
Dafür sind Meta-Tags und der X‑Robots-Tag HTTP-Header zuständig.
Lass uns eine Sache von vornherein klarstellen. Du kannst die Indexierung nicht mit der robots.txt kontrollieren. Das ist eine häufige Fehleinschätzung.
Die noindex-Regel in der robots.txt wurde nie offiziell von Google unterstützt. Und im Juli 2019 wurde sie offiziell abgeschafft.
In diesem Guide wirst du lernen:
- Was ein Robots-Meta-Tag ist
- Warum der Robots-Meta-Tag wichtig für SEO ist
- Die Werte und Attribute eines Meta-Robots-Tags
- Wie man den Robots-Meta-Tag einsetzt
- Was ein X‑Robots-Tag ist
- Wie man den X‑Robots-Tag einsetzt
- Wann man den Meta-Robots-Tag vs. X‑Robots-Tag einsetzt
- Wie man Crawlbarkeits- und (De)indexierungsfehler vermeidet
Was ist ein Robots-Meta-Tag?
Ein Robots-Meta-Tag ist ein HTML-Snippet, das Suchmaschinen mitteilt, wie sie bestimmte Seiten crawlen oder indexieren sollen. Es wird im <head>-Bereich einer Webseite platziert und sieht folgendermaßen aus:
<meta name="robots" content="noindex" />
Warum ist der Robots-Meta-Tag wichtig für SEO?
Der Meta-Robots-Tag wird häufig benutzt, um Seiten davon abzuhalten, in den Suchergebnissen zu erscheinen, obwohl es noch weitere Anwendungsfälle gibt (mehr dazu später).
Es gibt viele verschiedene Arten von Inhalten, die du vor der Suchmaschinenindexierung verbergen können möchtest:
- Inhaltsarme Seiten mit geringem oder keinem Wert für den Nutzer;
- Seiten auf einer Testumgebung;
- Admin- und Dankesseiten;
- Interne Suchergebnisse;
- PPC-Landing-Pages;
- Seiten über kommende Werbeveranstaltungen, Conteste oder Produkteinführungen;
- Doppelte Inhalte (Nutze den Canonical Tag um die beste Version zur Indexierung vorzugeben);
Ganz allgemein, je größer deine Seite ist, desto mehr wirst du damit umgehen müssen, die Crawlbarkeit und Indexierung deiner Seite zu verwalten. Du möchtest außerdem, dass Google und andere Suchmaschinen deine Seiten so effizient wie möglich crawlen und indexieren können. Das richtige Kombinieren von Direktiven auf Seitenebene mit robots.txt und Sitemaps ist sehr wichtig für SEO.
Was sind die Werte und Attribute eines Robots-Meta-Tags?
Robots-Meta-Tags bestehen aus zwei Attributen: name und content.
Du musst Werte für diese beiden Attribute definieren. Lass uns entdecken, welche das sind.
Das name Attribut und User-Agent-Werte
Das name-Attribut spezifiziert welche Crawler diesen Instruktionen folgen sollen. Dieser Wert ist auch als (UA) User Agent bekannt, da Crawler mit ihrem User Agent identifiziert werden müssen, um eine Seite anzufragen. Dein UA spiegelt den Browser, den du nutzt, wieder, aber Googles User Agents sind zum Beispiel Googlebot oder Googlebot-image.
Der UA-Wert “robots” spricht alle Crawler an. Du kannst außerdem so viele Robots-Meta-Tags im <head> einfügen, wie du benötigst. Wenn du zum Beispiel verhindern möchtest, dass deine Bilder in der Google- oder Bingsuche auftauchen, füge folgende Meta-Tags hinzu:
<meta name="googlebot-image" content="noindex" />
<meta name="MSNBot-Media" content="noindex" />
Das content-Attribut und Crawling/Indexierungs-Direktiven
Das “content”-Attribut gibt Anweisungen dazu, wie Informationen auf Seiten gecrawlt und indexiert werden sollen. Wenn kein Robots-Meta-Tag vorhanden ist, interpretieren Crawler es als index und follow. Das gibt ihnen die Erlaubnis, die Seite in den Suchergebnissen anzuzeigen und alle Links auf der Seite zu crawlen (wenn nicht anders mit dem rel=”nofollow”-Tag angegeben).
Die folgenden sind die unterstützten Werte für die content-Attribute von Google:
all
Der Standardwert mit “index, follow”, es gibt keinen Grund diese Direktive je zu nutzen.
<meta name="robots" content="all" />
noindex
Weist Suchmaschinen an, die Seite nicht zu indexieren. Dies hält sie davon ab, in Suchergebnissen zu erscheinen.
<meta name="robots" content="noindex" />
nofollow
Hält Crawler davon ab, alle Links auf der Seite zu crawlen. Bitte denke daran, dass diese URLs immer noch indexierbar sein können, besonders wenn Backlinks auf sie zeigen.
<meta name="robots" content="nofollow" />
none
Die Kombination von noindex, nofollow. Vermeide die Nutzung, da andere Suchmaschinen (wie Bing) das nicht unterstützen.
<meta name="robots" content="none" />
noarchive
Verhindert, dass Google eine gecachte Kopie der Seite in den SERPs anzeigt.
<meta name="robots" content="noarchive" />
notranslate
Verhindert, dass Google eine übersetzte Version der Seite in den SERPs anzeigt.
<meta name="robots" content="notranslate" />
noimageindex
Verhindert, dass Google Bilder, die auf der Seite eingebunden sind, indexiert.
<meta name="robots" content="noimageindex" />
unavailable_after:
Teilt Google mit eine Seite nach einem spezifizierten Datum/Zeit nicht mehr in den Suchergebnissen anzuzeigen. Im Prinzip handelt es sich dabei um eine noindex-Direktive mit einem Timer. Das Datum/Zeit muss im RFC 850 Format hinterlegt sein.
<meta name="robots" content="unavailable_after: Sunday, 01-Sep-19 12:34:56 GMT" />
nosnippet
Verhindert alle Text- und Video-Snippets innerhalb der SERPs. Es verhält sich außerdem gleichzeitig wie ein noarchive.
<meta name="robots" content="nosnippet" />
Seit Oktober 2019 bietet Google granularere Optionen an um zu kontrollieren, ob und wie du Snippets in den Suchergebnissen anzeigen lassen möchtest. Das gibt es zum Teil wegen der europäischen Copyright Richtlinie, welche zuerst von Frankreich in seinem neuen Urheberrechtsgesetz implementiert wurde.
Am wichtigsten ist, dass dieses Gesetz bereits alle Webseitenbesitzer betrifft. Wie? Weil Google nicht mehr länger Snippets (Text, Bilder oder Video) deiner Seite in Frankreich anzeigt, außer du willigst explizit mit den neuen Robots-Tags ein.
Wir diskutieren unten wie alle diese neuen Tags funktionieren. Falls dies deinen Geschäftsbereich betrifft und du nach einer schnellen Lösung suchst, füge das folgende HTML-Snippet zu jeder Seite hinzu, um Google mitzuteilen, dass du keine Beschränkungen in deinen Snippets möchtest:
<meta name="robots" content=”max-snippet:-1, max-image-preview:large, max-video-preview:-1" />
Denk daran, dass wenn du Yoast SEO benutzt, dann dieses Codestück automatisch auf jeder Seite hinzugefügt wird, außer du hast noindex oder nosnippet-Direktiven vergeben.
max-snippet:
Legt ein Maximum an Zeichen fest, die Google in seinen Text-Snippets anzeigen kann. Die Nutzung von 0 wird keine Text-Snippets anzeigen, während ‑1 kein Limit bei der Textvorschau deklariert.
Der folgende Tag setzt das Limit auf 160 Zeichen (ähnlich wie die Standard Meta-Description-Länge.):
<meta name="robots" content="max-snippet:160" />
max-image-preview:
Teilt Google mit ob es, und wie groß ein Bild sein kann, das für Image-Snippets genutzt werden kann. Diese Direktive hat drei mögliche Werte:
- none — Kein Image-Snippet wird gezeigt
- standard — Ein Standard-Image kann angezeigt werden
- large — Die größtmöglichste Image-Vorschau kann angezeigt werden
<meta name="robots" content="max-image-preview:large" />
max-video-preview:
Legt eine maximale Sekundenanzahl für ein Video-Snippet fest. Wie beim Text-Snippet bedeutet 0 keine Anzeige und ‑1 setzt keine Limits.
Der folgende Tag würde Google erlauben maximal 15 Sekunden zu zeigen:
<meta name="robots" content="max-video-preview:15" />
Neben den neuen Robots-Direktiven, die im Oktober 2019 eingeführt wurden, hat Google auch das data-snippet HTML-Attribut eingeführt. Du kannst diesen Tag benutzen, um Teile des Inhalts zu markieren, sodass diese nicht von Google als Snippet verwendet werden.
Dies kann in HTML bei div, span und Section-Elementen eingesetzt werden. Das data-nosnippet gilt als boolesches Attribut, was bedeutet das es ohne einen Wert gültig ist.
<p>Dies ist ein Text in einem Abschnitt, der als Snippet angezeigt werden kann<span data-nosnippet>doch dieser Teil nicht</span></p>
<div data-nosnippet>Dies wird nicht in einem Snippet angezeigt</div><div data-nosnippet="true">Und das hier auch nicht</div>
Nutzung dieser Direktiven
Die meisten SEOs müssen nicht über die Verwendung von noindex und nofollow-Direktiven hinaus gehen, aber es ist gut zu wissen, dass es auch andere Optionen gibt. Bedenke, dass alle oben genannten Direktiven von Google unterstützt werden.
Lass uns den Vergleich mit Bing überprüfen:
| Direktive | Bing | |
|---|---|---|
| all | ✅ | ❌ |
| noindex | ✅ | ✅ |
| nofollow | ✅ | ✅ |
| none | ✅ | ❌ |
| noarchive | ✅ | ✅ |
| nosnippet | ✅ | ✅ |
| max-snippet: | ✅ | ❌ |
| max-image-preview: | ✅ | ❌ |
| max-video-preview: | ✅ | ❌ |
| notranslate | ✅ | ❌ |
| noimageindex | ✅ | ❌ |
| unavailable_after: | ✅ | ❌ |
Du kannst mehrere Direktiven benutzen und sie kombinieren. Doch wenn sie in Konflikt miteinander stehen (z.B. “noindex, index”) oder eine ist eine Unteranweisung einer anderen (z.B. “noindex, noarchive”), dann wird Google die restriktivste benutzen. In diesem Fall wäre das einfach “noindex”.
Du wirst vielleicht auch Direktiven über den Weg laufen, die spezifisch für andere Suchmaschinen sind. Ein Beispiel wäre “noyaca”, das Yandex davon abhält, sein eigenes Verzeichnis zu nutzen, um Suchergebnissnippets zu generieren.
Andere können einmal nützlich gewesen sein und wurden in der Vergangenheit benutzt, doch sie sind bereits veraltet. Zum Beispiel wurde die “noodp”-Direktive benutzt, um Suchmaschinen davon abzuhalten, das Open Directory Project zu nutzen, um Snippets zu generieren.
Wie man das Robots-Meta-Tag einsetzt
Nun wo du weißt, was all diese Direktiven tun und wie sie aussehen, ist es an der Zeit zur tatsächlichen Implementierung auf deiner Seite zu kommen.
Robots-Meta-Tags gehören in die <head> Sektion einer Seite. Es ist ziemlich einfach, wenn du den Code mit HTML-Editoren wie Notepad++ oder Brackets bearbeitest. Aber was, wenn du ein CMS mit SEO-Plugins benutzt?
Lass uns auf die beliebtesten da draußen fokussieren.
Implementierung der Robots-Meta-Tags in WordPress unter Verwendung von Yoast SEO
Gehe zur “Advanced”-Sektion unter dem Bearbeitungsblock jedes Artikels oder Seite. Setze den Robots-Meta-Tag nach deinen Bedürfnissen. Die folgenden Einstellungen würden “noindex, nofollow”-Direktiven implementieren.
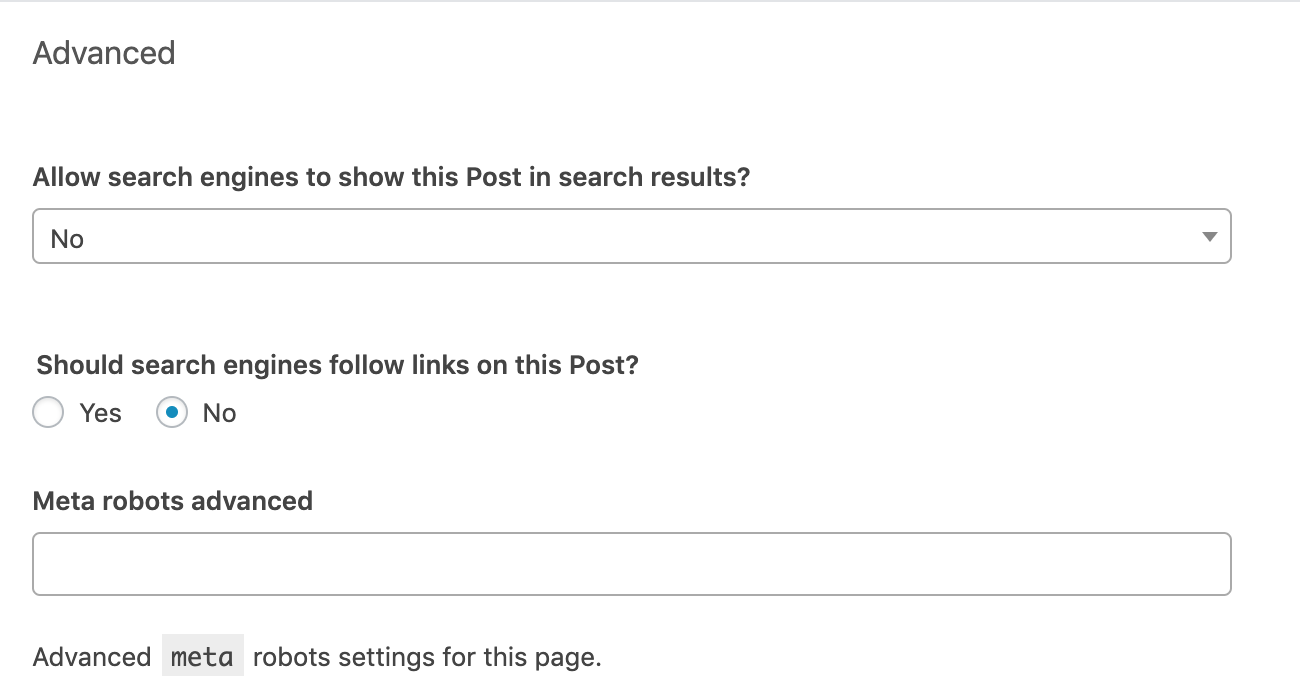
Die “Meta robots advanced” Zeile gibt dir die Option, andere Direktiven als “noindex” und “nofollow” zu implementieren, so wie noimageindex.
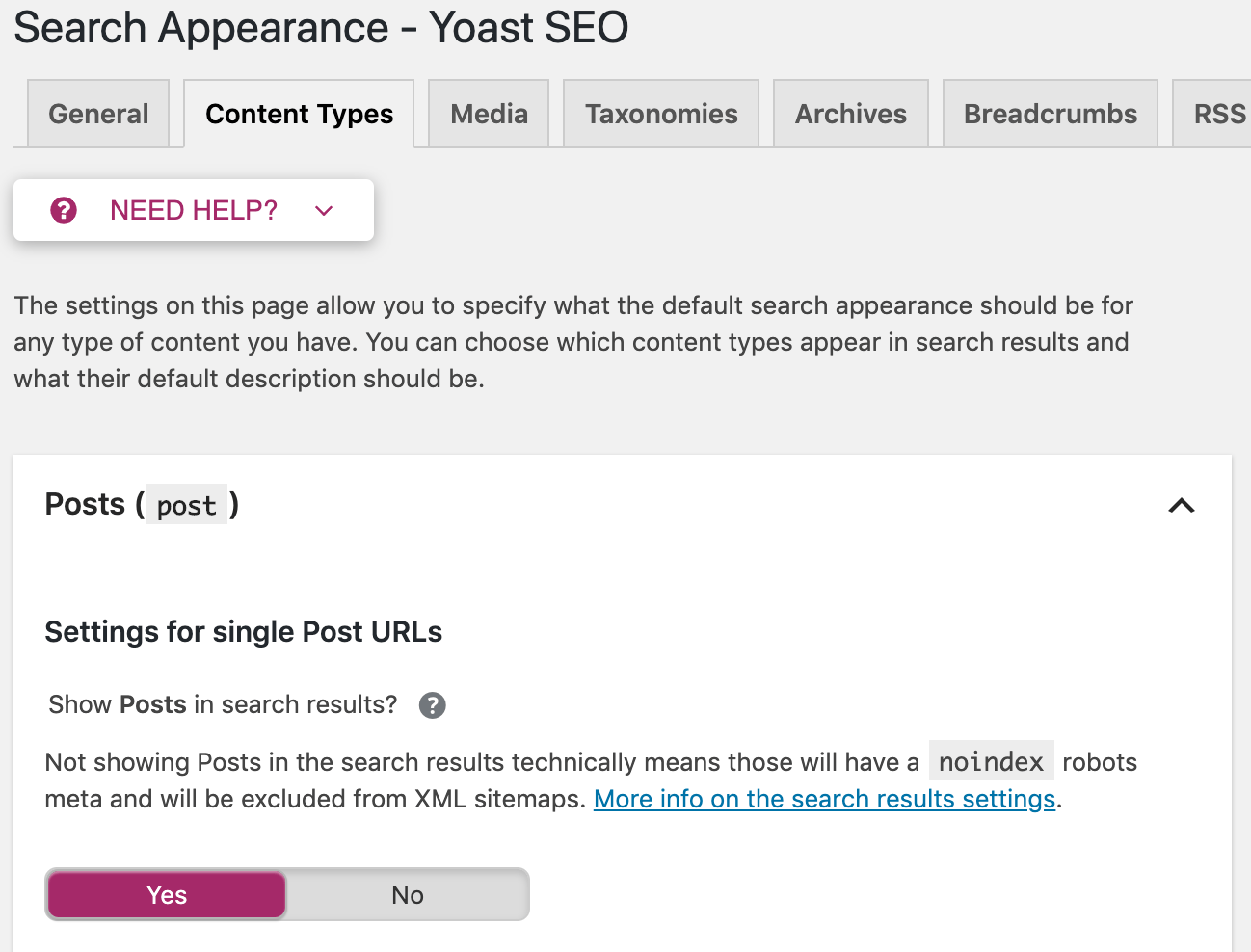
Du kannst diese Direktiven außerdem auch seitenweit nutzen. Gehe zu “Search Appearance” im Yoast Menü. Dort kannst du Meta-Robots-Tags auf allen Artikeln, Seiten oder nur bestimmten Taxonomien oder Archiven anpassen.
Was ist ein X‑Robots-Tag?
Der Robots-Meta-Tag ist geeignet, um hier und da noindex-Direktiven auf HTML-Seiten zu implementieren. Doch was ist, wenn du Suchmaschinen davon abhalten möchtest, Dateien so wie Bilder oder PDFs zu indexieren? Genau hier kommen X‑Robots-Tags ins Spiel.
Der X‑Robots-Tag ist ein HTTP-Header, der von einem Webserver gesendet wird. Anders als beim Meta-Robots-Tag wird er nicht im HTML der Seite platziert. Folgendermaßen kann er aussehen:
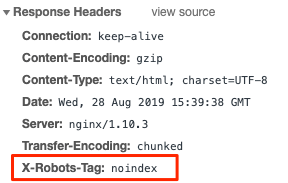
Das Prüfen von HTTP-Headern ist etwas komplizierter. Du kannst es auf die alte Weise mit den Developer Tools erledigen oder eine Browser Extension wie Live HTTP Headers benutzen.
Die Live-HTTP-Headers-Extension überwacht den gesamten HTTP(S)-Traffic, den dein Browser sendet (Request Headers) und empfängt (Response Headers). Es wird live gemessen, also stelle sicher, dass das Plugin aktiviert ist. Gehe dann zur Seite oder Datei, die du untersuchen möchtest und überprüfe das Plugin für die Logs. Es sieht wie folgt aus:
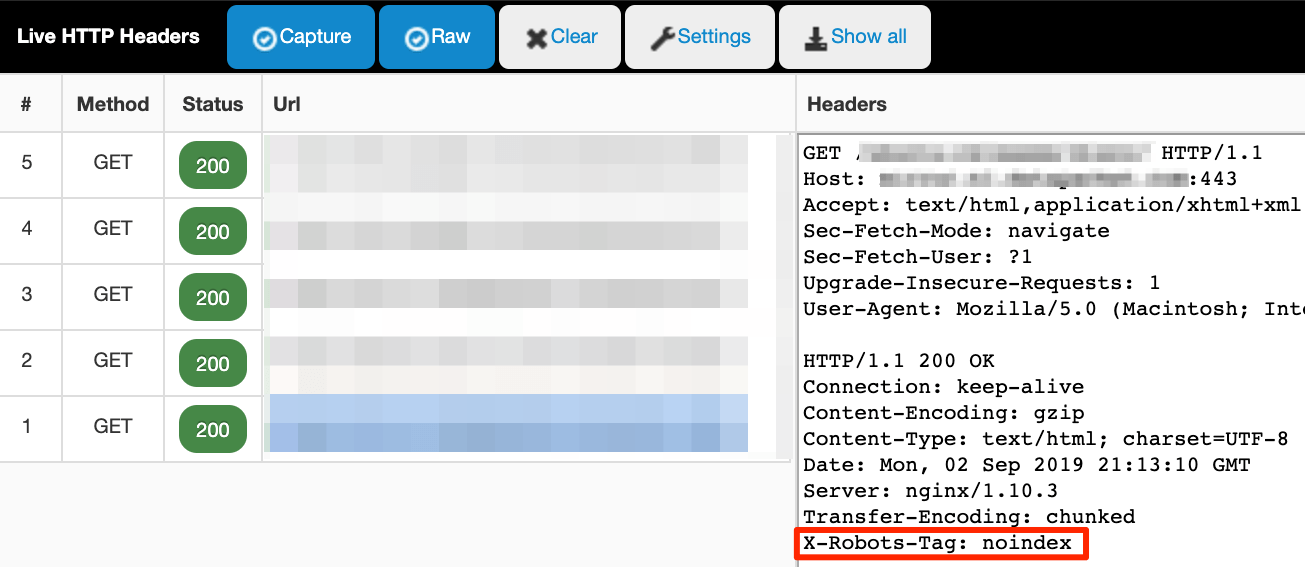
Wie man den X‑Robots-Tag einsetzt
Die Konfiguration hängt vom Typ des Webservers, den du benutzt und welchen Seiten oder Dateien du aus dem Index fernhalten möchtest, ab.
Die Code-Zeile sieht folgendermaßen aus:
Header set X-Robots-Tag “noindex”
Dieses Beispiel setzt den meist verbreiteten Servertyp voraus—Apache. Der praktischste Weg um HTTP-Header hinzuzufügen, ist die Hauptkonfigurationsdatei zu bearbeiten (üblicherweise httpd.conf) oder .htaccess-Dateien. Das kommt dir bekannt vor? Das ist auch der Ort, an dem Weiterleitungen stattfinden.
Du benutzt die selben Werte und Direktiven für den X‑Robots-Tag wie beim Meta-Robots-Tag. Es sollte aber gesagt sein, dass diese Art der Implementierung etwas für Fortgeschrittene ist. Backups sind dein Freund, denn selbst ein kleiner Syntax-Fehler kann die gesamte Webseite zerstören.
Wenn du ein CDN benutzt, dass serverlose Applikationen für Edge-SEO unterstützt, dann kannst du sowohl Robots-Meta-Tags als auch X‑Robots-Tags auf dem Edge-Server anpassen ohne Änderungen in der darunterliegenden Codebase machen zu müssen.
Während das Hinzufügen von HTML-Snippets wie die einfachste und geradlinige Option aussieht, kann das manchmal zu kurz gegriffen sein.
Nicht-HTML-Dateien
Du kannst kein HTML-Snippet in Nicht-HTML-Dateien wie PDFs oder Bildern platzieren. X‑Robots-Tags sind der einzige Weg.
Das folgende Snippet (auf einem Apache-Server) würde noindex HTTP-Header für alle PDF-Dateien auf der Seite konfigurieren.
<Files ~ ".pdf$"> Header set X-Robots-Tag "noindex" </Files>
Direktiven großflächig anwenden
Wenn du eine ganze (Sub)domain, Unterverzeichnis, Seiten mit bestimmten Parametern oder irgendetwas anderes, das eine Massenbearbeitung erfordert, deindexieren musst, nutze X‑Robots-Tags. Es ist einfacher.
HTTP-Header-Modifizierungen können mit regulären Ausdrücken gegen URLs und Dateinamen gematched werden. Komplizierte Massenbearbeitungen in HTML mit der Suchen und Ersetzen Funktion würde üblicherweise mehr Zeit und Rechenzeit erfordern.
Traffic von alternativen Suchmaschinen zu Google
Google unterstützt sowohl Meta-Robots-Tags und X‑Robots-Tags, aber das trifft nicht für alle Suchmaschinen zu.
Zum Beispiel Seznam, die tschechische Suchmaschine, unterstützt nur Robots-Meta-Tags. Wenn du steuern möchtest, wie diese Suchmaschine deine Seiten crawlt und indexiert, dann wird die Verwendung von X‑Robots-Tags nicht funktionieren. Du musst HTML-Snippets benutzen.
Wie du Crawlbarkeits- und (De)indexierungsfehler vermeiden kannst
Du möchtest alle wertvollen Seiten zeigen, Probleme mit doppelten Inhalten vermeiden und spezifische Inhalte aus dem Index halten. Wenn du eine große Webseite verwaltest, dann ist Crawl-Budget eine weitere Sache, der es Beachtung zu schenken gilt.
Lass uns einen Blick auf die häufigsten Fehler werfen, die Menschen hinsichtlich Robots-Direktiven machen.
Fehler #1: Noindex-Direktiven zu Seiten, die in der robots.txt gesperrt sind, hinzufügen
Verbiete niemals das Crawling von Seiten, die du versuchst zu deindexieren, über die robots.txt. Das zu tun verhindert, dass Suchmaschinen die Seite erneut crawlen und die noindex-Direktive erkennen.
Wenn du glaubst, diesen Fehler gemacht zu haben, dann crawle deine Seite mit Ahrefs Site Audit. Suche nach Seiten mit “Noindex-Seite erhält organischen Traffic”-Fehlern.
Nicht indexierbare Seiten, die organischen Traffic erhalten, sind ein klares Zeichen dafür, dass diese noch immer indexiert sind. Wenn du den Noindex-Tag nicht kürzlich hinzugefügt hast, dann ist das wegen einer Crawl-Blockierung in deiner robots.txt. Überprüfe auf Probleme und behebe diese, wo nötig.
Fehler #2: Schlechtes Sitemap-Management
Wenn du versuchst Content zu deindexieren, egal ob mit Meta-Robots-Tag oder X‑Robots-Tag, dann entferne ihn nicht aus deiner Sitemap bis er erfolgreich deindexiert wurde. Andernfalls wird Google mehr Zeit benötigen die Seite erneut zu crawlen.
@nishanthstephen generally anything you put in a sitemap will be picked up sooner
— Gary “鯨理” Illyes (@methode) 13 October 2015
Setze, um den Deindexierungsprozess weiter zu beschleunigen, das lastmod-Datum in deiner Sitemap auf das Datum, an dem du den noindex Tag hinzugefügt hast. Dies begünstigt ein erneutes Crawlen und eine Neubewertung.
Another trick you can do is submit a sitemap file with a lastmod date matching when you 404’d to encourage recrawl & reprocessing.
— 🍌 John 🍌 (@JohnMu) 16 January 2017
Lasse keine nicht indexierbaren Seiten langfristig in deiner Sitemap. Sobald der Inhalt deindexiert wurde, solltest du ihn aus deiner Sitemap entfernen.
Wenn du Sorge hast das alte, erfolgreich deindexierte Inhalte noch immer in deiner Sitemap existieren könnten, dann prüfe den “Noindex Seiten Sitemap” Fehler im Ahrefs Site Audit.
Fehler #3: Noindex-Direktiven nicht aus der Produktionsebene entfernen
Crawler davon abzuhalten etwas auf einer Staging-Umgebung zu crawlen oder zu indexieren ist ein gutes Vorgehen. Manchmal jedoch gerät das in die Produktionsumgebung, wird vergessen und dein organischer Traffic sinkt.
Noch schlimmer, der Abfall des organischen Traffics könnte nicht so bemerkbar sein wenn es sich um eine Seitenmigration mit Nutzung von 301-Weiterleitungen handelt. Wenn die neuen URLs die Noindex-Direktive haben oder per robots.txt gesperrt sind, dann wirst du noch immer einige Zeit organischen Traffic von den alten Seiten erhalten. Es kann Google bis zu ein paar Wochen abverlangen diese alten URLs zu deindexieren.
Wann immer es solche Änderungen auf deiner Seite gibt, behalte einen Blick auf die “Noindex Seite” Warnungen im Ahrefs Site Audit:
Um dabei zu helfen ähnliche Probleme künftig zu vermeiden, solltest du die Checkliste der Entwickler dahingehend erweitern, Disallow-Regeln aus der robots.txt und Noindex-Direktiven zu entfernen bevor etwas auf die Produktionsumgebung geht.
Fehler #4: “Geheime” URLs zur robots.txt hinzufügen anstatt sie auf noindex zu setzen
Entwickler versuchen häufig, Seiten über anstehende Promotions, Rabatte oder Produkteinführungen über ein Aussperren in der robots.txt zu verstecken. Das ist ein schlechtes Vorgehen, weil Menschen die robots.txt weiterhin sehen können. Deshalb werden diese Seiten schnell geleaked.
Behebe das, indem du “geheime” Seiten aus der robots.txt heraushältst und sie stattdessen auf noindex setzt.
Schlussgedanken
Das Crawling und die Indexierung deiner Seite gründlich zu verstehen und zu verwalten sind die Grundpfeiler von SEO. Technisches SEO kann ziemlich kompliziert sein, aber Robots-Meta-Tags sind nichts wovon man Angst haben müsste.
Ich hoffe, dass du nun darauf vorbereitet bist, das beste Vorgehen für langfristige Lösungen in großer Menge umzusetzen.
Lass es mich über Twitter oder in den Kommentaren wissen, wenn du irgendwelche Fragen hast.
Übersetzt von: Sebastian Simon. Sebastian Simon beschäftigt sich seit 2009 mit SEO, aktuell tut er das bei seven-bytes.de und heine.de.


