
Die meisten Websites verwenden irgendeine Form von JavaScript, um Interaktivität zu ermöglichen und die Benutzerfreundlichkeit zu verbessern. Einige verwenden es für Menüs, das Einblenden von Produkten oder Preisen, das Abrufen von Inhalten aus verschiedenen Quellen oder in einigen Fällen für alle Elemente auf der Website. Die Realität im modernen Internet ist, dass JavaScript allgegenwärtig ist.
Wie John Mueller von Google sagte:
The web has moved from plain HTML — as an SEO you can embrace that. Learn from JS devs & share SEO knowledge with them. JS’s not going away.
— 🍌 John 🍌 (@JohnMu) August 8, 2017
Ich sage nicht, dass SEOs losziehen und lernen müssen, wie man JavaScript programmiert. Das genaue Gegenteil ist der Fall. SEOs müssen vor allem wissen, wie Google mit JavaScript umgeht und wie sie Probleme beheben können. In sehr wenigen Fällen darf ein SEO den Code auch nur berühren. Mein Ziel mit diesem Beitrag ist es, dir beim Lernen zu helfen:
- Was ist Javascript SEO
- Wie Google Seiten mit JavaScript verarbeitet
- Wie man JavaScript testet und Fehler behebt
- Rendering Optionen
- Deine JavaScript-Website SEO-freundlich gestalten
JavaScript SEO ist ein Teil des technischen SEO (Search Engine Optimization), der darauf abzielt, JavaScript-lastige Websites einfach zu crawlen und zu indizieren, sowie suchfreundlich zu machen. Das Ziel ist es, dass diese Websites in Suchmaschinen gefunden werden und ein höheres Ranking erhalten.
Ist JavaScript schlecht für SEO; ist JavaScript böse? Ganz und gar nicht. Es ist nur anders als das, was viele SEOs gewohnt sind, und es gibt eine gewisse Lernkurve. Die Leute neigen dazu, es für Dinge zu nutzen, für die es wahrscheinlich eine bessere Lösung gibt. Aber manchmal muss man mit dem arbeiten, was man hat. Du musst nur wissen, dass Javascript nicht perfekt ist und nicht immer das richtige Werkzeug für die Aufgabe ist. Im Gegensatz zu HTML und CSS kann es nicht progressiv geparst werden, und es kann die Ladezeit der Seite und die Performance stark beeinträchtigen. In vielen Fällen tauschst du möglicherweise Leistung gegen Funktionalität.
In den frühen Tagen der Suchmaschinen reichte eine heruntergeladene HTML-Antwort aus, um den Inhalt der meisten Seiten zu sehen. Dank des Vormarsches von JavaScript müssen Suchmaschinen heute viele Seiten wie ein Browser darstellen, damit sie den Inhalt so sehen können, wie ein Benutzer ihn sieht.
Das System, das den Rendering-Prozess bei Google abwickelt, heißt Web Rendering Service (WRS). Google hat ein vereinfachtes Diagramm zur Verfügung gestellt, um zu zeigen, wie dieser Prozess funktioniert.
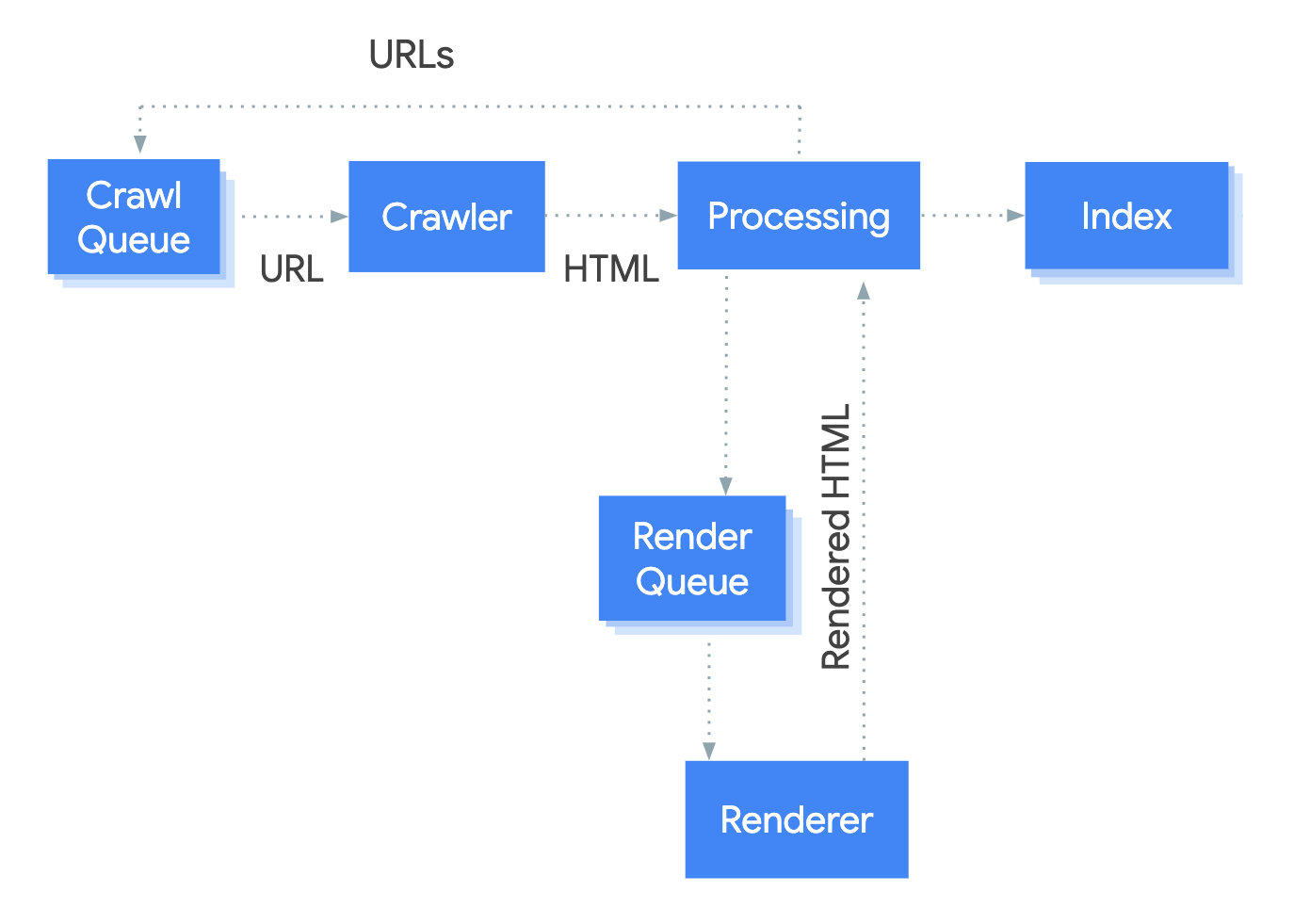
Nehmen wir an, wir beginnen den Prozess bei URL.
1. Crawler
Der Crawler sendet GET-Anforderungen an den Server. Der Server antwortet mit Headern und dem Inhalt der Datei, die dann gespeichert wird.
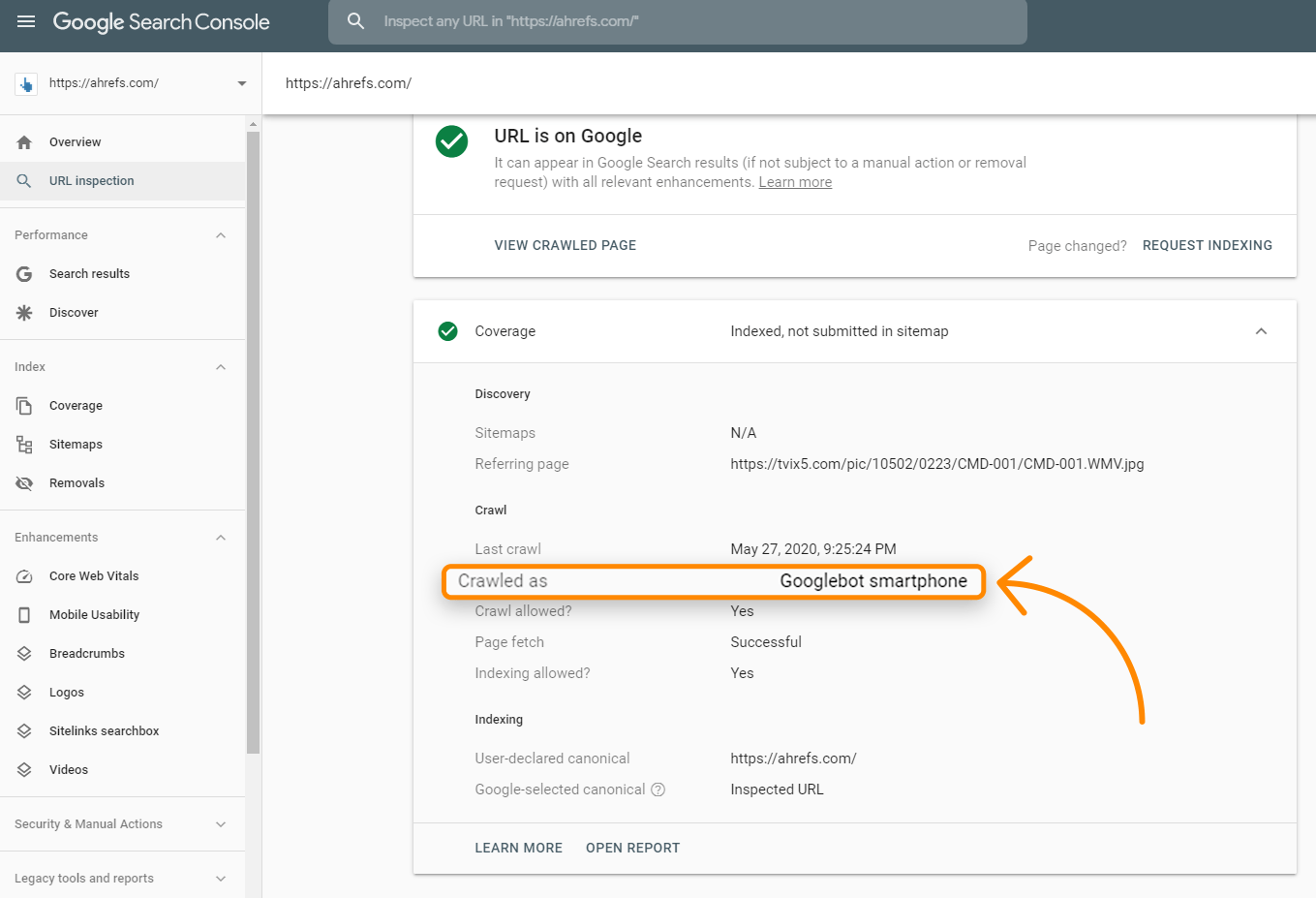
Die Anfrage wird wahrscheinlich von einem mobilen Nutzer-Agenten kommen, da Google jetzt hauptsächlich auf Mobile First indexiert ist. Mit dem URL-Inspektionstool in der Suchkonsole kannst du überprüfen, wie Google deine Website crawlt. Wenn du dies für eine URL ausführst, überprüfe die Abdeckungsinformationen für “Gecrawlt als”. Daran solltest du erkennen, ob du dich noch immer in der Desktop-Indizierung oder in der „Mobile First“-Indizierung befindest.
Die Anfragen kommen hauptsächlich aus Mountain View, CA, USA, aber sie crawlen auch einige lokal angepassten Seiten außerhalb der Vereinigten Staaten. Ich erwähne dies, weil einige Websites Besucher aus einem bestimmten Land oder die Verwendung einer bestimmten IP auf verschiedene Weise blockieren oder behandeln, was dazu führen kann, dass dein Content vom Googlebot nicht gesehen wird.
Einige Websites verwenden möglicherweise auch die User-Agent-Erkennung, um einem bestimmten Crawler Inhalte anzuzeigen. Insbesondere bei JavaScript-Websites sieht Google möglicherweise etwas anderes als ein Nutzer. Aus diesem Grund sind Google-Tools wie das URL-Inspektionstool in der Google-Suchkonsole, der Test zur Mobilfreundlichkeit und der Test zur Ermittlung von Rich Results wichtig für die Fehlerbehebung bei JavaScript-SEO-Problemen. Sie zeigen dir, was Google sieht, und sind nützlich, um zu überprüfen, ob Google möglicherweise blockiert wird und ob sie den Inhalt auf der Seite sehen können. Wie du dies testen kannst, werde ich im Abschnitt über den Renderer behandeln, da es einige wesentliche Unterschiede zwischen der heruntergeladenen GET-Anfrage, der gerenderten Seite und sogar den Testtools gibt.
Es ist auch wichtig zu beachten, dass Google zwar die Ausgabe des Crawling-Vorgangs als „HTML“ auf dem Bild oben angibt, in Wirklichkeit aber alle Ressourcen, die zum Erstellen der Seite benötigt werden, crawlt und speichert. HTML-Seiten, Javascript-Dateien, CSS, XHR-Anforderungen, API-Endpunkte und mehr.
2. Verarbeitung
Es gibt viele Systeme, die durch den Begriff „Verarbeitung“ im Bild verschleiert werden. Ich werde einige davon behandeln, die für JavaScript relevant sind.
Ressourcen und Links
Google navigiert nicht von Seite zu Seite, wie es ein Nutzer tun würde. Ein Teil der Verarbeitung besteht darin, die Seite auf Links zu anderen Seiten und Dateien zu überprüfen, die zum Aufbau der Seite benötigt werden. Diese Links werden herausgezogen und der Crawl-Warteschlange hinzugefügt, die von Google zur Priorisierung und Planung des Crawlens verwendet wird.
Google zieht Ressourcen-Links (CSS, JS usw.), die zum Aufbau einer Seite benötigt werden, aus Dingen wie <link> tags. Links zu anderen Seiten müssen jedoch in einem bestimmten Format vorliegen, damit Google sie als Links behandeln kann. Interne und externe Links müssen ein <a> tag mit einem href ‑Attribut aufweisen. Es gibt viele Möglichkeiten, wie du dies für Benutzer mit JavaScript umsetzen kannst, die nicht suchfreundlich sind.
Gut:
<a href=”/seite”>einfach ist gut</a> <a href=”/seite” onclick=”goTo(‘seite’)”>immer noch okay</a>
Schlecht:
<a onclick=”goTo(‘page’)”>nein, kein href</a> <a href=”javascript:goTo(‘page’)”>nein, Link fehlt</a> <a href=”javascript:void(0)”>nein, Link fehlt</a> <span onclick=”goTo(‘page’)”>nicht das korrekte HTML-Element</span> <option value="page">nein, falsches HTML-Element</option> <a href=”#”>kein Link</a> Button, ng-click, es gibt viele weitere Möglichkeiten, wie dies falsch gemacht werden kann.
Es ist auch erwähnenswert, dass interne Links, die mit JavaScript hinzugefügt wurden, erst nach dem Rendern übernommen werden. Das sollte relativ schnell gehen und in den meisten Fällen kein Grund zur Besorgnis sein.
Caching
Jede Datei, die Google herunterlädt, einschließlich HTML-Seiten, JavaScript-Dateien, CSS-Dateien usw., wird aggressiv gecached. Google ignoriert deine Cache-Timings und holt sich eine neue Kopie, wenn es das möchte. Ich werde im Abschnitt Renderer ein wenig mehr darüber sprechen und warum dies wichtig ist.
Beseitigung von Duplikaten
Doppelte Inhalte können aus dem heruntergeladenen HTML eliminiert oder depriorisiert werden, bevor sie zum Rendern gesendet werden. Bei App-Shell-Modellen kann es vorkommen, dass sehr wenig Inhalt und Code in der HTML-Antwort angezeigt wird. Tatsächlich kann es vorkommen, dass auf jeder Seite der Website derselbe Code angezeigt wird, und dies könnte derselbe Code sein, der auf mehreren Websites angezeigt wird. Dies kann manchmal dazu führen, dass Seiten als Duplikate behandelt werden und nicht sofort zum Rendering geschickt werden. Schlimmer noch, die falsche Seite oder sogar die falsche Website kann in den Suchergebnissen angezeigt werden. Dies sollte sich mit der Zeit von selbst beheben, kann aber problematisch sein, insbesondere bei neueren Websites.
Die restriktivsten Richtlinien
Google wählt die restriktivsten Anweisungen zwischen HTML und der gerenderten Version einer Seite aus. Wenn JavaScript eine Anweisung ändert und dies mit der Anweisung aus HTML in Konflikt steht, wird Google einfach diejenige Anweisung befolgen, die am restriktivsten ist. Noindex überschreibt den Index, und Noindex in HTML überspringt die Darstellung ganz.
3. Render Liste
Jede Seite geht jetzt zum Renderer. Eine der größten Bedenken vieler SEOs mit JavaScript und zweistufiger Indizierung (HTML, dann gerenderte Seite) ist, dass Seiten möglicherweise tage- oder sogar wochenlang nicht gerendert werden. Als Google dies untersuchte, stellte sich heraus, dass die Seiten bei einer durchschnittlichen Zeit von 5 Sekunden an den Renderer gingen, und das 90ste Perzentil lag bei Minuten. Die Zeitspanne zwischen dem Abrufen der HTML-Datei und dem Rendern der Seiten sollte also in den meisten Fällen kein Problem darstellen.
4. Renderer
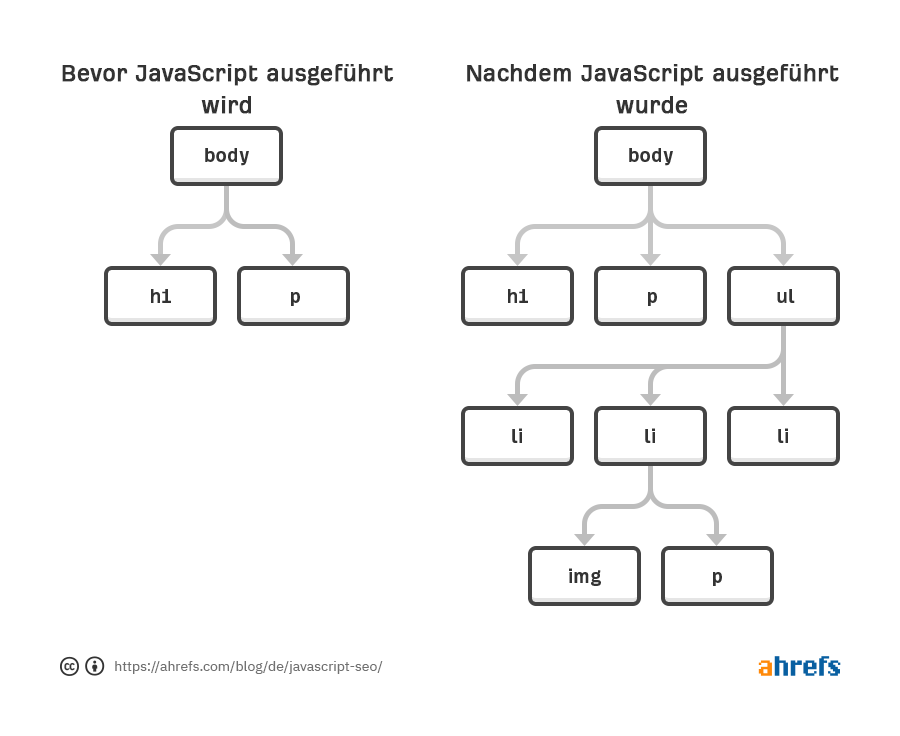
Der Renderer ist der Ort, an dem Google eine Seite rendert, um zu sehen, was ein Nutzer sieht. Hier werden das JavaScript und alle von JavaScript am Document Object Model (DOM) vorgenommenen Änderungen verarbeitet.
Dazu verwendet Google einen headless Chrome-Browser, der jetzt „evergreen“ ist, d.h. er sollte die neueste Chrome-Version verwenden und die neuesten Funktionen unterstützen. Bis vor kurzem hat Google mit Chrome 41 gerendert, so dass viele Funktionen nicht unterstützt wurden.
Google verfügt über weitere Informationen zum Web Rendering Service (WRS), der Dinge wie die Verweigerung von Berechtigungen, stateless, flattening-light-DOM und shadow-DOM und vieles mehr enthält, was lesenswert ist. DOM, and more that is worth reading.
Rendering im Maßstab des Web könnte das 8. Weltwunder sein. Es ist ein ernsthaftes Unterfangen und erfordert einen enormen Aufwand an Ressourcen. Wegen des Umfangs nimmt Google viele Abkürzungen beim Rendering-Prozess, um die Dinge zu beschleunigen. Wir bei Ahrefs sind das einzige große SEO-Tool, das Webseiten im großen Maßstab rendert, und wir schaffen es, ~150 Millionen Seiten pro Tag zu rendern, um unseren Link-Index vollständiger zu machen. Es erlaubt uns, auf JavaScript-Redirects zu prüfen, und wir können auch Links anzeigen, die wir mit JavaScript eingefügt gefunden haben und die wir mit einem JS-Tag in den Linkberichten anzeigen:

Gecachte Resourcen
Google verlässt sich stark auf gecachte Ressourcen. Seiten werden gecached; Dateien werden gecached; API-Anforderungen werden gecached; im Grunde wird alles im Cache gespeichert, bevor es an den Renderer gesendet wird. Google zieht nicht los und lädt bei jedem Seitenaufruf jede Ressource herunter, sondern verwendet stattdessen gecachte Ressourcen, um diesen Prozess zu beschleunigen.
Dies kann zu einigen unmöglichen Zuständen führen, in denen frühere Dateiversionen im Rendering-Prozess verwendet werden und die indizierte Version einer Seite Teile älterer Dateien enthalten kann. Du kannst Dateiversionierung oder Content-Fingerprinting verwenden, um neue Dateinamen zu generieren, wenn signifikante Änderungen vorgenommen werden, so dass Google die aktualisierte Version der Ressource zum Rendern herunterladen muss.
Kein festes Timeout
Ein verbreiteter SEO-Mythos ist, dass der Renderer nur fünf Sekunden wartet, um deine Seite zu laden. Es ist zwar immer eine gute Idee, deine Seite schneller zu machen, aber dieser Mythos macht nicht wirklich Sinn mit der Art und Weise, wie Google die oben erwähnten Dateien zwischenspeichert. Im Grunde laden sie eine Seite, auf der bereits alles zwischengespeichert ist. Der Mythos rührt von den Test-Tools wie dem URL-Inspektionstool her, bei dem Ressourcen live abgerufen werden und sie ein vernünftiges Limit setzen müssen.
Es gibt kein festes Timeout für den Renderer. Was sie wahrscheinlich tun, ist etwas Ähnliches wie das öffentliche Rendertron. Sie warten wahrscheinlich auf etwas wie networkidle0, wo keine Netzwerkaktivität mehr stattfindet, und setzen auch eine maximale Zeitspanne fest, falls etwas stecken bleibt oder jemand versucht, Bitcoin auf ihren Seiten abzubauen.
Was Googlebot sieht
Googlebot wird auf Webseiten nicht aktiv. Er wird nicht auf Dinge klicken oder scrollen, aber das bedeutet nicht, dass es keine Workarounds gibt. Was den Inhalt betrifft, so sehen sie ihn, solange er im DOM geladen ist, ohne dass eine Aktion erforderlich ist. Darauf werde ich im Abschnitt über die Fehlerbehebung näher eingehen, aber im Grunde genommen wird der Inhalt, wenn er sich im DOM befindet, aber nur versteckt ist, gesehen. Wenn er erst nach einem Klick in das DOM geladen wird, dann wird der Inhalt nicht gefunden.
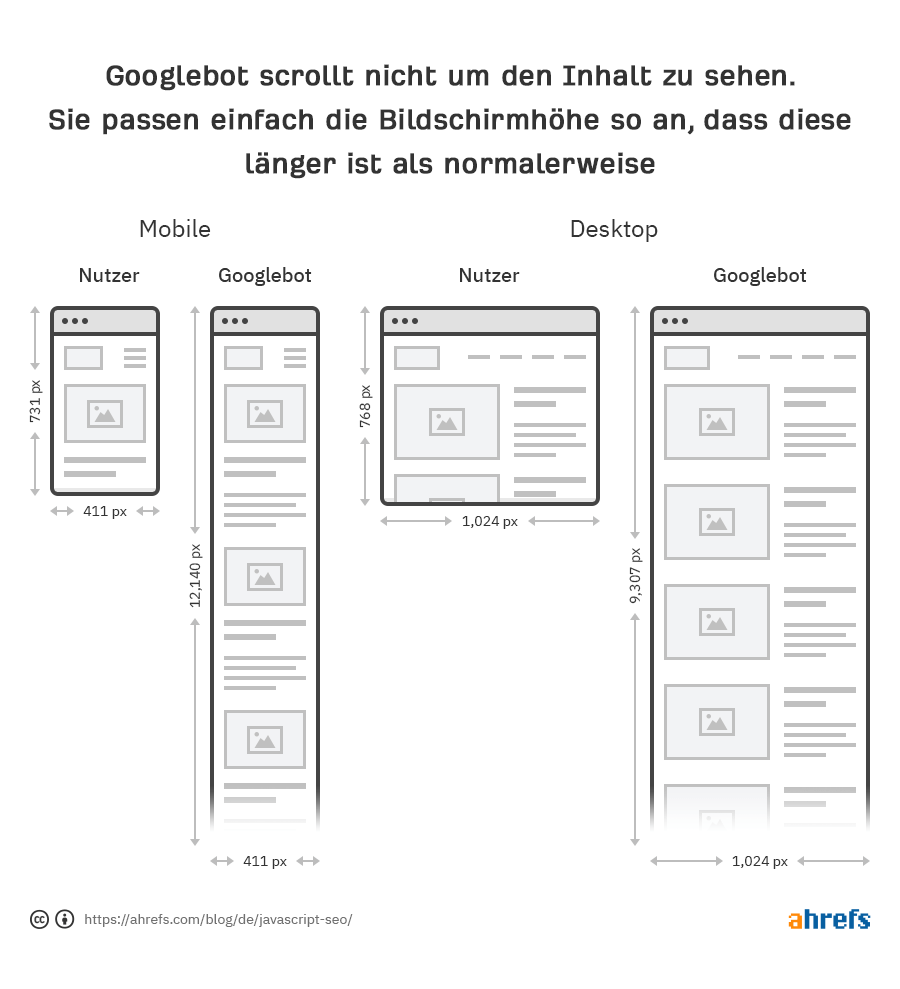
Google muss auch nicht scrollen, um deinen Content zu sehen, weil es eine clevere Workaround-Lösung hat, um den Content zu sehen. Für Handys laden sie die Seite mit einer Bildschirmgröße von 411x731 Pixeln und passen die Länge auf 12.140 Pixel an. Im Wesentlichen wird daraus ein wirklich langes Telefon mit einer Bildschirmgröße von 411x12140 Pixeln. Für den Desktop machen sie dasselbe und gehen von 1024x768 Pixel auf 1024x9307 Pixel.
Eine weitere interessante Abkürzung ist, dass Google die Pixel während des Rendervorgangs nicht darstellt. Das braucht Zeit und zusätzliche Ressourcen, um eine Seite fertig zu laden, und sie brauchen nicht wirklich den Endzustand mit den dargestellten Pixeln zu sehen. Sie müssen nur die Struktur und das Layout kennen, und das bekommen sie, ohne dass sie die Pixel tatsächlich darstellen müssen. Wie Martin Splitt von Google es ausdrückt:
https://youtube.com/watch?v=Qxd_d9m9vzo%3Fstart%3D154
Bei der Google-Suche kümmern wir uns nicht wirklich um die Pixel, weil wir sie nicht wirklich jemandem zeigen wollen. Wir wollen die Informationen und die semantischen Informationen verarbeiten, also brauchen wir etwas im Zwischenzustand. Wir müssen die Pixel nicht wirklich darstellen.
Eine visuelle Darstellung könnte helfen, den herausgeschnittenen Teil etwas besser zu erklären. Wenn du in Chrome Dev Tools einen Test auf der Registerkarte Leistung ausführst, erhältst du ein Ladediagramm. Der durchgehend grüne Teil stellt hier die Darstellungsphase dar, und für Googlebot geschieht das nie, so dass sie Ressourcen sparen.

Grau = Downloads
Blau = HTML
Gelb = JavaScript
Violett = Layout
Grün = Darstellung
5. Crawl Liste
Google hat eine Ressource, die ein wenig über das Crawl-Budget spricht, aber du solltest wissen, dass jede Website ein eigenes Crawl-Budget hat und jede Anfrage priorisiert werden muss. Google muss außerdem das Crawling deiner Website im Vergleich zu jeder anderen Website im Internet ausgleichen. Neuere Websites im Allgemeinen oder Websites mit vielen dynamischen Seiten werden wahrscheinlich langsamer gecrawlt. Einige Seiten werden weniger häufig aktualisiert als andere, und einige Ressourcen werden möglicherweise auch weniger häufig angefordert.
Ein Haken bei JavaScript-Seiten ist, dass sie nur Teile des DOM aktualisieren können. Als Nutzer zu einer anderen Seite zu browsen, kann dazu führen, dass einige Aspekte wie Titel-Tags oder kanonische Tags im DOM nicht aktualisiert werden. Aber dies ist für Suchmaschinen unter Umständen kein Problem. Denke daran, dass Google jede Seite zustandslos lädt, d.h. sie speichern keine früheren Informationen und navigieren nicht zwischen den Seiten. Ich habe gesehen, wie SEOs durcheinander gekommen sind, weil sie dachten, es gäbe ein Problem aufgrund der Dinge, die sie sehen, nachdem sie von einer Seite zur anderen navigiert sind, wie z.B. ein kanonisches Tag, das nicht aktualisiert wird. Google sieht jedoch diesen Zustand möglicherweise nie. Entwickler können dies beheben, indem sie den Status mit Hilfe der so genannten History-API aktualisieren, aber auch hier stellt dies möglicherweise kein Problem dar. Aktualisiere die Seite und schau dir an, was du siehst, oder besser noch, lasse sie durch eines von Googles Testtools laufen, um zu prüfen, was Google sieht. Mehr dazu in einer Sekunde.
View-source vs. Inspect
Wenn du in einem Browser-Fenster mit der rechten Maustaste klickst, siehst du eine Reihe von Optionen, um den Quellcode der Seite anzuzeigen und die Seite zu inspizieren. View-source wird dir das Gleiche zeigen wie eine GET-Anfrage. Dies ist das rohe HTML der Seite. Inspect zeigt dir das verarbeitete DOM, nachdem Änderungen vorgenommen wurden, und ist näher am Inhalt, den Googlebot sieht. Es handelt sich im Grunde um die aktualisierte und neueste Version der Seite. Du solltest eher Inspect statt View-Source verwenden, wenn du mit JavaScript arbeitest.
Google Cache
Googles Cache ist kein verläßliches Mittel, um zu überprüfen, was Googlebot sieht. Normalerweise ist es das ursprüngliche HTML, allerdings ist es manchmal auch das gerenderte HTML oder eine ältere Version. Das System wurde entwickelt, um den Inhalt zu sehen, wenn eine Website nicht verfügbar ist. Als Debugging-Tool ist es nicht besonders nützlich.
Google Testing Tools
Googles Test-Tools wie der URL-Inspektor in der Google-Suchkonsole, Mobile Friendly Tester, Rich Results Tester sind für die Fehlersuche nützlich. Dennoch unterscheiden sich auch diese Tools leicht von dem, was Google sehen wird. Ich habe bereits über das Fünf-Sekunden-Timeout in diesen Tools gesprochen, das der Renderer nicht hat, aber diese Tools unterscheiden sich auch dadurch, dass sie Ressourcen in Echtzeit abrufen und nicht die zwischengespeicherten Versionen verwenden, wie es der Renderer tun würde. Die Screenshots in diesen Tools zeigen auch Seiten mit den dargestellten Pixeln, die Google im Renderer nicht sieht.
Die Tools sind jedoch nützlich, um zu sehen, ob der Inhalt im DOM geladen ist. Das in diesen Tools angezeigte HTML ist das gerenderte DOM. Du kannst nach einem Textausschnitt suchen, um zu sehen, ob er standardmäßig geladen wurde.
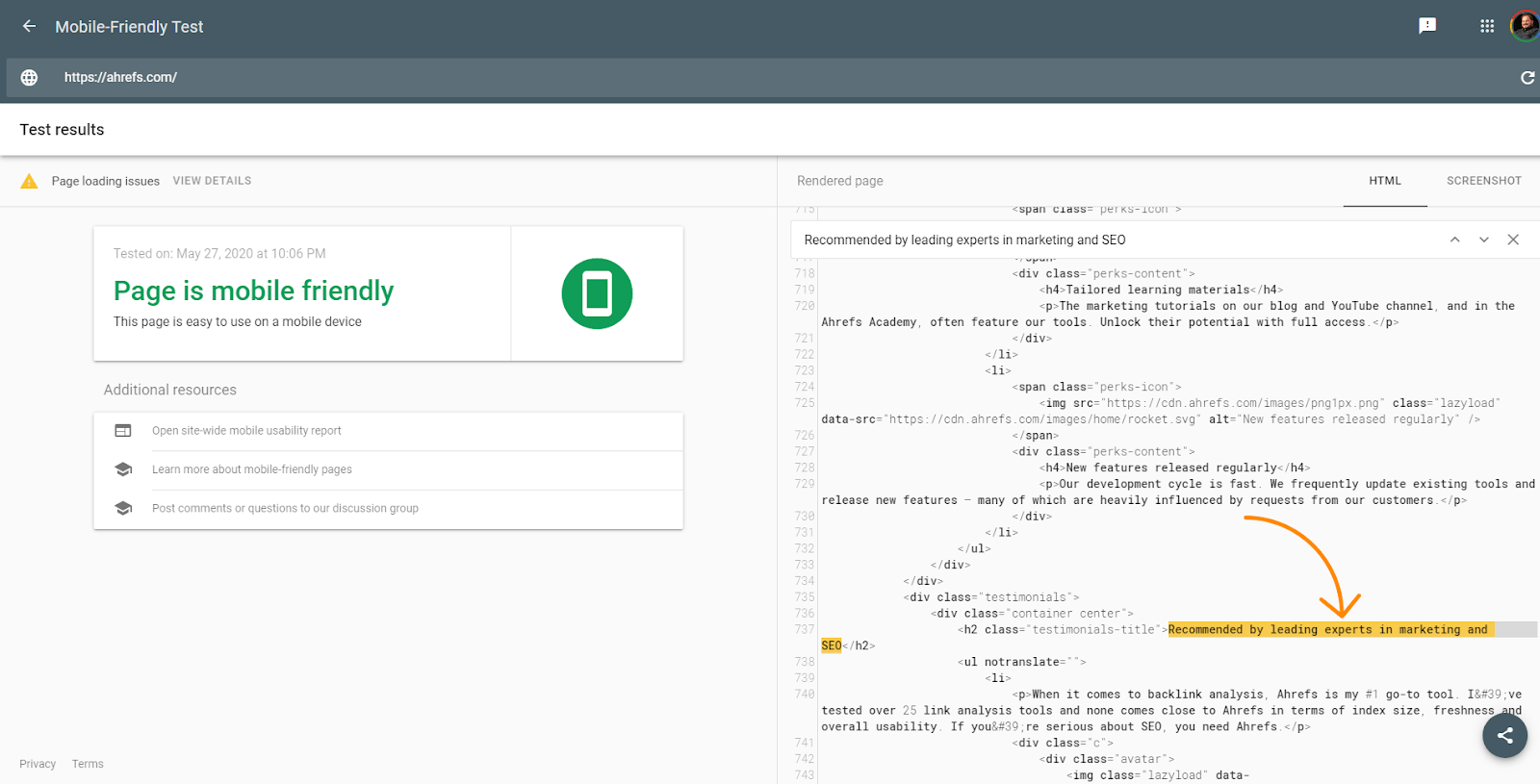
Die Tools zeigen dir auch Ressourcen an, die möglicherweise blockiert sind, und geben Fehlermeldungen in der Konsole aus, die für die Fehlersuche nützlich sind.
Text in Google suchen
Eine weitere schnelle Überprüfung, die du durchführen kannst, ist die einfache Suche nach einem Ausschnitt deines Inhalts in Google. Suche nach „irgendeinem Ausschnitt aus Ihrem Inhalt” und schaue nach, ob die Seite zurückgegeben wird. Wenn ja, dann wurde dein Inhalt wahrscheinlich gesehen. Beachte, dass Inhalte, die standardmäßig ausgeblendet sind, in deinem Snippet in den SERPs möglicherweise nicht angezeigt werden.
Ahrefs
Neben den Seiten mit Linkindex-Rendering kannst du JavaScript in Site Audit-Crawls aktivieren, um mehr Daten in deinen Audits freizuschalten.
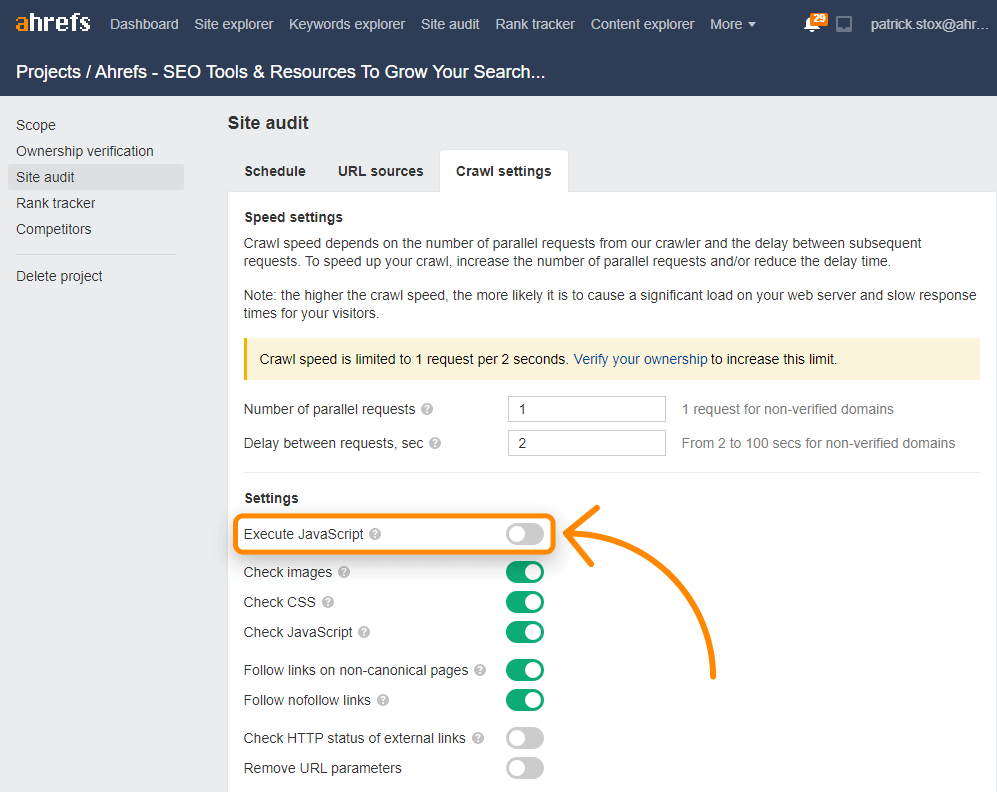
Die Ahrefs Toolbar unterstützt auch JavaScript und ermöglicht es dir, HTML mit gerenderten Versionen von Tags zu vergleichen.

Es gibt viele Optionen, wenn es um die Darstellung von JavaScript geht. Google hat ein solides Diagramm, das ich lediglich zeigen werde. Jede Art von SSR, statisches Rendering, Prerendering-Setup ist für Suchmaschinen in Ordnung. Das Hauptproblem ist das vollständige Client-seitige Rendering, bei dem das gesamte Rendering im Browser stattfindet.
Während Google wahrscheinlich sogar mit der clientseitigen Darstellung zufrieden wäre, ist es am besten, eine andere Darstellungsoption zu wählen, um auch andere Suchmaschinen zu unterstützen. Bing bietet auch Unterstützung für JavaScript-Rendering, aber der Umfang ist unbekannt. Yandex und Baidu haben nach dem, was ich bisher gesehen habe, nur begrenzte Unterstützung, und viele andere Suchmaschinen haben wenig bis gar keine Unterstützung für JavaScript.

Es gibt auch die Option des Dynamic Rendering, welches das Rendering für bestimmte Benutzer-Agenten ist. Dies ist im Grunde ein Workaround, kann aber nützlich sein, um für bestimmte Bots wie Suchmaschinen oder sogar Social-Media-Bots zu rendern. Social-Media-Bots führen kein JavaScript aus, daher werden Dinge wie OG-Tags nur dann angezeigt, wenn Sie den Inhalt rendern, bevor Sie ihn ihnen bereitstellen.
Falls du das alte AJAX-Crawling-Schema verwendet hast, beachte, dass dieses veraltet ist und möglicherweise nicht mehr unterstützt wird.
Viele der Prozesse ähneln den Dingen, die SEOs bereits gewohnt sind, aber es könnte leichte Unterschiede geben.
On-Page SEO
Alle normalen On-Page-SEO-Regeln für Inhalte, Titel-Tags, Meta-Beschreibungen, Alt-Attribute, Meta-Robots-Tags usw. gelten weiterhin. Siehe On-Page-SEO: Ein praktikabler Leitfaden.
Ein paar Probleme, die ich bei der Arbeit mit JavaScript-Websites immer wieder sehe, sind, dass Titel und Beschreibungen wiederverwendet werden und selten Alt-Attribute auf Bildern gesetzt werden.
Crawling zulassen
Blockiere nicht den Zugang zu Ressourcen. Google muss in der Lage sein, auf Ressourcen zuzugreifen und diese herunterzuladen, damit die Seiten korrekt dargestellt werden können. In deiner robots.txt, ist der einfachste Weg zu erlauben, die benötigten Ressourcen zu crawlen, in dem zu folgendes hinzufügst:
User-Agent: Googlebot Allow: .js Allow: .css
URLs
URLs bei der Aktualisierung von Inhalten ändern. Ich habe bereits die History-API erwähnt, aber du solltest wissen, dass die JavaScript-Frameworks einen Router haben, mit dem du auf saubere URLs mappen kannst. Du möchten keine Hashes (#) für das Routing verwenden. Dies ist insbesondere ein Problem für Vue und einige der früheren Versionen von Angular. Bei einer URL wie abc.com/#something wird also alles nach einem # in der Regel von einem Server ignoriert. Um dieses Problem für Vue zu beheben, kannst du mit deinem Entwickler zusammenarbeiten, um Folgendes zu ändern:
Vue router:
Use ‘History’ Mode instead of the traditional ‘Hash’ Mode.
const router = new VueRouter ({
mode: ‘history’,
router: [] //the array of router links
)}
Doppelter Inhalt
Mit JavaScript kann es mehrere URLs für den gleichen Inhalt geben, was zu Problemen mit doppelten Inhalten führt. Dies kann durch Großschreibung, IDs, Parameter mit IDs usw. verursacht werden. Diese URLs können also alle existieren:
domain.com/Abc
domain.com/abc
domain.com/123
domain.com/?id=123
Die Lösung ist einfach. Wähle eine Version, die indiziert werden soll, und setze kanonische Tags.
SEO-„Plugin“-Optionen
Bei JavaScript-Frameworks werden diese üblicherweise als Module bezeichnet. Du findest Versionen für viele der populären Frameworks wie React, Vue und Angular, indem du nach dem Framework + Modulnamen wie “React Helmet” suchst. Meta-Tags, Helm und Kopf sind allesamt beliebte Module mit ähnlicher Funktionalität, die es die Möglichkeit bieten, viele der beliebten Tags zu setzen, die für SEO benötigt werden.
Fehlerseiten
Da JavaScript-Frameworks nicht server-seitig sind, können sie nicht wirklich einen Serverfehler wie einen 404 auslösen. Du hast eine Reihe verschiedener Optionen Fehlerseiten zu erstellen:
- Verwende eine JavaScript-Umleitung zu einer Seite, die mit einem 404-Statuscode antwortet
- Füge einen noindex-Tag zu der Seite hinzu, die fehlgeschlagen ist, zusammen mit einer Art Fehlermeldung wie „404 Page Not Found“. Dies wird wie eine weiche 404 behandelt, da der tatsächlich zurückgegebene Statuscode ein Okay mit 200 ist.
Sitemap
JavaScript-Frameworks haben in der Regel Router, die auf saubere URLs abbilden. Diese Router verfügen in der Regel über ein Zusatzmodul, das auch Sitemaps erstellen kann. Du kannst sie finden, indem du nach deinem System + Router-Sitemap suchst, z.B. „Vue router sitemap“. Viele der Rendering-Lösungen verfügen möglicherweise auch über Sitemap-Optionen. Auch hier gilt: Finde einfach das von dir verwendete System und google nach dem System + Sitemap, z. B. „Gatsby-Sitemap“, und du wirst sicher eine Lösung finden, die bereits existiert.
Redirects
SEOs sind an 301/302-Weiterleitungen gewöhnt, welche serverseitig sind. Javascript wird jedoch typischerweise clientseitig ausgeführt. Dies ist in Ordnung, da Google die Seite wie nach der Weiterleitung verarbeitet. Die Weiterleitungen geben weiterhin alle Signale wie PageRank weiter. Du kannst diese Weiterleitungen normalerweise im Code finden, indem du nach “window.location.href” suchst.
Internationalisierung
Es gibt in der Regel einige wenige Moduloptionen für verschiedene Frameworks, die einige für die Internationalisierung erforderliche Funktionen wie hreflang unterstützen. Sie wurden auf die verschiedenen Systeme portiert und umfassen i18n, intl. In vielen Fällen können dieselben Module, die für Header-Tags wie Helmet verwendet werden, verwendet werden, um benötigte Tags hinzuzufügen.
Lazy Loading
Es gibt in der Regel Module für die Handhabung von Lazy Loading. Falls du es noch nicht bemerkt hast, es gibt Module für so ziemlich alles, was du bei der Arbeit mit JavaScript-Frameworks tun musst. Lazy und Suspense sind die beliebtesten Module für Lazy Loading. Du wirst Bilder „lazy“ laden wollen, aber sei vorsichtig, dass du keine Inhalte „lazy“ lädst. Dies kann mit JavaScript erreicht werden, aber es könnte bedeuten, dass der Inhalt von Suchmaschinen nicht korrekt erfasst wird.
Abschließende Gedanken
JavaScript ist ein Werkzeug, das mit Bedacht eingesetzt werden sollte, nicht aber etwas, wovor sich SEOs sich fürchten müssen. Hoffentlich hat dir dieser Artikel geholfen, besser zu verstehen, wie du damit besser umgehen kannst, aber scheue dich nicht, dich an deine Entwickler zu wenden und mit ihnen zusammenzuarbeiten und ihnen Fragen zu stellen. Sie werden deine größten Verbündeten sein, wenn es darum geht, deine JavaScript-Website für Suchmaschinen zu verbessern.
Hast du Fragen? Lasse es mich auf Twitter wissen.
Übersetzt von sehrausch.de: Suchmaschinen– & Conversion-Optimierung, Online-Marketing & Paid-Advertising. Passgenau aus einer Hand.


