


Yapay Zekâ Arama Motorları Nasıl Çalışır?

Yazan: Ryan Law
İçerik Pazarlama Direktörü, Ahrefs
ChatGPT’den spor yaparken kullanmak için en iyi kulak üstü kulaklıkları önermesini istediğinizde aslında ne yaşanıyor?
Yapay zekâ arama motorları nasıl yanıtlarını oluşturur ve ürün önerilerini seçer? Google gibi geleneksel arama motorlarından nasıl farklıdırlar (ve ne gibi ortak yanları vardır)?
En önemlisi, sizin web sitenizin, markanızın ve ürünlerinizin görünmesini nasıl sağlayabilirsiniz?
Bu bölümü gözden geçirip katkıda bulundukları için Gianluca Fiorelli ve Mark Williams-Cook’a teşekkürler.
Yapay zekâ arama motorları nelerdir?
Yapay zekâ arama motorları, büyük dil modellerini (LLM’ler) kullanarak bilgileri bulan ve yanıtlar oluşturan soru-cevap sistemleridir.
Geleneksel arama motorları ile yapay zekâ arama motorları arasında bazı temel farklar vardır (ancak geleneksel arama motorları daha fazla yapay zekâ özelliği kazandıkça bu farklar giderek azalmaktadır):
- Kullanıcılar, tek seferlik sorgular girmek yerine takip soruları sorabilir ve sohbeti devam ettirebilirler.
- Yapay zekâ arama motorları, sıralanmış bir bağlantı listesi döndürmek yerine doğrudan yanıtlar ve öneriler sunar (ve bu yanıtlar düzenli olarak değişebilir).
- Arama yapan kişileri web sitenizi ziyaret etmeye yönlendirmek yerine, kullanıcıların sorguları doğrudan sohbet arayüzünde yanıtlanır (bu da web sitenize geri yönlendiren tıklamaların azalmasına yol açar).
ChatGPT, Claude veya AI Mode’da görebileceğinize benzer tipik bir yapay zekâ araması arayüzü şu şekilde görünür:

- Sohbet istemi: Kullanıcının sorusu.
- Temellendirme mesajı: LLM’nin yanıtında kullanmak üzere ek bilgi aramaya karar verdiğini gösteren bir mesaj.
- Yanıt: Kullanıcının istemine karşılık yapay zekâ tarafından oluşturulan cevap.
- Bahsetme: Yanıt metninde satır içinde bahsedilen varlık (markanız veya ürününüz gibi).
- Alıntılar: Yanıt oluşturma sürecinde kullanılan ve genellikle son kısımda listelenen kaynak URL’leri.
Bu tarz yanıtlarda görünmenize yardımcı olmak için ilk olarak yapay zekâ arama motorlarını çalıştıran temel süreçleri anlamanız gerekir.
Eğitim nasıl çalışır?
LLM'ler çok büyük miktarlarda içerikle eğitilir. Pratikte Vikipedi'nin tamamını, Common Crawl veri setinin tamamını, Google Kitaplar'ın tamamını ve web'deki yüz milyonlarca sayfayı "okumuş" gibidirler.
Bu eğitim verileri, LLM’in dünyayı “anlamasına” yardımcı olur. Kulaklık şirketiniz eğitim verilerinde ilgili bağlamlarda ve olumlu nitelemelerle (“fiyat/performans”, “spor salonu için harika” vb.) birlikte birçok kez geçiyorsa kulaklıklarla ilgili istemlere LLM’in verdiği yanıtlarda şirketinizin adının bahsedilme olasılığı yüksektir.
Biliyor muydunuz?
Bu eğitim süreci, burada açıklanandan daha kapsamlıdır. HTML’yi ayıklamak, kişisel olarak tanımlanabilir bilgileri kaldırmak, engellenenler listesindeki sözcüklerini hariç tutmak ve verileri belirli dillere göre filtrelemek için eğitim öncesi aşamalar vardır. Ayrıca dil modelini, kullanışlı bir sohbet asistanı gibi davranacak şekilde (yalnızca bir sonraki belirteci tahmin eden bir sistem gibi değil) eğitmek için eğitim sonrası aşamalar da bulunur. Daha fazla bilgi için Andrej Karpathy’nin ChatGPT gibi LLM’lere Derinlemesine Bakış videosunu izleyin.


İşte bu noktada varlık tabanlı SEO kritik bir hâl alıyor. Markanız Bilgi Grafiklerinde tutarlı biçimde görünüyorsa, şema işaretlemesiyle doğru şekilde yapılandırılmışsa ve web genelinde yüksek kaliteli içeriklerde ilgili varlıklarla birlikte anılıyorsa eğitim verilerinde daha güçlü bir “varlık sinyali” oluşturuyorsunuz demektir.

Gianluca Fiorelli, Stratejik ve Uluslararası SEO/Yapay Zekâ Arama Danışmanı
Daha da önemlisi, LLM’ler pek çok tuhaf özelliğe sahiptir:
- Olasılıksaldırlar: Aynı istemi kullanıp her seferinde farklı yanıtlar alabilirsiniz. Bu olasılıksal yapı, bir anahtar kelimeyi optimize ettiğiniz gibi "bir istemi optimize edemeyeceğiniz" anlamına gelir. Bunun yerine dağılımlar üzerinden düşünün: 100 benzer istemin içinde markanızın görünme olasılığı nedir? Bu yüzden, yalnızca birkaç isteme odaklanmak yerine çok sayıda istemdeki ortalama görünürlüğü takip etmek daha iyidir.
- Bilgi birikimleri eşiklere sahiptir: Varsayılan olarak bir LLM’in bilgi birikimi, ilgili model eğitilirken veri kümesinde yer alanlarla sınırlıdır. Her model, belirli bir tarihe kadarki verilerin bir anlık görüntüsü üzerinde tek seferlik eğitilir. Daha güncel bilgi eşiklerine sahip yeni modeller düzenli olarak (tarihsel olarak yaklaşık her altı ayda bir) yayımlanır.
- Yanıltıcı bilgiler verirler: Doğru olmayan şeyleri büyük bir özgüvenle ifade edebilirler. LLM’ler metinleri gerçek verileri doğrulayarak değil, bir sonraki kelimelerin hangilerinin gelmesinin muhtemel olduğunu tahmin ederek üretir. Yardımcı ve doğru olmaları için eğitilmiş olsalar da yerleşik bir doğruluk kontrolü mekanizmasına sahip değildirler; bu yüzden web aramasıyla temellendirme son derece önemlidir.
LLM’lerin yazılım yamaları gibi “bilgi güncellemeleri” aldığı yaygın olarak bilinen yanlış bir kanıdır. Gerçekte her model, sabit bir veri kümesiyle bir defa eğitilir. Daha güncel bir bilgi eşiğine sahip yeni bir model sürümü gördüğünüzde bu, mevcut modele yapılan bir güncelleme değil, sıfırdan eğitilmiş tamamen yeni bir modeldir.
Gianluca Fiorelli, Stratejik ve Uluslararası SEO/Yapay Zekâ Arama Danışmanı
Yanıltıcı bilgiler üreten ve eski bilgileri paylaşan bir arama motoru pek kullanışlı değildir. Bu nedenle LLM’ler, temellendirme olarak bilinen bir süreçle bu sınırlamaların bir kısmını aşar.
Temellendirme ve RAG nasıl çalışır?
LLM'ler yanıtlarını iki şekilde doğrulayabilir ve iyileştirebilir: araçları (hesaplayıcılar veya diğer veri API'leri gibi) kullanarak veya haricî kaynaklardan ek bilgiler alarak. Bu ikinci süreç, teknik olarak Almayla Artırılmış Üretim (RAG) olarak bilinir.
Bir kullanıcı bir soru girdiğinde LLM, kendi kendine şunu sorar: “Yanıtı zaten biliyor muyum yoksa ek bilgiler bulmam gerekiyor mu?” LLM bir sonraki belirteci yüksek bir kesinlikle tahmin edebiliyorsa (örneğin “Kırmızı kan hücreleri ne işe yarar?” gibi cevabı pek değişmeyen sorularda) büyük olasılıkla temel bilgi birikimiyle yanıt verir. Bilginin kesinliği düşükse (örneğin “En iyi bütçe dostu kahve öğütücüsü hangisidir?” gibi cevabı değişken olan sorularda) internetteki diğer kaynaklardan ilgili bilgileri bulmak için arama aracını kullanabilir.
LLM’ler, aşağıdaki gibi ek bilgilerden fayda sağlayabilecek sorgu türlerini tanıyacak şekilde ayarlanmıştır:
- Modellerin eğitim kapsamı dışındaki konular: “Ahrefs Keywords Explorer tarafından kullanılan dâhilî sıralama faktörleri nelerdir?”
- Güncel veya zamana duyarlı bilgi gerektiren konular: “Google’ın en son temel güncellemesi neydi ve ne zaman yayımlandı?”
- Açık bir şekilde web araması isteyen konular: “2026’daki popüler bağlantı oluşturma taktikleri için internette arama yap.”
- Kaynak ve kanıt isteyen istemler: “Google’ın algoritmasında kullanıcı etkileşimi sinyallerini kullandığını doğrulayan kaynaklar sağla.”
Bazı LLM modelleri ek aramaları tetiklemeye de oldukça yatkındır (örneğin “kapsamlı araştırma” modelleri, özellikle birden fazla RAG aramasını tetikleyecek şekilde yapılandırılmıştır).
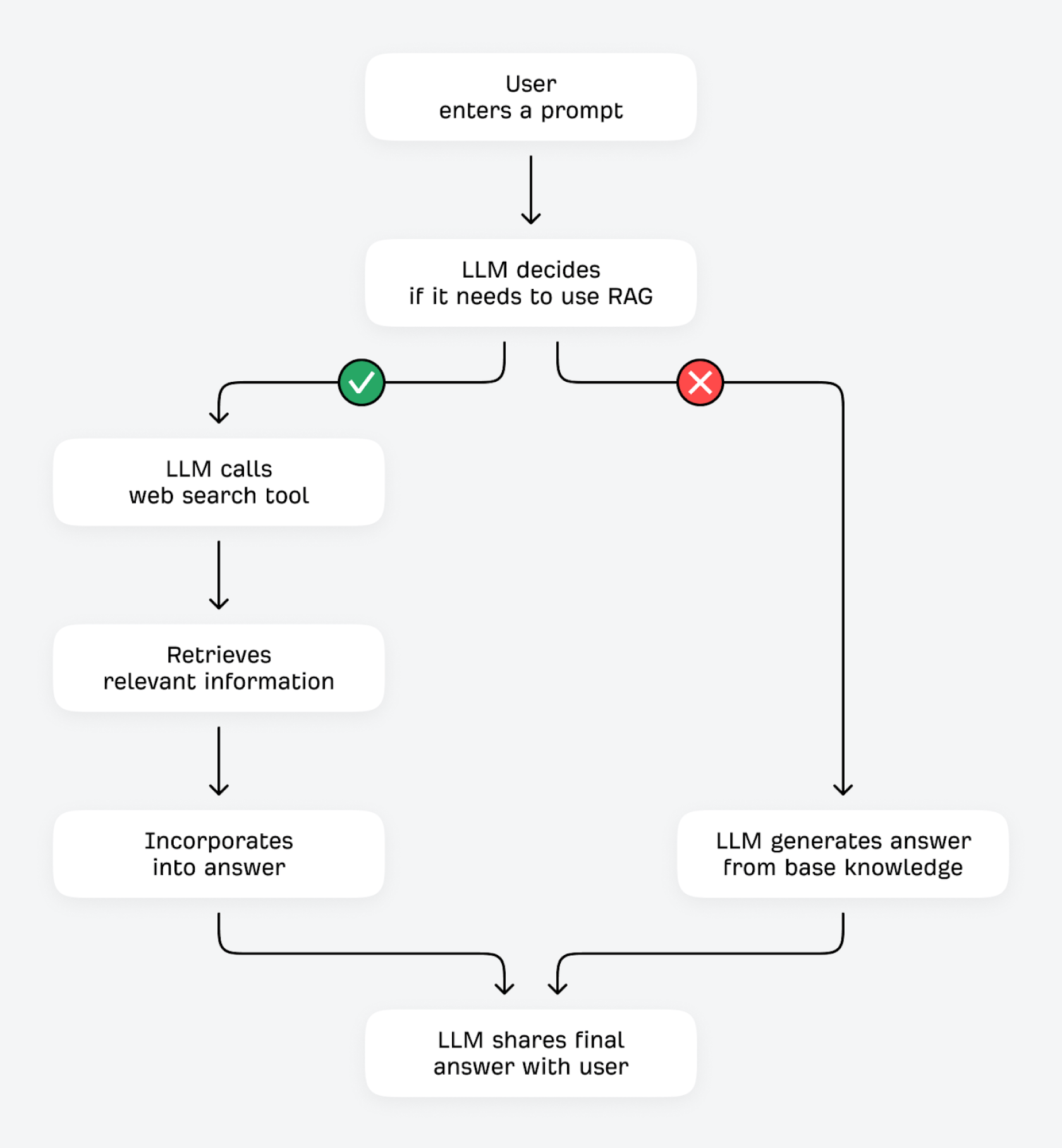
RAG aracılığıyla gerçek bilgileri bulma süreci (genellikle "temellendirme" olarak adlandırılır) çeşitli avantajlar sunar. LLM, yanıtlarını üçüncü taraf kaynaklara karşı kontrol ederek olgusal doğruluğu artırabilir ve yanıltıcı bilgileri azaltabilir. Eğitim verileri nispeten güncelliğini yitirmiş olsa bile güncel bilgileri bulup paylaşabilir. Paylaştığı her şey için daha ayrıntılı ve kapsamlı yanıtlar sunabilir ve daha iyi şeffaflık ile kaynak gösterimi sağlayabilir.
Yapay zekâ arama motorları bu temellendirme işlemini, sorgu yayılması olarak bilinen bir süreçle gerçekleştirir.
Sorgu yayılması nasıl çalışır?
Daha da önemli olarak sorgu yayılması, geleneksel SEO'nun yapay zekâ görünürlüğü açısından neden bu kadar önemli olduğunu açıklar.
ChatGPT, Gemini ve Perplexity gibi yapay zekâ asistanları, güncel bilgileri almak için Google, Bing ve Brave gibi arama dizinlerini kullanır.
Arama sağlayıcılarının her biri farklı sıralama algoritmaları, dizinleri ve kapsamına sahip olduğundan önemlidir: Markanızı Google Araması'nda görünür kılmak, Bing'e daha çok bağımlı olan ChatGPT'ye kıyasla AI Mode'daki görünürlüğünüzü artırabilir.
| Yapay zekâ arama motoru | Temellendirme için kullanılan arama dizinleri |
|---|---|
ChatGPT | Bing, Google |
Claude | Brave |
Gemini | Google |
Copilot | Bing |
Perplexity | In-house |
AI Mode | Google |
AI Overviews | Google |
Bir web araması tetiklendiğinde LLM, arama dizininden ilgili sonuçları ister. Arama dizini bir sonuç listesi döndürür ve LLM; sayfa başlığı, döndürülen sayfa parçacığının içerikleri ve güncelliği (ne kadar yakın zamanda yayımlandığı) gibi bilgileri değerlendirerek taranacak en ilgili sayfaları seçer.
SEO, yapay zekâ araması açısından neden son derece önemlidir?
Bunu tekrar söylemekte fayda var: Google ve Bing gibi geleneksel arama motorları, yapay zekâ arama motorlarının yanıtlarında hangi içerikten bahsedeceklerine ve hangisini alıntılayacaklarına karar vermelerine yardımcı olmada kritik bir rol oynamaktadır.
Başka bir deyişle geleneksel aramada üst sıralarda yer almak, yapay zekâ aramasındaki görünürlüğünüzü artıracaktır.
Peki LLM tam olarak neyi arar?
LLM’ler sorgu yayılımı adı verilen bir süreç kullanır. ChatGPT’ye ve diğer yapay zekâ arama motorlarına girilen pek çok istem son derece uzun, sohbet havasında ve çoğu zaman tamamen benzersizdir. Bu istemlerin birebir aynısını Google’da aratmak, karşınıza her zaman işe yarar içerikler çıkarmaz.
Yani kullanıcının sorgusunu bire bir alıp bir web araması gerçekleştirmek yerine…
"E-ticaret markalarına analiz ürünü satan orta ölçekli bir işletmeler arası SaaS şirketi için 6 aylık bir içerik stratejisi planlıyorum. Şirket…"

…LLM’ler, alakalı bilgileri getirmeye yardımcı olmak için bu ilk istemi kullanarak çeşitli daha kısa ve ilişkili sorgular üretir.
Bu yayılan sorgular da büyük dil modeli tarafından oluşturulur ve bu nedenle determinist değildir: Aynı arama için bile düzenli olarak değişebilirler.

Mark Williams-Cook, Kurucu, AlsoAsked
Bu süreç, SEO uzmanlarına tanıdık gelecektir: Bu ilgili sorgular, uzun kuyruklu anahtar kelimelere, alt niyetlere ve İnsanların Sordukları sorulara oldukça benzerdir:
- Yaygın işletmeler arası SaaS içeriği stratejisi çerçeveleri
- SaaS için TOFU ve BOFU içeriği örnekleri
- İçerik yenileme ve dâhilî bağlantılar için en iyi uygulamalar
- İçerik odaklı demografik büyüme ölçümleri
Hatta ChatGPT, Gemini ve Copilot tarafından alıntılanan bağlantıların yalnızca %12’si, kullanıcının orijinal istemi için Google’ın ilk 10 sonucunda görünmektedir. Ancak bu, geleneksel sıralamanın önemsiz olduğu anlamına gelmez. Yapay zekâ arama motorları, birden çok arama sorgusu oluşturarak içerik getirir ve bu yayılma sorguları çoğu zaman daha geleneksel ve anahtar kelime odaklı aramalardır; bu noktada mevcut SEO çalışmalarınız son derece önemlidir.

Sorgu yayılması özgürlük sağlar: İnsanların hangi sohbet istemlerini kullanacağını tahmin etmenize gerek yoktur. Bunun yerine, LLM'lerin doğal olarak oluşturacağı ayrıştırılmış sorgulara, yani anlamsal bileşenlere göre optimize edin. Bunlar geleneksel anahtar kelime araştırmasına oldukça benzer: [konu] + [belirleyici unsur], karşılaştırma sorguları, tanımsal sorgular ve "en iyi uygulamalar" içerikleri. Mevcut SEO araştırmanız, muhtemelen yayılma alanını zaten kapsıyordur.
Gianluca Fiorelli, Stratejik ve Uluslararası SEO/Yapay Zekâ Arama Danışmanı
Getirme, parçalara ayırma ve yanıt sentezi nasıl çalışır?
Bir LLM, arama dizininden ilgili sayfaları getirdiğinde bu sayfaları baştan sona okumaz. Bunun yerine sayfalar küçük metin “parçalarına” bölünür, model de sorguyla en alakalı görünen metin bölümlerine öncelik verir (ve bazen bu bölümleri genişletir).
Bu parçaların her biri genellikle birkaç yüz ile birkaç bin kelime arasında olur ve bu rakamlar çoğu web sayfasının küçük bir bölümüne denktir. LLM ayrıca, katı bağlam penceresi sınırlarıyla çalışır: Kullanıcının istemi, getirilen tüm parçalar ve kendi yanıtı dâhil olmak üzere sınırlı miktarda metni işleyebilir. Bu da hangi içeriği alıp dâhil edeceği konusunda son derece seçici olması gerektiği anlamına gelir.
İşte bir örnek:
| Tam sayfa içeriği | “Temellendirme, modelin haricî kaynakları getirdiği, ilgili gerçekleri çıkardığı ve yanıltıcı bilgileri azaltıp güncelliği artırmak için bu alıntıları kullandığı bir iş akışıdır. Ardından birden fazla kaynağı tarar, bilgileri karşılaştırır ve metni kelimesi kelimesine kopyalamak yerine bir yanıt sentezler. Bu sentez adımı, herhangi tek bir kaynağa aşırı bağımlılığı önlemeye yardımcı olur.” |
| Parçacık | “Asistanların web aramasını kullanarak haricî kaynakları nasıl getirdiğini ve yanıtları getirilen gerçek verilerle temellendirerek yanıltıcı bilgileri nasıl azalttığını açıklar.” |
| Genişletme (satır 1-2) | “Temellendirme, modelin haricî kaynakları getirdiği, ilgili gerçekleri çıkardığı ve yanıltıcı bilgileri azaltıp güncelliği artırmak için bu alıntıları kullandığı bir iş akışıdır. Model, web araması başlatmadan önce bir sorgunun güncel veya doğrulanabilir bilgiler gerektirip gerektirmediğini değerlendirir.” |
| Genişletme (satır 33-34) | “Ardından birden fazla kaynağı tarar, bilgileri karşılaştırır ve metni kelimesi kelimesine kopyalamak yerine bir yanıt sentezler. Bu sentez adımı, herhangi tek bir kaynağa aşırı bağımlılığı önlemeye yardımcı olur.” |
LLM’lerin içeriğinizi anlamasını kolaylaştırın
Bu konu önemlidir: Yapay zekâ arama motorları içeriğinizi internetten aldığında yalnızca belirli bölümlerini görebilirler, sayfanın tamamını göremezler. LLM’nin yanıtında alıntılanma olasılığını en üst düzeye çıkarmak için sayfanızın alaka düzeyi ve değeri, sayfanın tamamına erişim olmadan bile LLM’ler tarafından kolayca anlaşılabilir olmalıdır.
Yapay zekâ arama motoru, daha sonra bu metni yanıt oluşturma sürecine entegre eder.
Ham web içeriği, modelin yanıtına temellendirilir: Bir önceki adımda çıkarılan metin veya veri parçacıkları modelin bağlamına eklenir. Bu da özünde şu anlama gelir: “İşte web'den toplanan işe yarayabilecek bazı bağlam bilgileri, şimdi bu bilgileri kullanarak kullanıcının sorusunu yanıtla.”
Alıntılar nasıl seçilir?
Bu noktadan itibaren model, kendi içsel bilgisiyle getirilen içeriği birleştirerek bir yanıt oluşturur ve bunu kullanıcıyla paylaşır. Yanıt genellikle alıntılar, yani temellendirme sürecinde kullanılan kaynaklara bağlantı veren tıklanabilir URL’ler içerir.
Yapay zekâ arama motorunun getirdiği her sayfa, nihai yanıtta bir alıntı almaz. Model, hangi kaynakları alıntı yapacağını birkaç etmene göre seçer:
- Alaka düzeyi: Getirilen içeriğin yanıttaki belirli iddialara doğrudan katkı sağlama düzeyi.
- Güncellik: Kaynağın ne kadar yeni göründüğü.
- Çeşitlilik: Alıntı kaynaklarının çeşitliliği (yapay zekâ arama motorları, aynı kaynağı tekrar tekrar alıntılamak yerine genellikle birden fazla farklı kaynağı alıntılamayı tercih eder).
Bu, içeriğiniz alınıp okunsa bile görünür bir alıntı almanın garanti olmadığı anlamına gelir. İçeriğin, belirli bir iddiayla doğrudan ilgili olduğu değerlendirilmelidir.
Kişiselleştirme nasıl çalışır?
Bu, yapay zekâ arama motorlarının çalışma biçiminin temelidir ancak ekstra bir karmaşıklık düzeyi daha var: kişiselleştirme.
ChatGPT ve diğer yapay zekâ arama motorları, sonuçlarını kullanıcılara göre kişiselleştirebilir; yani aynı istem, farklı kişiler için farklı sonuçlar üretebilir. Kişiselleştirme, aşağıdakiler dâhil olmak üzere çeşitli şekillerde etkilenebilir:
- Mevcut sohbet bağlamı: Aynı sohbetteki önceki mesajlar, mevcut i̇steme verilecek yanıtı etkiler. Doğa yürüyüşü ekipmanınızda "dayanıklılığa" önem verdiğinizi belirtirseniz sohbetin ilerleyen kısmında "sırt çantası önerileri" istediğinizde ChatGPT'nin aramasına bu kriteri de dâhil etmesini bekleyebilirsiniz.
- Bellek: Birçok LLM’de, sistemin sohbetler arasında bazı gerçek verileri veya tercihleri korumasını sağlayan bir bellek özelliği vardır. Örneğin bellek etkinken ChatGPT, paylaştığınız ayrıntıları (adınız veya ilgi alanlarınız gibi) çıkarım yoluyla edinip hatırlar ve yanıtlarını kişiselleştirmek için bunları gelecekteki konuşmalarda kullanır.
- Konum, saat, tarih: Birçok yapay zekâ arama motoru, IP adresinizi yaklaşık konum için kullanmaktan ("yakınımdaki kahvaltı yerleri" gibi sorgular için) tarih ve saate ("kamp için hazırlık listesi", kışın 4 mevsimlik ve yazın 3 mevsimlik bir çadır önerebilir) kadar sizinle ilgili bilgileri çıkarım yoluyla elde edebilir ve yanıtlarını buna göre uyarlayabilir.
- Sistem istemleri: Sistem mesajında paylaşılan belirli tercihler konuşmalarınızı etkiler (sistem istemine “Unutma, veganım” bilgisini eklemek, “sağlıklı kahvaltılık fikirleri” gibi istemlere verilen yanıtları etkiler).
Sistem istemlerini anlamak için şöyle bir benzetme yapabiliriz: Diyelim ki futbol oynuyorsunuz, bu durumda "eğitim verileri", yıllar boyunca yaptığınız tüm antrenmanlar, yani uzun vadeli kas hafızasıdır. Sistem istemi ise sahaya çıkmadan önce teknik direktörünüzün size söyledikleridir. Sonucu etkileme olasılığı daha yüksek olan, güçlü ve kısa vadeli bir hafızadır.
Mark Williams-Cook, Kurucu, AlsoAsked

Bu nedenle tek bir istem yanıtına odaklanmak yerine, markanızın ve web sitenizin ortalama görünürlüğünü zaman içinde ve birçok istem genelinde izlemek daha iyi bir fikirdir.
Son görüşler
Her yapay zekâ arama motoru (ChatGPT’den Perplexity ve Google AI Mode’a kadar) biraz farklıdır ancak temel süreçler aynıdır. SEO uzmanları ve pazarlamacılar için önemli olan, Google ve Bing gibi geleneksel arama motorlarının yapay zekâ arama motorlarının çalışması için gereken altyapının büyük bir kısmını sağlıyor olmasıdır. Yapay zekâ araması optimizasyonu, büyük ölçüde geleneksel SEO açısından en iyi uygulamalara dayanır.
Daha fazla yazı
Ryan Law, Ahrefs'te İçerik Pazarlama Direktörü olarak görev yapmaktadır. Ryan'ın yazar, içerik stratejisi uzmanı, ekip lideri, pazarlama direktörü, VP, CMO ve ajans kurucusu olarak 13 yıllık deneyimi vardır. Google, Zapier, GoDaddy, Clearbit ve Algolia dâhil olmak üzere onlarca şirketin içerik pazarlaması ve SEO'sunu geliştirmesine yardımcı olmuştur. Aynı zamanda roman yazarı ve iki içerik pazarlama kursunun da yaratıcısıdır.
SEO'da Adım Adım Ustalaşın
Arama Motorları Nasıl Çalışır?
SEO öğrenmeye başlamadan önce arama motorlarının nasıl çalıştığını anlamanız gerekir.
SEO ile İlgili Temel Bilgiler
Web sitenizde nasıl SEO başarısı elde edeceğinizi ve SEO'nun dört ana yönünü öğrenin.
Anahtar Kelime Araştırması
SEO'nun başlangıç noktası, hedef müşterilerin ne arattığını anlamaktır.
SEO İçeriği
Arama motorlarında üst sıralarda yer alan içeriği nasıl oluşturacağınızı öğrenin.
Sayfa İçi SEO
Böylece arama motorlarının onları anlamasına yardımcı olmak için sayfalarınızı optimize edersiniz.
Bağlantı Oluşturma
Arama motorlarında üst sıralarda yer alan içeriği nasıl oluşturacağınızı öğrenin.
Teknik SEO
Google'ın web sitenize erişmesini ve sitenizi anlamasını engelleyen teknik sorunları önleyin.
Yerel SEO
Yerel arama sonuçlarında görünürlüğünüzü nasıl artıracağınızı öğrenin ve bölgenizden daha fazla müşteri kazanın.
Yapay Zekâ'nın SEO İçin Anlamı
Bugün üretken yapay zekâdan bahsetmeden SEO hakkında konuşamazsınız.
Yapay Zekâ Arama Motorları Nasıl Çalışır?
ChatGPT gibi yapay zekâ arama motorlarının yanıtlarını tam olarak nasıl oluşturduğunu ve bahsedeceği markalar ile ürünleri nasıl seçtiğini öğrenin.