


So funktionieren KI-Suchmaschinen

Nach Autor Ryan Law
Director of Content Marketing, Ahrefs
Was passiert eigentlich, wenn du ChatGPT bittest, dir die besten Over-Ear-Kopfhörer fürs Training zu empfehlen?
Wie generieren KI-Suchmaschinen ihre Antworten und wählen ihre Produktempfehlungen aus? Worin unterscheiden sie sich von traditionellen Suchmaschinen wie Google (und wo überschneiden sie sich)?
Und vor allem: Wie kannst du dazu beitragen, dass deine Website, deine Marke und deine Produkte besser sichtbar werden?
Vielen Dank an Gianluca Fiorelli und Mark Williams-Cook für die Überprüfung und Mitwirkung an diesem Kapitel.
Was sind KI-Suchmaschinen?
KI-Suchmaschinen sind Frage-Antwort-Systeme, die Large Language Models (LLMs) nutzen, um Informationen zu finden und Antworten zu generieren.
Es gibt einige wesentliche Unterschiede zwischen traditionellen Suchmaschinen und KI-Suchmaschinen (auch wenn diese Unterschiede kleiner werden, da traditionelle Suchmaschinen immer mehr KI-Funktionen integrieren):
- Statt einzelne Suchanfragen einzugeben, können Nutzer Rückfragen stellen und das Gespräch fortsetzen.
- Anstatt eine sortierte Liste von Links zurückzugeben, liefern KI-Suchmaschinen direkte Antworten und Empfehlungen (und diese Antworten können sich regelmäßig ändern).
- Anstatt Suchende dazu zu bringen, deine Website zu besuchen, bekommen Nutzer ihre Suchanfragen direkt in der Chat-Oberfläche beantwortet (was zu weniger Klicks zurück auf deine Website führt).
So sieht eine typische KI-Suchoberfläche aus – ähnlich dem, was du in ChatGPT, Claude oder dem KI-Modus sehen würdest:

- Konversationeller Prompt: Die Frage des Nutzers.
- Grounding-Nachricht: Eine Nachricht, die anzeigt, dass das LLM beschlossen hat, nach zusätzlichen Informationen zu suchen, die es in seiner Antwort verwendet.
- Antwort: Die von der KI erzeugte Antwort auf den Prompt der Nutzerin bzw. des Nutzers.
- Erwähnung: Eine Entität (wie deine Marke oder dein Produkt), die im Antworttext inline erwähnt wird.
- Zitate: Quell-URLs, die zur Generierung der Antwort verwendet wurden und in der Regel am Ende aufgeführt sind.
Damit du in solchen Antworten auftauchst, musst du zuerst die Kernprozesse verstehen, durch die KI-Suchmaschinen funktionieren.
Wie Training funktioniert
LLMs werden mit riesigen Mengen an Content trainiert. Sie haben praktisch „alles gelesen“: die komplette Wikipedia, das gesamte Common-Crawl-Dataset, alle Google Books und viele Millionen und Abermillionen Seiten mit Web-Content.
Diese Trainingsdaten tragen dazu bei, dem LLM ein „Verständnis“ der Welt zu vermitteln. Wenn dein Kopfhörerhersteller in den Trainingsdaten häufig vorkommt – in relevanten Kontexten und in Verbindung mit positiven Begriffen wie „bestes Preis-Leistungs-Verhältnis“, „ideal fürs Fitnessstudio“ und so weiter –, ist die Wahrscheinlichkeit groß, dass dein Unternehmen in den Antworten des LLM auf Prompts zum Thema Kopfhörer erwähnt wird.
Wusstest du schon?
Dieser Trainingsprozess ist komplexer, als hier dargestellt. Es gibt Pre-Training-Phasen, um HTML zu entfernen, personenbezogene Daten zu löschen, Blocklist-Wörter auszuschließen und die Daten auf bestimmte Sprachen zu filtern. Außerdem gibt es Post-Training-Phasen, um das Sprachmodell so zu trainieren, dass es sich eher wie ein hilfreicher Chat-Assistent verhält (und nicht nur wie ein Next-Token-Predictor). Wenn du mehr erfahren möchtest, sieh dir Andrej Karpathys Video Deep Dive into LLMs like ChatGPT an.


Hier wird entitätsbasiertes SEO entscheidend. Wenn deine Marke in Knowledge Graphs konsistent erscheint, mit Schema-Markup korrekt strukturiert ist und in hochwertigen Inhalten im Web gemeinsam mit relevanten Entitäten vorkommt, baust du ein stärkeres „Entitätssignal“ in Trainingsdaten auf.

Gianluca Fiorelli, Berater für strategische und internationale SEO/KI-Suchmaschinenoptimierung
Entscheidend ist, dass LLMs viele Eigenheiten haben:
- Sie sind probabilistisch: Du kannst denselben Prompt verwenden und jedes Mal unterschiedliche Antworten erhalten. Diese probabilistische Natur bedeutet, dass du nicht „für einen Prompt optimieren“ kannst, so wie du für ein Keyword optimierst. Denke stattdessen in Verteilungen: Wie hoch ist die Wahrscheinlichkeit, dass deine Marke über 100 ähnliche Prompts hinweg erscheint? Deshalb ist es besser, die durchschnittliche Sichtbarkeit über viele Prompts hinweg zu tracken, als sich an einer Handvoll Prompts festzubeißen.
- Ihr Wissen hat einen Cut-off: Standardmäßig ist das Wissen eines LLMs auf das begrenzt, was zum Zeitpunkt des Trainings dieses spezifischen Modells im Datensatz enthalten war. Jedes Modell wird einmal auf einem Daten-Snapshot bis zu einem bestimmten Datum trainiert. Neue Modelle mit aktuelleren Wissens-Cut-offs werden in regelmäßigen Abständen veröffentlicht (historisch etwa alle sechs Monate).
- Sie halluzinieren: Sie können Dinge mit großer Sicherheit behaupten, die nicht stimmen. LLMs erzeugen Text, indem sie vorhersagen, welche Wörter wahrscheinlich als Nächstes kommen – nicht, indem sie Fakten überprüfen. Auch wenn sie darauf trainiert sind, hilfreich und genau zu sein, haben sie keinen eingebauten Mechanismus zur Faktenprüfung; deshalb ist Grounding durch Websuche so wichtig.
Ein weit verbreiteter Irrtum ist, dass LLMs „Wissens-Updates“ erhalten, ähnlich wie Software-Patches. In Wirklichkeit wird jedes Modell einmalig auf einem festen Datensatz trainiert. Wenn du eine neue Modellversion mit einem aktuelleren Wissensstand siehst, handelt es sich um ein völlig neues Modell, das von Grund auf neu trainiert wurde, und nicht um ein Update des bestehenden Modells.
Gianluca Fiorelli, Berater für strategische und internationale SEO/KI-Suchmaschinenoptimierung
Eine Suchmaschine, die halluziniert und alte Informationen teilt, klingt nicht besonders nützlich. Deshalb überwinden LLMs einige dieser Einschränkungen durch einen Prozess, der als Grounding bekannt ist.
Wie Grounding und RAG funktionieren
LLMs können ihre Antworten auf zwei Arten überprüfen und verbessern: mithilfe von Tools (wie Taschenrechnern oder anderen Daten-APIs) oder durch das Abrufen zusätzlicher Informationen aus externen Quellen. Dieser zweite Prozess wird technisch als Retrieval-Augmented Generation (RAG) bezeichnet.
Wenn ein Nutzer eine Frage eingibt, fragt sich das LLM: „Kenne ich die Antwort bereits, oder sollte ich zusätzliche Informationen abrufen?“ Wenn das LLM das nächste Token mit hoher Sicherheit vorhersagen kann (zum Beispiel bei Fragen, die sich kaum verändern, wie „Was machen rote Blutkörperchen?“), antwortet es wahrscheinlich aus seinem Basiswissen heraus. Bei niedriger Sicherheit (bei Fragen, die sich eher ändern können, wie „Was ist die beste günstige Kaffeemühle?“) kann es sein Such-Tool nutzen, um relevante Informationen aus anderen Quellen im Internet zu finden.
Die LLMs sind feinabgestimmt, um Query-Typen zu erkennen, die von zusätzlichen Informationen profitieren könnten, wie zum Beispiel:
- Themen außerhalb des Trainingsumfangs der Modelle: „Welche internen Rankingfaktoren verwendet Ahrefs’ Keywords Explorer?“
- Themen, die frische oder zeitkritische Informationen erfordern: „Was war Googles jüngstes Core Update und wann wurde es eingeführt?“
- Themen, die explizit eine Websuche verlangen: „Durchsuche das Internet nach beliebten Linkbuilding-Taktiken im Jahr 2026.“
- Prompts, die nach Quellen und Belegen fragen: „Nenne Quellen, die bestätigen, dass Google in seinem Algorithmus Signale zur Nutzerinteraktion nutzt.“
Einige LLM-Modelle lösen außerdem mit hoher Wahrscheinlichkeit zusätzliche Suchen aus (zum Beispiel sind „Deep-Research“-Modelle speziell so konfiguriert, dass sie mehrere RAG-Suchen auslösen).
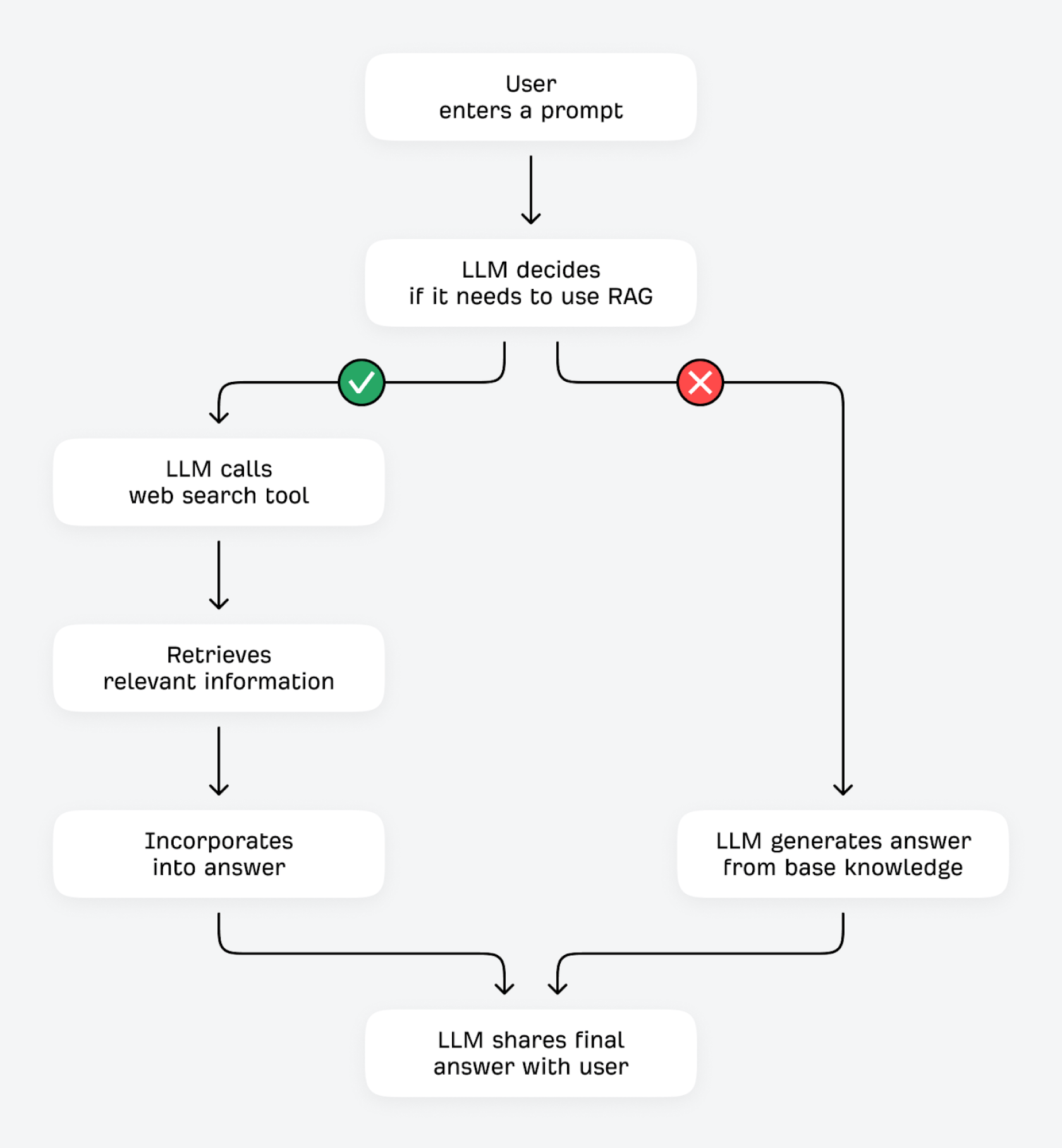
Dieser Prozess, Ground Truth über RAG zu finden (oft auch „Grounding“ genannt), bietet mehrere Vorteile. Das LLM kann die faktische Genauigkeit verbessern und Halluzinationen reduzieren, indem es seine Antworten mit Drittquellen abgleicht. Es kann aktuelle Informationen abrufen und teilen – selbst wenn seine Trainingsdaten bereits relativ veraltet sind. Es kann detailliertere, umfassendere Antworten liefern und für alles, was es teilt, bessere Transparenz und klare Quellenangaben bieten.
KI-Suchmaschinen führen dieses Grounding über einen Prozess durch, der als Query-Fan-out bekannt ist.
So funktioniert Query-Fan-out
Entscheidend ist: Query-Fan-out erklärt, warum klassische SEO für KI-Sichtbarkeit so wichtig ist.
KI-Assistenten wie ChatGPT, Gemini und Perplexity nutzen Suchindizes wie Google, Bing und Brave, um aktuelle Informationen abzurufen.
Der Suchanbieter spielt eine Rolle, da jeder unterschiedliche Ranking-Algorithmen, Indizes und Abdeckung hat: Deine Marke in der Google-Suche sichtbar zu machen, kann deine Sichtbarkeit im KI-Modus stärker steigern als bei ChatGPT, das deutlich stärker von Bing abhängt.
| KI-Suchmaschine | Für Grounding verwendete Suchindizes |
|---|---|
ChatGPT | Bing, Google |
Claude | Brave |
Gemini | Google |
Copilot | Bing |
Perplexity | In-house |
AI Mode | Google |
AI Overviews | Google |
Wenn eine Websuche ausgelöst wird, fordert das LLM relevante Ergebnisse aus seinem Suchindex an. Der Suchindex gibt eine Ergebnisliste zurück, und das LLM wählt die relevantesten Seiten zum Crawlen aus, indem es Informationen wie den Seitentitel, den Inhalt des zurückgegebenen Seitenausschnitts (Snippet) und die Aktualität (wie kürzlich er veröffentlicht wurde) bewertet.
Warum SEO für die KI-Suche entscheidend ist
Das verdient es, wiederholt zu werden: Traditionelle Suchmaschinen wie Google und Bing spielen eine entscheidende Rolle dabei, KI-Suchmaschinen zu helfen zu entscheiden, welche Inhalte sie in ihren Antworten erwähnen und zitieren.
Anders gesagt: Eine gute Platzierung in der traditionellen Suche verbessert deine Sichtbarkeit in der KI-Suche.
Aber wonach genau sucht das LLM?
LLMs verwenden einen Prozess namens Query-Fan-out. Viele Prompts, die in ChatGPT und andere KI-Suchmaschinen eingegeben werden, sind extrem lang, konversationell und oft völlig einzigartig. Diese exakten Prompts zu googeln, liefert nicht immer nützliche Inhalte.
Anstatt also eine Websuche mit der exakten Suchanfrage der Nutzerin bzw. des Nutzers auszuführen …
„Ich plane eine 6-monatige Content-Strategie für ein mittelständisches B2B-SaaS-Unternehmen, das ein Analytics-Produkt an E-Commerce-Marken verkauft. Das Unternehmen …“

…LLMs verwenden diesen initialen Prompt, um eine Reihe kürzerer, verwandter Suchanfragen zu generieren, die dabei helfen, relevante Informationen abzurufen.
Diese Fan-out-Abfragen werden ebenfalls vom Large Language Model generiert und sind daher nicht deterministisch: Sie können sich regelmäßig ändern – sogar bei derselben Suche.

Mark Williams-Cook, Gründer, AlsoAsked
Dieser Prozess dürfte SEOs vertraut vorkommen: Diese verwandten Suchanfragen ähneln stark Long-Tail-Keywords, Sub-Intents und „Nutzer fragten auch“-Fragen:
- Gängige Frameworks für Content-Strategien im B2B-SaaS
- TOFU- vs. BOFU-Content-Beispiele für SaaS
- Best Practices für Content-Refresh und interne Verlinkung
- Kennzahlen für demo-getriebenes Inhaltswachstum
Tatsächlich tauchen nur 12 % der von ChatGPT, Gemini und Copilot zitierten Links in den Top-10-Ergebnissen von Google für den ursprünglichen Nutzer-Prompt auf. Das bedeutet jedoch nicht, dass klassisches Ranking irrelevant ist. KI-Suchmaschinen rufen Inhalte ab, indem sie mehrere Suchanfragen generieren – und diese Fan-out-Queries sind oft traditionellere, keyword-fokussierte Suchen, bei denen deine bestehende SEO-Arbeit enorm wichtig ist.

Query-Fan-out ist befreiend: Du musst nicht raten, welche konversationellen Prompts Menschen verwenden werden. Optimiere stattdessen für die zerlegten Queries – also die semantischen Komponenten, die LLMs ganz natürlich generieren. Das sieht erstaunlich nach klassischer Keyword-Recherche aus: [topic] + [qualifier], Vergleichs-Queries, Definitions-Queries und „Best Practices“-Content. Deine bestehende SEO-Recherche deckt den Fan-out-Bereich wahrscheinlich bereits ab.
Gianluca Fiorelli, Berater für strategische und internationale SEO/KI-Suchmaschinenoptimierung
Wie Abruf, Chunking und Antwortsynthese funktionieren
Sobald ein LLM relevante Seiten aus einem Suchindex abruft, liest es sie nicht vollständig. Stattdessen werden Seiten in kleine Text-„Chunks“ aufgeteilt, wobei das Modell die Textabschnitte priorisiert (und manchmal erweitert), die für die Anfrage am relevantesten wirken.
Diese Chunks umfassen typischerweise jeweils einige Hundert bis einige Tausend Wörter – ein kleiner Bruchteil der meisten Webseiten. Das LLM unterliegt außerdem strengen Grenzen des Kontextfensters: Es kann nur eine begrenzte Menge Text verarbeiten, einschließlich des Prompts des Nutzers, aller abgerufenen Chunks und seiner eigenen Antwort. Das bedeutet, es muss sehr selektiv sein, welche Inhalte es abruft und einbezieht.
Hier ist ein Beispiel:
| Inhalt der gesamten Seite | „Grounding ist ein Arbeitsablauf, bei dem das Modell externe Quellen abruft, relevante Fakten extrahiert und diese Auszüge nutzt, um Fehlinformationen zu reduzieren und die Aktualität zu verbessern. … Anschließend durchsucht es mehrere Quellen, vergleicht Informationen und fasst eine Antwort zusammen, anstatt Text wörtlich zu kopieren. Dieser Schritt der Zusammenfassung hilft dabei, eine übermäßige Abhängigkeit von einer einzelnen Quelle zu vermeiden.“ |
| Snippet | „Erklärt, wie Assistenten die Websuche nutzen, um externe Quellen abzurufen und Halluzinationen zu reduzieren, indem Antworten auf abgerufene Fakten gestützt werden.“ |
| Erweiterung (Zeilen 1–2) | „Grounding ist ein Arbeitsablauf, bei dem das Modell externe Quellen abruft, relevante Fakten extrahiert und diese Auszüge nutzt, um Fehlinformationen zu reduzieren und die Aktualität zu verbessern. Das Modell prüft, ob eine Anfrage aktuelle oder überprüfbare Informationen erfordert, bevor es eine Websuche startet.“ |
| Erweiterung (Zeilen 33–34) | „Es durchsucht dann mehrere Quellen, vergleicht die Informationen und erstellt eine Antwort, anstatt Text wörtlich zu kopieren. Dieser Schritt der Zusammenfassung hilft dabei, eine übermäßige Abhängigkeit von einer einzelnen Quelle zu vermeiden.“ |
Mach es den LLMs leicht, deine Inhalte zu verstehen
Das ist wichtig: Wenn KI-Suchmaschinen deine Inhalte aus dem Internet abrufen, sehen sie nur Teilausschnitte und nicht die gesamte Seite. Um die Chancen zu maximieren, in der Antwort des LLM zitiert zu werden, müssen die Relevanz und der Wert deiner Seite für LLMs leicht verständlich sein, selbst ohne Zugriff auf die gesamte Seite.
Die KI-Suchmaschine integriert diesen Text dann in ihren Prozess der Antwortgenerierung.
Der rohe Webinhalt wird in die Antwort des Modells eingebettet (Grounding): Die im vorherigen Schritt extrahierten Text- oder Datenausschnitte werden dem Kontext des Modells hinzugefügt – im Grunde nach dem Motto: „Hier ist etwas Kontext aus dem Web, der nützlich sein könnte; beantworte nun die Frage des Nutzers mit diesen Informationen.“
Wie Zitate ausgewählt werden
Von dort aus generiert das Modell eine Antwort, indem es sein angeborenes Wissen mit abgerufenen Inhalten kombiniert, und teilt sie mit dem Nutzer. Die Antwort enthält in der Regel Quellenangaben: anklickbare URLs, die zu den Quellen verlinken, die während des Grounding-Prozesses verwendet wurden.
Nicht jede Seite, die die KI-Suchmaschine abruft, erhält in der finalen Antwort eine Quellenangabe. Das Modell wählt anhand mehrerer Faktoren aus, welche Quellen zitiert werden:
- Relevanz: Wie direkt der abgerufene Content zu konkreten Aussagen in der Antwort beigetragen hat.
- Aktualität: Wie aktuell die Quelle zu sein scheint.
- Diversität: Wie vielfältig die Zitierquellen sind (wobei KI-Suchmaschinen häufig lieber mehrere unterschiedliche Quellen zitieren, statt wiederholt dieselbe Quelle zu nennen).
Das bedeutet, dass selbst wenn dein Inhalt abgerufen und gelesen wird, keine Garantie dafür besteht, dass er ausdrücklich zitiert wird; der Inhalt muss als direkt relevant für eine bestimmte Behauptung in der Antwort angesehen werden.
Wie Personalisierung funktioniert
Das ist der Kern der Funktionsweise von KI-Suchmaschinen – aber es gibt noch eine zusätzliche Komplexitätsebene: Personalisierung.
ChatGPT und andere KI-Suchmaschinen können ihre Ergebnisse für einzelne Nutzerinnen und Nutzer personalisieren – das heißt, derselbe Prompt kann für unterschiedliche Personen unterschiedliche Ergebnisse erzeugen. Personalisierung kann auf mehrere Arten beeinflusst werden, unter anderem durch:
- Aktueller Konversationskontext: Frühere Nachrichten im selben Chat beeinflussen die Antwort auf den aktuellen Prompt. Wenn du erwähnst, dass dir bei deiner Wanderausrüstung „Langlebigkeit“ wichtig ist, kannst du davon ausgehen, dass ChatGPT dieses Kriterium in seine Suche einbezieht, wenn du später im Chat nach „Rucksackempfehlungen“ fragst.
- Memory: Viele LLMs verfügen über eine Memory-Funktion, mit der das System bestimmte Fakten oder Präferenzen über mehrere Chats hinweg behalten kann. Wenn Memory beispielsweise aktiviert ist, wird ChatGPT Details, die du geteilt hast (wie deinen Namen oder deine Interessen), ableiten und speichern und sie in zukünftigen Gesprächen nutzen, um Antworten zu personalisieren.
- Standort, Zeit, Datum: Viele KI-Suchmaschinen können Informationen über dich ableiten und ihre Antworten darauf basierend anpassen – von der Nutzung deiner IP-Adresse für einen ungefähren Standort (für Suchanfragen wie „Brunch in meiner Nähe“) bis hin zu Datum und Uhrzeit („Packliste fürs Camping“ könnte im Winter ein 4-Jahreszeiten-Zelt und im Sommer ein 3-Jahreszeiten-Zelt empfehlen).
- System-Prompts: Konkrete Präferenzen, die in der Systemnachricht angegeben werden, beeinflussen deine Unterhaltungen (wenn du dem System-Prompt z. B. „Merk dir, dass ich vegan bin“ hinzufügst, beeinflusst das Antworten auf Prompts wie „Ideen für ein gesundes Frühstück“).
Hier ist eine Analogie, um System-Prompts besser zu verstehen. Wenn du Fußball spielst, sind die „Trainingsdaten“ all das Training, das du über die Jahre absolviert hast – also dein langfristiges Muskelgedächtnis. Der System-Prompt ist das, was dein Trainer dir sagt, kurz bevor du auf den Platz gehst. Es ist das starke Kurzzeitgedächtnis, das den Ausgang des Spiels eher beeinflusst.
Mark Williams-Cook, Gründer, AlsoAsked

Deshalb ist es sinnvoll, die durchschnittliche Sichtbarkeit deiner Marke und Website im Laufe der Zeit und über viele Prompts hinweg zu verfolgen, statt sich an der Antwort auf einen einzelnen Prompt festzubeißen.
Abschließende Gedanken
Jede KI-Suchmaschine (von ChatGPT über Perplexity bis hin zum Google AI Mode) ist etwas anders, aber die Kernprozesse bleiben gleich. Wichtig für SEOs und Marketer: Traditionelle Suchmaschinen wie Google und Bing stellen einen großen Teil der Infrastruktur bereit, die KI-Suchmaschinen zum Funktionieren benötigen. Die Optimierung für KI-Suche hängt stark von traditionellen SEO-Best Practices ab.
Weiterführende Lektüre
Ryan Law ist der Director of Content Marketing bei Ahrefs. Ryan verfügt über 13 Jahre Erfahrung als Autor, Content-Stratege, Teamleiter, Marketingleiter, Vizepräsident, CMO und Gründer einer Agentur. Er hat Dutzenden von Unternehmen dabei geholfen, ihr Content-Marketing und ihre SEO zu verbessern, darunter Google, Zapier, GoDaddy, Clearbit und Algolia. Außerdem ist er Romanautor und der Ersteller von zwei Content-Marketing-Kursen.
SEO Schritt für Schritt meistern
So funktionieren Suchmaschinen
Wenn du SEO lernen willst, solltest du verstehen, wie Suchmaschinen funktionieren.
SEO-Grundlagen
Erfahre, wie du deine Website fit für die Suchmaschinenoptimierung machst, und mache dich mit den vier Grundpfeilern jeder SEO-Strategie vertraut.
Keyword-Recherche
Der Ausgangspunkt bei der SEO ist es, zu verstehen, wonach deine Zielkunden suchen.
SEO-Content
Lerne, wie du Content erstellst, der gut in Suchmaschinen rankt.
On-Page-SEO
Dabei optimierst du deine Seiten, damit Suchmaschinen sie besser verstehen.
Linkaufbau
Lerne, wie du Content erstellst, der gut in Suchmaschinen rankt.
Technisches SEO
Vermeidetechnische Probleme, die Google daran hindern, auf deine Website zuzugreifen und sie zu verstehen.
Local SEO
Erfahre, wie du deine Sichtbarkeit in lokalen Suchergebnissen verbessern und mehr Kunden aus deiner Umgebung gewinnen kannst.
Was KI für SEO bedeutet
Über SEO heute zu sprechen geht nicht ohne Erwähnung von generativer KI.
So funktionieren KI-Suchmaschinen
Lerne genau, wie KI-Suchmaschinen wie ChatGPT ihre Antworten generieren und auswählen, welche Marken und Produkte sie erwähnen.