
Bei der Erstellung eines Web-Indexes müssen Unternehmen eine Reihe von Entscheidungen bezüglich des Crawling, Parsing und der Indexierung von Daten treffen. Während es eine Menge Überschneidungen zwischen den Indizes gibt, so gibt es auch einige Unterschiede, die von den Entscheidungen der einzelnen Unternehmen abhängen.
Aus Transparenzgründen möchten wir euch mehr über den Link-Index von Ahrefs verraten.
- Was ist ein Link?
- Welche Links werden indexiert?
- Welche Domains werden indexiert?
- Warum wir nicht alle Links erfassen können
Links führen die User per Mausklick von einer Webseite zur anderen. Es gibt viele Möglichkeiten, Links zu erstellen, wobei die gängigste Methode das klassische HTML <a> Element mit einem href-Attribut ist.
<a href="url">link text</a>
Es ist jedoch auch möglich, Links mit anderen Elementen zu erstellen, z.B.:
- Onclick
- Button
- Ng-click
- Option/value
- Und viele mehr …
In einer idealen Welt würde alles, was als Link fungiert, gespeichert werden. Leider leben wir nicht in einer idealen Welt. Weder Ahrefs noch Google speichert alle Arten von Links. Denn es wäre schlichtweg ineffizient, jede Seite zu laden und jeden einzelnen Link anzuklicken. Genau das müsste man aber tun, wenn man jeden funktionierenden Link finden möchte.
Typischerweise rufen stattdessen Crawler die Webseiten ab, rendern diese gegebenenfalls und extrahieren sowie speichern dann verschiedene Arten von Links. Da jeder Crawler unterschiedlich funktioniert, zeigen wir dir, wie wir hier bei Ahrefs vorgehen.
Links, die wir speichern
In unserem Index speichern wir die folgenden Arten von Links:
Externe Links
Links von einer Website zu einer anderen, die mit dem typischen HTML <a>-Element mit einem href-Attribut erstellt werden.
Interne Links
Hierbei handelt es sich um Links von einer Seite auf einer Website zu einer anderen Seite auf derselben Website. In unserem Index gibt es 22,21 Billionen interne Backlinks. Das ist weitaus mehr als die Anzahl unserer externen Live-Links. Wir sind das einzige SEO-Tool, bei dem du auf diese Daten zugreifen kannst, ohne eine individuelle Website zu crawlen. Wir verwenden die internen Linkdaten in der URL Rating (UR)-Berechnung, ähnlich wie Google diese in seiner PageRank-Berechnung verwenden würde.
Wenn du sehen möchtest, wann wir eine URL zum ersten und letzten Mal gecrawlt haben, kannst du dir den Bericht “Best by links” im Site Explorer ansehen. Es gibt Registerkarten sowohl für externe als auch für interne Links.
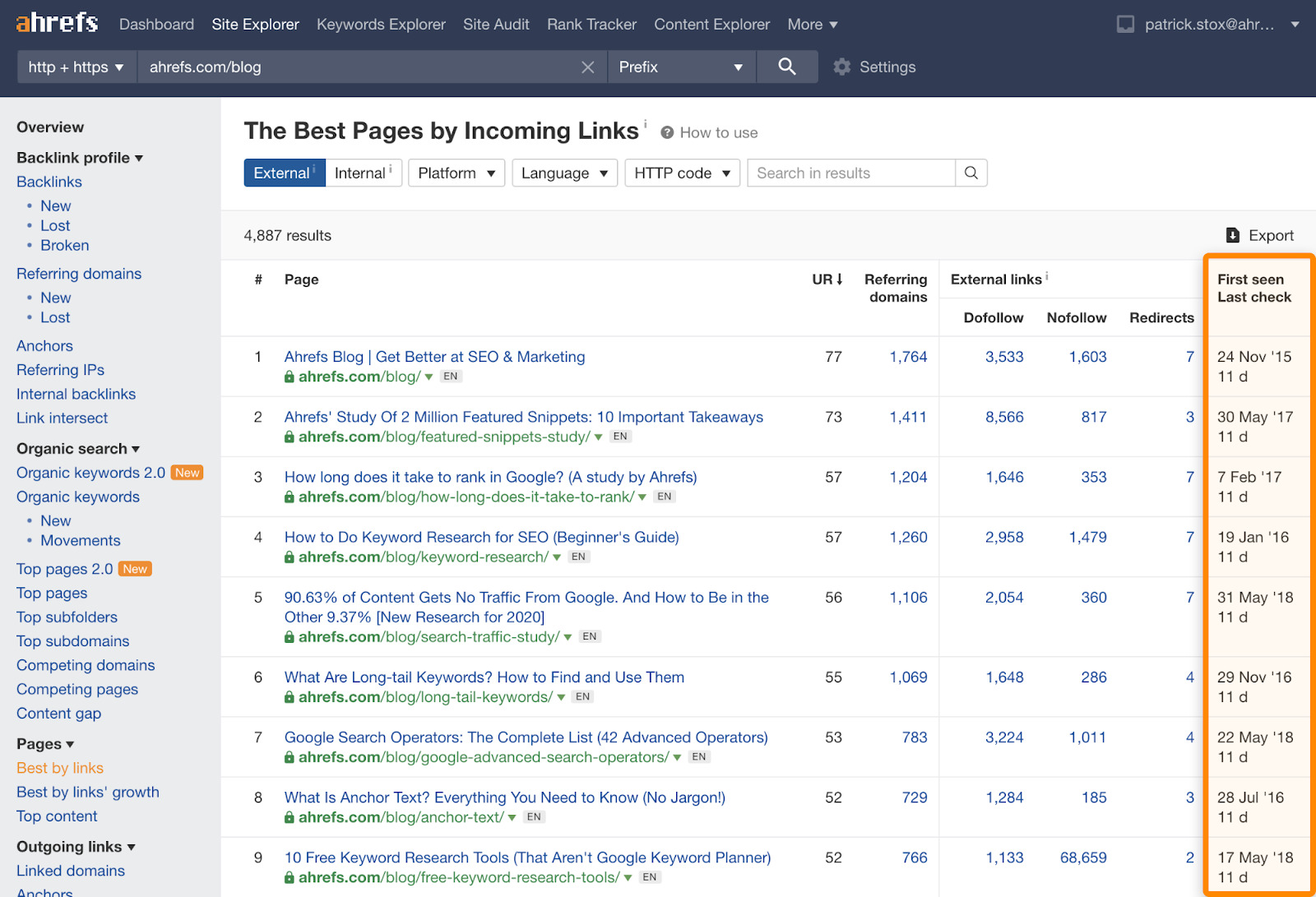
Links, die wir gegebenenfalls speichern
Nachfolgend alle Links, die wir unter bestimmten Umständen speichern:
Links, die mit JavaScript eingefügt wurden
Da Google alle Seiten rendert, kann die Suchmaschine Links zählen, die mit JavaScript eingefügt werden, aber nicht im HTML-Code stehen. Das Rendering in großem Stil benötigt viel mehr Ressourcen als das bloße Herunterladen des HTML-Codes von Seiten. Bei Ahrefs rendern wir etwa 80 Millionen Seiten pro Tag. Deshalb haben wir auch einige dieser Links, die mit JavaScript eingefügt wurden, aber nicht alle davon. Wir sind derzeit das einzige SEO-Tool, das während unseres regelmäßigen Web-Crawlings rendert, daher verfügen wir über einige Link-Daten, die andere Tools nicht haben.
Wir zählen jedoch nur Links, die mit JavaScript eingefügt wurden, wenn diese das Format eines HTML <a>-Elements mit einem href-Attribut aufweisen. Diese Links werden im Backlinks-Bericht als “JS” gekennzeichnet, etwa so:

Links von Seiten mit URL-Parametern
Parameter sind Zusätze einer URL wie ?tag=irgendwas. Möglicherweise siehst du einige dieser URLs in unserem Index, aber in der Regel handelt es sich um Parameter, die einen anderen Inhalt anzeigen. In vielen Fällen können Seiten mit Parametern denselben Inhalt zeigen. Wir haben viele Systeme eingerichtet, um URLs zu kanonischenVersionen zu konsolidieren und zusätzlichen Schutz für unendliche Crawl-Pfade zu bieten. Andere Tools treffen möglicherweise nicht die gleichen Entscheidungen oder haben nicht die gleichen Schutzmechanismen eingerichtet. Infolgedessen kann es vorkommen, dass sie denselben Link mehrmals zählen.
Links, die wir versuchen nicht zu speichern
Die folgenden Links versuchen wir nach Möglichkeit nicht zu speichern:
Links von Seiten mit URL-Parametern
Wie bereits erwähnt, gibt es gute und schlechte Arten von Parametern. Wir sind bemüht, diejenigen nicht zu speichern, die doppelt vorhanden sind.
Links von Seiten in unendlichen Crawl-Pfaden
Diese Pfade erzeugen eine unendliche Anzahl von möglichen URLs. Parameter sind eine Form, die sie bilden können, aber auch Filter, Dynamic Content und unterbrochene relative Pfade für Links. Wie bereits erwähnt, haben wir viele Vorkehrungen für Links auf diesen Seitentypen getroffen, um die Wahrscheinlichkeit zu verringern, dass sie in unseren Berichten angezeigt werden. Die Einhaltung der Kanonisierung und die Art und Weise, wie wir das Crawling von Seiten priorisieren, sind nur zwei dieser Vorkehrungen. Jeder Index muss sich mit diesen unendlichen Pfaden auseinandersetzen, aber diese Seiten haben die Möglichkeit, die Link Counts in die Höhe zu treiben.
Links, die wir nicht speichern
Die folgenden Links werden von uns niemals gespeichert:
Links in PDFs oder anderen Dokumenten
Google wandelt viele Dateiformate in HTML um und indexiert sie wie jede andere Seite. Das bedeutet, dass sie die Links in diesen Dokumenten zählen. Ich glaube nicht, dass irgendein SEO-Tool derzeit diese Links indexiert, aber das sollten wir wahrscheinlich tun. Ich denke, dass wir das eines Tages auch tun werden, aber ich bin ebenso besorgt darum, dass sich der Aufwand und die erforderlichen Ressourcen dafür nicht lohnen werden. Laut John Mueller, Google Webmaster Trends Analyst, haben die Links in PDFs keine praktische Auswirkung auf die Websuche.
Links in Iframes
Iframes erlauben es, eine andere Seite innerhalb einer Seite anzuzeigen. Aus diesem Grund zählen wir die Links in Iframes nicht. Allerdings werden sie den Nutzern angezeigt, so dass andere Tools sie möglicherweise zählen, obwohl der Inhalt technisch gesehen zu einer anderen Seite gehört. Es kann sein, dass Google diese Links zählt — oder auch nicht.
Links von nicht indexierten Seiten
Wir lassen diese Links aus. Es bestehen unterschiedliche Aussagen seitens Google darüber, ob sie diese berücksichtigen oder nicht. Andere Tools können in dieser Hinsicht andere Entscheidungen treffen.
something with noindex will never reach the serving index, but we will have the fetched copy for things like link graph calculation.— Gary 鯨理/경리 Illyes (@methode) December 17, 2020
Identische Links von mehreren IPs
Eine lustige Tatsache ist, dass Websites dieselbe Seite von mehreren IP-Adressen aus bereitstellen können. Wenn dies der Fall ist, kann es vorkommen, dass ein Link-Index denselben Link mehrfach zählt. Wir tun das nicht. Wir verknüpfen die Links mit den Seiten, auf denen sie sich befinden.
Mehrere Links, die von einer einzigen Seite aus auf dieselbe Seite verweisen
Derzeit erfassen wir nur eine Version eines Links auf einer Seite. Wenn du einen Link zu einer Seite im Website-Menü und dann noch einmal im Body der Website setzt, zählen wir nur einen dieser Links. Möglicherweise ändern wir das in Zukunft, um Usern mehr Daten zur Verfügung zu stellen, aber das ist der aktuelle Stand. Google zählt alle Versionen von Links für die Ermittlung des PageRank, berücksichtigt aber möglicherweise nur von einer Version den Anchor Text (Ankertext).
Andere linkbezogene Aspekte, die den Index beeinflussen
Zu verstehen, wie wir Links zählen, ist eine Sache. Darüber hinaus gibt es aber auch viele andere Faktoren, die beeinflussen, was gezählt wird und was nicht.
Anzahl der Links pro Seite
Ich glaube nicht, dass wir ein Limit für die Anzahl der Links haben, die pro Seite gezählt werden. Dennoch haben wir ein Limit für die Seitengröße, das sich möglicherweise auf die Anzahl der Links auswirkt, die wir sehen und erfassen können. Google empfiehlt maximal ein paar tausend Links pro Seite.
Weitergeleitet oder kanonisiert
Bei Ahrefs vertrauen wir allen Weiterleitungen und kanonischen Tags und konsolidieren die Links dort, wo die Websites uns das signalisieren. Für Google ist dies komplizierter, da sie viele Kanonisierungssignale haben, die bestimmen, welche Seite die führende in einem kanonischen Cluster ist. Wir setzen hier auf Pragmatismus, denn es ist unmöglich zu wissen, wie Google die jeweilige Situation sieht, und es würde unsere User verwirren, wenn wir Canonicals (kanonische Tags) und Redirects (Weiterleitungen) jedes Mal anders behandeln würden.
Diese Links werden in unseren Berichten mit “301”, “302” oder “Canonical” (“Kanonisch”) gekennzeichnet — wie z.B.:
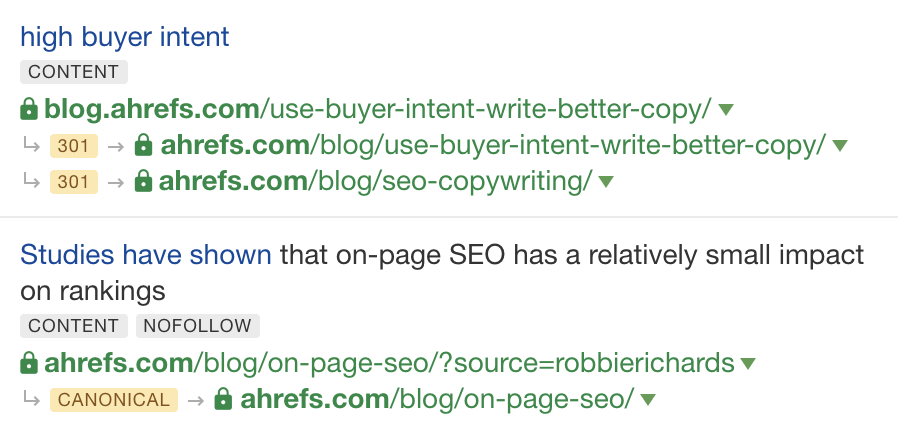
301- und kanonische Links im Site Explorer von Ahrefs.
In Ahrefs gibt es den Bericht “Referring Domains” (“Verweisende Domains”), der alle Domains anzeigt, die auf eine Website oder Webseite verlinken.
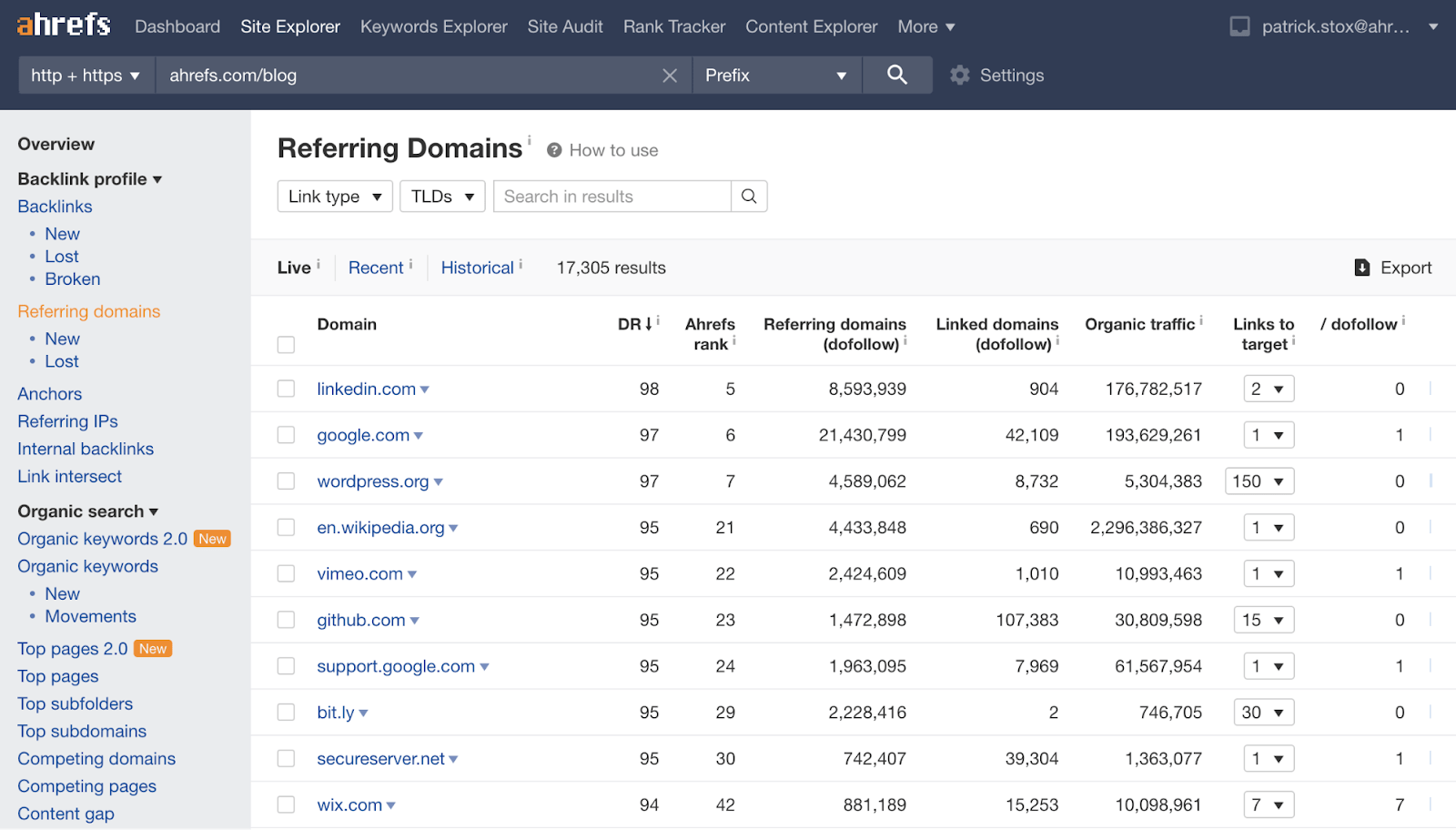
Bericht “Referring Domains” (“Verweisende Domains”) im Site Explorer von Ahrefs.
Aber wie genau zählen wir die Domains?
Man sollte meinen, diese Frage sei einfach zu beantworten — es handelt sich ja schließlich nur um “domain.com”, richtig? In der Tat ist die ganze Angelegenheit etwas komplizierter, da es viele Möglichkeiten gibt, Domains zu zählen. Eine Möglichkeit besteht darin, jede registrierte Domain als eine Domain zu behandeln — das scheint die Art und Weise zu sein, wie es Google in der Google Search Console handhabt. Eine andere Möglichkeit ist, jede Subdomain als eine andere Domain zu behandeln. Du könntest auch nur einige Abschnitte einer Website aggregieren und andere nicht (so wie es Google macht), jeden Abschnitt auf einem anderen Tech-Stack durchgehen usw. Es gibt eine Vielzahl an Möglichkeiten.
Bei Ahrefs liegen uns rund 175 Millionen Domains nach entsprechender Überprüfung vor. Dieser Überprüfungsprozess beinhaltet das Entfernen von Spam-Domains und das Herausfiltern einiger Subdomains, bei denen wir festgestellt haben, dass verschiedene User die verschiedenen Bereiche kontrollieren. Wir verwenden dafür eine eigene Liste, aber es gibt auch eine öffentliche Liste unter https://publicsuffix.org/list/.
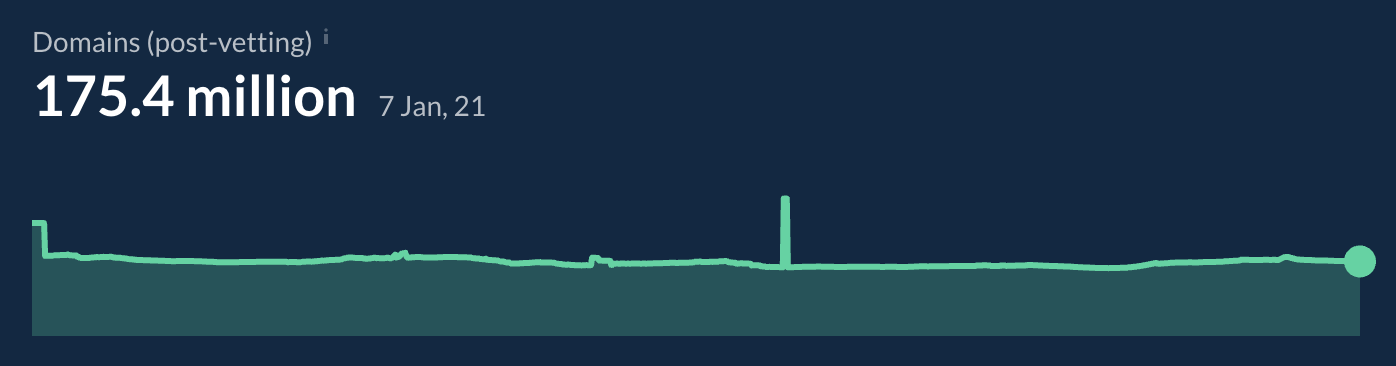
Es ist wichtig zu beachten, dass unterschiedliche Domain-Definitionen zu großen Variationen der verweisenden Domains führen können. Nachfolgend einige Beispiele für Elemente, die von anderen Anbietern — jedoch nicht von Ahrefs — möglicherweise als separate Domains gezählt werden können:
- Mobile-Subdomains (m.domain.com, mobile.domain.com, etc.)
- Länder-/Sprachen-Subdomains(en.domain.com, fr.domain.com, de.domain.com, jp.domain.com, etc). In unserem Index kann es Ausnahmen geben, wie z.B. wikipedia.org, aber das ist nicht die gängige Praxis.
- Beliebige Subdomains (support.domain.com, images.domain.com, etc.)
Eine weitere Entscheidung, die Anbieter von Backlink-Tools treffen müssen, ist, ob sie einige Unterordner bzw. Unterverzeichnisse als verschiedene Domains zählen sollen. Ich denke zum Beispiel, dass die meisten Link-Indizes verschiedene Blogs auf bekannten Plattformen (z.B. user1.blogspot.com, user2.blogspot.com) als verschiedene Domains zählen würden, da sie von verschiedenen Benutzern gesteuert werden. Aber warum sollte man das nicht auch für Seiten wie medium.com/user1 oder github.com/user1 tun? Bei Ahrefs machen wir das derzeit nicht, aber es besteht die Möglichkeit, dass wir das in Zukunft tun, da wir davon ausgehen, dass verschiedene Personen die jeweiligen Unterverzeichnis auf einer Site steuern werden.
Der Punkt hier ist, dass es viele Wege gibt, Domains zu zählen. Das wird deutlich, wenn man sich die unterschiedlichen Zahlen von Unternehmen ansieht, die Websites im Internet zählen. Laut Verisign gab es im dritten Quartal 2020 370,7 Millionen registrierte Domains über alle TLDs hinweg. Laut Netcraft gab es im November 2020 1.229.948.224 Websites auf 263.787.870 einzelnen Domains mit 193,8 Millionen aktiven Seiten. Laut Internet Live Stats gibt es etwa 1,8 Milliarden Websites mit weniger als 200 Millionen aktiven Seiten. Jedes Unternehmen wendet offensichtlich eine andere Methodik für das Zählen von Domains an.
Um es noch einmal zusammenzufassen: Was wir bei Ahrefs tun, ist, alle uns bekannten Websites zu erfassen, eine Vielzahl von Spam- und inaktive Domains zu entfernen und dann einige für Subdomains auf Websites wie blogspot.com hinzuzufügen. So kommen wir zu unserer Gesamtanzahl von rund 175 Millionen Domains. Andere Indizes handhaben das vielleicht anders und kommen zu einer anderen Anzahl.
Da wir Backlinks finden, indem wir das Web crawlen, können wir dies nur auf Websites tun, die wir crawlen dürfen. Wenn Website-Inhaber den AhrefsBot in ihrer robots.txt-Datei blockieren, können wir ihre Website nicht crawlen. Wenn du beispielsweise einen Backlink von website.com erhältst und website.com den AhrefsBot blockiert, können wir die Seite nicht crawlen und dein Backlink wird in Ahrefs nicht angezeigt. IP-Blocking, User-Agent-Blocking von Servern (anders als bei robots.txt), Server-Timeouts, Bot-Schutz (bot protection) und viele andere Dinge können die Möglichkeit, einige Websites zu crawlen, ebenfalls beeinflussen. Es ist in der Tat nicht einfach, das Web im großen Stil zu crawlen.
Wir verfügen über mehrere Link-Indizes
Jedes Tool muss Entscheidungen über die Speicherung und den Abruf von Daten treffen. Bei Ahrefs teilen wir unsere Daten auf mehrere Indizes auf.
- Live (aktuell) — Links, wo wir sehen, dass sie noch im Web aktiv sind. Dies repräsentiert am besten den aktuellen Zustand des Webs und ist das, was viele unserer User am nützlichsten finden.
- Recent (kürzlich) — Links, die wir in den letzten 3–4 Monaten im Web gesehen haben.
- Historical (gesamt) — alle Links, die wir jemals gesehen haben. Hierbei handelt es sich um die umfassendste Liste, jedoch beinhaltet diese auch viele Links, die nicht mehr existieren.
In unseren Backlink- und Referring-Domain-Berichten kannst du zwischen den Indizes hin- und herwechseln.
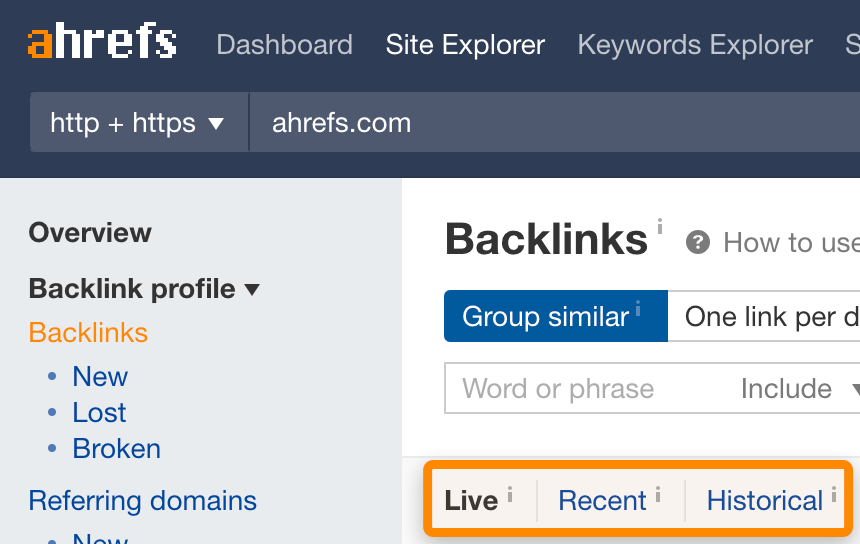
Andere Indizes entscheiden sich möglicherweise dafür, alle Daten anzuzeigen, die sie jemals gesehen haben. Das bedeutet zwar, dass sie eine Vielzahl an Links anzeigen, aber auch, dass viele dieser Links womöglich nicht mehr existieren.
Fazit
Mit diesem Blogartikel möchten wir euch Usern mehr Informationen über unseren Index und seine Funktionsweise geben, damit ihr bessere und fundierte Entscheidungen treffen könnt. Außerdem möchten wir gerne eure Meinung hören, wenn ihr glaubt, dass wir etwas ändern sollten und warum.
Wenn du derzeit Link-Indizes vergleichst und Fragen zu unseren Daten hast oder Unklarheiten bestehen sollten, kannst du dich natürlich gerne mit uns in Verbindung setzen.


