


AI 検索エンジンの仕組み

Ryan Law 作成
Ahrefs コンテンツマーケティングディレクター
ChatGPT に「運動に最適なオーバーイヤーヘッドフォンをおすすめして」と頼んだ時、実際には何が起こるのでしょうか?
AI 検索エンジンはどのように回答を生成し、おすすめ商品を選ぶのでしょうか?Google のような従来の検索エンジンとはどう異なり、また、どこが同じなのでしょうか?
そして肝心なのは、あなたのウェブサイト、ブランド、商品をどうやって表示させるかです。
この章のレビューと執筆を引き受けてくれた Gianluca Fiorelli と Mark Williams-Cook に感謝します。
AI 検索エンジンとは何ですか?
AI 検索エンジンとは、大規模言語モデル(LLM)を使って情報を見つけ、回答を生成する質問応答システムです。
従来の検索エンジンと AI 検索エンジンには、いくつかの大きな違いがあります(ただし、従来の検索エンジンにより多くの AI 機能が追加されるにつれて、二者の間の違いは小さくなりつつあります)。
- 単発の検索クエリを入力するのではなく、ユーザーは追加の質問をして会話を続けることができます。
- リンクを順位付けしたリストを表示するのではなく、AI 検索エンジンは直接的な回答やおすすめを表示します(そして、回答の内容は頻繁に変わることがあります)。
- 検索ユーザーはあなたのウェブサイトへと誘導されるのではなく、チャットインターフェース上で直接クエリに対する回答を得られます(結果としてウェブサイトへのクリック数が減少します)。
こちらは、ChatGPT、Claude、または AI モードなどが採用している、典型的な AI 検索インターフェースの例です。

- 会話形式のプロンプト:ユーザーの質問。
- グラウンディングメッセージ: LLM が、回答に追加情報を加えるために検索を行う判断をしたことを示すメッセージ。
- 回答: ユーザーのプロンプトに対して AI が生成した回答。
- 言及: 回答文章内で、(あなたのブランドや商品などの)エンティティ(存在)が言及されること。
- 引用:回答生成に使用したソース URL。通常は末尾に記載されます。
このような回答に表示されるためには、まず AI 検索エンジンの中核をなす動作プロセスを理解する必要があります。
トレーニングの仕組み
LLM は膨大な量のコンテンツを基にトレーニングされています。Wikipedia、Common Crawl の収集データ、Google ブックスの全情報に目を通し、何百万ページにも及ぶウェブコンテンツを「読み込んでいる」のです。
このトレーニングデータによって、LLM は世界を「理解」します。もしあなたのヘッドホン会社が、データ内の関連する文脈で何度も登場し、かつポジティブな表現(「コスパ最高」「ジムに最適」など)で説明されていれば、ヘッドホン関連のプロンプトに対する LLM の回答であなたの会社が言及される可能性は高くなります。
ご存じですか?
この学習プロセスは、ここで説明したものよりも複雑です。HTML を取り除き、個人を特定できる情報を削除し、ブロックリストの単語を除外し、特定の言語のデータに絞り込む、トレーニング前の段階があります。また、言語モデルを(単なる入力予測器ではなく)便利なチャットアシスタントとして動作させるためのトレーニング後の段階もあります。詳しくは、Andrej Karpathy の動画 Deep Dive into LLMs like ChatGPT(ChatGPT などの LLM 完全解説) をご覧ください。


ここで、エンティティベースの SEO が非常に重要になります。ブランドがナレッジグラフに一貫して表示され、スキーママークアップで適切に構造化され、ウェブ上に存在する質の高いコンテンツ内で関連するエンティティと一緒に出現している場合、トレーニングデータ内でより強い「エンティティシグナル」を発することができます。

Gianluca Fiorelli, 戦略的・海外 SEO/AI 検索コンサルタント
重要なのは、LLM にはいくつもの「癖」があるということです。
- 表示される確率に着目:同じプロンプトを与えても、そのたびに違う回答が返ってくることがあります。この確率的な性質のため、キーワードを狙った対策のように「プロンプトに合わせて最適化する」ことができません。このため、ブランドの出現を分布として捉えましょう。似たような 100 個のプロンプトに対する回答内で、あなたのブランドが登場する確率に注目すべきなのです。このため、少数の特定のプロンプトにこだわるより、多数のプロンプトに対する回答での出現頻度の平均を調べ、改善する方が効果的です。
- 知識に限界がある。 デフォルト設定では、LLM の持つ知識は、その特定のモデルが学習したデータセットに含まれていた情報に限定されます。各モデルは、特定の時点までのデータを基に一度だけトレーニングされます。その後、より最新の知識を備えた新モデルが定期的に(これまでの傾向ではおよそ半年ごとに)リリースされます。
- ハルシネーション(幻覚)を起こす: 事実ではないことを、もっともらしく断言することがあります。LLM は、事実を検証するのではなく、ある言葉の次に来そうな単語を予測することでテキストを生成します。有用かつ正確な情報を提供するようトレーニングされてはいるものの、事実確認の機能は内蔵していません。だからこそ、ウェブ検索によるグラウンディングが非常に重要なのです。
よくある誤解で、LLM もソフトウェアのパッチのような形で「知識がアップデートされる」と思われがちです。しかし実際には、各モデルは決められたデータセットで一度トレーニングされるだけです。より新しい知識を備えた新モデルがリリースされる場合、それは既存モデルのアップデート版ではなく、ゼロから学習し直したまったく別のモデルなのです。
Gianluca Fiorelli, 戦略的・海外 SEO/AI 検索コンサルタント
ハルシネーションを起こして古い情報を共有する検索エンジンは、有用とは言えません。そのため LLM は、グラウンディングと呼ばれるプロセスによって、この問題を部分的に解決しています。
グラウンディングと RAG の仕組み
LLM は、ツール(計算機やその他のデータ API など)を使用する方法と、外部ソースから追加情報を取得する方法のどちらかを用いて、回答を検証および改善することができます。後者の方法は、検索拡張生成(RAG)として知られています。
ユーザーが質問を入力すると、LLM は自分にこう問いかけます。「この答えをすでに知っている?それとも追加情報が必要?」LLM がクエリの次に来る単語を高い確実性で予測できる場合(例えば「赤血球の働きは何?」のように、あまり変化がないタイプの情報)は、基本知識に基づいて回答する可能性が高いです。確信度が低い場合は(例えば「安くておすすめのコーヒーミルは?」のように、常に変化している情報)、検索ツールを使ってインターネット上の他ソースから関連情報を探し出します。
LLM は、回答に追加情報を含めるべきと思われる、次のようなクエリタイプを認識するように調整されています。
- モデルの学習範囲外のトピック: 「Ahrefs のキーワードエクスプローラー内で採用されているランキング要因は?」
- 鮮度や速報性が求められるトピック: 「Google の最新のコアアップデートはどんな内容で、いつ実施されましたか?」
- 明らかにウェブ検索が必要なトピック: 「2026 年に人気のリンク構築施策をネットで検索して。」
- 情報ソースや根拠を求めるプロンプト: 「Google がアルゴリズムでユーザーエンゲージメントシグナルを使用していることを確認できる情報源を教えて。」
LLM モデルの中には、追加の検索をトリガーしやすいものもあります(たとえば「Deep Research」モデルは、複数回の RAG 検索をトリガーするよう特別に設定されています)。
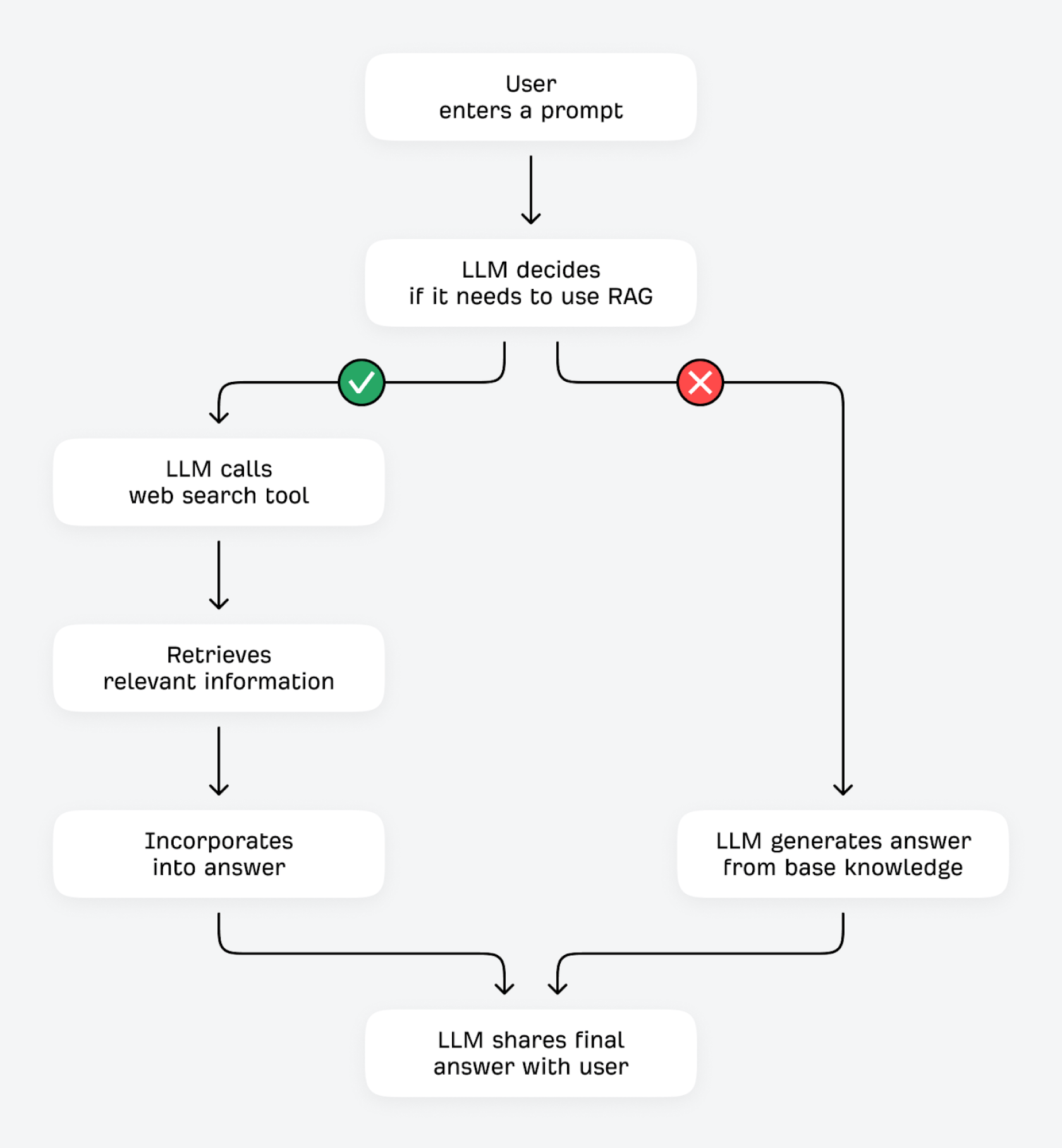
RAG を通じて正しい情報を見つける(しばしば「グラウンディング」と呼ばれる)このプロセスには、いくつかの利点があります。LLM は、サードパーティの情報源と照合することで、事実の正確性を向上させ、誤った情報を減らすことができます。トレーニングデータが比較的古い場合でも、最新情報を取得して共有できます。より詳細で網羅的な回答を提供でき、共有するすべての情報の透明性を確保し、出典を明示することができます。
AI 検索エンジンは、クエリファンアウトと呼ばれるプロセスでこのグラウンディングを行います。
クエリファンアウトの仕組み
重要なのは、クエリファンアウトが、AI 検索における可視性の向上に従来の SEO 手法が不可欠である理由を示している点です。
ChatGPT、Gemini、Perplexity のような AI アシスタントは、Google、Bing、Brave といった検索インデックスを使って最新情報を取得します。
どの検索プロバイダーをターゲットにするかが重要なのは、それぞれランキングのアルゴリズム、インデックス、掲載情報が異なるからです。例えば、Google 検索でブランドの存在感を高めると、Bing への依存度が高い ChatGPT よりも、Google AI モードの検索結果における可視性アップに役立つかもしれません。
| AI 検索エンジン | グラウンディングに使用される検索インデックス |
|---|---|
ChatGPT | Bing, Google |
Claude | Brave |
Gemini | Google |
Copilot | Bing |
Perplexity | In-house |
AI Mode | Google |
AI Overviews | Google |
ウェブ検索がトリガーされると、LLM は検索インデックスに対し、関連性の高い情報の提示を求めます。検索インデックスは結果の一覧を提供し、LLM はページタイトル、ページのスニペット(断片情報)や鮮度(公開日)などの情報からコンテンツを評価して、クロール対象とする最も関連性の高いページを選びます。
AI 検索での可視性向上に SEO が重要な理由
改めて強調しておきましょう。Google や Bing のような従来の検索エンジンは、AI 検索エンジンが回答内でどんなコンテンツに言及し、何を引用するかを判断する際、極めて重要な役割を果たしています。
言い換えると、従来の検索で上位ランクインすることが、AI 検索での可視性向上にもつながるのです。
では、LLM はいったい何を検索しているのでしょうか?
LLM はクエリファンアウトと呼ばれるプロセスを使います。ChatGPT などの AI 検索エンジンに入力されるプロンプトは、非常に長く会話形式で、しかもユーザー独特の表現であることが多いです。こうしたプロンプトをそのまま Google で検索しても、有益なコンテンツが見つかるとは限りません。
そのため、ユーザーのクエリをそのまま使ってウェブ検索を実行するのではなく…
「e コマースブランド向けに分析ツールを販売している中堅の BtoB SaaS 企業に依頼され、6 か月間のコンテンツ戦略を計画しています。その企業は…」

…LLM はその最初のプロンプトを使って、関連情報を取得しやすくするための、より短い関連クエリを連続して生成します。
こうしたクエリファンアウトも大規模言語モデルによって生成されるため、クエリは固定的ではありません。同じ内容の検索に対しても、頻繁に変わる可能性があります。

Mark Williams-Cook, AlsoAsked 創業者
このプロセスは SEO 担当者にはおなじみでしょう。これらの関連クエリは、ロングテールキーワード、副次的な検索意図、そして「他の人はこちらも質問(People Also Ask)」の質問と非常によく似ています。
- BtoB の SaaS 企業の一般的なコンテンツ戦略フレームワーク
- SaaS 向け TOFU と BOFU のコンテンツ例
- コンテンツ更新と内部リンク構築のベストプラクティス
- コンテンツ主導デモの成長を測る指標
実際、ChatGPT、Gemini、Copilot に回答内で引用されたリンクのうち、同じプロンプトを Google 検索した時に検索結果の上位 10 件に入っているページは たった 12% しかありません。ただ、だからといって従来の検索順位が無関係というわけではありません。AI 検索エンジンは複数の検索クエリを生成してコンテンツを取得します。そして、それらの派生クエリは多くの場合、従来型のキーワード中心の検索になるため、既存の SEO 対策が非常に大切になってくるのです。

クエリファンアウトは非常に便利です。会話の中でどのようなプロンプトが使われるかを推測する必要がなくなるからです。その代わりに、LLM が自然に生成する分解されたクエリ、つまり意味的な構成要素をターゲットに最適化しましょう。この手法は、従来のキーワードリサーチと非常によく似ています。[トピック] + [修飾語]、製品・サービスを比較するクエリ、言葉の定義を探すクエリ、そして「ベストプラクティス」コンテンツなどです。既存の SEO 調査で、おそらく既にファンアウトの派生クエリをカバーできているでしょう。
Gianluca Fiorelli, 戦略的・海外 SEO/AI 検索コンサルタント
検索・チャンク化・回答の合成の仕組み
LLM が検索インデックスから関連ページを取得しても、その全文を読むわけではありません。ページは小さなテキストの「かたまり」に分割され、モデルはクエリとの関連性が最も高いと思われるテキスト部分を優先的に抽出します(場合によってはその内容をさらに拡張します)。
これらのチャンク(情報のかたまり)は通常、それぞれ数百〜数千語程度で、ウェブページのごく一部にすぎません。LLM には厳格なコンテキストウィンドウの制限もあります。ユーザーのプロンプト、取得したすべてのチャンク、自身の回答を含め、処理できるテキスト量に上限があります。そのため、コンテンツを取り込む際には、情報を厳選する必要があるのです。
こちらがその例です。
| ページに含まれるすべてのコンテンツ | 「グラウンディングとは、モデルが外部ソースを取得し、関連する事実を抽出し、その結果得られる情報を用いて回答することでハルシネーションを減らし、情報の鮮度を高めるためのプロセスです。…その後、複数の情報源をスキャンして情報を比較し、テキストをそのままコピーするのではなく、回答を統合して生成します。この統合のステップによって、特定の 1 つの情報源への過度な依存を避けることができます。」 |
| スニペット(断片情報) | 「AI がウェブ検索などを通じて外部情報を取得し、その情報に基づいて回答を生成することで、ハルシネーションを減らす仕組み。」 |
| 拡張(1~2 行目) | 「グラウンディングとは、モデルが外部ソースを取得し、関連する事実を抽出し、その結果得られる情報を用いて回答することでハルシネーションを減らし、情報の鮮度を高めるためのプロセスです。モデルは、ウェブ検索を開始する前に、クエリが最新情報または事実確認できる情報を必要としているかどうかを判断します。」 |
| 拡張(33 ~ 34 行目) | 「その後、複数の情報源をスキャンして情報を比較し、テキストをそのままコピーするのではなく、統合して回答を生成します。この統合のステップによって、特定の 1 つの情報源への過度な依存を避けることができます。」 |
コンテンツを LLM が理解しやすい構造にする
これは重要なポイントです。AI 検索エンジンがインターネット上からコンテンツを取得する際、読み取れるのは一部の抜粋のみで、ページ全体に目を通すことはできません。このため、LLM の回答で引用される可能性を最大化するには、ページのすべての情報にアクセスできない場合でも、LLM にページの関連性と価値を理解してもらいやすい内容にする必要があります。
AI 検索エンジンはその後、このテキストを回答生成プロセスで統合します。
生のウェブコンテンツはモデルの回答にグラウンディングされ(根拠として組み込まれ)ます。前のステップで抽出されたテキストやデータのスニペット(断片)がモデルのコンテキストに追加され、簡単に言えば「ウェブから役に立ちそうな情報を入手しました。この情報を使ってユーザーの質問に答えてください」と指示されているのです。
引用ページが決定される仕組み
そこから、モデルは自身の持つ知識と取得したコンテンツを組み合わせて回答を生成し、ユーザーに共有します。回答には通常、引用が含まれます。引用とは、グラウンディングプロセスで利用した情報源へのリンク、つまりクリック可能な URL が掲載されることです。
AI 検索エンジンが取得したページのすべてが、最終的な回答で引用されるわけではありません。モデルは次のようないくつかの要因に基づいて、どの情報源を引用するかを決定します。
- 関連性:取得したコンテンツが、回答内の特定情報の提供にどれだけ直接貢献したか。
- 鮮度: 情報がどれだけ新しいものだと思われるか。
- 多様性: 引用元のバリエーション(AI 検索エンジンは、同じソースを繰り返し引用するよりも、複数の異なるソースの引用を好む傾向にあります)。
つまり、コンテンツが取得されて読まれたとしても、目に見える形で引用されるという保証はありません。回答内の情報と直接関係があると判断される必要があります。
パーソナライゼーションの仕組み
ここまでが AI 検索エンジンの基本的な仕組みですが、もう一つ複雑な要素が存在します。それがパーソナライズです。
ChatGPT などの AI 検索エンジンは、個々のユーザーに合わせて結果をパーソナライズするため、同じプロンプトでも人によって異なる結果が生成されることがあります。パーソナライズは、次のような要素を考慮して行われます。
- 現在の会話コンテキスト: チャット内の直前までのやり取りは、プロンプトに対する回答に影響します。例えば、ハイキングギアの「耐久性」を重視するとユーザーが発言した場合、あとで同じチャットで「バックパックのおすすめ」を聞いたときに、ChatGPT が検索条件にその基準を含めると思われます。
- メモリー: 多くの LLM には、過去の会話で出現した特定の情報やユーザーの嗜好を記憶できるメモリ機能が備わっています。例えば、メモリ機能を有効にすると、ChatGPT はユーザーが共有した詳細情報(名前や興味など)をもとに情報を推測したり記憶したりし、それ以降の会話に反映させることで回答をパーソナライズします。
- 場所、時間、日付: 多くの AI 検索エンジンは、ユーザーに関する情報を推測し、それを使って回答の内容を調整します。たとえば、IP アドレスからおおよその場所を推定して「ブランチが食べられる近くのお店」のようなクエリに対応したり、クエリの日付や時間帯を考慮したりします(「キャンプの持ち物リスト」なら、冬は 4 シーズンテント、夏は 3 シーズンテントを勧めるなど)。
- システムプロンプト: システムメッセージで共有された特定の嗜好は、会話に反映されます(システムプロンプトに「私はビーガンであることを覚えておいて」と伝えてあると、「朝食におすすめなヘルシーメニュー」といったプロンプトに対する回答の内容を、それに合わせて調整します)。
システムプロンプトについて理解していただくため、分かりやすいたとえ話をしましょう。サッカーに例えると、「トレーニングデータ」とは、長年にわたって積み重ねてきた練習の成果、つまり体に染みついた、長期にわたって記憶されている情報のことです。一方でシステムプロンプトとは、試合直前に与えられるコーチの指示のようなものです。試合でのパフォーマンスを大きく左右する、一時的にはっきりと記憶される情報だと言えるでしょう。
Mark Williams-Cook, AlsoAsked 創業者

そのため、個々のプロンプトへの回答にこだわるのではなく、ブランドやウェブサイトの平均的な認知度を、様々なプロンプトの追跡を通して長期的に調査していくのが良いでしょう。
まとめ
ChatGPT、Perplexity、Google AI モードなど、各 AI 検索エンジンの特徴はそれぞれ微妙に異なりますが、基本的な動作プロセスは同じです。SEO 担当者やマーケティング担当者にとって重要なのは、Google や Bing といった従来の検索エンジンが、AI 検索エンジンの稼働に必要なインフラストラクチャの大部分を提供している点です。このため、AI 検索に合わせてコンテンツを最適化するには、従来の SEO のベストプラクティスの実践がカギになります。
ライアン・ローは Ahrefs のコンテンツマーケティングディレクターです。ライアンにはライター、コンテンツ戦略家、チームリーダー、マーケティングディレクター、VP、CMO(最高マーケティング責任者)、エージェンシー設立者として 13 年の経験があります。彼は Google、Zapier、GoDaddy、Clearbit、Algolia など、多くの企業のコンテンツマーケティングと SEO 改善を支援してきました。彼は小説家でもあり、2 種類のコンテンツマーケティングコースの考案者でもあります。
SEO をステップバイステップでマスター
検索エンジンの仕組み
SEO について学習する前に、まず検索エンジンの仕組みを理解しましょう。
SEO の基本
SEO を成功させるウェブサイト作りを学び、SEO における 4 つの主要な側面を理解します。
キーワードリサーチ
SEO の出発点は、ターゲットとなるお客様が何を求めて検索しているのかを理解することです。
SEO コンテンツ
検索エンジンで上位に表示されるコンテンツの作り方をご紹介します。
オンページ SEO
そして、検索エンジンが理解できるようにページを最適化することです。
リンク構築
検索エンジンで上位に表示されるコンテンツの作り方をご紹介します。
テクニカル SEO
Google がウェブサイトにアクセスしてサイトの内容を理解するのを妨げる技術的な問題を未然に防ぎましょう。
ローカル SEO
ローカル検索結果での可視性を向上させ、拠点地域でより多くの顧客を獲得する方法を学びましょう。
AI が SEO にもたらす変化
現在、生成 AI に触れずに SEO について語るのは、もはや不可能です。
AI 検索エンジンの仕組み
ChatGPT のような AI 検索エンジンが、どのように回答を生成し、どのブランドや商品に言及するかをどうやって決めているのかを理解しましょう。