit zu verwenden.
Du bist nicht sicher, ob alle Seiten, die du indizieren möchtest, in deiner Sitemap enthalten sind? Probier das mal:
- Lade eine vollständigen Liste von Seiten auf deiner Website herunter (über dein CMS)
- Durchsuche deine Website (mit einem Tool wie Ahrefs’ Site Audit)
- Erstelle Querverweise auf die beiden Listen der URLs
Alle URLs, die während des Crawls nicht gefunden werden, sind verwaiste Seiten.
Du kannst verwaiste Seiten auf zwei Arten reparieren:
- Wenn die Seite unwichtig ist, lösche und entferne sie aus deiner Sitemap.
- Wenn die Seite wichtig ist, integriere sie in die interne Linkstruktur deiner Website.
6) Repariere interne nofollow links
Nofollow links sind links mit einem rel=“nofollow” tag. Sie verhindern die Vererbung von PageRank auf die Ziel-URL. Der Google-Crawler folgt diesen Links nicht.
Das sagt Google über die Gründe:
Im Wesentlichen bewirkt die Verwendung von nofollow, dass wir die Ziellinks aus unserem Gesamtverzeichnis des Webs entfernen. Die Zielseiten können jedoch weiterhin in unserem Index erscheinen, wenn andere Websites ohne Verwendung von nofollow auf sie verweisen oder wenn die URLs in einer Sitemap an Google übermittelt werden.
Kurz gesagt, solltest du darauf achten, dass alle internen Links zu indizierbaren Seiten eingehalten werden.
Benutze dazu das Site Audit-Tool von Ahrefs, um deine Website zu durchsuchen. Prüfe den Bericht über eingehende Links (Incoming links report)auf indizierbare Seiten mit dem Fehler “Seite hat nur eingehende interne Links”:

Lösche das nofollow-Tag von diesen internen Links, vorausgesetzt, du möchtest, dass Google die Seite indiziert. Wenn nicht, dann lösche entweder die Seite oder setze sie auf noindex.
Empfohlene Artikel: What Is a Nofollow Link? Everything You Need to Know (No Jargon!)
7) Füge “starke” interne Links hinzu
Google entdeckt neue Inhalte, indem es die Website durchsucht. Wenn du es versäumst, intern auf die betreffende Seite zu verlinken, dann kann es sein, dass Google diese nicht finden kann.
Eine einfache Lösung für dieses Problem ist es, einige interne Links zur Seite hinzuzufügen. Du kannst das von jeder anderen Webseite aus tun, die Google crawlen und indizieren kann. Wenn du jedoch möchtest, dass Google die Seite so schnell wie möglich indiziert, ist es sinnvoll, dies von einer deiner “mächtigeren” Seiten aus zu tun.
Warum? Weil Google wahrscheinlich solche Seiten schneller neu aufnehmen wird als weniger wichtige Seiten.
Hierzu wählst du den Ahrefs’ Site Explorer, gibst deine Domain ein und besuchst dann den Bericht Best by links.
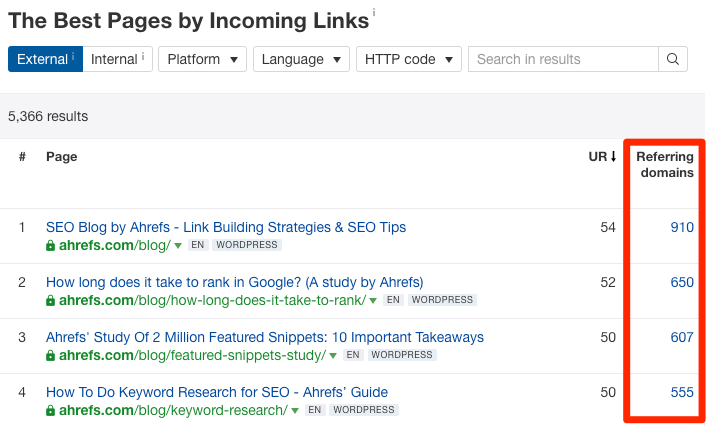
Hier werden alle Seiten deiner Website nach URL Rating (UR) sortiert angezeigt. Mit anderen Worten, es zeigt zuerst die maßgeblichen Seiten an.
Stöber in dieser Liste und schaue nach relevanten Seiten, von denen aus interne Links zu der betreffenden Seite hinzufügbar wären.
Zum Beispiel, wenn du einen internen Link zu unserem guest posting guide hinzufügen willst, wäre der link building guide wahrscheinlich ein relevanter Ort, das zu tun. Und die Seite wäre zudem die elftstärkste Seite auf unserem Blog:

Google erkennt dann den Link und folgt ihm beim nächsten besucht der Seite.
Fügt die Seite, von der aus ihr den internen Link hinzugefügt habt, in das URL-Inspection-Tool von Google ein. Klick auf die Schaltfläche “Request indexing”, um Google wissen zu lassen, dass sich etwas auf der Seite geändert hat und dass sie das Ganze so schnell wie möglich neu erstellen sollte. Dies kann den Prozess der Entdeckung des internen Links und damit der Seite, die du indizieren möchtest, beschleunigen
8) Versichere dich, dass die Seite einzigartig und wertvoll ist
Es ist unwahrscheinlich, dass Google minderwertige Seiten indiziert, da sie keinen Wert für die Nutzer haben. Hier ist, was John Müller von Google über die Indexierung im Jahr 2018 sagte:
https://twitter.com/JohnMu/status/948544364090970112
Er deutet an, dass, wenn du willst, dass Google deine Website oder Webseite indiziert, sie “fantastisch und inspirierend” sein muss.
Wenn du technische Probleme wegen der fehlenden Indexierung ausgeschlossen hast, dann könnte ein Wertmangel der Schuldige sein. Aus diesem Grund lohnt es sich, die Seite mit neuen Augen zu betrachten und sich zu fragen: Ist diese Seite wirklich wertvoll? Würde ein Benutzer wertvolle Informationen auf dieser Seite finden, wenn er ihn in den Suchergebnissen anklickt?
Wenn die Antwort auf eine dieser Fragen nein ist, dann musst du deinen Inhalt verbessern.
Du kannst noch mehr potenziell minderwertige Seiten finden, die nicht indexiert werden mit dem Ahrefs’ Site Audit tool und dem URL Profiler. Gehe dafür zum Page Explorer in Ahrefs’ Site Audit und verwende diese Einstellungen:
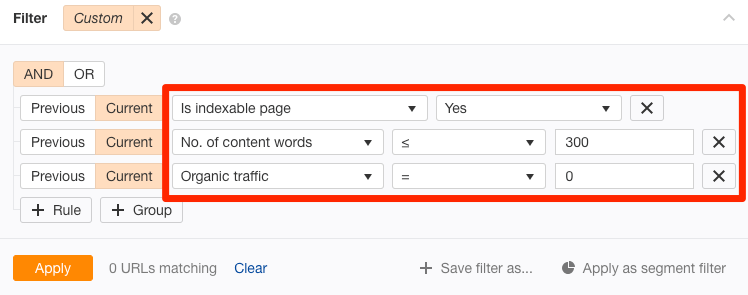
Dies gibt “dünne” Seiten zurück, die indizierbar sind und derzeit keinen organischen Traffic erhalten. Mit anderen Worten, es besteht eine gute Chance, dass sie nicht indiziert sind.
Der Bericht wird exportiert, dann werden alle URLs in den URL Profiler eingefügt und eine Google Indexierungsprüfung durchgeführt.
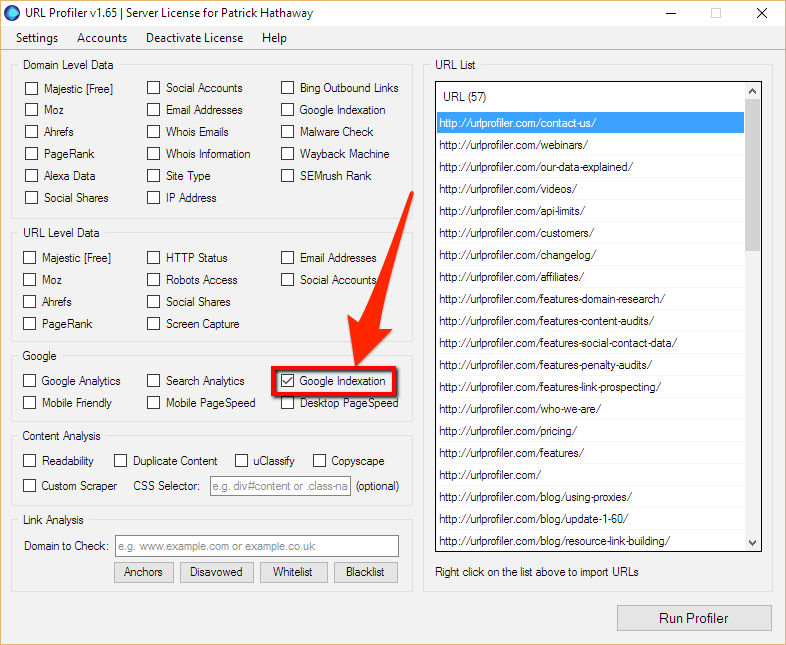
Quelle: https://urlprofiler.com/blog/google-indexation-checker-tutorial/
Es wird empfohlen, Proxies zu verwenden, wenn du dies für viele Seiten (z.B. über 100) tust. Andernfalls besteht die Gefahr, dass deine IP-Adresse von Google gesperrt wird. Wenn dies nicht möglich ist, besteht eine weitere Alternative darin, Google nach einem “kostenlosen Google-Indexierungsprüfer für große Mengen” zu suchen. Es gibt ein paar dieser Tools, aber die meisten sind auf <25 Seiten auf einmal beschränkt.
Kontrolliere alle nicht indexierten Seiten auf Qualitätsprobleme. Wenn nötig, verbessere die Seiten und fordere dann eine Neuindizierung in der Google Search Console an.
Du solltest auch versuchen, Probleme mit doppeltem Inhalt zu beheben. Es ist unwahrscheinlich, dass Google doppelte oder nahezu doppelte Seiten indiziert. Benutze den Bericht zur Inhaltsqualität (Duplicate content report) in Site Audit, um diese Probleme zu überprüfen.
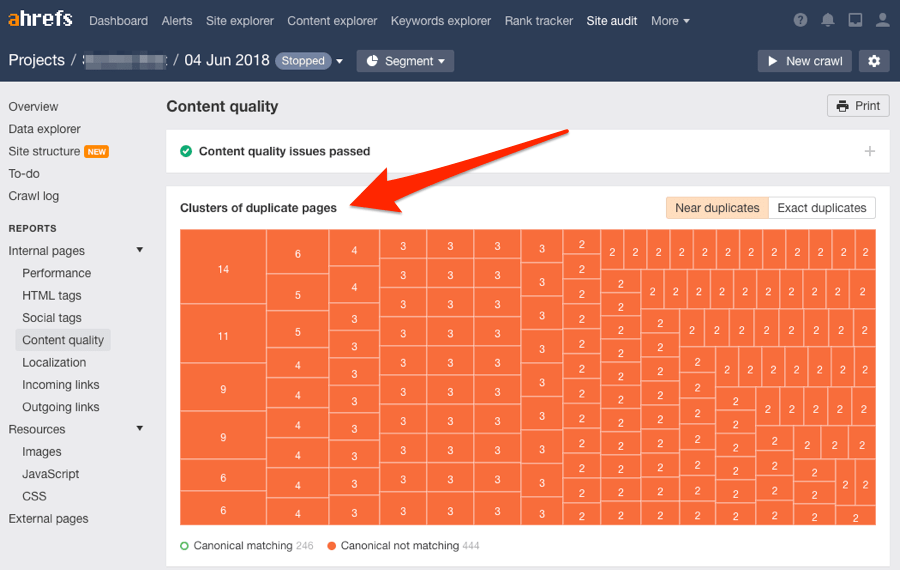
9) Beseitige minderwertige Seiten (und optimiere so das “crawl budget”)
Zu viele minderwertige Seiten auf der Webseite sind eine Verschwendung für das Crawl Budget.
Das sagt Google dazu:
Die Verschwendung von Serverressourcen auf[Seiten mit geringer Wertschöpfung] entzieht Crawl-Aktivitäten von Seiten, die tatsächlich einen Wert haben, was zu einer erheblichen Verzögerung bei der Entdeckung großartiger Inhalte auf einer Website führen kann.
Betrachte es als einen Lehrer, der Essays bewertet, von denen einer deiner ist. Wenn er zehn Aufsätze zu bewerten hat, wird er ziemlich schnell zu dir kommen. Wenn er hundert hat, wird es etwas länger dauern. Wenn er Tausende hat, ist seine Arbeitsbelastung zu hoch, und er kommt vielleicht nie dazu, deinen Aufsatz zu bewerten.
Google erklärt, dass “Crawl Budget [.…] nicht etwas ist, worüber sich die meisten Publisher Sorgen machen müssen”, und dass “wenn eine Website weniger als ein paar tausend URLs hat, sie meistens effizient gecrawlt wird”.
Dennoch ist das Entfernen von Seiten mit niedriger Qualität von der Website nie eine schlechte Sache. Es kann sich nur positiv auf das Crawl-Budget auswirken.
Du kannst unser content audit template nutzen, um potenziell minderwertige und irrelevante Seiten zu entdecken.
10) Baue hochwertige Backlinks auf
Backlinks zeigen Google die Wichtigkeit von Webseiten. Wenn eine Seite auf eine andere Seite verlinkt, muss diese schließlich einen gewissen Wert haben. Und das sind Seiten, die Google indexieren möchte.
Für volle Transparenz indiziert Google nicht nur Webseiten mit Backlinks. Es gibt viele (Milliarden) indizierte Seiten ohne Backlinks. Da Google jedoch Seiten mit hochwertigen Links für wichtiger hält, werden sie solche Seiten wahrscheinlich schneller crawlen und neu crawlen als die anderen. Das führt zu einer schnelleren Indexierung.
Wir haben viele Ressourcen, um hochwertige Backlinks im Blog zu erstellen.
Schau einfach mal in einen der nachstehend gelisteten Guides.
Indexing ≠ ranking
Die Indizierung deiner Website oder Webseite in Google bedeutet nicht, dass du ein Ranking oder Traffic erhältst.
Es gibt zwei verschiedene Dinge.
Indizierung bedeutet, dass Google von deiner Website Kenntnis hat. Das bedeutet nicht, dass man es für alle relevanten und lohnenden Fragen bewerten wird.
An dieser Stelle kommt SEO ins Spiel, um deine Webseiten für spezifische Anfragen zu optimieren.
Kurz gesagt, SEO beinhalte:
- Herauszufinden, was Kunden suchen;
- Inhalte um diesen Themen zu kreieren;
- Diese Seiten für die Ziel-Keywords zu optimieren;
- Backlinks aufbauen;
- Regelmäßig Inhalte wieder neu veröffentlichen und daraus einen “Evergreen”-Inhalt zu machen.
Hier ein Video wie du mit SEO anfängst:
… und ein bisschen Lektüre:
Abschließende Gedanken
Es gibt nur zwei mögliche Gründe, warum Google deine Website oder Internetseite nicht indiziert:
- Technische Probleme hindern sie daran, dies zu tun
- Sie sehen deine Website oder Seite als minderwertig und wertlos für ihre Nutzer.
Es ist durchaus möglich, dass beide Probleme existieren. Ich würde jedoch sagen, dass technische Probleme weitaus häufiger auftreten. Technische Probleme können auch zur automatischen Generierung von indizierbaren Inhalten mit geringer Qualität führen (z.B. Probleme mit der facettierten Navigation). Das ist nicht gut.
Dennoch sollte das Durchlaufen der obigen Checkliste das Problem der Indexierung neunmal von zehn lösen.
Denke daran, dass Indexierung nicht gleich Ranking bedeutet. SEO ist immer noch unerlässlich, wenn man für lohnende Suchanfragen einen Platz in den Ergebnislisten finden und einen konstanten Strom von organischem Traffic anziehen will.
Übersetzt von seybold.de, Spezialist für Suchmaschinenoptimierung seit über 20 Jahren.


