Each data layer has its own pros and cons, so if you’ve ever wondered why an AI confidently told you something wrong, why one tool seems to know about last week’s news and another doesn’t, or why your competitor’s product gets mentioned tons while yours doesn’t, the answer almost always traces back to which layer answered your question.
This article is a plain-English explanation of where AI knowledge actually comes from—and why that matters for how much you should trust any given response.
Before an AI model ever answers a single question, it goes through a phase called training.
During training, the model ingests billions of text, image, and code examples—public web crawls, books, Wikipedia, code repositories, licensed databases —and learns to predict patterns across all of it. By the time training ends, the model has effectively memorized a statistical snapshot of human knowledge up to that point.
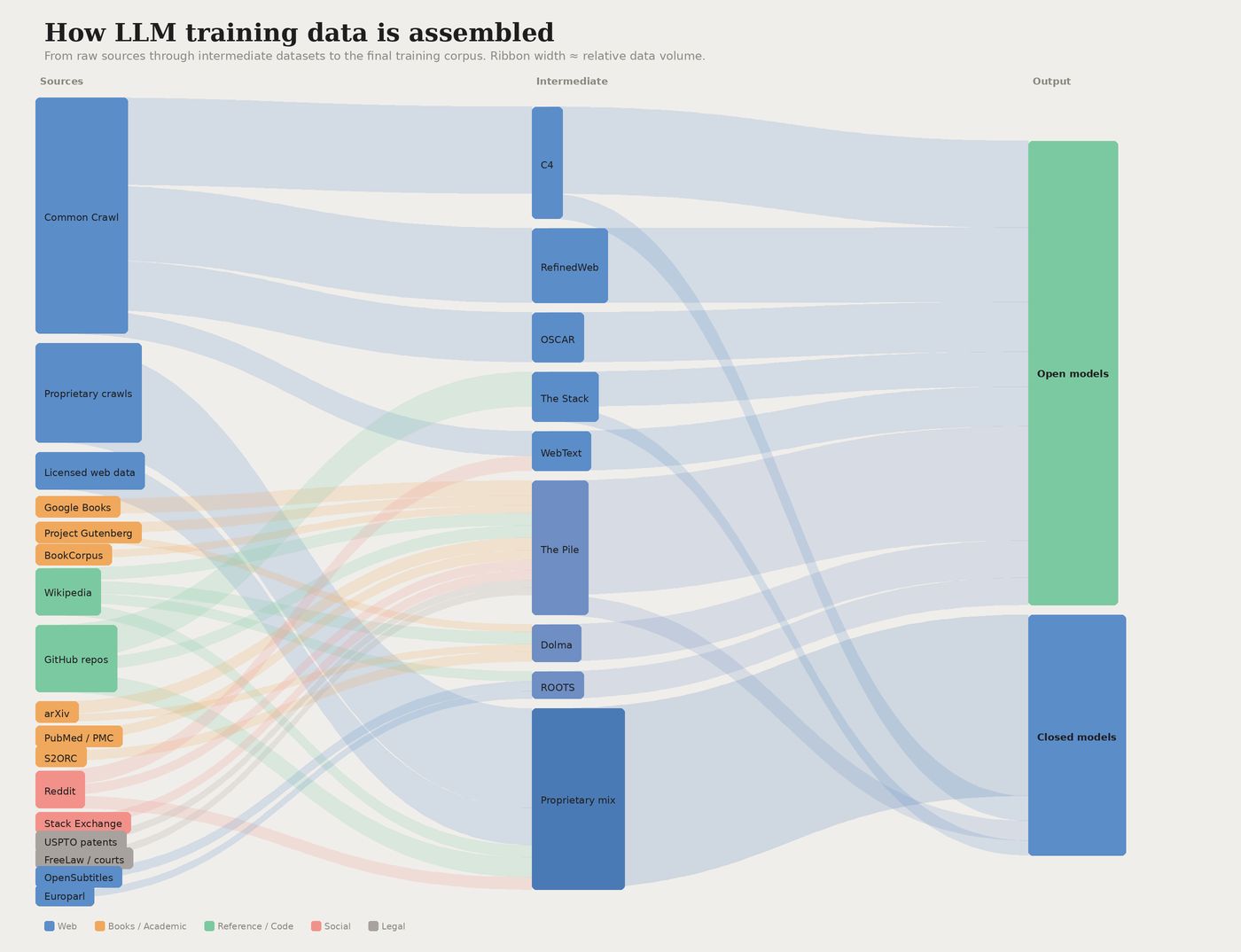
A visualisation of common data sources used in training large language models.
This is how AI models develop their “understanding” of the world. The occurrence of different entities in the training data (like your brand name, or your products: think “Patagonia” or “Nanopuff Hoody”), and the words they commonly co-occur with (like “environmentally-friendly” or “high quality”), shapes the model’s understanding of your brand.
As Gianluca Fiorelli explains:
LLMs learn the relationships between your brand and concepts like ‘gym’ or ‘noise-cancellation.’ These semantic associations directly influence whether and how you’re mentioned.

The scale involved in training is almost hard to picture. Training data for major models is measured in trillions of tokens (roughly, word-chunks). The costs give you a sense of what that requires: training GPT-4 cost an estimated $78 million; Google’s Gemini Ultra cost around $191 million.
The global market for AI training datasets was $3.2 billion in 2025, and it’s projected to hit $16.3 billion by 2033—a 22.6% annual growth rate that reflects how central data has become to the whole enterprise.
Here’s the critical thing to understand: once training ends, the model’s knowledge is frozen. It can’t learn from new events. It has no idea what happened yesterday, or last month, or after whatever date its training data was cut off.
Some providers periodically fine-tune their models on newer data, but that’s still a discrete process—more like issuing a software update than continuously reading the news.
The other major failure mode is hallucination. When a model doesn’t have reliable training data to draw on, it fills the gap with something plausible-sounding—a fabricated citation, a made-up statistic, a confident non-answer (like Google’s AI Overview citing an April Fool’s satire article as a factual source).
The model had no way to know the article was a joke; it just looked authoritative enough to fit the pattern.
Retrieval-Augmented Generation (RAG) is the main technique used to work around the knowledge cutoff problem.
Instead of relying purely on what the model learned during training, RAG lets the model pull in relevant documents at the moment a question is asked, then use those documents as context when generating a response.
Think of it as the difference between a closed-book exam and an open-book one. A training-only model has to answer from memory. A RAG-enabled model can look things up first, then answer. The result is more current and, in principle, more verifiable, because the answer is grounded in actual retrieved content rather than statistical pattern-matching.
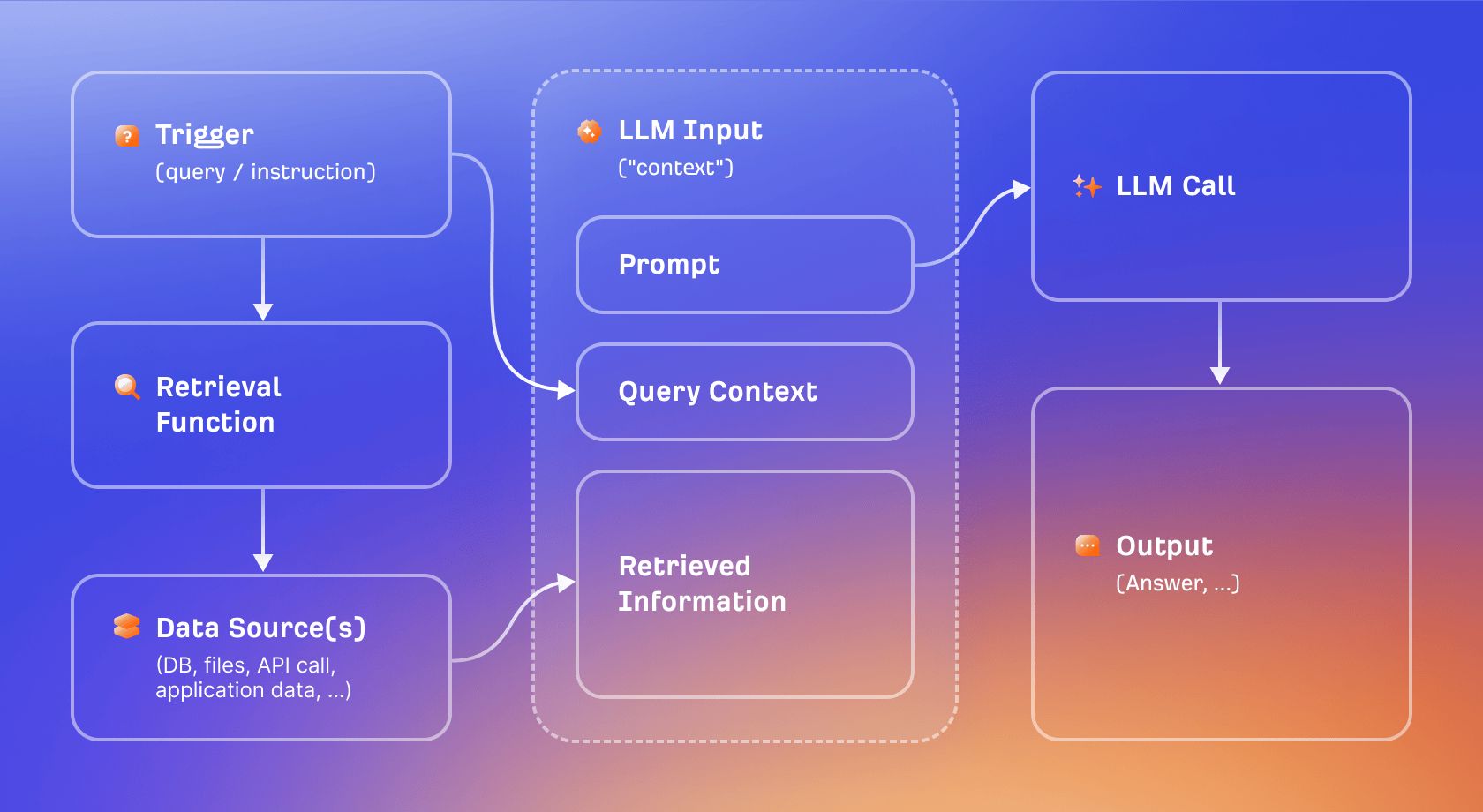
Retrieval augmented generation visualised.
“Grounding” is the broader term for this anchoring. When an AI answer is grounded, it’s tethered to specific retrieved sources, which dramatically reduces the hallucination risk.
As Britney Muller explains:
Grounding comes from ground truth, rooted in statistics and originally cartography, where it literally meant going outside to verify that your map matched reality.

AI search engines like ChatGPT and Gemini use traditional search indexes like Google and Bing for this grounding process. That’s why good SEO, and ranking highly in traditional search, will also improve your AI visibility. The higher you appear in the search index for the term the AI searches for, the higher your chance of being retrieved and cite din the answer.

Not every AI product uses RAG. A base ChatGPT session with browsing disabled, for example, is purely training-based: it has no access to current information and no way to verify its answers against live sources.
The tradeoff is speed and simplicity. Training-only responses are fast, but they’re permanently dated. RAG adds latency and introduces a new failure mode (retrieval errors—pulling in the wrong source, or a poor-quality one), but it makes recency possible.
RAG is one way to get fresh information into an AI response. But modern AI systems are increasingly going further, giving models the ability to call external tools mid-conversation. This is the territory of AI agents.
An AI agent doesn’t just retrieve documents; it can query APIs, run searches, execute code, and interact with live data sources as part of working through a task.
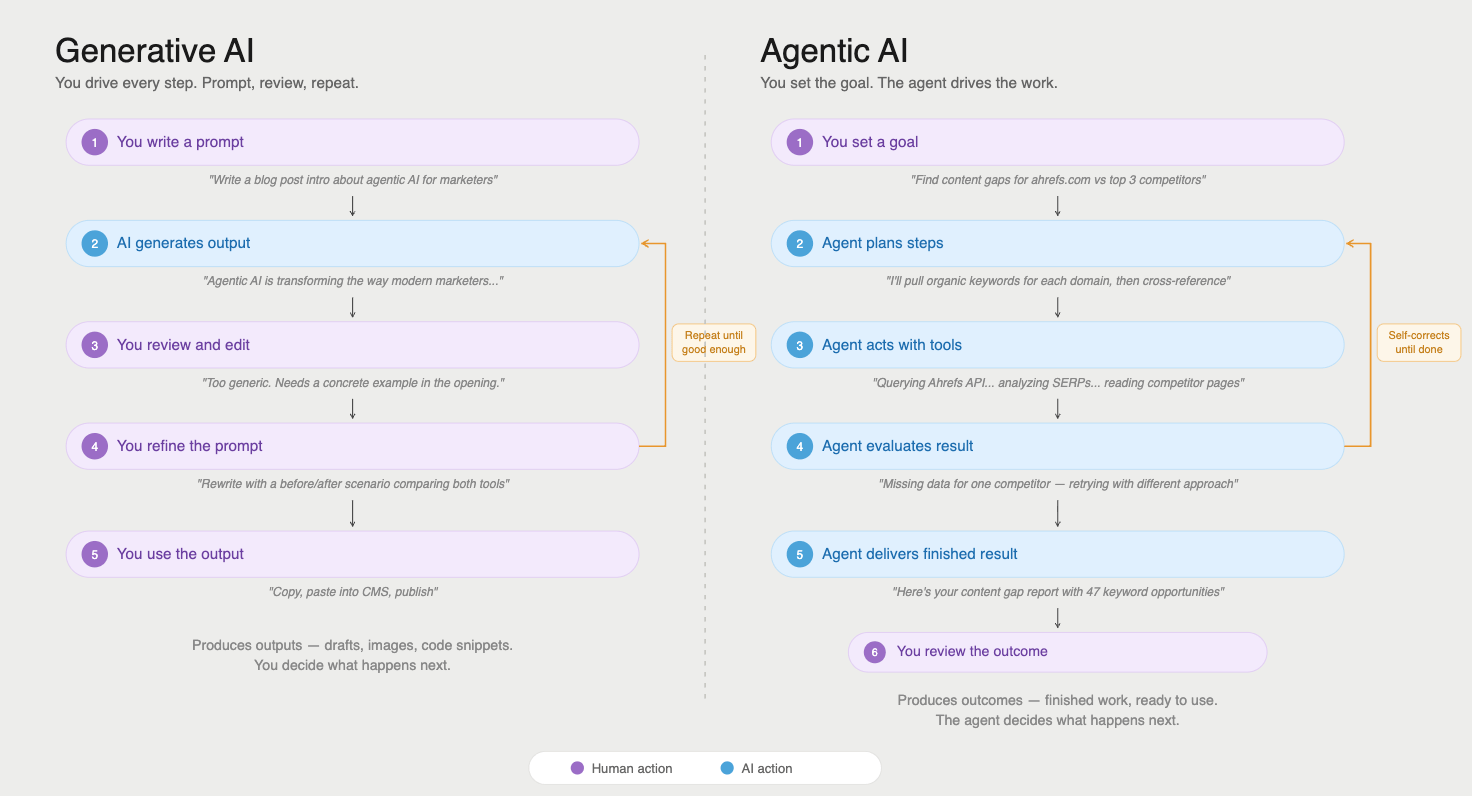
A comparison of using generative AI versus agentic AI.
The emerging infrastructure for this is called Model Context Protocol (MCP), a standard that lets AI models connect to external data sources in a structured way.
A concrete example: Ahrefs has an MCP integration that lets AI agents query Ahrefs data directly during a task, pulling keyword metrics, backlink data, or competitive insights without the user leaving their workflow.
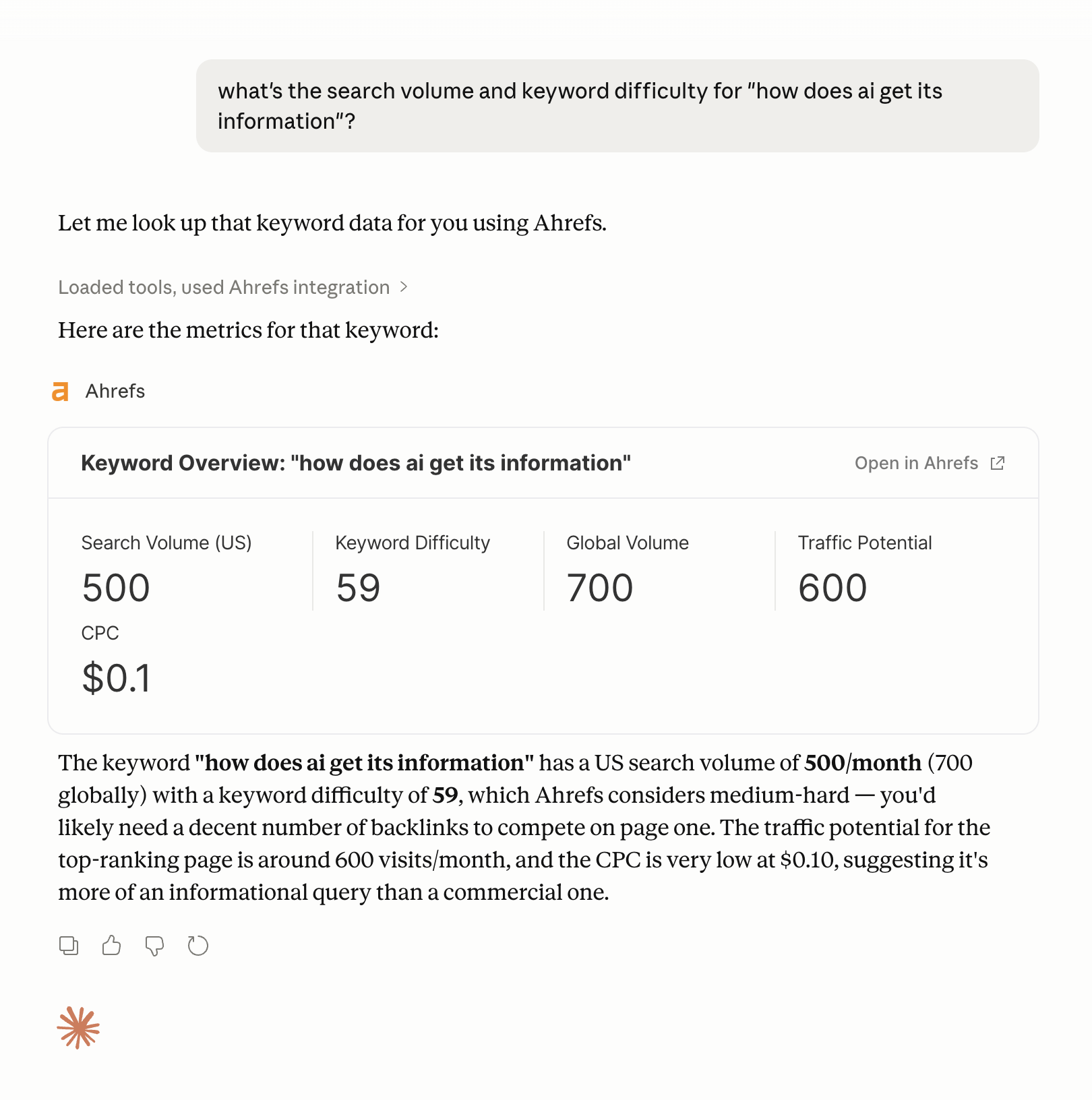
An example of getting keyword data using the Ahrefs MCP in Claude.
Ahrefs’ Agent A takes this further. It’s a marketing AI with direct, unlimited access to Ahrefs’ full internal dataset: keyword data, site metrics, competitive intelligence, the works.
Rather than an AI that has to approximate SEO insights from training data (which goes stale) or retrieve them from public sources (which are incomplete), Agent A works from the actual data.
For marketing and SEO tasks specifically, that’s a huge difference: Agent A can tackle many SEO and marketing workflows, without any hand-holding.
The broader principle is that tool-augmented AI is only as reliable as the tools it calls. If the API returns bad data, the AI produces a bad answer, confidently. The intelligence of the model doesn’t save you from garbage inputs. What it does do is extend the model’s reach far beyond what any training dataset could cover.
When you understand where AI gets its information from, you understand where your brand needs to show-up to stand the best chance of being cited:
- Off-site mentions. If you want AI to accurately represent your brand, the starting point isn’t your website—it’s off-site mentions. Models learn about brands from the sources they trained on: press coverage, third-party reviews, forum discussions, Wikipedia entries, and citations in authoritative publications. A brand that exists only on its own domain is largely invisible to the model’s training data.
- Query fan-out. Beyond brand recognition, you need to think about query fan-out, the adjacent questions AI systems generate around a core topic. A brand ranking for “project management software” should also be targeting content like “how to run a sprint review” or “agile vs. waterfall,” because those are the questions an AI system will surface when a user follows up on the initial query. Creating content that covers the full semantic neighborhood around your core topics increases the chances you appear in that expansion.
- AI accessibility. Technical accessibility still matters, too. Clean HTML, fast load times, and a well-configured robots.txt file affect whether AI crawlers can read your content at all. llms.txt is a proposed standard for helping LLMs navigate your site’s structure, but as of 2026 no major LLM provider has confirmed they respect it (so don’t waste your time).
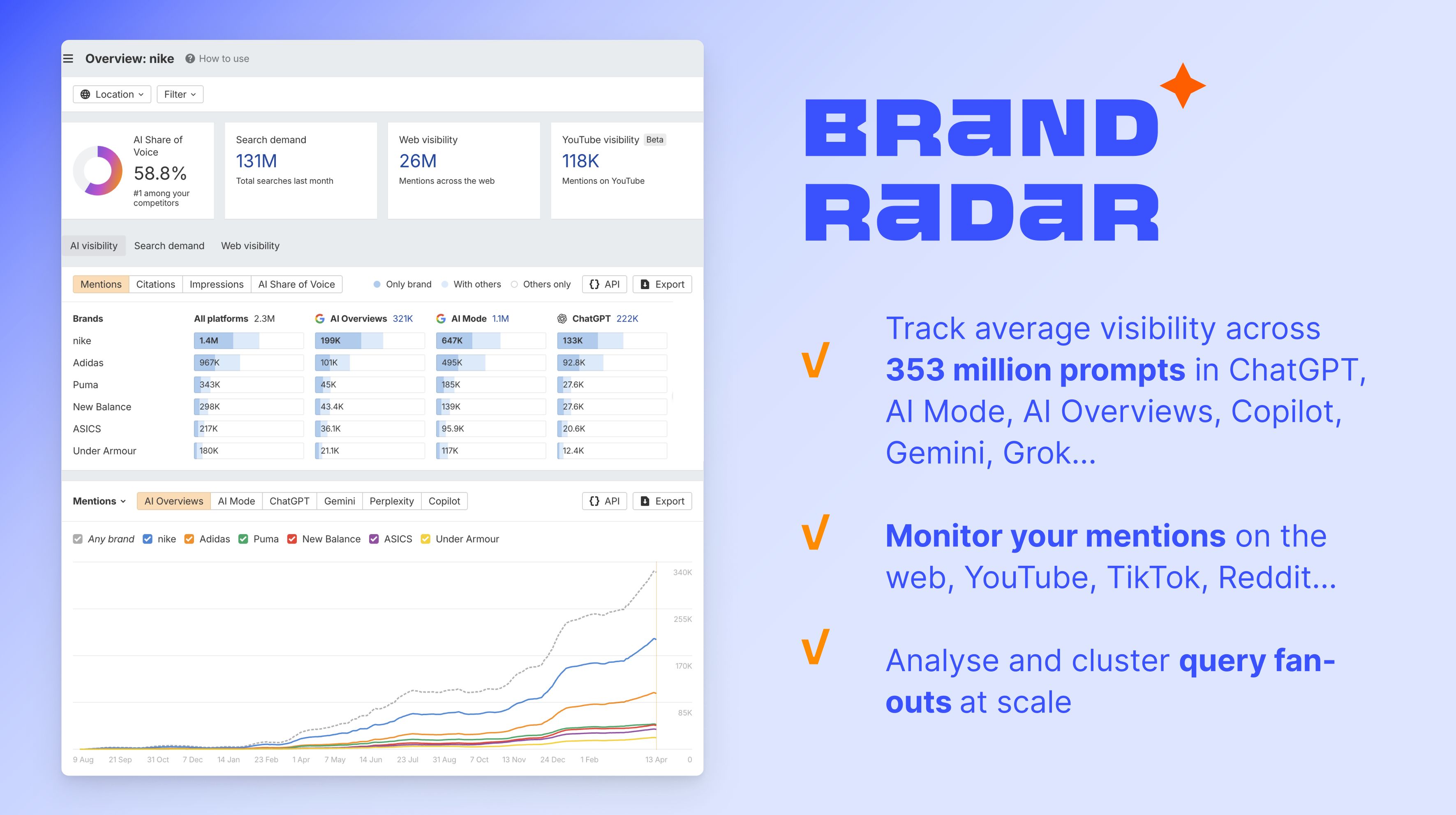
To measure how this is working in practice, Ahrefs’ Brand Radar tracks AI share of voice across ChatGPT, Gemini, Perplexity, AI Overviews, AI Model Grok, and many more, showing how often your brand is mentioned in AI-generated responses relative to competitors. Read this article to learn how it works.
Final thoughts
AI knowledge comes from three layers: frozen training data, retrieved live documents, and connected external tools, like APIs and MCPs. Each has a different accuracy profile, a different relationship with recency, and a different way of failing.
Training data is the foundation—vast, expensive, and static. RAG and grounding add currency at the cost of retrieval reliability. Tool integrations like Ahrefs’ MCP and purpose-built agents like Agent A extend that further, giving AI access to live, authoritative data at the moment it’s needed.
For a deeper look at how AI search engines stitch these layers together to generate answers, check out our guide to how AI search engines work.