


Jak działają wyszukiwarki AI?

Autor: Ryan Law
Dyrektor ds. marketingu treści w Ahrefs
Co tak naprawdę dzieje się, gdy wpisujesz na platformie ChatGPT prośbę o polecenie najlepszych słuchawek nausznych do treningu?
W jaki sposób wyszukiwarki AI generują odpowiedzi i dobierają swoje rekomendacje produktów? Czym różnią się od tradycyjnych wyszukiwarek, takich jak Google (i co je z nimi łączy)?
A co najważniejsze: jak sprawić, by Twoja strona, marka i produkty pojawiały się w generowanych odpowiedziach?
Za korektę i wkład w niniejszy rozdział dziękuję ekspertom ds. SEO: Gianluca Fiorelli i Mark Williams-Cook.
Czym są wyszukiwarki AI?
Wyszukiwarki AI to systemy umożliwiające zadawanie pytań i uzyskiwanie odpowiedzi, bazujące na dużych modelach językowych (LLM) w celu wyszukiwania informacji i generowania odpowiedzi.
Istnieje kilka kluczowych różnic pomiędzy tradycyjnymi wyszukiwarkami a wyszukiwarkami AI (choć różnice te coraz bardziej się zacierają, ponieważ tradycyjne wyszukiwarki wdrażają coraz więcej funkcji AI):
- Zamiast wpisywać jednorazowe zapytania, użytkownicy mogą zadawać pytania uzupełniające i w ten sposób podtrzymywać rozmowę.
- Zamiast zwracać listę linków uszeregowaną zgodnie z pozycjonowaniem stron, wyszukiwarki AI dostarczają bezpośrednie odpowiedzi i rekomendacje (przy czym odpowiedzi te mogą się regularnie zmieniać).
- Zamiast kierować wyszukujących do odwiedzenia Twojej witryny, użytkownicy otrzymują odpowiedzi na swoje zapytania bezpośrednio w interfejsie czatu (co skutkuje mniejszą liczbą kliknięć prowadzących do Twojej witryny).
Oto jak wygląda typowy interfejs wyszukiwania AI — podobny do tego, z jakim można się zetknąć na platformach ChatGPT, Claude lub w Trybie AI:

- Prompt konwersacyjny: pytanie użytkownika.
- Komunikat o groundingu: komunikat pokazujący, że model językowy zdecydował się wyszukać dodatkowe informacje, aby wykorzystać je w swojej odpowiedzi.
- Odpowiedź: wygenerowana przez AI odpowiedź na prompt użytkownika.
- Wzmianka: jednostka (np. Twoja marka lub produkt) wspomniana w treści odpowiedzi.
- Cytowania: adresy URL źródeł wykorzystanych przy generowaniu odpowiedzi, zwykle wymienione na końcu.
Jeśli chcesz, aby Twoja marka pojawiała się w takich odpowiedziach, najpierw musisz zrozumieć kluczowe procesy stojące za wyszukiwaniem AI.
Na czym polega trenowanie?
Duże modele językowe są trenowane na ogromnych ilościach treści. W praktyce „przeczytały” całą Wikipedię, całą bazę Common Crawl, wszystkie książki w Google Books oraz treści zamieszczone na milionach stron internetowych.
Te dane treningowe kształtują sposób, w jaki LLM „interpretuje” świat. Jeśli Twoja firma produkująca słuchawki wielokrotnie pojawia się w danych treningowych, w odpowiednich kontekstach i w zestawieniu z pozytywnymi określeniami („najlepszy stosunek jakości do ceny”, „doskonałe na siłownię” itd.), jest duża szansa, że zostanie ona wspomniana w odpowiedziach LLM na prompty dotyczące słuchawek.
Czy wiesz, że…
Proces trenowania jest oczywiście bardziej złożony, niż tu opisano. Istnieją etapy trenowania wstępnego, podczas których usuwa się kod HTML, dane osobowe umożliwiające identyfikację, słowa z listy blokowanych, a także filtruje się dane pod kątem konkretnych języków. Są też etapy trenowania wtórnego, mające na celu wytrenowanie modelu językowego tak, by zachowywał się niczym pomocny asystent na czacie (a nie jak mechanizm przewidujący kolejny token). Aby dowiedzieć się więcej, obejrzyj film Andreja Karpathy’ego Deep Dive into LLMs like ChatGPT.


Właśnie dlatego kluczowe staje się SEO oparte na encjach. Jeśli Twoja marka konsekwentnie pojawia się w grafach wiedzy, jest poprawnie ustrukturyzowana za pomocą znaczników schematu oraz współwystępuje z powiązanymi encjami w wysokiej jakości treściach w całej sieci, budujesz silniejszy „sygnał encji” w danych treningowych.

Gianluca Fiorelli, konsultant ds. strategicznego i międzynarodowego SEO oraz wyszukiwania AI
Warto pamiętać, że LLM-y mają wiele swoje dziwactwa:
- Są oparte na rachunku prawdopodobieństwa: Możesz użyć tego samego promptu i za każdym razem uzyskać inną odpowiedź. Ta probabilistyczna natura oznacza, że niemożliwa jest „optymalizacja pod prompt” tak, jak optymalizuje się pod słowo kluczowe. Zamiast tego należy myśleć rozkładami: jakie jest prawdopodobieństwo, że Twoja marka pojawi się w 100 podobnych promptach? Dlatego śledzenie średniej widoczności w wielu promptach jest lepsze niż skupianie się na kilku.
- Ich wiedza ma swój punkt odcięcia w czasie: Domyślnie wiedza, jaką dysponuje LLM, jest ograniczona do tego, co znajdowało się w zbiorze danych w momencie jego trenowania. Każdy model jest trenowany jednokrotnie na „migawce” danych obejmującej określony moment w czasie. Nowe modele z bardziej aktualnym zakresem wiedzy są wypuszczane okresowo (historycznie mniej więcej co sześć miesięcy).
- Mają skłonność do halucynacji: Potrafią z pełnym przekonaniem stwierdzać rzeczy, które nie są prawdziwe. LLM-y generują tekst, przewidując, jakie słowa najprawdopodobniej pojawią się dalej, a nie poprzez weryfikację faktów. Choć są trenowane w taki sposób, aby być użyteczne i dokładne, nie mają wbudowanego mechanizmu sprawdzania faktów — dlatego tak ważne jest, aby odpowiedzi te były osadzone w źródłach poprzez wyszukiwanie w sieci.
Częstym nieporozumieniem jest przekonanie, że LLM-y dostają „aktualizacje wiedzy” niczym poprawki oprogramowania. W rzeczywistości każdy model jest trenowany raz na stałym zbiorze danych. Gdy widzisz premierę nowego modelu z późniejszym punktem odcięcia wiedzy, to jest to zupełnie nowy model wytrenowany od zera, a nie aktualizacja istniejącego.
Gianluca Fiorelli, konsultant ds. strategicznego i międzynarodowego SEO oraz wyszukiwania AI
Wyszukiwarka, która halucynuje i podaje nieaktualne informacje, nie będzie zbyt użyteczna. Dlatego LLM-y przezwyciężają niektóre z tych ograniczeń dzięki procesowi zwanemu „groundingiem”, czyli osadzeniem w źródłach.
Na czym polega grounding i generowanie wspomagane wyszukiwaniem (RAG)?
Modele LLM mogą weryfikować i ulepszać swoje odpowiedzi na dwa sposoby: korzystając z narzędzi (np. kalkulatorów lub innych interfejsów API danych) albo pobierając dodatkowe informacje ze źródeł zewnętrznych. Ten drugi proces jest określany jako „generowanie wspomagane wyszukiwaniem” (RAG).
Gdy użytkownik zadaje pytanie, LLM pyta sam siebie: „Czy znam odpowiedź, czy też powinienem pobrać dodatkowe informacje?”. Jeśli LLM potrafi z dużą pewnością przewidzieć następny token (np. przy pytaniach, które rzadko ulegają zmianie, typu: „Jaką funkcję pełnią czerwone krwinki?”), najprawdopodobniej odpowie na podstawie swojej wiedzy bazowej. Przy niskiej pewności (w przypadku pytań bardziej podatnych na zmiany, jak np. „Jaki jest najlepszy budżetowy młynek do kawy?”) może użyć narzędzia wyszukiwania, aby znaleźć istotne informacje z innych źródeł w internecie.
Duże modele językowe są dostrajane tak, aby rozpoznawać typy zapytań, które mogą zyskać na dodatkowych informacjach, takie jak:
- Tematy wykraczające poza zakres treningowy modelu: „Jakie są wewnętrzne czynniki rankingowe stosowane przez narzędzie Keywords Explorer firmy Ahrefs?”
- Tematy wymagające aktualnych informacji lub danych uzależnionych od czasu: „Jaka była ostatnia aktualizacja główna Google i kiedy została wdrożona?”
- Prompty, które wprost proszą o wyszukiwanie w sieci: „Przeszukaj internet w poszukiwaniu popularnych strategii budowania linków w 2026 roku.”
- Prompty z prośbą o podanie źródła i dowodów: „Podaj źródła potwierdzające, że algorytm Google wykorzystuje sygnały zaangażowania użytkowników.”
Niektóre modele LLM wykazują również wysoką skłonność do uruchamiania dodatkowych wyszukiwań (na przykład modele „deep research” są specjalnie skonfigurowane, by wykonywać wielokrotne wyszukiwania w trybie RAG).
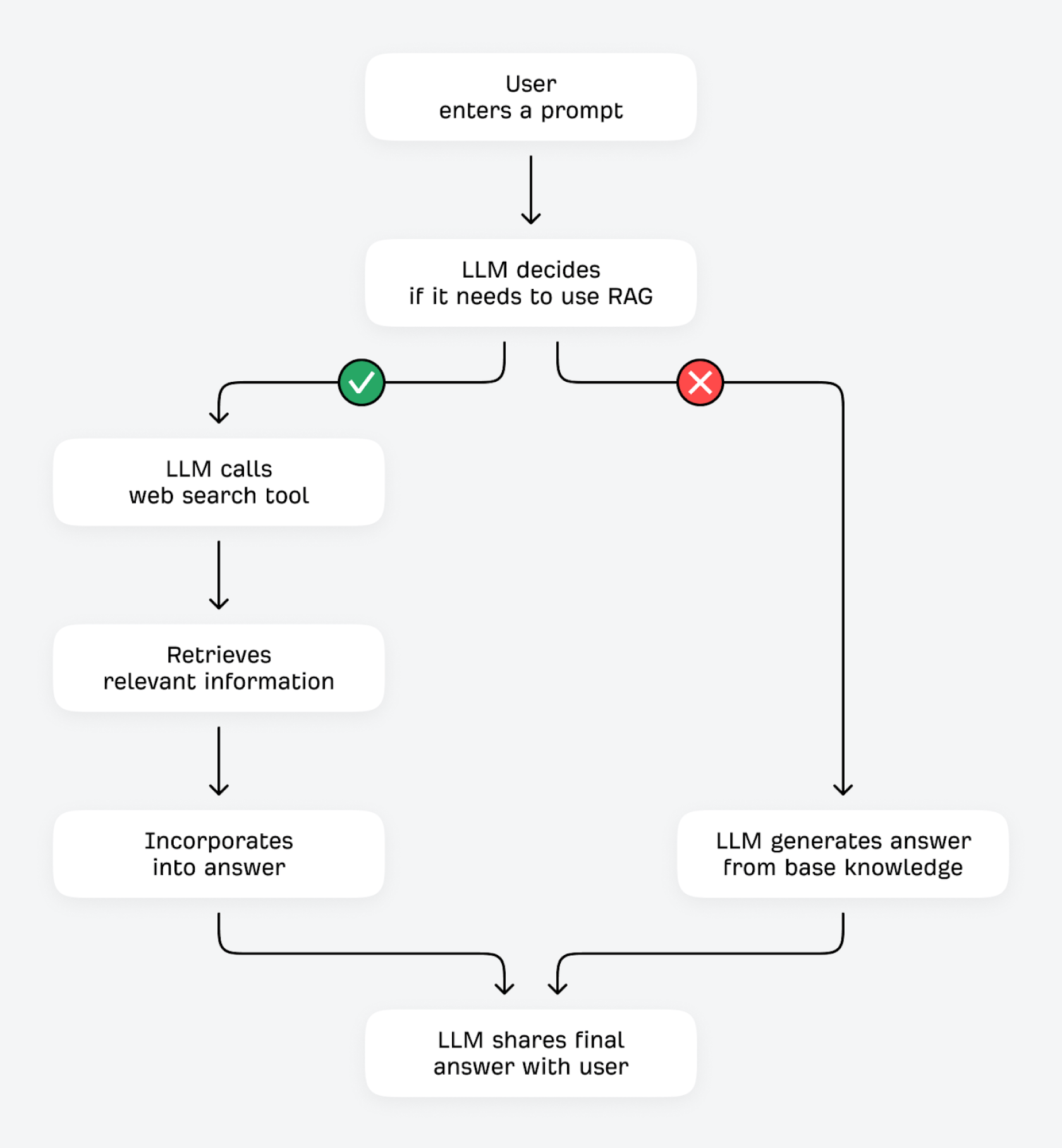
Proces odnajdywania informacji opartych na źródłach poprzez RAG (nazywany „groundingiem”) oferuje kilka korzyści. Weryfikując swoje odpowiedzi względem źródeł zewnętrznych, LLM może poprawić dokładność merytoryczną i ograniczyć halucynacje. Może pobierać i udostępniać aktualne informacje, nawet jeśli jego dane treningowe są już relatywnie nieaktualne. Może też generować bardziej szczegółowe, kompleksowe odpowiedzi oraz zapewniać lepszą przejrzystość i możliwość wskazania źródeł.
Wyszukiwarki AI zapewniają osadzenie w źródłach poprzez proces znany jako „query fan-out” (rozbicie zapytań).
Na czym polega „query fan-out”?
Co istotne, mechanizm „query fan-out” pokazuje, dlaczego tradycyjne SEO jest kluczowe dla widoczności w AI.
Aby pozyskiwać aktualne informacje, asystenci AI – np. ChatGPT, Gemini czy Perplexity – korzystają z indeksów wyszukiwarek, takich jak Google, Bing i Brave.
Wybór wyszukiwarki ma znaczenie, ponieważ każda korzysta z innych algorytmów rankingowych, indeksów i zasięgu. Z tego względu zadbanie o widoczność Twojej marki w wyszukiwarce Google może mieć większy wpływ na jej widoczność w Trybie AI udostępnianym przez Google niż w modelu ChatGPT, który w znacznie większym stopniu opiera się na silniku Bing.
| Wyszukiwarka AI | Indeksy wyszukiwania używane w procesie groundingu |
|---|---|
ChatGPT | Bing, Google |
Claude | Brave |
Gemini | Google |
Copilot | Bing |
Perplexity | In-house |
AI Mode | Google |
AI Overviews | Google |
Gdy uruchamiane jest wyszukiwanie w sieci, LLM pobiera odpowiednie wyniki ze swojego indeksu wyszukiwania. Indeks wyszukiwania zwraca listę wyników, a LLM wybiera najbardziej trafne strony do zindeksowania, oceniając m.in. tytuł strony, zawartość zwróconego fragmentu oraz jej aktualność (czyli jak dawno została opublikowana).
Dlaczego SEO jest kluczowe dla wyszukiwania AI
Warto to powtórzyć: tradycyjne wyszukiwarki, takie jak Google i Bing, odgrywają kluczową rolę w tym, które treści zostaną uwzględnione we wzmiankach i cytowaniach w odpowiedziach na wyszukiwania AI.
Innymi słowy: wysokie pozycjonowanie w tradycyjnym wyszukiwaniu zwiększy Twoją widoczność w wyszukiwaniu AI.
Ale czego dokładnie szuka LLM?
LLM-y korzystają z procesu znanego jako „query fan-out” (rozbicie zapytań). Wiele promptów wpisywanych na platformie ChatGPT i w innych wyszukiwarkach AI jest bardzo długich, ma konwersacyjny charakter i są całkowicie niepowtarzalne. Wyszukiwanie w Google tych konkretnych promptów nie zawsze zwróci przydatne treści.
Dlatego zamiast wykonywać wyszukiwanie w sieci z użyciem dokładnie tego samego zapytania użytkownika…
„Opracowuję 6-miesięczną strategię dotyczącą treści dla średniej wielkości firmy B2B SaaS, która sprzedaje markom e-commerce produkt z zakresu analityki. Firma…”

…LLM-y wykorzystują ten początkowy prompt, aby wygenerować serię krótszych, powiązanych zapytań, dzięki którym uzyskanie trafnych informacji będzie łatwiejsze.
Te „rozbite” zapytania również są generowane przez duży model językowy, dlatego mają charakter niedeterministyczny: mogą się regularnie zmieniać, nawet w przypadku tego samego wyszukiwania.

Mark Williams-Cook, założyciel AlsoAsked
Dla specjalistów ds. SEO proces ten powinien brzmieć znajomo: powiązane zapytania są bardzo podobne do słów kluczowych o długim ogonie, intencji pobocznych oraz pytań sekcji „Podobne pytania”:
- Popularne frameworki strategii dotyczącej treści dla B2B SaaS
- Przykłady treści TOFU vs BOFU dla SaaS
- Odświeżanie treści i najlepsze praktyki dotyczące linków wewnętrznych
- Metryki wzrostu liczby prezentacji (demo) opartego na treściach
W rzeczywistości tylko 12% linków cytowanych przez platformy ChatGPT, Gemini i Copilot pojawia się w pierwszej dziesiątce wyników Google zwracanych dla pierwotnego promptu użytkownika. Nie oznacza to jednak, że tradycyjne pozycjonowanie jest nieistotne. Wyszukiwarki AI pozyskują treści, generując wiele zapytań w procesie „query fan-out” — a te „rozbite” zapytania to często bardziej tradycyjne wyszukiwania skoncentrowane na słowach kluczowych, w przypadku których Twoja dotychczasowa praca w obszarze SEO ma ogromne znaczenie.

Mechanizm „query fan-out” jest wyzwalający: nie musisz zgadywać, jakie konkretnie prompty konwersacyjne będą wpisywać użytkownicy. Zamiast tego lepiej zoptymalizować treści pod kątem rozbitych zapytań, czyli komponentów semantycznych, które modele językowe naturalnie generują. Wygląda to uderzająco podobnie do tradycyjnego badania słów kluczowych: [temat] + [określenie], zapytania o porównanie lub definicję oraz treści typu „najlepsze praktyki". Twoje dotychczasowe analizy SEO prawdopodobnie już pokrywają przestrzeń rozbitych zapytań.
Gianluca Fiorelli, konsultant ds. strategicznego i międzynarodowego SEO oraz wyszukiwania AI
Na czym polega pobieranie, dzielenie na fragmenty i synteza odpowiedzi?
Gdy LLM pobierze już z indeksu wyszukiwania odpowiednie strony, nie czyta ich w całości. Zamiast tego strony są dzielone na małe „fragmenty” tekstu, a model traktuje priorytetowo (a czasem rozszerza) te sekcje, które wydają się najbardziej istotne dla danego zapytania.
Takie fragmenty mają zwykle od kilkuset do kilku tysięcy słów, czyli w przypadku większości stron internetowych stanowią zaledwie niewielką część całości. LLM działa też w ramach ścisłych limitów okna kontekstowego: może przetworzyć ograniczoną ilość tekstu, wliczając w to prompt użytkownika, wszystkie pobrane fragmenty oraz własną odpowiedź. Oznacza to, że musi bardzo selektywnie wybierać, które treści pobiera i uwzględnia.
Oto przykład:
| Pełna treść na stronie | „Grounding to proces, w którym model pobiera źródła zewnętrzne, wyodrębnia istotne fakty i wykorzystuje te fragmenty, aby ograniczyć halucynacje i zwiększyć aktualność… Następnie skanuje wiele źródeł, porównuje informacje i syntetyzuje odpowiedź, zamiast kopiować tekst słowo w słowo. Ten etap syntezy pomaga uniknąć nadmiernego polegania na jednym źródle”. |
| Fragment | „Wyjaśnia, w jaki sposób asystenci korzystają z wyszukiwania w sieci, aby uzyskać zewnętrzne źródła i ograniczać halucynacje, osadzając odpowiedzi w pozyskanych faktach”. |
| Rozwinięcie (wiersze 1–2) | „Grounding to proces, w którym model pobiera źródła zewnętrzne, wyodrębnia istotne fakty i wykorzystuje te fragmenty, aby ograniczyć halucynacje i zwiększyć aktualność. Zanim zainicjuje wyszukiwanie w sieci, model ocenia, czy zapytanie wymaga aktualnych informacji lub danych możliwych do zweryfikowania”. |
| Rozwinięcie (wiersze 33–34) | „Następnie skanuje wiele źródeł, porównuje informacje i syntetyzuje odpowiedź, zamiast kopiować tekst dosłownie. Ten etap syntezy pomaga uniknąć nadmiernego polegania na jednym źródle”. |
Spraw, by Twoje treści były zrozumiałe dla LLM-ów
Ważne: Gdy wyszukiwarki AI pobierają Twoje treści z internetu, widzą tylko fragmenty, a nie całą stronę. Aby Twoje szanse na pojawienie się w odpowiedziach generowanych przez modele językowe były jak największe, trafność i wartość Twojej strony muszą być dla LLM-ów zrozumiałe, nawet bez dostępu do całej strony.
Następnie wyszukiwarka AI wykorzystuje ten tekst w procesie generowania odpowiedzi.
Surowa treść z sieci zostaje osadzona w odpowiedzi modelu: fragmenty tekstu lub dane wyodrębnione w poprzednim kroku są dodawane do kontekstu, z którego korzysta model, co w praktyce sprowadza się do instrukcji: „Oto kontekst z sieci, który może się przydać — teraz odpowiedz na pytanie użytkownika, korzystając z tych informacji”.
W jaki sposób wybierane są cytowania?
Następnie model generuje odpowiedź, łącząc swoją wbudowaną wiedzę z pobraną treścią, i udostępnia ją użytkownikowi. Odpowiedź zawiera zwykle cytowania, czyli klikalne adresy URL prowadzące do źródeł wykorzystanych w procesie groundingu.
Nie każda strona pobrana przez wyszukiwarkę AI otrzyma cytowanie w ostatecznej odpowiedzi. Model wybiera, które źródła zacytować, na podstawie kilku czynników:
- Trafność: W jakim stopniu bezpośrednio pobrana treść odpowiada za konkretne stwierdzenia w odpowiedzi?
- Aktualność: Na ile aktualne wydaje się dane źródło.
- Różnorodność: Na ile zróżnicowane są źródła cytowań (zważywszy, że wyszukiwarki AI często wolą cytować wiele różnych źródeł, zamiast wielokrotnie powoływać się na to samo)?
Oznacza to, że nawet jeśli Twoje treści zostaną pobrane i przeczytane, nie ma gwarancji, że zostaną one w sposób widoczny zacytowane; treść strony musi zostać uznana za bezpośrednio istotną dla konkretnego stwierdzenia w odpowiedzi.
Jak działa personalizacja?
Tak wyglądają podstawy działania wyszukiwarek AI, ale jest jeszcze dodatkowy poziom złożoności: personalizacja.
ChatGPT i inne wyszukiwarki AI mogą personalizować wyniki pod kątem konkretnych użytkowników, co oznacza, że ten sam prompt może generować różne wyniki u różnych osób. Na personalizację może wpływać kilka czynników, m.in.:
- Kontekst bieżącej rozmowy: Poprzednie wiadomości w tym samym czacie będą wpływać na odpowiedź udzieloną na bieżący prompt. Jeśli wspomnisz, że w sprzęcie turystycznym ważna jest dla Ciebie trwałość, możesz spodziewać się, że ChatGPT uwzględni to kryterium w wyszukiwaniu, gdy później poprosisz w tym samym czacie o rekomendacje dotyczące plecaków.
- Pamięć: Wiele LLM-ów ma funkcję pamięci, która pozwala systemowi zapamiętywać określone fakty lub preferencje między czatami. Na przykład przy włączonej pamięci ChatGPT wywnioskuje i zapamięta udostępnione przez Ciebie szczegóły (np. imię lub zainteresowania) i uwzględni je w przyszłych rozmowach, aby spersonalizować odpowiedzi.
- Lokalizacja, czas, data: Wiele wyszukiwarek AI potrafi wywnioskować informacje na Twój temat i na ich podstawie dostosować odpowiedzi — przykładowo, na podstawie Twojego adresu IP może określić przybliżoną lokalizację (na potrzeby zapytań typu „brunch niedaleko mnie") lub zmienić odpowiedź w zależności od daty i godziny (np. w przypadku promptu „lista rzeczy na kemping" może zasugerować namiot całoroczny zimą lub sezonowy latem).
- Prompty systemowe: Wszelkie konkretne preferencje przekazane w komunikacie systemowym będą wpływać na Twoje rozmowy (dodanie do promptu systemowego komunikatu „pamiętaj, że jestem na diecie wegańskiej” wpłynie na odpowiedzi na prompty typu „pomysły na zdrowe śniadanie”).
Oto analogia ułatwiająca zrozumienie promptów systemowych: Jeśli grasz w piłkę nożną, „dane treningowe” to cała Twoja praktyka z wielu lat – długotrwała pamięć mięśniowa. Prompt systemowy jest tym, co trener mówi Ci tuż przed wejściem na boisko. To potężna, krótkotrwała pamięć, która ma największy wpływ na to, co zrobisz w danej chwili.
Mark Williams-Cook, założyciel AlsoAsked

Z tego powodu warto monitorować średnią widoczność swojej marki i strony internetowej na przestrzeni czasu oraz w wielu promptach, zamiast obsesyjnie skupiać się na odpowiedziach na konkretny prompt.
Na koniec
Każda wyszukiwarka AI (od ChatGPT przez Perplexity po Google AI Mode) działa nieco inaczej, ale podstawowe procesy pozostają takie same. Co ważne z punktu widzenia specjalistów ds. SEO i marketingu, tradycyjne wyszukiwarki – takie jak Google i Bing – dostarczają dużą część infrastruktury niezbędnej do działania wyszukiwarek AI. Optymalizacja pod wyszukiwanie AI w dużej mierze opiera się na sprawdzonych najlepszych praktykach SEO.
Warto przeczytać
Ryan Law jest dyrektorem ds. marketingu treści w Ahrefs. Ryan ma 13 lat doświadczenia jako twórca treści, strateg ds. treści, lider zespołu, dyrektor ds. marketingu, wiceprezes, CMO oraz założyciel agencji. Pomógł poprawić marketing treści i SEO dziesiątkom firm, wśród których wymienić można Google, Zapier, GoDaddy, Clearbit czy Algolia. Jest także powieściopisarzem oraz twórcą dwóch kursów z zakresu marketingu treści.
Opanuj SEO krok po kroku
Jak działają wyszukiwarki
Zanim zaczniesz uczyć się SEO, musisz zrozumieć, jak działają wyszukiwarki.
Podstawy SEO
Dowiedz się, jak skonfigurować witrynę pod kątem skuteczności SEO, i zapoznaj się z czterema głównymi aspektami SEO.
Analiza słów kluczowych
Punktem wyjścia w SEO jest zrozumienie, czego szukają Twoi klienci docelowi.
Treści SEO
Dowiedz się, jak tworzyć treści, które zajmują wysokie pozycje w wyszukiwarkach.
SEO na stronie
W tym miejscu optymalizujesz swoje strony, aby pomóc wyszukiwarkom je zrozumieć.
Budowanie linków
Dowiedz się, jak tworzyć treści, które zajmują wysokie pozycje w wyszukiwarkach.
SEO techniczne
Zapobiegaj problemom technicznym, które uniemożliwiają Google'owi dostęp do Twojej witryny i jej zrozumienie.
Lokalne SEO
Dowiedz się, jak poprawić widoczność w lokalnych wynikach wyszukiwania i pozyskiwać więcej klientów z okolicy.
Co oznacza AI dla SEO
Dzisiaj nie można mówić o SEO bez wspomnienia o generatywnej AI.
Jak działają wyszukiwarki AI?
Dowiedz się dokładnie, w jaki sposób wyszukiwarki AI, takie jak ChatGPT, generują odpowiedzi i wybierają, które marki i produkty zostaną uwzględnione we wzmiankach.