


Como funcionam os mecanismos de busca por IA

Por Ryan Law
Diretor de Marketing de Conteúdo na Ahrefs
Quando você pede ao ChatGPT para recomendar os melhores fones de ouvido over-ear para se exercitar, o que realmente acontece?
Como mecanismos de busca por IA geram suas respostas e escolhem suas recomendações de produtos? Em que eles diferem de mecanismos de busca tradicionais como o Google (e em que pontos eles se sobrepõem)?
E, mais importante, como você pode ajudar seu site, sua marca e seus produtos a aparecerem?
Agradecemos a Gianluca Fiorelli e Mark Williams-Cook por revisarem e contribuírem para este capítulo.
O que são mecanismos de busca com IA?
Mecanismos de busca com IA são sistemas de perguntas e respostas que usam grandes modelos de linguagem (LLMs) para encontrar informações e gerar respostas.
Há algumas diferenças importantes entre mecanismos de busca tradicionais e mecanismos de busca por IA (embora essas diferenças estejam diminuindo à medida que os mecanismos de busca tradicionais incorporam mais recursos de IA):
- Em vez de fazer pesquisas pontuais, os usuários podem fazer perguntas de acompanhamento e manter a conversa.
- Em vez de retornar uma lista de links ranqueada, mecanismos de busca com IA fornecem respostas e recomendações diretas (e essas respostas podem mudar com frequência).
- Em vez de enviar os pesquisadores para visitar seu site, os usuários têm suas consultas respondidas diretamente na interface de chat (resultando em menos cliques de volta para o seu site).
Veja como é uma interface típica de busca com IA, semelhante ao que você veria no ChatGPT, Claude ou no Modo IA:

- Prompt conversacional: A pergunta do usuário.
- Mensagem de grounding: Uma mensagem que mostra que o LLM decidiu buscar informações extras para usar na resposta.
- Resposta: A resposta gerada por IA ao prompt do usuário.
- Menção: Uma entidade (como sua marca ou produto) mencionada diretamente no texto da resposta.
- Citações: URLs das fontes usadas na geração da resposta, normalmente listadas no final.
Para ajudar você a aparecer em respostas como essas, primeiro é preciso entender os processos centrais que fazem os mecanismos de busca por IA funcionarem.
Como funciona o treinamento
Os LLMs são treinados com enormes quantidades de conteúdo. Eles efetivamente "leram" toda a Wikipedia, todo o conjunto de dados Common Crawl, todos os Google Books e muitos milhões de páginas de conteúdo da web.
Esses dados de treinamento ajudam a fornecer ao LLM sua “compreensão” do mundo. Se a sua empresa de fones de ouvido aparece muitas vezes nos dados de treinamento, em contextos relevantes e acompanhada de descritores positivos (“melhor custo-benefício”, “ótimo para a academia” e assim por diante), há uma boa chance de a sua empresa ser mencionada nas respostas do LLM a prompts relacionados a fones de ouvido.
Você sabia?
Esse processo de treinamento é mais complexo do que o explicado aqui. Há etapas de pré-treinamento para remover HTML, eliminar informações de identificação pessoal, excluir palavras de listas de bloqueio e filtrar os dados para determinados idiomas. Também há etapas de pós-treinamento para treinar o modelo de linguagem a se comportar mais como um assistente de chat útil (e não apenas como um preditor de próximo token). Para saber mais, assista ao vídeo de Andrej Karpathy, Deep Dive into LLMs like ChatGPT.


É aqui que o SEO baseado em entidades se torna crucial. Se a sua marca aparece de forma consistente em Knowledge Graphs, está corretamente estruturada com marcação Schema e coocorre com entidades relevantes em conteúdo de alta qualidade na web, você está construindo um “sinal de entidade” mais forte nos dados de treinamento.

Gianluca Fiorelli, Consultor(a) estratégico(a) de SEO e busca com IA em nível internacional
O mais importante é que os LLMs têm muitas peculiaridades:
- São probabilísticos: você pode usar o mesmo prompt e obter respostas diferentes a cada vez. Essa natureza probabilística significa que você não consegue “otimizar para um prompt” do mesmo jeito que otimiza para uma palavra-chave. Em vez disso, pense em distribuições: qual é a probabilidade de a sua marca aparecer em 100 prompts semelhantes? É por isso que acompanhar a visibilidade média em muitos prompts é melhor do que se fixar em apenas alguns prompts.
- O conhecimento tem uma data de corte: por padrão, o conhecimento de um LLM se limita ao que estava contido no conjunto de dados quando aquele modelo específico foi treinado. Cada modelo é treinado uma única vez em um recorte de dados até uma determinada data. Novos modelos, com datas de corte de conhecimento mais recentes, são lançados periodicamente (historicamente, a cada seis meses ou algo assim).
- Eles alucinam: podem afirmar com confiança coisas que não são verdade. Os LLMs geram texto prevendo quais palavras provavelmente virão a seguir, não verificando fatos. Embora sejam treinados para ser úteis e precisos, não têm um mecanismo interno de checagem de fatos — por isso o grounding via busca na web é tão importante.
Um equívoco comum é achar que LLMs recebem “atualizações de conhecimento” como patches de software. Na prática, cada modelo é treinado uma vez com um conjunto de dados fixo. Quando você vê o lançamento de um novo modelo com um corte de conhecimento mais recente, isso é um modelo totalmente novo, treinado do zero — não uma atualização do modelo existente.
Gianluca Fiorelli, Consultor(a) estratégico(a) de SEO e busca com IA em nível internacional
Um mecanismo de busca que alucina e compartilha informações antigas não parece muito útil. Por isso, os LLMs superam algumas dessas limitações por meio de um processo conhecido como grounding.
Como funcionam o grounding e a RAG
LLMs podem verificar e melhorar suas respostas de duas formas: usando ferramentas (como calculadoras ou outras APIs de dados) ou buscando informações adicionais em fontes externas. Esse segundo processo é conhecido tecnicamente como Geração Aumentada por Recuperação (RAG).
Quando um usuário faz uma pergunta, o LLM pergunta a si mesmo: "Já sei a resposta, ou devo buscar informações adicionais?" Se o LLM pode prever o próximo token com alta confiança (por exemplo, perguntas que não mudam muito, como "o que fazem as hemácias?"), é provável que responda com seu conhecimento básico. Com baixa confiança (para perguntas que são mais propensas a mudar, como "qual é o melhor orçamento para moedor de café?"), ele pode usar sua ferramenta de pesquisa para encontrar informações relevantes de outras fontes na internet.
Os LLMs são ajustados para reconhecer tipos de consulta que podem se beneficiar de informações adicionais, como:
- Tópicos fora do escopo de treinamento dos modelos: “Quais são os fatores internos de ranqueamento usados pelo Keywords Explorer da Ahrefs?”
- Tópicos que exigem informações recentes ou sensíveis ao tempo: “Qual foi a Atualização principal mais recente do Google e quando ela foi implementada?”
- Tópicos que solicitam explicitamente uma busca na web: “Pesquise na internet táticas populares de link building em 2026.”
- Prompts que solicitam fontes e evidências: “Forneça fontes que confirmem que o Google usa sinais de engajamento do usuário no seu algoritmo.”
Alguns modelos de LLM também têm uma grande probabilidade de acionar buscas adicionais (por exemplo, modelos de "pesquisa profunda" são configurados especificamente para acionar múltiplas buscas de RAG).
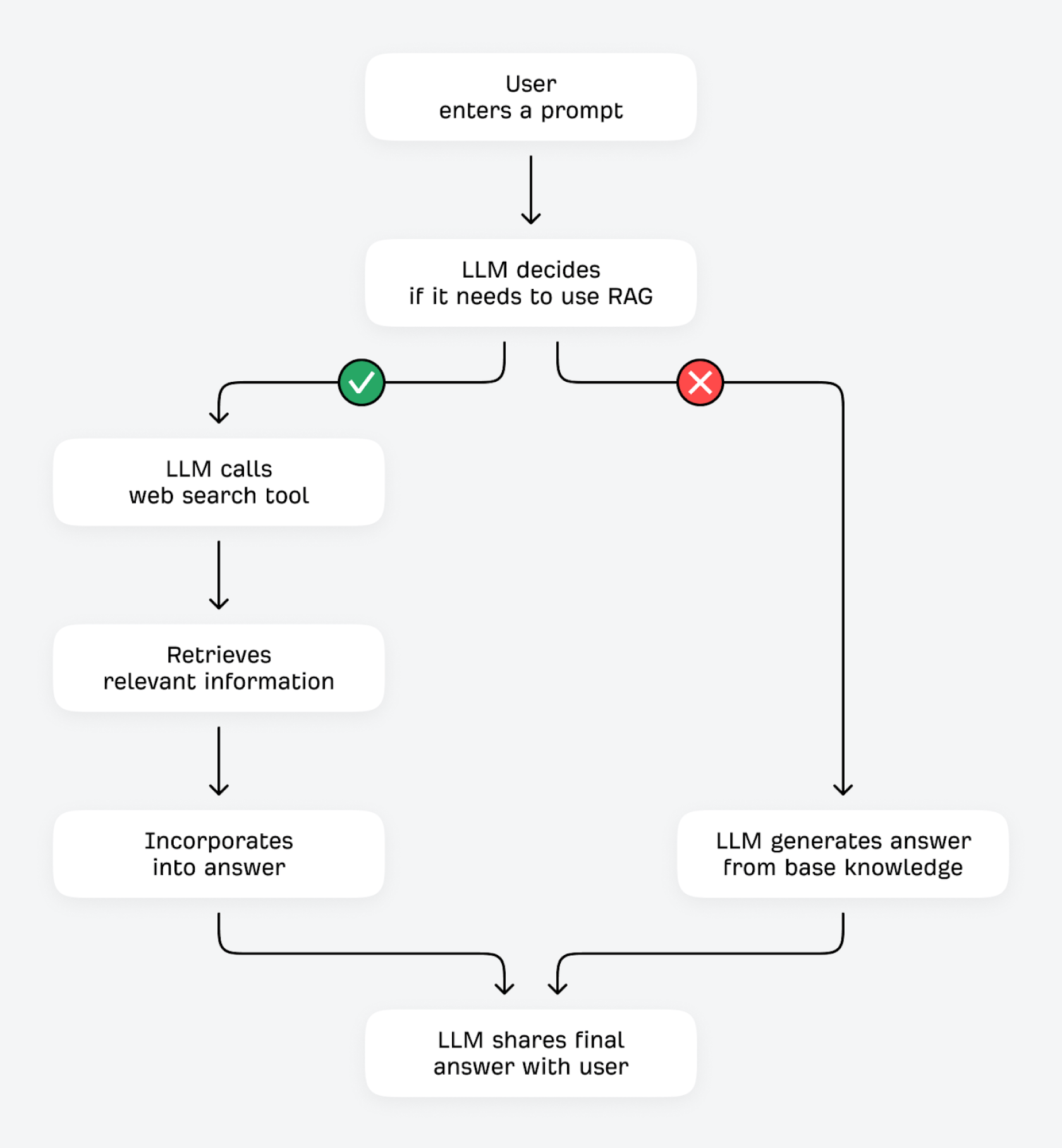
Esse processo de encontrar a verdade fundamental por meio de RAG (frequentemente chamado de "grounding") oferece vários benefícios. O LLM pode melhorar a precisão factual e reduzir alucinações ao verificar suas respostas em fontes de terceiros. Ele pode recuperar e compartilhar informações atualizadas, mesmo que seus dados de treinamento estejam relativamente desatualizados. Ele pode compartilhar respostas mais detalhadas e abrangentes e oferecer melhor transparência e atribuição para tudo o que compartilha.
Mecanismos de busca por IA realizam esse grounding usando um processo conhecido como query fan-out.
Como funciona o query fan-out
O query fan-out explica, de forma essencial, por que o SEO tradicional é crítico para a visibilidade em IA.
Assistentes com IA como ChatGPT, Gemini e Perplexity usam índices de busca como Google, Bing e Brave para recuperar informações atualizadas.
O provedor de busca importa porque cada um tem algoritmos de classificação, índices e cobertura diferentes: fazer sua marca ficar visível na Pesquisa Google pode ajudar na sua visibilidade no Modo IA mais do que no ChatGPT, que depende mais do Bing.
| Mecanismo de busca por IA | Índices de busca usados para grounding |
|---|---|
ChatGPT | Bing, Google |
Claude | Brave |
Gemini | Google |
Copilot | Bing |
Perplexity | In-house |
AI Mode | Google |
AI Overviews | Google |
Quando uma busca na web é acionada, o LLM solicita resultados relevantes do seu índice de busca. O índice de busca retorna uma lista de resultados, e o LLM seleciona as páginas mais relevantes para rastrear avaliando informações como o título da página, o conteúdo do trecho retornado e a atualidade dele (há quanto tempo foi publicado).
Por que o SEO é crucial para a busca com IA
Vale repetir: mecanismos de busca tradicionais como Google e Bing têm um papel crucial para ajudar mecanismos de busca com IA a decidir qual conteúdo mencionar e citar nas respostas.
Ou, dito de outra forma, ranquear bem na busca tradicional vai melhorar sua visibilidade na busca com IA.
Mas, afinal, o que exatamente o LLM busca?
LLMs usam um processo chamado query fan-out. Muitos prompts inseridos no ChatGPT e em outros mecanismos de busca com IA são extremamente longos, conversacionais e, muitas vezes, totalmente únicos. Pesquisar no Google exatamente esses prompts nem sempre vai retornar conteúdo útil.
Então, em vez de fazer uma pesquisa na web com a consulta exata do usuário…
"Estou planejando uma estratégia de conteúdo de 6 meses para uma empresa B2B de SaaS de médio porte que vende um produto de analytics para marcas de e-commerce. A empresa…"

…os LLMs usam esse prompt inicial para gerar uma série de consultas mais curtas e relacionadas, para ajudar a recuperar informações relevantes.
Essas consultas de fan-out também são geradas pelo grande modelo de linguagem e, portanto, são não determinísticas: podem mudar com frequência, mesmo para a mesma busca.

Mark Williams-Cook, Fundador, AlsoAsked
Esse processo deve soar familiar para SEOs: essas consultas relacionadas são muito parecidas com palavras-chave longas, subintenções e perguntas do People Also Ask:
- Frameworks comuns de estratégia de conteúdo B2B SaaS
- Exemplos de conteúdo TOFU vs BOFU para SaaS
- Boas práticas de atualização de conteúdo e links internos
- Métricas para crescimento de demos orientado por conteúdo
Na verdade, apenas 12% dos links citados pelo ChatGPT, Gemini e Copilot aparecem nos 10 primeiros resultados do Google para o prompt original do usuário. Porém, isso não significa que o ranqueamento tradicional seja irrelevante. Os mecanismos de busca por IA recuperam conteúdo gerando várias consultas de pesquisa — e essas consultas ("query fan-out") muitas vezes são buscas mais tradicionais, focadas em palavras-chave, nas quais seu trabalho de SEO importa enormemente.

O query fan-out é libertador: você não precisa adivinhar quais prompts conversacionais as pessoas vão usar. Em vez disso, otimize para as consultas decompostas, ou seja, os componentes semânticos que os LLMs gerarão naturalmente. Elas se parecem muito com a pesquisa por palavras-chave tradicional: [tópico] + [qualificador], consultas de comparação, consultas de definição e conteúdo de "boas práticas". Sua pesquisa de SEO existente provavelmente já cobre o espaço de fan-out.
Gianluca Fiorelli, Consultor(a) estratégico(a) de SEO e busca com IA em nível internacional
Como funcionam a recuperação, a divisão em trechos e a síntese de respostas
Quando um LLM recupera páginas relevantes de um índice de pesquisa, ele não as lê na íntegra. Em vez disso, as páginas são divididas em pequenos "chunks" de texto, e o modelo prioriza (e às vezes expande) as seções de texto que parecem mais relevantes para a consulta.
Esses trechos geralmente têm de algumas centenas a alguns milhares de palavras cada, uma pequena fração da maioria das páginas da web. O LLM também opera sob limites rigorosos da janela de contexto: ele consegue processar uma quantidade limitada de texto, incluindo o prompt do usuário, todos os trechos recuperados e a própria resposta. Isso significa que ele precisa ser muito seletivo quanto ao conteúdo que recupera e inclui.
Aqui vai um exemplo:
| Conteúdo de página inteira | “Grounding é um fluxo de trabalho em que o modelo recupera fontes externas, extrai fatos relevantes e usa esses extratos para reduzir alucinações e aumentar a atualidade.… Em seguida, ele analisa várias fontes, compara as informações e sintetiza uma resposta, em vez de copiar o texto ao pé da letra. Essa etapa de síntese ajuda a evitar dependência excessiva de uma única fonte.” |
| Snippet | "Explica como assistentes usam a busca na web para recuperar fontes externas e reduzir alucinações ao fundamentar as respostas em fatos recuperados." |
| Expansão (linhas 1–2) | “Grounding é um fluxo de trabalho em que o modelo recupera fontes externas, extrai fatos relevantes e usa esses extratos para reduzir alucinações e aumentar a atualidade. O modelo avalia se uma consulta exige informações atualizadas ou verificáveis antes de iniciar uma busca na web.” |
| Expansão (linhas 33–34) | “Em seguida, ele analisa várias fontes, compara as informações e sintetiza uma resposta, em vez de copiar o texto ao pé da letra. Essa etapa de síntese ajuda a evitar dependência excessiva de uma única fonte.” |
Faça com que os LLMs entendam seu conteúdo mais facilmente
Isso é importante: quando mecanismos de busca por IA recuperam seu conteúdo da internet, eles conseguem ver apenas trechos parciais, e não a página inteira. Para maximizar as chances de ser citado na resposta do LLM, a relevância e o valor da sua página precisam ser fáceis para os LLMs entenderem, mesmo sem acesso à página inteira.
O mecanismo de busca com IA então integra esse texto ao seu processo de geração de respostas.
O conteúdo bruto da web é ancorado na resposta do modelo: os trechos de texto ou dados extraídos na etapa anterior são adicionados ao contexto do modelo, essencialmente dizendo: "Aqui está um contexto da web que pode ser útil; agora responda à pergunta do usuário usando estas informações."
Como as citações são escolhidas
A partir daí, o modelo gera uma resposta combinando seu conhecimento inato com o conteúdo recuperado e a compartilha com o usuário. A resposta geralmente inclui citações: URLs clicáveis que levam às fontes usadas durante o processo de grounding.
Nem todas as páginas que o mecanismo de busca por IA recupera receberão uma citação na resposta final. O modelo seleciona quais fontes citar com base em vários fatores:
- Relevância: O quanto o conteúdo recuperado contribuiu diretamente para afirmações específicas na resposta.
- Atualidade: O quão recente a fonte parece ser.
- Diversidade: Quão diversas são as fontes das citações (com mecanismos de busca por IA frequentemente preferindo citar várias fontes diferentes em vez de citar repetidamente a mesma).
Isso significa que, mesmo que seu conteúdo seja recuperado e lido, não há garantia de receber uma citação visível; o conteúdo precisa ser considerado diretamente relevante para uma afirmação específica na resposta.
Como funciona a personalização
Este é o núcleo de como funcionam os mecanismos de busca por IA, mas há um nível extra de complexidade: personalização.
O ChatGPT e outros mecanismos de busca com IA podem personalizar os resultados para usuários individuais, o que significa que o mesmo prompt pode gerar resultados diferentes para pessoas diferentes. A personalização pode ser influenciada de várias formas, incluindo:
- Contexto atual da conversa: Mensagens anteriores no mesmo chat influenciarão a resposta ao prompt atual. Se você mencionar que valoriza “durabilidade” nos seus equipamentos de trilha, pode esperar que o ChatGPT inclua esse critério na busca quando você pedir “recomendações de mochilas” mais tarde no chat.
- Memória: muitos LLMs têm um recurso de memória que permite ao sistema reter certos fatos ou preferências ao longo de chats. Por exemplo, com a memória ativada, o ChatGPT vai inferir e lembrar detalhes que você compartilhou (como seu nome ou interesses) e incluí-los em conversas futuras para personalizar as respostas.
- Local, hora, data: muitos mecanismos de busca com IA conseguem inferir informações sobre você e adaptar as respostas com base nelas, desde usar seu endereço IP para estimar a localização (para consultas como “brunch perto de mim”) até considerar data e hora (“lista de itens para acampar” pode sugerir uma barraca 4 estações no inverno e uma barraca 3 estações no verão).
- Prompts do sistema: quaisquer preferências específicas compartilhadas na mensagem do sistema vão influenciar suas conversas (adicionar “lembre-se de que sou vegano” ao prompt do sistema vai influenciar respostas a prompts como “ideias de café da manhã saudável”).
Aqui vai uma analogia para entender prompts do sistema. Se você estivesse jogando futebol, os “dados de treinamento” seriam toda a prática que você fez ao longo dos anos, a memória muscular de longo prazo. O prompt do sistema é o que seu técnico diz para você instantes antes de entrar em campo. É uma memória poderosa, de curto prazo, que tem mais chance de impactar a saída.
Mark Williams-Cook, Fundador, AlsoAsked

Por isso, é uma boa ideia acompanhar a visibilidade média da sua marca e do seu site ao longo do tempo e em muitos prompts, em vez de se fixar na resposta de um único prompt.
Considerações finais
Cada mecanismo de busca com IA (do ChatGPT ao Perplexity e ao Google AI Mode) é um pouco diferente, mas os processos centrais continuam os mesmos. E, para SEOs e profissionais de marketing, isso é importante: mecanismos de busca tradicionais como Google e Bing fornecem grande parte da infraestrutura necessária para que mecanismos de busca com IA funcionem. Otimizar para busca com IA depende bastante das melhores práticas tradicionais de SEO.
Leitura adicional
Ryan Law é o Diretor de Marketing de Conteúdo na Ahrefs. Ryan possui 13 anos de experiência como redator, estrategista de conteúdo, líder de equipe, diretor de marketing, vice-presidente, CMO e fundador de agência. Ele ajudou dezenas de empresas a melhorar seu marketing de conteúdo e SEO, incluindo Google, Zapier, GoDaddy, Clearbit e Algolia. Ele também é escritor e criador de dois cursos de marketing de conteúdo.
Domine SEO passo a passo
Como funcionamos motores de pesquisa
Antes de começar a aprender sobre SEO, você precisa entender como funcionam os motores de busca.
Fundamentos de SEO
Aprenda como configurar o seu site para um SEO de sucesso, e familiarize-se com as quatro principais facetas do SEO.
Pesquisa por palavras-chave
O primeiro passo no SEO é compreender o que seu público-alvo está pesquisando.
Conteúdo de SEO
Aprenda a criar conteúdo ranqueador nos motores de busca.
SEO na página
Ao otimizar suas páginas, você ajuda os mecanismos de pesquisa a entendê-las.
Construção de links
Aprenda a criar conteúdo ranqueador nos motores de busca.
SEO técnico
Evite problemas técnicos que impeçam o Google de acessar e entender seu site.
SEO local
Aprenda como melhorar sua visibilidade nos resultados de pesquisa local e conseguir mais clientes da sua região.
O Que IA Significa para SEO
Não se pode falar de SEO atualmente sem mencionar IA gerativa.
Como funcionam os mecanismos de busca por IA
Aprenda exatamente como mecanismos de busca com IA como o ChatGPT geram suas respostas e escolhem quais marcas e produtos mencionar.