Le contenu dupliqué est un erreur que je vois souvent passer lors de mes audits SEO.
Lisez n’importe quoi à ce sujet, et vous en ressortirez convaincu que votre site est une bombe à retardement. La pénalité Google n’est qu’une question de jours.
Heureusement, ce n’est pas si dramatique, mais le contenu dupliqué peut quand même nuire à votre référencement naturel. Et comme 25 à 30 % du web est constitué de contenu dupliqué, autant savoir comment éviter et corriger ce type de problème.
Dans ce guide, vous allez apprendre :
- Ce qu’est le contenu dupliqué
- Pourquoi le contenu dupliqué est mauvais pour le SEO
- Si Google applique une pénalité pour contenu dupliqué
- Les causes courantes de contenu dupliqué
- Comment détecter et corriger le contenu dupliqué
Le contenu dupliqué, c’est un contenu identique ou très similaire qui apparaît à plusieurs endroits sur le web. Il peut exister au sein d’un même site ou sur plusieurs sites différents.
Par exemple, jouons à trouver les différences…
Voici la page située à l’URL caltonnutrition.com/tag/protein-powder/…
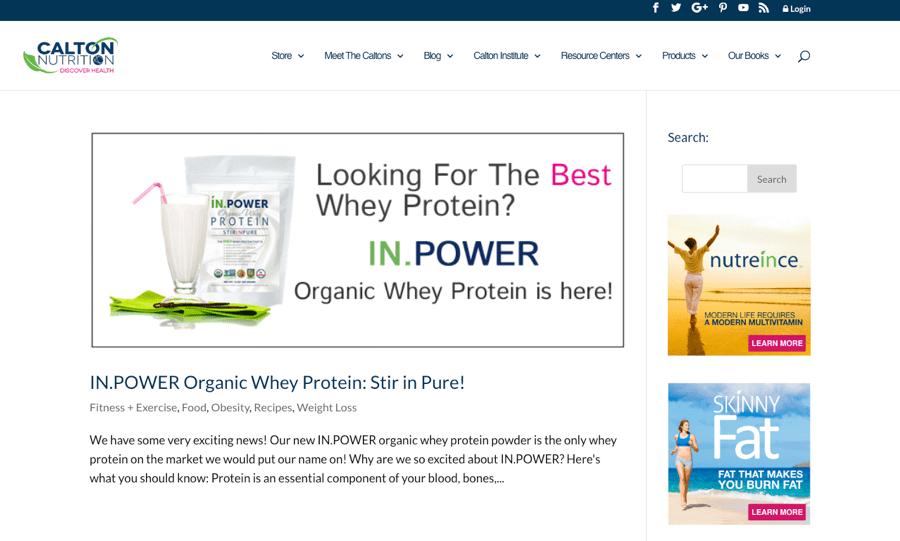
… et voici la page à l’URL caltonnutrition.com/tag/whey/ :
Vous voyez une différence ? Moi non plus. Le contenu des deux URL est identique. Autrement dit : du contenu dupliqué.
Google affirme qu’il n’existe pas de pénalité pour contenu dupliqué. Mais le contenu dupliqué peut quand même nuire à vos performances SEO, pour plusieurs raisons.
- Des URL indésirables ou peu lisibles dans les résultats de recherche
- La dilution des backlinks
- Une consommation inutile du budget de crawl
- Du contenu copié qui vous dépasse dans les classements
1. Des URL indésirables dans les résultats de recherche
Imaginez que la même page soit accessible via trois URL différentes :
- domain.com/page/
- domain.com/page/?utm_content=buffer&utm_medium=social
- domain.com/category/page/
La première devrait apparaître dans les résultats, mais Google peut se tromper. Si c’est le cas, une URL peu lisible prend sa place.
Les internautes étant moins enclins à cliquer sur une URL peu engageante, vous risquez de perdre du trafic organique.
2. La dilution des backlinks
Si le même contenu est accessible via plusieurs URL, chacune d’elles peut attirer des backlinks. Résultat : la « popularité de lien » se répartit entre ces URL.
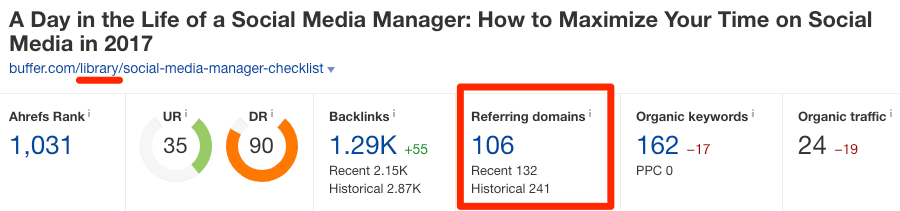
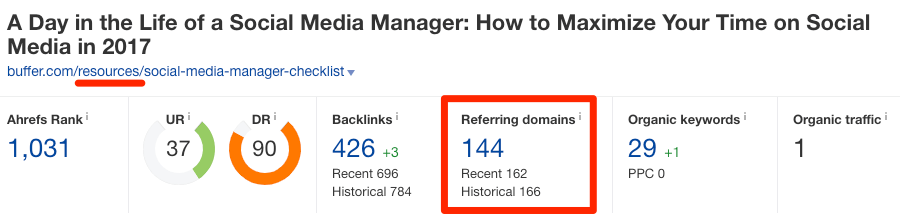
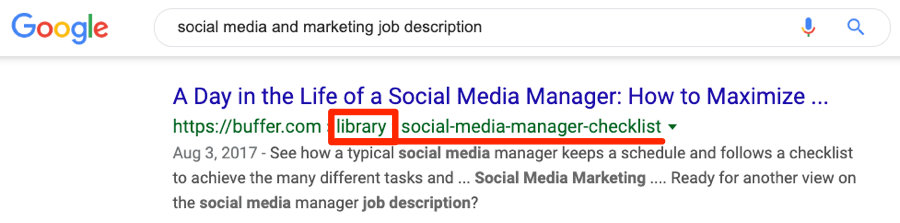
Pour illustrer cela, regardez ces deux pages sur buffer.com :
- https://buffer.com/library/social-media-manager-checklist
- https://buffer.com/resources/social-media-manager-checklist
Ces pages sont quasiment identiques. Elles comptent respectivement 106 et 144 domaines référents (les domaines référents sont des backlinks provenant de sites uniques).
Pas de panique : ce n’est pas toujours un problème, grâce à la façon dont Google gère le contenu dupliqué.
En résumé, quand Google détecte du contenu dupliqué, il regroupe les URL dans un même cluster. Il « sélectionne ensuite ce qu’il considère comme la “meilleure” URL pour représenter le cluster dans les résultats de recherche » et « consolide les propriétés des URL du cluster, comme la popularité des liens, vers l’URL représentative ». Ce processus s’appelle la canonicalisation.
Dans le cas ci-dessus, Google ne devrait afficher qu’une seule des URL dans la recherche organique et attribuer tous les domaines référents du cluster (106+144) à cette URL.
Mais ce n’est pas ce qui se passe : on voit les deux URL se classer pour des mots-clés similaires.
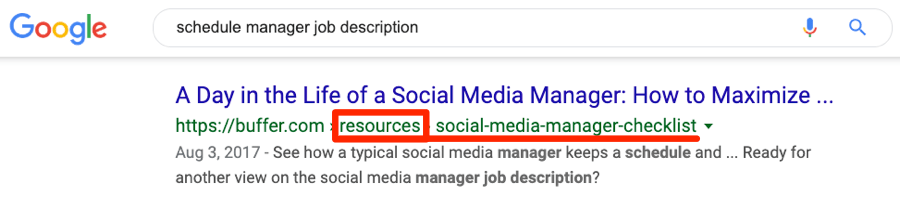
Dans ce cas précis, Google ne consolide probablement pas la popularité des liens vers une seule URL.
On ne peut pas savoir avec certitude comment Google perçoit ces deux URL, car on n’a pas accès au compte Google Search Console de Buffer. Il est possible que Google les considère comme des doublons et que l’une d’elles disparaisse prochainement des résultats organiques.
3. Une consommation inutile du budget de crawl
Google découvre les nouveaux contenus de votre site via le crawl : ses robots suivent les liens des pages existantes vers de nouvelles pages. Il recrawle aussi régulièrement les pages déjà connues pour détecter les changements.
Le contenu dupliqué ne fait qu’alourdir ce travail. Cela peut affecter la vitesse et la fréquence à laquelle Google crawle vos pages nouvelles ou mises à jour.
C’est problématique, car cela peut retarder l’indexation des nouvelles pages et la réindexation des pages modifiées.
4. Du contenu copié qui vous dépasse dans les classements
Parfois, vous pouvez autoriser un autre site à republier votre contenu. C’est ce qu’on appelle la syndication. D’autres fois, des sites copient votre contenu et le republient sans autorisation.
Ces deux scénarios créent du contenu dupliqué sur plusieurs domaines, mais ils ne posent généralement pas de problème. C’est seulement quand le contenu copié ou republié commence à vous dépasser dans les résultats de recherche que les ennuis commencent.
La bonne nouvelle : c’est rare, mais ça peut arriver.
Google a affirmé à plusieurs reprises qu’il n’applique pas de pénalité pour contenu dupliqué.
« Nous n’avons pas de pénalité pour contenu dupliqué. Ce n’est pas parce qu’un site a beaucoup de contenu dupliqué que nous allons le pénaliser. »
« Mettons les choses au clair une bonne fois pour toutes : il n’existe pas de pénalité pour contenu dupliqué. »
« Le saviez-vous ? Google n’a pas de pénalité pour contenu dupliqué. »
Mais ce n’est pas tout à fait vrai. Si votre contenu dupliqué est accidentel et ne résulte pas d’une tentative délibérée de manipuler les résultats de recherche ou de pratiques abusives, vous ne serez pas pénalisé. Si c’est le cas, c’est une autre histoire.
Google le confirme ici :
« Dans les rares cas où Google estime que du contenu dupliqué pourrait être affiché dans l’intention de manipuler nos classements et de tromper nos utilisateurs, nous apporterons également les ajustements appropriés à l’indexation et au classement des sites concernés. En conséquence, le classement du site peut en pâtir, ou le site peut être entièrement supprimé de l’index Google et n’apparaîtra donc plus dans les résultats de recherche. »
La question est : qu’est-ce qui constitue une « intention de manipuler nos classements et de tromper nos utilisateurs » ?
Google fournit de nombreuses informations à ce sujet ici. En gros, cela inclut :
- Créer intentionnellement plusieurs pages, sous-domaines ou domaines avec beaucoup de contenu dupliqué.
- Publier massivement du contenu copié.
- Publier du contenu d’affiliation copié depuis Amazon ou d’autres sites (sans apporter de valeur ajoutée).
Cela dit, comme on l’a vu plus haut, le contenu dupliqué peut nuire au SEO — même sans pénalité.
Le contenu dupliqué n’a pas une seule cause. Il en a plusieurs.
Navigation à facettes / navigation filtrée
La navigation à facettes permet aux utilisateurs de filtrer et trier les éléments d’une page. Les sites e-commerce l’utilisent beaucoup.
Ce type de navigation ajoute des paramètres à la fin de l’URL.

Comme les combinaisons de filtres sont souvent nombreuses, la navigation à facettes génère fréquemment beaucoup de contenu dupliqué ou quasi-dupliqué.
Regardez ces deux pages, par exemple :
- bbclothing.co.uk/en-gb/clothing/shirts.html?new_style=Checked
- bbclothing.co.uk/en-gb/clothing/shirts.html?Size=S&new_style=Checked
Les URL sont différentes, mais le contenu est presque identique.
De plus, l’ordre des paramètres n’a souvent pas d’importance. Par exemple, la même page est accessible via ces deux URL :
- bbclothing.co.uk/en-gb/clothing/shirts.html?new_style=Checked&Size=XL
- bbclothing.co.uk/en-gb/clothing/shirts.html?Size=XL&new_style=Checked
La navigation à facettes est une vraie complexité. Si vous pensez qu’elle est à l’origine de vos problèmes de contenu dupliqué, lisez ceci.
Paramètres de tracking
Les URL paramétrées servent aussi à des fins de suivi. Par exemple, vous pouvez utiliser des paramètres UTM pour suivre les visites depuis une campagne newsletter dans Google Analytics :
Exemple : example.com/page?utm_source=newsletter
Canonisez vos URL paramétrées vers des versions compatibles SEO sans paramètres de tracking.
Identifiants de session
Les identifiants de session stockent des informations sur vos visiteurs. Ils ajoutent généralement une longue chaîne de caractères à l’URL, comme ceci :
Exemple : example.com?sessionId=jow8082345hnfn9234
Canonisez ces URL vers des versions compatibles SEO.
HTTPS vs. HTTP, et www vs. non-www
La plupart des sites sont accessibles via l’une de ces quatre variantes :
- https://www.example.com (HTTPS, www)
- https://example.com (HTTPS, non-www)
- http://www.example.com (HTTP, www)
- http://example.com (HTTP, non-www)
Si vous utilisez HTTPS, ce sera l’une des deux premières. Le choix entre www et non-www vous appartient.
En revanche, si votre serveur n’est pas correctement configuré, votre site sera accessible via deux de ces variantes ou plus. Ce n’est pas idéal et peut entraîner des problèmes de contenu dupliqué.
Utilisez des redirections pour vous assurer que votre site n’est accessible qu’à un seul endroit.
URL sensibles aux majuscules
Google considère les URL comme sensibles à la “casse” : aux majuscules et minuscules.
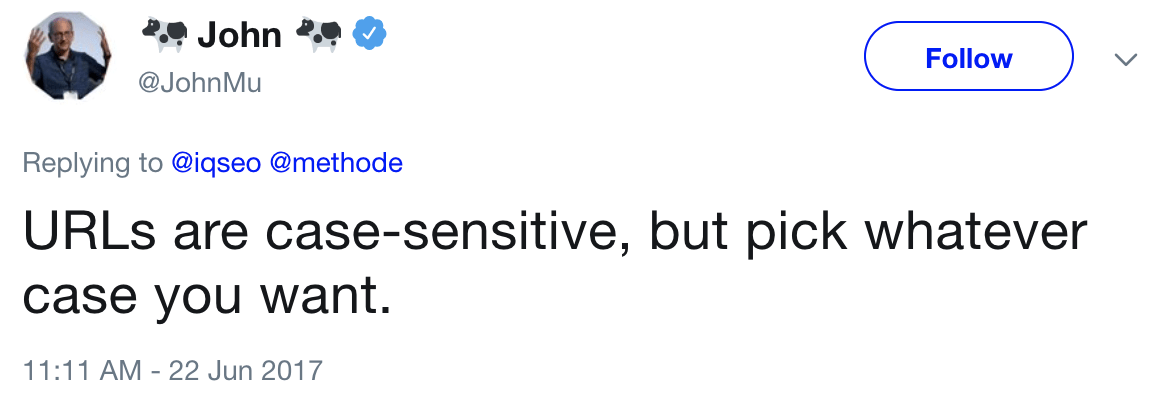
Ce qui ne semble pas être le cas pour Bing, qui traite toutes les URL en minuscules.
Cela signifie que ces trois URL sont toutes différentes :
- example.com/page
- example.com/PAGE
- example.com/pAgE
Soyez cohérent dans vos liens internes (ne créez pas de liens vers plusieurs versions d’une même URL). Si cela ne suffit pas, vous pouvez toujours canoniser ou rediriger.
URL avec ou sans barre oblique finale
Google traite les URL avec et sans barre oblique finale comme des URL distinctes. Ces deux URL sont donc différentes aux yeux de Google :
- example.com/page/
- example.com/page
Si votre contenu est accessible via les deux URL, cela peut créer des problèmes de contenu dupliqué.
Pour vérifier si c’est le cas, essayez de charger une page avec et sans la barre oblique finale. Idéalement, une seule version devrait charger. L’autre devrait rediriger.
Google indique que ce comportement est idéal.
URL pour impression
Les versions imprimables ont le même contenu que l’original. Seule l’URL diffère.
- example.com/page
- example.com/print/page
Canonisez la version imprimable vers l’originale.
URL pour mobile
Les URL mobile, tout comme les URL pour impression, sont des doublons.
- example.com/page
- m.example.com/page
Canonisez la version mobile vers l’originale. Utilisez rel=“alternate” pour indiquer à Google que l’URL mobile est une version alternative du contenu desktop.
Lecture recommandée : Annotations pour les URL desktop et mobile
URL AMP
Les pages AMP (Accelerated Mobile Pages) sont des doublons.
- example.com/page
- example.com/amp/page
Canonisez la version AMP vers la version non-AMP. Utilisez rel="amphtml" pour indiquer à Google que l’URL AMP est une version alternative du contenu non-AMP.
Si vous n’avez que du contenu AMP, utilisez une balise canonical auto-référençante.
Lecture recommandée : Rendre vos pages découvrables amp.dev
Pages de tags et de catégories
La plupart des CMS créent des pages dédiées aux tags lorsque vous les utilisez.
Par exemple, si vous avez un article sur la whey protéine bio et que vous utilisez les tags « protein powder » et « whey », vous vous retrouvez avec deux pages de tags comme celles-ci :
- https://www.caltonnutrition.com/tag/whey/
- https://www.caltonnutrition.com/tag/protein-powder/
Cela ne crée pas toujours du contenu dupliqué en soi, mais ça peut arriver.
C’est le cas ici, car il n’y a qu’une seule page sur le site avec ces deux tags. Chaque page de tag est donc identique.
Deux options pour résoudre ce problème :
- Ne pas utiliser de tags. La plupart du temps, ils ont peu ou pas de valeur de toute façon.
- Noindexer vos pages de tags. Cela ne résout pas le problème du budget de crawl, car Google continuera à crawler ces pages.
Les pages de catégories peuvent poser des problèmes similaires. Par exemple :
- https://www.xs-stock.co.uk/adidas/
- https://www.xs-stock.co.uk/brands/Chelsea-FC.html
Ces deux pages sont presque identiques parce qu’aucun produit n’est listé dans ces catégories. On se retrouve donc uniquement avec le contenu générique du modèle de page.
La solution : utiliser un nombre raisonnable de catégories sur votre site, ou même noindexer vos pages de catégories.
Pages d’attachement d’images
Beaucoup de CMS créent des pages dédiées aux pièces jointes d’images. Ces pages n’affichent généralement que l’image et du contenu générique.
Comme ce contenu est identique sur toutes les pages auto-générées, cela crée du contenu dupliqué.
Désactivez les pages dédiées aux images dans votre CMS. Sur WordPress, vous pouvez le faire via un plugin comme Yoast.
Commentaires paginés
WordPress et d’autres CMS permettent la pagination des commentaires. Cela crée du contenu dupliqué en générant plusieurs versions de la même URL.
- example.com/post/
- example.com/post/comment-page-2
- example.com/post/comment-page-3
Désactivez la pagination des commentaires ou noindexez vos pages paginées via un plugin comme Yoast.
Localisation
Si vous servez un contenu similaire à des internautes dans différentes régions qui parlent la même langue, cela peut créer du contenu dupliqué.
Par exemple, vous pourriez avoir des versions différentes de votre site pour les États-Unis, le Royaume-Uni et l’Australie. Comme les différences entre les contenus servis à chaque région sont souvent mineures (les prix en dollars plutôt qu’en livres sterling, par exemple), les versions seront quasi-dupliquées.
Notez que le contenu traduit n’est pas du contenu dupliqué.
Utilisez des balises hreflang pour indiquer aux moteurs de recherche la relation entre les différentes versions.
Pages de résultats de recherche interne
Beaucoup de sites disposent d’une barre de recherche interne. Son utilisation mène généralement à une URL paramétrée.
Exemple : example.com?q=terme-recherche
Matt Cutts, ancien responsable de la lutte contre le webspam chez Google, a déclaré :
« En général, les résultats de recherche web n’apportent pas de valeur aux utilisateurs. Notre objectif principal étant de fournir les meilleurs résultats de recherche possible, nous excluons généralement les pages de résultats de recherche de notre index. »
Matt Cutts
Utilisez une balise meta robots pour retirer les pages de résultats de recherche de l’index Google ou bloquez leur accès dans le fichier robots.txt. Évitez d’y créer des liens internes.
Environnement de staging
Un environnement de staging est une version dupliquée ou quasi-dupliquée de votre site, utilisée à des fins de test.
Par exemple, imaginons que vous souhaitiez installer un nouveau plugin ou modifier du code sur votre site. Vous ne voulez probablement pas déployer ça directement sur un site en production avec des centaines de milliers de visiteurs quotidiens. Le risque est trop élevé. La solution : tester les modifications dans un environnement de staging.
Les environnements de staging deviennent un problème SEO quand Google les indexe, car cela génère du contenu dupliqué.
Protégez votre environnement de staging via une authentification HTTP, un filtrage par IP ou un accès VPN. S’il est déjà indexé, utilisez une directive robots noindex pour le faire retirer.
Rendez-vous dans Site Audit d’Ahrefs et lancez un crawl.
Une fois terminé, accédez au rapport Qualité du contenu.
Recherchez les clusters de pages dupliquées et quasi-dupliquées sans canonical. Ils sont mis en évidence en orange.
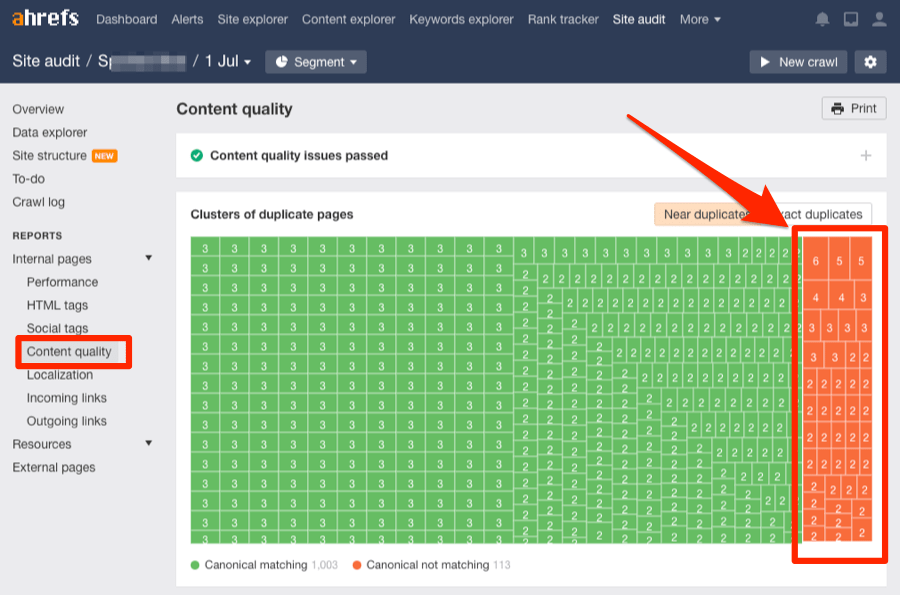
Cliquez sur l’un de ces clusters pour voir les pages concernées.
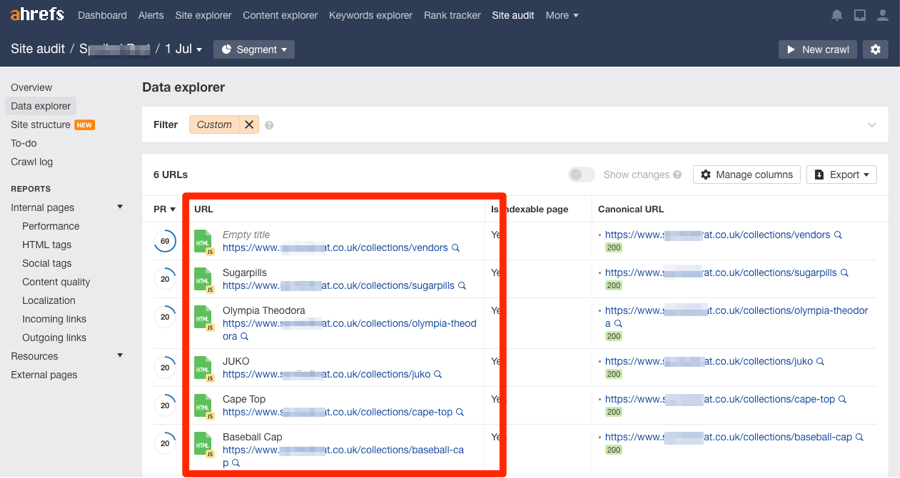
Analysez la cause du contenu dupliqué, puis prenez les mesures appropriées.
Notez que ces situations ne nécessitent pas toujours une correction, notamment dans le cas de quasi-doublons.
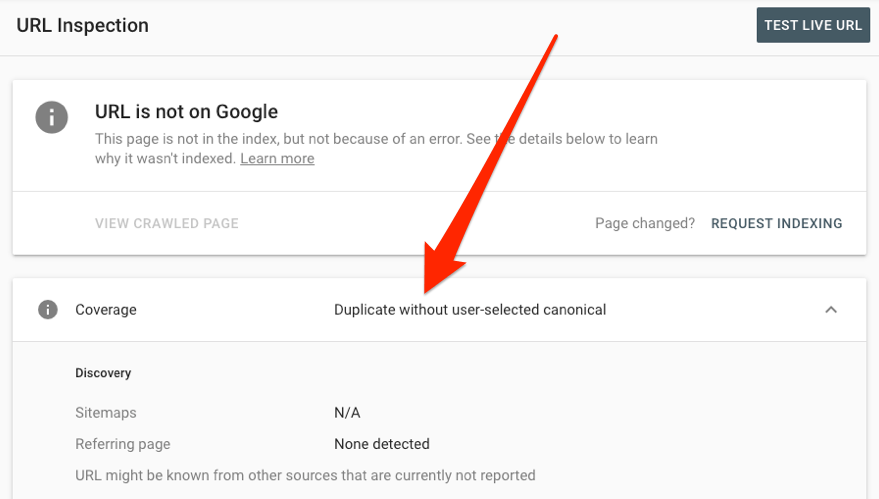
Recherchez également ces avertissements liés au contenu dupliqué dans Google Search Console :
- Doublon, sans canonical sélectionné par l’utilisateur
- Doublon, Google a choisi un canonical différent de l’utilisateur
- Doublon, l’URL soumise n’a pas été sélectionnée comme canonical
Pour en savoir plus sur la gestion de ces avertissements, consultez cette page.
Pour voir comment Google traite une URL spécifique, utilisez l’outil d’inspection d’URL.
Vous pouvez aussi vérifier les balises de titre dupliquées, les meta descriptions et les H1 dans le rapport Balises HTML.
Cherchez les mauvais doublons : des pages avec des balises meta dupliquées mais des canonicals différents.
Sélectionnez-les en cliquant sur le filtre « Mauvais doublons » dans le rapport Balises HTML et contenu.
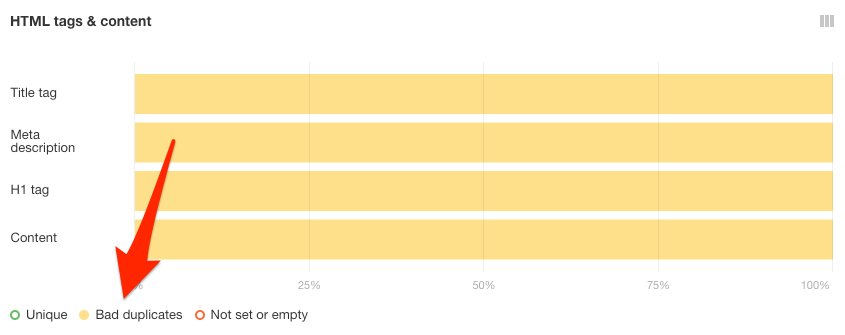
Cliquez sur l’une des barres jaunes pour voir les pages concernées.
Les pages avec des titres, meta descriptions ou H1 dupliqués sont souvent très similaires.
Par exemple, ces deux pages ont la même balise de titre et un contenu presque identique car le produit est le même. La seule différence est que l’une correspond à un pack de 3 bûches allume-feu, l’autre à une seule log.
- https://www.xs-stock.co.uk/big-k-instant-light-the-wrapper-firelog-3-pack-camp-fire-fuel/
- https://www.xs-stock.co.uk/big-k-instant-light-the-wrapper-firelog-camp-fire-chiminea/
Google recommande de réduire ce type de contenu similaire :
« Si vous avez de nombreuses pages similaires, envisagez d’étoffer chaque page ou de les regrouper en une seule. »
Cela dit, un petit nombre de pages similaires ne devrait pas poser de problème majeur.
Le scraping et la syndication de contenu peuvent aussi créer des problèmes de contenu dupliqué. Mais c’est généralement un problème uniquement si vous constatez que des versions copiées de votre contenu vous dépassent dans les classements.
Est-ce que ça arrive ? Oui, mais c’est souvent davantage un problème pour les sites jeunes ou peu autoritaires. Pourquoi ? Parce que les sites qui copient votre contenu sont souvent plus autoritaires. Cela « trompe » parfois Google, qui pense que leur version est l’originale.
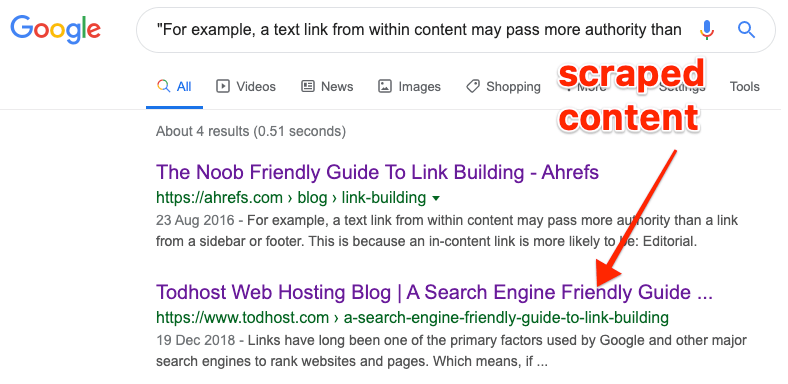
Pour un petit site, vous pouvez souvent retrouver du contenu copié en recherchant dans Google un extrait de texte de votre page entre guillemets.
Pour les sites plus importants, vous aurez besoin d’un outil automatisé comme Copyscape, qui recherche sur le web d’autres occurrences du contenu de vos pages.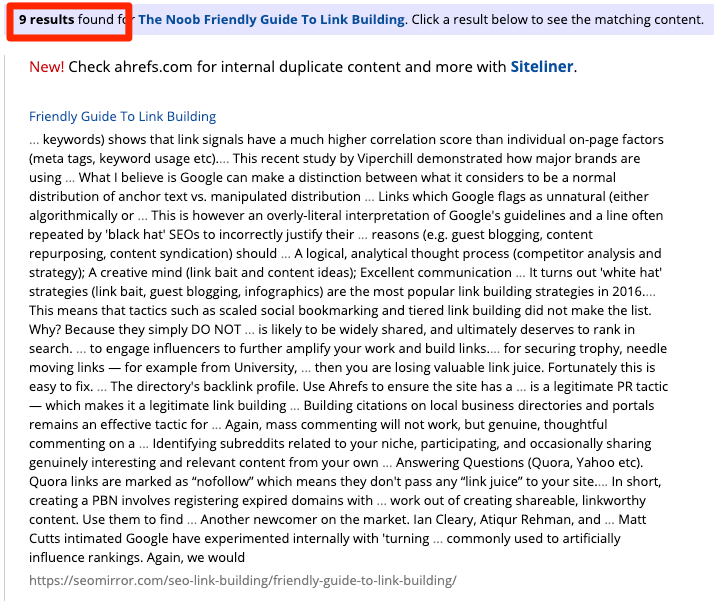
Quelle que soit la méthode utilisée, la plupart des résultats proviendront de sites de faible qualité ou spam.
En règle générale, rien à craindre. En revanche, si vous constatez qu’un site légitime a copié votre contenu et vous préoccupe de perdre du trafic, entrez son URL dans Site Explorer d’Ahrefs pour obtenir une estimation de son trafic organique.
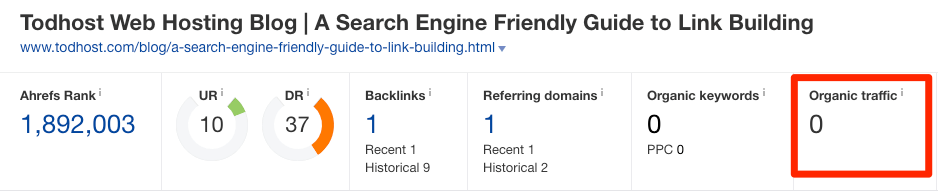
S’il reçoit plus de trafic que votre page, il y a peut-être un problème.
Dans ce cas, vous avez trois options :
- Les contacter pour demander le retrait du contenu.
- Les contacter pour demander l’ajout d’un lien canonical vers l’original sur votre site.
- Soumettre une demande de retrait DMCA via Google.
Si vous syndiquez intentionnellement du contenu vers d’autres sites, il vaut la peine de leur demander d’ajouter un lien canonical vers l’original. Cela élimine tout risque de problème de contenu dupliqué.
Si vous republiez du contenu d’autres sources sur votre site, deux approches permettent d’éviter les problèmes :
- Canoniser vers l’original.
- Noindexer la page.
Ne vous stressez pas trop à propos du contenu dupliqué. C’est généralement bien moins problématique qu’on ne le pense.
Si vous avez quelques pages dupliquées ou quasi-dupliquées, il est peu probable que cela pose un problème majeur. Il en va de même pour les citations de contenu provenant d’autres sites ou d’autres pages du vôtre. Une petite quantité de contenu dupliqué ou générique devrait passer sans encombre : Google dispose de systèmes pour gérer ce type de situation.
Ce à quoi vous devez vraiment faire attention, ce sont les erreurs de SEO technique qui génèrent des centaines ou des milliers de pages de contenu dupliqué, comme une mauvaise implémentation de la navigation à facettes sur les sites e-commerce.
Cela peut sérieusement impacter votre budget de crawl, entre autres choses.
Partagez vos questions sur le contenu dupliqué en commentaire ou sur X.


