


¿Cómo funcionan los motores de búsqueda de IA?

Por Ryan Law
Director de Marketing de contenidos de Ahrefs
Cuando le pides a ChatGPT que te recomiende los mejores auriculares de diadema para entrenar, ¿qué ocurre realmente?
¿Cómo generan sus respuestas los motores de búsqueda con IA y eligen sus recomendaciones de productos? ¿En qué se diferencian de los motores de búsqueda tradicionales como Google (y en qué se solapan)?
Y, lo más importante, ¿cómo puedes ayudar a que tu sitio web, marca y productos aparezcan?
Gracias a Gianluca Fiorelli y Mark Williams-Cook por revisar y contribuir en este capítulo.
¿Qué son los motores de búsqueda de IA?
Los motores de búsqueda de IA son sistemas de preguntas y respuestas que utilizan modelos de lenguaje de gran tamaño (LLM) para encontrar información y generar respuestas.
Hay algunas diferencias clave entre los motores de búsqueda tradicionales y los motores de búsqueda en IA (aunque estas diferencias se están reduciendo a medida que los motores de búsqueda tradicionales incorporan más funciones de IA):
- En lugar de introducir consultas puntuales, los usuarios pueden hacer preguntas de seguimiento y mantener la conversación.
- En lugar de devolver una lista de enlaces ordenada por relevancia, los motores de búsqueda de IA ofrecen respuestas y recomendaciones directas (y estas respuestas pueden cambiar con regularidad).
- En lugar de enviar a la persona que está realizando la búsqueda a visitar tu sitio web, los usuarios obtienen sus consultas respondidas directamente en la interfaz del chat (lo que se traduce en menos clics de vuelta a tu sitio web).
Así es como se ve una interfaz de búsqueda de IA arquetípica, similar a lo que verías en ChatGPT, Claude o en el modo IA:

- Prompt conversacional: La pregunta del usuario.
- Mensaje de fundamentación: Un mensaje que muestra que el LLM ha decidido buscar información adicional para usarla en su respuesta.
- Respuesta: La respuesta generada por IA al prompt del usuario.
- Mención: Una entidad (como tu marca o producto) mencionada en línea en el texto de la respuesta.
- Citas: URL de las fuentes utilizadas en la generación de la respuesta, que suelen aparecer al final.
Para ayudarte a aparecer en respuestas como estas, primero debes entender los procesos clave que hacen que los motores de búsqueda de IA funcionen.
Cómo funciona el entrenamiento
Los LLM se entrenan con enormes cantidades de contenido. En la práctica, han "leído" toda la Wikipedia, todo el conjunto de datos Common Crawl, todos los Google Books y muchos, muchísimos millones de páginas de contenido web.
Estos datos de entrenamiento ayudan a proporcionar al LLM su "comprensión" del mundo. Si tu empresa de auriculares aparece muchas veces en sus datos de entrenamiento, en contextos relevantes y junto a descriptores positivos ("mejor relación calidad-precio", "genial para el gimnasio", etc.), es muy probable que tu empresa se mencione en las respuestas del LLM a prompts relacionados con auriculares.
¿Sabías esto?
Este proceso de entrenamiento es más complejo de lo que se explica aquí. Hay etapas de preentrenamiento para eliminar HTML, quitar información personal identificable, excluir palabras de listas de bloqueo y filtrar los datos para determinados idiomas. También hay etapas de posentrenamiento para entrenar el modelo de lenguaje con el objeto de que se comporte más como un asistente de chat útil (y no solo como un predictor del siguiente token). Para obtener más información, reproduce el vídeo de Andrej Karpathy, Deep Dive into LLMs like ChatGPT.


Aquí es donde el SEO basado en entidades se vuelve fundamental. Si tu marca aparece de forma constante en los Gráficos de conocimiento, está correctamente estructurada con marcado Schema y coexiste con entidades relevantes en contenido de alta calidad en toda la web, estás construyendo una "señal de entidad" más sólida en los datos de entrenamiento.

Gianluca Fiorelli, Consultor estratégico e internacional de SEO/búsqueda con IA
Fundamentalmente los LLM tienen muchas peculiaridades:
- Son probabilísticos: puedes usar el mismo prompt y obtener respuestas diferentes cada vez. Esta naturaleza probabilística significa que no puedes “optimizar para un prompt” de la misma manera que optimizas para una palabra clave. En su lugar, piensa en distribuciones: ¿cuál es la probabilidad de que tu marca aparezca en 100 prompts similares? Por eso, hacer un seguimiento de la visibilidad media en muchos prompts es mejor que obsesionarse con unos pocos prompts.
- Su conocimiento tiene una fecha de corte: de forma predeterminada, el conocimiento de un LLM se limita a lo que estaba contenido en el conjunto de datos cuando se entrenó ese modelo en concreto. Cada modelo se entrena una sola vez con una instantánea de datos hasta una fecha determinada. Periódicamente se publican nuevos modelos con fechas de corte más recientes (históricamente, aproximadamente cada seis meses).
- Alucinan: pueden afirmar con seguridad cosas que no son ciertas. Los LLM generan texto prediciendo qué palabras es probable que vengan a continuación, sin verificar hechos. Aunque se entrenan para ser útiles y precisos, no tienen un mecanismo integrado de verificación de datos, razón por la que la fundamentación mediante búsqueda web es tan importante.
Es malentendido común pensar que los LLM reciben «actualizaciones de conocimiento» como parches de software. En realidad, cada modelo se entrena una sola vez con un conjunto de datos fijo. Cuando ves el lanzamiento de un nuevo modelo con un corte de conocimiento más reciente, se trata de un modelo completamente nuevo entrenado desde cero, no una actualización del existente.
Gianluca Fiorelli, Consultor estratégico e internacional de SEO/búsqueda con IA
Un motor de búsqueda que alucina y comparte información antigua no suena muy útil. Por eso, los LLM superan algunas de estas limitaciones mediante un proceso conocido como fundamentación.
Cómo funcionan la fundamentación y la RAG
Los LLM pueden verificar y mejorar sus respuestas de dos maneras: usando herramientas (como calculadoras u otras API de datos) o recuperando información adicional de fuentes externas. Este segundo proceso se conoce técnicamente como generación aumentada por recuperación (RAG).
Cuando un usuario introduce una pregunta, el LLM se pregunta a sí mismo: “¿Ya sé la respuesta o debería obtener información adicional?”. Si el LLM puede predecir el siguiente token con un alto grado de certeza (por ejemplo, en preguntas que no cambian mucho, como “¿qué hacen los glóbulos rojos?”), probablemente responderá a partir de su conocimiento base. Con un bajo grado de certeza (en preguntas más propensas a cambiar, como “¿cuál es el mejor molinillo de café económico?”), puede usar su herramienta de búsqueda para encontrar información relevante de otras fuentes en internet.
Los LLM se ajustan para reconocer tipos de consulta que podrían beneficiarse de información adicional, como:
- Temas fuera del alcance del entrenamiento de los modelos: “¿Cuáles son los factores internos de posicionamiento que utiliza Keywords Explorer de Ahrefs?”
- Temas que requieren información actual o sensible al paso del tiempo: "¿Cuál fue la actualización principal más reciente de Google y cuándo se implementó?"
- Temas que piden explícitamente una búsqueda web: “Busca en internet tácticas populares de link building en 2026”.
- Prompts que solicitan fuentes y pruebas: "Proporciona fuentes que confirmen que Google utiliza señales de interacción del usuario en su algoritmo".
Algunos modelos de LLM también son muy propensos a activar búsquedas adicionales (por ejemplo, los modelos de "investigación profunda" están configurados específicamente para activar múltiples búsquedas RAG).
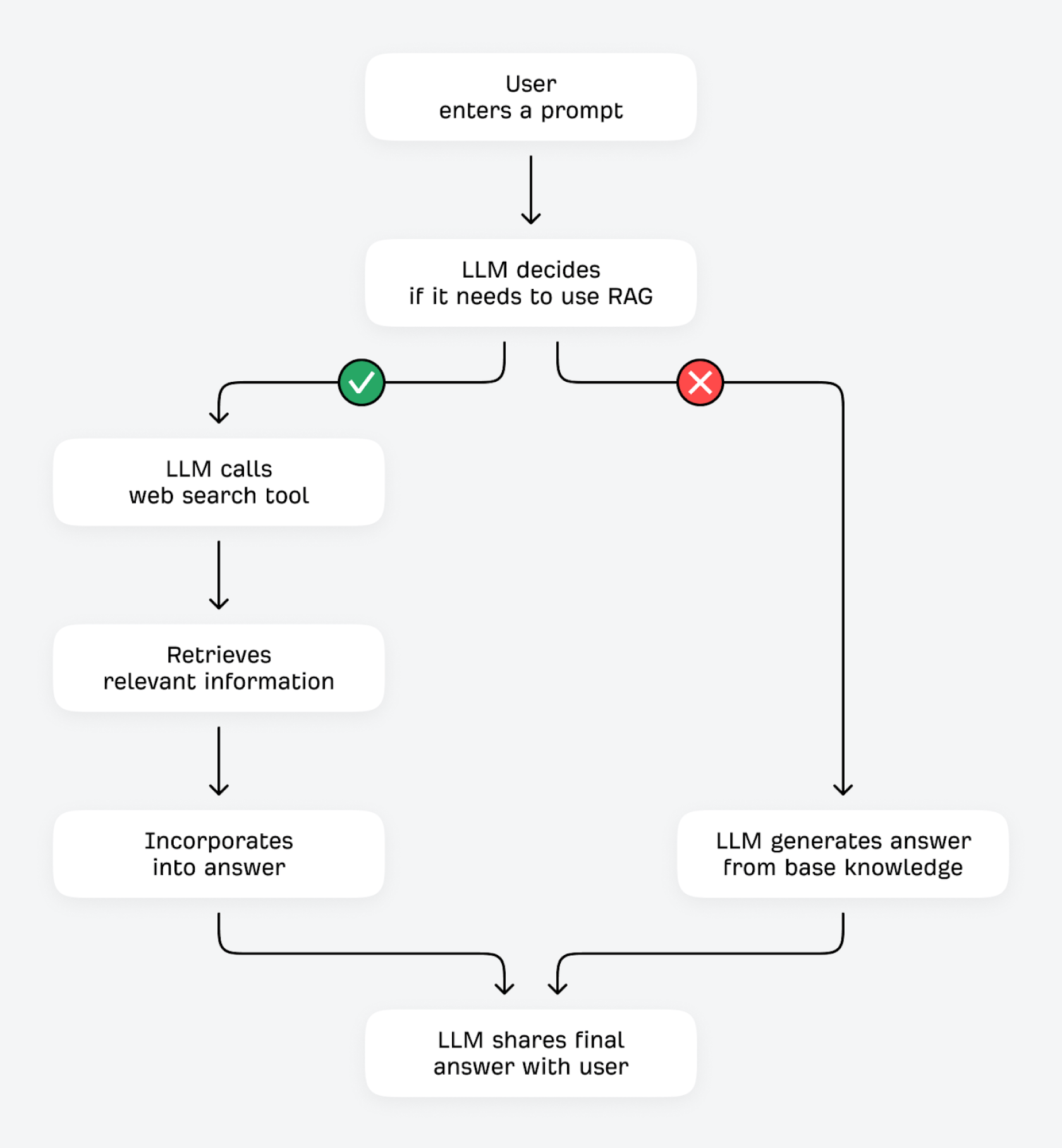
Este proceso de encontrar la verdad fundamental mediante RAG (a menudo denominado "búsqueda fundamentada") ofrece varias ventajas. El LLM puede mejorar la precisión factual y reducir las alucinaciones al contrastar sus respuestas con fuentes de terceros. Puede recuperar y compartir información actualizada, incluso si sus datos de entrenamiento están relativamente desactualizados. Puede compartir respuestas más detalladas y completas, y ofrecer mayor transparencia y atribución de todo lo que comparte.
Los motores de búsqueda con IA realizan esta fundamentación mediante un proceso conocido como desglose de consulta.
Cómo funciona el desglose de consultas
En definitiva, la ramificación de consultas explica por qué el SEO tradicional es fundamental para la visibilidad en IA.
Los asistentes de IA como ChatGPT, Gemini y Perplexity utilizan índices de búsqueda como Google, Bing y Brave para recuperar información actualizada.
El proveedor de búsquedas resulta importante porque cada uno tiene algoritmos de posicionamiento, índices y cobertura distintos: hacer que tu marca sea visible en la Búsqueda de Google podría mejorar tu visibilidad en el modo IA más que en ChatGPT, que depende en mayor medida de Bing.
| Motor de búsqueda con IA | Índices de búsqueda utilizados para la fundamentación |
|---|---|
ChatGPT | Bing, Google |
Claude | Brave |
Gemini | Google |
Copilot | Bing |
Perplexity | In-house |
AI Mode | Google |
AI Overviews | Google |
Cuando se activa una búsqueda web, el LLM solicita resultados relevantes a su índice de búsqueda. El índice de búsqueda devuelve una lista de resultados, y el LLM selecciona las páginas más relevantes para rastrear mediante la evaluación de información como el título de la página, el contenido del fragmento de resultado mostrado y su actualidad (cuándo fue publicado).
Por qué el SEO es crucial para la búsqueda con IA
Vale la pena repetirlo: los motores de búsqueda tradicionales como Google y Bing desempeñan un papel crucial a la hora de ayudar a los motores de búsqueda de IA a decidir qué contenido mencionar y citar en sus respuestas.
O dicho de otro modo, posicionarte arriba en la búsqueda tradicional mejorará tu visibilidad en la búsqueda de IA.
Pero ¿qué busca exactamente el LLM?
Los LLM usan un proceso llamado desglose de consultas. Muchos prompts que se introducen en ChatGPT y otros motores de búsqueda de IA son extremadamente largos, conversacionales y a menudo completamente únicos. Buscar en Google esos prompts exactos no siempre devolverá contenido útil.
Así que, en lugar de hacer una búsqueda web con la consulta exacta del usuario…
"Estoy planificando una estrategia de contenidos de 6 meses para una empresa B2B SaaS de tamaño medio que vende un producto de analítica a marcas de ecommerce. La empresa…"

…Los LLM usan ese prompt inicial para generar una serie de consultas más cortas y relacionadas que ayuden a recuperar información relevante.
Estas consultas desglosadas también las genera el modelo de lenguaje de gran tamaño y, por lo tanto, son no deterministas: pueden cambiar con regularidad, incluso para la misma búsqueda.

Mark Williams-Cook, Fundador, AlsoAsked
Este proceso debería resultar familiar a los profesionales de SEO: estas consultas relacionadas son muy parecidas a las palabras clave long-tail, las subintenciones y las preguntas de "Otras preguntas de los usuarios":
- Marcos habituales de estrategia de contenidos B2B para SaaS
- Ejemplos de contenido TOFU vs BOFU para SaaS
- Prácticas recomendadas de actualización de contenido y enlaces internos
- Métricas para el crecimiento con demos impulsadas por contenido
De hecho, solo el 12% de los enlaces citados por ChatGPT, Gemini y Copilot aparecen en los 10 primeros resultados de Google para el prompt original del usuario. Sin embargo, esto no significa que el posicionamiento tradicional sea irrelevante. Los motores de búsqueda de IA recuperan contenido generando múltiples consultas de búsqueda, y esas consultas desglosadas suelen ser búsquedas más tradicionales, centradas en palabras clave, en las que el trabajo de SEO que haces importa muchísimo.

El desglose de consultas es liberador: no necesitas adivinar qué prompts conversacionales usará la gente. En su lugar, optimiza para las consultas descompuestas, es decir, los componentes semánticos que los LLM generarán de forma natural. Se parecen muchísimo a la investigación tradicional de palabras clave: [tema] + [calificador], consultas de comparación, consultas de definición y contenido de "prácticas recomendadas". Es probable que tu investigación SEO actual ya cubra el espacio de desglose.
Gianluca Fiorelli, Consultor estratégico e internacional de SEO/búsqueda con IA
Cómo funcionan la recuperación, la fragmentación y la síntesis de respuestas
Una vez que un LLM recupera páginas relevantes de un índice de búsqueda, no las lee por completo. En su lugar, las páginas se dividen en pequeños “fragmentos” de texto, y el modelo prioriza (y a veces amplía) las secciones de texto que parecen más relevantes para la consulta.
Estos fragmentos suelen tener desde unos cientos hasta unos miles de palabras cada uno, una pequeña fracción de la mayoría de las páginas web. El LLM también opera con límites estrictos de ventana de contexto: puede procesar una cantidad limitada de texto, incluido el prompt del usuario, todos los fragmentos recuperados y su propia respuesta. Esto significa que debe ser muy selectivo con el contenido que recupera e incluye.
Aquí tienes un ejemplo:
| Contenido de la página completa | «La fundamentación es un flujo de trabajo en el que el modelo recupera fuentes externas, extrae hechos relevantes y utiliza esos extractos para reducir las alucinaciones y aumentar la actualidad.… A continuación, analiza múltiples fuentes, compara información y sintetiza una respuesta en lugar de copiar el texto literalmente. Este paso de síntesis ayuda a evitar la dependencia excesiva de una única fuente». |
| Fragmento | “Explica cómo los asistentes usan la búsqueda web para recuperar fuentes externas y reducir las alucinaciones al fundamentar las respuestas en hechos recuperados”. |
| Ampliación (líneas 1–2) | “La fundamentación es un flujo de trabajo en el que el modelo recupera fuentes externas, extrae hechos relevantes y utiliza esos extractos para reducir las alucinaciones y aumentar la actualidad. El modelo evalúa si una consulta requiere información actualizada o verificable antes de iniciar una búsqueda web”. |
| Ampliación (líneas 33–34) | “A continuación, analiza múltiples fuentes, compara información y sintetiza una respuesta en lugar de copiar el texto literalmente. Este paso de síntesis ayuda a evitar la dependencia excesiva de una única fuente”. |
Facilita que los LLM comprendan tu contenido
Esto es importante: cuando los motores de búsqueda con IA recuperan tu contenido de internet, solo pueden ver extractos parciales, y no la página completa. Para maximizar las probabilidades de que se te cite en la respuesta del LLM, la relevancia y el valor de tu página deben ser fáciles de entender para los LLM, incluso sin tener acceso a la página completa.
El motor de búsqueda de IA integra entonces este texto en su proceso de generación de respuestas.
El contenido web en bruto se integra mediante fundamentación en la respuesta del modelo: los fragmentos de texto o datos extraídos en el paso anterior se añaden al contexto del modelo, básicamente indicando: "Aquí tienes algo de contexto de la web que podría ser útil; ahora responde a la pregunta del usuario usando esta información".
Cómo se eligen las citas
A partir de ahí, el modelo genera una respuesta combinando su conocimiento innato con el contenido recuperado y la comparte con el usuario. La respuesta suele incluir citas: URL en las que se puede hacer clic que enlazan a las fuentes utilizadas durante el proceso de fundamentación.
No todas las páginas que recupera el motor de búsqueda de IA recibirán una cita en la respuesta final. El modelo selecciona qué fuentes citar en función de varios factores:
- Relevancia: En qué medida el contenido recuperado en la respuesta contribuyó de forma directa a las peticiones específicas.
- Actualidad: Cómo de reciente parece ser la fuente.
- Diversidad: La diversidad de las fuentes de las citas (ya que los motores de búsqueda con IA suelen preferir citar múltiples fuentes distintas en lugar de citar repetidamente la misma).
Esto significa que, aunque tu contenido se recupere y se lea, no hay garantía de recibir una cita visible; el contenido debe considerarse directamente relevante para una afirmación concreta en la respuesta.
Cómo funciona la personalización
Este es el corazón del funcionamiento de los motores de búsqueda con IA, pero hay un nivel adicional de complejidad: la personalización.
ChatGPT y otros motores de búsqueda de IA pueden personalizar sus resultados para cada usuario, lo que significa que el mismo prompt puede generar resultados diferentes para distintas personas. La personalización puede verse influida de varias maneras, entre ellas:
- Contexto actual de la conversación: Los mensajes anteriores en el mismo chat influirán en la respuesta al prompt actual. Si mencionas que valoras la “durabilidad” en tu equipo de senderismo, puedes esperar que ChatGPT incluya este criterio en su búsqueda cuando pidas “recomendaciones de mochilas” más adelante en el chat.
- Memoria: Muchos LLM tienen una función de memoria que permite al sistema conservar ciertos datos o preferencias entre chats. Por ejemplo, con la memoria habilitada, ChatGPT inferirá y recordará detalles que hayas compartido (como tu nombre o intereses) y los incluirá en futuras conversaciones para personalizar sus respuestas.
- Ubicación, hora, fecha: Muchos motores de búsqueda de IA pueden inferir información sobre ti y adaptar sus respuestas con ella: desde usar tu dirección IP para una ubicación aproximada (para consultas como “brunch cerca de mí”) hasta la fecha y la hora (“lista para acampar” podría sugerir una tienda de campaña de 4 estaciones en invierno y una de 3 estaciones en verano).
- Prompts del sistema: Cualquier preferencia específica compartida en el mensaje del sistema influirá en tus conversaciones (añadir "recuerda que soy vegano" al prompt del sistema influirá en respuestas a prompts como "ideas de desayuno saludable").
Aquí tienes una analogía para entender los prompts del sistema. Si estuvieras jugando al fútbol, los “datos de entrenamiento” serían toda la práctica acumulada a lo largo de los años: la memoria muscular a largo plazo. El prompt del sistema es lo que te dice tu entrenador justo antes de saltar al campo. Es la potente memoria a corto plazo, y es más probable que influya en el resultado.
Mark Williams-Cook, Fundador, AlsoAsked

Por esta razón, es buena idea hacer un seguimiento de la visibilidad media de tu marca y de tu sitio web a lo largo del tiempo y en muchos prompts, en lugar de obsesionarte con la respuesta de un único prompt.
Reflexiones finales
Cada motor de búsqueda de IA (desde ChatGPT hasta Perplexity o Google AI Mode) es ligeramente distinto, pero los procesos fundamentales son los mismos. Y, lo que es importante para profesionales de SEO y del marketing, los motores de búsqueda tradicionales como Google y Bing proporcionan gran parte de la infraestructura necesaria para que funcionen los motores de búsqueda de IA. Optimizar para la búsqueda de IA depende en gran medida de las buenas prácticas tradicionales de SEO.
Más información
Ryan Law es el director de marketing de contenidos de Ahrefs. Ryan tiene 13 años de experiencia como escritor, estratega de contenidos, líder de equipo, director de marketing, vicepresidente, CMO y fundador de agencias. Ha ayudado a decenas de empresas a mejorar su marketing de contenidos y SEO, incluidas Google, Zapier, GoDaddy, Clearbit y Algolia. También es novelista y creador de dos cursos de marketing de contenidos.
Domina el SEO paso a paso
¿Cómo funcionan los motores de búsqueda?
Antes de empezar a aprender SEO, es necesario entender cómo funcionan los motores de búsqueda.
Fundamentos de SEO
Aprende a preparar tu sitio web para el éxito en SEO y conoce los cuatro pilares principales del SEO.
Keyword Research
El punto de partida del SEO es entender qué buscan tus clientes objetivo.
Contenido de SEO
Aprende a crear contenido que se posicione en los motores de búsqueda.
SEO On-Page
Aquí es donde optimizas tus páginas para ayudar a los motores de búsqueda a entenderlas.
Link Building
Aprende a crear contenido que se posicione en los motores de búsqueda.
SEO técnico
Evita problemas técnicos que impidan que Google acceda a tu sitio web y lo comprenda.
SEO local
Aprende a mejorar tu visibilidad en los resultados de búsqueda locales y consigue más clientes de tu zona.
Qué Significa la IA para el SEO
No se puede hablar de SEO hoy en día sin mencionar la IA generativa.
¿Cómo funcionan los motores de búsqueda de IA?
Aprende exactamente cómo los motores de búsqueda de IA como ChatGPT generan sus respuestas y eligen qué marcas y productos mencionar.