Según el analista de tendencias para webmasters de Google Gary Illyes, el ~ 60 % de internet es contenido duplicado:
Google’s crawling process is highly focused on removing duplication because 60% of the internet is duplicate 🤯 @methode #seodaydk pic.twitter.com/OJ9OkP74DU
— Lily Ray 😏 (@lilyraynyc) March 30, 2022
La canonicalización es un tema complejo y, a menudo, malinterpretado. No creo que la mayoría de los duplicados sean malos. En la mayoría de los casos, son problemas técnicos los que los causan. Veremos esto más adelante. Voy a hablar de cómo funciona el proceso de canonicalización, además de tratar también los temas siguientes:
En el proceso de canonicalización intervienen muchas señales distintas. Según Gary Illyes de Google, hay 20 señales diferentes. Entre ellas se incluyen:
- Duplicados
- Enlaces canónicos
- URL del sitemap
- Enlaces internos
- Enlaces externos
- Redirecciones
- Hreflang
- PageRank
- Páginas HTTPS sobre HTTP
- URL más cortas frente a URL más largas
- Dónde se publicó/visualizó el contenido por primera vez
- Señales a nivel de sitio, como tener un historial con contenido pirateado
- Páginas sobre PDF
Google examina todas las señales y las compara para determinar cuál debería ser la versión canónica. Esta es la versión de la página que indexará y la que se suele mostrar a los usuarios. De este proceso se encarga un sistema de machine learning.
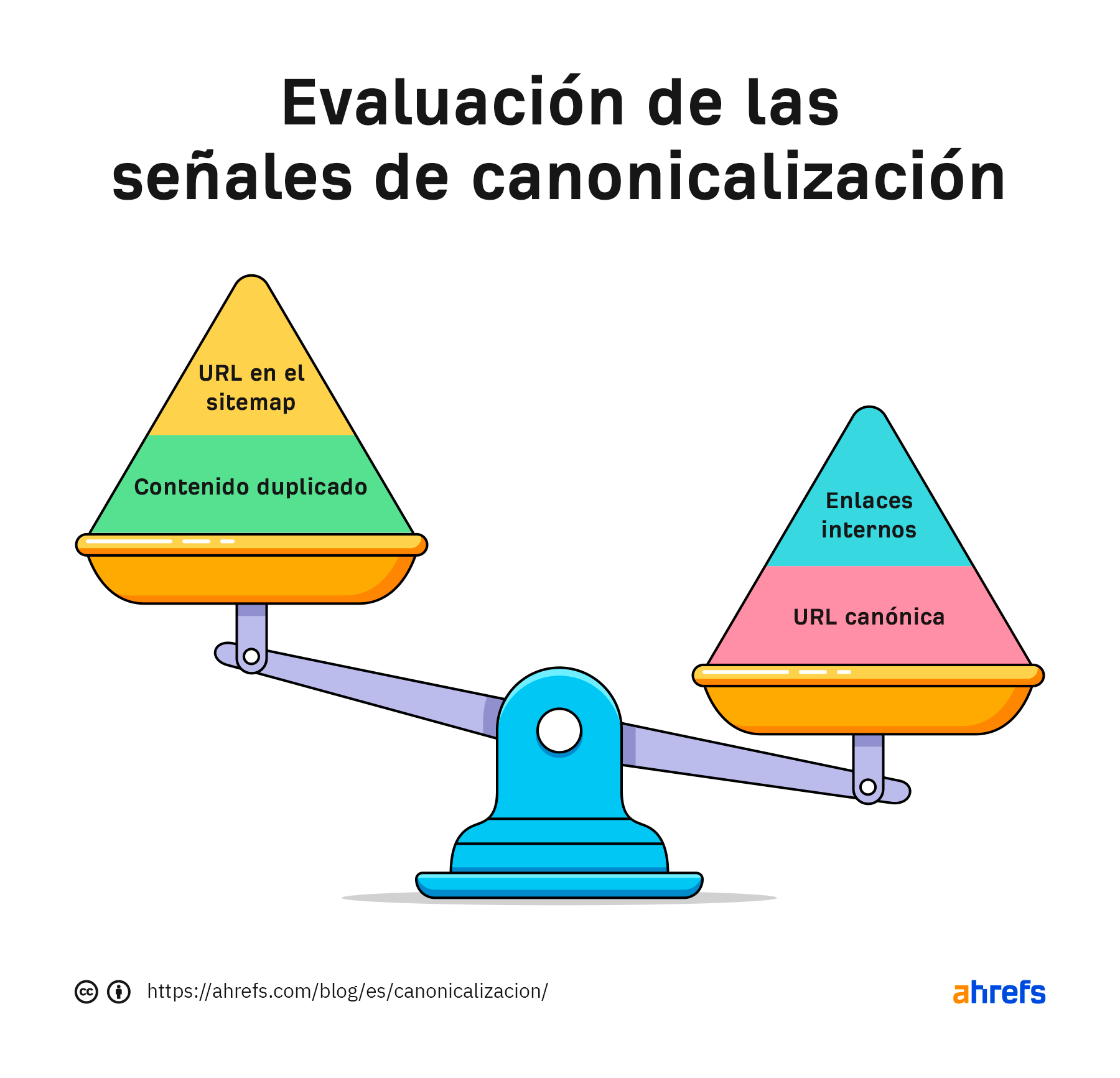
Un escenario potencial cuando Google decide la canonicalización basada en enlaces internos y la URL canónica.
Duplicados
Con el contenido duplicado, Google elegirá una versión canónica que quiera indexar. Todas las páginas elegibles forman un grupo de páginas y las señales que van a las páginas de ese grupo se consolidarán en la canónica elegida. Incluso, esta versión canónica puede cambiar con el tiempo.
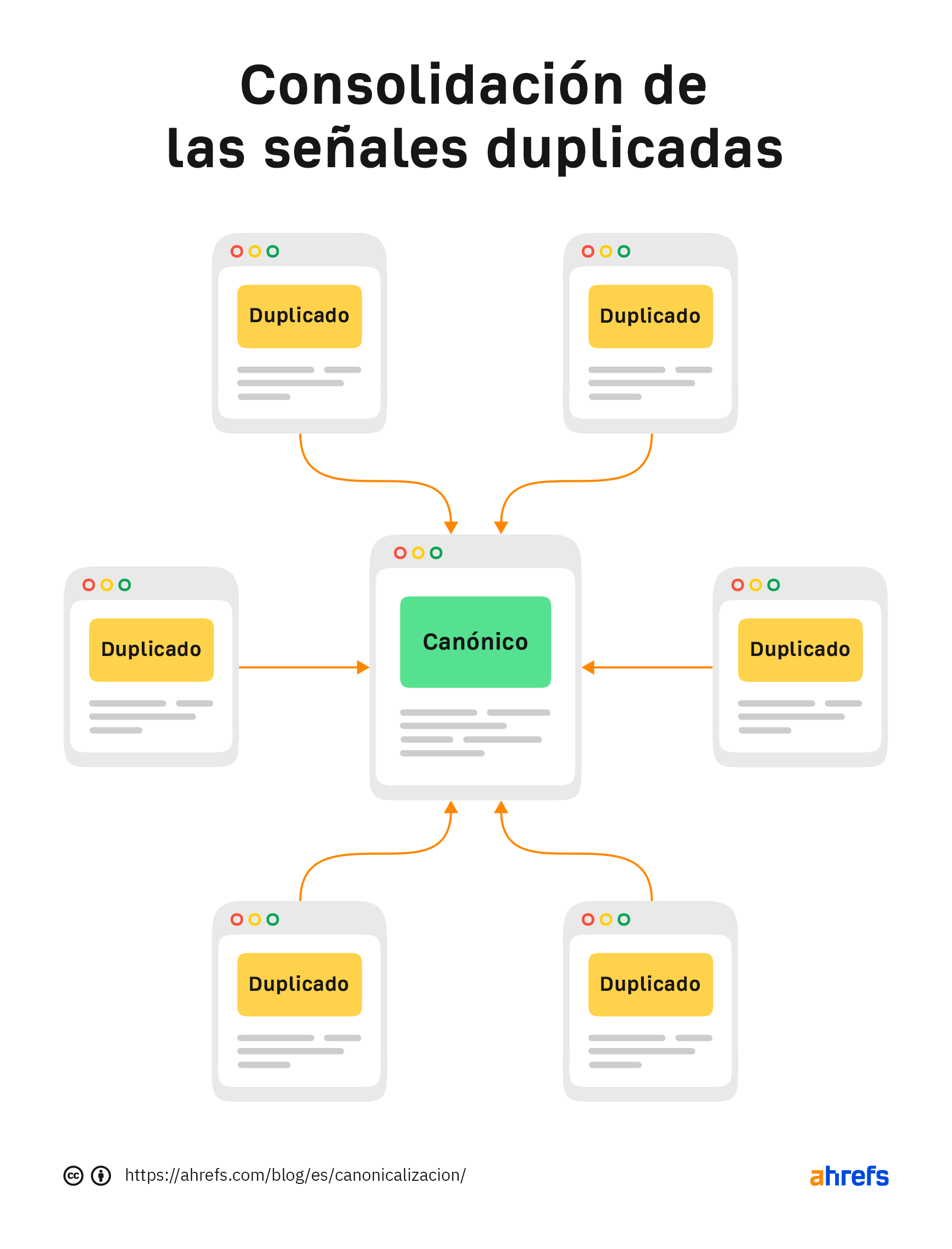
Algunos SEO creen que existe una penalización por el contenido duplicado, algo que no es cierto. Por lo general, se indexará una versión u otra. Puede que no sea la versión que quieras la que se termine indexando, pero se indexará y se posicionará igual de bien que cualquier otra versión de la misma página.
Estos son algunos ejemplos de lo que puede causar páginas duplicadas y, a veces, problemas de canonicalización:
- HTTP y variantes HTTPS. Ejemplos: http://www.ejemplo.com y https://www.ejemplo.com.
- Variantes sin www y con www. Ejemplos: http://ejemplo.com y http://www.ejemplo.com.
- URL con y sin barras al final. Ejemplos: https://ejemplo.com/pagina/ y https://ejemplo.com/pagina.
- URL con y sin mayúsculas. Ejemplos: https://ejemplo.com/pagina/ y https://ejemplo.com/Pagina/.
- Versiones predeterminadas de la página, como las páginas de índice. Ejemplos: https://www.ejemplo.com/, https://www.ejemplo.com/index.htm, https://www.ejemplo.com/index.html, https://www.ejemplo.com/index.php, https://www.ejemplo.com/default.htm, etc.
- Versiones alternativas de las páginas. Puede incluir versiones mobile (ejemplo.com y m.ejemplo.com), versiones AMP (ejemplo.com/pagina y amp.ejemplo.com/pagina), versiones para imprimir (ejemplo.com/pagina y ejemplo.com/pagina/print), versiones alternativas destinadas a otros países pero con el mismo contenido (ejemplo.com/es-es/, ejemplo.com/es-mx/, ejemplo.com/es-ar/) o versiones en un sitio de desarrollo (dev.ejemplo.com).
- Parámetros URL. Ejemplos: ejemplo.com?parametro=lo-que-sea. Pueden existir mediante códigos de seguimiento, navegación facetada, clasificación de contenidos, identificadores de sesión, etc. Hay algunos casos en los que los parámetros pueden cambiar el contenido de la página para que no sea un duplicado.
- Otras páginas que muestran el contenido completo. Google puede elegir la canónica incorrecta cuando otra página muestra el contenido completo. Esto puede incluir la página principal del blog, páginas paginadas, páginas de etiquetas, páginas de categorías o páginas de feeds.
- Contenido sindicado. Las prácticas recomendadas de sindicación de contenido generalmente recomiendan tener una etiqueta canónica de vuelta al contenido original o, al menos, un enlace al contenido original. Esto se debe a que el canónico elegido puede ser un dominio completamente distinto. Intentan seleccionar la fuente original como canónica, pero, en algunos casos, eligen la página equivocada.
La mayoría de estos puntos no suelen ser problemas. Como ya hemos mencionado, Google suele elegir una versión u otra como canónica. Pero hay algunas excepciones.
- A veces, con la sindicación de contenidos, la fuente original no se elige como canónica. Esto es un problema grave. ¿Cómo te sentirías si otra persona empezara a posicionarse con un artículo que has escrito tú?
- Hreflang no resuelve la duplicación en webs internacionales. Por lo general, Google intentará intercambiarlo para mostrar la versión correcta, pero no está garantizado y esta configuración suele romperse. Cuando esto ocurre, los usuarios ven páginas del país equivocado. Lo mejor es no tener el mismo contenido en varias páginas de sitios web internacionales.
- Con algunos sitios JavaScript (normalmente modelos de aplicaciones), el código inicial de las páginas puede parecerse a otras páginas o incluso al código de otros sitios web. A veces, estas páginas se canonicalizan a otras páginas del mismo sitio web o, incluso, de sitios distintos.
Creo que parte del problema, tanto con hreflang como con el contenido JavaScript, es que Google puede estar ejecutando la detección de duplicados a través de algoritmos de rastreo que detectan patrones de duplicación, una vez más después de ver el código, y otra vez después de renderizar las páginas.
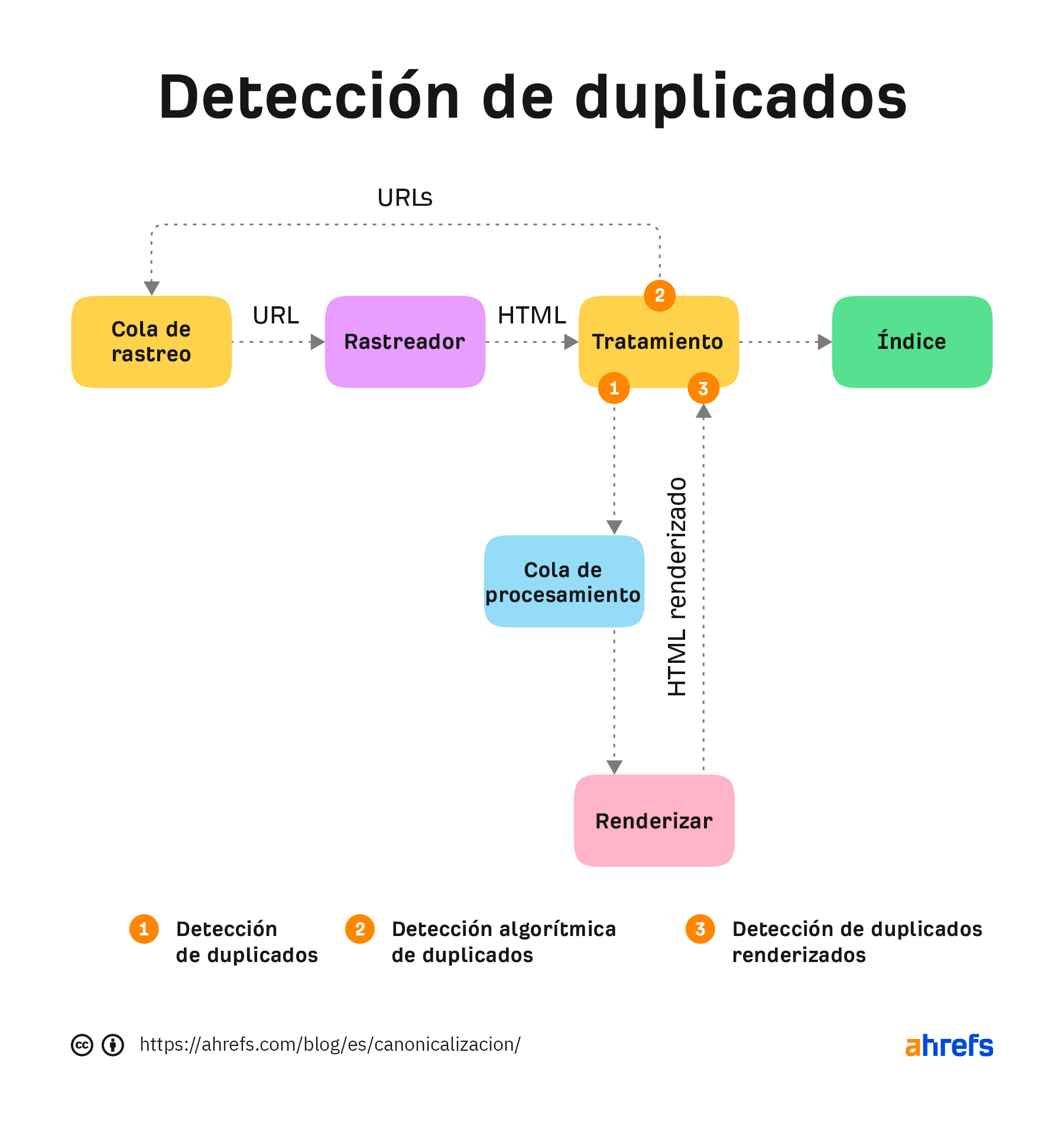
Con las páginas que utilizan hreflang, si se decide que las páginas son duplicadas sin rastrearlas, es posible que no puedan intercambiarse correctamente.
Antes de que una página se procese, puede “parecerse” a otra página basándose en el contenido HTML. Es posible que Google elija la página canónica basándose en esta versión inicial y que no le dé prioridad a la hora de procesarla porque ya se considera una página duplicada. Por lo general, esto se resuelve tras la renderización, pero puede tardar algún tiempo en resolverse.
Google tiene un par de reglas que suele seguir en lo que respecta a la canonicalización de duplicados.
1. Prefiere las páginas HTTPS a las HTTP.
Por lo general, Google indexará la versión HTTPS, pero hay algunos problemas o señales contradictorias que pueden hacer que elija la versión HTTP en su lugar como, por ejemplo:
- Tener un certificado de seguridad no válido.
- Enlaces de páginas HTTPS a recursos HTTP en la página (excluye imágenes).
- Redireccionamiento HTTPS a HTTP.
- La página HTTPS tiene un elemento de enlace rel=“canonical” que apunta a la página HTTP.
2. Prefiere URL más cortas que más largas.
Esto ha sido malinterpretado a lo largo de los años por los SEO para decir que todas sus URL deben ser más cortas. Sin embargo, lo que Google realmente dijo fue que, si tienes, por ejemplo, una versión “limpia” y corta de una URL y una versión más larga con parámetros adjuntos, generalmente elegiría la versión más corta de la URL sin el parámetro como la versión canónica.
Elemento de enlace canónico
También se conoce como etiqueta canónica. Se parece a algo así:
<link rel="canonical" href="https://www.ejemplo.com"/>
La etiqueta canónica a veces se denomina como una pista o sugerencia porque es solo una señal de canonicalización. Google la ignora si hay otras señales que sean más fuertes.
Si se respeta la etiqueta canonical, todas las señales como los enlaces transmitirán valor. Sin embargo, si se ignora, no se transmite ningún valor. El valor no se pierde, permanece en la página original o va a la página que Google elija como canónica.
Un elemento de enlace canónico puede implementarse de dos formas: (1) puede estar en la sección <head> o (2) en la cabecera HTTP.
Una anécdota interesante: la guía SEO Starter Guide de Google solía ser un PDF. No tenía una etiqueta canónica establecida en el encabezado HTTP y la gente solía “robar” el listado con su propia versión duplicada.
A veces, la sección <head> de una página termina antes de lo debido. Esto suele deberse a que una etiqueta del <head> no se cierra correctamente. Cuando esto ocurre, es posible que se coloque una etiqueta canónica en la sección <body> en su lugar. Si esto ocurre, la etiqueta canónica no se respetará.

Etiqueta canónica no válida situada en la sección <body>.
URL del sitemap
Las URL que incluyas en tu sitemap también son una señal de canonicalización. En la mayoría de los casos, solo es recomendable incluir las URL de las páginas que se quieran indexar.
Hay algunas excepciones, ya que las URL de los sitemaps también ayudan al rastreo. Tras la migración de una web, se debe crear un sitemap que incluya las páginas antiguas, aunque no sean canónicas. Esto ayudará a que las redirecciones se procesen con mayor rapidez. Una vez que la mayoría de los redireccionamientos hayan sido recogidos y procesados, tienes que eliminar este mapa del sitio.
Enlaces internos
Lo importante es cómo enlazas a las páginas. Los enlaces internos son otra señal de canonicalización.
Por lo general, deberías enlazar a la versión de una página que quieras que sea canónica y actualizar los enlaces a cualquier URL que pueda haber cambiado. No obstante, hay excepciones, como en el caso de la navegación por facetas. En algunos casos como este, lo que es mejor para los usuarios puede prevalecer sobre lo que es mejor para el SEO.
Enlaces externos
Es importante cómo otros enlazan a tus páginas. Si puedes actualizar los enlaces externos para que apunten a la última versión de tu página, te ayudará a demostrar que quieres que se indexe la última versión de la página.
Redireccionamientos
Existen varios tipos de redireccionamientos y todos son señales de canonicalización. Transmiten PageRank y ayudan a determinar qué URL se mostrará en el índice de Google.
Los redireccionamientos 301 y 308 envían señales hacia la nueva URL. Los 302 y algunos 307 envían señales hacia atrás, hacia la URL redirigida. Si un 302 permanece el tiempo suficiente o si la URL a la que se redirige ya existe, puede tratarse como un 301 y enviar señales hacia delante en su lugar. Se requieren un número suficiente de señales para invertir la escala que vimos anteriormente para las señales de canonicalización. Según se van acumulando los enlaces, se modifican los enlaces internos, se actualizan las URL de los sitemaps, etc., más señales apuntan a la nueva URL que a la antigua y se produce la inversión.
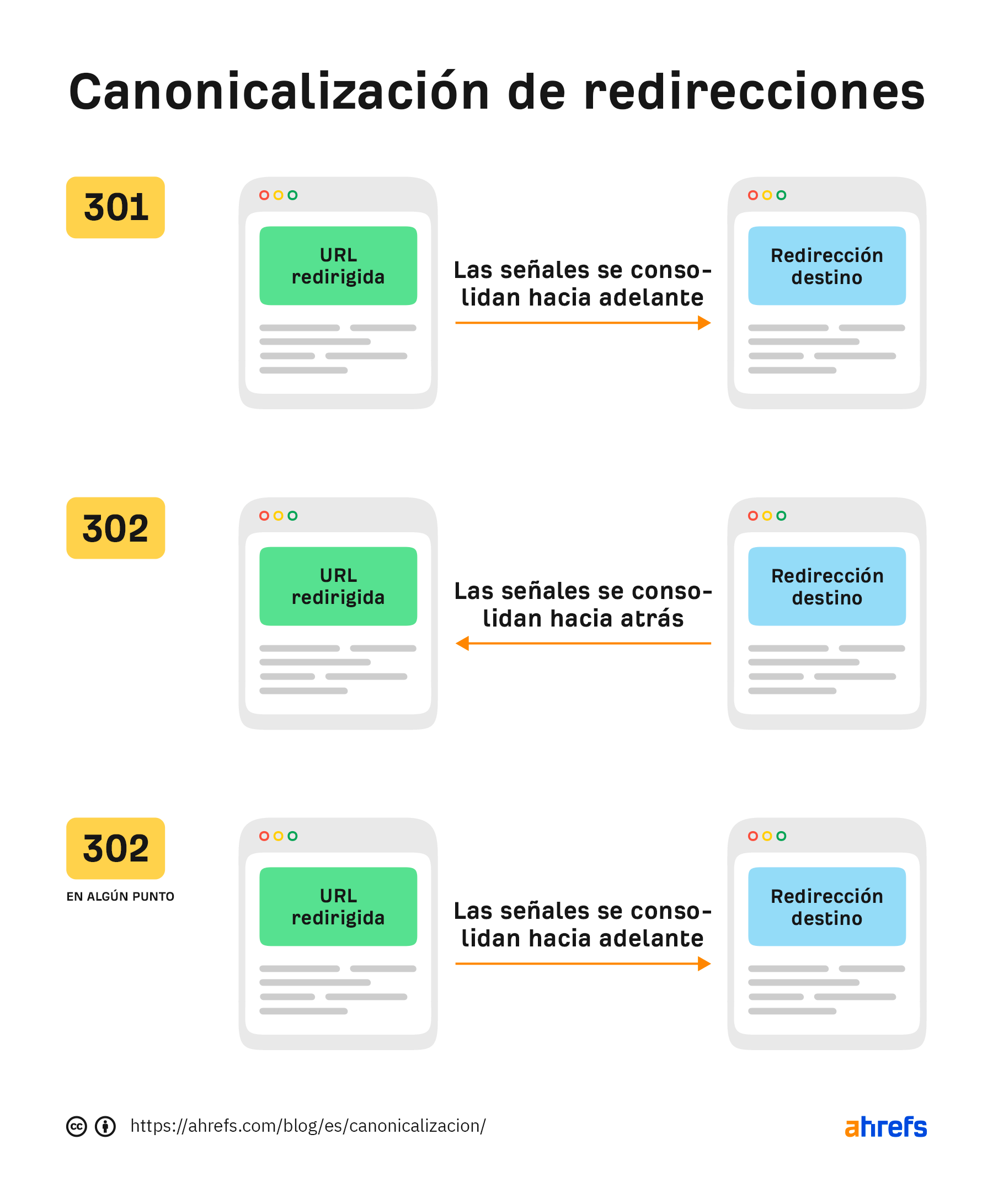
En algún momento, la balanza se inclina para los 302.
Un 307 tiene dos casos distintos. En los casos en los que sea una redirección temporal, se tratará igual que un 302 y se intentará consolidar hacia atrás. Cuando los servidores web exigen a los clientes que solo utilicen conexiones HTTPS (política HSTS), Google no verá el 307 porque se almacena en caché en el navegador. El hit inicial (sin caché) tendrá un código de respuesta del servidor que posiblemente sea un 301 o un 302, pero el navegador mostrará un 307 para las peticiones posteriores.
Tipos de redireccionamientos permanentes
- HTTP 301
- HTTP 308
- Meta refresh 0
- HTTP refresh 0
- JavaScript location
- Crypto redirect
Tipos de redireccionamientos temporales
- HTTP 302
- HTTP 303
- HTTP 307 (en el servidor, no en la caché del navegador)
- Meta refresh >0
- HTTP refresh >0
Consolidación de señales
Las señales suelen consolidarse permanentemente al cabo de 1 año. Si se elimina un redireccionamiento después de ese periodo, las señales permanecerán en la página a la que se redirigió. Si se restaura la página original, cualquier señal nueva irá a la página restaurada, pero las señales antiguas seguirán consolidándose en la página a la que se redirigió.
Hreflang
Hreflang es otra señal para la canonicalización. Las páginas incluidas en las etiquetas hreflang tienen más posibilidades de ser seleccionadas como canónicas.
Esto se complica cuando se trata de páginas duplicadas, ya que, generalmente, una página puede ser indexada y las señales se consolidan allí. Pero aún así, pueden cambiar la página mostrada por una más apropiada para los usuarios en los resultados de búsqueda.
Esta parte es complicada. Te recomendaría que leyeras Hreflang: una guía para principiantes para más información.
PageRank
El PageRank también se confirma como una señal de canonicalización. Una página con un PageRank más alto tendrá un peso mayor y es más posible que sea la canónica.
La fuente principal para saber qué es lo que ha elegido Google como canónico es la herramienta de inspección de URL del Google Search Console. Introduce la URL y te mostrará cuál es la canónica declarada y cuál ha elegido Google como canónica.
Si no tienes acceso a Google Search Console, lo que se recomienda para comprobar la versión de una página que Google ha indexado es pegar la URL en Google. El primer resultado suele ser el canónico.
Del mismo modo, si compruebas la versión almacenada en caché de una página en Google y aparece una página distinta, significa que Google ha seleccionado una versión diferente de la página.
Advertencia: No utilices las búsquedas de site: para comprobar los resultados canónicos. Muestra lo que Google conoce, no necesariamente lo que está indexado o la canónica seleccionada.
Dentro del Site Audit de Ahrefs, mostramos muchos problemas relacionados con la canonicalización. Ten en cuenta que estamos marcando las prácticas recomendadas en la mayoría de los casos. Puesto que el canonical es una indicación, Google y otros motores de búsqueda tendrán que elegir qué versión de una página indexar.
Aunque tu web tenga muchos problemas relacionados con la canonicalización, los motores de búsqueda pueden ser capaces de averiguar qué versión se debe indexar y dónde se tienen que consolidar las señales. Puede que no les suponga ningún problema en absoluto.
Dato curioso: cuando realizamos una auditoría del sitio, solo contamos la versión canónica de las páginas como créditos de rastreo. Otras herramientas cuentan todas las versiones de una página para los créditos. En muchos sitios, esto puede consumir varios créditos por página.
Hay muchas cosas que pueden salir mal con la canonicalización. Veamos algunos errores comunes.
Error #1: Bloquear la URL canonicalizada mediante robots.txt
El bloqueo de una URL en robots.txt impide que Google la rastree, lo que significa que no puede ver ninguna etiqueta canónica en esa página. Esto impide, a su vez, que Google transfiera “link equity” de la página no canónica a la canónica.
A no ser que tengas un problema de crawl budget, probablemente sea mejor dejar que todas las señales se consoliden. Incluso si vas a bloquear o no indexar algunas versiones, es posible que quieras comprobar si hay versiones con enlaces que deberías canonicalizar de forma alternativa. Sin embargo, dado que Google tiende a rastrear menos las páginas no canónicas con el tiempo, es posible que te convenga esperar.
Error #2: Establecer la URL canonicalizada como “noindex”
Nunca mezcles noindex y rel=canonical. Son instrucciones contradictorias.
Como afirma John Mueller, Google suele dar prioridad a la etiqueta canonical sobre la etiqueta “noindex”.
Error #3: Establecer un código de estado HTTP 4XX para la URL canonicalizada
Establecer un código de estado HTTP 4XX para una URL canonicalizada tiene el mismo efecto que utilizar la etiqueta “noindex”: Google será incapaz de ver la etiqueta canonical y transferir “link equity” a la versión canonical.
Error #4: Canonicalización de todas las páginas paginadas a la página de inicio
Las páginas paginadas no deben canonicalizarse a la primera página paginada de la serie. En su lugar, se deben utilizar canónicas de autorreferencia en todas las páginas paginadas.
¿Por qué? Como John dijo en Reddit, es un uso incorrecto de rel=canonical.
Lo que principalmente hay que evitar, ya que este post trata sobre la canonicalización, es utilizar el rel=canonical en la página 2 apuntando a la página 1. La página 2 no es equivalente a la página 1, por lo que el rel=canonical sería incorrecto.

Contamos con una guía sobre la paginación para SEO y las prácticas recomendadas si te interesa.
Error #5: Utilizar la herramienta de eliminación de URL en Google Search Console para la canonicalización
Puedes eliminar todas las versiones de una URL, desindexando efectivamente tu página de la búsqueda.
Error #6: No mantener la coherencia de las señales de canonicalización
Como hemos dicho antes, hay muchas señales de canonicalización distintas.
Tener varias señales que sugieran distintas versiones canónicas significa que dependerás de Google para que seleccione una versión canónica. Cuantas más señales coherentes le muestres a Google con la versión que te interese, más posibilidades tendrás de que esa versión sea la canónica elegida.
Error #7: No utilizar etiquetas canónicas con hreflang
Las etiquetas hreflang especifican el idioma y la localización geográfica de una página web.
Google indica que, al utilizar hreflang, “la página canónica debería estar en el mismo idioma; si no está disponible en ese idioma, selecciona la página del idioma que consideres más adecuado”.
Error #8: Tener varias etiquetas rel=canonical
Tener varias etiquetas rel=canonical hará que Google las ignore. En muchos casos, sucede porque las etiquetas se insertan en un sistema en puntos diversos, como el CMS, el tema y los plugins. Esta es la razón por la que muchos plugins tienen una opción de sobrescritura destinada a garantizar que son la única fuente de etiquetas canónicas.
Otra área donde puede ser un problema es con las etiquetas canónicas añadidas con JavaScript. Si no se especifica ninguna URL canónica en la respuesta HTML y, a continuación, se añade una etiqueta rel=canonical con JavaScript, esta se respetará cuando Google muestre la página. Sin embargo, si se especifica una URL canónica en HTML y se cambia la versión preferida con JavaScript, se envían señales contradictorias a Google.
Error #9: Rel=canonical en el <body>
La etiqueta rel=canonical solo debería aparecer en el <head> de un documento. Una etiqueta canónica en la sección <body> de una página se ignorará.
Esto puede plantear problemas a la hora de analizar un documento. Aunque el código fuente de la página tenga la etiqueta rel=canonical en el lugar correcto, hay muchas cosas, como etiquetas no cerradas, JavaScript inyectado o <iframes> en la sección <head>, que pueden hacer que el <head> termine antes de tiempo durante el procesamiento. En estos casos, una etiqueta canónica se puede introducir accidentalmente en el <body> de una página renderizada, donde no se respetará.
Reflexiones finales
Se han eliminado muchas de las herramientas que tenían los SEO para gestionar la canonicalización, como la herramienta de parámetros de URL y la configuración de dominio preferido en Google Search Console. Sin embargo, sigue habiendo muchas otras señales que ayudan a Google a elegir una canónica.
¿Tienes alguna duda o pregunta? Escríbenos en Twitter.


