Para eso están las metaetiquetas robots y la cabecera HTTP X-Robots-Tag.
Dejemos una cosa clara desde el principio: no se puede controlar la indexación con robots.txt. Es un error muy común.
La regla noindex en robots.txt nunca fue apoyada formalmente por Google, quedando oficialmente obsoleta en julio de 2019.
¿Eres nuevo en el SEO técnico? Consulta nuestra
guía para principiantes al SEO técnico
Una metaetiqueta robots es un fragmento de HTML que indica a los robots de los motores de búsqueda lo que pueden y no pueden hacer en una página determinada. Permite controlar el rastreo, la indexación y cómo se muestra la información de esa página en los resultados de búsqueda. Se coloca en la sección <head> de una página web.
Ejemplo
<meta name="robots" content="noindex, nofollow">
La metaetiqueta robots se suele utilizar para evitar que las páginas aparezcan en los resultados de búsqueda, aunque también tiene otros usos (los abordaremos más adelante).
Existen varios tipos de contenido que es posible que quieras que los motores de búsqueda no indexen:
- Páginas con poco o ningún valor para el usuario
- Páginas en un entorno de prueba
- Páginas de administración y agradecimiento
- Resultados de búsqueda interna
- Landing pages para el PPC
- Páginas sobre próximas promociones, concursos o lanzamientos de productos
- Contenido duplicado (utiliza etiquetas canónicas para sugerir la mejor versión para la indexación)
Por lo general, cuanto más grande sea tu web, más tiempo tendrás que invertir en gestionar la rastreabilidad y la indexación. Además, es necesario que Google y otros motores de búsqueda rastreen e indexen las páginas de la forma más eficaz posible. Combinar correctamente las directivas a nivel de página con robots.txt y sitemaps es crucial para el SEO.
Las metaetiquetas robots constan de dos atributos: name y content.
Tienes que especificar valores para cada uno de estos atributos. Veamos cuáles son.
El atributo name y los valores de user-agent
El atributo name especifica qué rastreadores deben seguir estas instrucciones. Este valor también se conoce como user-agent (UA) porque los rastreadores necesitan identificarse con el UA para solicitar una página. Tu UA refleja el navegador que utilizas, pero los user-agents de Google son, por ejemplo, Googlebot o Googlebot-image.
El valor UA “robots” se aplica a todos los rastreadores. También puede añadir todas las metaetiquetas robots que necesites en la sección <head>. Por ejemplo, si quieres evitar que tus imágenes aparezcan en una búsqueda de imágenes de Google o Bing, añade las siguientes metaetiquetas:
<meta name="googlebot-image" content="noindex">
<meta name="MSNBot-Media" content="noindex">
El atributo de content y las directivas de rastreo e indexación
El atributo content proporciona instrucciones sobre cómo rastrear e indexar la información de la página. Si no hay metaetiqueta robots, los rastreadores la interpretan como indexar y seguir. Esto les da permiso para mostrar la página en los resultados de búsqueda y rastrear todos los enlaces de la página (a no ser que se indique lo contrario con la etiqueta rel=“nofollow”).
Vamos a ver los valores admitidos por Google para el atributo content:
all
El valor predeterminado de “index, follow”. No es necesario utilizar nunca esta directiva.
<meta name="robots" content="all">
noindex
Indica a los motores de búsqueda que no indexen la página. Esto impide que aparezca en los resultados de búsqueda.
<meta name="robots" content="noindex">
nofollow
Impide que los robots rastreen todos los enlaces de la página. Ten en cuenta que esas URL pueden seguir siendo indexables, especialmente si tienen backlinks que apunten a ellas.
<meta name="robots" content="nofollow">
none
La combinación de noindex, nofollow. No la utilices, ya que otros motores de búsqueda (por ejemplo, Bing) no la admiten.
<meta name="robots" content="none">
noarchive
Evita que Google muestre una copia en caché de la página en las SERP.
<meta name="robots" content="noarchive">
notranslate
Evita que Google ofrezca una traducción de la página en las SERP.
<meta name="robots" content="notranslate">
noimageindex
Evita que Google indexe las imágenes insertadas en la página.
<meta name="robots" content="noimageindex">
unavailable_after:
Indica a Google que no muestre una página en los resultados de búsqueda después de una fecha/hora determinada. Básicamente es una directiva noindex con un temporizador. La fecha/hora debe especificarse utilizando el formato RFC 850.
<meta name="robots" content="unavailable_after: Sunday, 01-May-23 12:34:56 GMT">
nosnippet
Desactiva todos los fragmentos de texto y vídeo dentro de las SERP. También funciona como noarchive al mismo tiempo.
<meta name="robots" content="nosnippet">
Desde octubre de 2019, Google ofrece opciones más personalizadas para controlar si quieres mostrar tus snippets en los resultados de búsqueda y cómo quieres hacerlo. Esto se debe, en parte, a la Directiva Europea de Derechos de Autor, que fue implementada por primera vez por Francia con su nueva ley de derechos de autor.
Lo más importante es que esta legislación ya afecta a todos los propietarios de páginas web. ¿Por qué? Porque Google ya no muestra snippets (texto, imagen o vídeo) de tu sitio a los usuarios de Francia, a menos que te registres mediante sus nuevas metaetiquetas robots.
A continuación, explicamos cómo funciona cada una de estas etiquetas. Dicho esto, si esto afecta a tu negocio y buscas una solución rápida, añade el siguiente fragmento HTML a todas las páginas de tu sitio para indicar a Google que no quieres restricciones en tus fragmentos:
<meta name="robots" content="max-snippet:-1, max-image-preview:large, max-video-preview:-1">
Ten en cuenta que, si utilizas Yoast SEO, este código se añade automáticamente en cada página a menos que hayas añadido las directivas noindex o nosnippet.
max-snippet:
Especifica el número máximo de caracteres que Google puede mostrar en sus fragmentos de texto. El uso de 0 excluirá los fragmentos de texto; -1 declara que no hay límite en la vista previa de texto.
La siguiente etiqueta establecerá el límite en 160 caracteres (similar a la longitud estándar de la meta descripción):
<meta name="robots" content="max-snippet:160">
max-image-preview:
Indica a Google si puede utilizar una imagen para los fragmentos de imagen y de qué tamaño. Esta directiva tiene tres valores posibles:
- none: no se mostrará ningún fragmento de imagen
- standard: se mostrará una vista previa de la imagen por defecto
- large: se mostrará la vista previa de la imagen más grande posible
<meta name="robots" content="max-image-preview:large">
Se recomienda utilizar el valor large con imágenes que tengan al menos 1200 px de ancho, ya que aumenta la probabilidad de aparecer en Google Discover.
max-video-preview:
Establece un número máximo de segundos para un fragmento de vídeo. Al igual que con el fragmento de texto, 0 lo excluirá por completo y -1 no pone límites.
La siguiente etiqueta permitiría a Google mostrar un máximo de 15 segundos:
<meta name="robots" content="max-video-preview:15">
Junto con las nuevas directivas de robots introducidas en octubre de 2019, Google también introdujo el atributo HTML data-nosnippet. Puedes utilizarlo para etiquetar partes de texto que no quieres que Google utilice como fragmento.
Esto se puede hacer en HTML en elementos div, span y section. El atributo data-nosnippet se considera un atributo booleano, lo que significa que es válido con o sin valor.
<p>Este es un texto de un párrafo que puede mostrarse como fragmento <span data-nosnippet> excluyendo esta parte </span></p><div data-nosnippet="">Esto no aparecería en un fragmento.</div><div data-nosnippet="true">Ni esto.</div>
nositelinkssearchbox
Evita que Google muestre un searchbox como parte de tus sitelinks.
<meta name="robots" content="nositelinkssearchbox">
indexifembedded
Permite a Google indexar contenido integrado mediante iframes o etiquetas HTML similares en una página con una directiva noindex. Solo funciona cuando ambas directivas están presentes, como en este caso:
<meta name="robots" content="noindex, indexifembedded">
La documentación de Google explica muy bien el caso de uso aquí.
Utilización de estas directivas
La mayoría de los SEO normalmente no tienen que ir más allá de las directivas noindex y nofollow, pero es bueno saber que existen otras opciones. Recuerda que todas las directivas de las que hablamos aquí se basan en las que admite Google. Hay algunas directivas exclusivas de otros motores de búsqueda, pero no merece la pena profundizar en ellas.
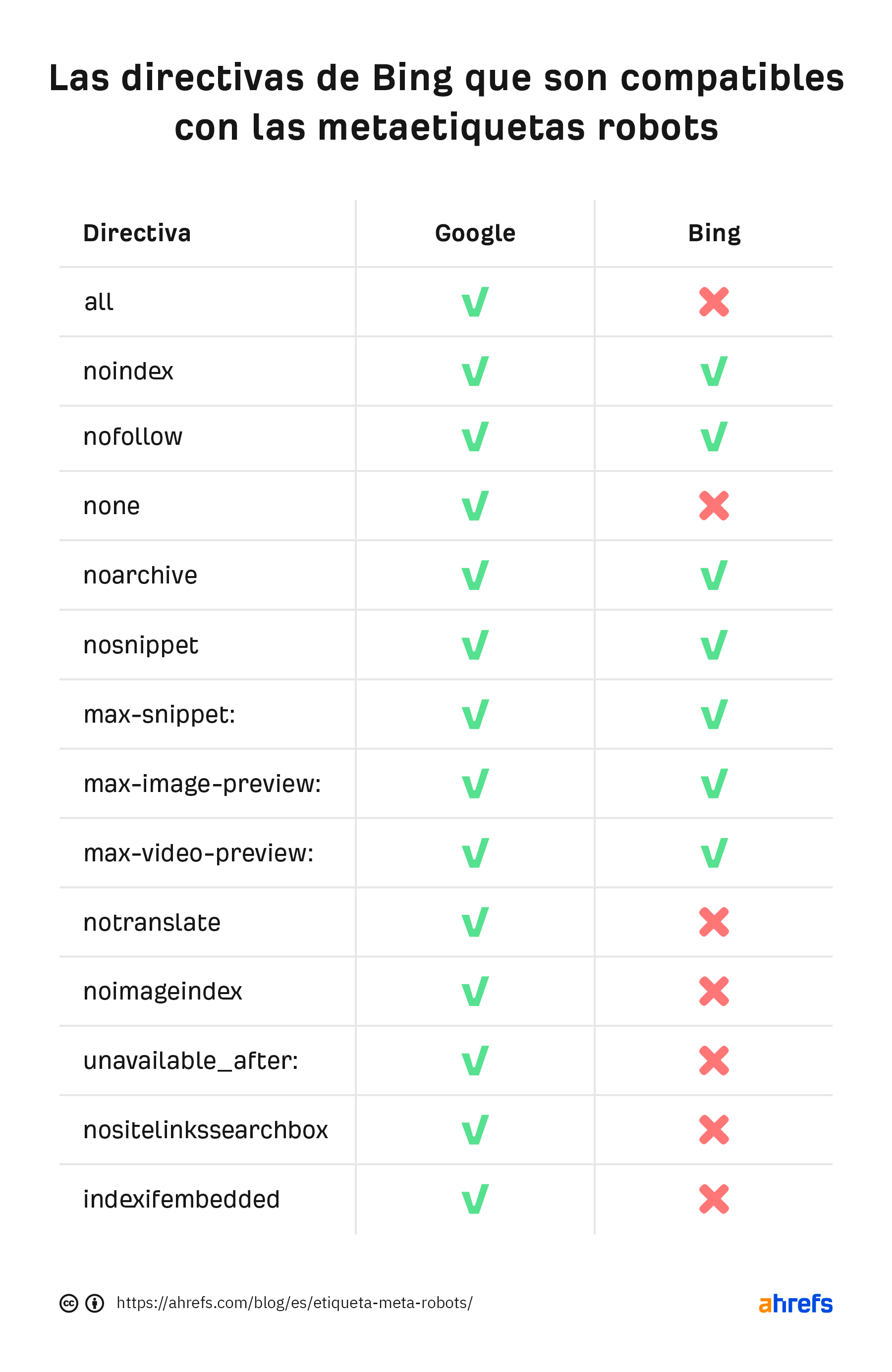
Veamos la comparación con Bing:
Puedes utilizar varias directivas a la vez y combinarlas, pero, si entran en conflicto (por ejemplo, “noindex, index”) o una es un subconjunto de otra (por ejemplo, “noindex, noarchive”), Google utilizará la más restrictiva. En estos casos, sería simplemente “noindex”.
Ahora que ya sabes qué hacen y qué aspecto tienen todas estas directivas, es hora de pasar a la implementación real en tu web.
Las metaetiquetas robots pertenecen a la sección <head>de una página. Es bastante sencillo si editas el código utilizando editores HTML como Notepad++ o Brackets, pero ¿y si utilizas un CMS con plugins SEO?
Vamos a centrarnos en la opción más popular que existe.
Implementación de metaetiquetas robots en WordPress usando Yoast SEO
Dirígete a la sección “Avanzado” debajo del bloque de edición de cada post o página. Configura la metaetiqueta robots según tus necesidades. La siguiente configuración implementaría las directivas “noindex, nofollow”.
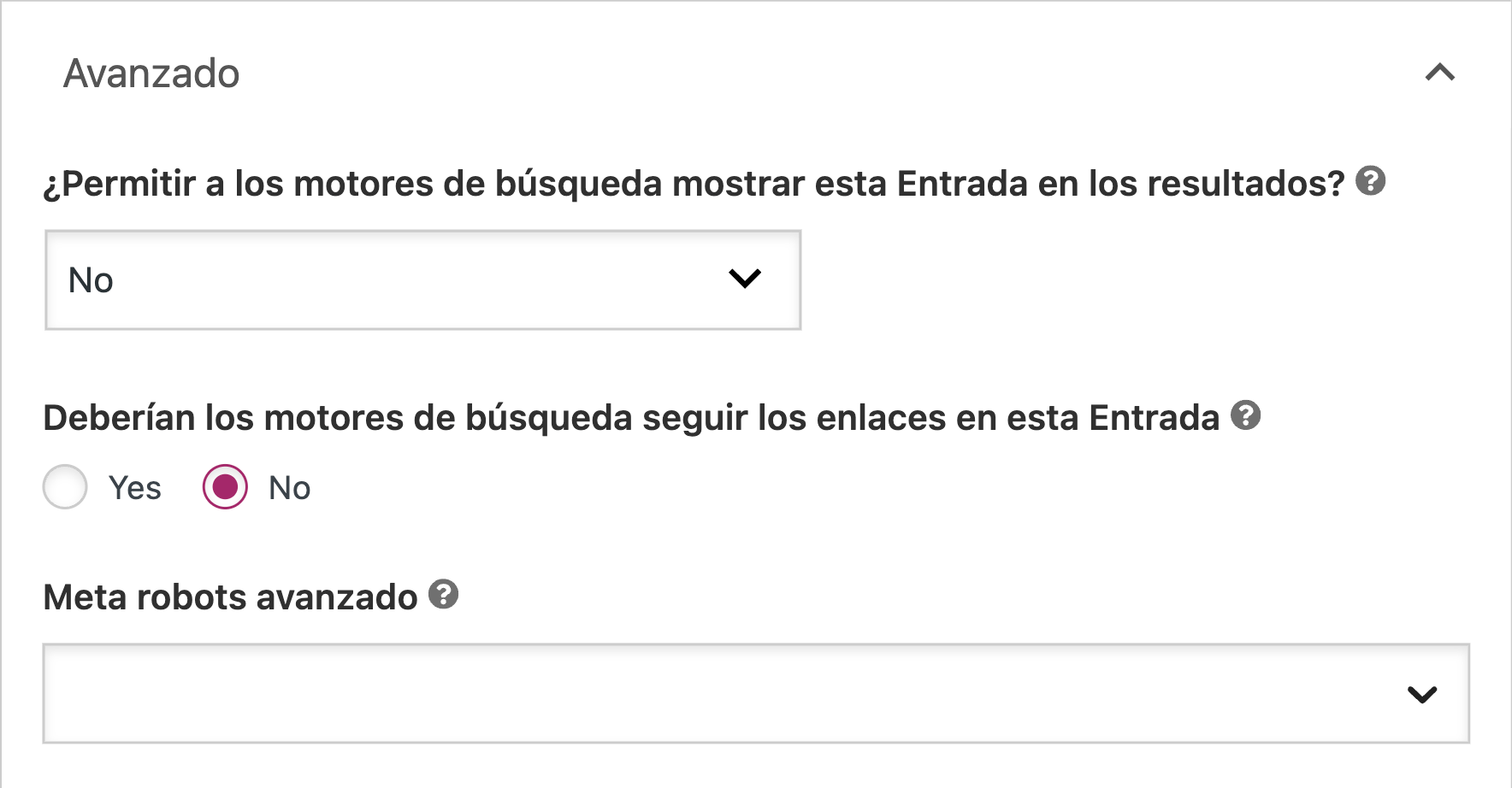
La fila “Meta robots avanzado” te ofrece la opción de aplicar directivas que no sean noindex y nofollow, como noimageindex.
También tienes la opción de aplicar estas directivas a toda la web. Dirígete a “Ajustes” en el menú de Yoast y busca las pestañas de “Tipo de contenido”. Ahí podrás configurar las metaetiquetas robots en todos los posts, páginas o solo en taxonomías o archivos específicos.
La metaetiqueta robots está bien para implementar directivas noindex en páginas HTML de vez en cuando, pero ¿qué ocurre si se quiere impedir que los motores de búsqueda indexen archivos como imágenes o PDF? Aquí es cuando entra en juego el X-Robots-Tag.
El X-Robots-Tag es una cabecera HTTP enviada desde un servidor web. A diferencia de la metaetiqueta robots, no se coloca en el HTML de la página. Este es el aspecto que tiene:
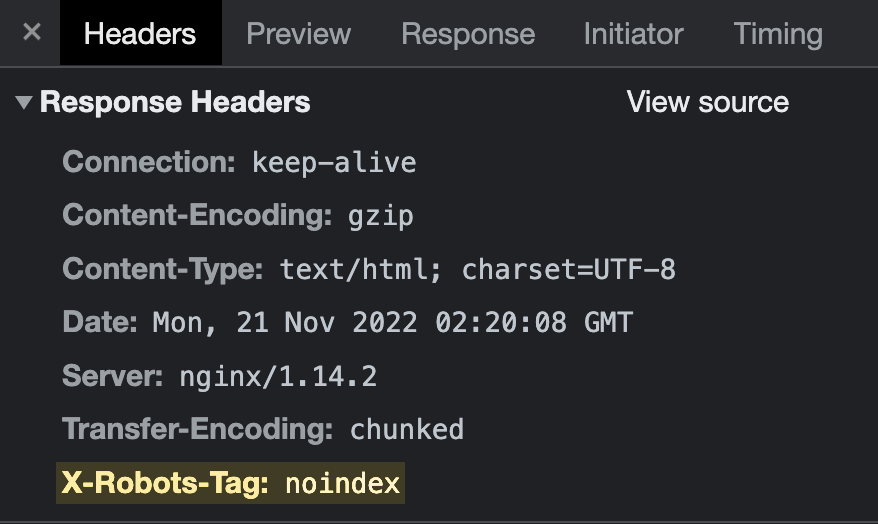
La forma más sencilla de comprobar las cabeceras HTTP es con la extensión gratuita de la barra de herramientas SEO de Ahrefs. Simplemente dirígete a la pestaña de encabezado HTTP y comprueba si aparece X-Robots-Tag:
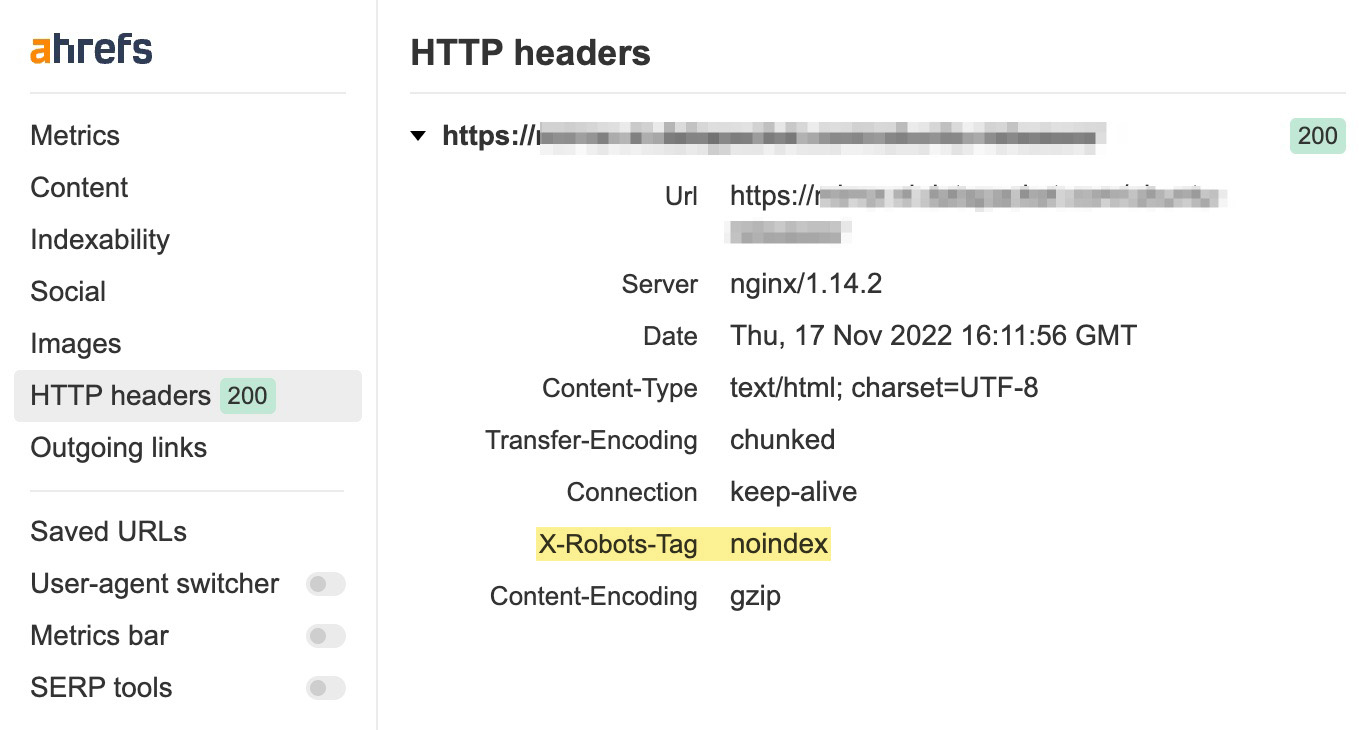
La configuración depende del tipo de servidor web que utilices y de las páginas o archivos que quieras mantener fuera del índice.
La línea de código sería algo así:
Header set X-Robots-Tag “noindex, nofollow”
Este ejemplo tiene en cuenta el tipo de servidor más extendido: Apache. La forma más práctica de añadir la cabecera HTTP es modificando el archivo de configuración principal (normalmente httpd.conf) o los archivos .htaccess. ¿Te suena? Ahí es donde también se producen las redirecciones.
Se utilizan los mismos valores y directivas para el X-Robots-Tag que para una metaetiqueta robots. Dicho esto, la aplicación de estos cambios se tiene que dejar en manos de gente que sepa lo que hace. Las copias de seguridad son clave, ya que el más mínimo error de sintaxis puede romper toda la web.
Si se usa una CDN compatible con aplicaciones sin servidor para Edge SEO, se pueden modificar tanto las metaetiquetas robots como los X-Robots-Tags en el servidor Edge sin realizar cambios en el código base.
A pesar de que añadir un fragmento HTML parezca la opción más fácil y sencilla, en algunos casos se queda corta.
Archivos que no son HTML
No se puede colocar el fragmento HTML en archivos que no sean HTML, como PDF o imágenes. X-Robots-Tag es la única manera.
El siguiente fragmento (en un servidor Apache) configuraría cabeceras HTTP noindex en todos los archivos PDF del sitio.
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex" </Files
La aplicación de directivas a escala
Si tienes que hacer un noindex de todo un (sub)dominio, subdirectorio, páginas con ciertos parámetros o cualquier otra cosa que requiera edición masiva, usa X-Robots-Tags, para que sea más fácil.
Las modificaciones de las cabeceras HTTP pueden compararse con URL y nombres de archivo mediante expresiones regulares. La edición masiva compleja en HTML utilizando la función de buscar y reemplazar normalmente requeriría más tiempo y más potencia computacional.
Tráfico procedente de otros motores de búsqueda que no sean Google
Google admite tanto las metaetiquetas robots como las X-Robots-Tags, pero no ocurre lo mismo de todos los motores de búsqueda.
Por ejemplo, Seznam, un motor de búsqueda checo, solo admite metaetiquetas robots. Si quisieras controlar cómo rastrea e indexa tus páginas este motor de búsqueda, utilizar X-Robots-Tags no funcionaría. Por el contrario, tendrías que utilizar los fragmentos HTML.
El objetivo es mostrar todas las páginas valiosas, evitar el contenido duplicado y evitar el contenido duplicado y los problemas, y mantener determinadas páginas fuera del índice. Si administras una web grande, la gestión del crawl budget es otro aspecto al que tienes que prestar atención.
Echemos un vistazo a los errores más comunes que comete la gente con respecto a las directivas robots.
Error #1: Añadir directivas noindex a páginas no permitidas en robots.txt
Nunca bloquees el rastreo del contenido que intentas desindexar en robots.txt. Si lo haces, evitarás que los motores de búsqueda vuelvan a rastrear la página y descubran la directiva noindex.
Si crees que podrías haber cometido este error, rastrea tu web de forma gratuita con Ahrefs Webmaster Tools. Busca páginas con errores “Noindex page receives organic traffic”.
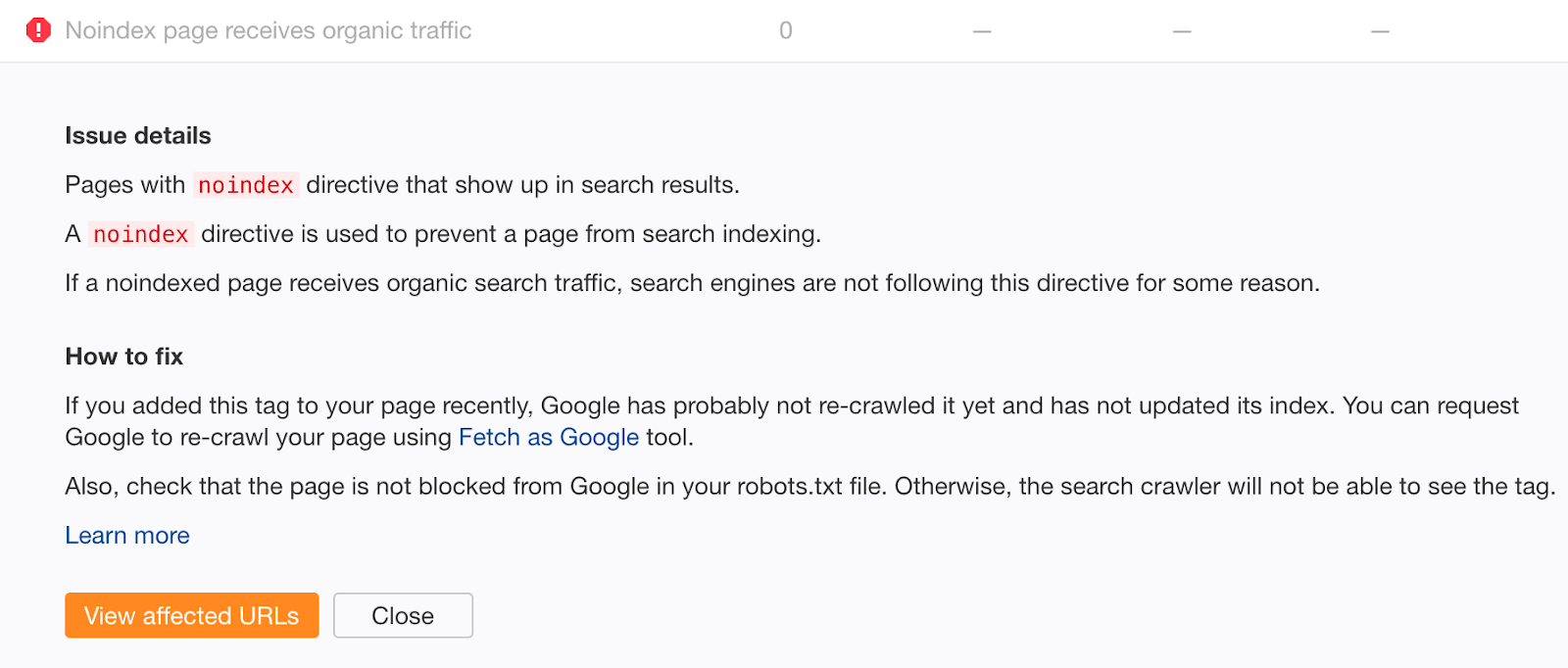
Las páginas no indexadas que reciben tráfico orgánico están claramente indexadas. Si no has añadido la etiqueta noindex recientemente, lo más probable es que se deba a un bloqueo de rastreo en tu archivo robots.txt. Comprueba si hay problemas y arréglalos según veas oportuno.
Error #2: Mala gestión de los sitemaps
Si estás intentando desindexar contenido mediante una metaetiqueta robots o un X-Robots-Tag, no lo elimines del sitemap hasta que se haya desindexado correctamente. De lo contrario, Google podría tardar más en volver a rastrear la página.
@nishanthstephen generally anything you put in a sitemap will be picked up sooner
— Gary 鯨理/경리 Illyes (so official, trust me) (@methode) October 13, 2015
Para acelerar aún más el proceso de desindexación, ajusta la fecha de la última modificación del sitemap a la fecha en la que añadiste la etiqueta noindex. Esto fomenta el rastreo y el reprocesamiento.
https://twitter.com/JohnMu/status/821056466018861056
No incluyas páginas no indexadas en tu sitemap a largo plazo. Una vez que el contenido haya sido desindexado, elimínalo del sitemap.
Si te preocupa que el contenido antiguo desindexado con éxito pueda seguir existiendo en tu sitemap, comprueba el error “Noindex page in sitemap” en Ahrefs Webmaster Tools.
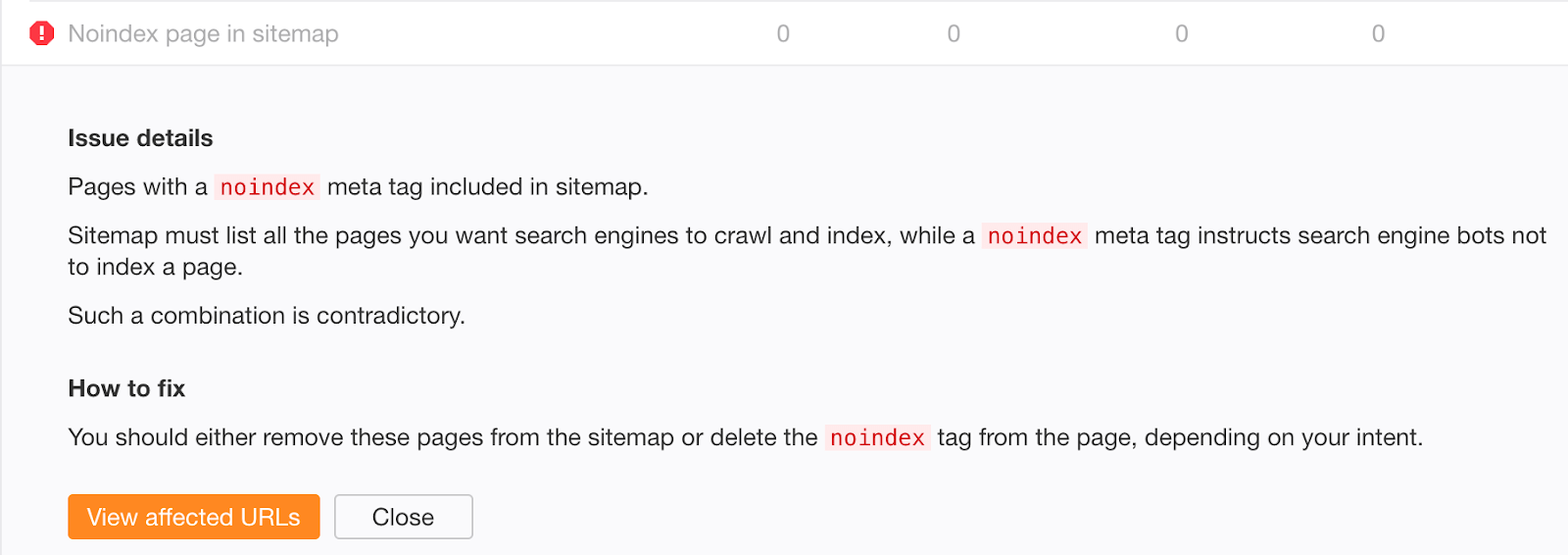
Error #3: No eliminar las directivas noindex del entorno de producción
Evitar que los robots rastreen e indexen cualquier cosa en el entorno de pruebas es una buena práctica. Sin embargo, a veces se pasa a producción, se olvida y su tráfico orgánico cae en picado.
Peor aún, la caída del tráfico orgánico puede no ser tan notable si te encuentras en medio de una migración web utilizando redireccionamientos 301. Si las URL nuevas contienen la directiva noindex o no están permitidas en robots.txt, seguirás recibiendo tráfico orgánico de las antiguas durante algún tiempo. Google puede tardar hasta unas semanas en desindexar las URL antiguas.
Siempre que se produzcan cambios de este tipo en tu web, presta atención a las advertencias de noindex en el informe de Indexability:
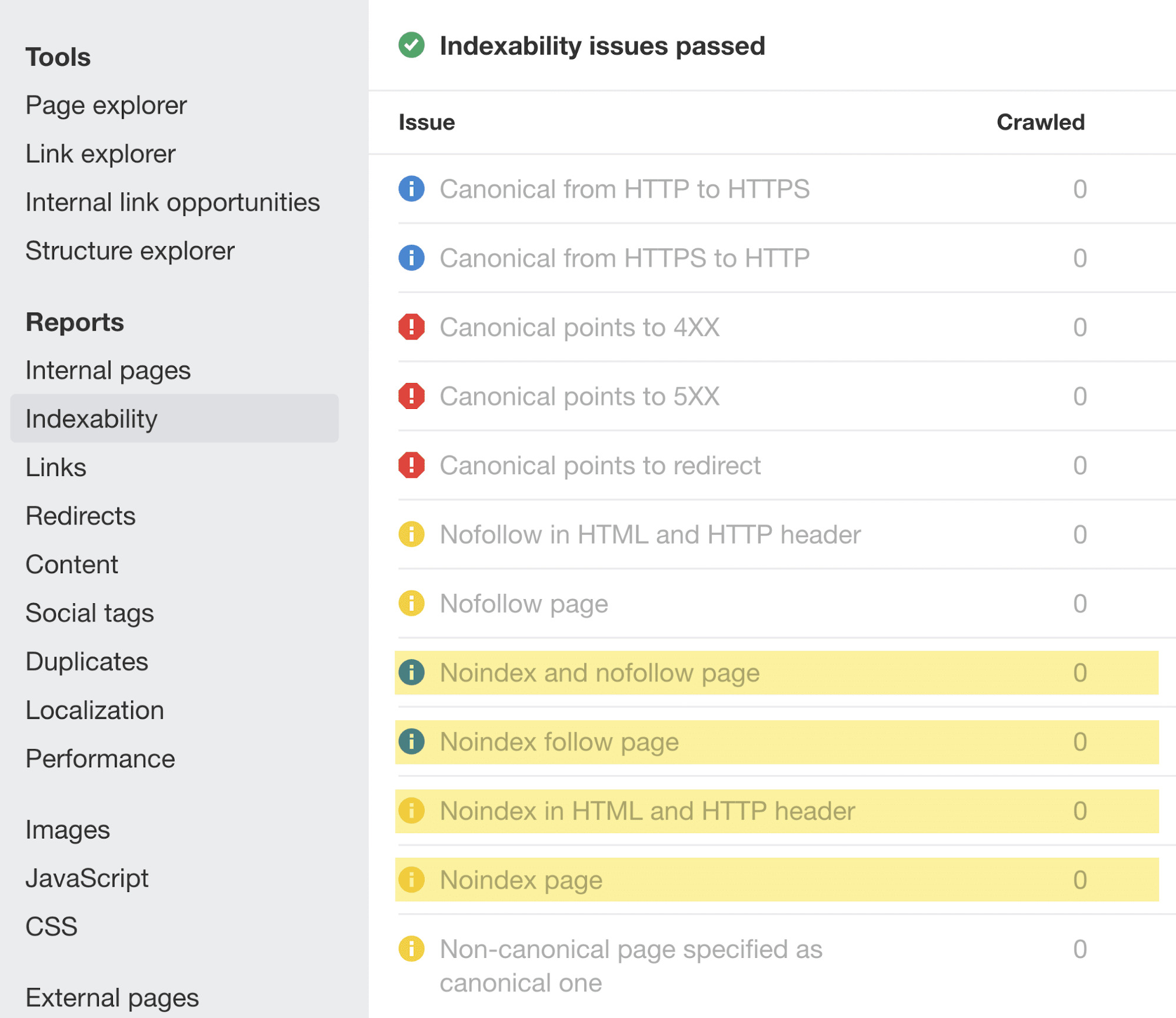
Para ayudar a prevenir problemas similares en el futuro, mejora la checklist del equipo de desarrollo con instrucciones para eliminar las reglas disallow de robots.txt y las directivas noindex antes de pasar a producción.
Error #4: Añadir secret a URL en robots.txt en vez de noindex
En muchas ocasiones, los desarrolladores intentan ocultar páginas sobre promociones próximas, descuentos o lanzamientos de productos, impidiendo el acceso a ellas en el archivo robots.txt del sitio. Esta práctica es deficiente porque la gente puede ver el archivo robots.txt. Por lo tanto, estas páginas se filtran fácilmente.
Para solucionarlo, mantén las páginas secretas fuera del archivo robots.txt y, en su lugar, desindéxalas.
Reflexiones finales
Entender y gestionar correctamente el rastreo y la indexación de tu sitio web es el pilar fundamental del SEO. No es nada verdaderamente complicado… Bueno, al menos en comparación con otros aspectos complicados dentro del campo del SEO técnico.
Espero que ahora tengas todo listo para ponerte en marcha con las prácticas recomendadas y obtener soluciones a largo plazo.
¿Tienes alguna pregunta? Contáctanos por Twitter.


