
In the words of Patrick Stox, this whole idea is “preposterous.”
He’s right. Having multiple pages about the same thing can lead to unexpected or undesirable rankings, but it doesn’t always mean that something’s wrong or needs fixing. However, it can occasionally signal an opportunity to consolidate content to improve rankings and organic performance.
In this guide, you’ll learn:
- What keyword cannibalization is
- Why keyword cannibalization is bad
- How to find keyword cannibalization issues
- How to fix keyword cannibalization issues
- Bad keyword cannibalization solutions
Keyword cannibalization is an SEO issue that happens when multiple pages on a website target the same or similar keywords. This leads to a situation where the site’s pages compete against each other for search engine rankings. This can dilute the website’s ability to rank effectively for targeted keywords.
For example, let’s say we have two pages about technical SEO. If we could get more organic traffic overall by combining the two pages into one, that’s a cannibalization issue. The existence of those two pages is eating away at our organic performance.
Keyword cannibalization is bad. But it’s crucial to remember that you only have a real cannibalization issue when multiple pages target the same keyword and hurt a site’s organic performance.
Given that pages tend to rank for many keywords, that’s not always the case.
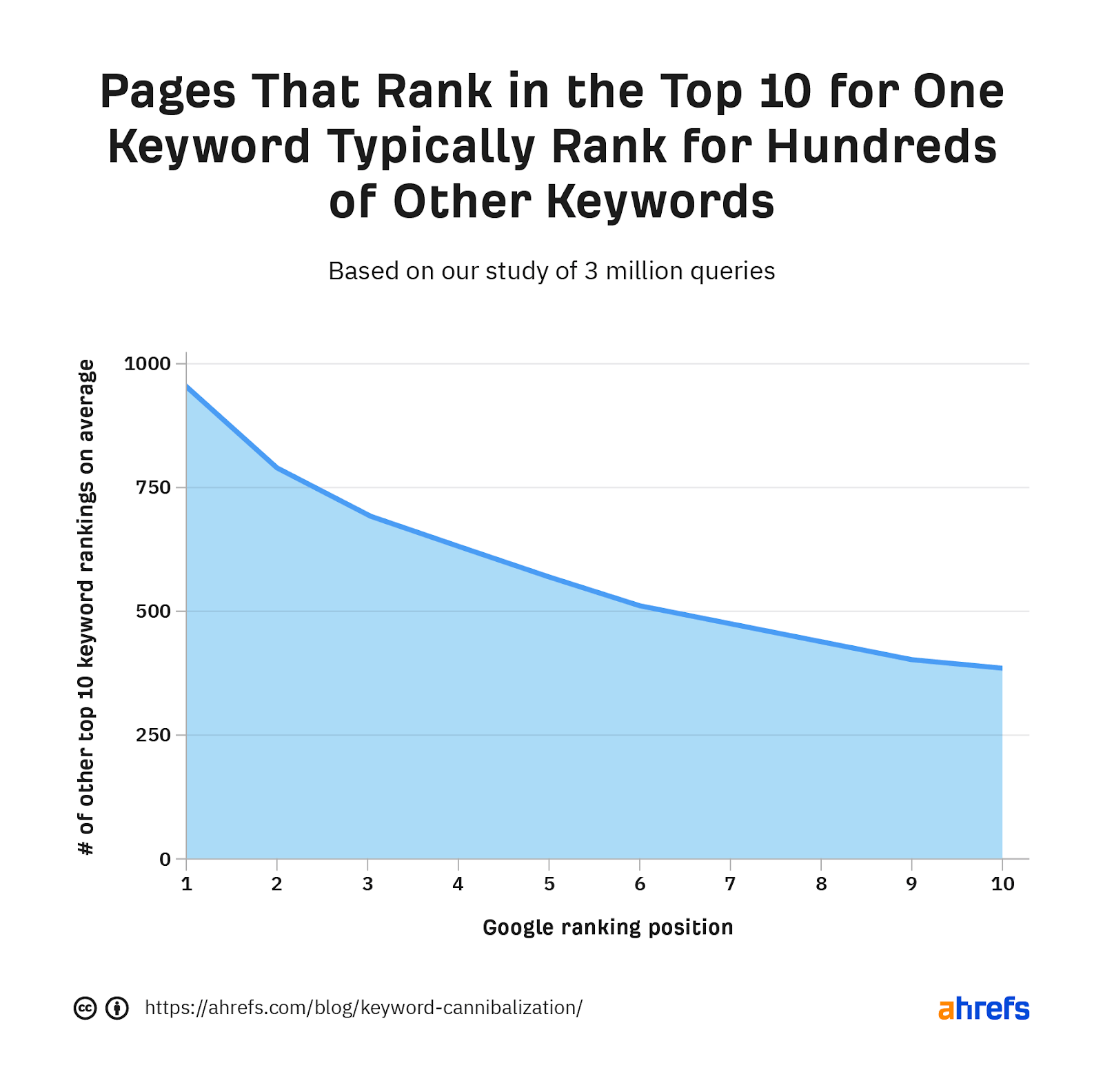
For example, let’s say that we have two pages targeting the same keyword. One of them ranks #1, but the other page (that we’d prefer to rank) is nowhere to be seen. You could argue that this is textbook keyword cannibalization because one page is seemingly “cannibalizing” traffic to the other page.
But even if that’s true for traffic from this keyword, what if these pages each rank for hundreds of other keywords?
In that case, why worry about traffic from just one keyword?
The reality is that we don’t have a real cannibalization issue here because the existence of these two pages likely isn’t harming our site’s overall organic performance. If we were to merge or delete one of them, we’d likely lose some of our other keyword rankings and see a net drop in traffic.
The trick to finding real cannibalization issues is to look for pages that target the same keywords and fulfill the same or very similar intent.
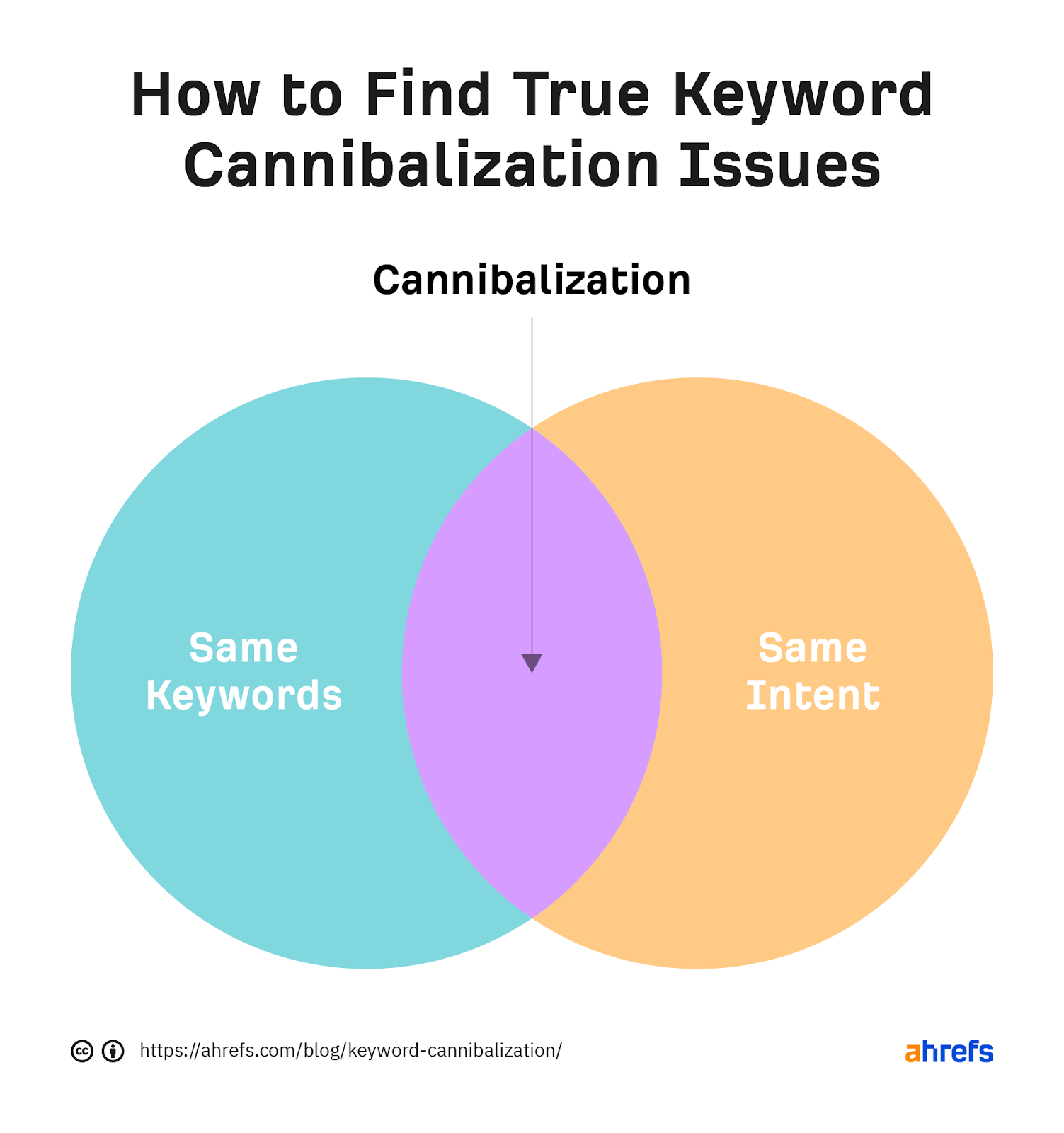
The reason for this is that if the intent is the same, each page is unlikely to be ranking for lots of different long-tail keyword variations. So there’s usually more to gain than lose by consolidating the pages.
Let’s look at a few ways to identify these pages.
Option 1. Do a content audit
Unless your site is huge, cannibalization issues should be relatively easy to spot during a content audit.
Option 2. Look at historic rankings
This works best when you want to check for cannibalization issues for a specific keyword.
Here’s how to it in Ahrefs’ Site Explorer:
- Enter your domain
- Go to the Organic keywords report
- Filter for the keyword you want to investigate
- Click the ranking history dropdown
For example, if we look at Moz’s historical rankings for “keyword cannibalization,” we see three pages ranking in the last six months—none of which ranked higher than position #8:
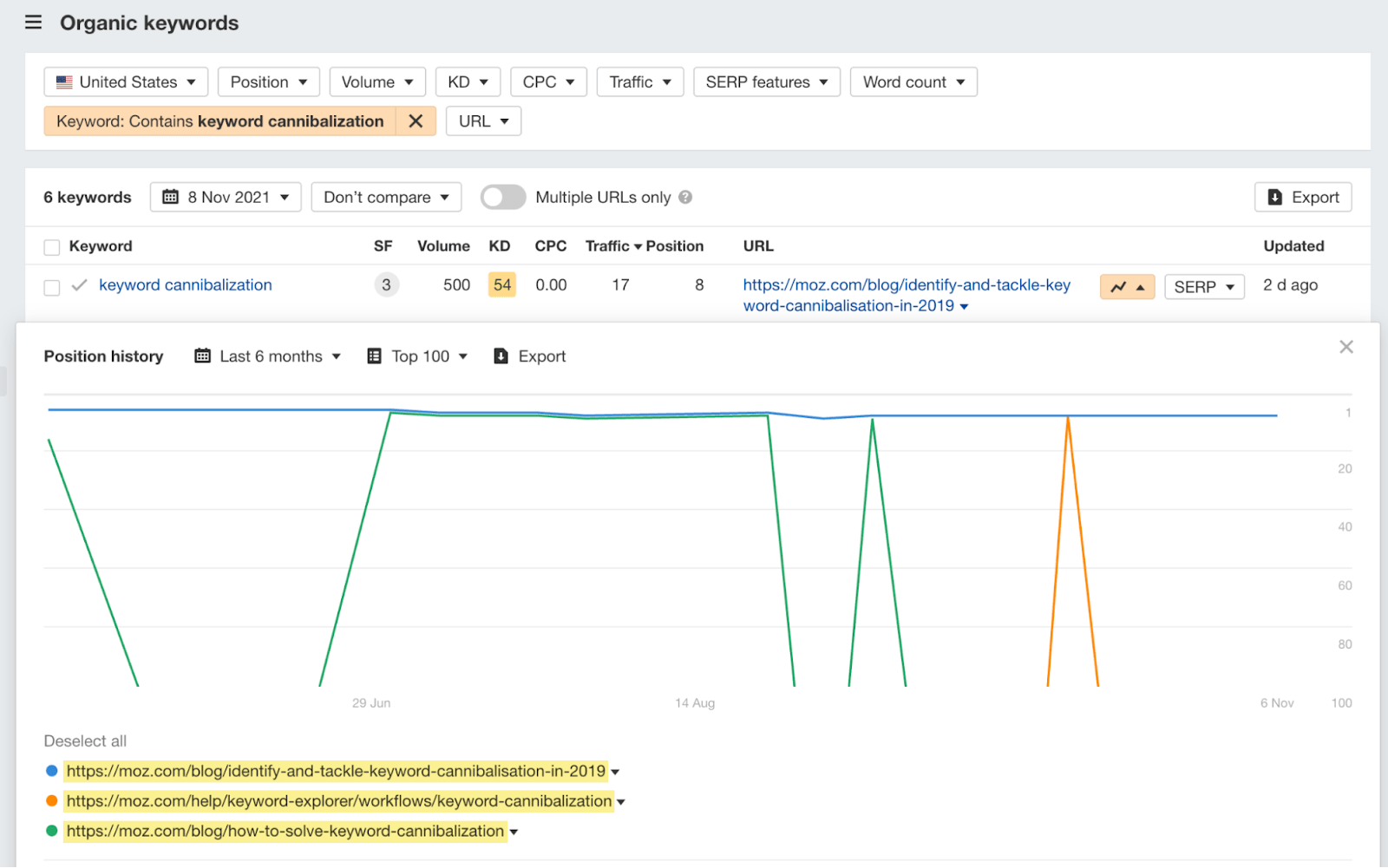
Let’s take a closer look at two of those URLs:
/blog/identify-and-tackle-keyword-cannibalisation-in-2019
/blog/how-to-solve-keyword-cannibalization
Here’s what they tell us about the pages:
- They’re both blog posts.
- They’re both about the same thing (i.e., tackling/solving keyword cannibalization).
- The first one is outdated (it has “2019” in the URL).
So this is almost certainly a cannibalization issue. The pages fulfill the same intent and compete against each other. Moz’s overall organic performance could likely be improved by consolidating them.
Option 3. Run a site: search
Head to Google and search for site:yourwebsite.com "topic". You’ll see all the pages on your site related to that topic.
If we do this for site:moz.com "keyword cannibalization", you can see that the first three results are the ones we previously discovered in Site Explorer:
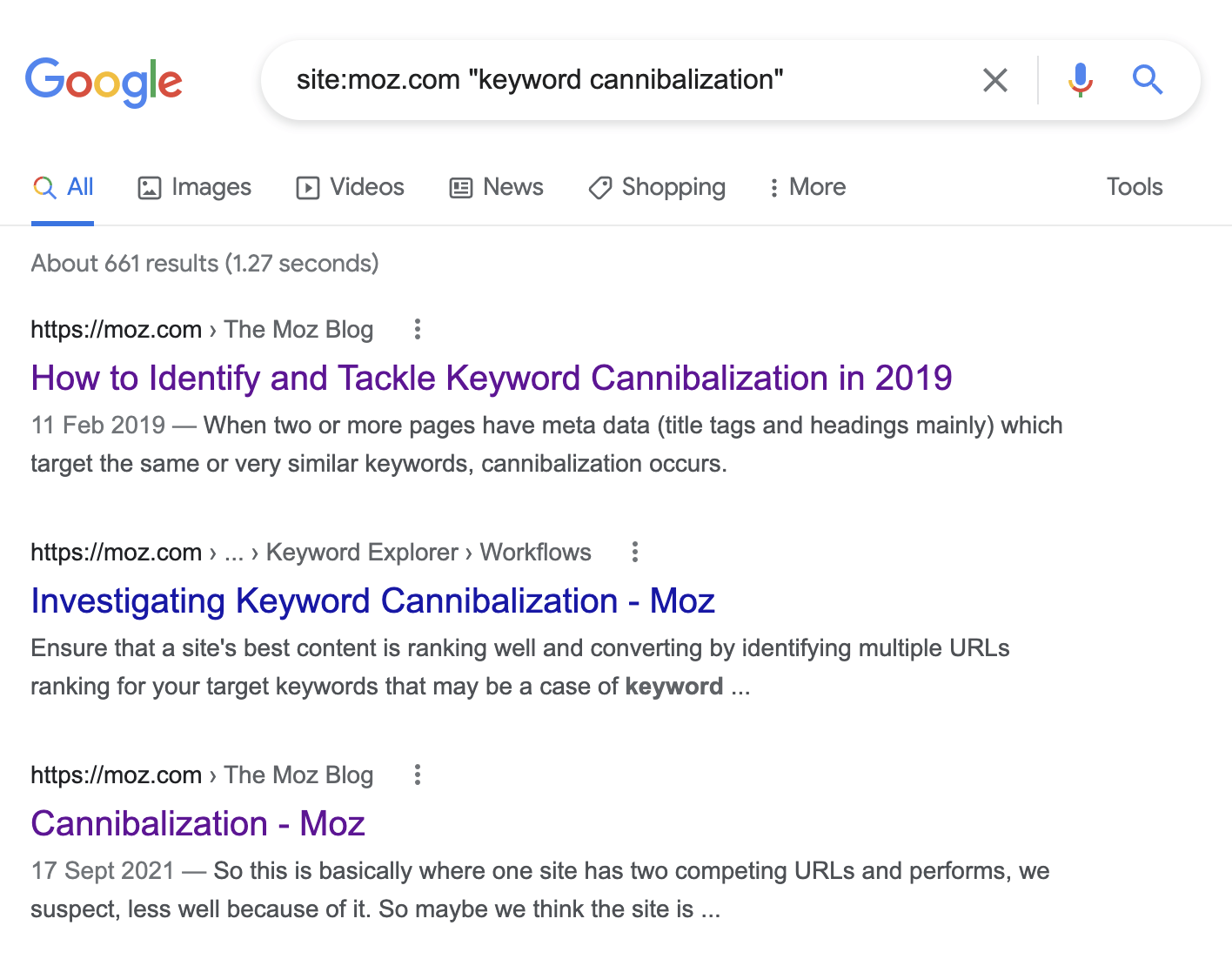
Be careful with this tactic, as Google returns every vaguely matching result. For example, you can see above that there are 661 results for our search. Moz may very well have a keyword cannibalization issue here, but not all of these pages are problematic. Most are targeting completely different keywords.
Option 4. Run a Google search and remove host clustering
Running a site: search can help you to find potential cannibalization issues. The only issue is that the results lack a sense of place, making it hard to know how to tackle the issue.
If you look at the previous example, you’ll see that it probably makes sense for Moz to merge three of their pages. But how exactly should they merge them? Which pages should be redirected, and which should they keep? Is this even likely to improve things?
You can often find answers to these questions by running a regular Google search and removing host clustering—which is where Google excludes similar pages from the same host from the search results.
For example, if we search for “keyword cannibalization” in Google, we only see one result from Moz in the top 20:
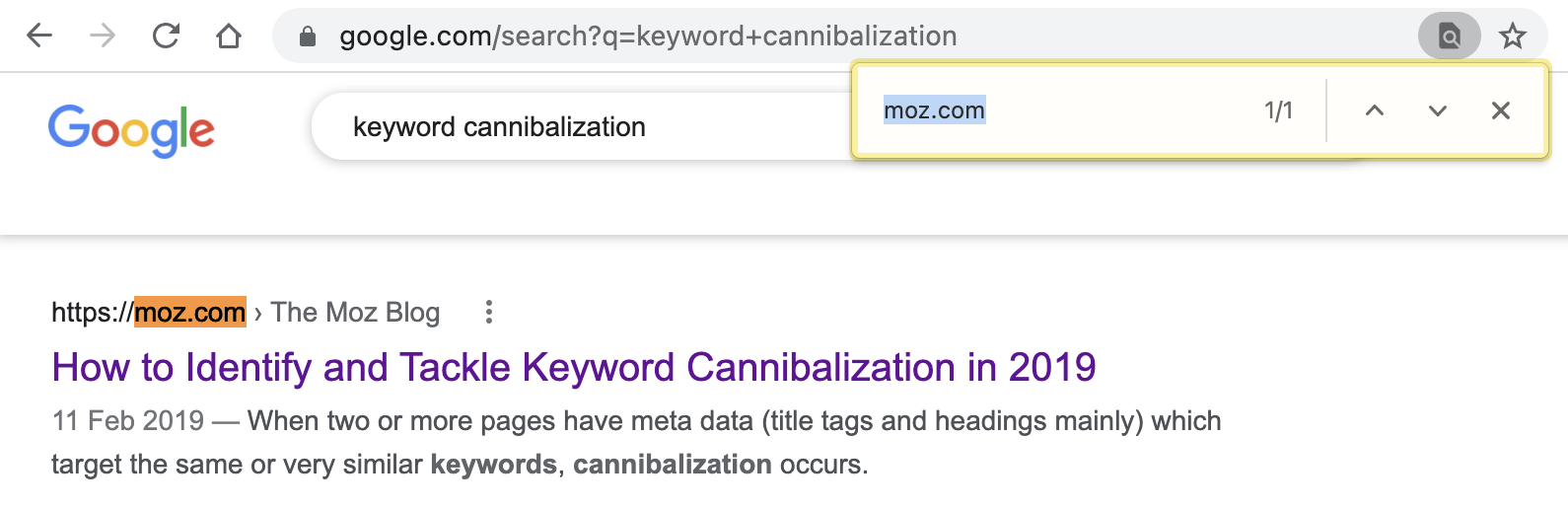
But if we append &filter=0 to the Google search URL, it removes host clustering and reveals three results from Moz in the top 20:
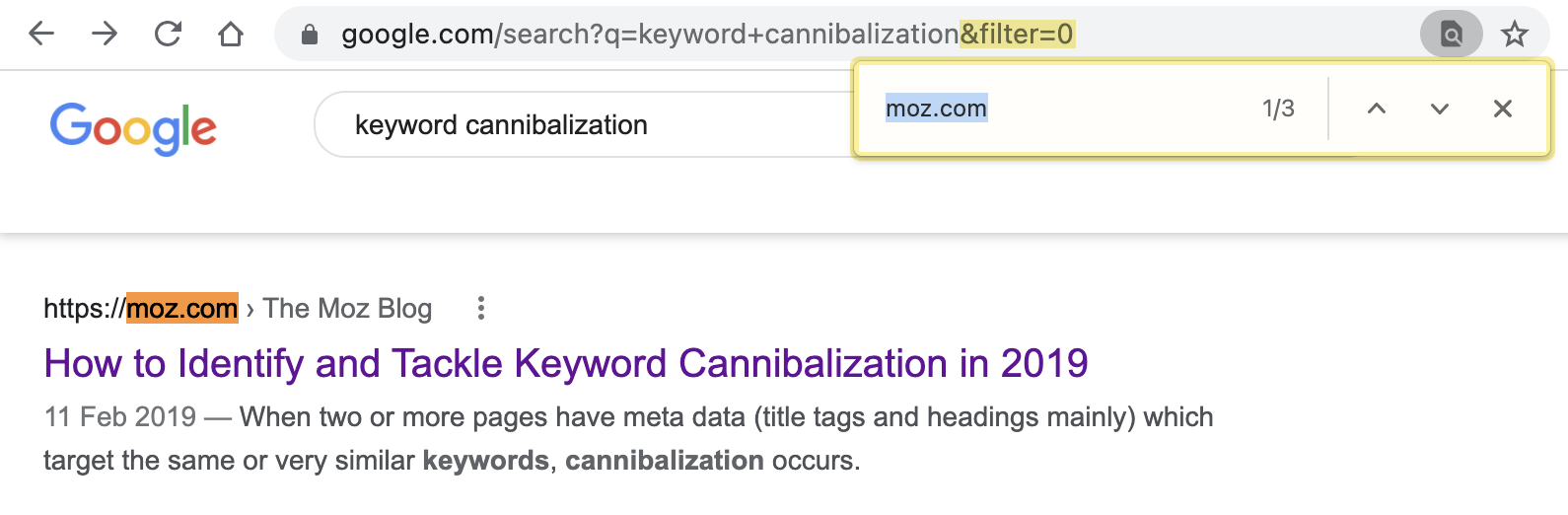
This is useful because it gives each URL a sense of place.
In this example, we see Moz’s 2019 post ranking in position #6 and the other two posts ranking in positions #12 and #13, respectively.
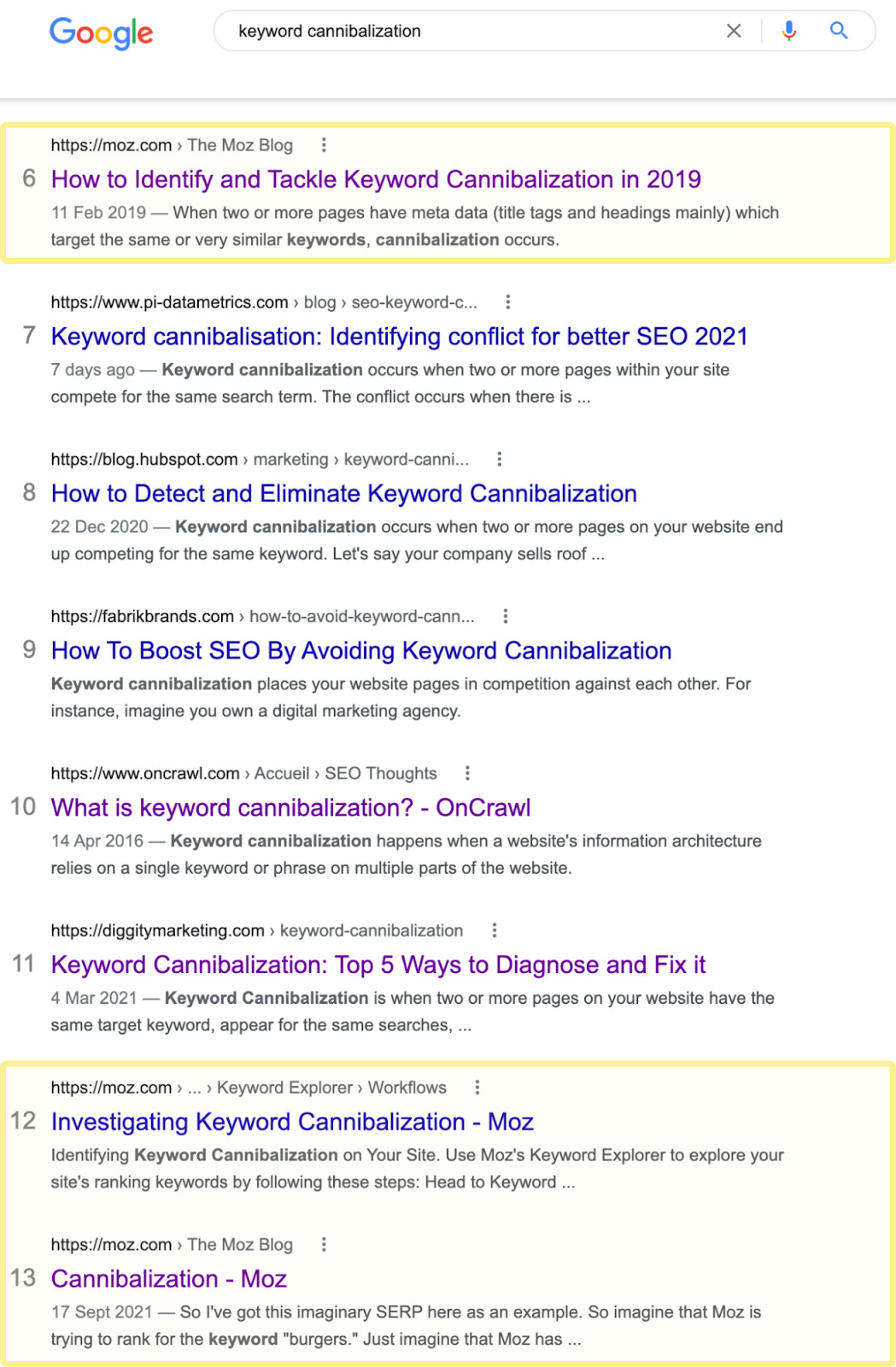
So we know now Moz could rank higher than position #6 by combining some of these pages and redirecting. It’s also evident that Google currently considers the page in position #6 the most relevant result for this keyword. Thus, it probably makes sense to work primarily with that page and redirect the other pages there.
Option 5. Check for multiple ranking URLs
If Google ranks multiple URLs for a keyword, that can be a sign of a cannibalization issue.
Here’s how to find these keywords in Site Explorer:
- Enter your domain
- Go to the Organic keywords report
- Toggle “Multiple URLs only”
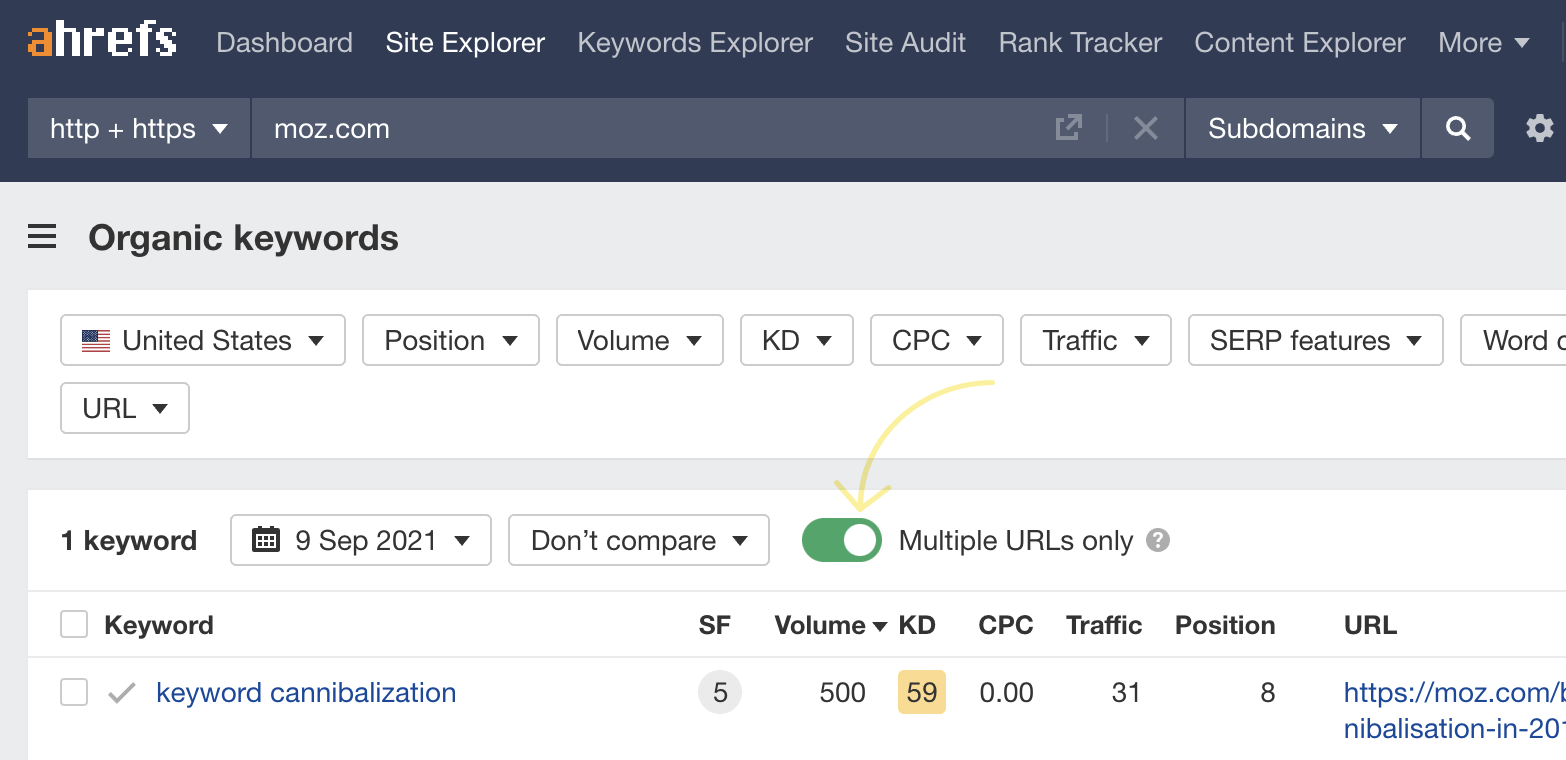
You can see that when we do this for Moz, Site Explorer finds the same issue for the term “keyword cannibalization” as we found earlier using method #2.
Just be aware that this doesn’t always work, as Google tends not to rank multiple pages (in “regular” positions) from the same host, as discussed previously. But as it’s super quick to do in Site Explorer, it’s still worth a quick check.
Not all of the keywords that show up here will reflect “cannibalization” issues. You should always check the SERP and ranking history to ensure you have a real cannibalization issue on your hands.
If you’re confident that you have a cannibalization issue on your hands, you can often improve organic performance by consolidating the pages. That may mean redirecting an old, outdated page to something more relevant that you already have or combining multiple pages into something new.
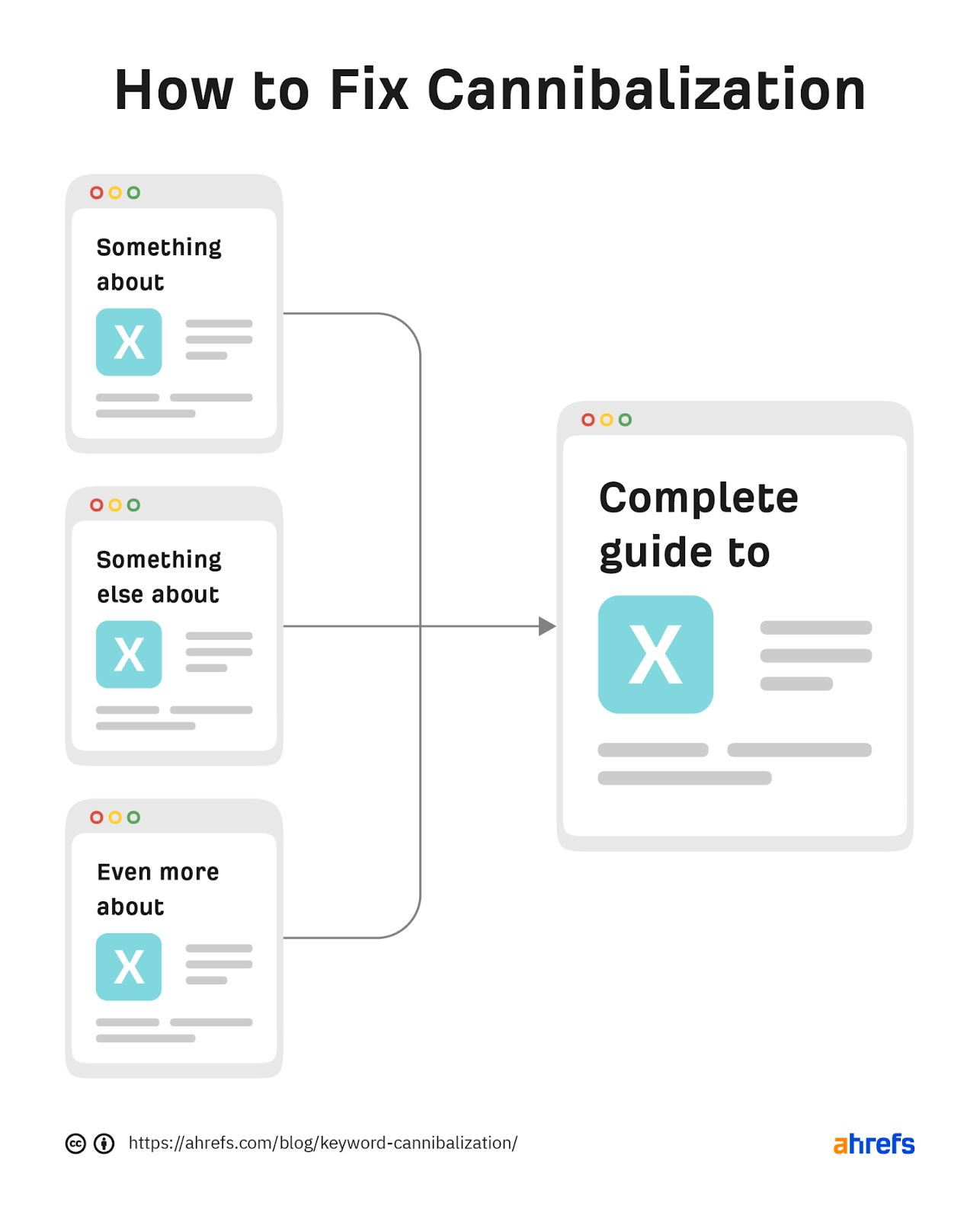
Either option will usually have a positive impact because they consolidate known ranking signals like backlinks and internal links into one page rather than diluting them across multiple pages.
We saw success by doing this in 2018 for two guides about broken link building.
Here’s what we did:
- We wrote a new guide consolidating the knowledge from both guides.
- We published the new guide at one of the existing URLs.
- We deleted the old guide and redirected it to the new guide.
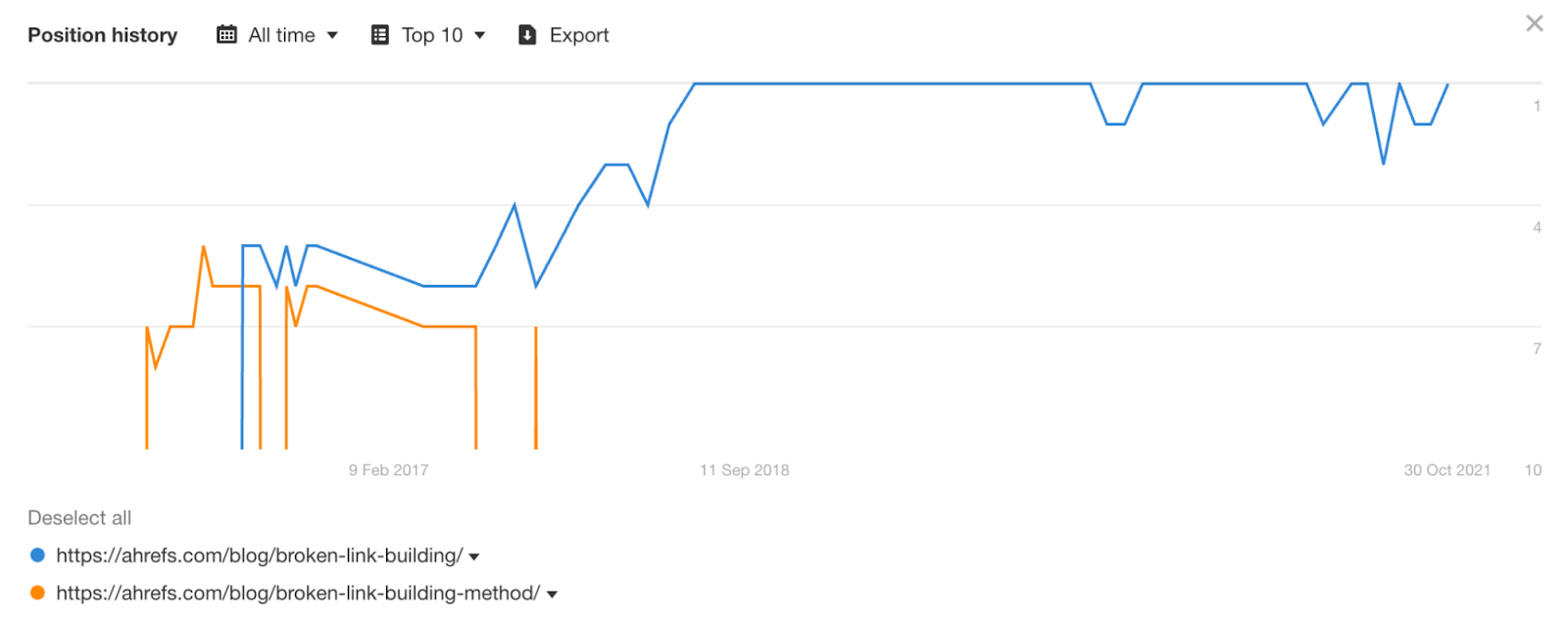
You can probably tell when we did this in the graph below, which shows our historical rankings for “broken link building”:
Our historical estimated organic traffic to these two pages also shows the positive change (the arrow marks the consolidation date):
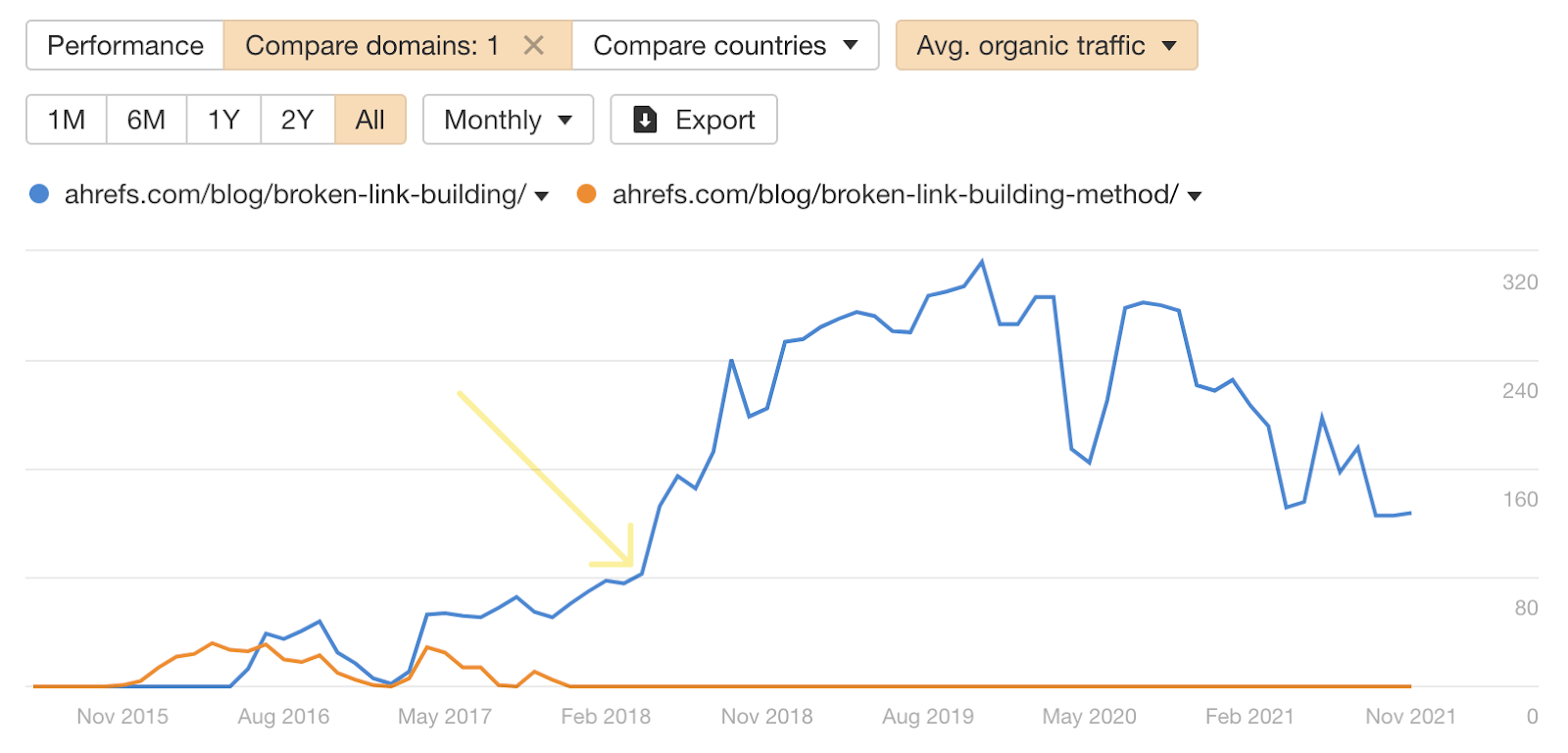
Until the redirect in 2018, both pages were getting a bit of traffic. After consolidating and redirecting, only one gets traffic… but it gets way more traffic than both pages (combined) did beforehand.
Remember that it’s always a best practice to swap out any internal links after implementing redirects. You can use the Link Explorer tool in Ahrefs’ Site Audit to do this:
- Crawl your site with Site Audit
- Go to the Link Explorer tool
- Click Advanced filter
- Click +Rule
- Change the new rule from “Is source internal” to “Target URL”
- Enter the old redirected URL
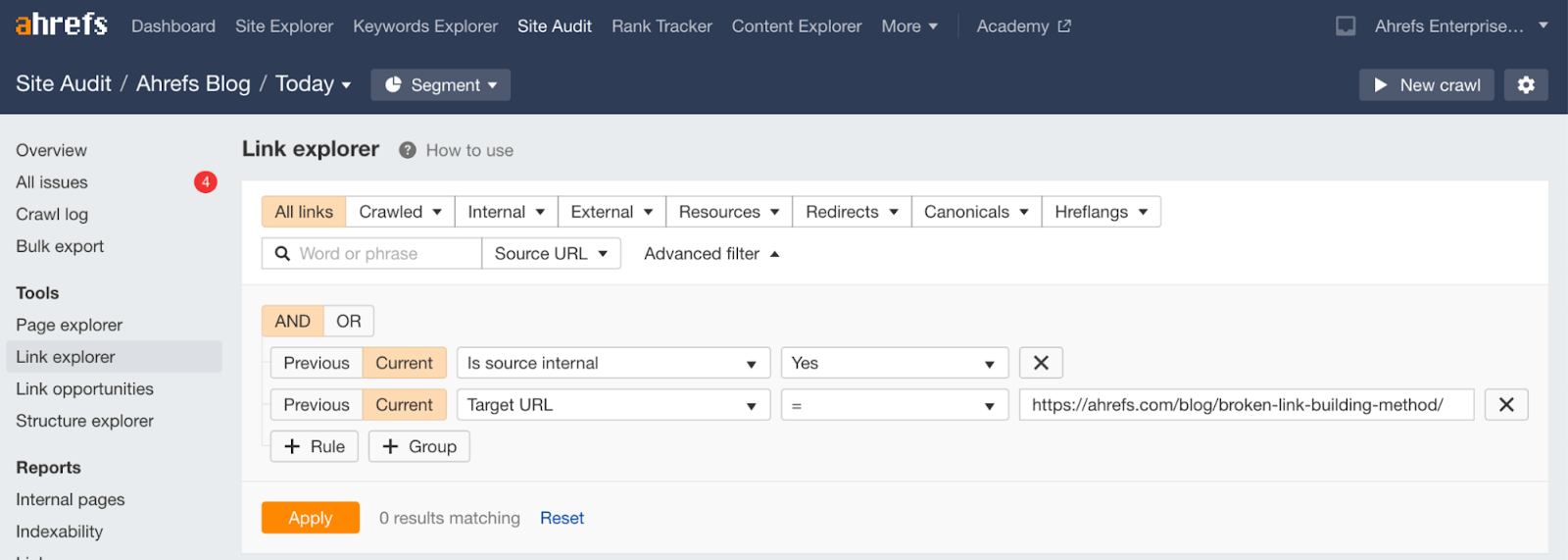
You’ll then see a list of pages internally linking to this URL, along with the anchor text of the link and other details.

Learn more: Internal Links for SEO: An Actionable Guide
Is the solution really this simple?
Most of the time, yes. But as our more experienced readers will know, there’s a lot of “it depends” in SEO, so there are times when things are a bit more nuanced.
For example, we have two very similar guides:
How to Submit Your Website to Search Engines
How to Submit Your Website to Google
Both of these pages fulfill very similar intent, despite targeting slightly different keywords. And if we look at their estimated organic traffic, we see that one page’s traffic pales in comparison to the other:
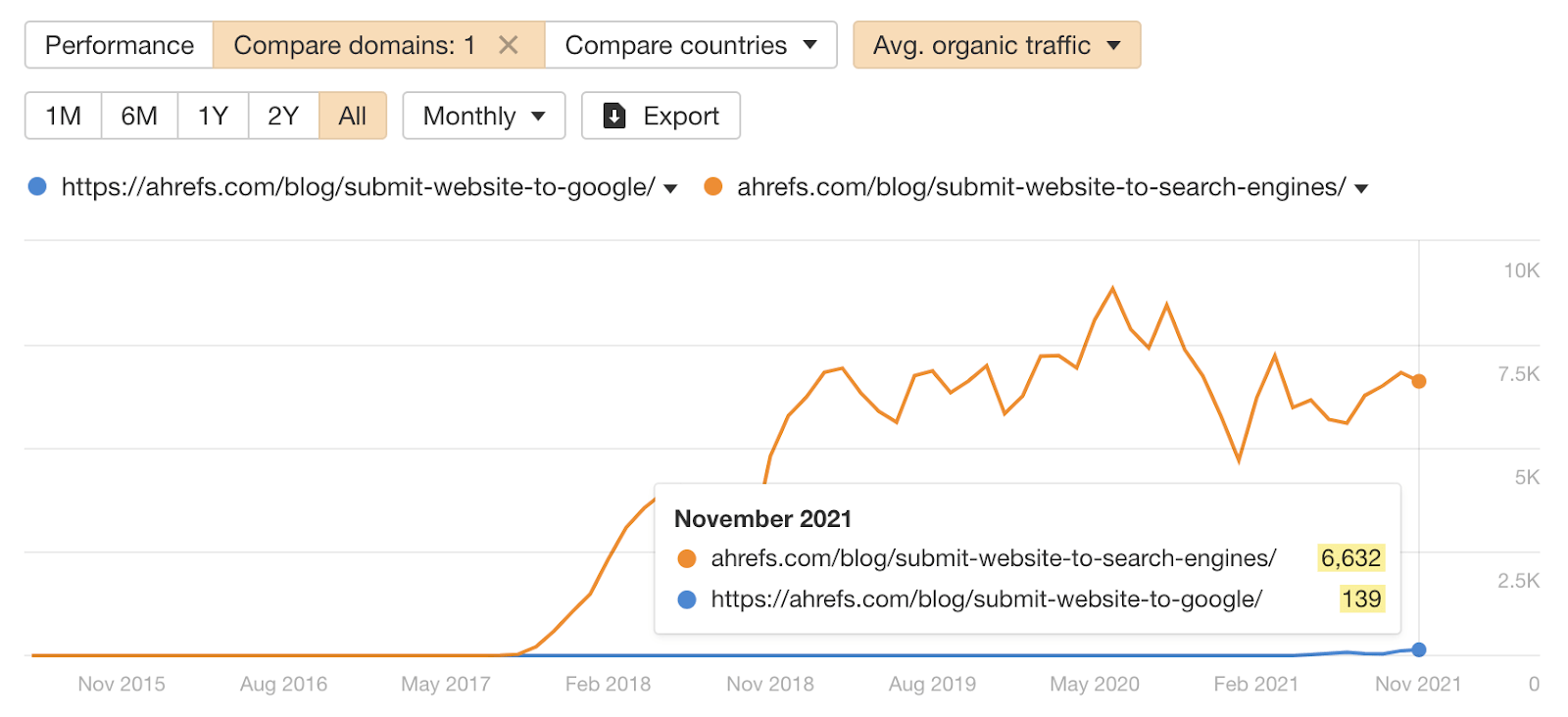
So this looks like a cannibalization issue, and we should probably merge the pages. Right?
Perhaps. But then again, our guide to submitting websites to search engines couldn’t be performing any better in organic search right now.
It ranks #1 for its primary target keyword…
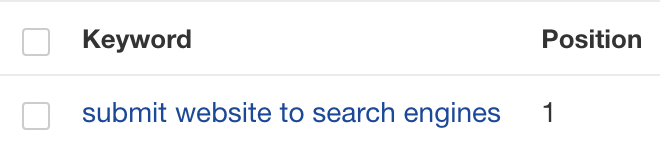
… and seems to have pretty much maxed out its “traffic potential” (it’s getting more traffic than every other similar guide):
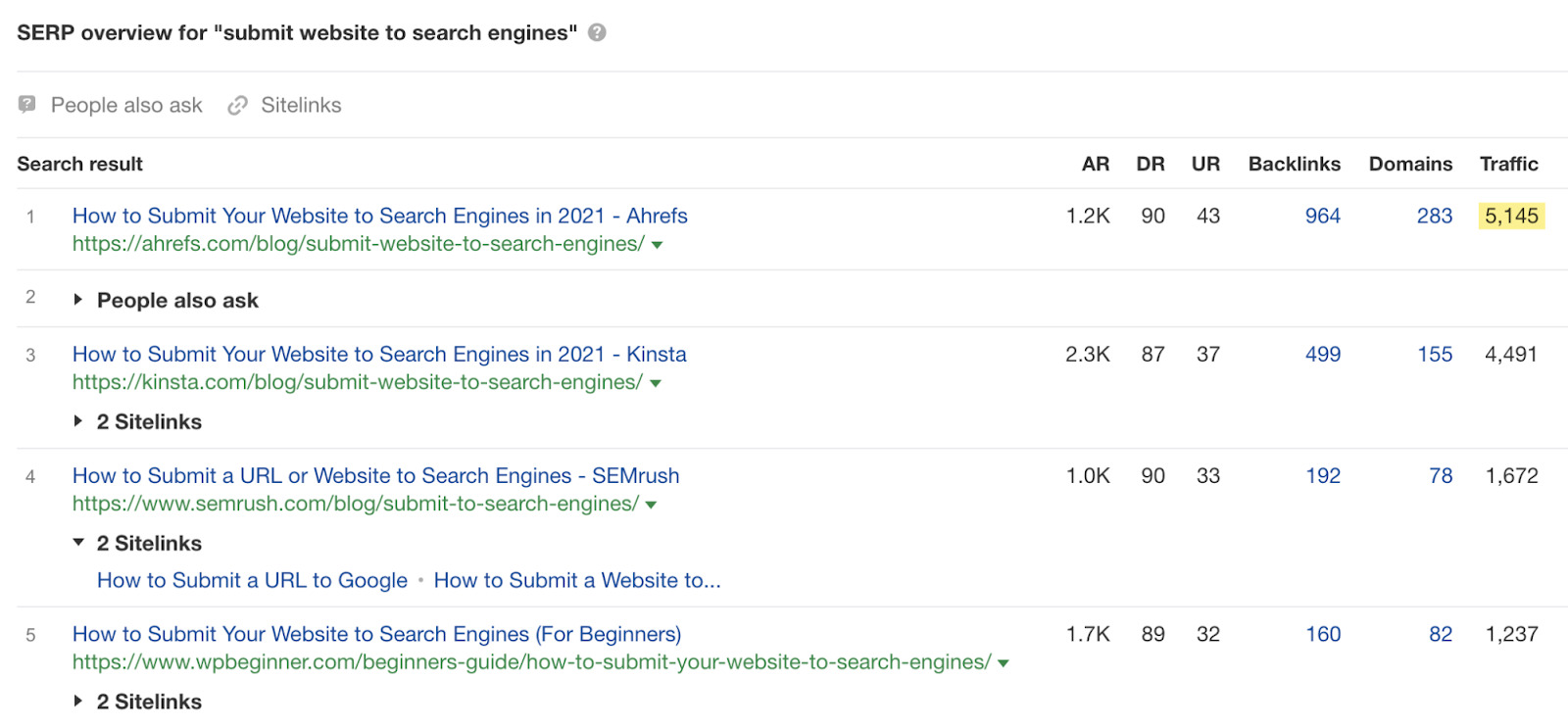
So is this really a cannibalization issue? Is there really anything to be gained by merging these pages? Probably not. And consolidating the posts into one would probably cause us to lose the small amount of organic traffic that the other guide currently gets. So why bother?
Another example of a nuanced scenario is targeting the same keyword on multiple pages that fulfill different intents. This is fine if the keyword has mixed intent, and this usually isn’t a real cannibalization issue. Sure, you may see some keyword overlap or periodic rank swaps. But each page will usually get traffic from its own bucket of long-tail keywords.
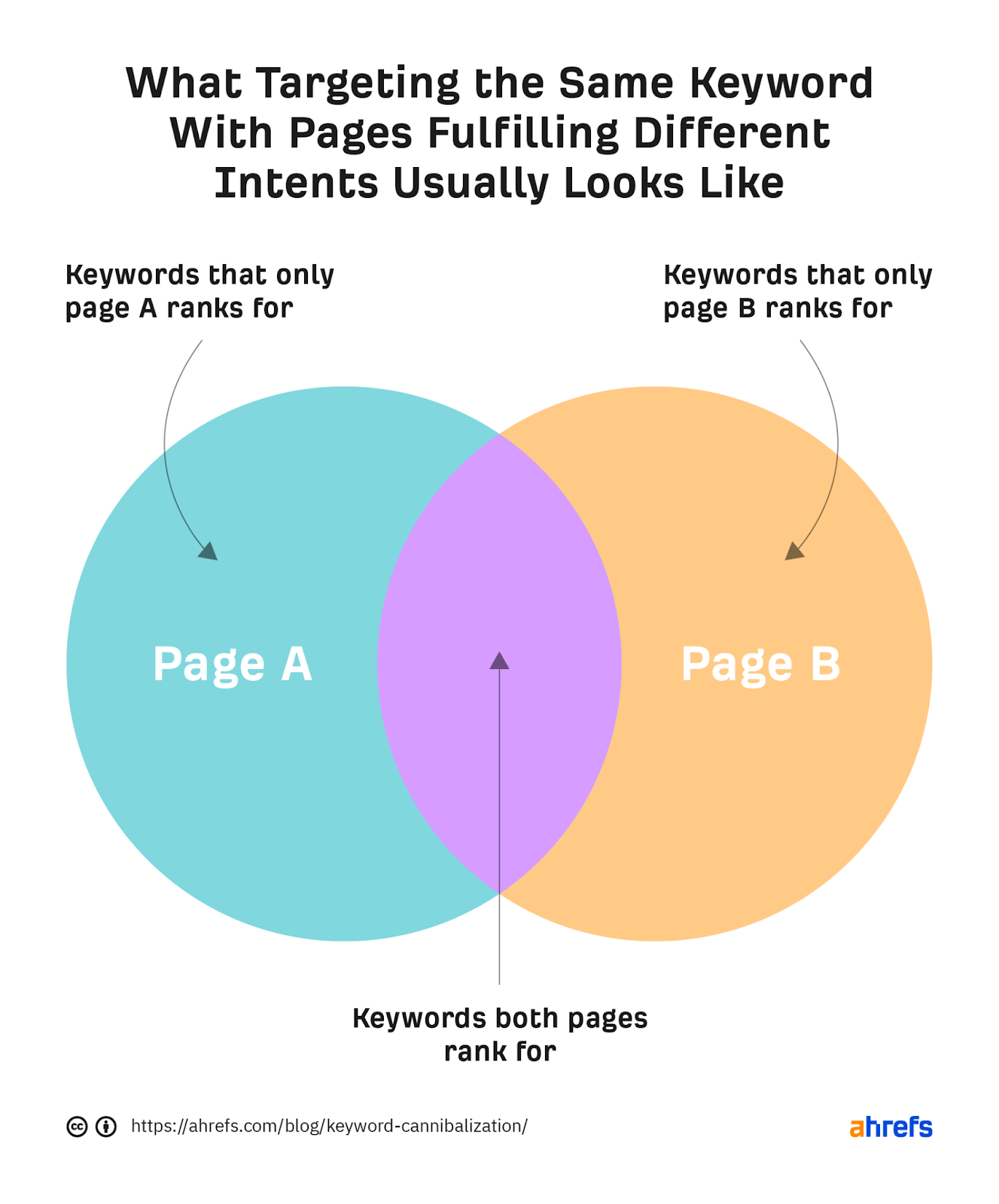
(Again, this is why it doesn’t usually make much sense to focus on “fixing” cannibalization at the keyword level. You risk losing traffic from long-tails.)
But what if your analytics tell you that one of these pages has little or no value?
For example, perhaps one is a super ToFu blog post, and the other is a BoFu landing page.
In this case, as long as you’re 100% certain that the low-value blog post has no value to your business, you can delete the page and redirect it to the landing page to consolidate “authority.”
This will likely cause you to lose some organic traffic overall. But it shouldn’t matter, as you identified that traffic as having no value to your business.
People often try to solve cannibalization at the keyword level with seemingly logical solutions that are fundamentally flawed in practice. Let’s take a closer look at these, so you know what not to do.
Delete the page
This is rarely a good solution unless the page has no value for your business (discussed previously) or ranks for only the “cannibalizing” keyword. Both of these scenarios are pretty unlikely, so this is a rare thing to do in the face of cannibalization.
Noindex the page
Noindexing causes search engines to drop the page from their index, meaning it won’t rank for anything. This is a terrible way to fix cannibalization and, again, highlights the reason why tackling cannibalization at the keyword level is almost always a bad idea.
Recommended reading: Robots Meta Tag & X‑Robots-Tag: Everything You Need to Know
Canonicalize the page
This is only a viable solution when dealing with multiple pages that are near or exact duplicates, otherwise known as duplicate content. Canonicalization is not a way to fix keyword cannibalization.
Recommended reading: Canonical Tags: A Simple Guide for Beginners
De-optimize the page
This one kind of makes sense in theory but is fundamentally flawed because you can’t de-optimize a page for just one keyword. Things don’t work that way. For example, removing all internal links with the cannibalizing keyword as the anchor is likely to affect the page’s rankings for other keywords too. The same is true for removing mentions of the cannibalizing keyword from the page.
Final thoughts
Keyword cannibalization isn’t really a thing—at least not in the way most people understand it. Google doesn’t get “confused” by multiple pages about similar things or pages targeting the same keywords. It knows what’s on those pages and ranks them accordingly.
Does that mean Google will always rank the page you want it to rank? Of course not. But that doesn’t mean that it’s “ranking the wrong page” or that drastic action is required to “fix” the problem. Many common “solutions” to keyword cannibalization do more harm than good.
Got questions? Disagree with me? Ping me on Twitter.


