


O Que é o Googlebot e Como Funciona?

Por Patrick Stox
SEO técnico na Ahrefs
Existem mais rastreadores que o Google usa para tarefas específicas, sendo que cada rastreador identifica-se com uma sequência de texto diferente chamada de "agente do usuário". O Googlebot é eterno, o que significa que observa sites como os usuários veriam na versão do navegador Chrome mais recente.
O Googlebot é executado através de milhares de máquinas. Estas máquinas determinam a rapidez e o que rastrear nos websites, porém acabam por desacelerar o rastreamento para não os sobrecarregar.
Vamos verificar o processo dos Googlebots para construir um índice na web.
Como o Googlebot rastreia e indexa a web
O Google disponibilizou algumas versões passadas para servirem como guia. O abaixo é o mais recente.
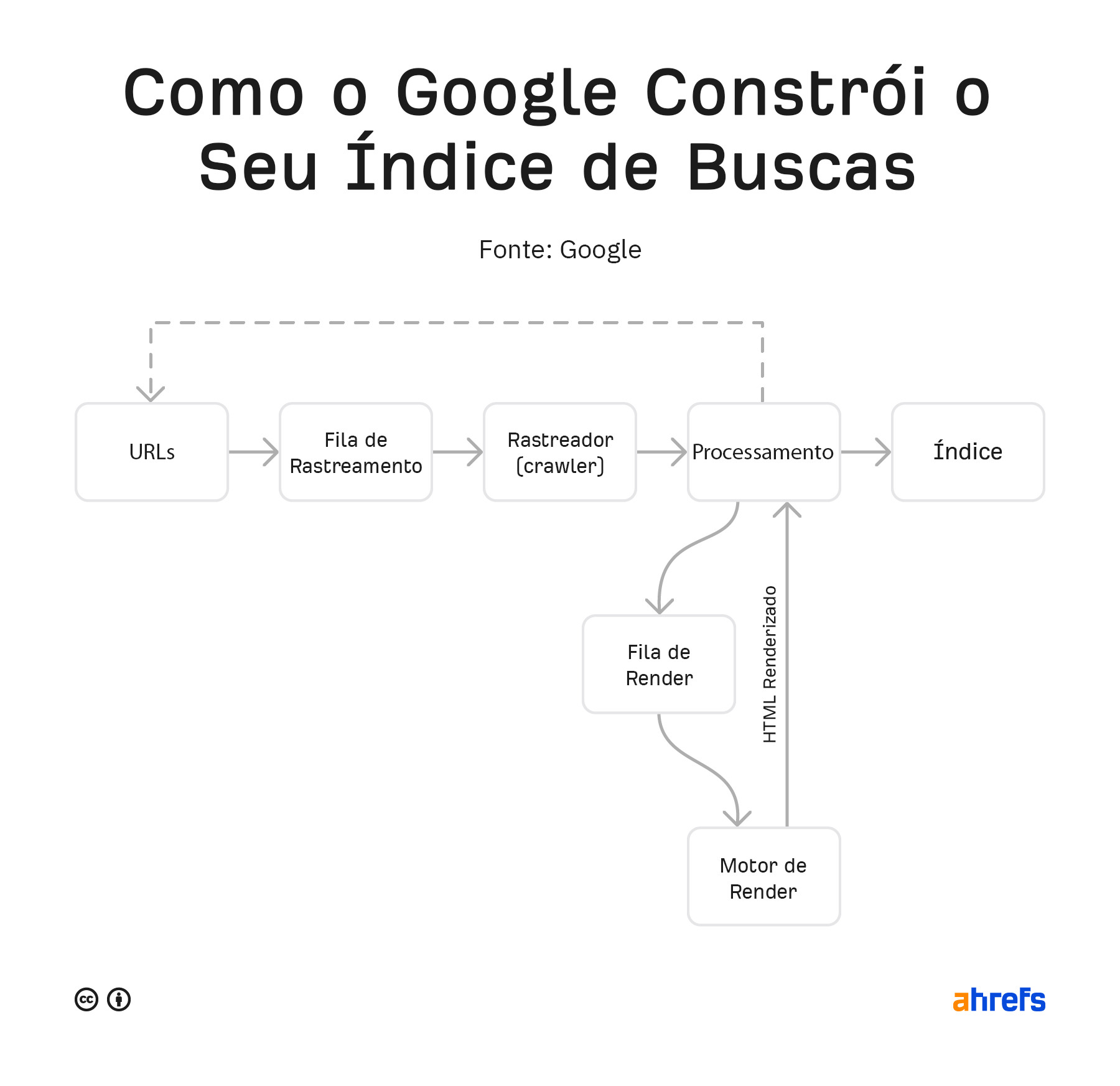
Ele processa isso tudo de novo e procura quaisquer alterações na página ou novos links. O conteúdo das páginas “renderizadas” é o conteúdo que é armazenado e pesquisável no índice do Google. Quaisquer novos links encontrados voltam à “caixa” de URLs para serem rastreados – e assim sucessivamente.
Temos mais detalhes sobre esse processo no nosso artigo sobre como funcionam os mecanismos de busca.
Como controlar o Googlebot
O Google dá-lhe algumas formas de controlar o que é rastreado e, por sua vez, indexado.
Maneiras de controlar o rastreamento
- Robots.txt – Este arquivo presente no seu website permite que você controle o que é rastreado.
- Nofollow – Nofollow é um atributo de link ou meta tag de robôs que sugere que um link não deve ser seguido por ninguém. Isto é considerado apenas uma dica, portanto, pode ser ignorado.
- Alterar a taxa de rastreamento – Esta ferramenta alicerçada ao Google Search Console permite que você reduza a velocidade de rastreamento do Google.
Maneiras de controlar a indexação
- Apague o seu conteúdo – Se você excluir uma página, não haverá nada para indexar. A desvantagem disso é que mais ninguém pode aceder à mesma.
- Limite o acesso ao conteúdo – O Google não faz login em websites, portanto, qualquer tipo de proteção por senha ou autenticação impedirá que ele veja o conteúdo.
- Noindex – Um chamado “noindex” na meta tag de robôs informa aos mecanismos de pesquisa para não indexarem a sua página.
- Ferramenta de remoção de URLs – O nome desta ferramenta do Google é um pouco duvidoso, pois a maneira como funciona é de ocultar temporariamente o conteúdo. O Google continuará a ver e a rastrear esse conteúdo, mas as páginas não aparecerão nos resultados de pesquisa.
- Robots.txt (Só imagens) – Bloquear o rastreamento da imagem do Googlebot significa que as suas imagens jamais serão indexadas.
Se tiver com dúvidas sobre qual o controle de indexação que deve usar, confira o nosso fluxograma no nosso artigo sobre como remover URLs da pesquisa do Google.
Será mesmo um Googlebot?
Muitas ferramentas de SEO e alguns bots maliciosos fingirão ser o Googlebot, pelo que isto pode permitir que eles acedam a websites que tentam bloqueá-los.
No passado, precisava de executar uma pesquisa de DNS para verificar o Googlebot. Mas mais recentemente, o Google tornou ainda mais fácil e acabou por fornecer uma lista de IPs públicos que você pode usar para verificar se as solicitações são de facto provenientes do Google. Por fim, pode comparar isso com os dados das entradas feitas no servidor.
Por consequência, também terá acesso a um relatório de “Estatísticas de rastreamento” no Google Search Console. Se você for consultar Configurações > Estatísticas de rastreamento, o relatório contém muitas informações sobre como o Google está a rastrear o seu website. Você pode ver, ainda, qual o Googlebot que está a rastrear, quais os arquivos em causa e quando os acedeu.
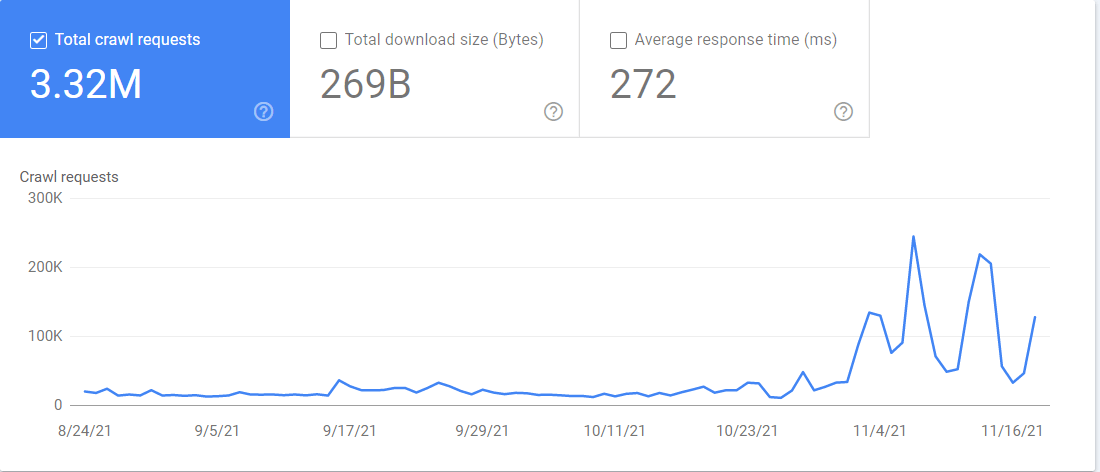
Considerações finais
A web (a internet) é um lugar gigantesco e confuso. O Googlebot precisa de navegar por todas as configurações diferentes, para não falar dos tempos de inatividade e das restrições impostas, de forma a recolher os dados que precisa para que o seu mecanismo de pesquisa funcione.
Um dado curioso para encerrar este artigo é que o Googlebot, geralmente é descrito como um robô (e é apropriadamente chamado de “Googlebot”). Há também uma mascote em formato de aranha que se chama “Crawley”.
Ainda tem dúvidas? Escreva-me no Twitter.
Patrick Stox é consultor de produtor, SEO técnico e embaixador da marca na Ahrefs. Ele foi o autor principal do capítulo de SEO do Web Almanac 2021 e revisor do capítulo de SEO 2022. Ele também foi coautor do SEO Book For Beginners da Ahrefs e foi o editor de revisão técnica do livro The Art of SEO (4ª edição). Ele é organizador do Triangle SEO Meetup, da conferência Tech SEO Connect, administra um grupo Technical SEO Slack e é moderador do /r/TechSEO no Reddit.

