


Come funzionano i motori di ricerca di IA

di Ryan Law
Direttore di Content Marketing, Ahrefs
Quando chiedi a ChatGPT di consigliarti le migliori cuffie over-ear per allenarti, cosa succede davvero?
In che modo i motori di ricerca di IA generano le loro risposte e scelgono i consigli sui prodotti? In cosa si distinguono dai motori di ricerca tradizionali come Google, e in cosa invece sono simili?
E, cosa fondamentale, come puoi far sì che il tuo sito web, il tuo brand e i tuoi prodotti compaiano nelle loro risposte?
Grazie a Gianluca Fiorelli e Mark Williams-Cook per aver revisionato e contribuito a questo capitolo.
Cosa sono i motori di ricerca di IA?
I motori di ricerca di IA sono sistemi di domanda e risposta che usano modelli linguistici di grandi dimensioni (LLM) per trovare informazioni e generare risposte.
Ci sono alcune differenze essenziali tra i motori di ricerca tradizionali e quelli di IA, anche se queste differenze diventano meno spiccate man mano che i motori di ricerca tradizionali incorporano più funzionalità di IA:
- Invece di una query isolata, gli utenti possono fare domande di follow-up e proseguire la stessa conversazione.
- Invece di restituire un elenco di link in ordine di rilevanza, i motori di ricerca basati sull'IA forniscono risposte e consigli diretti (e queste risposte possono cambiare regolarmente).
- Anziché indirizzare gli utenti a un sito web, i motori di IA rispondono alle domande direttamente nell'interfaccia della chat (e di conseguenza i clic verso i siti web diminuiscono).
Ecco come si presenta un'interfaccia di ricerca con IA tipica, simile a quella di ChatGPT, Claude o AI Mode:

- Prompt conversazionale: la domanda dell'utente.
- Messaggio di grounding: un messaggio che indica che l'LLM ha deciso di cercare informazioni aggiuntive da usare nella sua risposta.
- Risposta: la risposta generata dall'IA per il prompt dell'utente.
- Menzione: un'entità (come il tuo brand o prodotto) citata nel testo della risposta.
- Citazioni: URL delle fonti utilizzate per generare la risposta, in genere elencati alla fine.
Per riuscire a comparire in risposte come queste, devi innanzitutto capire i processi fondamentali su cui si basano i motori di ricerca di IA.
Come funziona l'addestramento
Gli LLM vengono addestrati su enormi quantità di contenuti. Di fatto hanno "letto" tutta Wikipedia, l'intero dataset Common Crawl, tutti i Google Books e decine di milioni di pagine di contenuti web.
Questi dati di addestramento aiutano a fornire all'LLM la sua "comprensione" del mondo. Se un'azienda che produce cuffie compare molte volte nei dati di addestramento, in contesti pertinenti e insieme a descrittori positivi ("miglior rapporto qualità-prezzo", "ottime per la palestra" e così via), ci sono buone probabilità che l'azienda venga menzionata nelle risposte dell'LLM a prompt relativi alle cuffie.
Lo sapevi?
Questo processo di addestramento è più articolato di quanto spiegato qui. Ci sono fasi di pre-addestramento per rimuovere il codice HTML, le informazioni che permettono di identificare una persona, le parole presenti in blocklist e filtrare i dati per determinate lingue. Ci sono anche fasi di post-addestramento per far sì che il modello linguistico si comporti come un assistente di chat utile anziché limitarsi a prevedere il token successivo. Per saperne di più, guarda il video di Andrej Karpathy, Deep Dive into LLMs like ChatGPT.


È qui che la SEO basata sulle entità diventa cruciale. Se il tuo brand compare regolarmente nei grafi della conoscenza, è strutturato correttamente con Schema markup e appare insieme ad entità pertinenti in contenuti di alta qualità in tutto il web, il suo "segnale di entità" nei dati di addestramento sarà più forte.

Gianluca Fiorelli, Consulente di SEO strategica e internazionale/Ricerca con IA
È fondamentale ricordare che gli LLM hanno molte particolarità:
- Sono probabilistici: puoi usare lo stesso prompt e ottenere risposte diverse ogni volta. Questa natura probabilistica significa che non puoi "ottimizzare per un prompt" come fai per una parola chiave. Piuttosto, devi pensare in termini di distribuzione: qual è la probabilità che il tuo brand compaia su 100 prompt simili? Ecco perché monitorare la visibilità media su molti prompt è meglio che fissarsi su pochi prompt specifici.
- La loro conoscenza ha una scadenza: di default, la conoscenza di un LLM è limitata a ciò che era contenuto nel dataset al momento dell'addestramento di quello specifico modello. Ogni modello viene addestrato una sola volta su un'istantanea dei dati fino a una certa data. Periodicamente vengono rilasciati nuovi modelli con scadenza più recente (di solito circa ogni sei mesi).
- Sono soggetti ad allucinazioni: possono affermare con sicurezza cose non vere. Gli LLM generano testo prevedendo quali parole è probabile che vengano dopo, non verificando i fatti. Anche se sono addestrati per essere utili e accurati, non hanno un meccanismo interno di verifica fattuale: ecco perché il grounding tramite ricerca sul web è indispensabile.
Un equivoco comune è che gli LLM ricevano "aggiornamenti di conoscenza" come le patch software. In realtà, ogni modello viene addestrato una sola volta su un dataset fisso. Quando viene rilasciato un nuovo modello con una scadenza di conoscenze più recente, si tratta di un modello completamente nuovo addestrato da zero, non di un aggiornamento di quello esistente.
Gianluca Fiorelli, Consulente di SEO strategica e internazionale/Ricerca con IA
Un motore di ricerca che va soggetto ad allucinazioni e fornisce informazioni obsolete non sembra molto utile. Per questo motivo, gli LLM superano alcune di queste limitazioni tramite un processo noto come grounding.
Come funzionano grounding e RAG
Gli LLM possono verificare e migliorare le proprie risposte in due modi: usando strumenti (come calcolatrici o altre API di dati) oppure recuperando informazioni aggiuntive da fonti esterne. Questo secondo processo è noto, in termini tecnici, come Retrieval-Augmented Generation (RAG).
Quando un utente pone una domanda, l'LLM si chiede: "Conosco già la risposta o dovrei recuperare informazioni aggiuntive?" Se è in grado di prevedere il prossimo token con un grado di certezza elevato (ad esempio nel caso di domande la cui risposta è poco soggetta a cambiamento, come "a cosa servono i globuli rossi?"), probabilmente risponderà attingendo alle sue conoscenze di base. Se il grado di certezza è basso, come per le domande la cui risposta può variare nel tempo, (ad esempio "qual è il miglior macinacaffè economico?"), l'LLM può usare il suo strumento di ricerca per trovare informazioni pertinenti da altre fonti su Internet.
Gli LLM sono ottimizzati per riconoscere i tipi di query che potrebbero beneficiare di informazioni aggiuntive, ad esempio:
- Argomenti fuori dall'ambito di addestramento del modello: "Quali sono i fattori di ranking interni usati da Keywords Explorer di Ahrefs?"
- Argomenti che richiedono informazioni aggiornate o sensibili al fattore tempo: "Qual è stato l'aggiornamento principale più recente di Google e quando è stato rilasciato?"
- Argomenti che richiedono esplicitamente una ricerca sul web: "Cerca su internet le tattiche di link building più diffuse nel 2026."
- Prompt che richiedono fonti e prove: "Trova fonti che confermino che Google utilizza segnali di coinvolgimento degli utenti nel suo algoritmo."
Alcuni LLM hanno anche un'elevata probabilità di attivare ricerche aggiuntive (ad esempio, i modelli di "deep research" sono configurati appositamente per attivare più ricerche RAG).
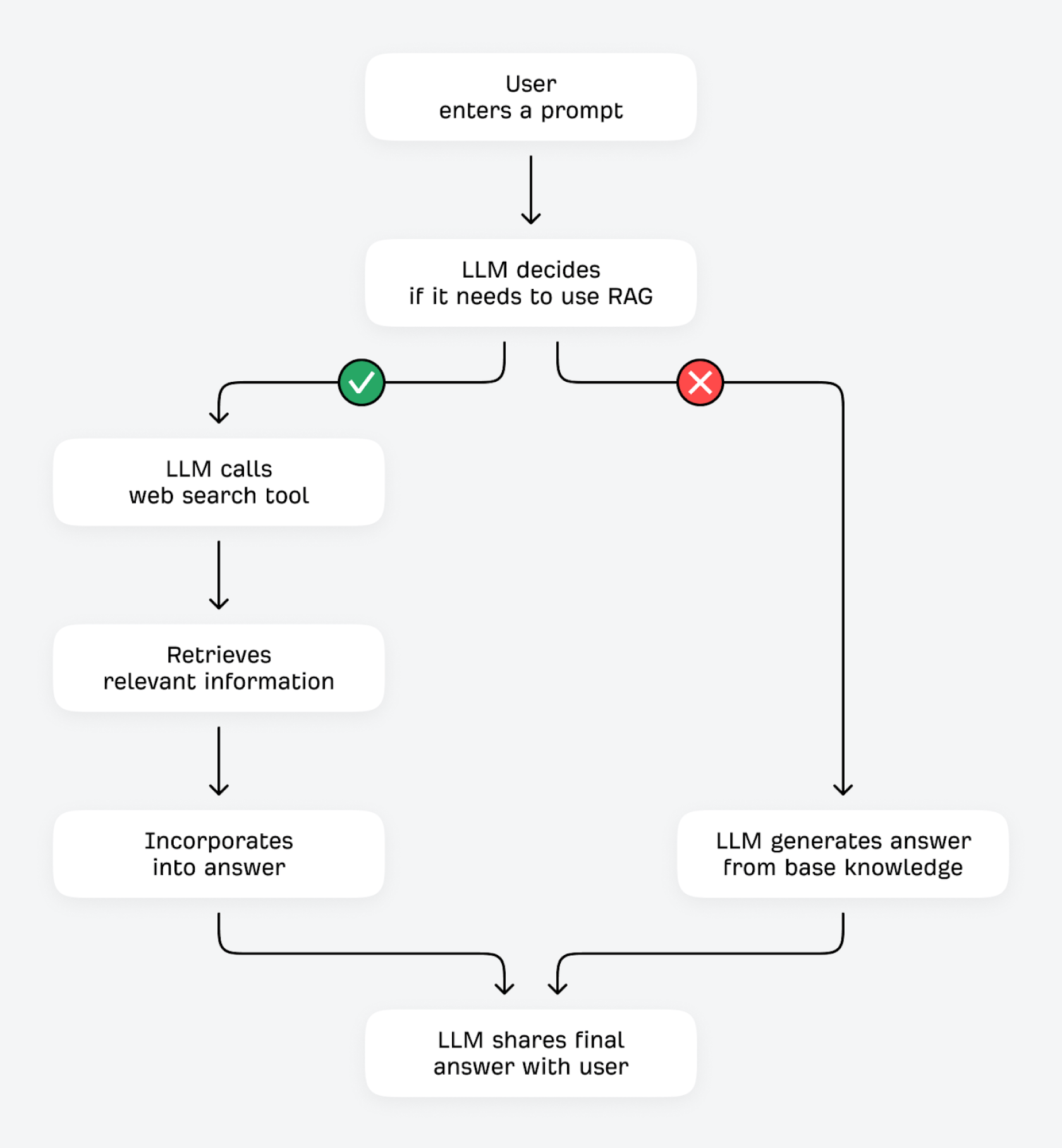
Questo processo di ricerca della "verità di riferimento" tramite RAG, spesso chiamato "grounding") offre diversi vantaggi: l'LLM può migliorare l'accuratezza fattuale e ridurre le allucinazioni verificando le proprie risposte con fonti di terze parti; può recuperare e fornire informazioni aggiornate anche se i suoi dati di addestramento sono relativamente datati; può dare risposte più dettagliate e complete e offrire maggiore trasparenza e dati di attribuzione per le informazioni che fornisce.
I motori di ricerca di IA eseguono questo grounding tramite un processo noto come "fan-out della query".
Come funziona il fan-out delle query
Il fan-out delle query spiega perché la SEO tradizionale è fondamentale per la visibilità nell'IA.
Gli assistenti basati sull'IA come ChatGPT, Gemini e Perplexity usano indici di ricerca come Google, Bing e Brave per recuperare informazioni aggiornate.
Il provider di ricerca è importante perché ognuno ha algoritmi di ranking, indici e copertura diversi: rendere il tuo brand visibile su Ricerca Google potrebbe contribuire alla sua visibilità in AI Mode più che in ChatGPT, che dipende maggiormente da Bing.
| Motore di ricerca di IA | Indici di ricerca usati per il grounding |
|---|---|
ChatGPT | Bing, Google |
Claude | Brave |
Gemini | Google |
Copilot | Bing |
Perplexity | In-house |
AI Mode | Google |
AI Overviews | Google |
Quando viene attivata una ricerca sul web, l'LLM richiede risultati pertinenti al suo indice di ricerca. L'indice di ricerca restituisce un elenco di risultati e l'LLM seleziona le pagine più pertinenti da scansionare valutando fattori come il titolo della pagina, il contenuto dello snippet della pagina restituita e la sua freschezza (quanto recentemente è stata pubblicata).
Perché la SEO è cruciale per la ricerca con IA
Vale la pena ripeterlo: i motori di ricerca tradizionali come Google e Bing svolgono un ruolo cruciale nell'aiutare i motori di ricerca basati sull'IA a decidere quali contenuti menzionare e citare nelle loro risposte.
In altre parole, posizionarsi in alto nella ricerca tradizionale migliora la visibilità anche nella ricerca basata sull'IA.
Ma cosa cerca esattamente l'LLM?
Gli LLM utilizzano un processo chiamato fan-out delle query. Molti prompt inseriti in ChatGPT e in altri motori di ricerca basati sull'IA sono estremamente lunghi, discorsivi e spesso del tutto unici. Effettuare una ricerca su Google utilizzando questi prompt esatti non restituisce sempre contenuti utili.
Quindi, invece di eseguire una ricerca sul web con la query esatta dell'utente:
"Sto pianificando una strategia di contenuti di 6 mesi per un'azienda B2B SaaS di medie dimensioni che vende un prodotto di analytics a brand di e-commerce. L'azienda..."

…gli LLM usano quel prompt iniziale per generare una serie di query più brevi e correlate, utili a recuperare informazioni pertinenti.
Queste query di fan-out vengono anch'esse generate dal modello linguistico di grandi dimensioni e sono quindi non deterministiche: possono cambiare regolarmente, anche per la stessa ricerca.

Mark Williams-Cook, Fondatore, AlsoAsked
Questo processo dovrebbe risultare familiare ai professionisti della SEO: queste query correlate sono infatti molto simili alle parole chiave long tail, alle intenzioni secondarie e alle domande di "Le persone hanno chiesto anche":
- Framework comuni di strategia dei contenuti B2B SaaS
- Esempi di contenuti TOFU vs BOFU per SaaS
- Best practice per aggiornamento dei contenuti e link interni
- Metriche per la crescita delle demo basata sui contenuti
In realtà, solo il 12% dei link citati da ChatGPT, Gemini e Copilot compare tra i primi 10 risultati di Google per il prompt originale dell'utente. Tuttavia, questo non significa che il ranking tradizionale sia irrilevante. I motori di ricerca di IA recuperano contenuti generando più query di ricerca e queste query di fan-out sono spesso ricerche più tradizionali, incentrate sulle parole chiave, in cui l'attuale lavoro di SEO conta enormemente.

Il fan-out delle query è liberatorio: non devi indovinare quali prompt conversazionali useranno le persone. Piuttosto, ottimizza per le query scomposte, ossia i componenti semantici che gli LLM genereranno naturalmente. Assomigliano moltissimo alla tradizionale ricerca di parole chiave: [argomento] + [qualificatore], query di confronto, query definitorie e contenuti sulle "best practice". Si tratta di aree che la tua attuale ricerca per la SEO probabilmente copre già.
Gianluca Fiorelli, Consulente di SEO strategica e internazionale/Ricerca con IA
Come funzionano recupero, chunking e sintesi della risposta
Quando un LLM recupera pagine pertinenti da un indice di ricerca, non le legge per intero. Le suddivide invece in piccoli bocchi di testo ("chunk") e dà priorità (e talvolta amplia) alle sezioni di testo che sembrano più rilevanti per la query.
Questi blocchi sono in genere composti da poche centinaia a poche migliaia di parole ciascuno: una piccola frazione della maggior parte delle pagine web. L'LLM inoltre opera con rigidi limiti della finestra di contesto: può elaborare una quantità limitata di testo, inclusi il prompt dell'utente, tutti i blocchi recuperati e la propria risposta. Ciò significa che deve essere molto selettivo riguardo ai contenuti che recupera e include.
Ecco un esempio:
| Intero contenuto della pagina | "Il grounding è un flusso di lavoro in cui il modello recupera fonti esterne, estrae fatti rilevanti e usa tali estratti per ridurre le allucinazioni e assicurare che le informazioni siano aggiornate.… Poi analizza più fonti, confronta le informazioni e sintetizza una risposta anziché copiare il testo parola per parola. Questo passaggio di sintesi aiuta a evitare un'eccessiva dipendenza da una singola fonte.» |
| Snippet | "Spiega come gli assistenti utilizzano la ricerca sul web per trovare fonti esterne e ridurre le allucinazioni ancorando le risposte a fatti trovati.” |
| Espansione (righe 1–2) | "Il grounding è un flusso di lavoro in cui il modello recupera fonti esterne, estrae fatti rilevanti e usa tali estratti per ridurre le allucinazioni e assicurare che le informazioni siano il più possibile aggiornate. Il modello valuta se una query richiede informazioni aggiornate o verificabili prima di avviare una ricerca sul web." |
| Espansione (righe 33–34) | "Poi analizza più fonti, confronta le informazioni e sintetizza una risposta anziché copiare il testo parola per parola. Questo passaggio di sintesi aiuta a evitare un'eccessiva dipendenza da una singola fonte." |
Rendi i tuoi contenuti facili da capire per gli LLM
Questo è molto importante: quando i motori di ricerca di IA recuperano i tuoi contenuti da Internet, possono vedere solo estratti parziali e non l'intera pagina. Se vuoi massimizzare le probabilità di ottenere una citazione nella risposta dell'LLM, devi fare in modo che il modello possa comprendere facilmente la pertinenza e il valore della tua pagina anche senza leggerla tutta.
Il motore di ricerca basato su IA integra poi il testo selezionato nel processo di generazione della risposta.
Il contenuto del web grezzo viene ancorato nella risposta del modello: gli snippet di testo o i dati estratti nel passaggio precedente vengono aggiunti al contesto del modello, dicendo in sostanza: "Ecco un po' di contesto dal web che potrebbe essere utile, ora rispondi alla domanda dell'utente usando queste informazioni."
Come vengono scelte le citazioni
A questo punto, il modello genera una risposta combinando la propria conoscenza innata con i contenuti recuperati e la fornisce all'utente. La risposta di solito include citazioni: URL cliccabili che rimandano alle fonti utilizzate durante il processo di grounding.
Non tutte le pagine recuperate dal motore di ricerca di IA saranno citate nella risposta finale. Il modello seleziona quali fonti citare in base a diversi fattori:
- Rilevanza: quanto direttamente i contenuti recuperati hanno contribuito a specifiche affermazioni nella risposta.
- Attualità: quanto recente sembra essere la fonte.
- Diversità: quanto diversificate sono le fonti delle citazioni (i motori di ricerca di IA spesso preferiscono citare più fonti diverse invece di citare ripetutamente la stessa).
Ciò significa che, anche se i tuoi contenuti vengono recuperati e letti, non è detto che ottengano una citazione visibile; i contenuti devono essere ritenuti direttamente pertinenti a un'affermazione specifica nella risposta.
Come funziona la personalizzazione
Quello descritto fin qui è il funzionamento di base dei motori di ricerca di IA, ma c'è un ulteriore livello di complessità: la personalizzazione.
ChatGPT e altri motori di ricerca basati sull'IA possono personalizzare i risultati per i singoli utenti, il che significa che lo stesso prompt può generare risultati diversi per persone diverse. La personalizzazione può essere influenzata in diversi modi, tra cui:
- Contesto attuale della conversazione: i messaggi precedenti nella stessa chat influenzeranno la risposta al prompt attuale. Ad esempio, se menzioni che per te la "durata" dell'attrezzatura da trekking è importante, puoi aspettarti che ChatGPT includa questo criterio nella sua ricerca quando più avanti nella chat chiederai "consigli sugli zaini".
- Memoria: molti LLM hanno una funzionalità di memoria che consente al sistema di ricordare determinati fatti o preferenze tra una chat e l'altra. Ad esempio, se la funzione di memoria è attivata, ChatGPT dedurrà e ricorderà i dettagli che hai condiviso (come il tuo nome o i tuoi interessi) e li includerà nelle conversazioni future per personalizzare le risposte.
- Località, ora, data: molti motori di ricerca basati su IA possono dedurre informazioni su di te e personalizzare le risposte di conseguenza. Ad esempio, possono usare l'indirizzo IP per ricavare la tua posizione approssimativa per rispondere a query come "pizzeria vicino a me", oppure usare data e ora per compilare una lista delle cose da portare in campeggio (e suggerire una tenda 4 stagioni in inverno e una tenda 3 stagioni in estate).
- Prompt di sistema: eventuali preferenze specifiche condivise nel messaggio di sistema influenzeranno le tue conversazioni (aggiungere "ricorda che sono vegano" al prompt di sistema influenzerà le risposte a prompt come "idee per una colazione sana").
Ecco un'analogia per capire i prompt di sistema. Se stessi giocando a calcio, i "dati di addestramento" sarebbero tutta la pratica fatta negli anni, la "memoria muscolare" di lungo periodo. Il prompt di sistema è ciò che ti dice l'allenatore appena prima di scendere in campo. È la potente memoria a breve termine, quella che ha più probabilità di influenzare l'output.
Mark Williams-Cook, Fondatore, AlsoAsked

Per questo motivo, è consigliare monitorare nel tempo la visibilità media del tuo brand e del tuo sito web in molti prompt anziché fissarsi sulla risposta a un singolo prompt.
Considerazioni finali
Ogni motore di ricerca basato sull'IA – da ChatGPT a Perplexity ad AI Mode di Google – è leggermente diverso, ma i processi principali restano gli stessi. E, cosa importante per esperti di SEO e marketer, i motori di ricerca tradizionali come Google e Bing forniscono gran parte dell'infrastruttura necessaria affinché i motori di ricerca basati sull'IA funzionino. L'ottimizzazione per la ricerca basata sull'IA dipende in larga misura dalle best practice della SEO tradizionale.
Ryan Law è il direttore di Content Marketing di Ahrefs. Ryan ha 13 anni di esperienza come autore, stratega di contenuti, responsabile di team, direttore del marketing, vicepresidente, CMO e fondatore di agenzie. Ha aiutato dozzine di aziende a migliorare il loro marketing dei contenuti e la SEO, tra cui Google, Zapier, GoDaddy, Clearbit e Algolia. È anche romanziere e autore di due corsi di content marketing.
Master SEO Step by Step
Come funzionano i motori di ricerca
Prima di iniziare a imparare la SEO, è necessario capire come funzionano i motori di ricerca.
Principi fondamentali della SEO
Scopri come preparare il tuo sito web per il successo SEO e affronta i quattro aspetti principali della SEO.
Ricerca di parole chiave
Il punto di partenza nella SEO è capire cosa cercano i tuoi clienti di riferimento.
Contenuti per la SEO
Scopri come creare contenuti che si posizionano bene nei motori di ricerca.
SEO on page
È qui che ottimizzi le tue pagine per aiutare i motori di ricerca a comprenderle.
Link building
Scopri come creare contenuti che si posizionano bene nei motori di ricerca.
SEO tecnica
Previeni i problemi tecnici che impediscono a Google di accedere al tuo sito web e di comprenderlo.
SEO locale
Scopri come migliorare la tua visibilità nei risultati di ricerca locali e ottenere più clienti della tua zona.
Cosa significa l'IA per la SEO
Non si può parlare di SEO oggi senza menzionare l'IA generativa.
Come funzionano i motori di ricerca di IA
Scopri esattamente come i motori di ricerca basati sull'IA come ChatGPT generano le loro risposte e come scelgono quali brand e prodotti menzionare.