
Molti siti web usano dei tipi di JavaScript per aggiungere interattività e per migliorare la user experience. Alcuni li usano per i menu, inserire prezzi o prodotti, prendere contenuti da molte fonti, o in alcuni casi, per tutto ciò che è nel sito. La realtà nel web contemporaneo è che JavaScript è onnipresente.
Come ha detto John Mueller di Google:
The web has moved from plain HTML — as an SEO you can embrace that. Learn from JS devs & share SEO knowledge with them. JS’s not going away.
— 🍌 John 🍌 (@JohnMu) August 8, 2017
Non sto dicendo che i tecnici SEO devono andare subito ad imparare la programmazione JavaScript. E’ l’opposto. I tecnici SEO devono soprattutto conoscere come Google gestisce i JavaScript e come risolvere eventuali problemi. In pochi casi succederà che un tecnico SEO sia autorizzato a toccare il codice. Il mio obiettivo in questo articolo è che tu impari a:
- Cos’è la SEO JavaScript
- Come Google esamina le pagine con JavaScript
- Come fare diagnosi e risolvere problemi JavaScript
- Opzioni di rendering
- Rendere il sito JavaScript SEO friendly
La Javascript SEO è la parte della SEO tecnica (Search Engine Optimization) che cerca di rendere siti web con molto JavaScript facili da scansionare ed indicizzare, ed anche facili per la ricerca. L’obiettivo è di far trovare questi siti web e posizionarli in alto nei motori di ricerca.
E’ JavaScript un male per la SEO; è JavaScript il demonio? Assolutamente no. E’ solamente diversa da ciò che molti tecnici SEO sono abituati, e c’è una piccola curva di apprendimento. Le persone tendono ad usarla troppo per cose che hanno probabilmente soluzioni migliori, ma devi lavorare con ciò che hai nel momento. Devi solamente sapere che JavaScript non è perfetto e non è sempre lo strumento giusto. Non può essere progressivamente analizzato, al contrario di HTML e CSS, e può essere pesante nelle performance e caricamento pagina. In molti casi, potresti negoziare performance sulla funzionalità.
Nei primi tempi dei motori di ricerca, una risposta di un HTML scaricato era sufficiente per vedere il contenuto di molte pagine. Grazie all’ascesa di JavaScript, i motori di ricerca ora devono scansionare molte pagine come farebbe un browser per poter vedere il contenuto come lo vede un utente.
Il sistema che gestisce il processo di rendering di Google si chiama Web Rendering Service (WRS). Google ha rilasciato un diagramma semplicistico per spiegare come funziona il processo.
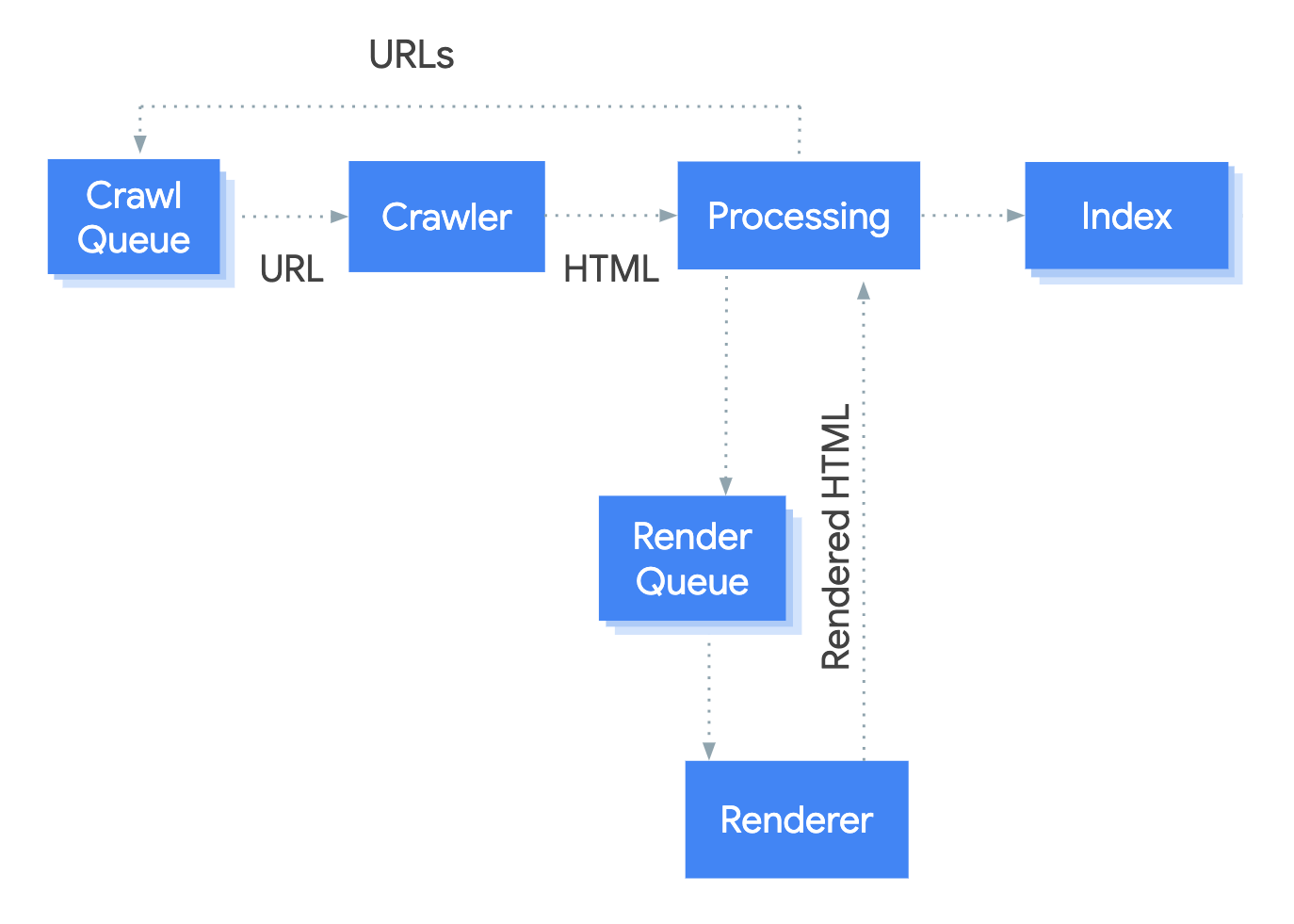
Immaginiamo di iniziare il processo dall’URL.
1. Crawler
Il crawler invia richieste GET al server. Il server risponde con gli header e i contenuti dei file, che sono così salvati.
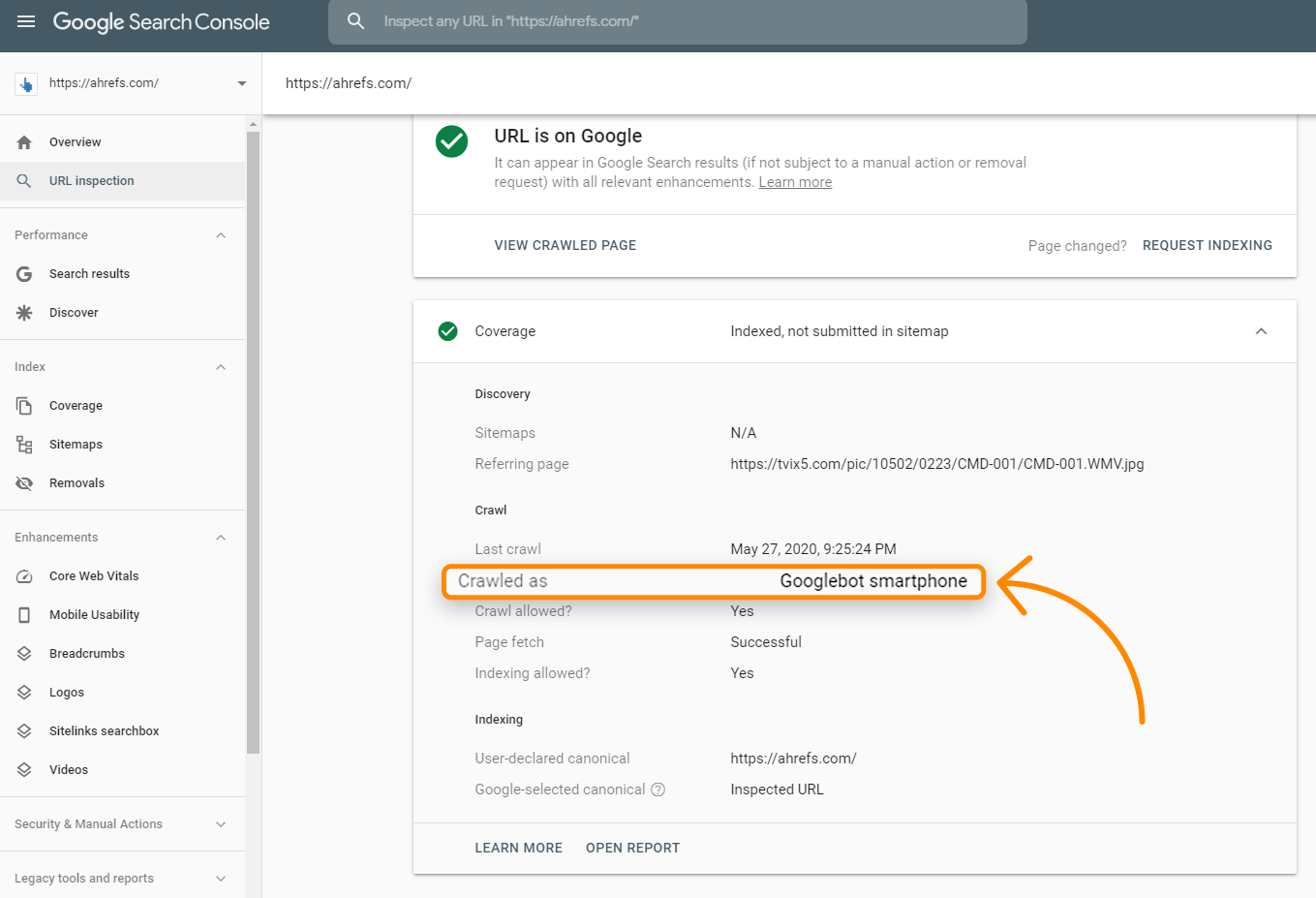
La richiesta probabilmente avviene da un user-agent mobile dal momento che Google sta soprattutto indicizzando mobile-first. Puoi controllare per vedere come Google sta scannerizzando il tuo sito con lo strumento URL Inspection dentro la Search Console. Quando lo avvii per una URL, controlla l’informazione Copertura su “Scansionato come”, e ti dovrebbe dire se sei nell’indicizzazione desktop o mobile-first.
Le richieste avvengono spesso da Mountain View, CA, USA, ma a volte fanno alcune scansioni per pagine locali dall’esterno degli Stati Uniti. Lo dico perché alcuni siti bloccano o trattano i visitatori di un paese specifico o con un particolare IP in modi diversi, e potrebbe succedere così che il tuo contenuto non venga visto dal Googlebot.
Alcuni siti potrebbero anche usare un rilevatore user-agent per mostrare contenuto ad un crawler specifico. Specialmente con i siti JavaScript, Google potrebbe vedere qualcosa di diverso dall’utente. Ecco perché gli strumenti Google come lo strumento Ispezione URL di Google Search Console, il Test Mobile-Friendly, e i Test Rich Results sono importanti per risolvere i problemi legati alla SEO JavaScript. Ti mostrano ciò che Google vede e sono utili per sapere se Google li sta bloccando e se possono vedere il contenuto nella pagina. Spiegherò come fare il test nella sezione del render perché ci sono delle nette differenze tra la richiesta GET scaricata, la pagina renderizzata, ed anche gli strumenti di test.
E’ anche importante ricordare che mentre Google indica l’output del processo di scansione come “HTML” per l’immagine sopra, in realtà, stanno scannerizzando e memorizzando tutte le risorse necessarie per costruire la pagina. Pagine HTML, file JavaScript, CSS, richieste XHR, endpoint API, ed altro.
2. Elaborazione
Ci sono molti sistemi offuscati dal termine “Elaborazione” nell’immagine. Andrò a parlare di alcuni di essi che sono rilevanti per JavaScript.
Link e Risorse
Google non naviga da pagina a pagina come farebbe un utente. Parte dell’Elaborazione è controllare la pagina e link alle altre pagine e file necessari a costruire la pagina. Questi link sono estratti e aggiunti alla coda di scansione, che è ciò che Google usa per le priorità e la programmazione delle scansioni.
Google prenderà i link alle risorse (CSS, JS, ecc.) necessari per costruire una pagina da tag come <link>. Tuttavia, i link alle altre pagine devono essere in un formato specifico perché Google li tratti come link. I link interni ed esterni devono essere un tag <a> con un attributo href. Ci sono molti modi in cui puoi farlo funzionare per gli utenti con JavaScript e difficili per le ricerche.
Giusto:
<a href=”/page”>semplice è meglio</a> <a href=”/page” onclick=”goTo(‘page’)”>va comunque bene</a>
Sbagliato:
<a onclick=”goTo(‘page’)”>no, non c’è href</a> <a href=”javascript:goTo(‘page’)”>no, link mancante</a> <a href=”javascript:void(0)”>no, link mancante</a> <span onclick=”goTo(‘page’)”>errato elemento HTML</span> <option value="page">no, errato elemento HTML</option> <a href=”#”>no link</a> Pulsante, ng-click, ci sono molti modi per farlo sbagliato.
Non c’entra molto che i link interni aggiunti con JavaScript non saranno presi finché ci sarà il rendering. Dovrebbe essere relativamente rapido e non causare problemi la maggior parte delle volte.
Caching
Ogni file che Google scarica, incluse le pagine HTML, file JavaScript, file CSS, ecc, finiranno spesso nella cache. Google ignorerà il timing della cache e ne prenderà una copia ogni volta che lo vorrà. Ne parlerò ancora e sul perché è importante nella sezione Render.
Eliminazione dei duplicati
I contenuti duplicati possono essere eliminati o deprioritizzati dall’HTML scaricato prima di essere inviato al render. Con i modelli di shell app, poco codice e contenuto potrebbe essere visto nella risposta HTML. Infatti, ogni pagina del sito potrebbe mostrare lo stesso codice, e potrebbe essere lo stesso codice mostrato in diversi siti web. Questo a volte potrebbe trattare le pagine come duplicate e non andranno immediatamente nel rendering. Ancora peggio, la pagina sbagilata o il sito sbagilato possono apparire nei risultati di ricerca. Si dovrebbe risolvere da solo con il tempo ma può essere problematico, specialmente con i siti web più nuovi.
Direttive Più Restrittive
Google sceglie le direttive più restrittive tra HTML e la versione renderizzata di una pagina. Se JavaScript cambia una direttiva ed è in conflitto con quella HTML, Google semplicemente seguirà quella più restrittiva. Noindex verrà prima di index, e noindex nel HTML farà saltare completamente il render.
3. Coda del render
Oggi ogni pagina va al render. Uno dei più grandi problemi per molti tecnici SEO con JavaScript e indicizzazione in 2 passaggi (HTML e pagina renderizzata) è che le pagine potrebbero non essere renderizzate per giorni o settimane. Quando Google ha analizzato la cosa, ha trovato che le pagine andavano nel render con un tempo mediano di 5 secondi, ed il novantesimo percentile erano minuti. Quindi il tempo necessario tra l’HTML ed il rendering della pagina non dovrebbe essere un problema nella maggioranza dei casi.
4. Renderizzatore
Il renderizzatore è dove Google renderizza una pagina per vedere quello che l’utente vede. Qui è dove avviene l’esecuzione di JavaScript ed ogni modifica fatta da JavaScript al Document Object Model (DOM).

Per questo, Google sta utilizzando un browser Chrome che ora è un “evergreen”, che significa dovrebbe usare l’ultima versione di Chrome e supportare le ultime funzionalità. Fino a poco fa, Google faceva render con Chrome 41, quindi molte funzionalità non erano supportate.
Google ha più informazioni nel Web Rendering Service (WRS), che includono cose come il rifiuto di permessi, essere privo di stato, ed altre cose degne d’essere lette.
Fare render su scala del web potrebbe essere l’ottava meraviglia del mondo. E’ un compito serio e prende una grande fetta di risorse. A causa della scala, Google prende molte scorciatoie con il processo di rendering per velocizzare le cose. Ad Ahrefs, siamo gli unici ad avere uno strumento che renderizza pagine web su larga scala, e riusciamo a renderizzare ~150 milioni di pagine al giorno per rendere il nostro indice più completo. Ci permette di controllare i redirect JavaScript e possiamo anche mostrare i link che troviamo inseriti nei JavaScript che mostriamo con un tag JS nel report link:

Risorse in cache
Google sta usando molto le risorse in cache. Pagine in cache; file in cache; le richieste API sono in cache; di base, tutto passa dalla cache prima di essere inviato al render. Non escono e scaricano ogni risorsa per ogni pagina scaricata, invece vengono utilizzate risorse in cache per velocizzare il processo.
Questo può portare ad alcuni stati impossibili dove versioni del file precedente sono usate nel processo di rendering e e le versioni indicizzate di una pagina potrebbe contenere parti di file più vecchi. Puoi usare il versioning del file o l’impronta digitale del contenuto per generare nuovi nomi di file dove cambiamenti significativi sono fatti così google deve scaricare la versione aggiornata della risorsa da renderizzare.
Timeout Non specificato
Un mito comune nella SEO è che il motore di render attende solo 5 secondi per caricare la tua pagina web. Mentre è sempre una buona idea per mettere un sito più veloce, questo mito non ha molto senso con il metodo in cui Google usa la cache dei file come detto sopra. Di fatto caricano una pagina con tutto già nella cache. Il mito nasce da strumenti di test come lo strumento di Ispezione URL dove le risorse sono prese in diretta e devono impostare un limite ragionevole.
Non c’è un tempo limite per il motore render. Ciò che fanno è qualcosa di simile a quello che fa Rendertron. Aspettano probabilmente qualcosa come networkidle0 dove non c’è più attività di network in corso e impostano un tempo massimo in caso qualcosa si blocchi o qualcuno stia provando a minare bitcoin nelle loro pagine.
Ciò Che Vede Googlebot
Googlebot non prende azioni nelle pagine web. Non clicca le cose o effettua scroll, ma non significa che non abbiano soluzioni. Per i contenuti, fintanto che è caricato nella DOM senza un’azione richiesta, lo vedranno. Ne scriverò di più nella sezione della risoluzione dei problemi ma di base, se il contenuto è nel DOM ma è nascosto, sarà visto. Se non è caricata nel DOM dopo un click, allora il contenuto non sarà trovato.
Google non ha neanche bisogno di fare lo scorrimento per vedere il tuo contenuto perché hanno trucchetti interessanti per vedere il contenuto. Per il mobile, caricano la pagina con una dimensione schermo di 411x731 pixel e ridimensionano la lunghezza a 12.140 pixel. Essenzialmente, diventa un telefono molto lungo con uno schermo di dimensione 411x12140 pixel. Per il desktop, fanno lo stesso e vanno da 1024x768 a 1024x9307 pixel.

Un’altra scorciatoia interessante è che Google non colora i pixel durante il processo di rendering. Prende tempo e risorse addizionali per finire il caricamento di una pagina, e non hanno bisogno di vedere lo stato finale del pixel colorato. Come dice Martin Splitt di Google:
https://youtube.com/watch?v=Qxd_d9m9vzo%3Fstart%3D154
In ricerca Google a noi non interessa davvero il pixel perché non vogliamo farlo vedere a qualcuno. Vogliamo processare l’informazione e l’informazione semantica ed abbiamo bisogno di qualcosa nello stato intermedio. Non dobbiamo colorare i pixel.
Un grafico può aiutare a spiegarlo un po’ meglio. Nei Dev Tools di Chrome, se lanci un test nella tab Performance avrai un grafico di caricamento. La parte verde rappresenta la sessione della colorazione e per Googlebot non è mai successa quindi ha risparmiato risorse.

Grigio = download
Blu = HTML
Giallo = JavaScript
Viola = Layout
Verde = Colorazione
5. Coda di scansionamento
Google ha una risorsa che un po’ parla del budget del crawler, ma dovresti sapere che ogni sito ha il proprio budget del crawler, ed ogni richiesta deve avere una priorità. Google inoltre deve bilanciare la scansione del tuo sito con ogni altro sito su internet. I siti nuovi generalmente o siti con molte pagine dinamiche saranno scansionati più lentamente. Alcune pagine saranno aggiornate meno di altre, ed alcune risorse potrebbero essere richieste meno frequentemente.
Una ‘epifania’ con i siti JavaScript è che possono aggiornare solamente parti del DOM. Navigare su altre pagine come utente potrebbe non aggiornare alcune parti come tag titolo e tag canonical nel DOM, ma potrebbe non essere un problema per i motori di ricerca. Ricorda, Google carica ogni pagina senza stato, quindi non stanno salvando informazioni precedenti e non stanno navigando tra le pagine. Ho visto tecnici SEO bloccarsi nel pensare che c’è un problema per ciò che vedono dopo la navigazione da una pagina all’altra, come tag canonical che non si aggiornano, ma Google potrebbe non vedere mai questi stati. Gli sviluppatori possono sistemare con l’aggiornamento di stato usando ciò che si chiama History API , ma comunque potrebbe non essere un problema. Ricarica la pagina e controlla ciò che vedono o ancora meglio caricala in uno strumento di testing di Google per vedere ciò che loro vedono. Di più tra poco.
Vista-sorgente vs. Ispezione
Quando fai click con tasto destro sulla finestra browser, vedrai un paio di opzioni per visualizzare il codice sorgente della pagina e per ispezionare la pagina. La vista sorgente ti mostrerà ciò che avresti con una richiesta GET. E’ la base HTML della pagina. L’ispezione mostra il DOM processato dopo le modifiche fatte ed è più simile al contenuto che vedono i Googlebot. E’ fondamentalmente l’ultima e più aggiornata versione della pagina. Dovresti usare l’ispezione al posto della vista-sorgente quando lavori con JavaScript.
Cache di Google
La cache di Google non è un sistema affidabile per controllare ciò che vede il Googlebot. E’ di solito l’HTML iniziale, anche se a volte è la versione renderizzata HTML o una vecchia versione. Il sistema è stato fatto per vedere il contenuto quando un sito web è inaccessibile. Come strumento di diagnosi non è molto utile.
Strumenti di Test Google
Gli strumenti di test di Google come URL Inspector all’interno di Google Search Console, Mobile Friendly Tester, Rich Result Tester sono utili per la diagnostica. Eppure, anche questi strumenti sono leggermente diversi da ciò che Google vedrà. Ho già parlato del timeout di 5 secondi in questi strumenti che il motore di render non ha, ma questi strumenti sono anche diversi perché prendono le risorse in tempo reale e non usano versioni in cache come farebbe il motore di render. Gli screenshot in questi strumenti inoltre mostrano pagine con i pixel colorati, che Google non mostra nel motore di render.
Questi tool sono utili per vedere se il contenuto è caricato anche sul DOM. L’HTML mostrato in questi strumenti è del motore di render DOM. Puoi cercare del testo per vedere se di default è stato caricato.
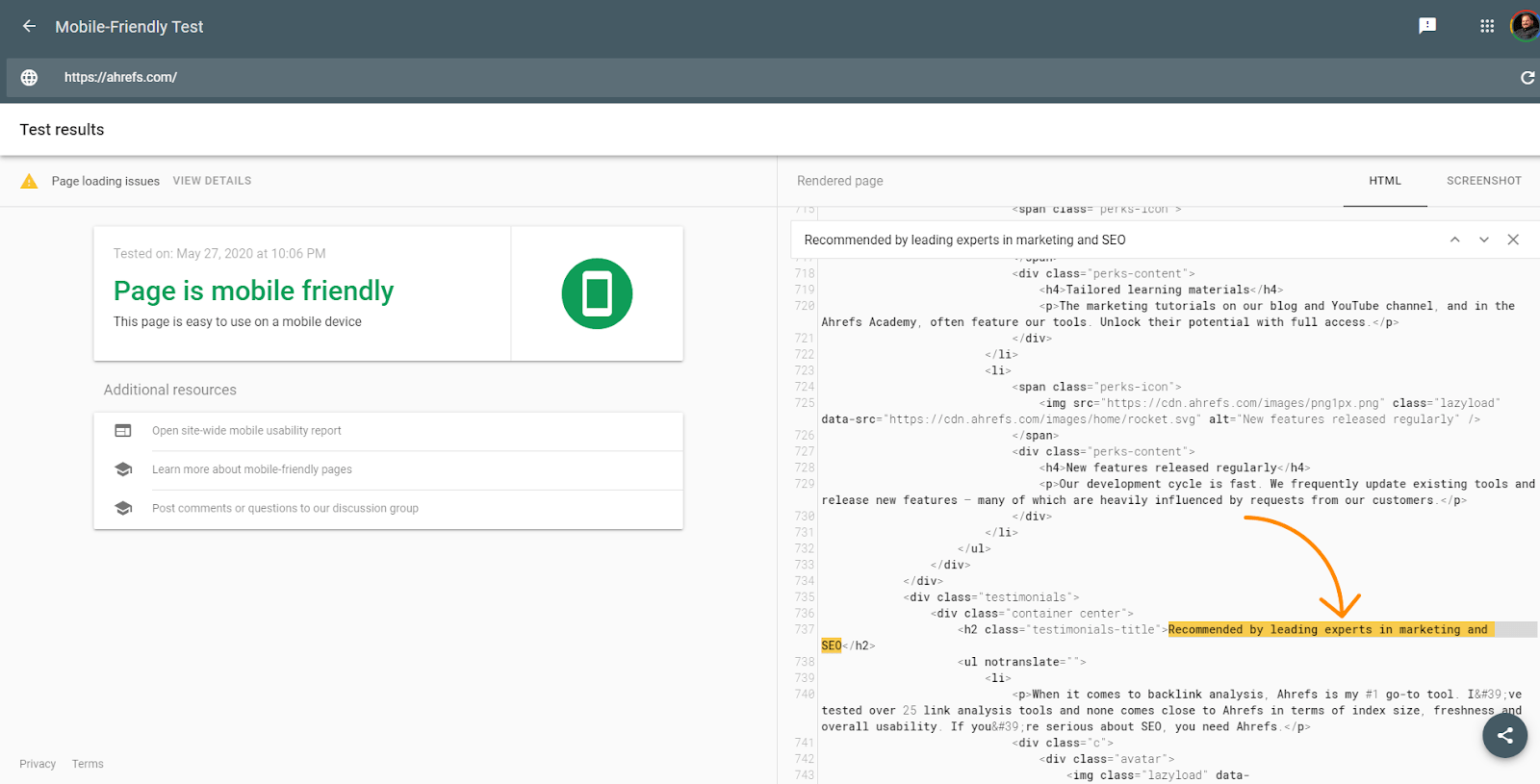
Gli strumenti inoltre ti fanno vedere le risorse che potrebbero essere bloccate e messaggi di errore della console utili alla risoluzione di problemi.
Cercare Testo su Google
Un rapido controllo che puoi fare è semplicemente cercare un pezzo del tuo content su Google Cerca per “una frase del tuo contenuto” e vedi se restituisce la pagina. Se lo è, allora è stata probabilmente vista. Nota che i contenuti nascosti di default potrebbero non apparire nello snippet nelle SERP.
Ahrefs
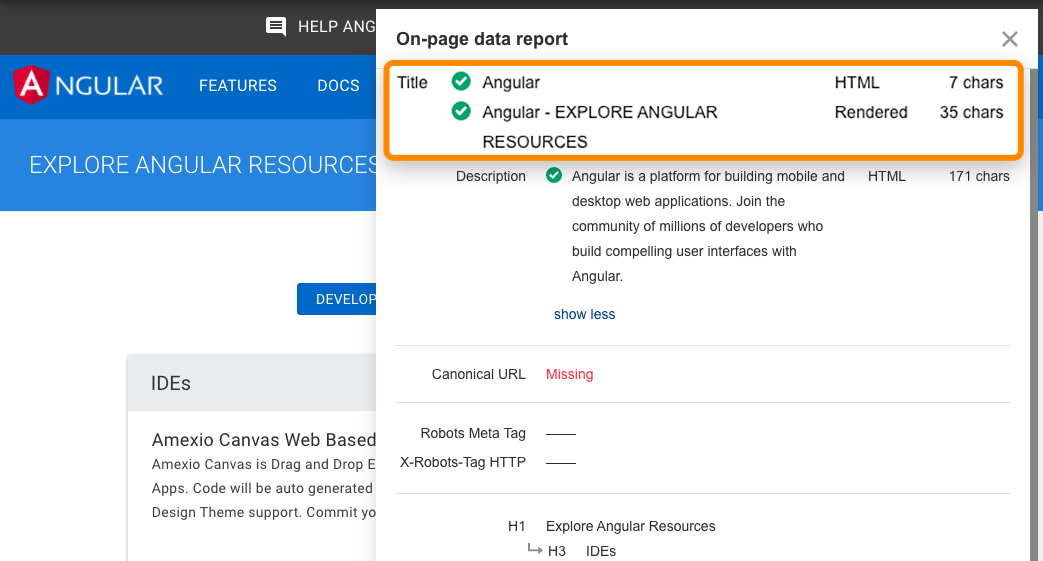
Assieme alle pagine renderizzare nell’indice, puoi abilitare JavaScript nella scansione del Site Audit per avere maggiori dati nei tuoi audit.

Anche la Toolbar di Ahrefs supporta JavaScript e permette di comarare HTML con versioni di tag renderizzate.
Ci sono molte opzioni quando si tratta di renderizzare JavaScript. Google ha uno schema valido che adesso ti mostrerò. Qualsiasi tipo di SSR, rendering statico, setup prerendering sarà buono per i motori di ricerca. Il principale che causerà problemi è il rendering completo client-side dove tutto il rendering avviene nel browser.
Mentre Google potrebbe non aver problema alcuno con i rendering client-side, è preferibile scegliere un’opzione di rendering diversa per supportare altri motori di ricerca. Anche Bing ha supporto per rendering JavaScript, ma non si conosce la scala. Yandex e Baidu hanno supporto limitato da quanto ho visto, e molti altri motori di ricerca hanno poco o nulla per JavaScript.

C’è anche l’opzione del Dynamic Rendering, che è il render per alcuni user-agent. Questo è di base una scorciatoia ma può essere utile per il render per alcuni bot come i motori di ricerca o i bot dei social media. I bot dei social media non avviano JavaScript, quindi cose come i tag OG non saranno visti a meno di avviare il render del contenuto prima di servirli.
Se stavi usando il vecchio schema di scansione AJAX, nota che è stata deprecata e potrebbe non essere più supportata.
Un sacco di processi sono simili alle cose che i tecnici SEO stanno già facendo, ma ci potrebbero essere alcune piccole differenze.
SEO On-page
Tutte le regole dei contenuti della SEO on-page, tag title, meta description, attributi alt, tag meta robot, ecc. rimangono valide. Vedi SEO On-Page: Una Guida Pratica.
Un paio di problemi che vedo ripetutamente quando lavoro con siti web JavaScript sono che i titoli e descrizioni possono essere riutilizzati e che gli attributi alt nelle immagini sono raramente impostati.
Permettere la scansione del crawler
Non bloccare l’accesso alle risorse. Google deve essere in grado di accedere e scaricare le risorse così può effettuare il rendering correttamente. Nel tuo robots.txt, il modo più facile di permettere accesso alle risorse dal crawl è aggiungere:
User-Agent: Googlebot Allow: .js Allow: .css
Gli URL
Cambiare gli URL quando si aggiornato i contenuti. Ho già menzionato la History API, ma dovresti sapere che con gli schemi JavaScript, avranno una via che ti permette di mappare a URL puliti. Non vorrai usare hash (#) per il routing. E’ un problema particolarmente per Vue ed alcune prime versioni di Angular. Quindi per un URL come abc.com/#qualcosa, tutto quello che c’è dopo # è di solito ignorato dal server. Per risolverlo su Vue, puoi lavorare con lo sviluppatore per modificare questo:
Vue router:
Usa modalità ‘History’ al posto della modalità tradizionale ‘Hash’.
const router = new VueRouter ({
mode: ‘history’,
router: [] //the array of router links
)}Contenuti duplicati
Con JavaScript, ci possono essere molti URL per lo stesso contenuto, e ciò porta a problemi di contenuto duplicato. Può succedere per capitalizzazione, ID, parametri dell’ID, ecc. Quindi, tutto questo può esistere:
dominio.com/Abc
dominio.com/abc
dominio.com/123
dominio.com/?id=123
La soluzione è semplice. Scegli la versione che vuoi indicizzare ed imposta i tag canonical.
Opzioni dei “plugin” SEO
Per gli schemi JavaScript, questi sono di solito chiamati moduli. Troverai versioni per gli schemi più comuni come React, Vue ed Angular cercando il nome dello schema + nome del modulo come “React Helmet”. Meta tags, Helmet e Head sono i moduli più famosi con funzioni simili e ti permettono di impostare molti dei tag popolari per la SEO.
Pagine di errore
Siccome gli schemi JavaScript non sono nel lato del server, non possono davvero inviare un errore di server come un 404. Hai un paio di opzioni per le pagine di errore:
- Usa un redirect JavaScript in una pagina che non risponde con un codice 404
- Aggiungi un tag noindex alla pagina che sta avendo errori con alcuni messaggi di errore come “404 Pagina Non Trovata”. Sarà trattata come un 404 soffice visto che il vero codice di stato inviato sarà un 200 okay.
Sitemap
Gli schemi JavaScript hanno tipicamente router che mappano a URL puliti. Questi router di solito hanno un modulo addizionale che può anche creare sitemap. Puoi trovarli cercando per il tuo sistema + router sitemap, come “Vue router sitemap”. Molte delle soluzioni di render potrebbero avere opzioni per sitemap. Di nuovo, trova il sistema che usi e scrivi su Google il sistema + sitemap come “Gatsby sitemap” e sarai sicuro di trovare una soluzione che già esiste.
I redirect
I tecnici SEO sono abituati ai redirect 301/302, dal lato server. Ma JavaScript gira spesso come client-side. Questo va bene perché Google analizza la pagina e segue i redirect. I redirect passano comunque tutti i segnali come PageRank. Puoi anche trovare solitamente questi redirect nel codice cercando per “window.location.href”.
Internazionalizzazione
Ci sono di solito alcuni opzioni di modulo per diversi schemi che supportano alcune funzionalità necessarie per l’internazionalizzazione come hreflang. Sono stati portati normalmente su sistemi diversi e includono i18n, intl, o molte volte lo stesso modulo utilizzato per tag header come Helmet può essere usato per aggiungere un tag necessario.
Lazy loading
Ci sono spesso moduli per gestire il lazy loading. Se non lo hai ancora notato, ci sono moduli per gestire praticamente tutto ciò di cui hai bisogno quando lavori con gli schemi JavaScript. Lazy e Suspense sono i moduli più famosi per il lazy loading. Dovrai impostare il lazy loading per le immagini, ma attento a non impostare il lazy loading nei contenuti. Può essere fatto con JavaScript, ma potrebbe non essere analizzato correttamente dai motori di ricerca.
Conclusioni
JavaScript è uno strumento da usare con saggezza, e non qualcosa da temere dai tecnici SEO. Mi auguro che questo articolo ti ha aiutato a capire come lavorarci meglio, ma non aver paura di chiedere ai tuoi sviluppatori e lavorare assieme a loro e chiedere domande. Saranno i tuoi maggiori alleati nell’aiutarti a migliorare il tuo sito JavaScript per i motori di ricerca.
Hai domande? Puoi farmele su Twitter.
Tradotto da Mauro Marinello


