每个外链查询工具都会存储各种不同的链接。
如果你需要对整个互联网建立索引库,势必会在爬行、解析、索引上做出许多选择。有可能索引的内容会有重复的地方。又因为每个公司决策的方式不同,所以也会存在一些差异。 为了保证数据的透明性,我们希望让用户知道Ahrefs的链接是如何索引的。 链接会在单击时,将用户从一个网页引导到另一个网页。创建它们的方法有很多,最常见的方法是通过传统的 HTML 方式。 <a> 其中还包含 href 属性元素。 <a href="url">链接文字</a> 同时,你还可以通过其他的方式建立链接,比如:- Onclick
- Button
- Ng-click
- Option/value
- 以及更多…
我们储存的链接
在我们的索引库中会储存很多类型的链接。外部链接
从一个网站到另一个网站的链接。这些链接是使用带有 href 属性的传统 HTML 的 <a> 标签进行创建的。内部链接
从网站上的一页链接到同一网站上的另一页的链接。 我们的索引库中储存了 22.21 万亿个内部链接记录。这比我们的实时的外部链接数要广泛得多。我们是唯一可以不用自己抓取网站就可以访问此数据的SEO工具。我们在网址评分 (URL Rating) 计算中使用这些数据,原理类似于谷歌计算 PageRank 的方法。 如果你要查看我们第一次和最后一次抓取URL的时间,可以在Site Explorer(网站分析)中查看Best by links(按外链数量排序)报告。外部链接和内部链接的数据都在里面。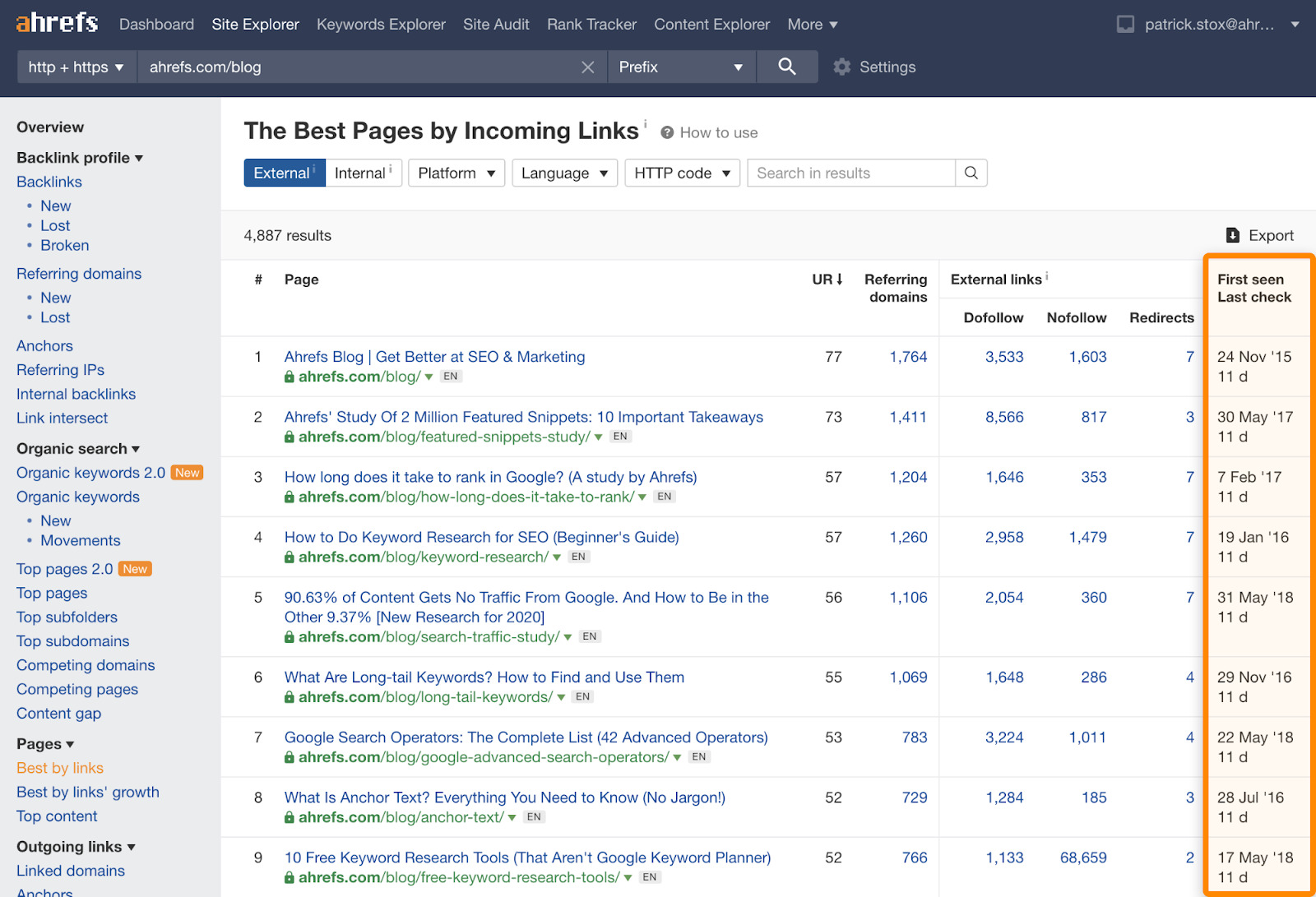
我们可能会储存的链接
下面是我们在部分情况下存储的链接形式。用 JavaScript 插入的链接
因为谷歌会渲染所有页面,所以它们可能会将 JavaScript 插入但不在 HTML 代码中的链接纳入计算范围。由于大规模的渲染比加载页面 HTML 需要更多的资源。在 Ahrefs 我们每天渲染约8000万个页面。这就是为什么我们只会统计一部分用 JavaScript 插入的一些链接,而不是所有链接。目前我们唯一个会在抓取时渲染页面的 SEO 工具,因此我们拥有一些其他工具所没有的链接数据。 但是,仅当使用 JavaScript 插入的链接为带 有href 属性的HTML <a> 元素格式时,我们才对它们进行计数。你会在外链报告中看到这些链接标记为“ JS”,如下所示:
来自具有URL参数的页面的链接
参数类似URL的补充,例如这样:?tag=something。你可能会在我们的索引数据中看到其中一些URL,但是它们通常是显示不同内容的带参数URL。在许多情况下,带有参数的页面可能会显示相同的内容。 我们有许多系统可以将URL合并为规范版本,不会让抓取无限制的进行下去。但那时其他的工具可能不会有类似的保护措施。结果就是它们可能多次计算了相同的链接。我们尝试不存储的链接
以下是我们尽力避免存储的链接类型。来自具有URL参数的页面的链接
如上所述,参数有好有坏。我们尽量不存储重复的内容。来自无限抓取路径中页面的链接
这些路径创建了无限数量的的URL。参数是它们可以形成的一种方式,但过滤器、动态内容、断开的链接、相对路径等也会造成这种状况。如前所述,我们为这些类型的页面上的链接提供了很多保护,尽量使它们不出现在我们的报告中。遵循规范地址、以及对抓取页面进行优先级排序,只是其中的两项保护。由于每个索引数据都必须审查是否是来自无限抓取路径的,所以在处理过程中难免会有链接数量增加的情况。我们不存储的链接
下面是是我们从不存储的链接类型。PDF或其他文档中的链接
谷歌将许多文档格式转换为HTML,并像对其他页面上一样对它们进行索引。这意味着谷歌会计算这些文档中的链接。我们不认为目前有任何SEO工具会为这些链接建立索引,但我们以后可能会这么做。但同时,我也担心为此付出的努力和资源是不值得的。因为根据谷歌网站趋势分析师 John Mueller 的说法,PDF中的链接在网络搜索中没有任何实际作用。Iframe 中的链接
iframe允许另一个页面内容显示在当前页面内部。因此,Ahrefs 不计算 iframe 中的任何链接。但是,它们依然会向用户显示,因此即使内容从技术上来说属于其他页面,其他工具也可能会将其计算在内。谷歌可能会、也可能不会计算这些链接。来自未建立索引页面的链接
我们会删除这些链接数据。谷歌方面不的同人对待这个也有不同的意见。同时不同的工具可能也会有不同的结论。译: 没有索引的页面永远不会记录到索引库中。但我们会将这个记录为副本并用于诸如链接图计算之类的。something with noindex will never reach the serving index, but we will have the fetched copy for things like link graph calculation.
— Gary 鯨理/경리 Illyes (@methode) December 17, 2020
来自多个 IP 的相同链接
关于网站的一个有趣事实是,站点可能会通过多个IP地址为同一页面提供服务。在这种情况下,部分工具的链接索引可能会多次计算同一链接。但我们不这样做。我们会将链接与它们所在的页面本生相关联。从单个页面到另一页面的多个链接
目前,我们仅在页面上记录链接的一种版本。如果你在导航菜单中链接到了某个页面,然后又在正文中做了链接,则我们将仅计入其中之一。将来我们可能会更改此设置,以便为用户提供更多数据。谷歌会计算所有版本的链接来传递 PageRank,但多半只使用一个版本的锚文本。其他影响索引链接的相关要素
理解我们如何计算链接数是一回事,但是许多其他的因素也会影响到什么样内容没有被计算在内。页面中存在的链接数量
我认为我们对每页链接数并没有限制,但是我们确实有页面大小限制,这最终可能会影响我们看到的链接数量。 同时谷歌也建议每页链接不要超过几千个。重定向链接或规范化链接
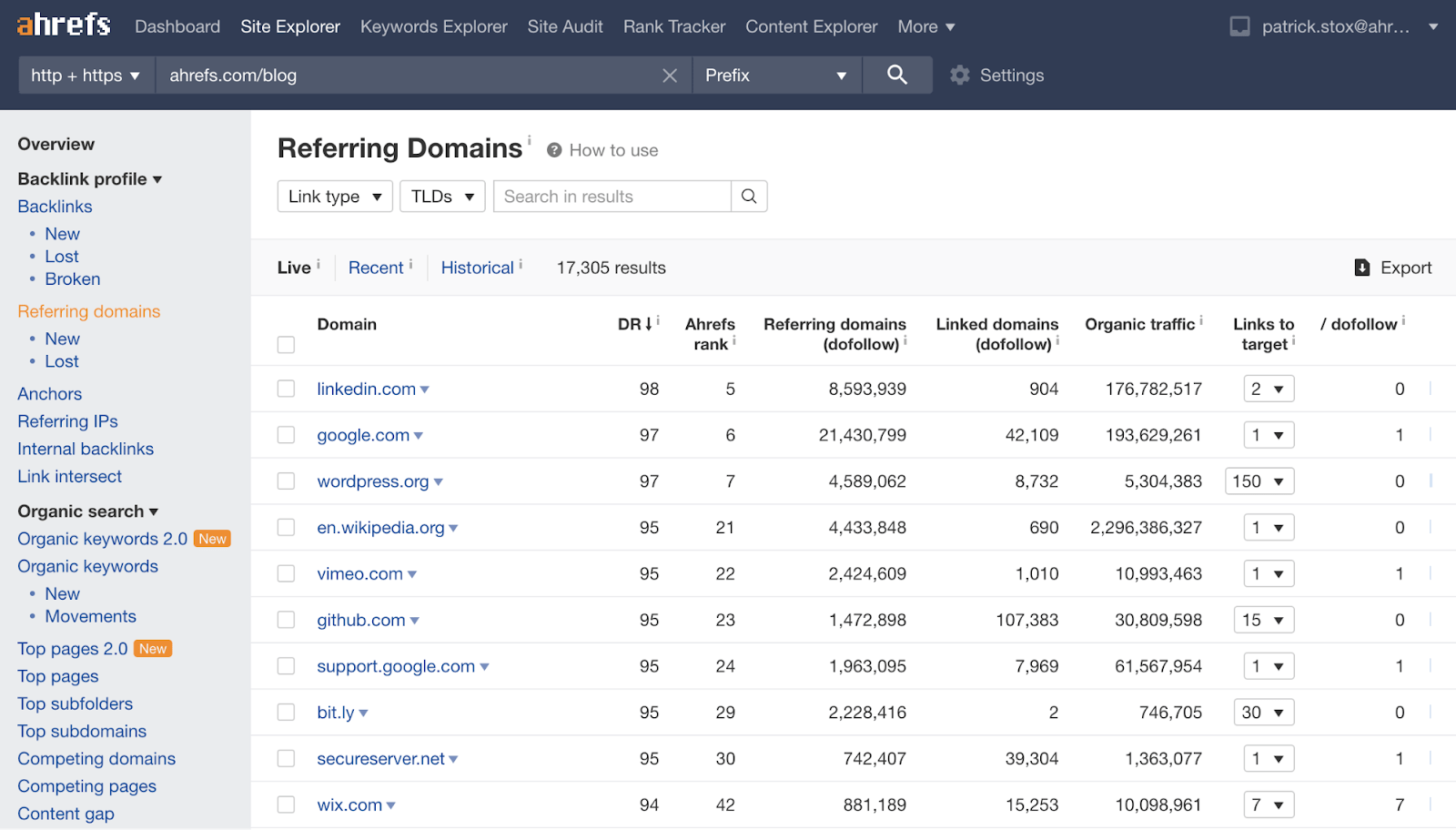
在 Ahrefs,我们信任所有重定向的、有规范标签的链接,并会着重处理这些链接。对于谷歌而言,这更为复杂,因为网站中有许多规范标签,通过它们可以确定哪个页面是作为主导页面存在的。我们的处理则相对比较简单,因为不可能知道谷歌是如何看待每种情况,而且如果我们处理规范化链接、重定向链接的方式每次都不同的话,会让我们的用户很困惑。 在我们的报告中,这些链接会被贴上 “301”、“302”、或是 “Canonical” 的标注: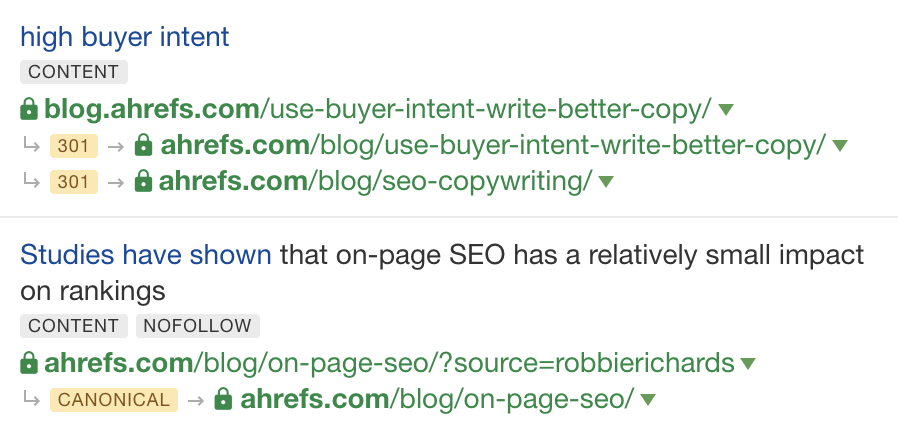
Ahrefs Site Explorer(网站分析)中的 301 以及 canonical 链接
Ahrefs Site Explorer(网站分析)中的 Referring domains(反链域名)报告
- 移动端子域名 (m.domain.com, mobile.domain.com 等)
- 国家/语言类子域名(en.domain.com, fr.domain.com, de.domain.com, jp.domain.com 等). 我们的索引中可能有例外,例如 Wikipedia.org,但通常不会这样。
- 随机子域名 (support.domain.com, images.domain.com 等)
我们有多个链接索引库
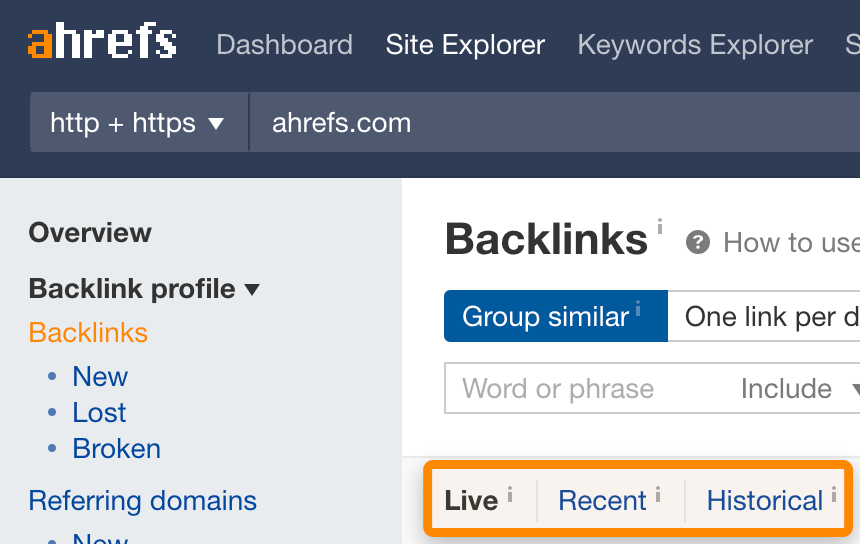
每个工具都必须做出有关数据存储和检索的决策。在Ahrefs,我们会把数据分在多个索引库中。- Live(现存的) — 当前仍然存在于页面上的链接。这最好地代表了当前的数据状态,这也是目前用户认为最有用的数据。
- Recent(近期的) — 过去3–4个月内,我们在页面上抓取到的链接。
- Historical(历史的) — 我们见过的所有链接。这将是最全面的列表,但其中包含许多当前已经不再存在的链接。