
Das ist ein wichtiger Punkt, den es zu verstehen gilt. Nicht nur, dass die Verwendung der falschen Methode manchmal dazu führt, dass Seiten nicht wie beabsichtigt aus dem Index entfernt werden, sondern es kann sich auch negativ auf die SEO auswirken.
Damit du schnell entscheiden kannst, welche Methode der Entfernung für dich am besten geeignet ist, haben wir ein Flussdiagramm erstellt, damit du zum entsprechenden Abschnitt des Artikels springen kannst.
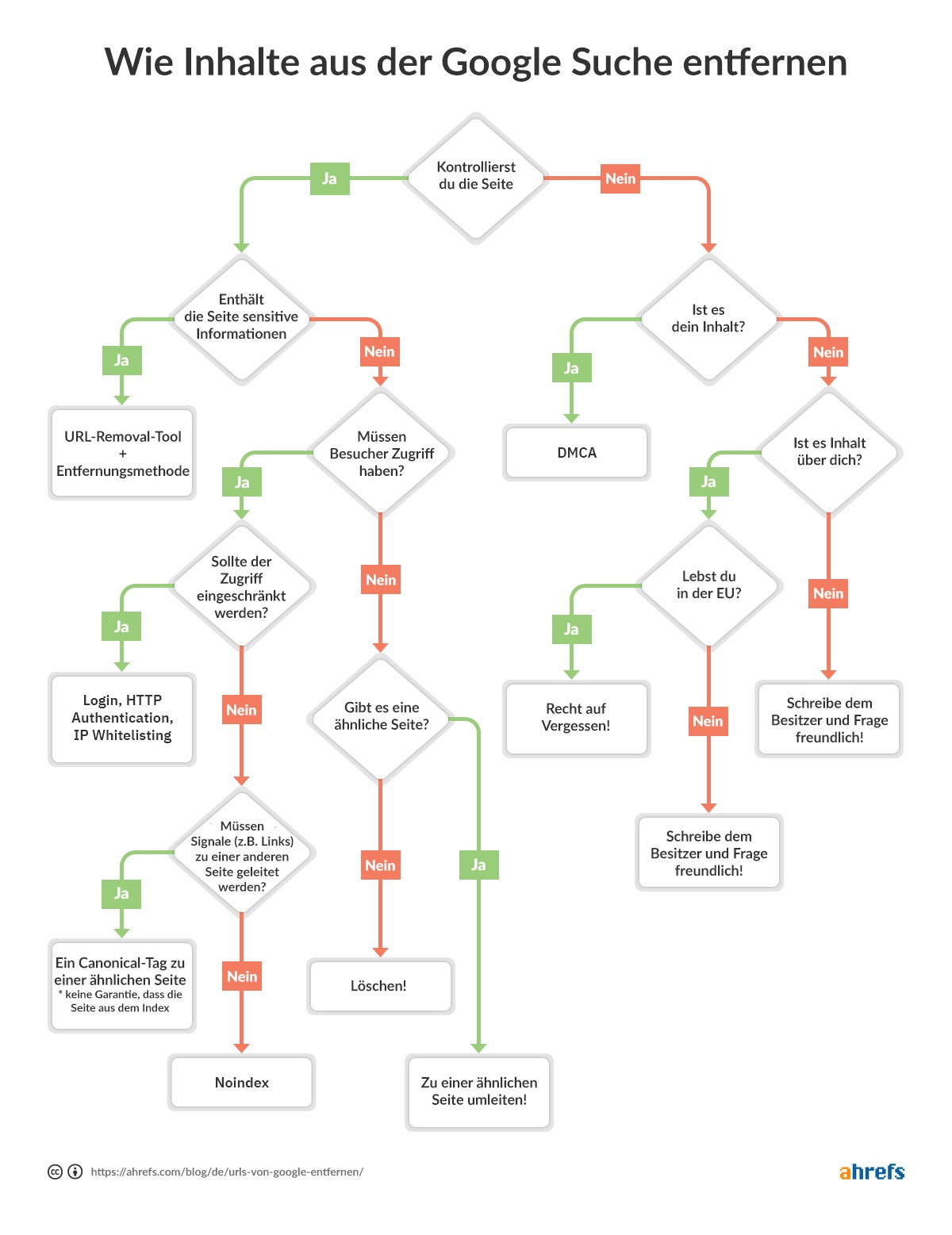
Flussdiagramm, das dir bei der Entscheidung hilft, wie du deine Seiten aus Google entfernen kannst.
In diesem Beitrag wirst du lernen:
- Wie überprüft man, ob eine URL indiziert ist?
- Fünf Möglichkeiten zum Entfernen von URLs aus Google
- Wie man Entfernungen priorisiert
- Häufig zu vermeidende Fehler bei der Entfernung
- Wie du Inhalte entfernen kannst, die sich nicht auf deiner Website befinden
- Wie man Bilder entfernt
Ich sehe SEOs sehr häufig mit Hilfe des „site:“-Operators zu prüfen, ob ein Inhalt in Google indiziert ist (z.B. site:https://ahrefs.com). „site:“-Suchanfragen können nützlich sein, um die Seiten oder Abschnitte einer Website zu identifizieren, die problematisch sein könnten, wenn sie in den Suchergebnissen angezeigt werden. Du musst jedoch vorsichtig sein, da es sich nicht um normale Suchanfragen handelt und dir nicht wirklich zeigt, ob eine Seite indiziert ist. Du kannst Seiten anzeigen, die Google bekannt sind, aber das bedeutet nicht, dass sie in normalen Suchergebnissen ohne den „site:“-Operator angezeigt werden können.
Zum Beispiel kann die „site:“-Suche immer noch Seiten anzeigen, die auf eine andere Seite umleiten oder kanonisiert sind. Wenn du nach einer bestimmten Website fragst, zeigt Google möglicherweise eine Seite aus dieser Domain mit dem Inhalt, Titel und der Beschreibung aus einer anderen Domain an. Nimm zum Beispiel moz.com, das früher seomoz.org war. Alle regulären Nutzeranfragen, die zu Seiten auf moz.com führen, zeigen moz.com in den SERPs an, während site:seomoz.org seomoz.org in den SERPs wie unten dargestellt anzeigt.
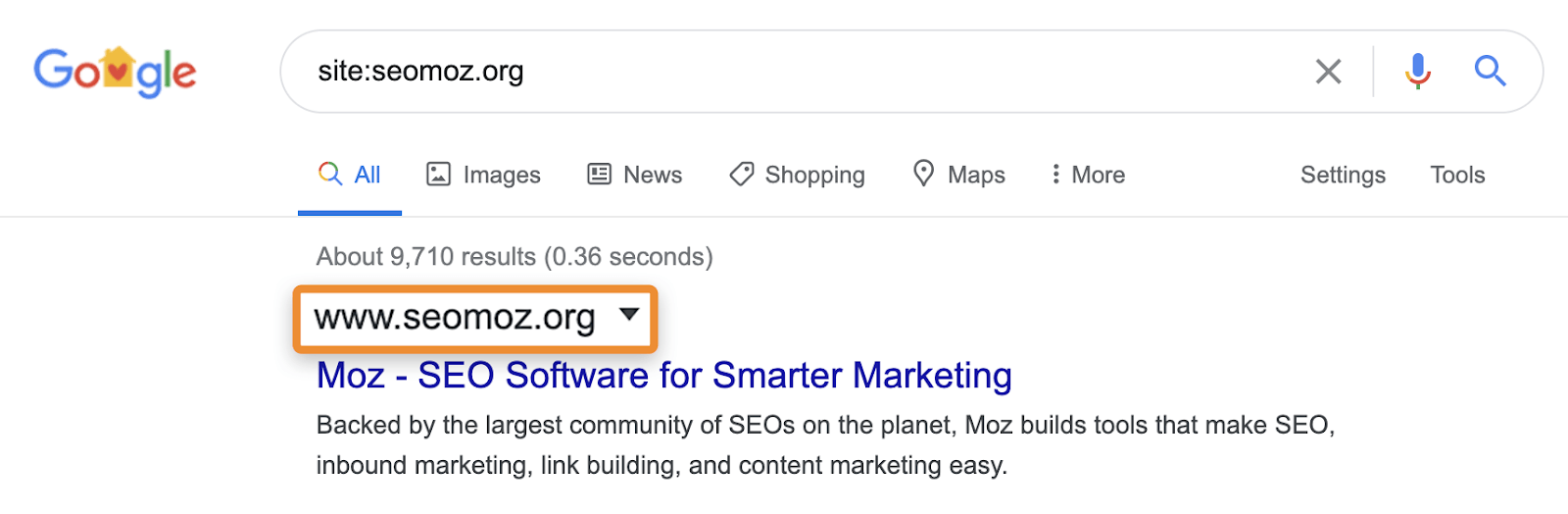
Der Grund für diese wichtige Unterscheidung ist, dass sie SEOs dazu verleiten kann, Fehler zu machen, wie z.B. das aktive Blockieren oder Entfernen von URLs aus dem Index für die alte Domain, was eine Konsolidierung von Signalen wie PageRank verhindert. Ich habe viele Fälle mit Domain-Migrationen gesehen, bei denen Leute glauben, dass sie während der Migration einen Fehler gemacht haben, weil diese Seiten immer noch für site:alte-domain.com angezeigt werden und am Ende aktiv ihre Website schädigen, während sie versuchen, das Problem zu „beheben“.
Die bessere Methode zur Überprüfung der Indexierung ist die Verwendung des Indexabdeckungsberichts in der Google-Suchkonsole oder des URL-Inspektionstools für eine einzelne URL. Mit diesen Tools erfährst du, ob eine Seite indiziert ist, und erhälst zusätzliche Informationen darüber, wie Google die Seite behandelt. Wenn du keinen Zugriff darauf hast, durchsuche Google einfach nach der vollständigen URL deiner Seite.
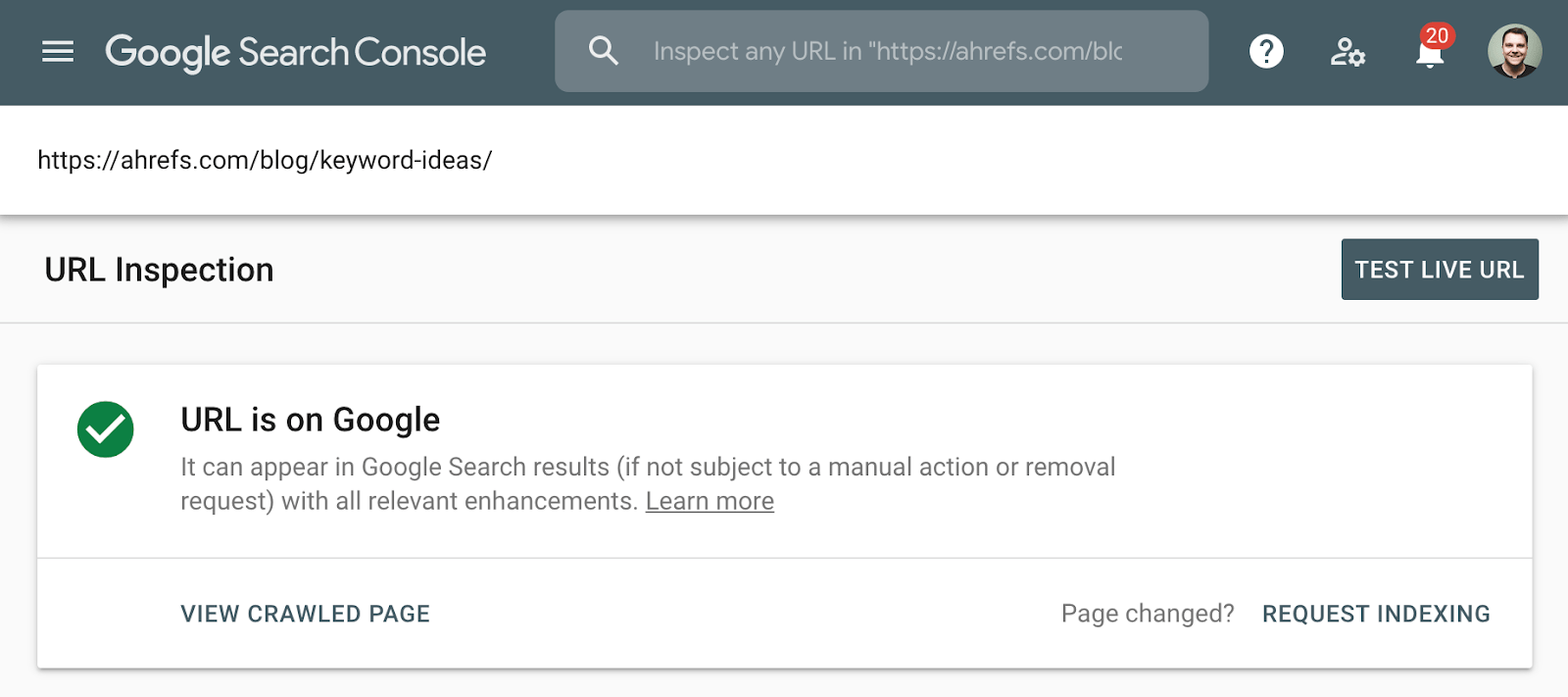
Screenshot des URL-Inspektionstools in der Google-Suchkonsole.
Wenn du in Ahrefs die Seite in unserem „Top Seiten“-Bericht oder im Ranking für organische Keywords findest, bedeutet dies in der Regel, dass wir sie bei normalen Suchanfragen im Ranking gesehen haben, und ist ein guter Hinweis darauf, dass die Seite indiziert wurde. Beachte, dass die Seiten indiziert waren, als wir sie gesehen haben, aber das kann sich geändert haben. Überprüfen das Datum, an dem wir die Seite zuletzt für eine Suchanfrage gesehen haben.
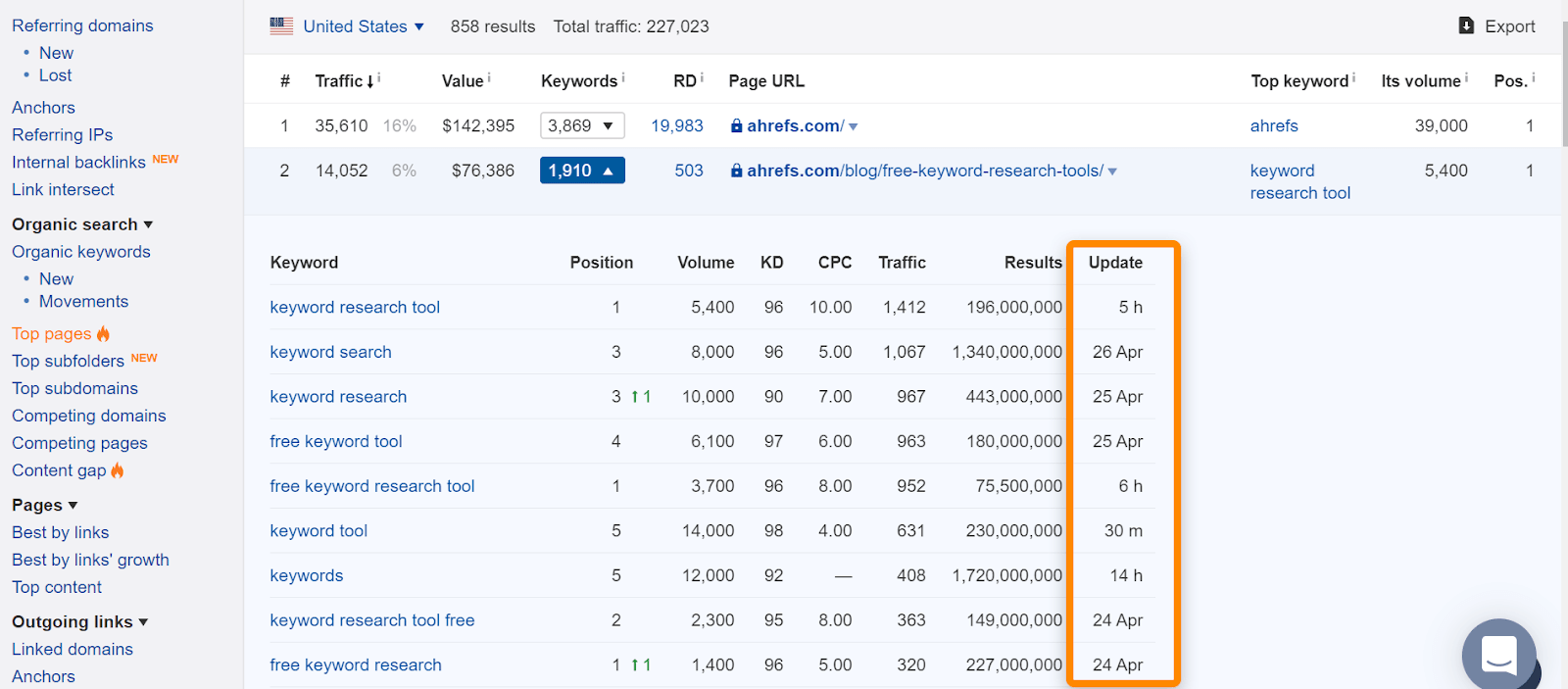
Wenn es ein Problem mit einer bestimmten URL gibt und diese aus dem Index entfernt werden muss, folge dem Flussdiagramm am Anfang des Artikels, um die richtige Entfernungsoption zu finden, und springe dann zu dem entsprechenden Abschnitt weiter unten.
Wenn du die Seite entfernt und entweder den Statuscode 404 (nicht gefunden) oder 410 (verschwunden) zurückgibst, wird die Seite kurz nach dem erneuten Crawlen der Seite aus dem Index entfernt. Solange sie nicht entfernt wurde, wird die Seite möglicherweise noch in den Suchergebnissen angezeigt. Und selbst wenn die Seite selbst nicht mehr verfügbar ist, kann eine zwischengespeicherte Version der Seite vorübergehend verfügbar sein.
Wenn du vielleicht eine andere Option brauchst:
- Ich brauche eine sofortige Entfernung. Siehe den Abschnitt URL-Entfernungstool.
- Ich muss Signale wie Links konsolidieren. Siehe den Abschnitt über die Kanonisierung.
- Ich brauche die für Benutzer verfügbare Seite. Prüfen Sie, ob die Abschnitte Noindex oder Zugriffsbeschränkung für Ihre Situation geeignet sind.
Entfernungsoption 2: Noindex
Ein Noindex-Meta-Robots-Tag oder eine x‑robots-Header-Antwort weist Suchmaschinen an, eine Seite aus dem Index zu entfernen. Das Meta-Robots-Tag funktioniert für Seiten, wo die x‑robots-Antwort für Seiten und zusätzliche Dateitypen wie PDFs funktioniert. Damit diese Tags angezeigt werden, muss eine Suchmaschine in der Lage sein, die Seiten zu crawlen – stelle also sicher, dass sie nicht in der robots.txt blockiert sind. Beachte auch, dass das Entfernen von Seiten aus dem Index die Konsolidierung von Links und anderen Signalen verhindern kann.
Beispiel für einen Meta-Robots noindex:
<meta name="robots" content="noindex">
Beispiel für das x‑robots noindex-Tag in der Header-Antwort:
HTTP/1.1 200 OK X-Robots-Tag: noindex
Wenn du möglicherweise eine andere Option benötigst:
- Ich möchte nicht, dass Benutzer auf diese Seiten zugreifen. Siehe den Abschnitt über die Zugangsbeschränkung.
- Ich muss Signale wie Links konsolidieren. Siehe den Abschnitt über die Kanonisierung.
Entfernungsoption 3: Beschränkung des Zugangs
Wenn du möchtest, dass die Seite für einige Benutzer, aber nicht für Suchmaschinen zugänglich ist, dann ist wahrscheinlich eine dieser drei Optionen für dich geeignet:
- eine Art Anmeldesystem (Login);
- HTTP-Authentifizierung (wobei für den Zugang ein Passwort erforderlich ist);
- IP-Whitelisting (das nur bestimmten IP-Adressen den Zugriff auf die Seiten erlaubt).
Diese Art des Setups eignet sich am besten für Dinge wie interne Netzwerke, Inhalte nur für Mitglieder oder für Staging‑, Test- oder Entwicklungs-Sites. Sie ermöglicht einer Gruppe von Benutzern den Zugriff auf die Seite, aber Suchmaschinen können nicht auf sie zugreifen und indizieren die Seiten nicht.
Wenn du gegebenenfalls eine andere Option benötigst:
- Ich brauche eine sofortige Entfernung. Siehe den Abschnitt mit dem URL-Entfernungstool. In diesem speziellen Fall kann es sein, dass du eine sofortigere Entfernung wünschst, wenn der Inhalt, den du zu verbergen versuchst, zwischengespeichert wurde und du verhindern musst, dass Benutzer diesen Inhalt sehen können.
Entfernungsoption 4: URL-Entfernungs-Tool
Der Name für dieses Tool von Google ist leicht irreführend, da es den Inhalt vorübergehend ausblendet. Google wird diesen Content weiterhin sehen und crawlen, aber die Seiten werden für die Nutzer nicht angezeigt. Dieser vorübergehende Effekt hält bei Google sechs Monate an, während Bing ein ähnliches Tool hat, das drei Monate lang funktioniert. Diese Tools sollten in den extremsten Fällen für Dinge wie Sicherheitsprobleme, Datenlecks, persönlich identifizierbare Informationen (PII) usw. verwendet werden. Verwende für Google das Removals-Tool und schau dir im Falle von Bing an, wie man URLs blockiert.
Du musst noch eine andere Methode zusammen mit der Verwendung des Entfernungswerkzeugs anwenden, um die Seiten tatsächlich für einen längeren Zeitraum zu entfernen (noindex oder löschen) oder Benutzer am Zugriff auf den Inhalt zu hindern, wenn sie die Links noch haben (löschen oder Zugriff einschränken). Diese Option gibt dir nur eine schnellere Möglichkeit, die Seiten auszublenden, während die Entfernung Zeit zur Bearbeitung hat. Die Bearbeitung des Antrags kann bis zu einem Tag dauern.
Entfernungsoption 5: Kanonisierung
Wenn du mehrere Versionen einer Seite hast und Signale wie z.B. Links zu einer einzigen Version konsolidieren möchtest, dann ist die empfehlenswerte Vorgehensweise eine Form der Kanonisierung. Dies dient vor allem dazu, doppelten Inhalt zu verhindern und gleichzeitig mehrere Versionen einer Seite zu einer einzigen indizierten URL zu konsolidieren.
Du hast mehrere Möglichkeiten der Kanonisierung:
- Canonical Tag. Dadurch wird eine andere URL als die kanonische Version oder die Version, die angezeigt werden soll, angegeben. Wenn Seiten doppelt vorhanden oder sehr ähnlich sind, sollte dies in Ordnung sein. Wenn Seiten zu unterschiedlich sind, kann die kanonische Version ignoriert werden, da es sich lediglich um einen Hinweis und nicht um eine Anweisung handelt.
- Redirects. Eine Weiterleitung führt einen Benutzer und einen Suchroboter von einer Seite zur anderen. 301 ist die von SEOs am häufigsten verwendete Weiterleitung, und sie teilt den Suchmaschinen mit, dass die endgültige URL diejenige sein soll, die in den Suchergebnissen angezeigt wird, und wo die Signale konsolidiert werden. Eine 302 oder temporäre Umleitung teilt den Suchmaschinen mit, dass die ursprüngliche URL diejenige sein soll, die im Index verbleibt und die Signale dort konsolidiert werden.
- URL parameter handling. Ein Parameter wird an das Ende der URL angehängt und enthält normalerweise ein Fragezeichen, wie ahrefs.com?dies=Parameter. Mit diesem Tool von Google kannst du Google mitteilen, wie URLs mit bestimmten Parametern behandelt werden sollen. So kannst du beispielsweise angeben, ob der Parameter den Seiteninhalt ändert oder ob er nur dazu dient, die Nutzung zu verfolgen.
Wenn du mehrere Seiten aus dem Google-Index entfernen musst, sollten diese entsprechend priorisiert werden.
Höchste Priorität: Diese Seiten sind in der Regel sicherheitsrelevant oder beziehen sich auf vertrauliche Daten. Dazu gehören Inhalte, die persönliche Daten (PII), Kundendaten oder urheberrechtlich geschützte Informationen enthalten.
Mittlere Priorität: Hierbei handelt es sich in der Regel um Inhalte, die für eine bestimmte Gruppe von Benutzern bestimmt sind. Firmen-Intranets oder Mitarbeiterportale, Inhalte, die nur für Mitglieder bestimmt sind, sowie Staging‑, Test- oder Entwicklungsumgebungen.
Geringe Priorität: Bei diesen Seiten handelt es sich in der Regel um doppelten Inhalt irgendeiner Art. Einige Beispiele hierfür wären Seiten, die von mehreren URLs aus bedient werden, URLs mit Parametern und wiederum könnten Staging‑, Test- oder Entwicklungsumgebungen umfassen.
Ich möchte im folgenden auf einige der Fehler bei der Entfernung von URLs eingehen, die ich häufig beobachte und was in den einzelnen Szenarien geschieht, damit die Menschen verstehen, warum sie nicht funktionieren.
Noindex in robots.txt
Während Google früher inoffiziell noindex in robots.txt unterstützte, war dies nie ein offizieller Standard, und sie haben die Unterstützung jetzt offiziell entfernt. Viele der Sites, die dies taten, taten dies fälschlicherweise und schadeten sich damit selbst.
Blockieren des Crawlings in robots.txt
Crawling ist nicht dasselbe wie Indexierung. Selbst wenn Google für das Crawling von Seiten blockiert ist, kann eine Seite indiziert werden, wenn es interne oder externe Links zu einer Seite gibt. Google wird nicht wissen, was sich auf der Seite befindet, da sie die Seite nicht crawlen, aber sie wissen, dass eine Seite existiert und schreiben sogar einen Titel, der in den Suchergebnissen angezeigt wird, basierend auf Signalen wie dem Anker-Text von Links zu der Seite.
Nofollow
Dies wird häufig mit noindex verwechselt, und einige Leute verwenden es auf Seitenebene verwenden und erwarten, dass die Seite nicht indiziert wird. Nofollow ist ein Hinweis, und obwohl es ursprünglich verhinderte, dass Links auf der Seite und einzelne Links mit dem nofollow-Attribut gecrawlt werden, ist dies nicht mehr der Fall. Google kann diese Links nun crawlen, wenn es dies wünscht. Nofollow wurde auch für einzelne Links verwendet, um zu versuchen, das Crawlen von Google zu bestimmten Seiten zu verhindern, sowie für die Modellierung des PageRank. Auch dies funktioniert nicht mehr, da nofollow ein Hinweis ist. Wenn die Seite in der Vergangenheit einen anderen Link zu ihr hatte, kann Google immer noch von diesem alternativen Crawling-Pfad erfahren.
Beachte, dass du unter Verwendung dieses Filters im Page Explorer im Site Audit Tool von Ahrefs Seiten mit „nofollow“ in großen Mengen finden kannst.
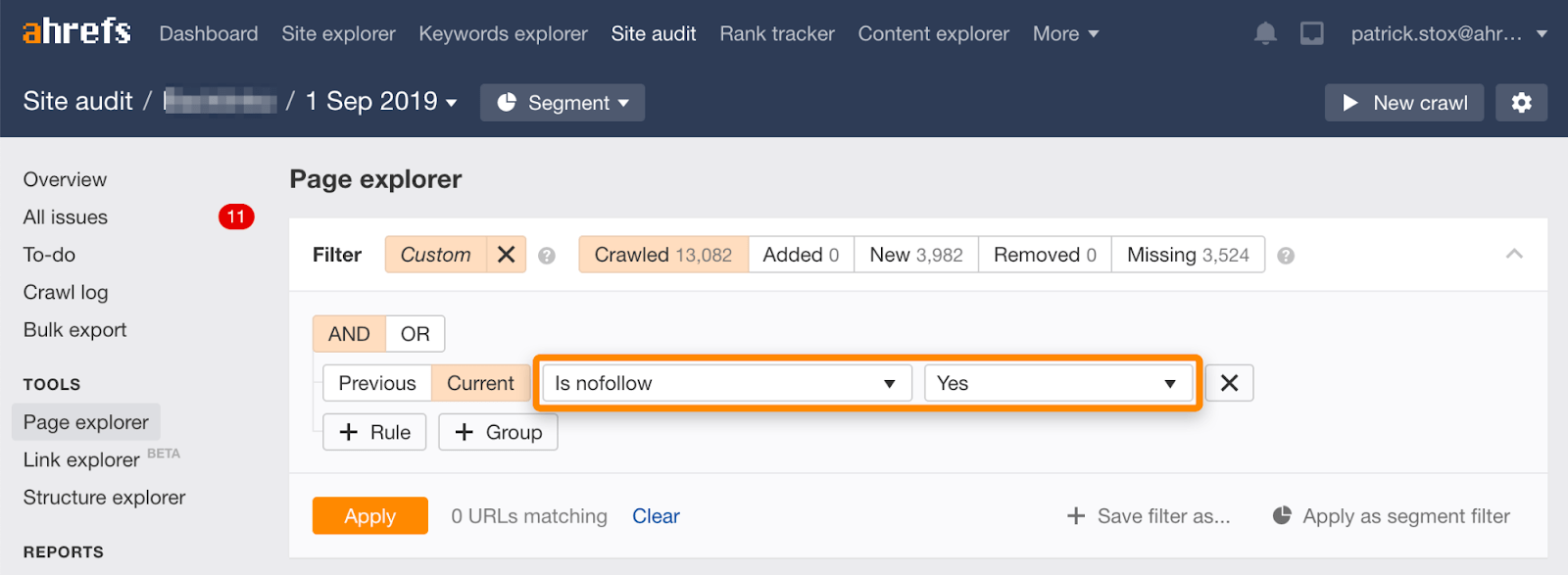
Da es selten sinnvoll ist, allen Links auf einer Seite nicht zu folgen, sollte die Anzahl der Ergebnisse gleich Null oder nahe Null sein. Wenn es übereinstimmende Ergebnisse gibt, bitte ich dich dringend zu prüfen, ob die nofollow-Direktive versehentlich anstelle von noindex hinzugefügt wurde, und gegebenenfalls eine geeignetere Methode zur Entfernung zu wählen.
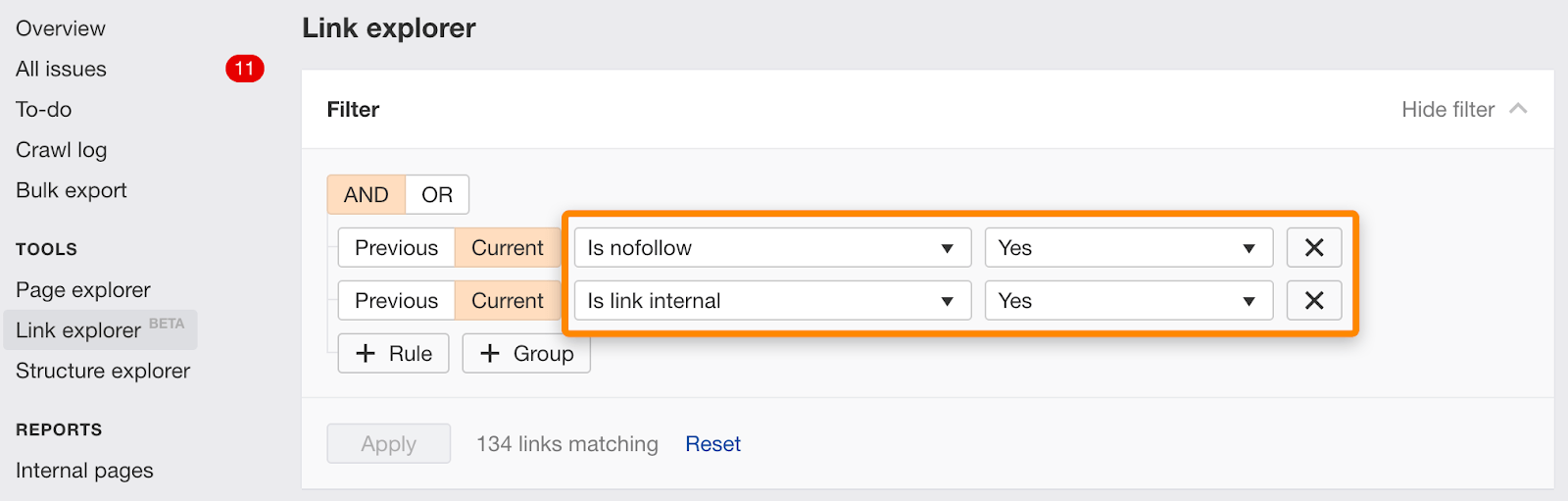
Du kannst auch einzelne Links, die mit nofollow markiert sind, mit diesem Filter im Link Explorer finden.
Noindex und kanonische zu einer anderen URL
Diese Signale sind widersprüchlich. Noindex sagt, dass die Seite aus dem Index entfernt werden soll, und canonical sagt, dass eine andere Seite die Version ist, die indiziert werden soll. Dies könnte bei der Konsolidierung tatsächlich funktionieren, da Google in der Regel den Noindex ignoriert und stattdessen das kanonische Signal als Hauptsignal verwendet. Dies ist jedoch kein absolutes Verhalten. Es ist ein Algorithmus im Spiel, und es besteht das Risiko, dass das Noindex-Tag das gezählte Signal sein könnte. Wenn das der Fall ist, dann werden die Seiten nicht richtig konsolidiert.
Beachte, dass du unter Verwendung der nachfolgenden Filter im Page Explorer im Site Audit-Tool nicht indizierte Seiten mit nicht selbstreferenzierenden Canonicals finden kannst:
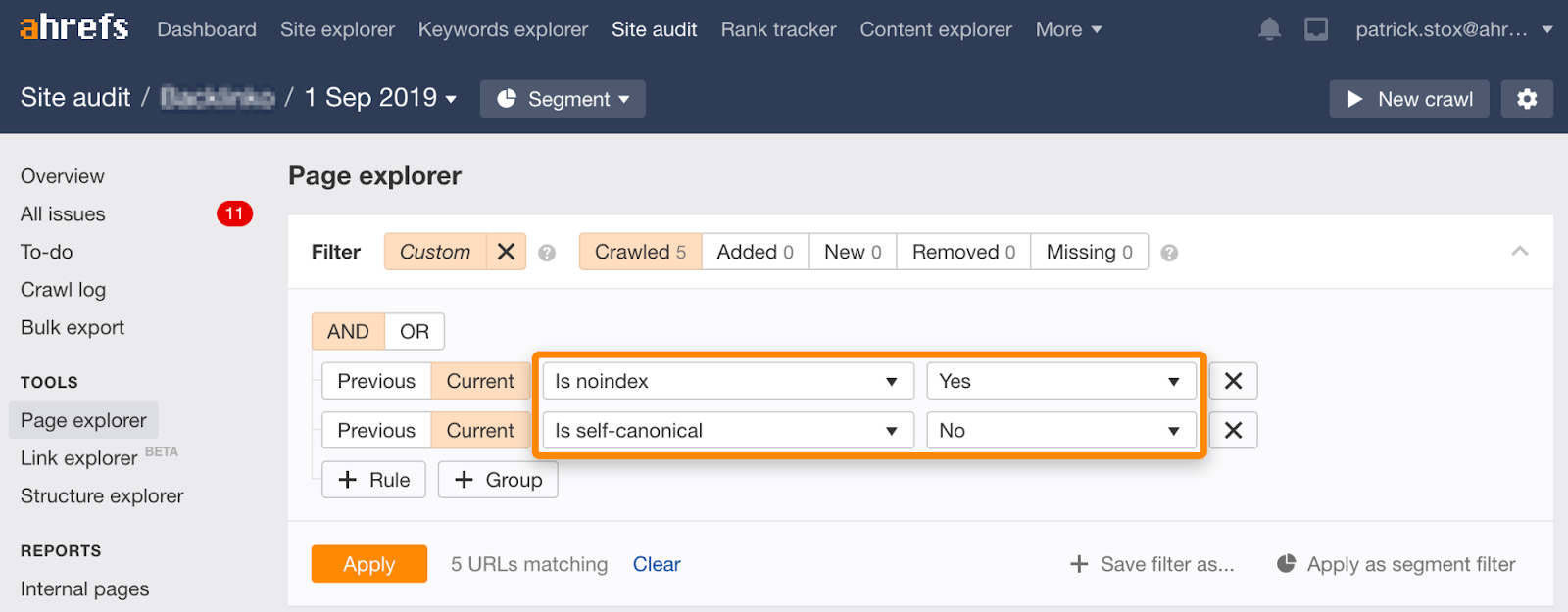
Noindex, warten, bis Google gecrawlt hat, und dann das Crawlen blockieren
Dies geschieht in der Regel auf verschiedene Weise:
- Seiten sind bereits blockiert, werden aber indiziert, Personen fügen den Noindex hinzu und geben die Blockierung auf, so dass Google den Noindex crawlen und sehen kann, und blockieren dann die Seiten erneut für das Crawlen.
- Die Nutzer fügen Noindex-Tags für die Seiten hinzu, die entfernt werden sollen, und nachdem Google den Noindex-Tag gecrawlt und verarbeitet hat, blockieren sie die Seiten für das Crawling.
So oder so, es wird verhindert, dass das Endergebnis gecrawlt wird. Wenn du dich erinnerst, haben wir vorhin darüber gesprochen, dass Crawling nicht dasselbe ist wie Indexierung. Auch wenn diese Seiten blockiert sind, können sie dennoch im Index landen.
Wenn du Eigentümer des Inhalts bist, der auf einer anderen Website verwendet wird, kannst du möglicherweise einen Anspruch auf der Grundlage des Digital Millennium Copyright Act (DMCA) geltend machen. Du kannst Googles Copyright-Removal-Tool verwenden, um einen sogenannten DMCA-Take-Down durchzuführen, der die Entfernung von urheberrechtlich geschütztem Material verlangt.
Was ist, wenn es Inhalte über dich gibt, aber nicht auf einer Website, die dir gehört?
Wenn du in der EU lebst, kannst du dank eines Gerichtsbeschlusses über das Recht auf Vergessen Inhalte entfernen lassen, die Informationen über dich enthalten. Du kannst beantragen, dass persönliche Informationen entfernt werden, indem du das „EU Privacy Removal“-Formular verwendest.
Bilder aus Google zu entfernen geht am einfachsten mit robots.txt. Während die inoffizielle Unterstützung für das Entfernen von Seiten aus robots.txt entfernt wurde (wie wir zuvor erwähnt haben), ist das simple Verbieten des Crawlings von Bildern der richtige Weg, um Bilder zu entfernen.
For a single image:
User-agent: Googlebot-Image Disallow: /images/dogs.jpg
For all images: User-agent: Googlebot-Image Disallow: /
Abschließende Gedanken
Wie du URLs entfernst, ist ziemlich situationsabhängig. Wir haben über mehrere Optionen gesprochen, aber wenn du immer noch verwirrt bist, welche die richtige für dich ist, schaue noch einmal auf das Flussdiagramm am Anfang.
Du kannst auch die von Google zur Verfügung gestellte rechtliche Fehlerbehebung zur Entfernung von Content durchlaufen.
Hast du Fragen? Lassen es mich auf Twitter wissen.
Übersetzt von sehrausch.de: Suchmaschinen– & Conversion-Optimierung, Online-Marketing & Paid-Advertising. Passgenau aus einer Hand.


