Responsable des contenus @ Ahrefs (ce qui veut dire en gros, que je dois m’assurer que chaque article publié est ÉPIQUE).
Les moteurs de recherche explorent (“crawlent”) le web grâce à des bots appelés spiders. Ces crawlers suivent les liens de page en page pour trouver du nouveau contenu et l’ajouter à leur index de recherche. Lorsque vous utilisez un moteur de recherche, les résultats pertinents sont extraits de l’index et sont classés (“rankés”) à l’aide d’un algorithme.
Si cela vous semble compliqué, c’est normal : ça l’est. Mais si vous voulez être mieux positionné dans les résultats de recherche pour obtenir plus de trafic sur votre site, il faut comprendre les bases : comment les moteurs de recherche trouvent, indexent et classent le contenu.
Avant de rentrer dans le côté technique, assurons-nous de comprendre ce que sont les moteurs de recherche, pourquoi ils existent et pourquoi est-ce que tout cela a de l’importance.
Que sont les moteurs de recherche ?
Les moteurs de recherche sont des outils qui trouvent et classent le contenu du web qui correspond à la requête de l’utilisateur du moteur.
Chaque moteur de recherche a deux parties principales :
Search index, l’index de recherche. Une librairie numérique qui contient des informations sur les pages web
Algorithme(s) de recherche. Un ou plusieurs programmes informatiques qui classent les contenus selon la requête tapée dans le moteur.
Comme moteurs de recherche les plus utilisés, on peut citer Google, Bing et DuckDuckGo.
Quel est le but des moteurs de recherche ?
Chaque moteur de recherche a pour but de fournir les meilleurs résultats, les plus pertinents, à ses utilisateurs. C’est comme cela qu’ils gagnent ou maintiennent leur part de marché. Du moins en théorie.
Comment les moteurs de recherche gagnent-ils de l’argent ?
Les moteurs de recherche ont deux types de résultats :
Résultat organique du search index. On ne peut pas payer pour y apparaître.
Résultats payants des publicités. Vous devez payer pour y apparaître.
Chaque fois que quelqu’un clique sur un résultat payé (les fameux premiers résultats “Annonce” sur Google par exemple) la cible du lien paye le moteur de recherche. C’est ce qu’on appelle le PPC, pay-per-click ou coût par clic (CPC) en français.
D’où l’importance de la part de marché : plus il y a d’utilisateurs, plus ces publicités sont cliquées, plus les revenus augmentent.
Pourquoi se soucier de la manière dont fonctionnent les moteurs de recherche ?
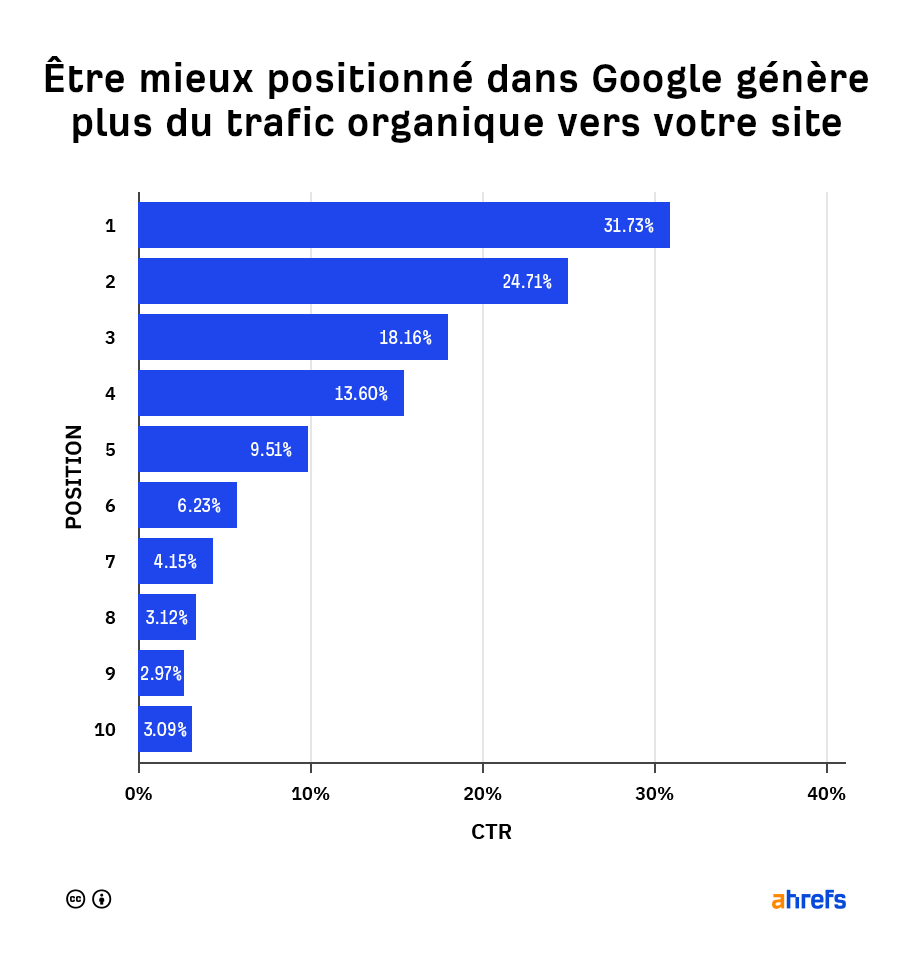
Comprendre comment les moteurs de recherche trouvent, indexent et classent le contenu va vous aider à mieux positionner votre site dans les résultats de recherche organique sur des requêtes ou mots-clés pertinents et fréquemment utilisés.
Si vous vous positionnez bien sur ces requêtes, vous obtiendrez plus de clics et donc plus de trafic organique sur votre contenu.
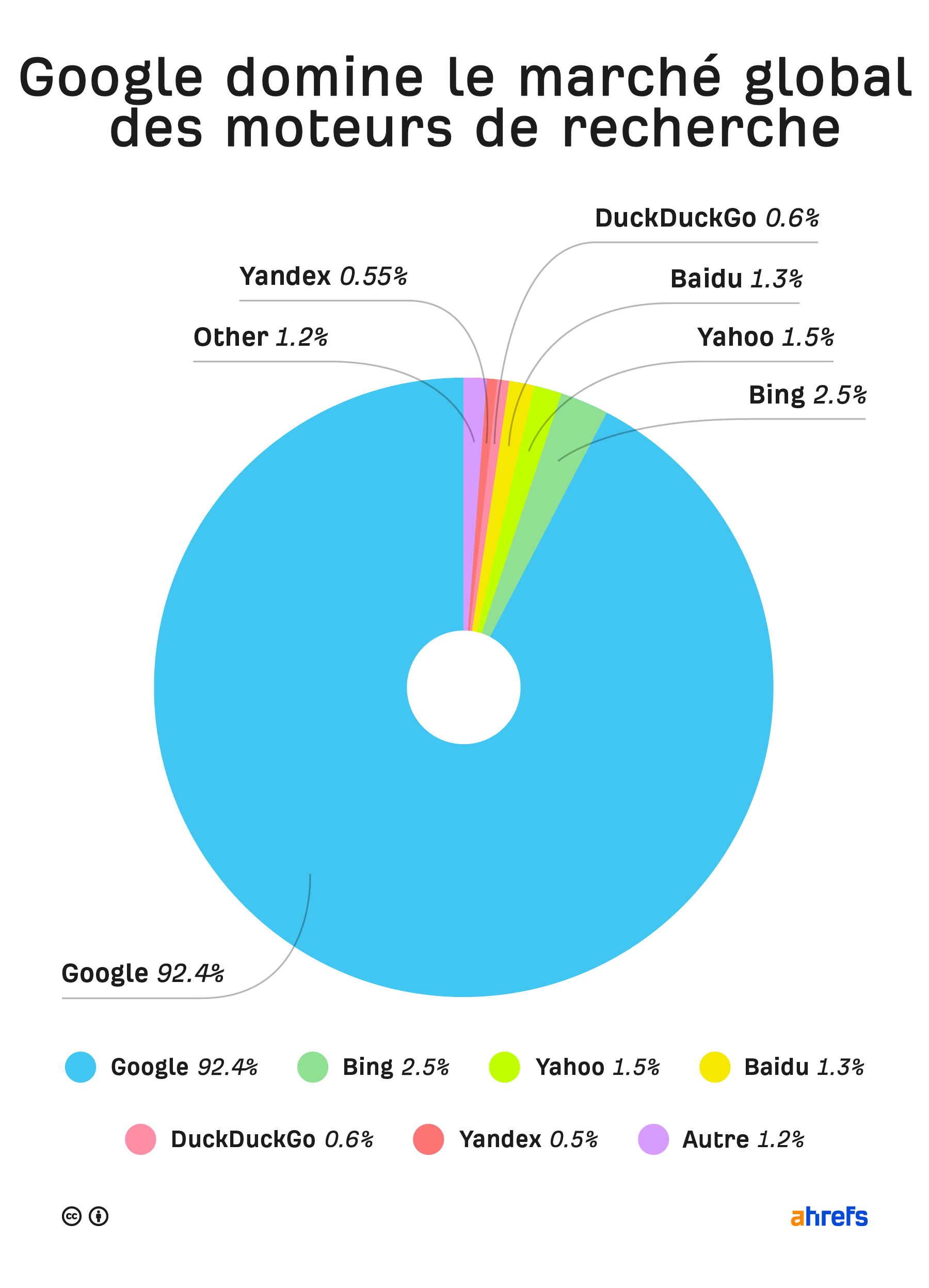
Google est le moteur de recherche dont se soucient le plus la plupart des professionnels du SEO et des propriétaires de site. Il est en mesure d’envoyer plus de trafic que n’importe quel autre.
Comment les moteurs de recherche construisent leur index
Les moteurs de recherche les plus connus comme Google et Bing disposent de trillions de pages dans leur index de recherche. Avant de parler d’algorithmes de ranking, voyons un peu plus en détail la méthode qu’ils utilisent pour construire et entretenir cet index.
Le processus ci-dessous s’applique spécifiquement à Google, mais il y a de grandes chances que ce soit très similaire pour des moteurs de recherche comme Bing. Il existe d’autres types de moteurs comme Amazon, YouTube et Wikipédia qui ne montrent que les résultats issus de leur propre site.
Étape 1 : URLs
Tout commence par une liste des URLs connues. Google les découvre par différents moyens, mais voici les trois plus fréquents :
Depuis les backlinks (liens entrants)
Google dispose déjà d’un index de trillions de pages web. Si quelqu’un ajoute dans l’une d’entre elles un lien vers l’une de vos pages, il peut vous trouver comme cela.
Un sitemap fait la liste de toutes les pages importantes de votre site. Si vous soumettez votre sitemap à Google, cela va l’aider à trouver votre site plus vite.
Depuis une soumission d’URL
Google permet aussi la soumission d’URL individuelles via la Google Search Console.
Étape 2 : exploration (crawling)
L’étape de crawling est lorsque qu’un bot informatique appelé spider (comme Googlebot) visite et télécharge les pages découvertes.
Il faut savoir que Google ne crawle pas toujours les pages en suivant l’ordre dans lequel il les découvre.
L’ordre dans lequel il classe l’exploration se base sur plusieurs facteurs dont :
Le PageRank de l’URL
La fréquence à laquelle l’URL change
Si le contenu est récent ou ancien.
Il faut le savoir, car cela veut dire que les moteurs de recherche vont peut-être crawler et indexer certaines de vos pages avant les autres. Si vous avez un gros site internet, il faudra certainement un bon moment aux moteurs de recherche pour l’explorer entièrement.
Étape 3 : traitement
Le traitement est l’étape où Google tente de comprendre et extraire les informations les plus importantes des pages qu’il explore. Personne en dehors du géant Google ne connait tous les détails de ce processus. Mais les parties les plus importantes pour bien comprendre la méthode sont l’extraction de lien et le stockage de contenu pour indexation.
Google a besoin de charger les pages en entier pour les traiter, c’est le moment où le moteur de recherche déroule tout le code de la page pour comprendre comment il apparaît pour les utilisateurs.
Cela dit, certaines phases du traitement arrivent avant et après ce chargement, comme vous pouvez le voir dans le diagramme plus haut.
Étape 4 : l’indexation
L’indexation est la partie du processus où les informations des pages explorées sont ajoutées à l’immense base de données appelée Search Index. C’est globalement une libraire numérique de trillions de pages web d’où Google va tirer ses résultats de recherche.
C’est là un point important. Lorsque vous tapez une requête dans un moteur de recherche, vous ne cherchez pas réellement tout internet. Les résultats seront issus de l’index des pages web du moteur de recherche. Si une page n’est pas dans l’index, les utilisateurs du moteur de recherche ne pourront pas les trouver. C’est pour cela que faire indexer vos sites dans les plus grands moteurs de recherche comme Google et Bing est important.
Comment les moteurs de recherche classent les pages
La découverte, le crawl et l’indexation du contenu ne sont que les premières pièces du puzzle. Les moteurs de recherche ont besoin d’un moyen de faire correspondre les résultats avec ce que tapent les utilisateurs. C’est le travail des algorithmes.
Chaque moteur de recherche utilise ses propres algorithmes pour classer, “ranker” les pages. Google étant celui le plus largement utilisé (à part en Asie et en Russie), c’est celui sur lequel nous allons nous concentrer dans ce guide.
Google est célèbre pour avoir plus de 200 facteurs de classement, ou ranking.
Personne ne les connaît réellement tous, mais nous en savons assez sur les plus importants.
Parlons-en :
Backlinks (liens entrants)
Pertinence
Fraîcheur
Autorité sur le sujet
Vitesse de la page
Adapté aux mobiles
Backlinks (liens entrants)
Les backlinks sont l’un des facteurs de ranking les plus importants de Google.
Cela a été confirmé par Andrey Lupattsev, un Stratège Senior en Qualité de Recherche chez Google, lors d’un webinaire en 2016. Lorsqu’on lui a demandé quels étaient les deux plus importants facteurs de ranking, sa réponse était simple : le contenu et les liens.
Tout à fait. Je peux vous dire ce qu’ils (les deux plus importants facteurs) sont. C’est le contenu. Ce sont les liens qui pointent vers votre site.
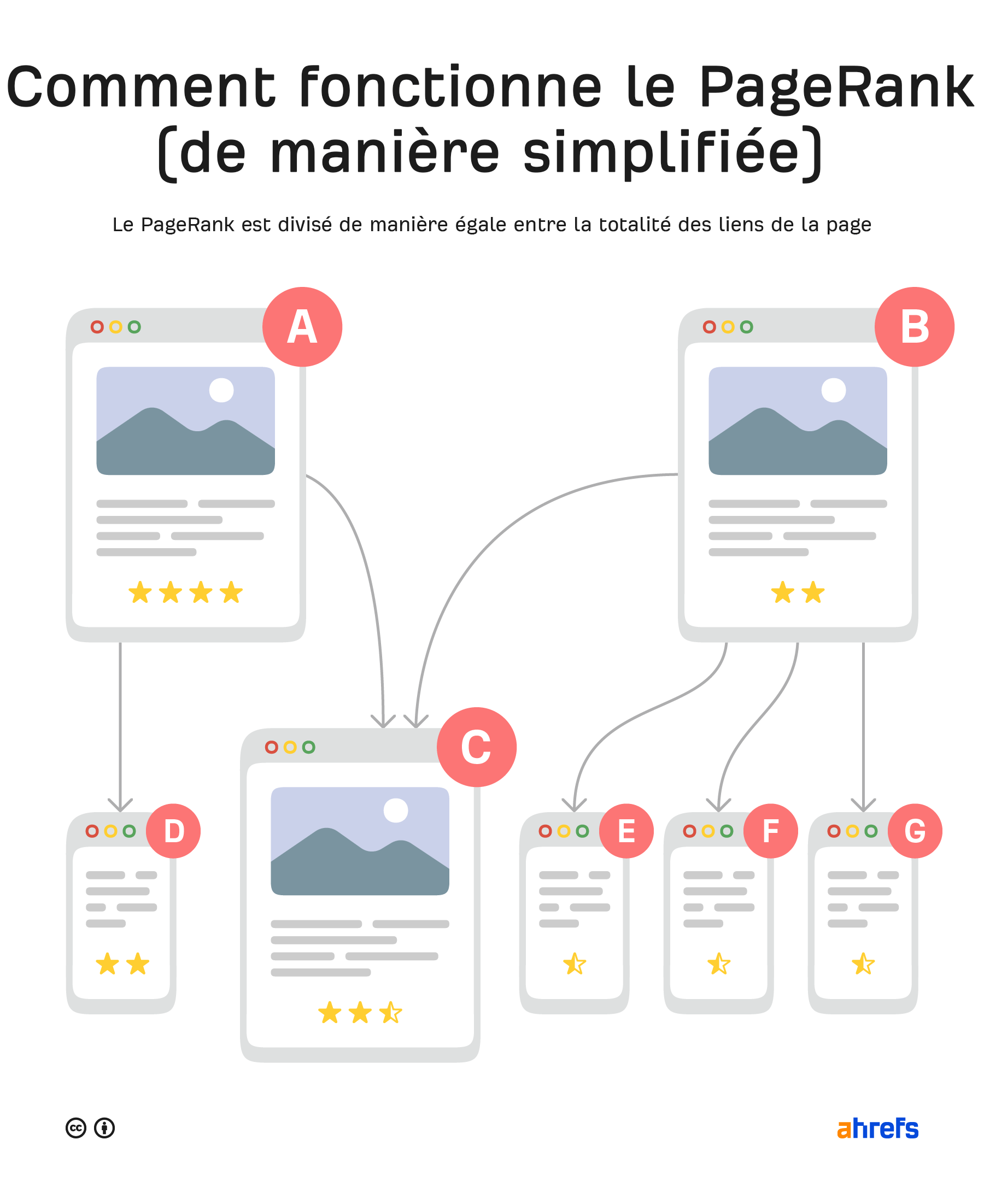
Les liens ont été d’une importance capitale pour Google depuis 1997 lorsqu’ils ont mis en place PageRank, une formule dont le but est de juger de la valeur d’une page web en se basant sur la quantité et la qualité des liens entrants vers le site.
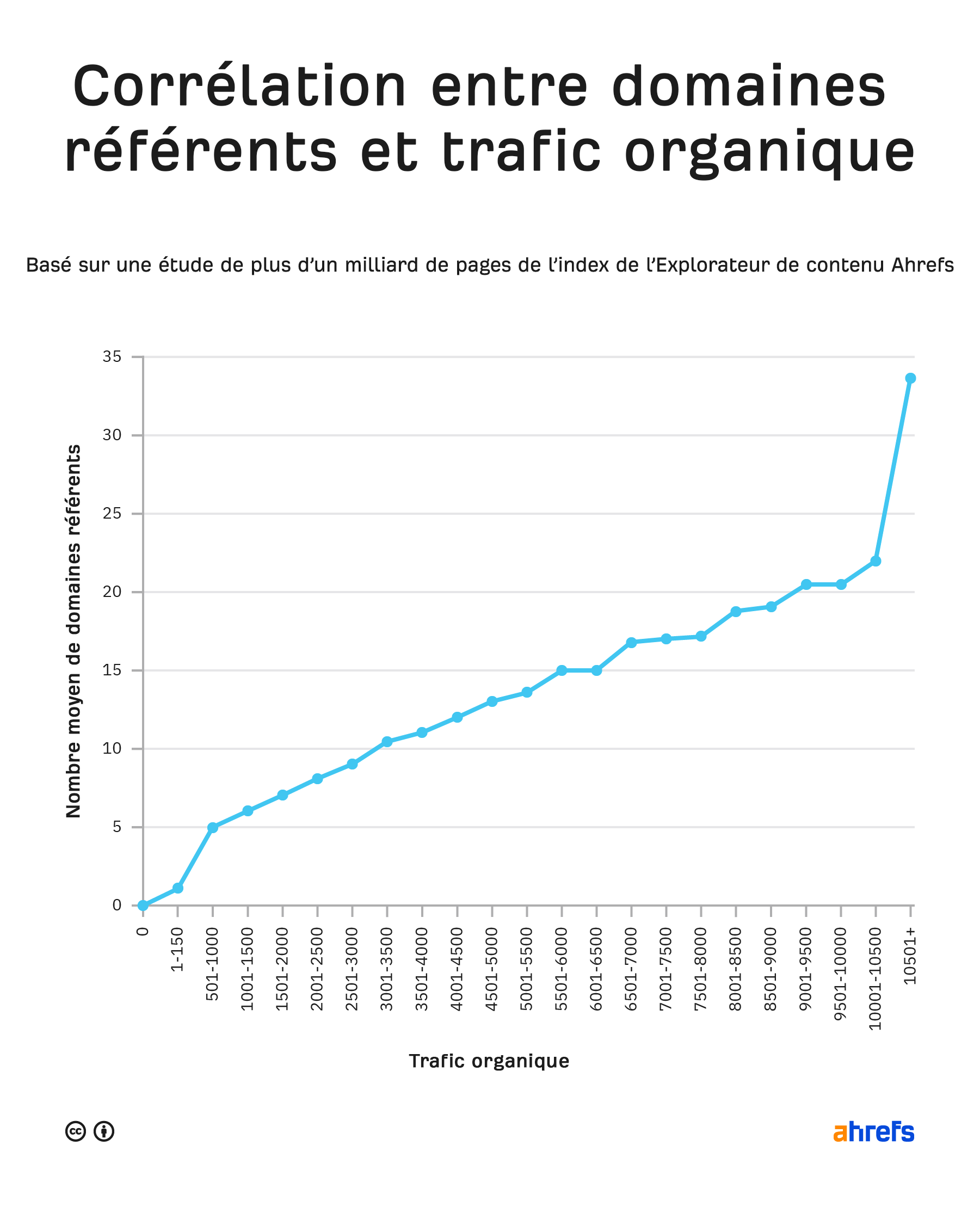
Lorsque nous avons analysé plus d’un milliard de pages, nous avons découvert une forte corrélation entre le nombre de sites qui proposent un lien vers une page et le trafic organique que cette dernière obtient de Google.
Mais ce n’est pas qu’une question de quantité, tous les backlinks ne sont pas égaux. Il est tout à fait possible pour une page d’avoir peu de backlinks de qualité et d’en dépasser une autre qui dispose de beaucoup plus de backlinks, mais de plus basse qualité.
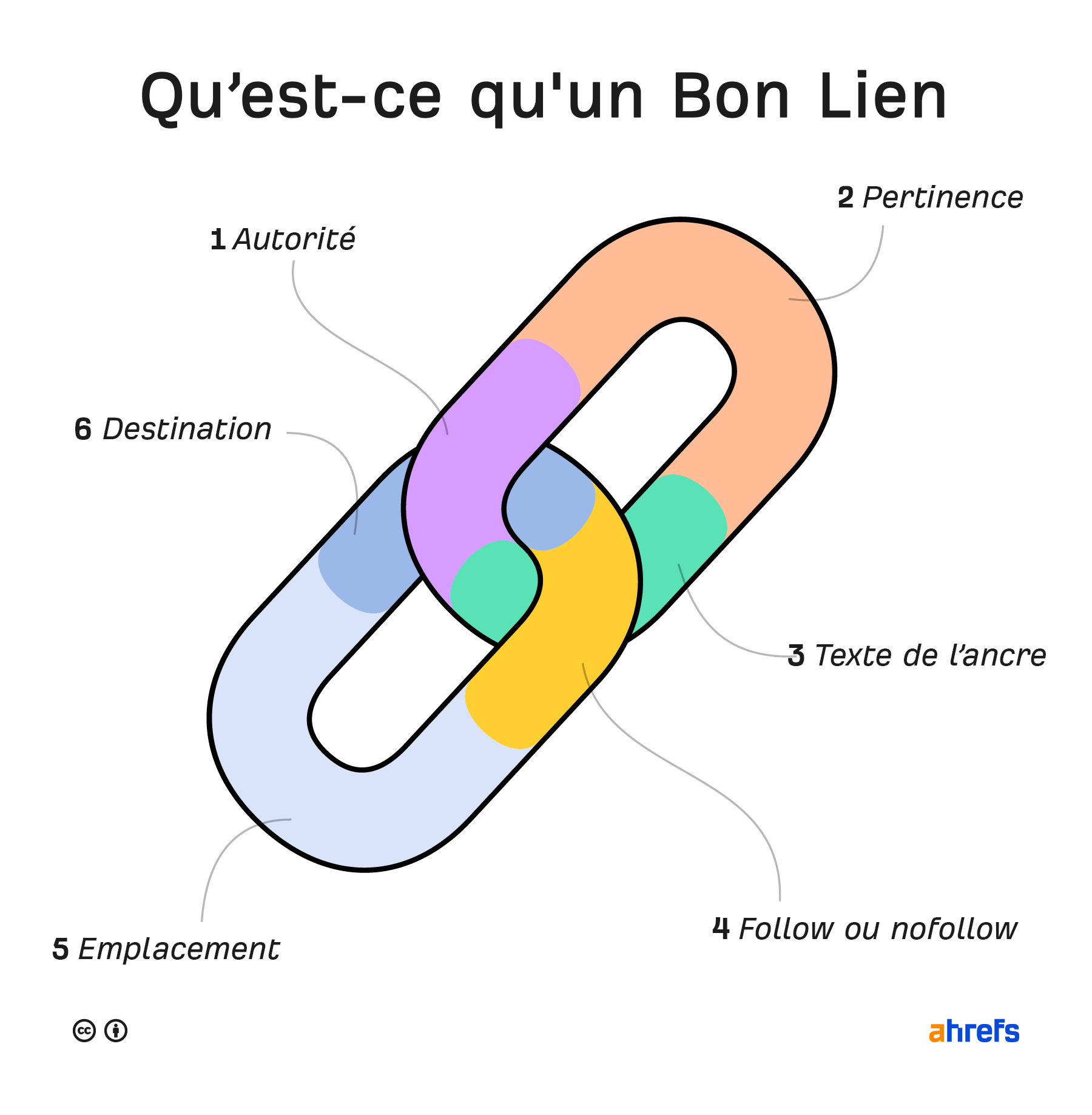
Il y a six facteurs clés pour définir un bon backlink.
Regardons d’un peu plus près ce que l’on pourrait considérer comme les deux éléments les plus importants : l’autorité et la pertinence.
Autorité de lien
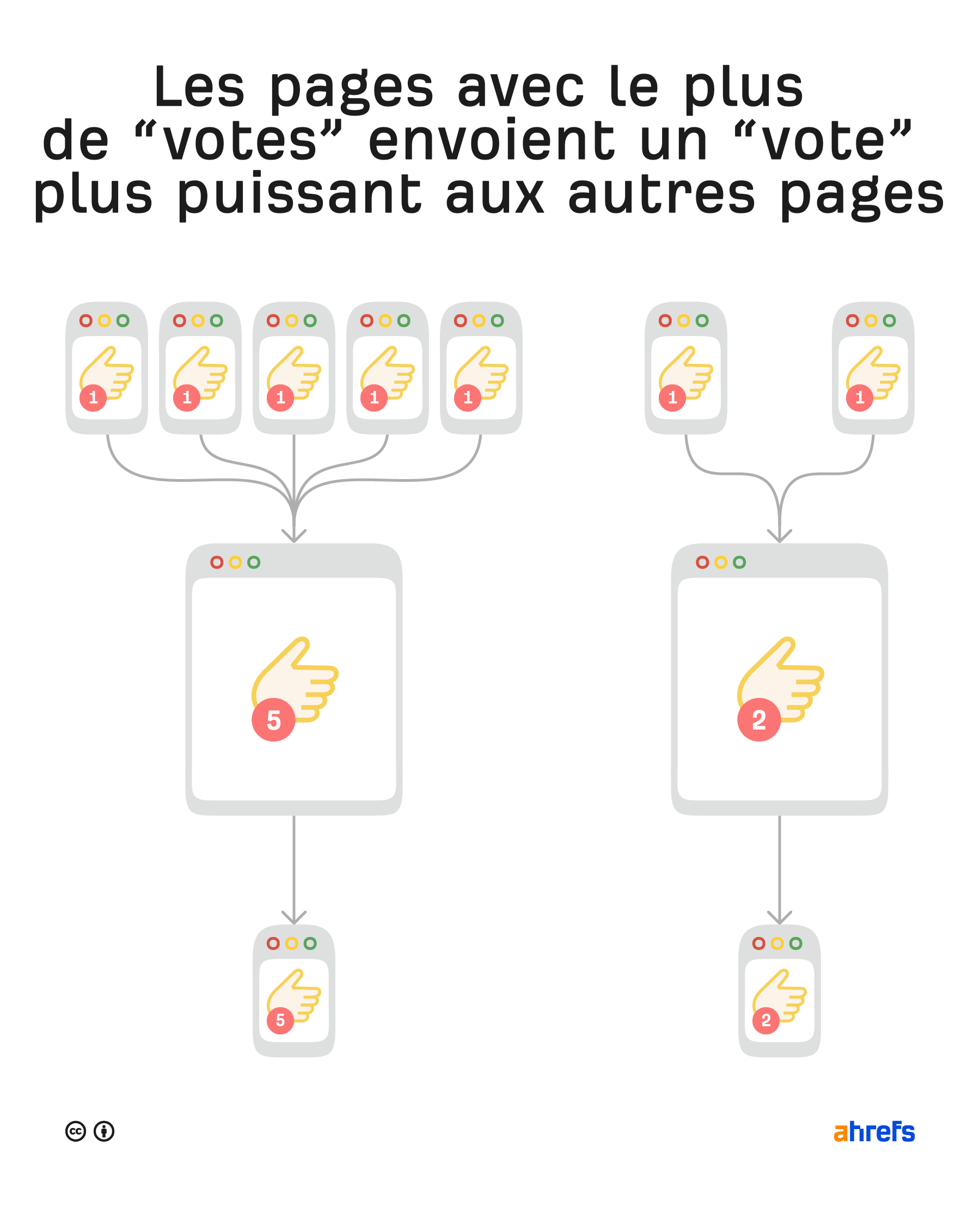
Les backlink sur des pages ou sites qui sont déjà reconnus comme d’une certaine autorité ou importance ont un plus gros impact sur le ranking.
Comment définir l’autorité ? Dans le SEO, ce que l’on considère comme ayant une forte autorité sont les pages ou sites qui ont le plus de backlinks, que l’on peut considérer comme des “votes”.
Chez Ahrefs, nous nous basons sur deux facteurs pour estimer l’autorité relative d’une page ou d’un site :
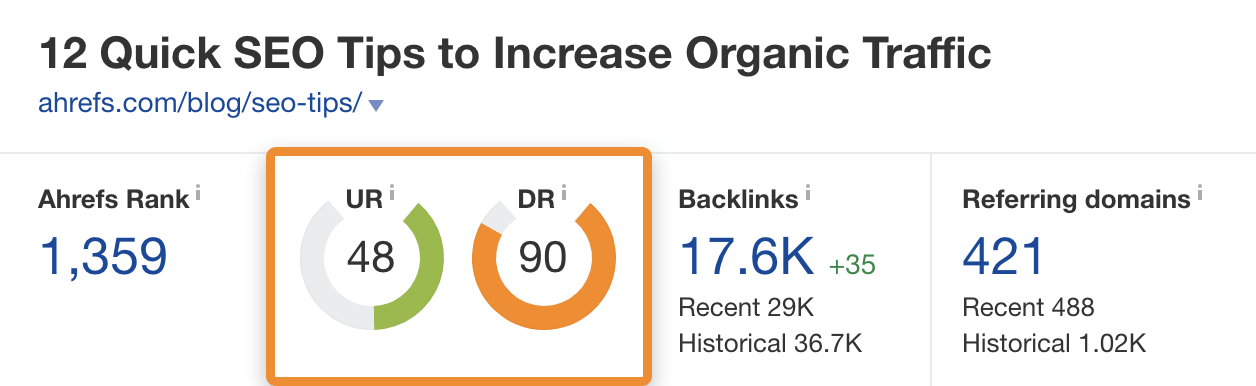
L’autorité de domaine ou Domain Rating (DR) : l’autorité relative d’un site sur une échelle de 0 à 100.
L’autorité d’URL ou URL Rating (UR) : l’autorité relative d’une page sur une échelle de 0 à 100.
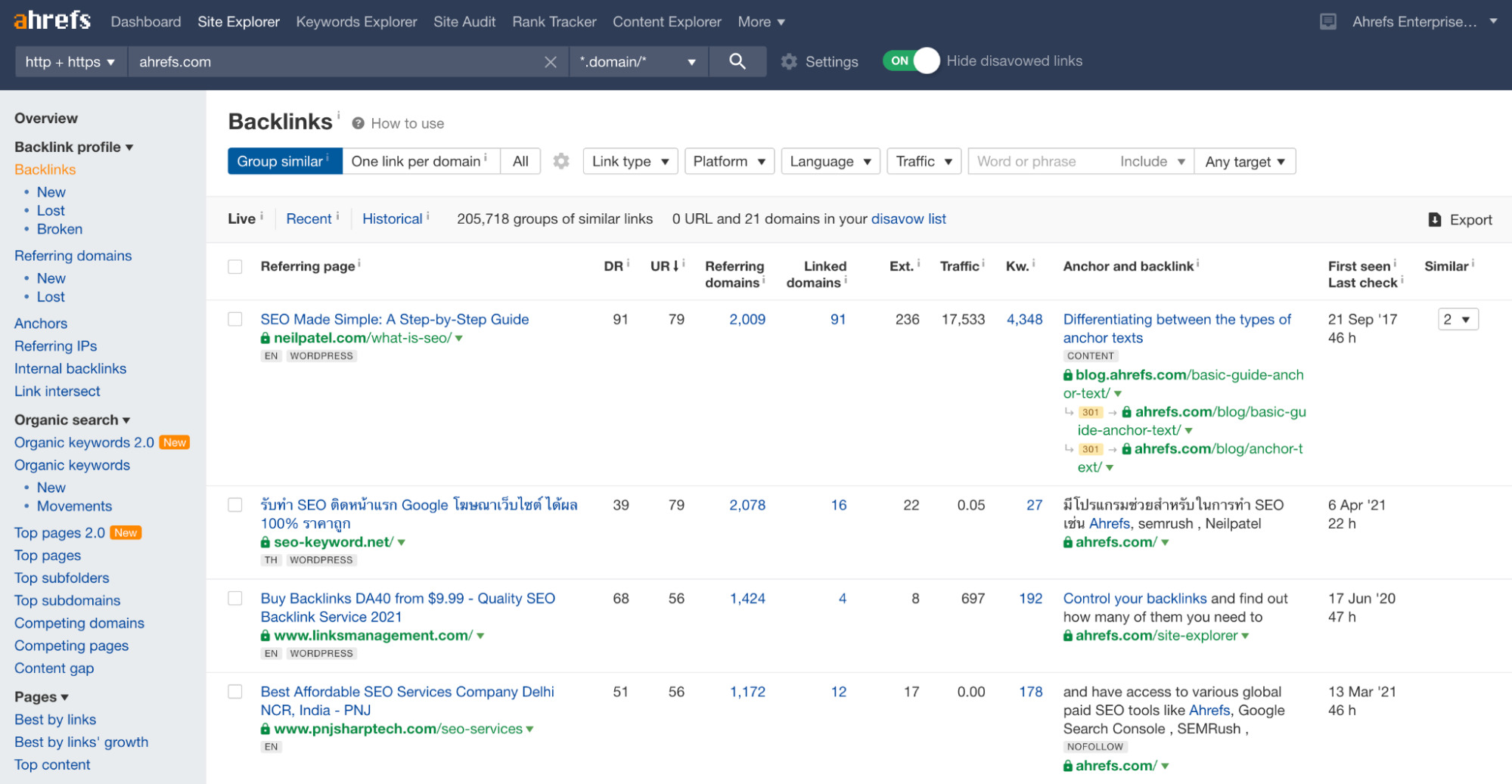
Vous pouvez voir l’autorité de n’importe quel site ou page dans l’Explorateur de Site de Ahrefs.
Pertinence de lien
Les liens qui viennent de sites et pages pertinents ont généralement plus de valeur.
Si d’autres sites reconnus sur le sujet renvoient vers la page, c’est un bon signal que l’information est de bonne qualité.
Si vous vous demandez pourquoi la pertinence a une importance, comparez cela à la vraie vie. Vous allez sans doute porter plus de crédit à l’avis de votre ami chef cuisinier lorsque vous cherchez un bon restaurant qu’à celui de votre ami vétérinaire. Mais si vous cherchiez des informations sur la nourriture pour chat, ce serait l’inverse.
Pertinence
Google a plusieurs moyens de déterminer la pertinence d’une page.
Pour ce qui est du plus simple, il vérifie que les pages contiennent les mêmes mots-clés que la requête de recherche.
“Le signal le plus simple indiquant la présence d’informations pertinentes dans une page Web est la présence de mots-clés figurant dans votre requête de recherche.”
Mais la pertinence va bien plus loin que la recherche de la présence de mots-clés.
Google utilise aussi des données sur l’interaction de ses utilisateurs avec ses résultats de recherche. En d’autres mots, est-ce que les utilisateurs trouvent la page utile ?
“Au-delà de la simple identification de mots-clés en commun, nous utilisons des données d’interactions globales et anonymes pour évaluer l’intérêt des résultats de recherche en lien avec les requêtes.”
C’est en grande partie pour cela que tous les meilleurs résultats pour “apple” sont au sujet de la société, pas du fruit (pomme en anglais). En analysant les données d’interactions, il a déterminé que la majorité des personnes qui tapent ces recherches veulent en apprendre plus sur la marque que sur le fruit.
Mais ces fameuses données d’interactions ne sont pas les seuls éléments sur lesquels Google se base.
La société a investi dans beaucoup de technologies différentes pour l’aider à mieux comprendre les liens entre les entités comme les gens, les lieux et les objets. Le Knowledge Graph (littéralement graphique de connaissance) est l’une de ces technologies, qui n’est ni plus ni moins qu’une immense base de données d’entités et des relations qu’elles ont entre elles.
Apple (le fruit en anglais) et Apple (la société) sont des entités connues du Knowledge Graph.
Google utilise les liens entre les entités pour mieux comprendre la pertinence d’une page. Un résultat qui correspond à “apple” et parle aussi d’oranges et de bananes se réfère clairement au fruit. Mais une qui parle aussi d’iPhone, iPad et iOS parle certainement de l’entreprise.
C’est en partie grâce à ce Knowledge Graph que Google peut aller plus loin que la simple correspondance des mots-clés.
Parfois vous pouvez voir des résultats de recherche qui ne contiennent même pas les mots-clés qui semblent importants dans la requête. Par exemple, si on regarde certains résultats de la première page pour “apple paper app”, le mot “apple” n’est pas dans le contenu.
Google sait que c’est un résultat pertinent en grande partie car la page mentionne des entités comme iPhone et iPad qui sont bien évidemment très proches d’Apple dans le Knowledge Graph.
Note.
Les données d’interactions et le Knowledge Graph ne sont pas les seules technologies utilisées par Google pour jauger de la pertinence d’une page par rapport à la requête de recherche. Une bonne partie du travail repose aussi sur d’autres technos pour comprendre le sens et les intentions derrière la requête en elle-même, comme BERT et RankBrain. Parfois Google réécrit la requête sans le montrer pour donner des résultats plus pertinents.
Fraîcheur
La fraîcheur (à quel point le contenu est récent) est aussi un facteur qui va dépendre de la requête, elle aura plus d’importance pour certaines requêtes que pour d’autres.
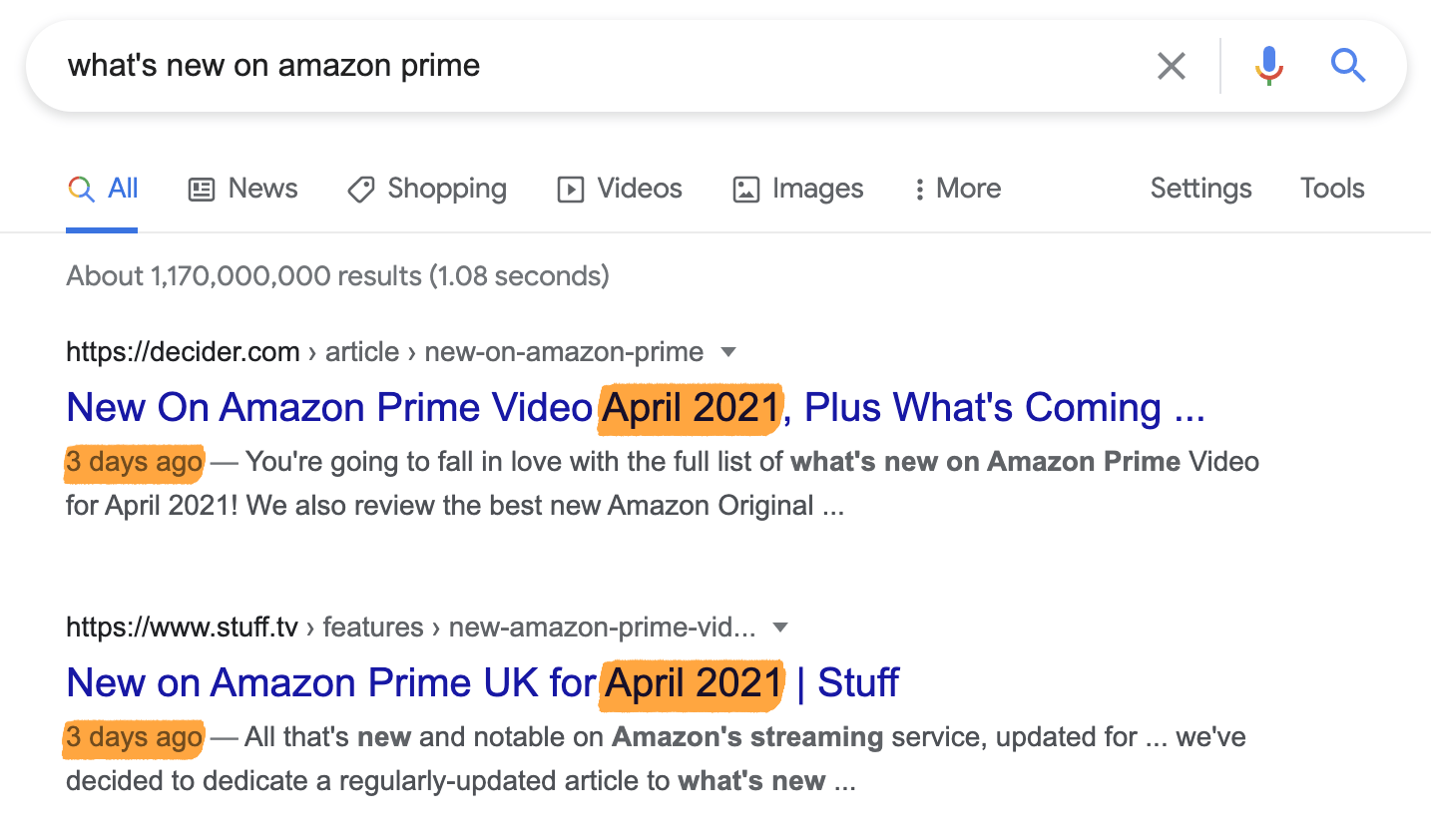
Pour une requête comme “dernières sorties sur amazon prime” la fraîcheur est très importante car les utilisateurs veulent savoir quels sont les derniers films et séries qui ont été ajoutés au catalogue. C’est pour cela que Google va placer en premier les pages récemment publiées ou mises à jour.
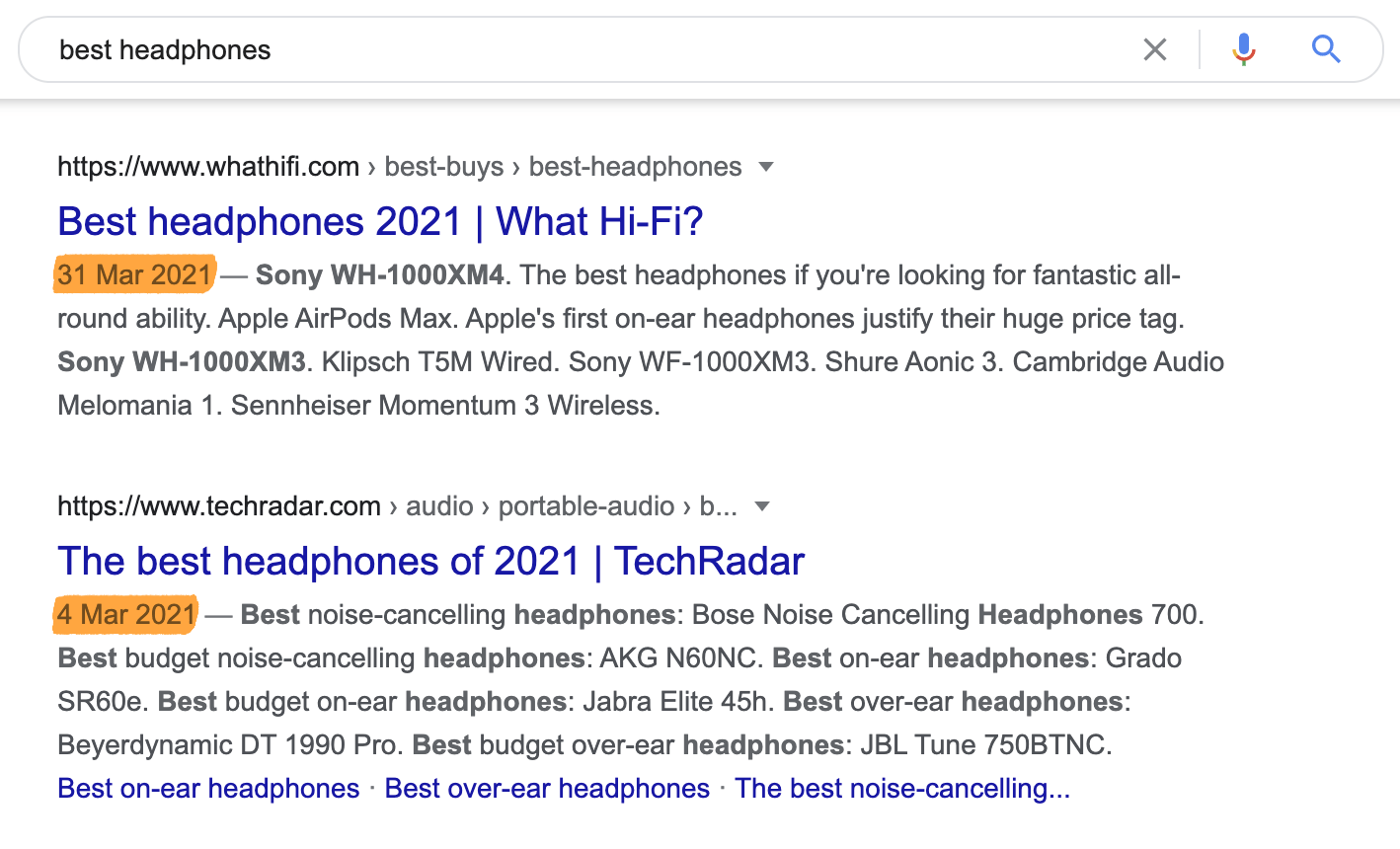
Pour des requêtes comme “meilleur casque audio”, la fraîcheur a aussi de l’importance, mais un peu moins. La technologie audio va vite donc un résultat de 2015 n’aura pas beaucoup d’importance, mais un article publié il y a 2 ou 3 mois pourrait toujours être utile.
Google le sait et pourra montrer des résultats qui ont été publiés ou mis à jour dans les derniers mois.
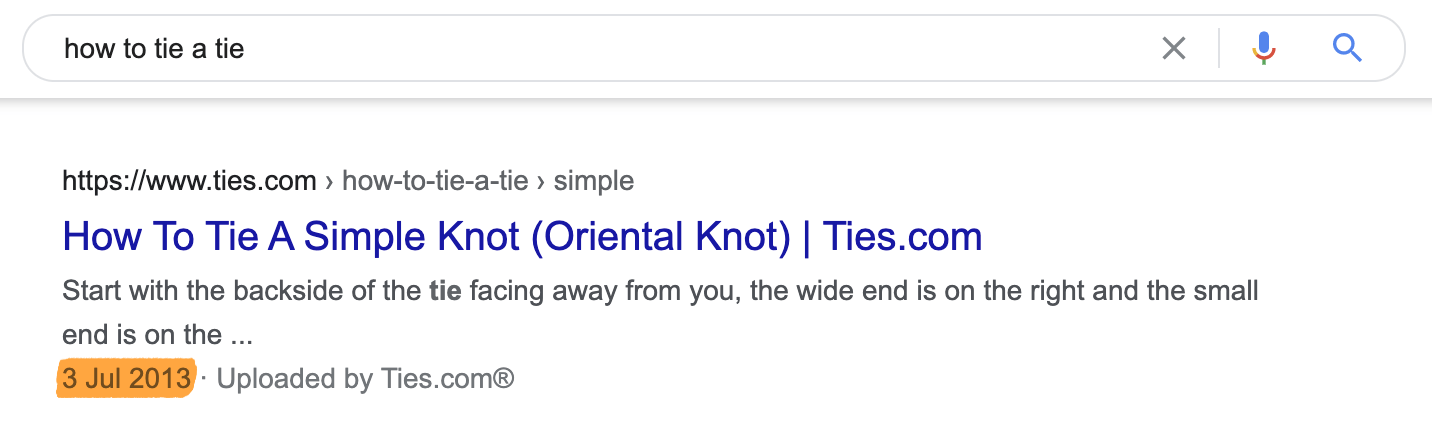
Et il existe aussi des requêtes où la fraîcheur du résultat n’a quasiment aucune importance, comme pour “comment faire un nœud de cravate”. Rien n’a changé à ce sujet depuis des décennies donc, peu importe si la page a été publiée hier ou en 1998. Google le sait bien et n’a aucun problème à bien positionner des articles qui ont été écrits il y a des années.
Autorité du sujet
Google veut classer en premier le contenu de sites qui ont une certaine autorité sur un sujet. Cela veut dire qu’il va juger qu’un site peut tout à fait être une bonne source pour des requêtes sur un certain sujet, mais pas sur d’autres.
Que le système de recherche considère un site comme d’autorité va être dépendant de la requête (…) par exemple le système peut considérer un site du centre de contrôle des maladies “cdc.gov” pour être une source d’autorité pour des recherches comme “CDC piqûre de moustique”, mais ne le trouvera pas pertinent pour des requêtes comme “recommandation de restaurant”.
Même si cela n’est que l’un des nombreux brevets déposés par Google, on voit facilement les preuves que “l’autorité de sujet” joue un rôle dans le classement des résultats pour beaucoup de requêtes.
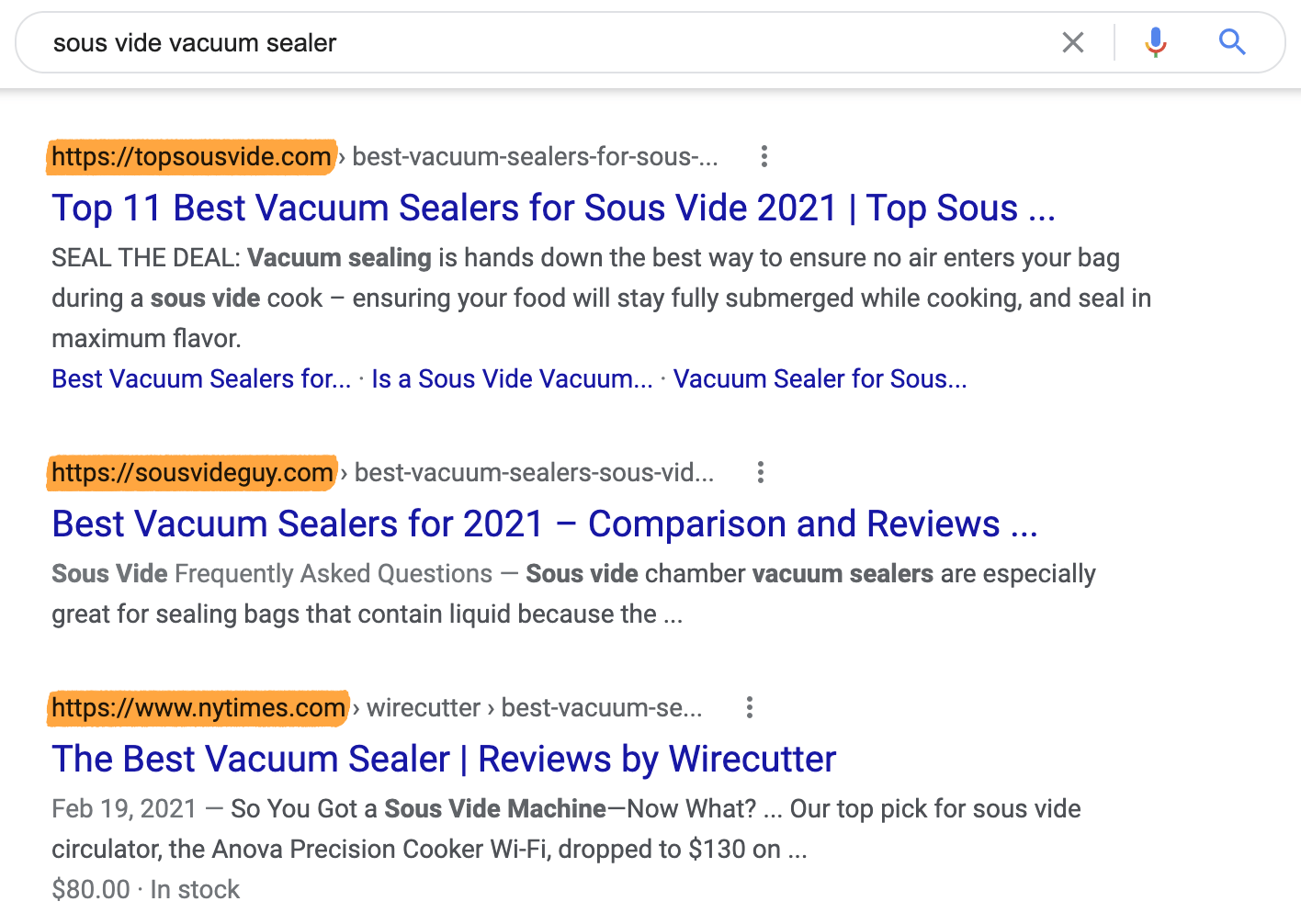
Voyons les résultats pour “sous vide vacuum sealer” (pompe à vide).
Nous voyons ici deux petits sites de niche qui parlent de la cuisine sous vide qui dépasse le New York Times.
Même s’il y a certainement d’autres facteurs en jeu ici, il semble très probable que “l’autorité de sujet” est l’une des raisons du positionnement de ces sites.
Cultivez la réputation d’expertise et de fiabilité dans un domaine spécifique.
Vitesse de la page
Personne n’aime attendre que les pages chargent, et Google le sait. C’est pour cela que la vitesse d’une page entre en compte dans le classement des résultats sur ordinateur depuis 2010 et des recherches sur mobile depuis 2018.
Beaucoup de gens font une fixation sur la vitesse des pages, il faut donc préciser que vos pages n’ont pas besoin de charger à la vitesse de l’éclair. Google dit que la vitesse de chargement n’est considérée comme problématique que pour celles qui “offrent l’expérience la plus lente à leurs utilisateurs”.
En d’autres termes, gagner quelques millisecondes sur un site qui est déjà rapide a peu de chance d’améliorer votre positionnement. Il faut juste qu’il soit suffisamment rapide pour ne pas avoir un impact négatif sur les utilisateurs.
Vous pouvez vérifier la vitesse de n’importe quelle page web dans le PageSpeed Insights, qui va aussi vous donner des suggestions pour améliorer ces scores.
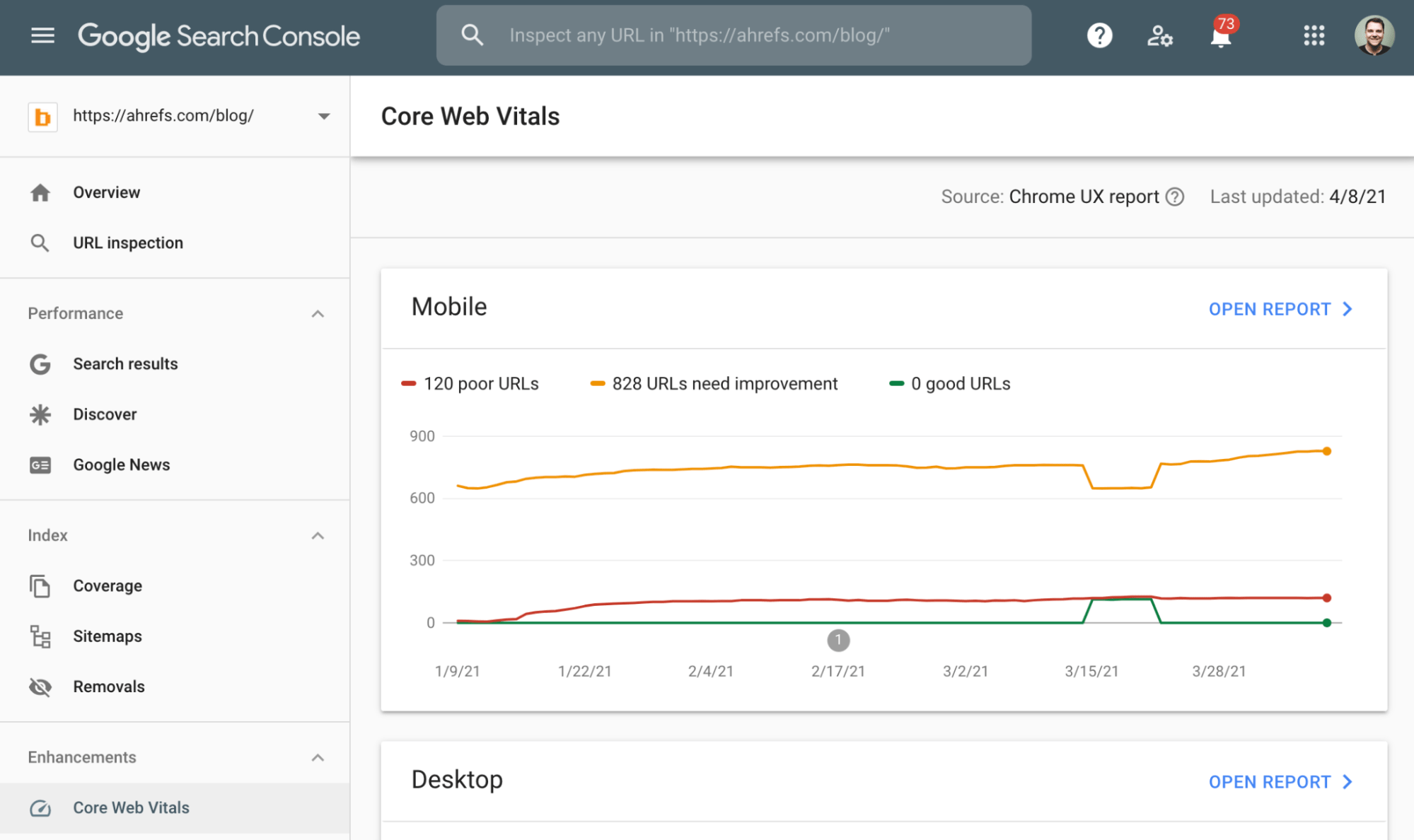
Le rapport de PageSpeed Insight vous montre aussi les scores de votre page au niveau des Core Web Vitals.
Les Core Web Vitals sont basés sur trois indicateurs qui vont juger de la performance de chargement d’une page, de son interactivité et de sa stabilité visuelle. Google a confirmé que les Core Web Vitals vont commencer à avoir un rôle dans le ranking à partir de juin 2021.
Vous pouvez voir les performances de toutes les pages de votre site grâce au rapport Core Web Vitals de la Google Search Console.
Si un grand nombre de vos URL ont une mauvaise optimisation et ont besoin d’être améliorées, parlez-en à un développeur.
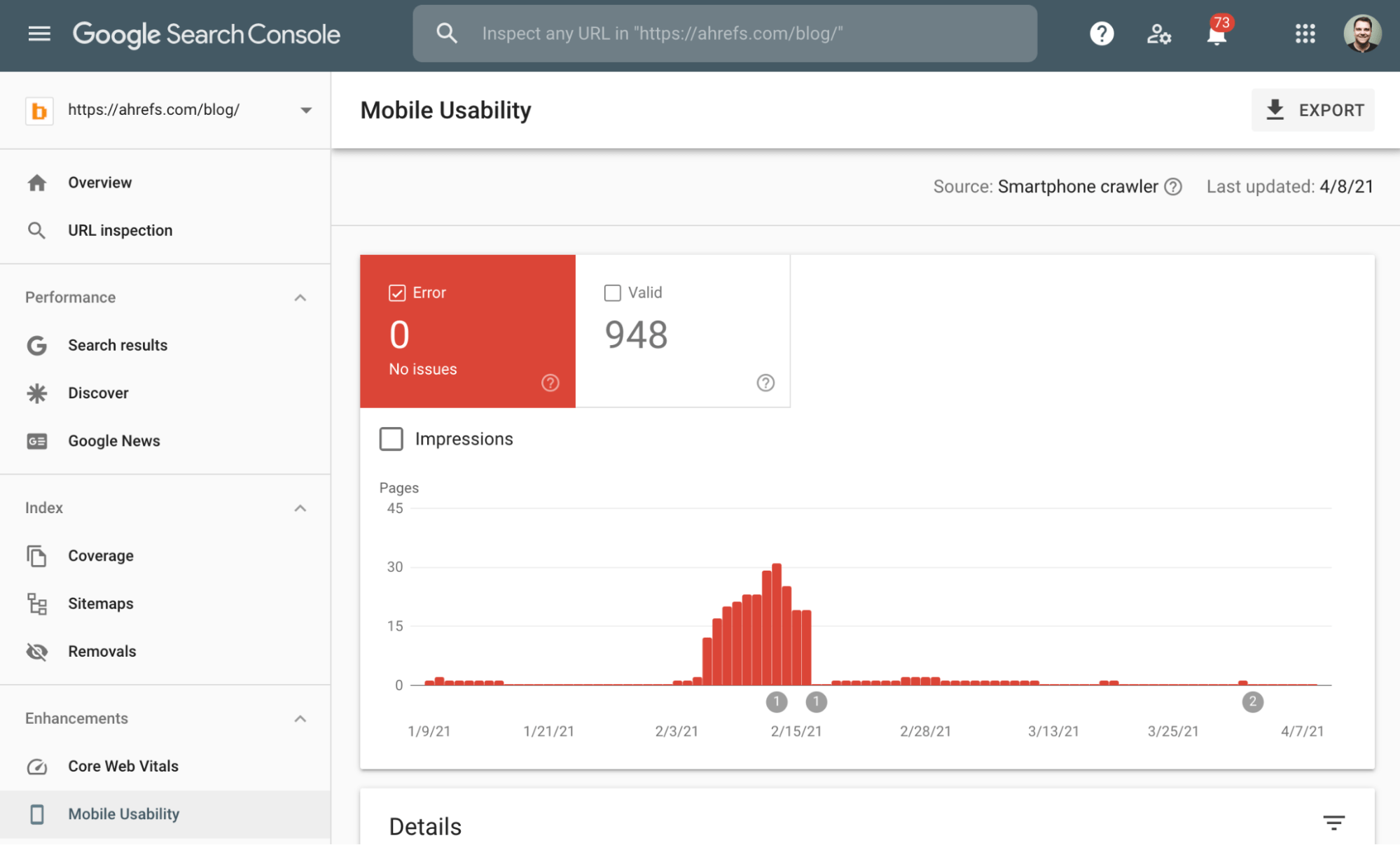
Depuis 2019, le responsive est aussi un facteur de ranking pour les recherches sur ordinateur car Google est passé sur une indexation mobile first. Cela veut dire que Google “favorise l’utilisation de la version mobile du contenu pour l’indexation et le ranking” quel que soit l’appareil utilisé.
En d’autres termes, un site mal optimisé sur mobile sera pénalisé dans son ranking, même sur ordinateur.
Vous pouvez vérifier si votre site est considéré comme mobile-friendly en utilisant l’outil de Google Mobile-Friendly Test, ou bien dans la partie Ergonomie mobile de la Google Search Console.
Comment les moteurs de recherche personnalisent les résultats
Les moteurs de recherche savent que différents résultats ne vont pas parler de la même manière à différentes personnes. C’est pour cela qu’ils proposent des résultats sur mesure à chaque utilisateur.
Si vous avez déjà tenté l’expérience de chercher les mêmes requêtes sur plusieurs appareils ou navigateurs, vous aurez déjà vu ces personnalisations. Les résultats ne vont souvent pas être positionnés au même endroit en fonction de différents résultats.
C’est pour cela que si vous travaillez sur le SEO, il vaut mieux vous servir d’outils dédiés comme le Rank Tracker d’Ahrefs pour suivre les positions dans le SERP. Le ranking proposé dans ces outils est normalement plus proche de la réalité car ils consultent le web d’une manière qui ne donne pas aux moteurs de recherche d’informations leur permettant de personnaliser les résultats.
Comment les moteurs de recherche personnalisent les résultats ?
Google déclare que des “informations comme votre position, vos historiques de recherche et paramètres de recherche (nous) aident à adapter les résultats à ce qui est le plus pertinent et vous est le plus utile sur le moment”.
Voyons ces trois éléments de plus près :
1. Position
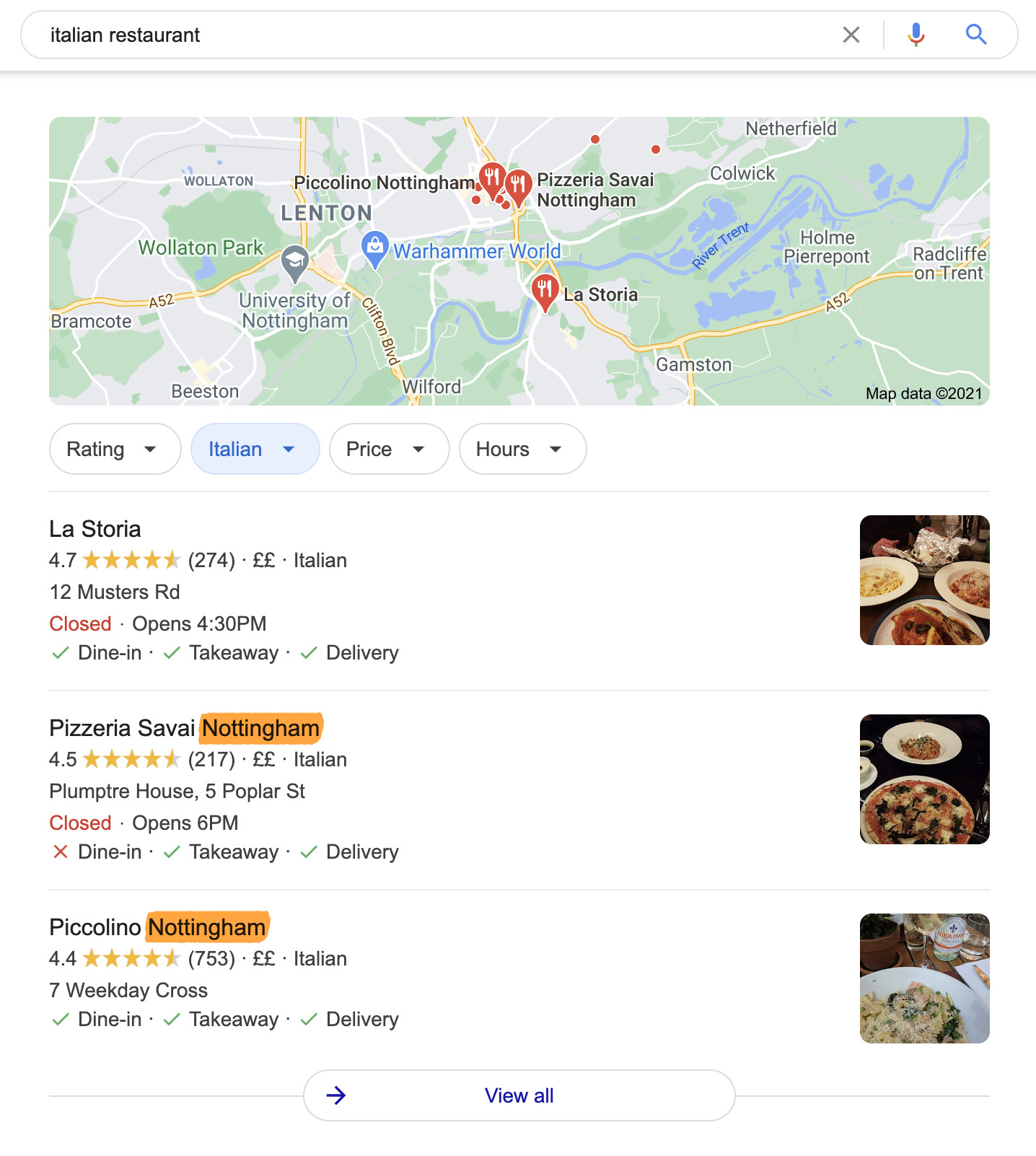
Si vous cherchez quelque chose comme “restaurant italien”, vous verrez dans les résultats de maps que vous aurez des restaurants locaux.
Google fait cela car il y a peu de chance que vous preniez un avion pour l’autre bout du monde juste pour déjeuner.
Mais Google utilise aussi votre position pour personnaliser les résultats en dehors de maps. Si vous descendez dans les résultats pour “restaurant italien” même les résultats de TripAdvisor sont personnalisés et l’on voit également que la plupart des meilleurs résultats sont des sites de restaurants locaux.
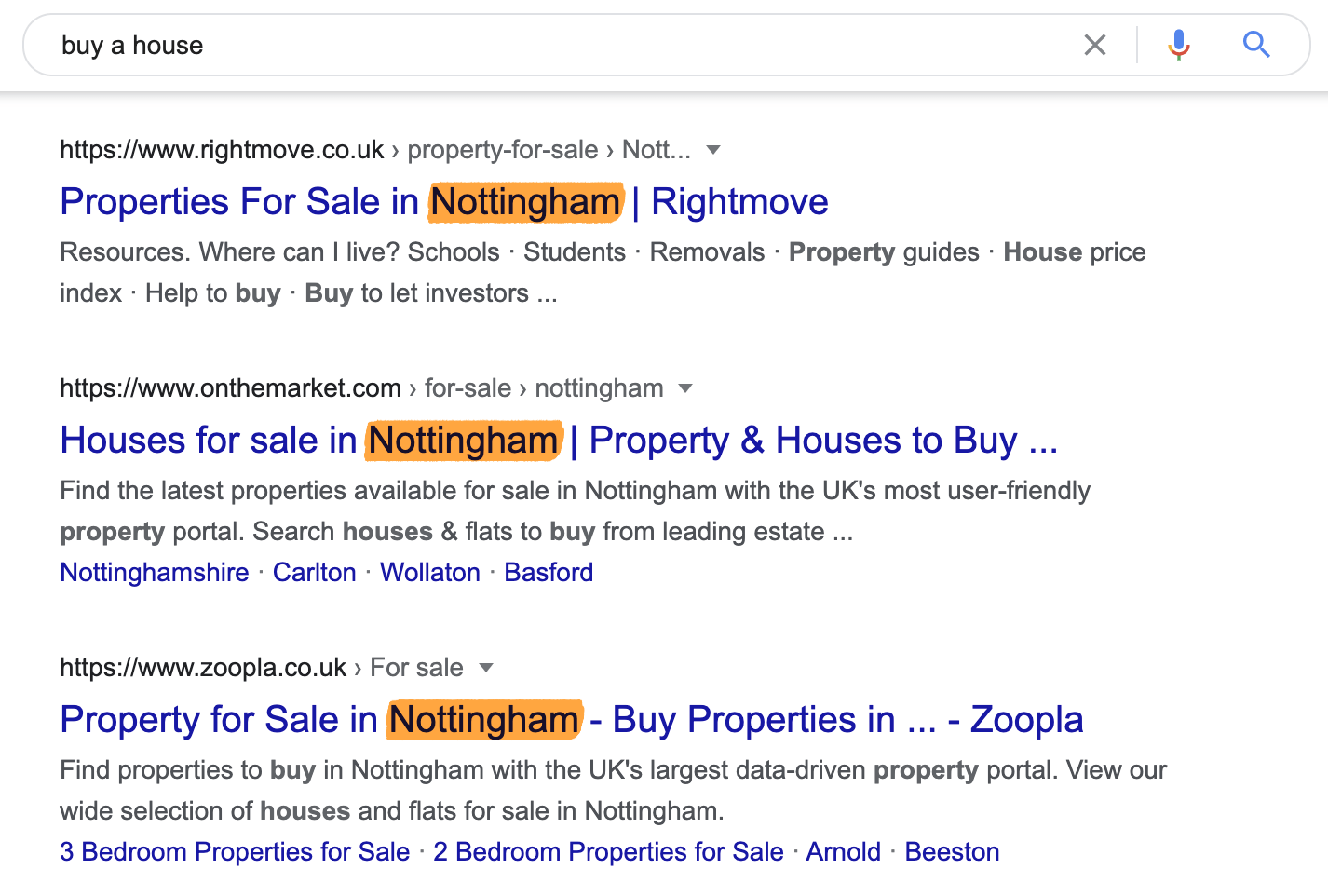
Ce sera la même chose pour des requêtes comme “acheter une maison”. Google va sortir les résultats autour de vous plutôt que de partir du principe que vous voulez changer de pays.
Votre position va avoir un tel impact sur les résultats de requêtes locales qu’il n’y a quasiment aucune similarité si vous cherchez la même chose à deux endroits différents.
2. Langue
Google sait qu’il n’y a pas d’intérêt à proposer des résultats en anglais pour des utilisateurs espagnols. C’est pour cela qu’il positionne la version anglaise de notre tuto SEO YouTube pour des recherches anglophones et la version en espagnol pour les recherches hispanophones.
Mais d’une certaine manière, Google s’appuie sur les créateurs de site internet pour faire cela. Si vous avez des pages en plusieurs langues, il ne va pas forcément s’en rendre compte si vous ne le lui “dites” pas.
Vous pouvez le faire avec un attribut HTML appelé hreflang.
L’utilisation de hreflang est un peu compliquée et sort du spectre de ce guide, mais pour faire simple c’est un petit bout de code qui indique la relation entre plusieurs versions d’une même page en différentes langues.
3. Historique de recherche
L’exemple sans doute le plus flagrant de la manière dont Google utilise l’historique de recherche pour personnaliser le résultat est lorsqu’il positionne plus haut un résultat sur lequel vous avez cliqué la dernière fois que vous avez effectué cette recherche.
Cela n’arrive pas systématiquement, mais reste assez fréquent, surtout si vous cliquez sur le résultat ou visitez une page plusieurs fois sur une courte période.
Pour conclure
Comprendre la manière dont fonctionnent les moteurs de recherche et la première étape pour apprendre à mieux se positionner dans Google et obtenir plus de trafic. Si les moteurs de recherche ne peuvent trouver, explorer et indexer vos pages, vous avez perdu d’entrée de jeu.
Si vous voulez apprendre les bases de l’optimisation de site pour le référencement, vous pouvez lire notre guide sur les bases du SEO.
Vous avez des questions ? Faites-le-moi savoir dans les commentaires ou sur Twitter.