El contenido duplicado es una fuente de ansiedad constante para muchos propietarios de sitios web.
Basta con leer casi cualquier cosa sobre el tema para acabar creyendo que tu web es una bomba de relojería de problemas de contenido duplicado y que Google está tardando en penalizarte.
Afortunadamente, este no es el caso, pero el contenido duplicado puede seguir causando problemas de SEO. Teniendo en cuenta que entre el 25 y el 30 % de la web es contenido duplicado, resulta útil saber cómo evitar y solucionar estos problemas.
En esta guía, aprenderás:
- Qué es el contenido duplicado
- Por qué el contenido duplicado es malo para el SEO
- Saber si Google penaliza el contenido duplicado
- Causas comunes del contenido duplicado
- Cómo comprobar (y corregir) el contenido duplicado
¿Es tu primera vez en el SEO técnico? Consulta nuestra Guía para principiantes sobre SEO técnico
Los contenidos duplicados son contenidos idénticos o casi iguales que aparecen en la web en más de un lugar. Esto puede ocurrir en un solo sitio web o en varios dominios.
Por ejemplo, si volvieses a publicar este post en ahrefs.com/blog/es/contenido-duplicado-copia/, entonces sería contenido duplicado. Lo mismo ocurriría si lo volviera a publicar en otro sitio web.
Google afirma que la mayor parte del contenido duplicado no tiene un origen engañoso.
El contenido duplicado puede perjudicar el rendimiento del SEO por varias razones.
- URL indeseables o poco amigables en los resultados de búsqueda.
- Dilución de backlinks.
- Crawl budget reducido.
- Contenido copiado o indeseado que te sobrepasa en el ranking.
Analicémoslaos más a fondo.
1. URL indeseables o poco amigables en los resultados de búsqueda
Imagina que la misma página está disponible en tres URL diferentes:
- dominio.com/pagina/
- dominio.com/pagina/?utm_content=buffer&utm_medium=social
- dominio.com/categoria/pagina/
La primera debería aparecer en los resultados de búsqueda, pero Google puede equivocarse. Si eso ocurre, una URL indeseable puede ocupar su lugar.
Dado que la gente puede estar menos dispuesta a hacer clic en una URL poco amigable, es posible que obtengas menos tráfico orgánico.
2. Dilución de backlinks
Si el mismo contenido está disponible en muchas URL, entonces cada una de esas URL puede atraer backlinks. El resultado es la división del valor de los enlaces entre las URL.
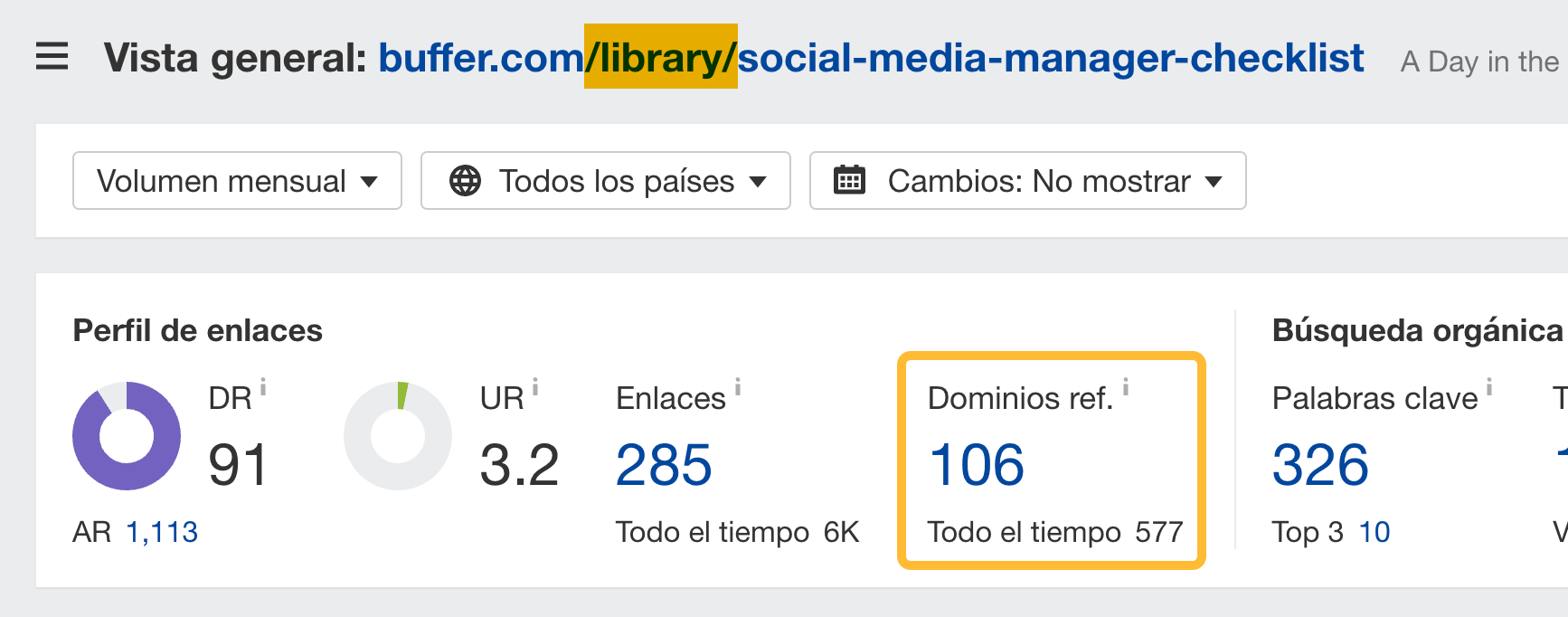
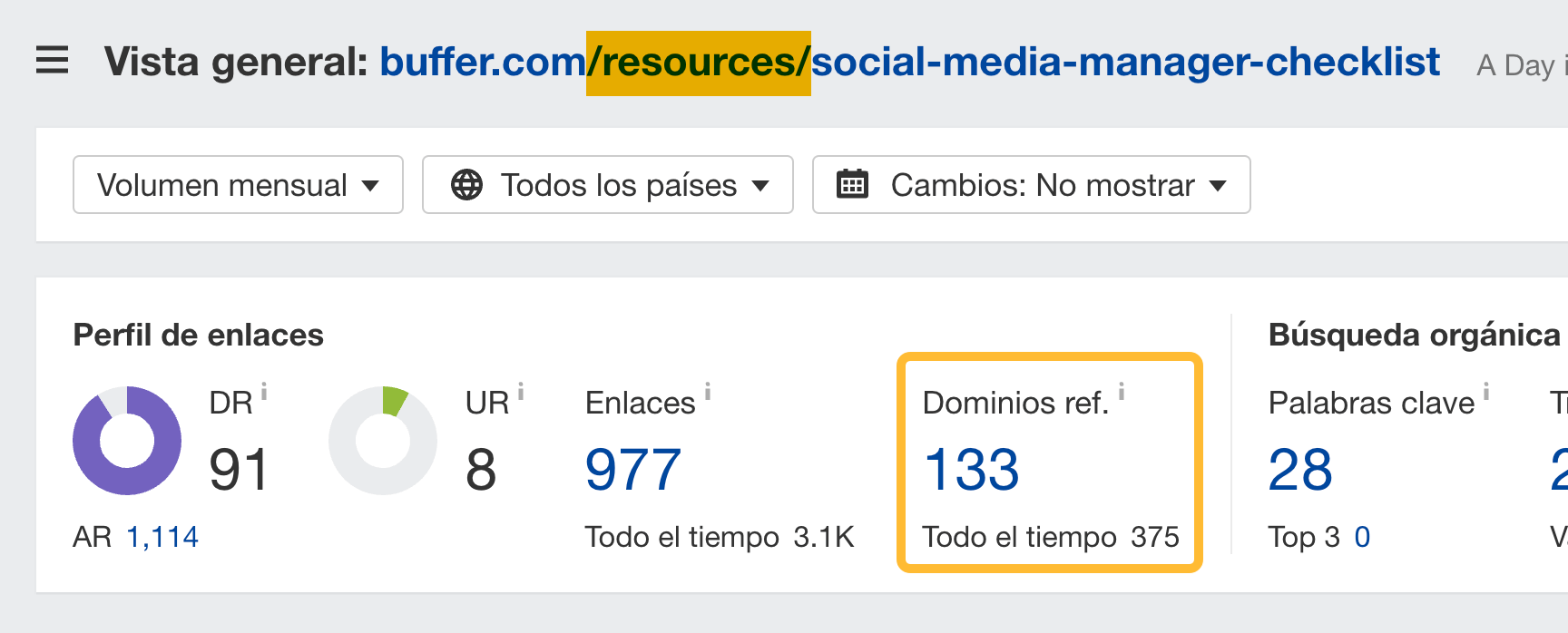
Echemos un vistazo a estas dos páginas en buffer.com:
https://buffer.com/library/social-media-manager-checklist
https://buffer.com/resources/social-media-manager-checklist
Estas páginas son duplicados casi exactos, con 106 y 133 dominios de referencia (enlaces desde sitios web únicos), respectivamente.
Antes de que cunda el pánico, es importante saber que no siempre supone un problema debido a la forma en que Google gestiona el contenido duplicado.
Básicamente, Google agrupa las URL en un grupo cuando detecta contenido duplicado. A continuación, selecciona la que considera más apropiada para representar el grupo en los resultados de búsqueda y consolida las propiedades de las URL del grupo, como la popularidad de los enlaces, en la URL representativa. Este proceso se conoce como “canonicalización”.
Así, en el caso anterior, Google debería mostrar solo una de las URL en la búsqueda orgánica y atribuir todos los dominios de referencia del clúster (106+133) a esa URL.
Sin embargo, esto no es lo que ocurre, ya que ambas URL aparecen en Google con palabras clave muy parecidas.

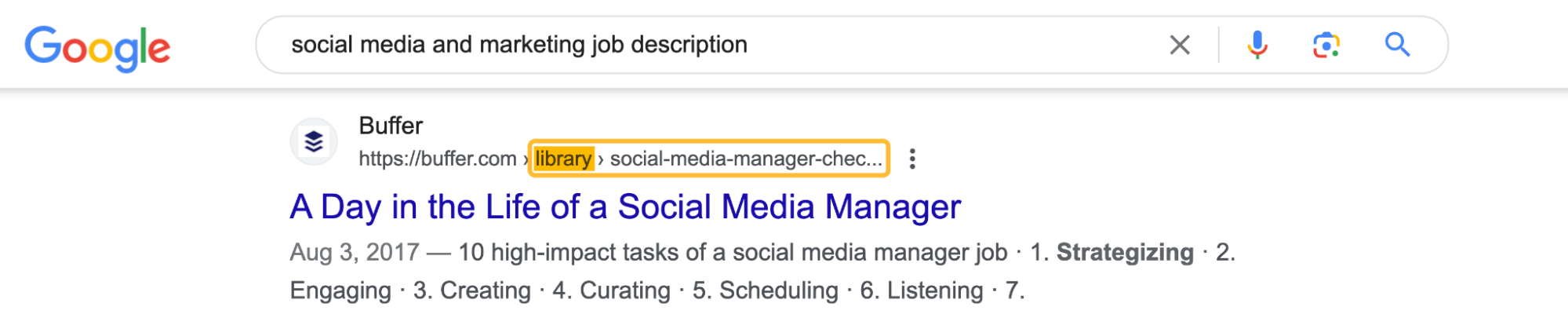
En este caso, es posible que Google no esté consolidando el valor de los enlaces en una URL.
No podemos saber con seguridad cómo percibe Google estas dos URL, ya que no tenemos acceso a la cuenta de Google Search Console de Buffer. Es posible que vea ambas URL como duplicadas y que una de ellas desaparezca en algún momento de las búsquedas orgánicas.
3. Crawl budget reducido
Google localiza el contenido nuevo de las webs a través del rastreo, lo que significa que sigue los enlaces de las páginas existentes a las nuevas. Además, vuelve a rastrear de vez en cuando las páginas que conoce para ver si ha habido algún cambio.
El contenido duplicado tan solo sirve para complicar el trabajo y puede afectar a la velocidad y frecuencia con la que rastrean las páginas nuevas o actualizadas.
Esta situación es perjudicial porque puede provocar retrasos en la indexación de las páginas nuevas y en la reindexación de las páginas actualizadas.
4. Contenido copiado que te supera en el ranking
En ciertas ocasiones, es posible que te interese que otras webs vuelvan a publicar tu contenido. Es lo que se conoce como “sindicación”. No obstante, a veces estas webs no te piden permiso para hacerlo.
Ambas situaciones generan contenido duplicado en varios dominios, pero no suelen causar problemas. Los problemas surgen solo cuando el contenido copiado o republicado empieza a superar al original en tu sitio.
La buena noticia es que no suele ocurrir, pero a veces pasa.
Google ha declarado en múltiples ocasiones que no existe una penalización por contenido duplicado.
No penalizamos el contenido duplicado. No es que degrademos un sitio por tener mucho contenido duplicado.

Acabemos con esto de una vez por todas: no existe la penalización por contenido duplicado.

Por si no lo sabías, Google no tiene una penalización por contenido duplicado.

Sin embargo, no es del todo cierto. Si el contenido duplicado es accidental y no el resultado de una manipulación intencionada de los resultados de búsqueda o de prácticas de spam, entonces no se penalizará. Si lo es, entonces puede que sí.
Google lo confirma aquí:
En los casos excepcionales en los que Google perciba que puedes mostrar contenidos duplicados con la intención de manipular nuestros rankings y engañar a nuestros usuarios, realizaremos también los ajustes oportunos en la indexación y el ranking de los sitios implicados. Como resultado, el posicionamiento del sitio puede verse afectado, o el sitio puede eliminarse por completo del índice de Google, en cuyo caso dejará de aparecer en los resultados de búsqueda.
La pregunta es, ¿qué cuenta como intención de manipular nuestros rankings y engañar a nuestros usuarios?
Google tiene mucha información al respecto aquí. En cualquier caso, básicamente son acciones como:
- Crear intencionadamente múltiples páginas, subdominios o dominios con mucho contenido duplicado.
- Publicar mucho contenido copiado.
- Publicar contenido de afiliados extraído de Amazon o de otros sitios (sin aportar ningún valor añadido).
Sin embargo, como ya hemos comentado, el contenido duplicado puede perjudicar al SEO, incluso sin penalización.
No hay una única causa de contenido duplicado. Hay muchas.
Navegación facetada/filtrada
La navegación por facetas permite a los usuarios filtrar y ordenar los elementos de la página. Los ecommerce la utilizan mucho.
Este tipo de navegación añade parámetros al final de la URL.

Como suele haber muchas combinaciones de estos filtros, la navegación facetada suele dar lugar a muchos contenidos duplicados o casi duplicados.
Echa un vistazo a estas dos páginas:
adidas.es/camisetas.html?new_style=Checked
adidas.es/camisetas.html?Size=S&new_style=Checked
Las URL son únicas, pero el contenido es casi idéntico.
Además, el orden de los parámetros no suele importar. Por ejemplo, se puede acceder a la misma página a través de estas dos URL:
adidas.es/camisetas.html?new_style=Checked&Size=XL
adidas.es/camisetas.html?Size=XL&new_style=Checked
La navegación por facetas es un tema complejo. Si tienes sospechas de que esta es la causa de tus problemas de contenido duplicado, lee esto (en inglés).
Parámetros de seguimiento
Las URL parametrizadas también se utilizan con fines de seguimiento. Por ejemplo, puedes utilizar parámetros UTM para realizar un seguimiento de las visitas de una campaña de newsletter en Google Analytics:
Ejemplo: ejemplo.com/pagina?utm_source=newsletter
Canonicaliza tus URL parametrizadas a versiones SEO-friendly sin parámetros de rastreo.
Session IDs
Los identificadores de sesión almacenan información sobre los visitantes. Suelen añadir una cadena larga a la URL, por ejemplo:
Ejemplo: ejemplo.com?sessionId=jow8082345hnfn9234
Canonicaliza las URL a versiones SEO-friendly.
HTTPS vs. HTTP, y no-www vs. www
Se puede acceder a la mayoría de las webs a través de una de estas cuatro variantes:
- https://www.ejemplo.com (HTTPS, www)
- https://ejemplo.com (HTTPS, non-www)
- http://www.ejemplo.com (HTTP, www)
- http://ejemplo.com (HTTP, non-www)
Si usas HTTPS, será una de las dos primeras. Si es la versión www o la no www, ahí ya es cosa tuya.
No obstante, si no configuras correctamente tu servidor, tu sitio será accesible en dos o más de estas variantes, lo cual no es bueno y puede dar lugar a problemas de contenido duplicado.
Usa redireccionamientos para asegurarte de que tu web solo sea accesible con una ubicación.
URL que distinguen mayúsculas de minúsculas
Google distingue entre mayúsculas y minúsculas en las URL.
Es decir, estas tres URL son distintas:
- ejemplo.com/pagina
- ejemplo.com/PAGINA
- ejemplo.com/pAgINa
Sé consistente y sistemático con los enlaces internos (es decir, no enlaces internamente a múltiples versiones de URL). Si con esto no se solucionan las cosas, siempre puedes canonicalizar o redirigir.
Barra diagonal final vs. sin barra diagonal
Google trata las URL con y sin barras diagonales al final de la URL como únicas. Esto significa que estas dos URL son únicas a los ojos de Google:
- ejemplo.com/pagina/
- ejemplo.com/pagina
Si tu contenido está disponible en ambas URL, pueden producirse problemas de contenido duplicado.
Para comprobar si se trata de un problema, intenta cargar una página con y sin la barra diagonal final. Lo ideal es que solo se cargue una versión y la otra redirigirá.
Por ejemplo, si intentas cargar esta entrada sin la barra diagonal final, se redirigirá a la URL con la barra diagonal final.
Google afirma que este comportamiento es el ideal.
Lo ideal es que solo se pueda devolver una versión (es decir, que una redirija a la otra). Esta configuración supone una gran ventaja, ya que evita que se duplique el contenido.
Redirige la versión no deseada (por ejemplo, sin barra diagonal final) a la versión deseada (por ejemplo, con barra diagonal). También deberías mantener la coherencia con los enlaces internos. No enlaces a versiones con barras diagonales de forma esporádica. Elige una versión y no la cambies.
URL aptas para impresión
Las versiones para imprimir tienen el mismo contenido que la original y solo varía la URL.
- ejemplo.com/pagina
- ejemplo.com/imprimir/pagina
Canonicaliza la versión para imprimir con la original.
URL mobile-friendly
Las URL aptas para móviles, al igual que las aptas para impresión, son duplicados.
- ejemplo.com/pagina
- m.ejemplo.com/pagina
Canonicaliza la versión mobile-friendly a la original. Utiliza rel="alternate" para indicar a Google que la URL adaptada para móviles es una versión alternativa del contenido desktop.
Lectura recomendada: Prácticas recomendadas para la indexación centrada en los móviles y los sitios web móviles
URL AMP
Las páginas móviles aceleradas (AMP, Accelerated Mobile Pages) son duplicados.
- ejemplo.com/pagina
- ejemplo.com/amp/pagina
Canonicaliza la versión AMP a la versión no AMP. Utiliza rel="amphtml"< para indicar a Google que la URL AMP es una versión alternativa del contenido no AMP.
Si solo tienes contenido AMP, utiliza una etiqueta canónica de autorreferencia.
Lectura recomendada: Haz que tus páginas se puedan descubrir - amp.dev
Páginas de etiquetas y categorías
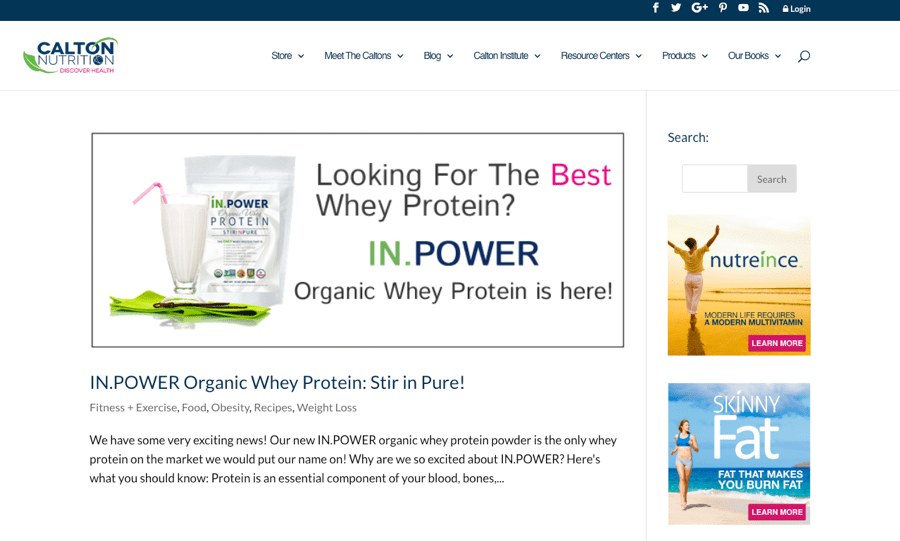
La mayoría de los CMS crean páginas de etiquetas dedicadas cuando se utilizan etiquetas. Por ejemplo, si tienes un artículo sobre proteína whey y utilizas tanto proteína en polvo como whey para las etiquetas, entonces tendrás dos páginas de etiquetas como estas:
https://www.caltonnutrition.com/tag/whey/
https://www.caltonnutrition.com/tag/protein-powder/
Es cierto que no siempre provoca contenido duplicado, pero podría hacerlo.
Este es el caso en el ejemplo de estas dos URL, ya que solo hay una página en el sitio con esas dos etiquetas, por lo que cada etiqueta es idéntica.
Dos opciones:
- No uses etiquetas. De cualquier modo, la mayoría de las veces tienen poco o ningún valor.
- Haz noindex en tus páginas de etiquetas. No obstante, esto no resuelve el problema del crawl budget, ya que Google seguirá perdiendo tiempo rastreando estas páginas.
Ten en cuenta que las páginas de categorías pueden causar problemas similares a las páginas de etiquetas. Un ejemplo:
https://www.elcorteingles.es/adidas/
https://www.elcorteingles.es/marcas/Chelsea-FC.html
Ambas páginas son casi idénticas porque no hay productos en ninguna de las categorías, así que lo que nos queda es la copia repetitiva de la plantilla.
Para solucionar este problema, utiliza un número razonable de categorías en tu sitio o incluso haz un noindex de las páginas de categorías.
URL de las imágenes adjuntas
Muchos CMS crean páginas dedicadas a las imágenes adjuntas. Estas páginas no suelen mostrar nada más que la imagen y algún texto repetitivo.
Este texto termina siendo el mismo en todas las páginas autogeneradas, por lo que genera contenido duplicado.
Desactiva las páginas dedicadas a las imágenes en tu CMS. En WordPress, puedes hacerlo usando un plugin como Yoast.
Paginación de comentarios
WordPress y otros CMS permiten comentarios paginados. Esto provoca contenido duplicado, ya que crea múltiples versiones de las mismas URL.
- ejemplo.com/post/
- ejemplo.com/post/comentarios-pagina-2
- ejemplo.com/post/comentarios-pagina-3
Desactiva la paginación de comentarios o haz un noindex de tus páginas paginadas utilizando un plugin como Yoast.
Localización
Si ofreces contenidos similares a personas de distintos países que hablan el mismo idioma, puedes generar contenido duplicado.
Por ejemplo, es posible que tengas distintas versiones de tu sitio para usuarios de México, Colombia y España. Como es posible que solo haya pequeñas diferencias entre el contenido que se ofrece en cada país (por ejemplo, precios en dólares mexicanos o euros), las versiones serán prácticamente duplicadas.
Utiliza etiquetas hreflang para indicar a los motores de búsqueda la relación entre las variaciones.
Páginas de resultados de búsqueda
Muchas webs tienen cuadros de búsqueda. Al utilizarlos, normalmente se accede a una URL de búsqueda parametrizada.
Example: ejemplo.com?q=termino-busqueda
El antiguo Head de Webspam de Google, Matt Cutts, declaró lo siguiente:
Normalmente, los resultados de búsqueda web no añaden valor a los usuarios y, dado que nuestro objetivo principal es ofrecer los mejores resultados de búsqueda posibles, por lo general excluimos los resultados de búsqueda de nuestro índice de búsqueda web. (Por supuesto, no todas las URL que contienen elementos como “/results” o “/search” son resultados de búsqueda).

Utiliza una metaetiqueta robots para eliminar las páginas de búsqueda del índice de Google o bloquea el acceso a las páginas de resultados de búsqueda en robots.txt. Evita enlazar internamente a las páginas de resultados de búsqueda.
Entorno de pruebas
Un entorno de pruebas (staging environment) es una versión duplicada o casi duplicada de tu web que se utiliza para realizar pruebas.
Por ejemplo, imagínate que quieres instalar un plugin nuevo o cambiar algo de código. Es posible que no quieras pasarlo directamente a la versión en vivo con miles, o cientos de miles, de usuarios. El riesgo de accidente es demasiado alto. La solución es probar los cambios en un entorno de pruebas primero.
Los entornos de pruebas se convierten en un problema de SEO cuando Google los indexa, ya que dan lugar a contenido duplicado.
Protege tu entorno de pruebas mediante autenticación HTTP, IP Whitelisting o acceso VPN. Si ya está indexado, utiliza una directiva robots noindex para eliminarlo.
Dirígete a Site Audit de Ahrefs e inicia un rastreo.
Después, accede al informe Duplicates.
Busca grupos de duplicados (Exact duplicates) y casi duplicados (Near duplicates) sin una canónica. Aparecen resaltados en naranja.
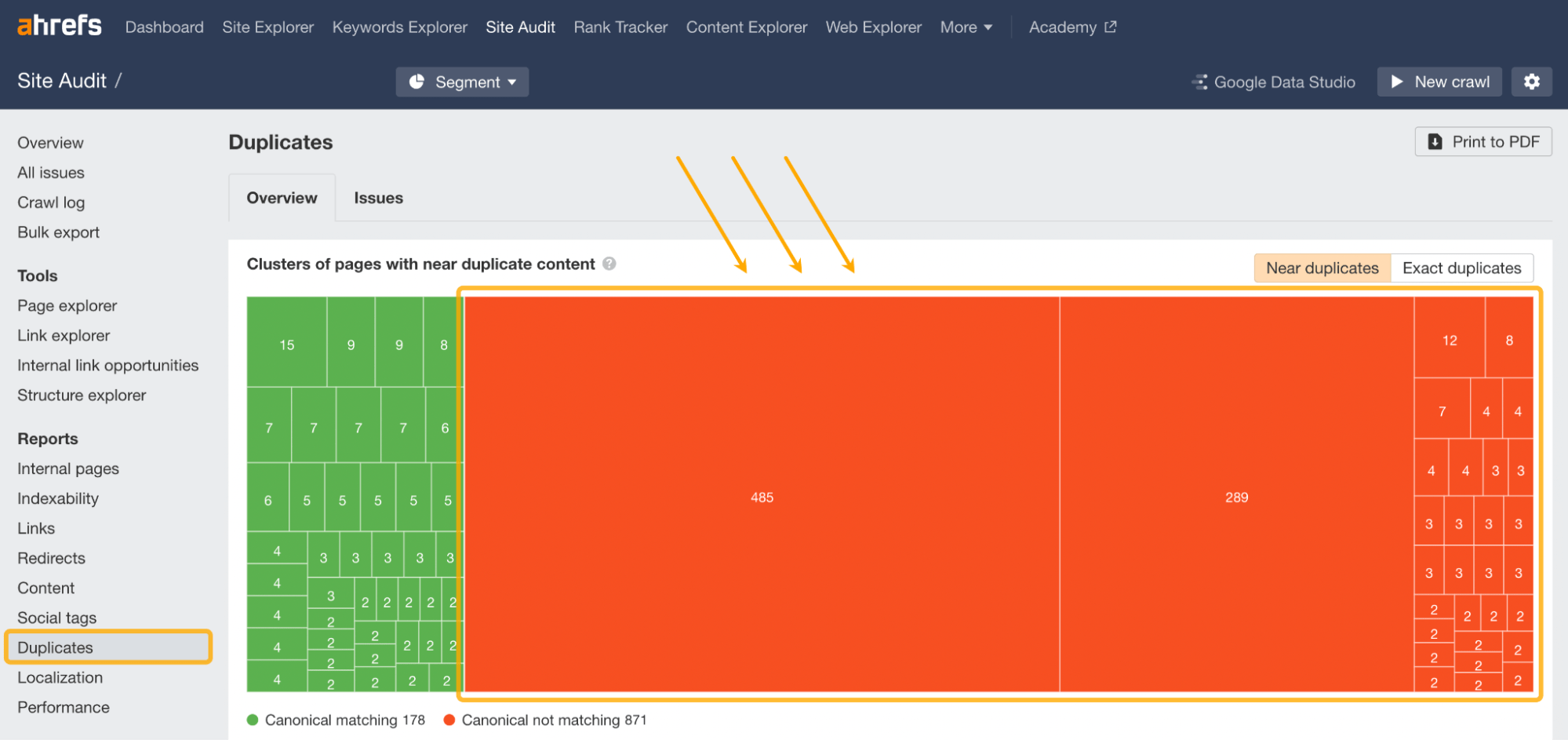
Haz clic en cualquiera de estos grupos para ver las páginas afectadas.
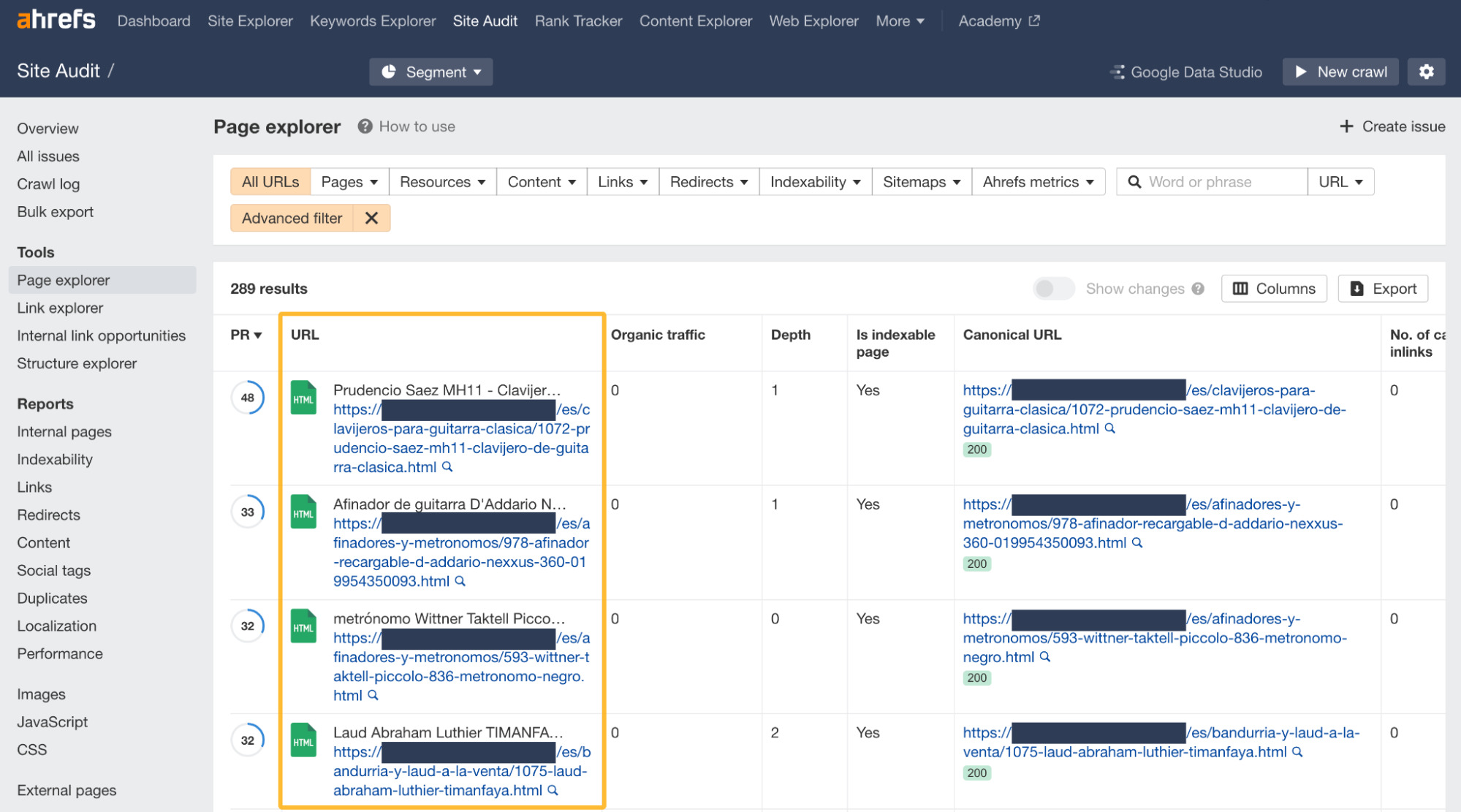
Investiga la razón del contenido duplicado y toma las medidas oportunas.
Ten en cuenta que no siempre se trata de problemas que haya que rectificar, sobre todo en el caso de los casi duplicados (near duplicates).
Busca estas advertencias relacionadas con el contenido duplicado en Google Search Console:
- Duplicado sin canonical elegido por el usuario
- Duplicado, Google eligió canonical diferente a la del usuario
- Duplicado, URL enviada no seleccionada como canónica
Para más información sobre cómo tratar estas advertencias, haz clic aquí.
Para ver cómo Google gestiona una URL específica, utiliza la herramienta de inspección de URLs.
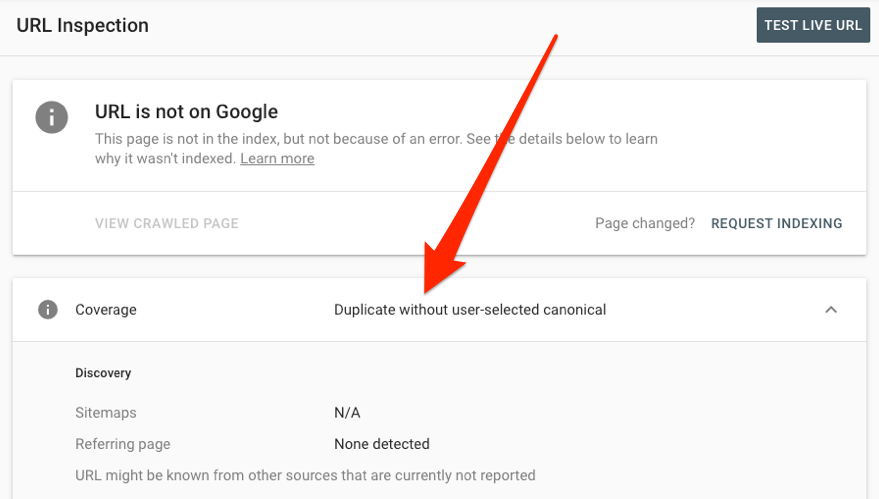
También puedes comprobar si hay etiquetas de título, meta descripciones y H1 duplicados en el informe de etiquetas HTML.
Lo que hay que buscar son duplicados defectuosos, es decir, páginas con metaetiquetas duplicadas, pero canónicas diferentes.
Para seleccionarlas, haz clic en el botón “Bad duplicates” en “Duplicate content distribution”.
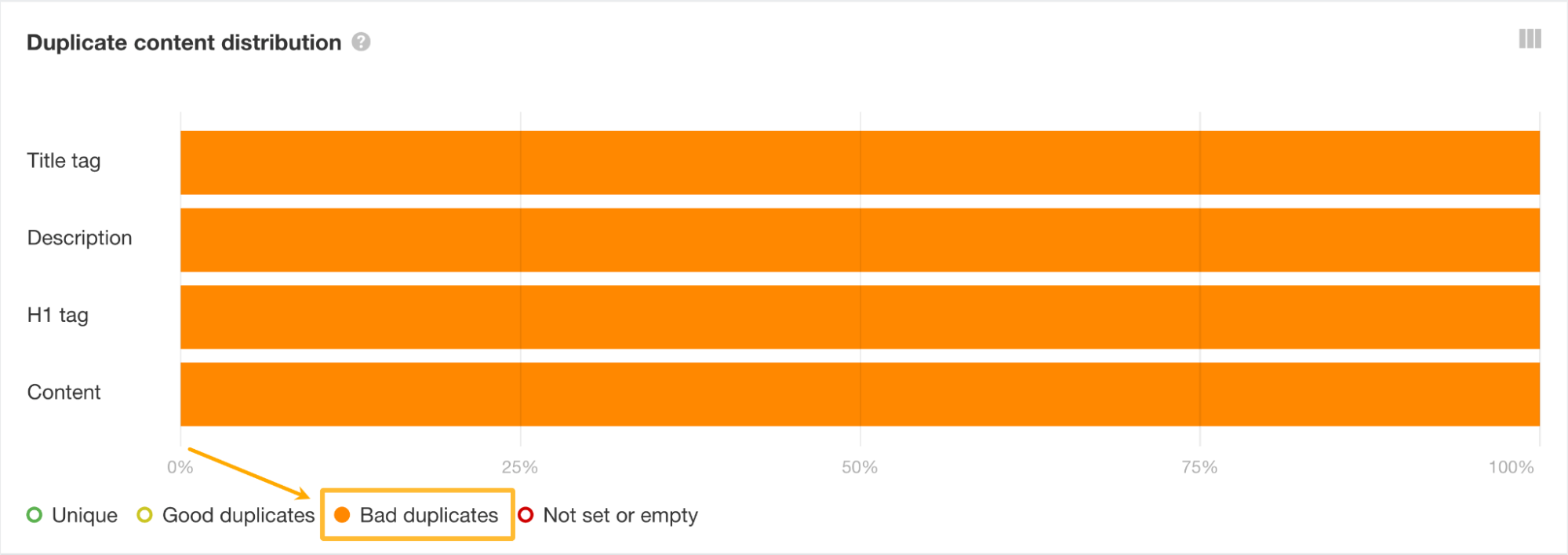
Haz clic en cualquiera de las barras naranjas para ver las páginas afectadas.
Las páginas con títulos, meta descripciones o H1 duplicados suelen ser muy similares.
Por ejemplo, estas dos tienen el problema que mencionamos anteriormente. El CMS crea páginas idénticas para categorías y etiquetas, creando así duplicados de forma constante.
https://……/category/guitarras-para-principiantes/
https://……/tag/guitarras-para-principiantes/
Google indica que se debe minimizar el contenido similar a este:
Si tienes muchas páginas similares, considera la posibilidad de ampliar cada una de ellas o consolidarlas en una sola.
Sin embargo, es poco probable que un número reducido de páginas semejantes suponga un gran problema.
El scraping y la sindicación de contenidos también pueden provocar problemas de contenido duplicado. Sin embargo,esto solo suele suponer un problema si ves que las versiones de tu contenido obtenidas por scraping te superan en el ranking.
¿Esto ocurre? Sí, pero suele ser más un problema para los sitios web nuevos o débiles, ya que los sitios que copian el contenido de otras webs no suelen estar bien posicionados. Esto es algo que a veces engaña a Google para que piense que el suyo es el original.
Si tienes una web pequeña, es posible encontrar contenido copiado buscando en Google un fragmento de texto de tu página entre comillas.
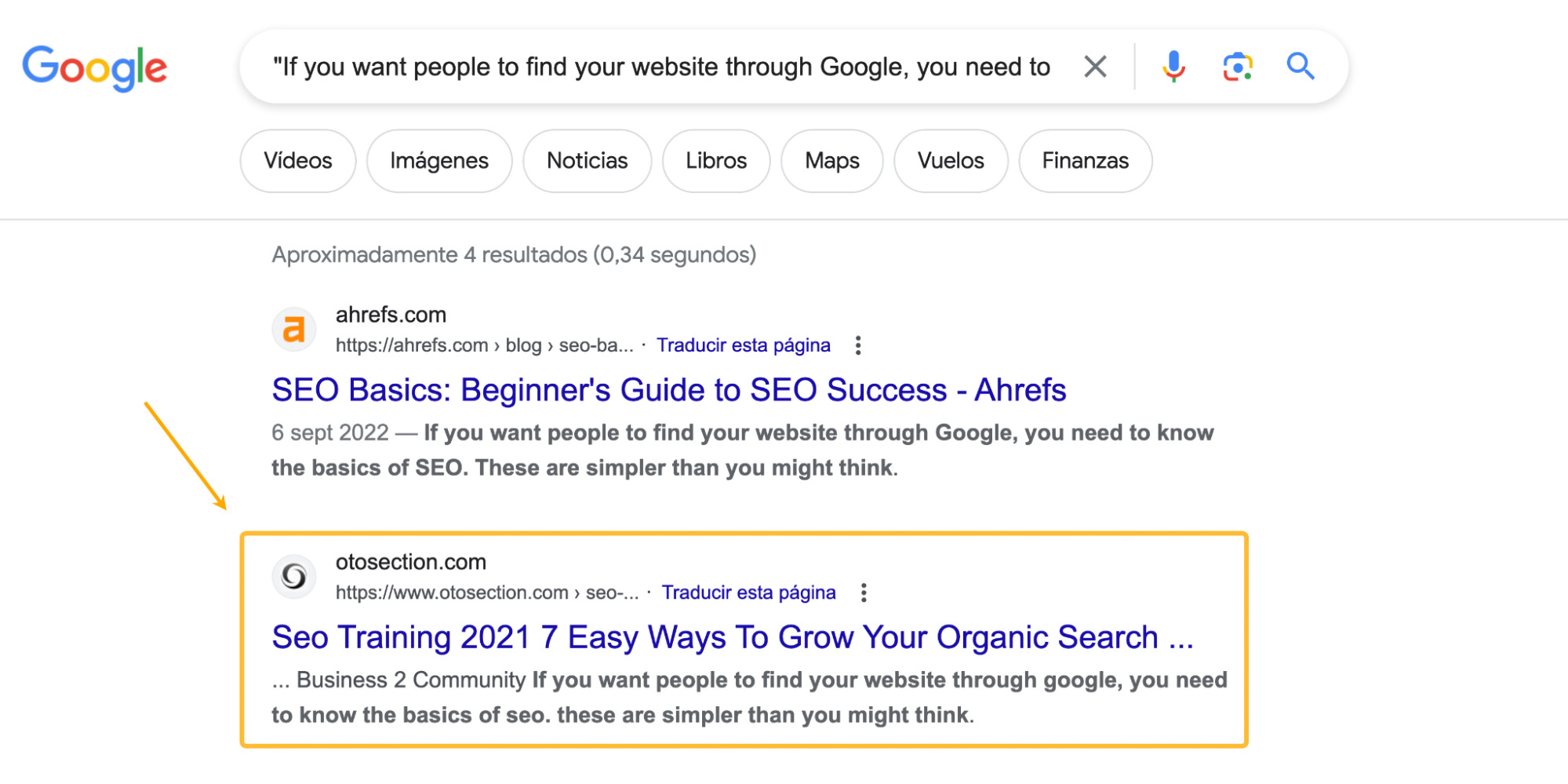
Para los sitios más grandes, es necesario utilizar una herramienta automatizada como Copyscape. Esta herramienta busca en Internet otras apariciones del contenido de las páginas.

Sea cual sea el método que utilices, la mayoría de los resultados procederán de sitios de spam y de baja calidad.
En general, no hay de qué preocuparse. Sin embargo, si ves que un sitio web legítimo ha copiado tu contenido y te preocupa que pueda estar robándote tráfico, introduce la URL en el Site Explorer de Ahrefs para ver una estimación del tráfico orgánico.
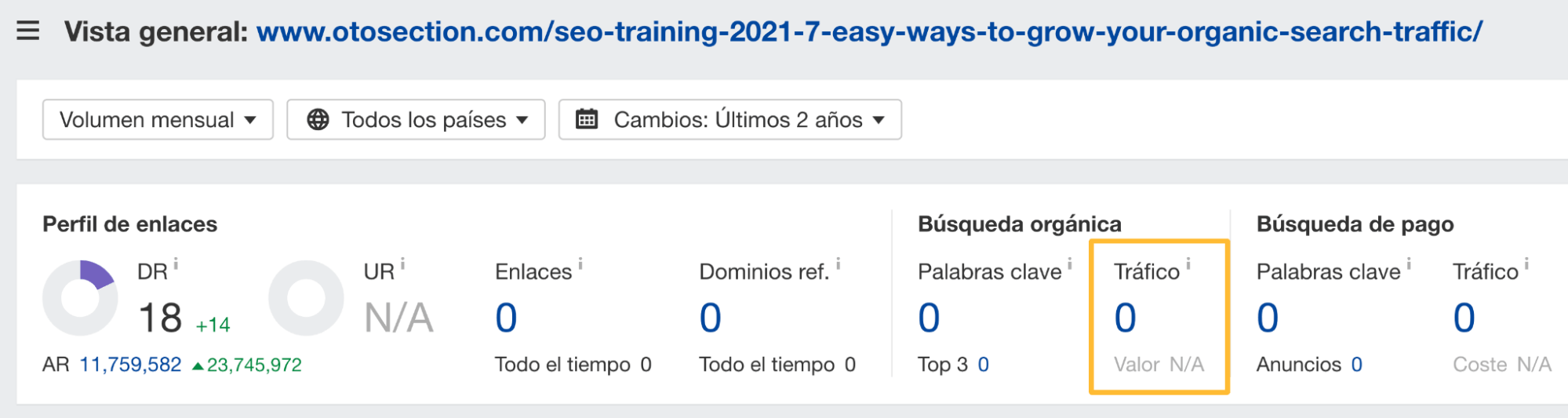
Si está recibiendo más tráfico que tu página, entonces puede haber un problema.
En tal caso, tienes tres opciones:
- Ponte en contacto con ellos y pídeles que eliminen el contenido.
- Ponte en contacto con ellos y pídeles que añadan un enlace canónico al original en tu sitio.
- Envía una solicitud de retirada DMCA a través de Google.
Si intencionadamente distribuyes contenido a otros sitios web, merece la pena pedirles que añadan un enlace canónico al original. Esto eliminará el riesgo de problemas de contenido duplicado.
Si estás republicando contenido de otros en tu sitio, hay dos maneras de evitar problemas de contenido duplicado:
- Canonicalizar la página original.
- Hacer un noindex de la página.
Reflexiones finales
No es necesario preocuparse demasiado por el contenido duplicado.: Ssuele ser un problema mucho menor de lo que parece.
Si tienes varias páginas duplicadas o casi duplicadas, es poco probable que haya problemas. Lo mismo ocurre cuando se cita contenido de otro sitio web o de otras páginas de tu sitio. El contenido duplicado o repetido en pequeñas dosis no debería suponer ningún problema. y Google dispone de sistemas para solucionarlo.
A lo que sí hay que estar atento, sin embargo, es a los errores técnicos de SEO que conducen a la generación de cientos, o miles, de páginas de contenido duplicado, como la implementación incorrecta de la navegación por facetas en los ecommerce.
Esto puede causar graves problemas en el crawl budget, entre otras cosas.
¿Tienes problemas con el contenido duplicado? Escríbenos por Twitter.


