Google también tiene más rastreadores que utiliza para tareas específicas y cada uno de ellos se identifica con una cadena de texto diferente denominada user agent. Realmente, al rastrear las webs, las visualiza como lo harían los usuarios en la última versión de Chrome.
Googlebot está operativo gracias a miles de servidores, que son los que determinan a qué velocidad carga una web y qué rastrear una vez en ellas. Eso sí, rastrean más despacio para no saturar los servidores de las webs.
Veamos el proceso que utiliza Google para construir un índice de la web.
Google ha compartido algunas versiones de su pipeline en el pasado. La siguiente es la más reciente:
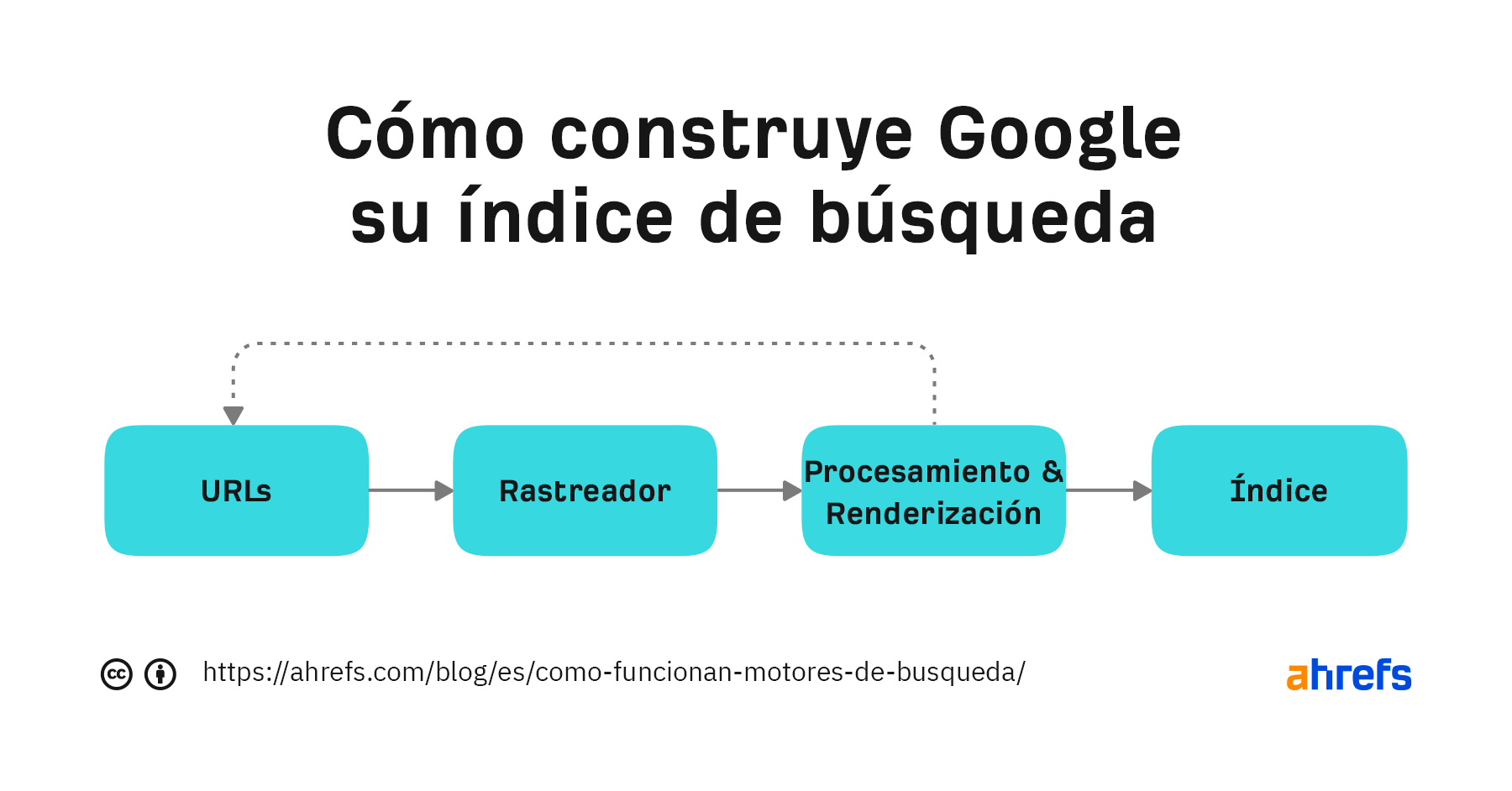
Vuelve a procesar las páginas web y busca cualquier cambio en la página en concreto o en enlaces nuevos. El contenido de las páginas procesadas es lo que se almacena y se puede buscar en el índice de Google. Todos los enlaces nuevos que se encuentran vuelven al grupo de URL que se rastrean.
Se incluyen más detalles sobre este proceso en nuestro artículo sobre cómo funcionan los motores de búsqueda.
Google ofrece varias formas de controlar lo que se rastrea e indexa.
Formas de controlar el rastreo
- Robots.txt: este archivo de tu web te permite controlar lo que se rastrea.
- Nofollow: nofollow es un atributo de enlace o metaetiqueta robots que sugiere que un enlace no debería seguirse. Solo se considera una sugerencia, por lo que puede ignorarse.
- Cambia la velocidad de rastreo: esta herramienta incluida en Google Search Console permite ralentizar el rastreo de Google.
Formas de controlar la indexación
- Borra el contenido: si borras una página, no hay nada que indexar. La desventaja es que nadie más puede acceder a ella.
- Restringe el acceso al contenido: Google no puede iniciar sesión en las webs, por lo que cualquier tipo de protección mediante contraseña o autenticación le impedirá ver el contenido.
- Noindex: un noindex en la metaetiqueta robots indica a los motores de búsqueda que no indexen tu página.
- Herramienta de retirada de URL: el nombre de esta herramienta de Google es un poco engañoso, ya que funciona ocultando temporalmente el contenido. Google seguirá viendo y rastreando este contenido, pero las páginas no aparecerán en los resultados de búsqueda.
- Robots.txt (solo imágenes): bloquear el rastreo de imágenes de Googlebot significa que tus imágenes no se indexarán.
Si no sabes con seguridad qué control de indexación deberías utilizar, consulta el diagrama de flujo de nuestra publicación sobre la retirada de URL de la búsqueda de Google.
Hay muchas herramientas SEO y algunos bots maliciosos que se hacen pasar por Googlebot, lo que les permite acceder a aquellas webs que intentan bloquearlos.
Antes era necesario realizar una búsqueda de DNS para verificar Googlebot, pero, hace poco, Google ha facilitado un poco este proceso al proporcionar una lista de IP públicas que puedes utilizar para verificar que las solicitudes proceden de Google y que puedes comparar con los datos de los registros de tu servidor.
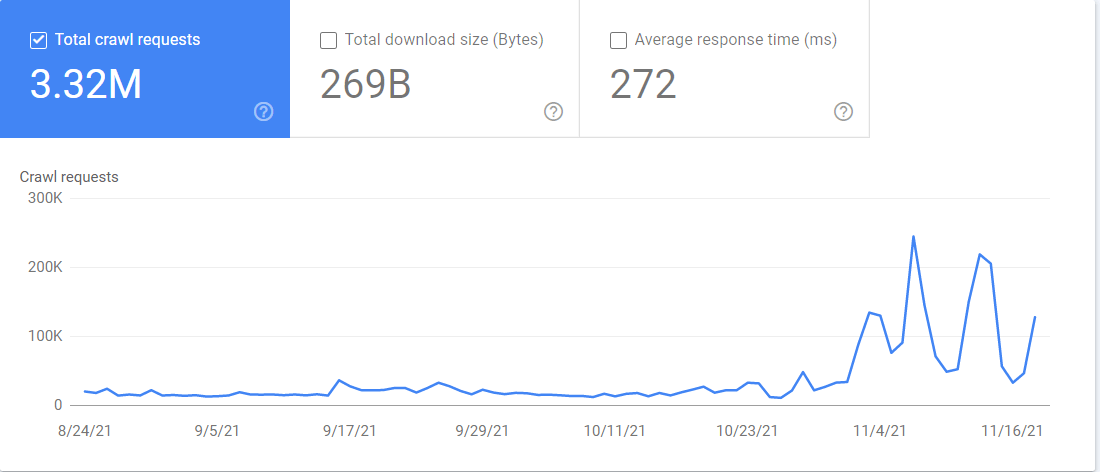
También puedes acceder a un informe de Crawl stats (estadísticas de rastreo) en Google Search Console. Si entras en Configuración > Estadísticas de rastreo, el informe contiene mucha información sobre cómo Google rastrea las webs. Puedes ver qué archivos está rastreando Googlebot y cuándo ha accedido a ellos.
Reflexiones finales
La web es un lugar amplio y caótico. Googlebot tiene que navegar por todo tipo de configuraciones, además de cumplir con los tiempos de inactividad y las restricciones, para poder recopilar así los datos que Google necesita para que su motor de búsqueda funcione.
(Dato curioso: Googlebot suele describirse como un robot y se le conoce acertadamente como Googlebot. También hay una araña mascota que se llama Crawley).
¿Tienes alguna pregunta? Estamos por Twitter.


