
If so, you’re already familiar with web scraping.
But, while this can certainly be useful, there’s much more to web scraping than grabbing a few title tags—it can actually be used to extract any data from any web page in seconds.
The question is: what data would you need to extract and why?
In this post, I’ll aim to answer these questions by showing you 6 web scraping hacks:
- How to find content “evangelists” in website comments
- How to collect prospects’ data from “expert roundups”
- How to remove junk “guest post” prospects
- How to analyze performance of your blog categories
- How to choose the right content for Reddit
- How to build relationships with those who love your content
I’ve also automated as much of the process as possible to make things less daunting for those new to web scraping.
But first, let’s talk a bit more about web scraping and how it works.
A basic introduction to web scraping
Let’s assume that you want to extract the titles from your competitors’ 50 most recent blog posts.
You could visit each website individually, check the HTML, locate the title tag, then copy/paste that data to wherever you needed it (e.g. a spreadsheet).
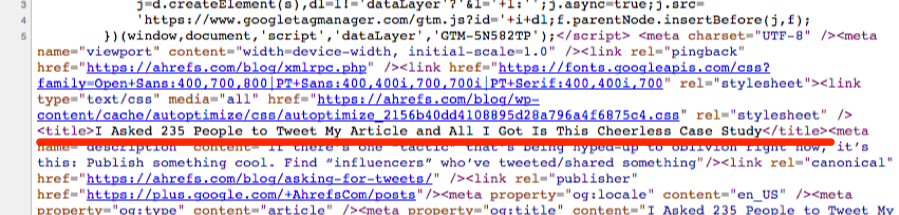
But, this would be very time-consuming and boring.
That’s why it’s much easier to scrape the data we want using a computer application (i.e. web scraper).
In general, there are two ways to “scrape” the data you’re looking for:
- Using a path-based system (e.g. XPath/CSS selectors);
- Using a search pattern (e.g. Regex)
XPath/CSS (i.e. path-based system) is the best way to scrape most types of data.
For example, let’s assume that we wanted to scrape the h1 tag from this document:
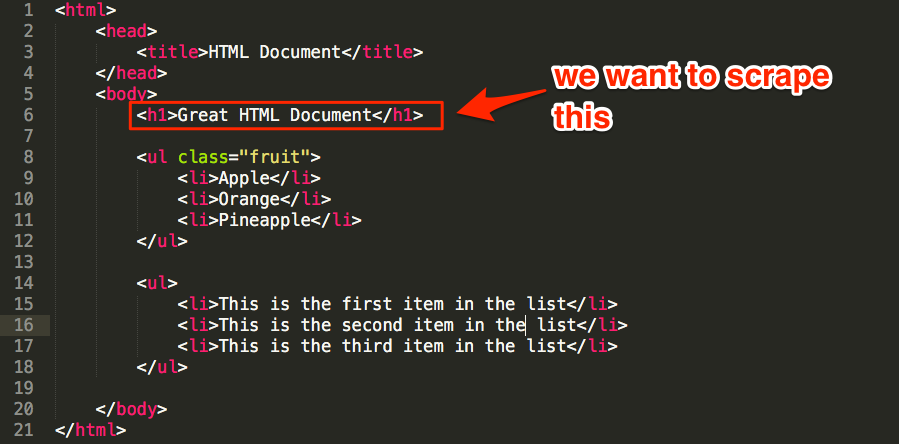
We can see that the h1 is nested in the body tag, which is nested under the html tag—here’s how to write this as XPath/CSS:
- XPath: /html/body/h1
- CSS selector: html > body > h1
But what if we wanted to scrape the list of fruit instead?
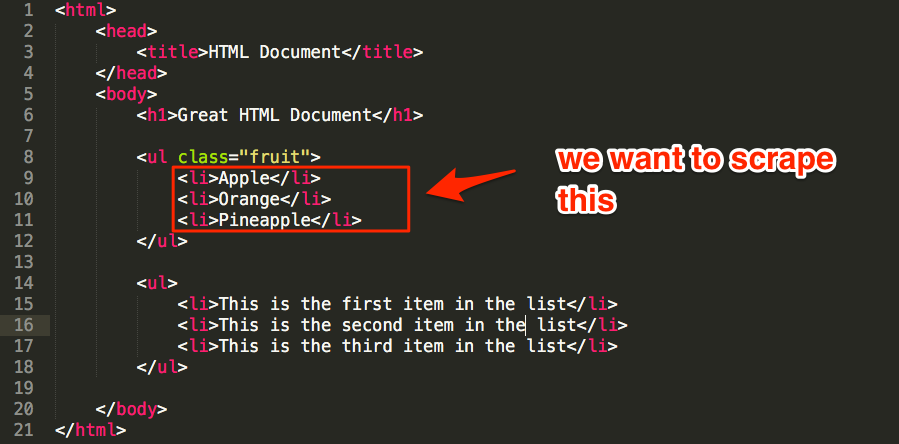
You might guess something like: //ul/li (XPath), or ul > li (CSS), right?
Sure, this would work. But because there are actually two unordered lists (ul) in the document, this would scrape both the list of fruit AND all list items in the second list.
However, we can reference the class of the ul to grab only what we want:
- XPath: //ul[@class=’fruit’]/li
- CSS selector: ul.fruit > li
Regex, on the other hand, uses search patterns (rather than paths) to find every matching instance within a document.
This is useful whenever path-based searches won’t cut the mustard.
For example, let’s assume that we wanted to scrape the words “first’, “second,” and “third” from the other unordered list in our document.
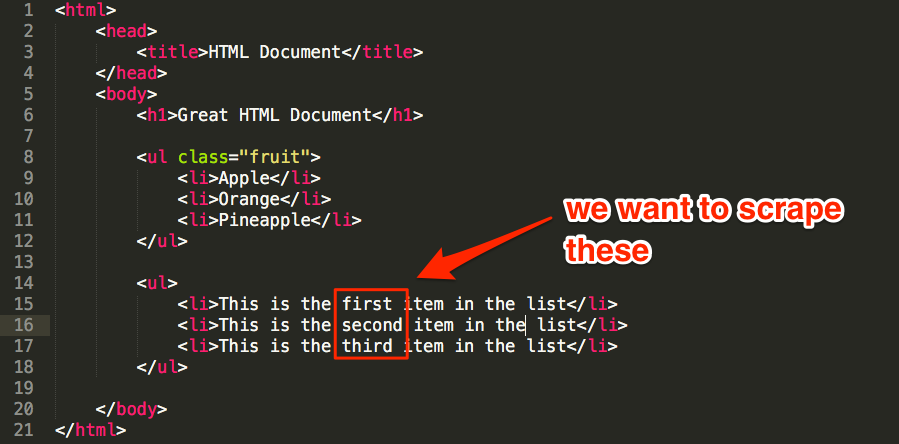
There’s no way to grab just these words using path-based queries, but we could use this regex pattern to match what we need:
<li>This is the (.*) item in the list<\/li>
This would search the document for list items (li) containing “This is the [ANY WORD] item in the list” AND extract only [ANY WORD] from that phrase.
Here are a few useful XPath/CSS/Regex resources:
- Regexr.com — Learn, build and test Regex;
- W3Schools XPath tutorial;
And scraping tools:
OK, let’s get started with a few web scraping hacks!
1. Find “evangelists” who may be interested in reading your new content by scraping existing website comments
Most people who comment on WordPress blogs will do so using their name and website.
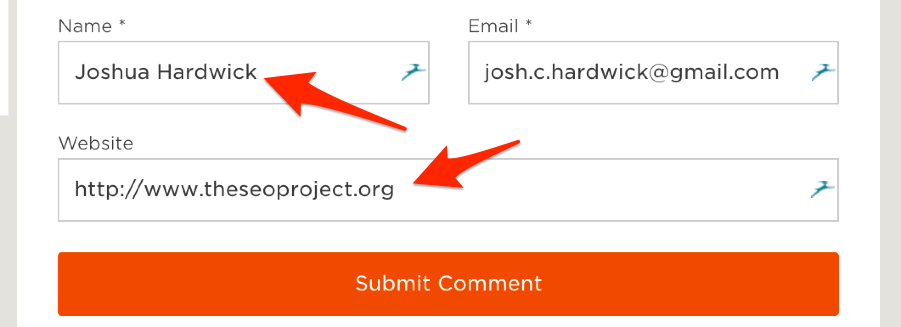
You can spot these in any comments section as they’re the hyperlinked comments.

But what use is this?
Well, let’s assume that you’ve just published a post about X and you’re looking for people who would be interested in reading it.
Here’s a simple way to find them (that involves a bit of scraping):
- Find a similar post on your website (e.g. if your new post is about link building, find a previous post you wrote about SEO/link building—just make sure it has a decent amount of comments.);
- Scrape the names + websites of all commenters;
- Reach out and tell them about your new content.
Here’s how to scrape them:
Go to the comments section then right-click any top-level comment and select “Scrape similar…” (note: you will need to install the Scraper Chrome Extension for this).
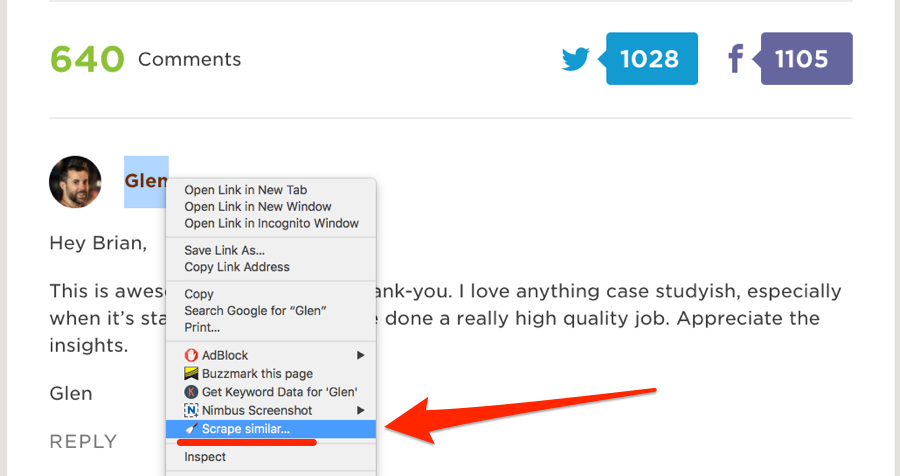
This should bring up a neat scraped list of commenters names + websites.
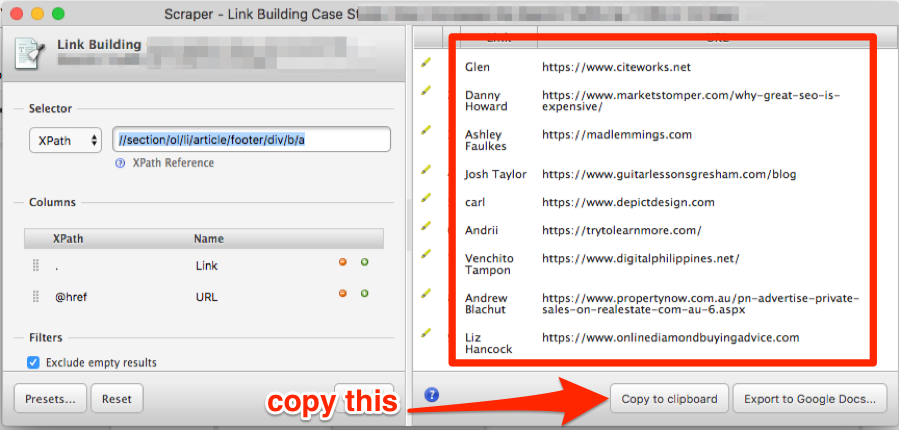
Make a copy of this Google Sheet, then hit “Copy to clipboard,” and paste them into the tab labeled “1. START HERE”.
Go to the tab labeled “2. NAMES + WEBSITES” and use the Google Sheets hunter.io add-on to find the email addresses for your prospects.
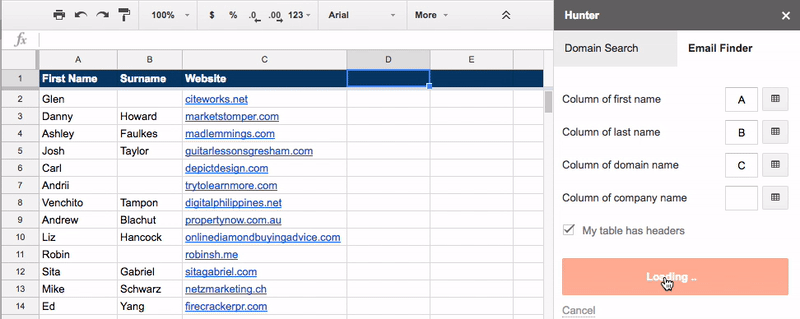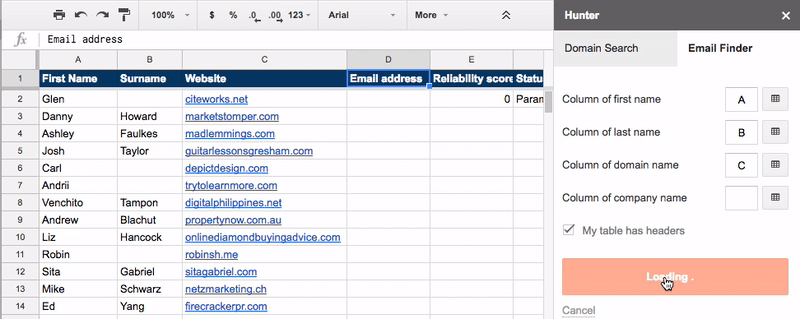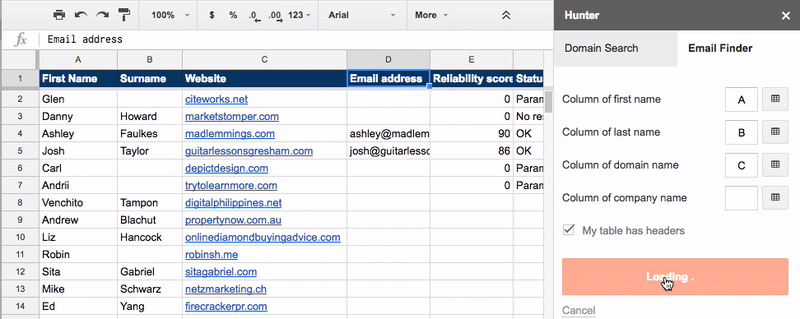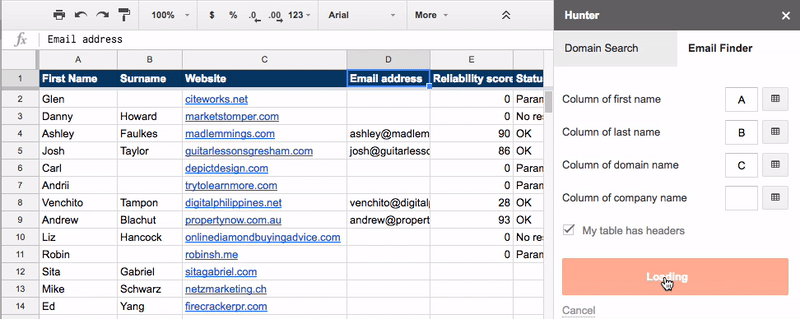
You can then reach out to these people and tell them about your new/updated post.
IMPORTANT: We advise being very careful with this strategy. Remember, these people may have left a comment, but they didn’t opt into your email list. That could have been for a number of reasons, but chances are they were only really interested in this post. We, therefore, recommend using this strategy only to tell commenters about the updates to the post and/or other new posts that are similar. In other words, don’t email people about stuff they’re unlikely to care about!
Here’s the spreadsheet with sample data.
2. Find people willing to contribute to your posts by scraping existing “expert roundups”
“Expert” roundups are WAY overdone.
But, this doesn’t mean that including advice/insights/quotes from knowledgeable industry figures within your content is a bad idea; it can add a lot of value.
In fact, we did exactly this in our recent guide to learning SEO.
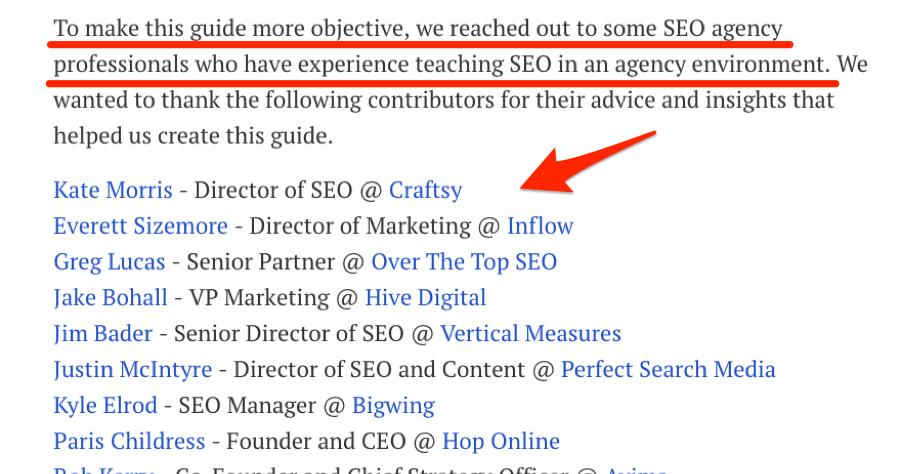
But, while it’s easy to find “experts” you may want to reach out to, it’s important to remember that not everyone responds positively to such requests. Some people are too busy, while others simply despise all forms of “cold” outreach.
So, rather than guessing who might be interested in providing a quote/opinion/etc for your upcoming post, let’s instead reach out to those with a track record of responding positively to such requests by:
- Finding existing “expert roundups” (or any post containing “expert” advice/opinions/etc) in your industry;
- Scraping the names + websites of all contributors;
- Building a list of people who are most likely to respond to your request.
Let’s give it a shot with this expert roundup post from Nikolay Stoyanov.
First, we need to understand the structure/format of the data we want to scrape. In this instance, it appears to be full name followed by a hyperlinked website.
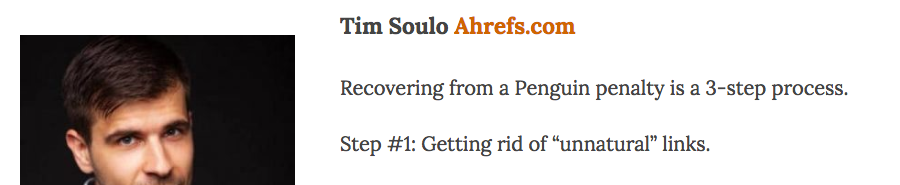
HTML-wise, this is all wrapped in a <strong> tag.
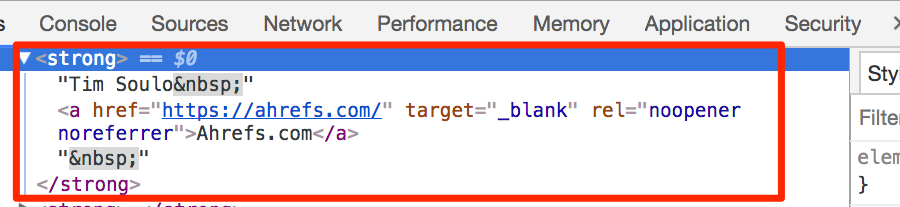
Because we want both the names (i.e. text) and website (i.e. link) from within this <strong> tag, we’re going to use the Scraper extension to scrape for the “text()” and “a/@href” using XPath, like this:
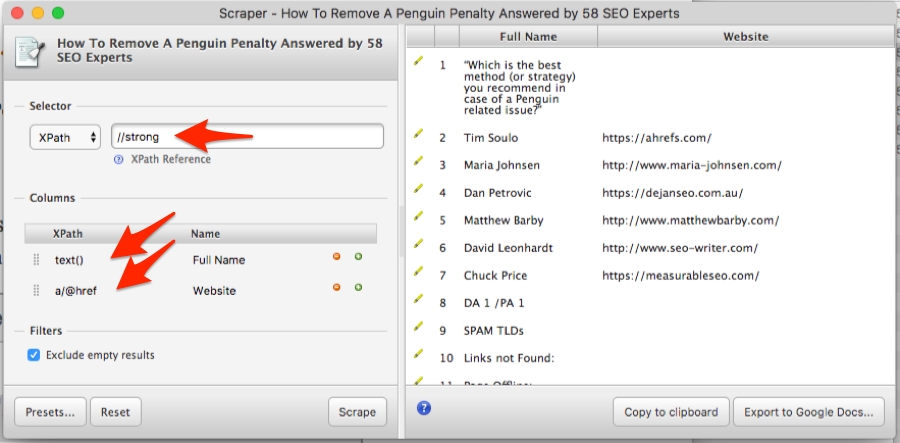
Don’t worry if your data is a little messy (as it is above); this will get cleaned up automatically in a second.
Next, make a copy of this Google Sheet, hit “Copy to clipboard,” then paste the raw data into the first tab (i.e. “1. START HERE”).
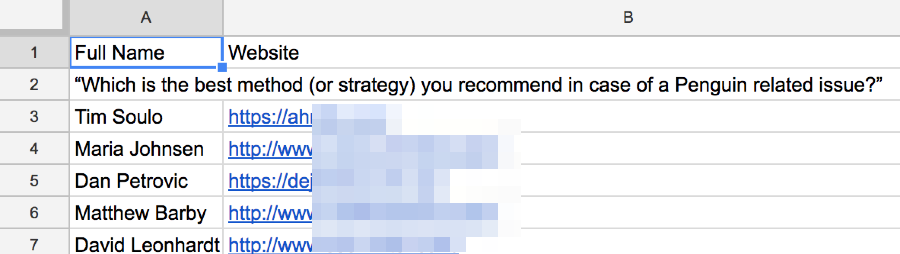
Repeat this process for as many roundup posts as you like.
Finally, navigate to the second tab in the Google Sheet (i.e. “2. NAMES + DOMAINS”) and you’ll see a neat list of all contributors ordered by # of occurrences.
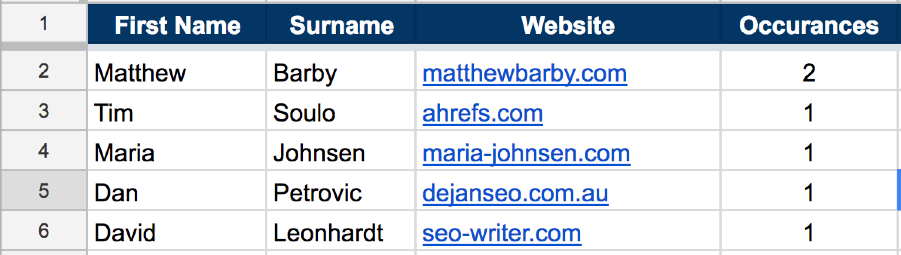
Here are 9 ways to find the email addresses for everyone on your list.
IMPORTANT: Always research any prospects before reaching out with questions/requests. And DON’T spam them!
Here’s the spreadsheet with sample data.
3. Remove junk “guest post” prospects by scraping RSS feeds
Blogs that haven’t published anything for a while are unlikely to respond to guest post pitches.
Why? Because the blogger has probably lost interest in their blog.
That’s why I always check the publish dates on their few most recent posts before pitching them.
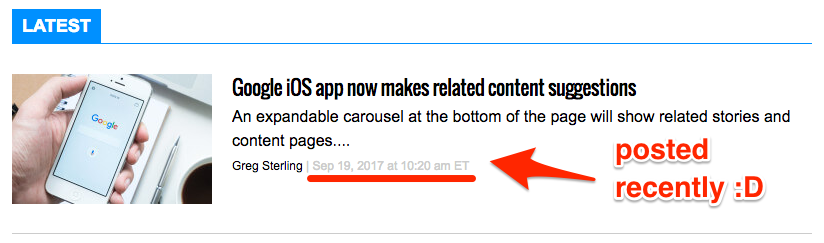
(If they haven’t posted for more than a few weeks, I don’t bother contacting them)
However, with a bit of scraping knowhow, this process can be automated. Here’s how:
- Find the RSS feed for the blog;
- Scrape the “pubDate” from the feed
Most blogs RSS feeds can be found at domain.com/feed/—this makes finding the RSS feed for a list of blogs as simple as adding “/feed/” to the URL.
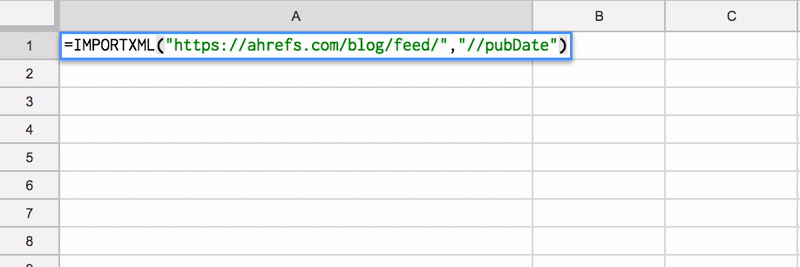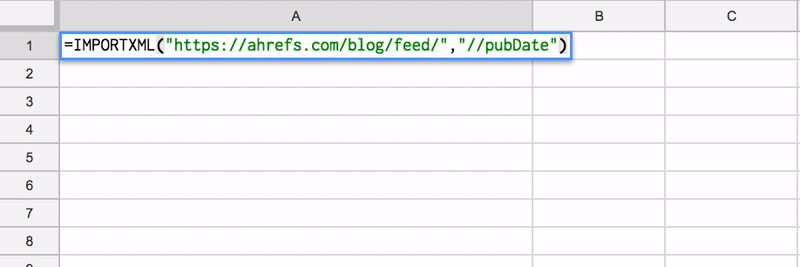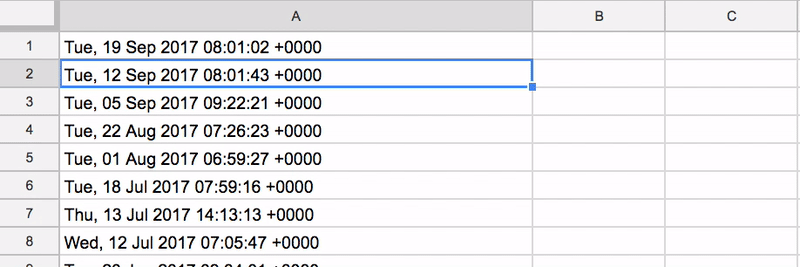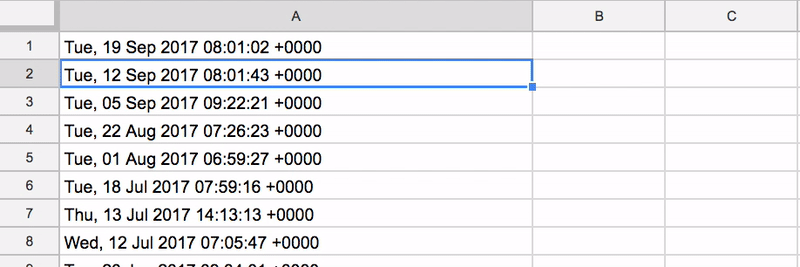
For example, the RSS feed for the Ahrefs blog can be found at https://ahrefs.com/blog/feed/
You can then use XPath within the IMPORTXML function in Google Sheets to scrape the pubDate element:
importxml(“https://ahrefs.com/blog/feed/”,”//pubDate”)))
This will scrape every pubDate element in the RSS feed, giving you a list of publishing dates for the most recent 5-10 blog posts for that blog.
But how do you do this for an entire list of blogs?
Well, I’ve made another Google Sheet that automates the process for you—just paste a list of blog URLs (e.g. https://ahrefs.com/blog) into the first tab (i.e. “1. ENTER BLOG URLs”) and you should see something like this appear in the “RESULTS” tab:
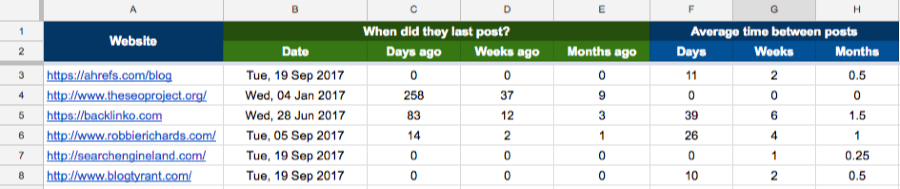
It tells you:
- The date of the most recent post;
- How many days/weeks/months ago that was;
- Average # of days/weeks/months between posts (i.e. how often they post, on average)
This is super-useful information for choosing who to pitch guest posts to.
For example, you can see that we publish a new post every 11 days on average, meaning that Ahrefs would definitely be a great blog to pitch to if you were in the SEO/marketing industry 🙂
Here’s the spreadsheet with sample data.
Recommended reading: An In-Depth Look at Guest Blogging in 2016 (Case Studies, Data & Tips)
4. Find out what type of content performs best on your blog by scraping post categories
Many bloggers will have a general sense of what resonates with their audience.
But as an SEO/marketer, I prefer to rely on cold hard data.
When it comes to blog content, data can help answer questions that aren’t instantly obvious, such as:
- Do some topics get shared more than others?
- Are there specific topics that attract more backlinks than others?
- Are some authors more popular than others?
In this section, I’ll show you exactly how to answer these questions for your blog by combining a single Ahrefs export with a simple scrape. You’ll even be able to auto-generate visual data representations like this:
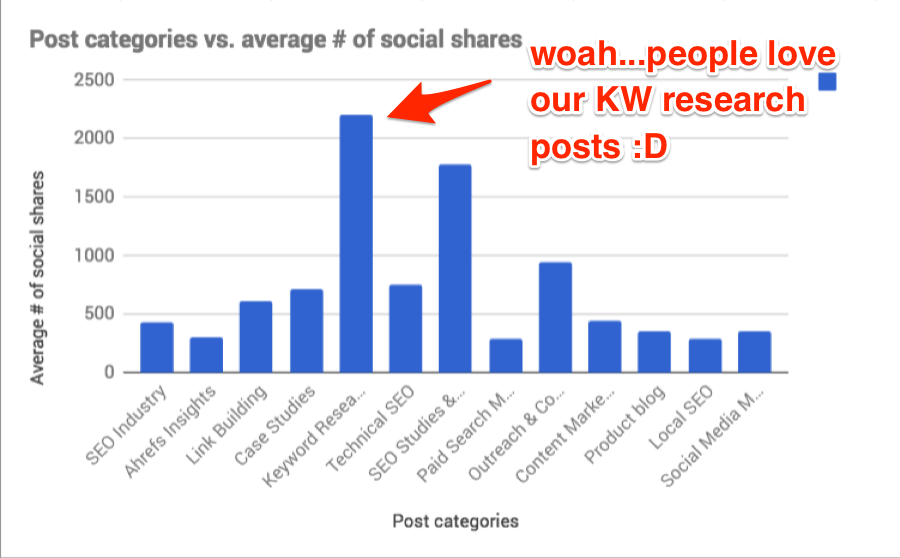
Here’s the process:
- Export the “top content” report from Ahrefs Site Explorer;
- Scrape categories for all the blog posts;
- Analyse the data in Google Sheets (hint: I’ve included a template that does this automagically!)
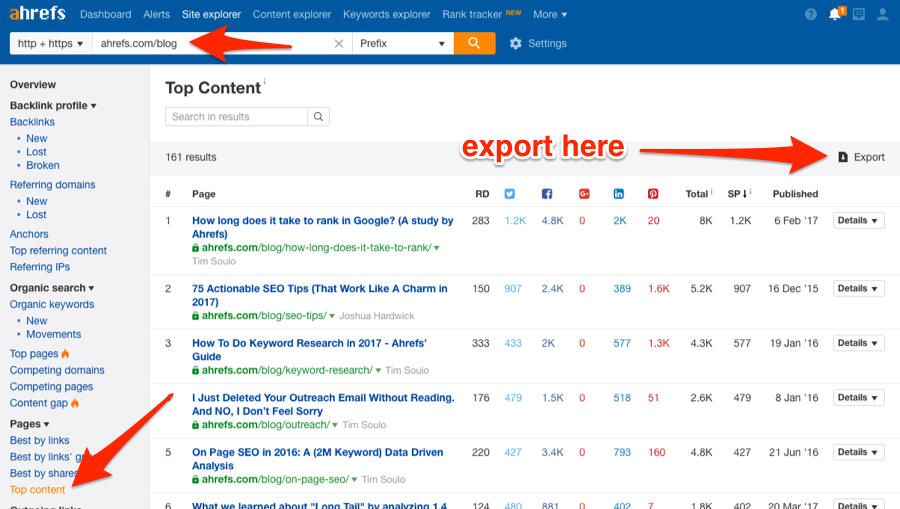
To begin, we need to grab the top pages report from Ahrefs—let’s use ahrefs.com/blog for our example.
Site Explorer > Enter ahrefs.com/blog > Pages > Top Content > Export as .csv
Next, make a copy of this Google Sheet then paste all data from the Top Content .csv export into cell A1 of the first tab (i.e. “1. Ahrefs Export”).
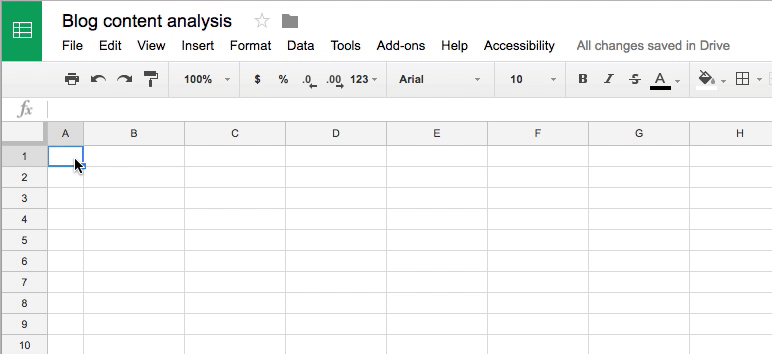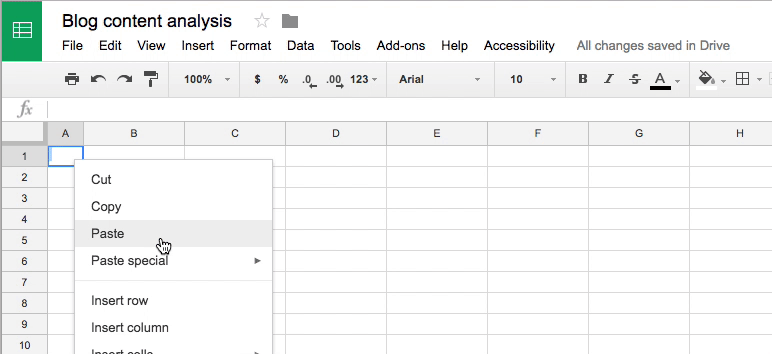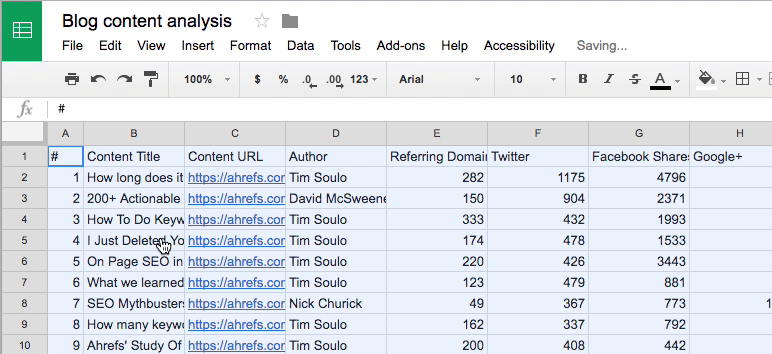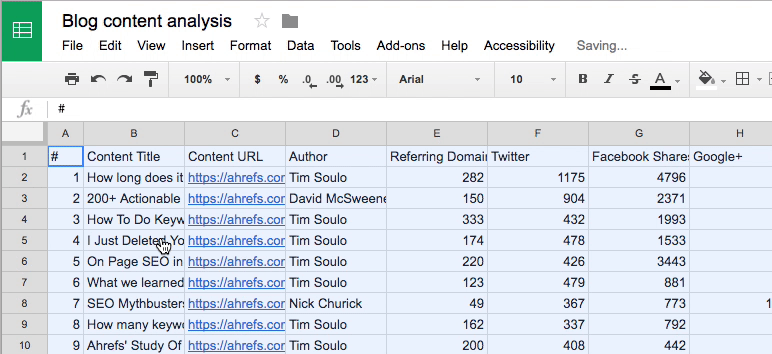
Now comes the scraping…
Open up one of the URLs from the “Content URL” column and locate the category under which the post was published.

We now need to figure out the XPath for this HTML element, so right-click and hit “Inspect” to view the HTML.
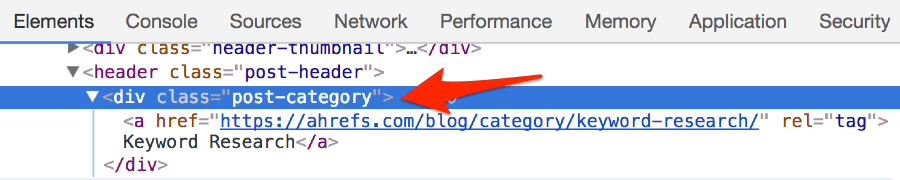
In this instance, we can see that the post category is contained within a <div> with the class “post-category”, which is nested within the <header> tag. This means our XPath would be:
//header/div[@class=‘post-category’]
Now that we know this, we can use Screaming Frog to scrape the post category for each post; here’s how:
- Open Screaming Frog and go to “Mode” > “List”;
- Go to “Configuration” > “Spider” and uncheck all the boxes (like this);
- Go to “Configuration” > “Custom” > “Extraction” > “Extractor 1” and paste in your XPath (e.g. //header/div[@class=‘post-category’]). Make sure you choose “XPath” as the scraper mode and “Extract Text” as the extractor mode (like this)
- Copy/paste all URLs from the Content URL into Screaming Frog, and start the scrape;
Once complete, head to the “Custom” tab, filter by “Extraction” and you’ll see the extracted data for each URL.
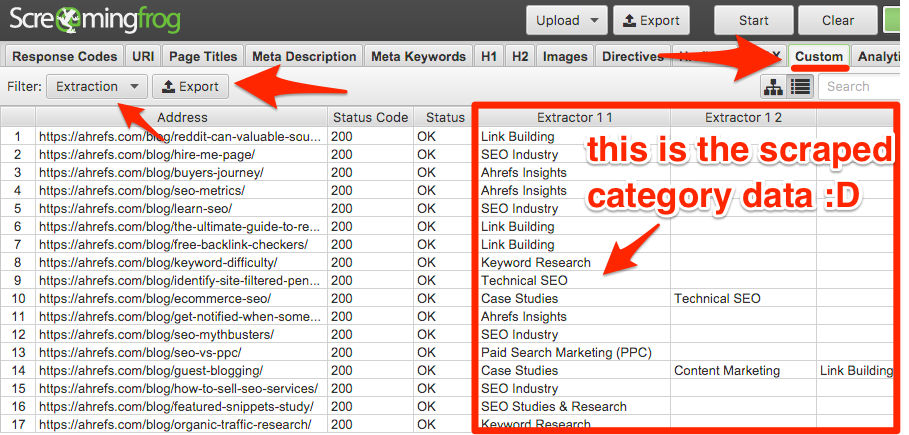
Hit “Export”, then copy all the data in the .csv into the next tab in the Google Sheet (i.e. “2. SF extraction”).
Go to the final tab in the Google Sheet (i.e. “RESULTS”) and you’ll see a bunch of data + accompanying graphs.
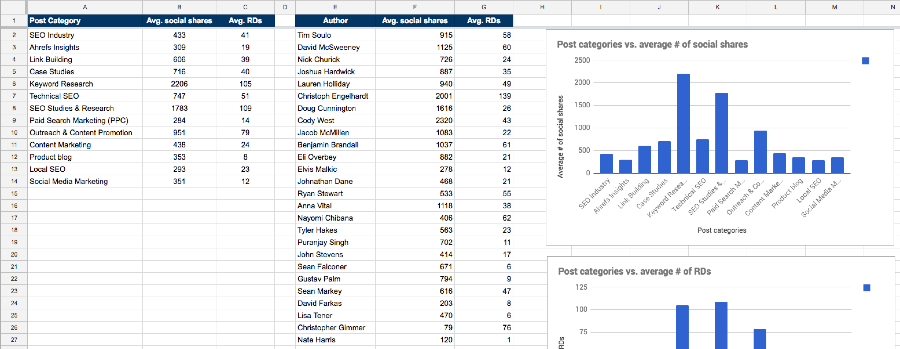
Here’s the spreadsheet with sample data.
5. Promote only the RIGHT kind of content on Reddit (by looking at what has already performed well)
Redditors despise self-promotion.
In fact, any lazy attempts to self-promote via the platform are usually met with a barrage of mockery and foul-language.
But here’s the thing:
Redditors have nothing against you sharing something with them; you just need to make sure it’s something they actually care about.
The best way to do this is to scrape (and analyze) what they liked in the past, then share more of that type of content with them.
Here’s the process:
- Choose a subreddit (e.g. /r/Entrepreneur);
- Scrape the top 1000 posts of all time;
- Analyse the data and act accordingly (yep, I’ve included a Google Sheet that does this for you!)
OK, first things first, make a copy of this Google Sheet + enter the subreddit you want to analyze. You should then see a formatted link to that subreddits top posts appear alongside it.

This takes you to a page showing the top 25 posts of all time for that subreddit.
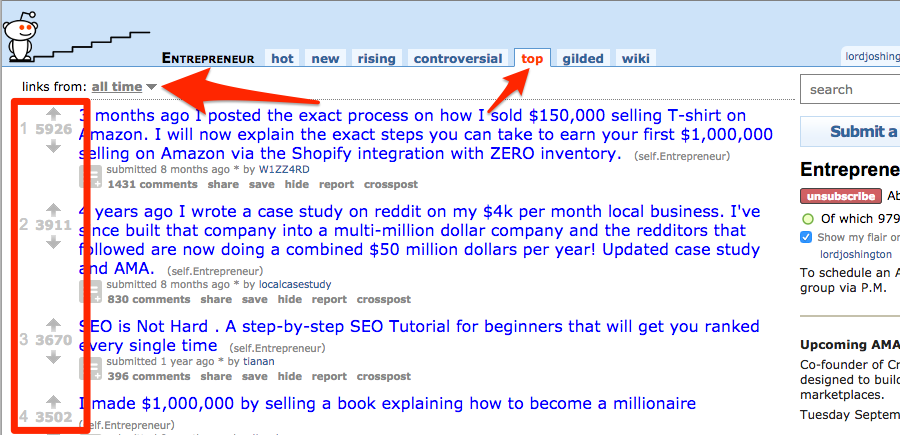
However, this page only shows the top 25 posts. We’re going to analyze the top 1,000, so we need to use a scraping tool to scrape multiple pages of results.
Reddit actually makes this rather difficult but Import.io (free up to 500 queries per month, which is plenty) can do this with ease.
Here’s what we’re going to scrape from these pages (hint: click the links to see an example of each data point)):
- Rank;
- Score/upvotes;
- Title;
- User submitted by;
- Comments;
- Link flair (optional as this is not available on all subreddits…it’s also more obvious on some subreddits than others—learn more here)
OK, let’s stick with /r/Entrepreneur for our example…
Go to Import.io > sign up > new extractor > paste in the link from the Google Sheet (shown above)
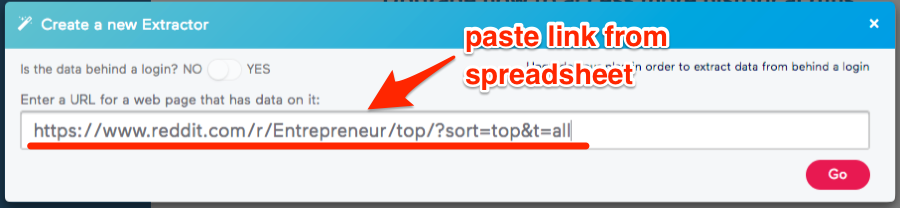
Click “Go”.
Import.io will now work its magic and extract a bunch of data from the page.
Hit “Save” (but don’t run it yet!)
Right now, the extractor is only set up to scrape the top 25 posts. You need to add the other URLs (from the tab labeled “2. MORE LINKS” in the Google Sheet) to scrape the rest.
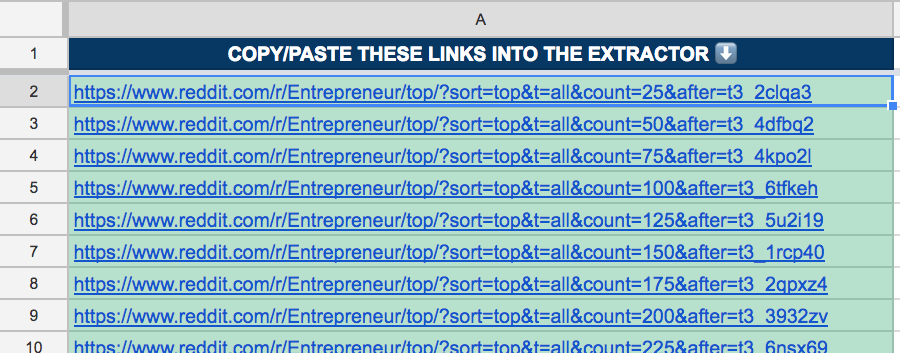
Add these under the “Settings” tab for your extractor.
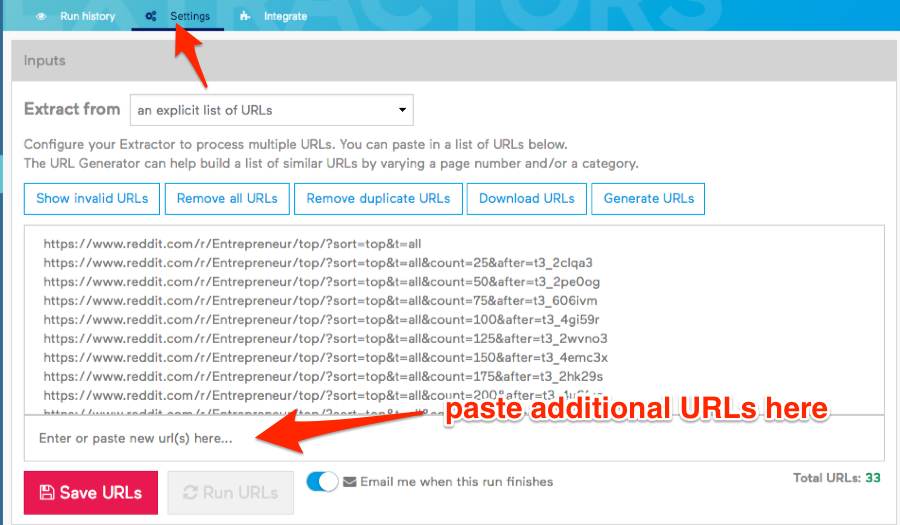
Hit “Save URLs” then run the extractor.
Download the .csv once complete.

Copy/paste all data from the .csv into the sheet labeled “3. IMPORT.IO EXPORT” in the spreadsheet.
Finally, go to the “RESULTS” sheet and enter a keyword—it will then kick back some neat stats showing how interested that subreddit is likely to be in your topic.
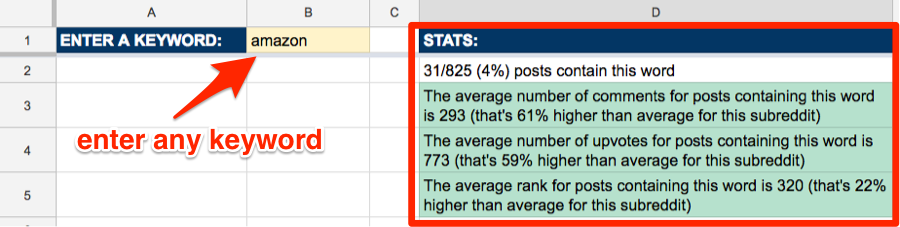
Here’s the spreadsheet with sample data.
6. Build relationships with people who are already fans of your content
Most tweets will drive ZERO traffic to your website.
That’s why “begging for tweets” from anyone and everyone is a terrible idea.
However, that’s not to say all tweets are worthless—it’s still worth reaching out to those who are likely to send real traffic to your website.
Here’s a workflow for doing this (note: it includes a bit of Twitter scraping):
- Scrape and add all Twitter mentions to a spreadsheet (using IFTTT);
- Scrape the number of followers for the people who’ve shared a lot of your stuff;
- Find contact details, then reach out and build relationships with these people.
OK, so first, make a copy of this Google Sheet.
IMPORTANT: You MUST make a copy of this on the root of your Google Drive (i.e. not in a subfolder). It MUST also be named exactly “My Twitter Mentions”.

Next, turn this recipe on within your IFTTT account (you’ll need to connect your Twitter + Google Drive accounts to IFTTT in order to do this).
What does this recipe do? Basically, every time someone mentions you on Twitter, it’ll scrape the following information and add it to a new row in the spreadsheet:
- Twitter handle (of the person who mentioned you);
- Their tweet;
- Tweet link;
- Time/date they tweeted
And if you go to the second sheet in the spreadsheet (i.e. the one labeled “1.Tweets”), you’ll see the people who’ve mentioned you and tweeted a link of yours the highest number of times.
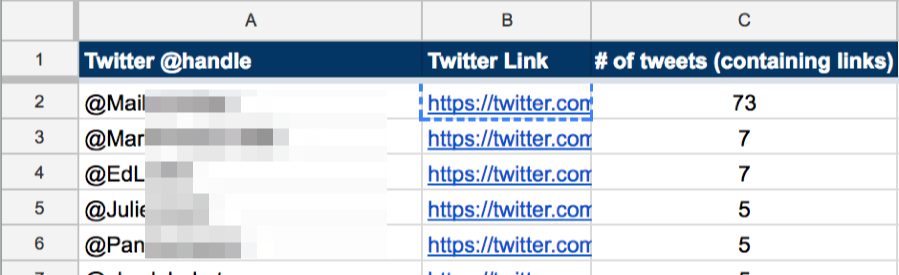
But, the fact that they’ve mentioned you a number of times doesn’t necessarily indicate that they’ll drive any real traffic to your website.
So, you now want to scrape the number of followers each of these people has.
You can do this with CSS selectors using Screaming Frog.
Just set your search depth to “0” (see here), then use these settings under the custom extractor:

Here’s each CSS selector (for clarification):
- Twitter Name: h1
- Twitter Handle: h2 > a > span > b
- Followers: li.ProfileNav-item.ProfileNav-item--followers > a > span.ProfileNav-value
- Website: div.ProfileHeaderCard > div.ProfileHeaderCard-url > span.ProfileHeaderCard-urlText.u-dir > a
Copy/paste all the Twitter links from the spreadsheet into Screaming Frog and run it.
Once finished, go to:
Custom > Extraction > Export

Open the exported .csv, then copy/paste all the data into the next tab in the sheet (i.e. the one labeled “2. SF Export”).
Lastly, go to the final tab (i.e. “3. RESULTS”) and you’ll see a list of everyone who’s mentioned you along with a bunch of other information including:
- # of times they tweeted about you,
- # of followers
- Their website (where applicable)
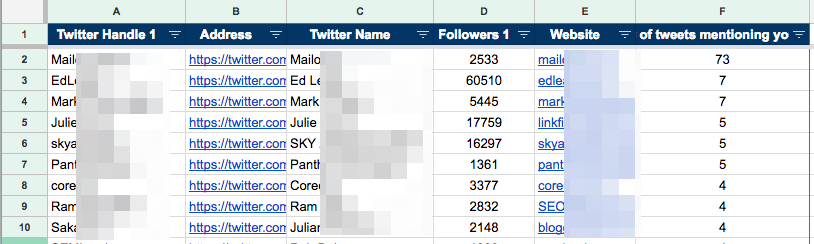
Because these people have already shared your content in the past, and also have a good number of followers, it’s worth reaching out and building relationships with them.
Here’s the spreadsheet with sample data.
Final thoughts
Web scraping is crazily powerful.
All you need is some basic XPath/CSS/Regex knowledge (along with a web scraping tool, of course) and it’s possible to scrape anything from any website in a matter of seconds.
I’m a firm believer that the best way to learn is by doing, so I highly recommend that you spend some time replicating the experiments above. This will also teach you to pay attention to things that could easily be automated with web scraping in future.
So, play around with the tools/ideas above and let me know what you come up with in the comments section below 🙂



