
Es gibt mehrere Crawler, die Google für bestimmte Aufgaben einsetzt, und jeder Crawler identifiziert sich selbst mit einer anderen Textzeichenfolge, die “User Agent” genannt wird. Googlebot ist Evergreen, d.h. er sieht Websites so, wie Nutzer sie im neuesten Chrome-Browser sehen würden.
Googlebot läuft auf Tausenden von Rechnern. Sie bestimmen, wie schnell und was auf Websites gecrawlt werden soll. Aber er verlangsamt sein Crawling, um Websites nicht zu überfordern.
Schauen wir uns an, wie Googlebot einen Index des Webs erstellt.
Wie Googlebot das Web crawlt und indexiert
Google hat in der Vergangenheit einige Versionen seiner Pipeline veröffentlicht. Die untenstehende ist die aktuellste.
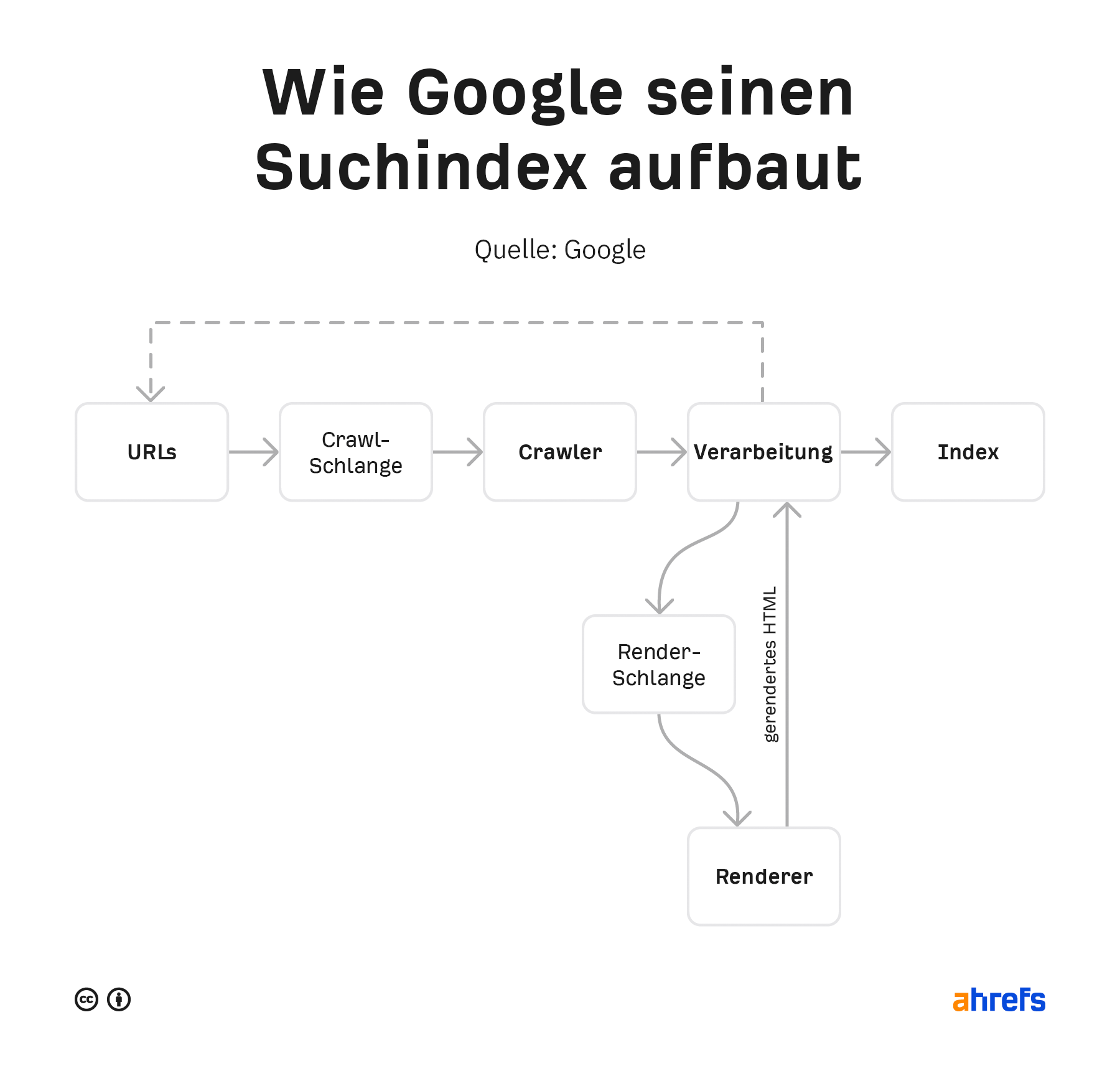
Er verarbeitet diese Daten erneut und sucht nach Änderungen auf der Seite oder neuen Links. Der Inhalt der gerenderten Seiten wird in Googles Index gespeichert und durchsuchbar gemacht. Alle neuen Links, die gefunden werden, wandern zurück zur Sammlung der URLs, die gecrawlt werden sollen.
Mehr Details zu diesem Prozess findest du in unserem Artikel über die Funktionsweise von Suchmaschinen.
Wie du den Googlebot kontrollierst
Google gibt dir ein paar Möglichkeiten, um zu kontrollieren, was gecrawlt und indexiert wird.
Wie du das Crawlen kontrollierst
- Robots.txt – Mit dieser Datei auf deiner Website kannst du kontrollieren, was gecrawlt wird.
- Nofollow – Nofollow ist ein Link-Attribut oder Meta-Robots-Tag, das darauf hinweist, dass einem Link nicht gefolgt werden sollte. Es wird nur als Hinweis betrachtet und kann daher ignoriert werden.
- Change your crawl rate – Mit diesem Tool in der Google Search Console kannst du das Crawling von Google verlangsamen.
Wie du das Indexieren kontrollierst
- Lösche deinen Inhalt — Wenn du eine Seite löschst, gibt es nichts mehr zu indexieren. Der Nachteil dabei ist, dass auch kein anderer darauf zugreifen kann.
- Zugriff auf den Inhalt einschränken — Google loggt sich nicht in Websites ein, also verhindert jede Art von Passwortschutz oder Authentifizierung, dass es den Inhalt sieht.
- Noindex — Ein Noindex im Meta-Robots-Tag weist Suchmaschinen an, deine Seite nicht zu indexieren.
- URL-Entfernungstool — Der Name dieses Tools von Google ist etwas irreführend, denn es funktioniert so, dass es den Inhalt vorübergehend ausblendet. Google sieht und crawlt diese Inhalte weiterhin, aber die Seiten werden nicht in den Suchergebnissen angezeigt.
- Robots.txt (nur Bilder) — Wenn du Googlebot Image am Crawlen hinderst, bedeutet das, dass deine Bilder nicht indexiert werden.
Wenn du dir nicht sicher bist, welche Indexierungskontrolle du verwenden solltest, schau dir unser Flussdiagramm in unserem Beitrag über das Entfernen von URLs aus der Google-Suche an.
Ist es wirklich Googlebot?
Viele SEO-Tools und einige bösartige Bots geben sich als Googlebot aus. Dadurch können sie auf Websites zugreifen, die versuchen, sie zu blockieren.
In der Vergangenheit musstest du einen DNS-Lookup durchführen, um Googlebot zu verifizieren. Kürzlich hat Google es aber noch einfacher gemacht und eine Liste mit öffentlichen IPs zur Verfügung gestellt, mit der du überprüfen kannst, ob die Anfragen von Google stammen. Du kannst sie mit den Daten in deinen Serverprotokollen vergleichen.
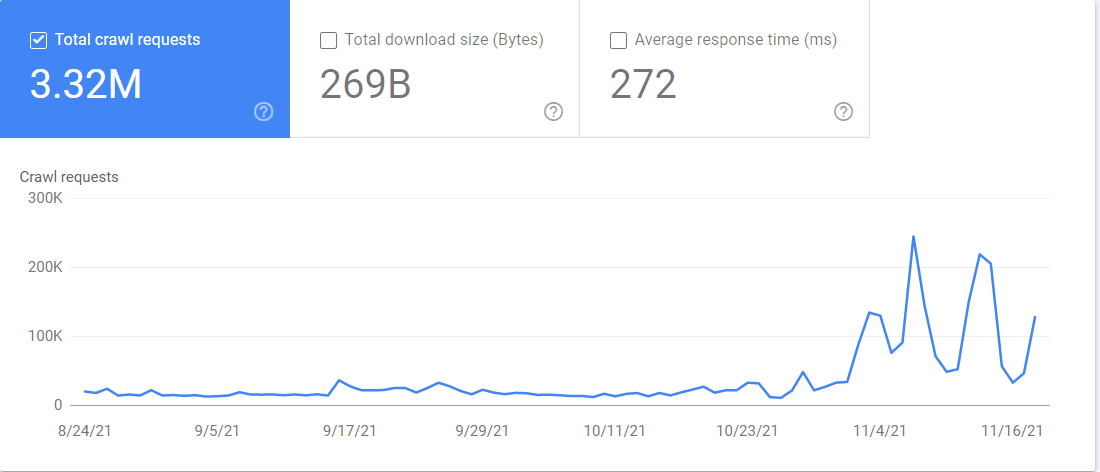
Du hast auch Zugang zu einem “Crawl-Statistik”-Bericht in der Google Search Console. Wenn du zu Einstellungen > Crawl-Statistiken gehst, enthält der Bericht eine Menge Informationen darüber, wie Google deine Website crawlt. Du kannst sehen, welcher Googlebot welche Dateien crawlt und wann er auf sie zugegriffen hat.
Fazit
Das Internet ist ein großer und unübersichtlicher Ort. Der Googlebot muss sich durch all die verschiedenen Setups, Ausfallzeiten und Einschränkungen bewegen, um die Daten zu sammeln, die Google für seine Suchmaschine benötigt.
Zum Schluss noch ein lustiger Fakt: Googlebot wird normalerweise als Roboter dargestellt und treffend als “Googlebot” bezeichnet. Es gibt auch ein Spinnenmaskottchen, das “Crawley” heißt.
Noch Fragen? Schreib mir auf Twitter.


