
分面导航是一种被广泛接受的 UX 模式,可帮助用户在更短的时间内发现他们正在寻找的内容。 缺点是它带有许多潜在的 SEO 问题。
这篇导航种你可以学到:
分面导航(或分面搜索)是一种在拥有多个列表的网站的类别/存档页面上找通常会出现的导航类型。 其目的是帮助用户更具多个列表属性,更轻松地找到他们正在寻找的内容。
许多人将分面导航简单地称为“过滤器”。
你最常在以下类别的页面上找到此类导航:
- 电子商务网站,例如 AO.com
- 招聘类网站,例如 Total Jobs
- 旅游/预定网站,例如 Google Flights 或 Airbnb
在其他的一些大型网站上也很常见。
分面导航会按属性过滤页面上的列表。 如前所述,列表通常是:
- 招聘职位
- 商品
- 旅店/航班
属性因站点而异,但常见示例包括:
- 价格
- 颜色
- 品牌
- 重量
- 航班时间
- 薪资
- 包裹数量
- 寄送时间
一旦站点管理员为列表提供了相关属性,站点就会在列表中向用户显示这些属性:
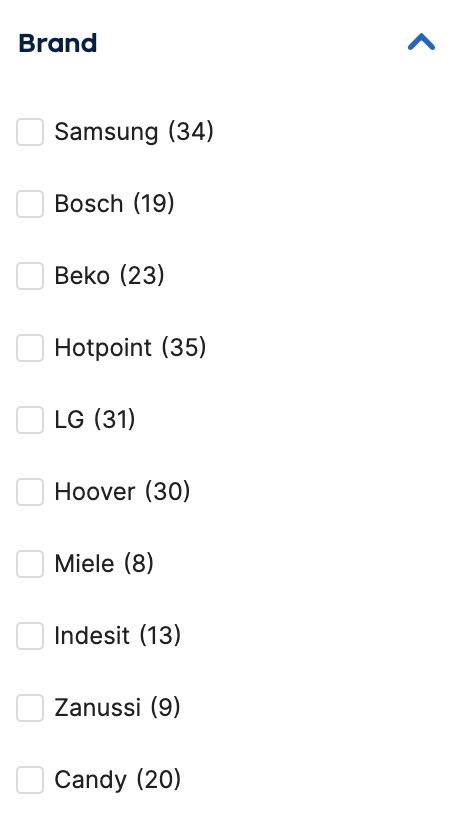
当用户选择过滤器时通常会发生四种情况之一。
- 列表会立即更新以反映选择,无需重新加载页面(通过使用 JavaScript)。
- 页面重新加载,列表反映了选择(不涉及 JavaScript)。
- 当用户选择列表中的一个项目时,除非他们也点击“应用”按钮,否则不会发生任何事情,然后更新列表以反映选择(再次使用 JavaScript)
- 当用户单击以应用过滤器时,将加载一个新页面。
前两个选项具有类似的 UX,但与选项三的 UX 模式不同。
你使用哪种 UX 模式取决于用户是否可能使用多个过滤器。 如果用户倾向于应用多个过滤器,那么只应用过滤器并在他们选择应用后更新列表是有意义的。
应用过滤器后,URL 发生的情况也可能有所不同:
- 它什么都不做。 列表更新,URL 没有更改。
- 该站点将参数附加到 URL 中,例如 “?colour=blue&brand=samsung”。
- 该站点在 URL 中附加一个哈希来做标识,例如,#colour=blue
- 创建一个新的静态 URL,如 /jeans/blue/(用户在此示例中选择颜色为 “蓝色”)
你可能并不希望分面导航出现这些问题:
- 重复内容
- 索引虚高
- 抓取问题
不幸的是,分面导航可能会创建几乎无限数量的分面组合和可索引的 URL。 无论上述哪个问题对 SEO 的影响都很很高。
以下是这些问题如何发生的、以及其对你网站 SEO 的影响的一些示例。
重复内容
重复内容是指可以通过多个 URL 访问相同或相似的内容。 过滤器因大量创建具有重复内容的 URL 而臭名昭著。 主要原因是由于过滤出的页面和原始副本非常相似,从而导致重复内容出现。
虽然重复的内容不一定是负面的排名信号,但它可能会导致以下问题:
- 关键词蚕食
- 将排名权重稀释为多个 URL(而不是合并为一个更强大的 URL)
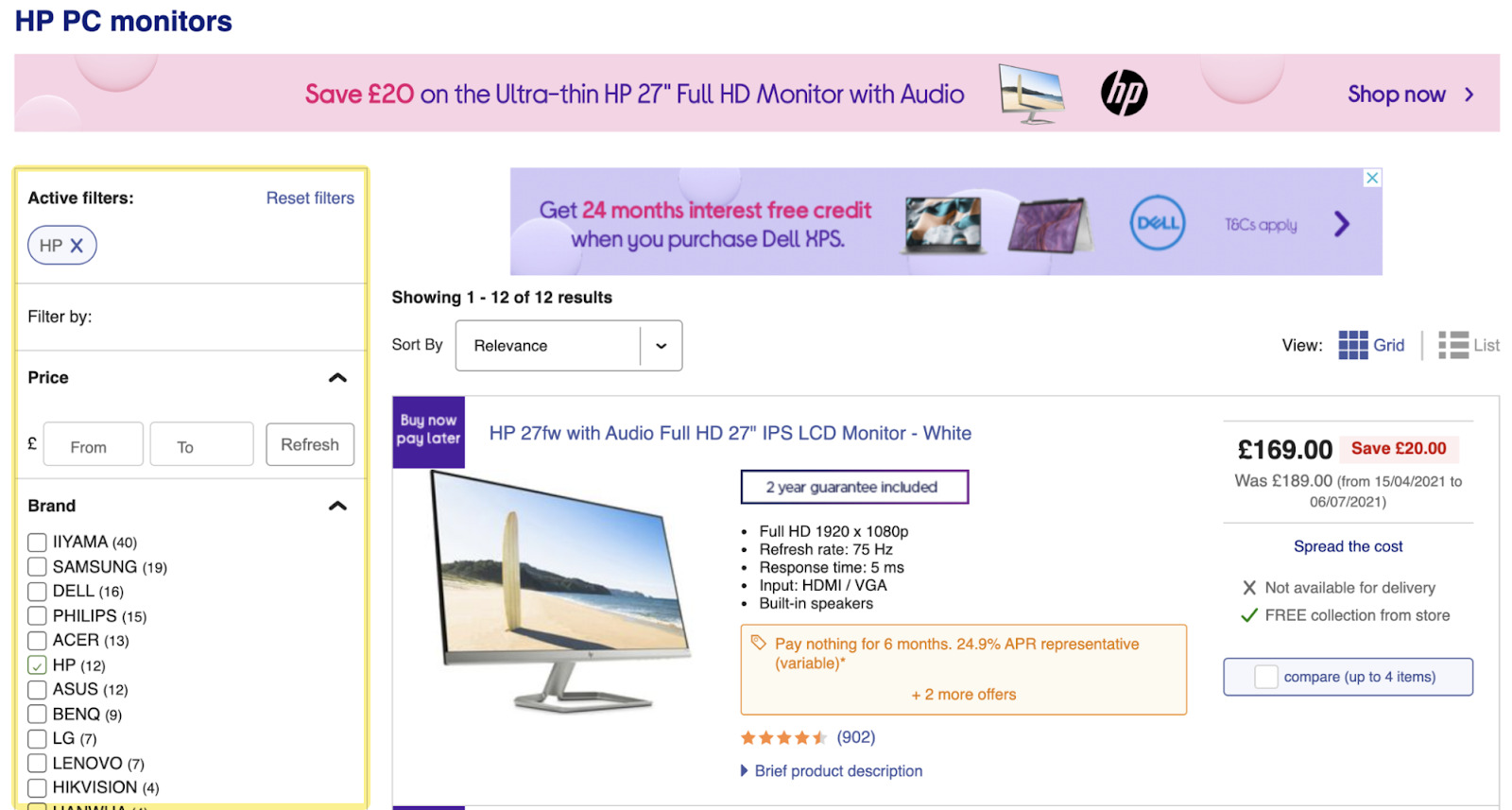
以电子商务网站 currys.co.uk 为例。 我们从他们的 HP PC Monitors 页面开始。 这是一个相当标准的电子商务布局,顶部有标题、列表和分面搜索:
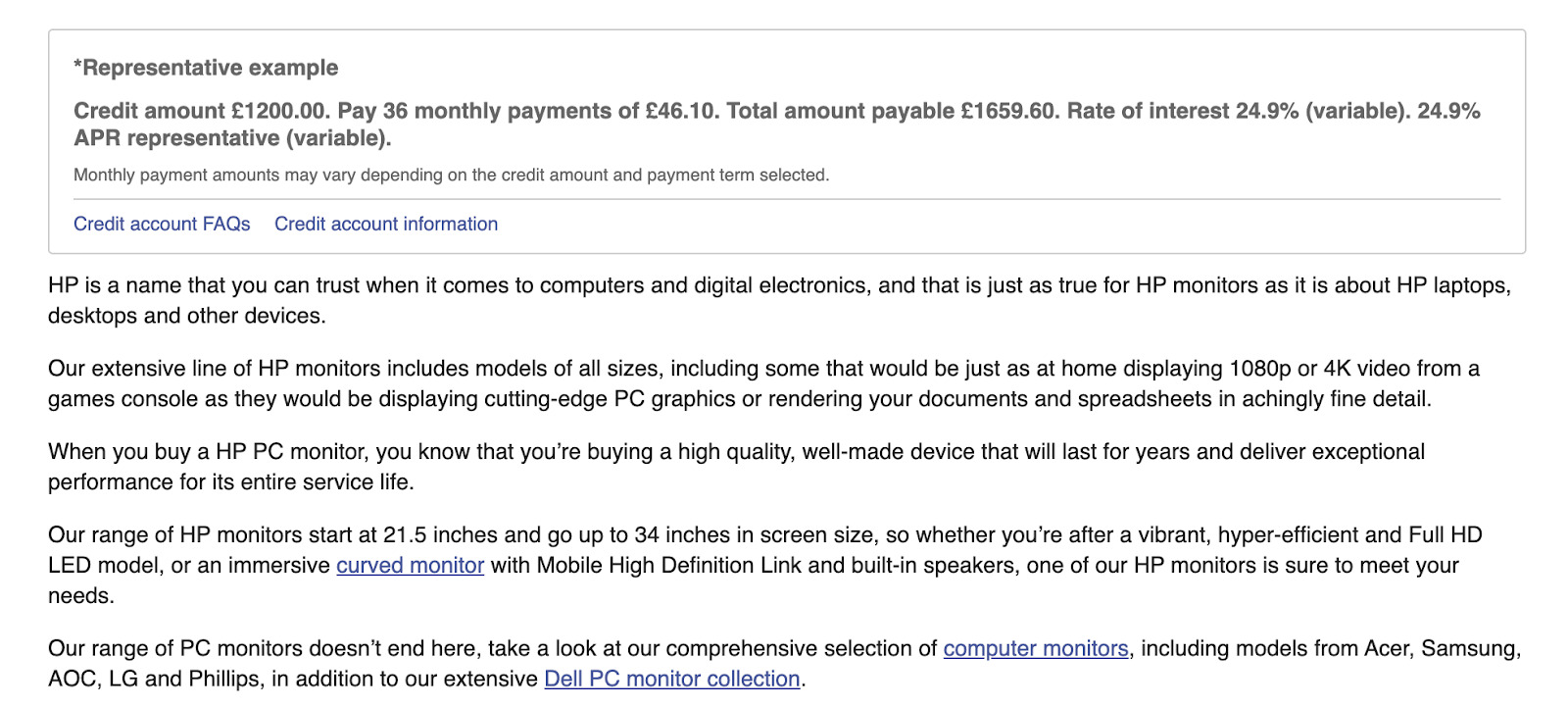
然后在产品列表下方,有关 HP 显示器的一些内容:
现在应用 “4k monitors” 过滤器。
你将看到产品列表更新、H1 以及 URL 的更改:
/hp-computing/pc-monitors/pc-monitors/354_3057_30059_16_xx/xx-criteria.html
变成了:
/hp-4k-monitors/pc-monitors/pc-monitors/354_3057_30059_16_ba00012894-bv00311096/xx-criteria.html
但是,如果你回滑动到页面底部,列表下方存在相同的内容块。
这只是网站上重复的一个例子。 在每个可用的过滤器中进行扩展,你将很快拥有数百万个重复页面。
索引虚增
索引虚增是指搜索引擎将你网站上大量的没有搜索价值的页面编入索引。
正如 John Mueller 在此视频中所解释的那样,仅允许 Google 将高质量页面编入索引至关重要,因为将低质量页面编入索引会影响 Google 对你网站的整体看法:
分面导航可能会创建数百万个没有独特内容的可索引 URL。 它还可能生成许多对使用搜索引擎的用户没有价值的页面变体。
下面就是个示例:
AO.com 有一个专用于 “freestanding washing machines” 的类别页面:
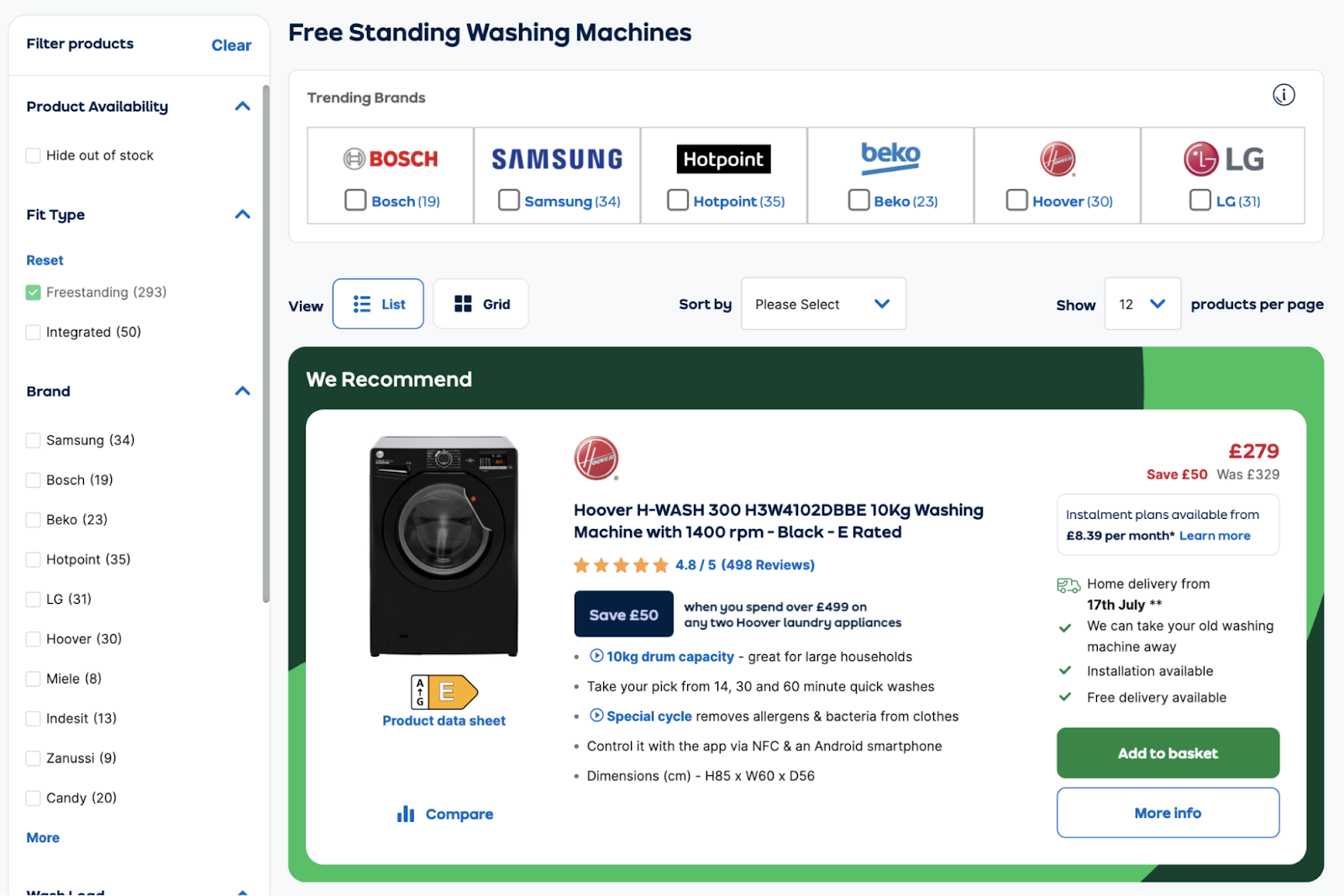
用户可以访问此页面并决定他们的想做的筛选:
- 品牌: Samsung
- 清洗量: Large
- 颜色: Silver
- 清洗体积: Large
- 特色: Quick Wash
- 能耗指标: A
多亏了过滤器,该网站准确地返回了适合用户需求的洗衣机。
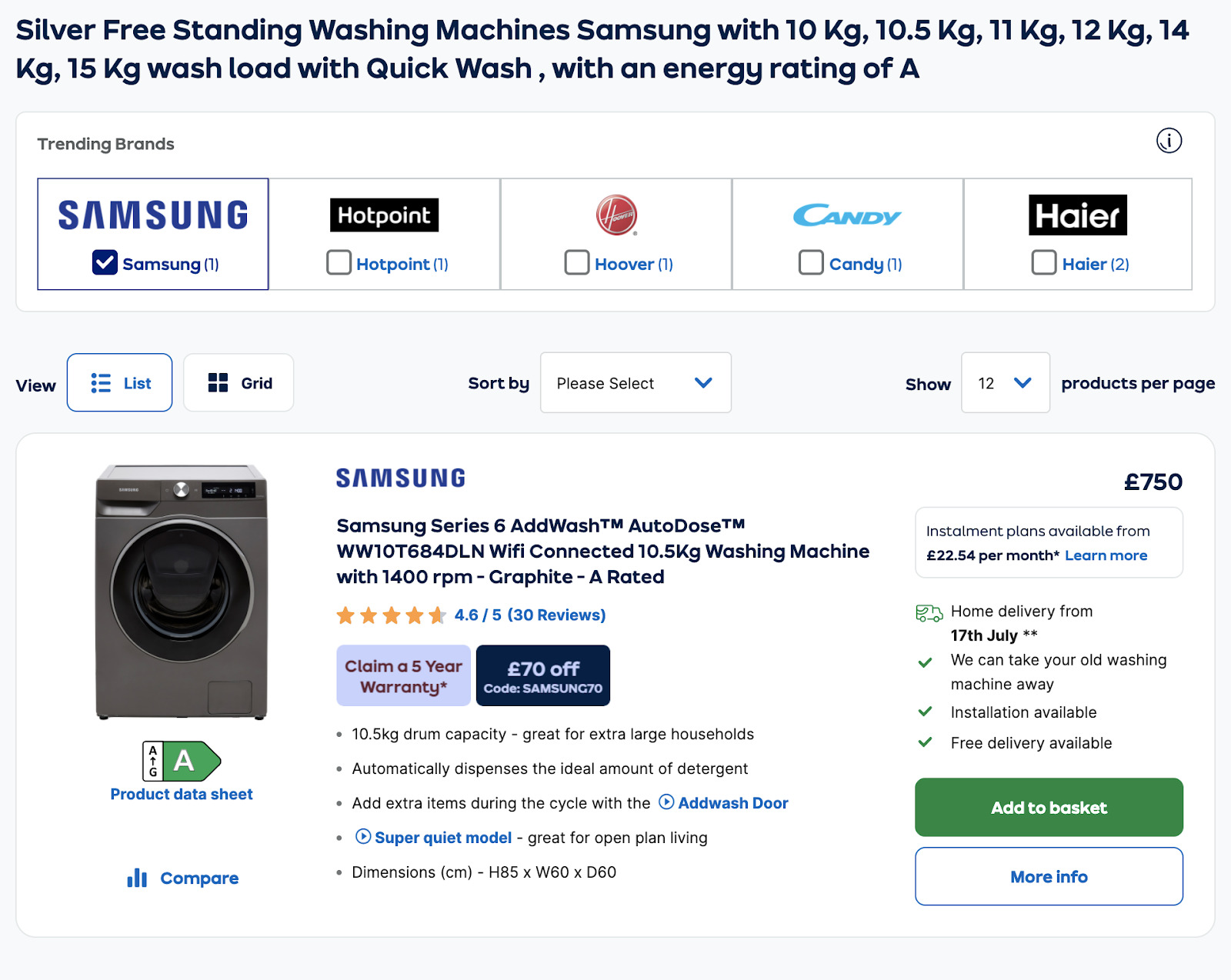
但是,用户会在 Google 中搜索如此精确的内容吗?
答案是否定的。
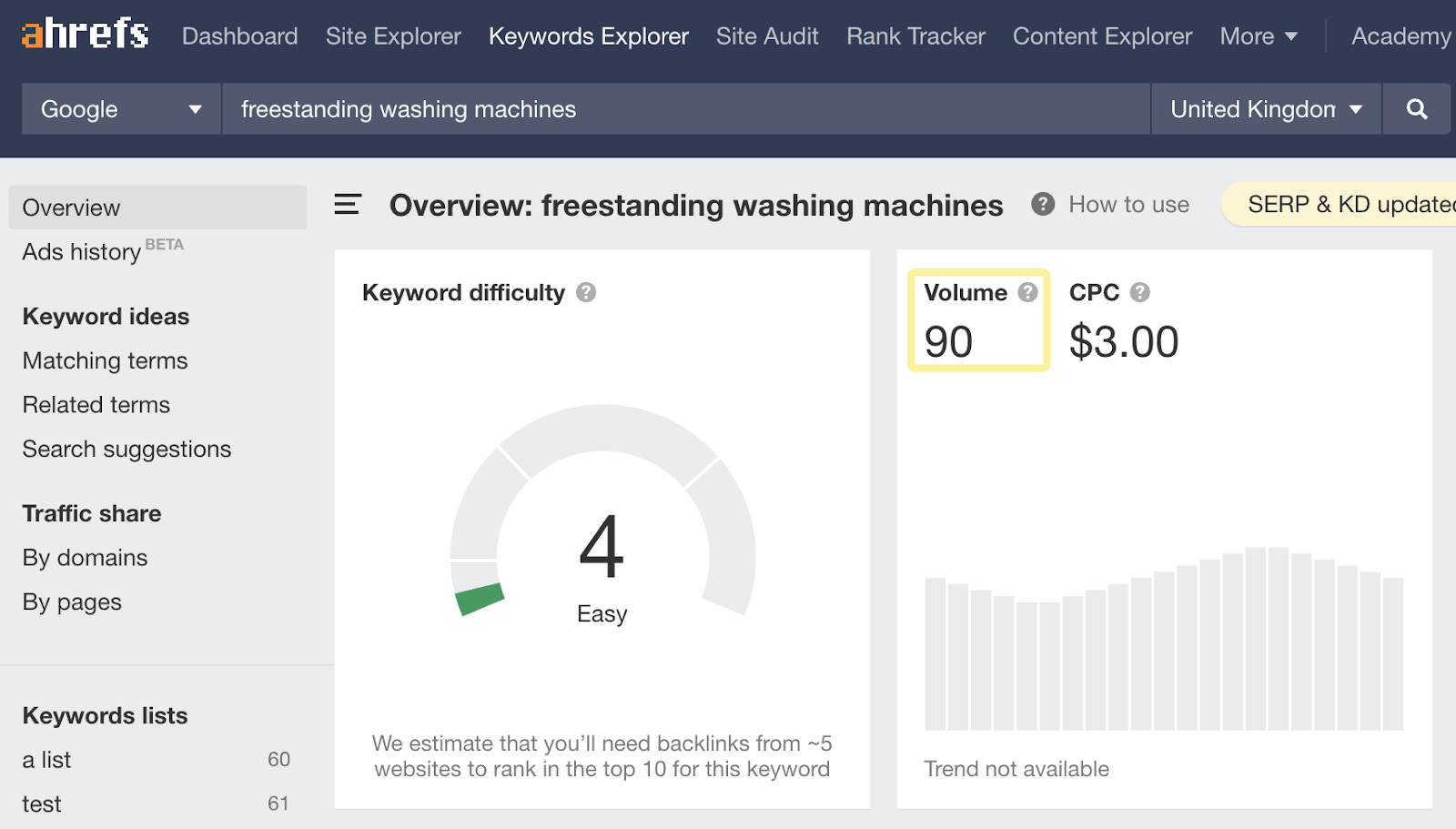
我们知道这一点,因为在英国,估计每月只有 90 次搜索 “freestanding washing machines”,因此极不可能有很多(如果有的话)更具体的搜索,例如 “large silver samsung freestanding washing machine with quick wash feature and energy rating A”。
将此类页面编入索引非但不能满足搜索需求,且质量低下,会使你的网站面临受到算法负面影响的风险。
浪费抓取预算
Google 只能将有限的资源用于抓取你网站上的网页。 这就是你的抓取预算。
除非你拥有内容变化非常快的大型网站(超过 100 万个独立页面)或中型网站(超过 1 万个独立页面),否则 Google 不会优先考虑管理抓取预算。

鉴于该建议,如果你只有几千个类别和产品,你可能认为无需担心抓取预算的问题。
但有可能你想错了。
一些分面导航实现将为每个可用的选项组合创建为一个可抓取的链接。
忽略潜在的索引虚高的问题,这也意味着你可能会生成数百万个 URL 供 Google 抓取,因此你就需要考虑抓取预算的问题。
你可以在 next.co.uk 网站上找到这样的示例:
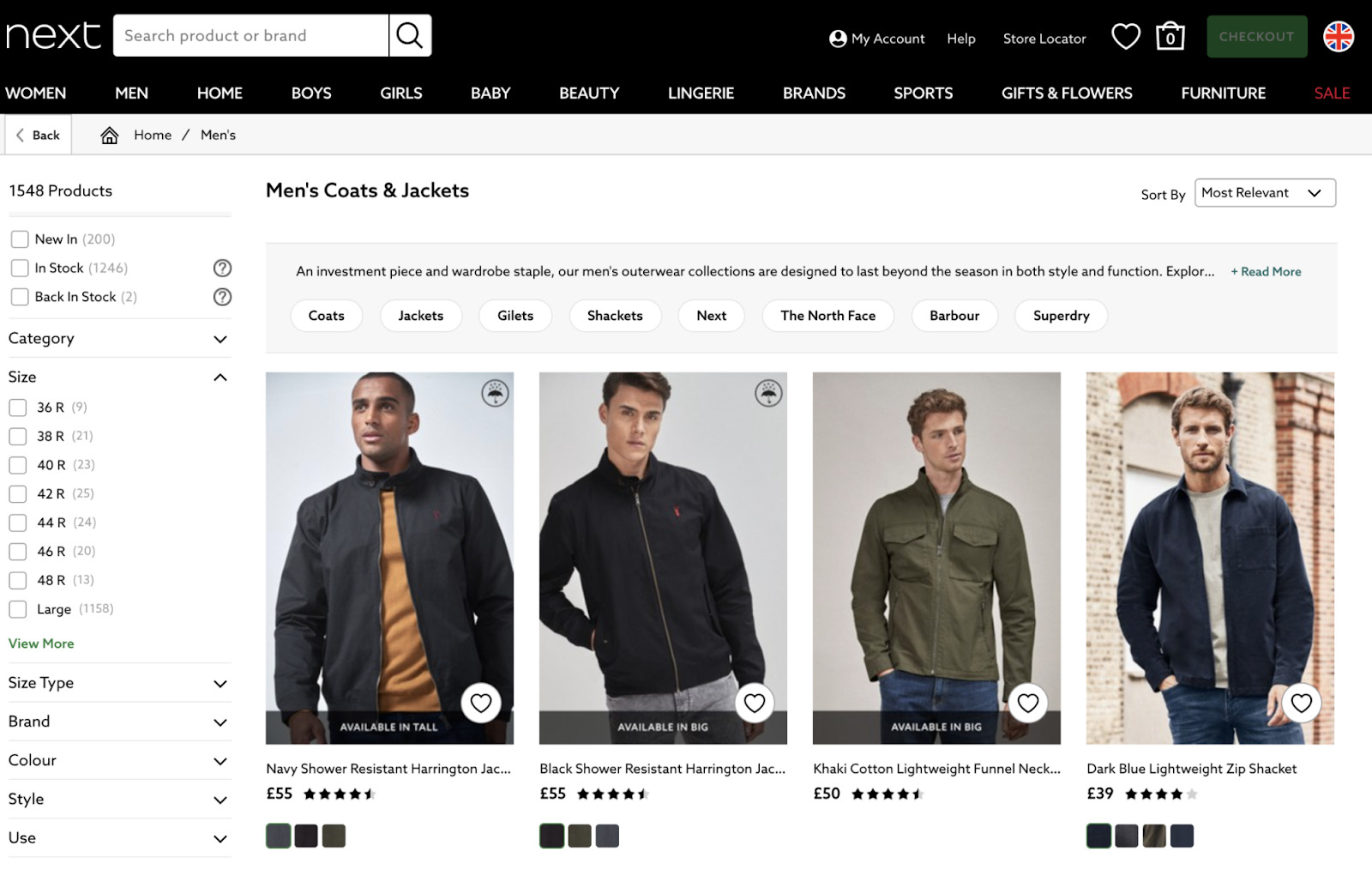
当你检查页面的 HTML 时,你会在 HTML 中看到一个链接:

Once you’ve followed that link, you can then check the HTML of another facet like the blue one:

你可以看到这些选项组合成了一个全新的可抓取的 URL。
现在考虑不同过滤器选项的所有潜在组合。 你就知道为什么有些分面导航会出现抓取问题。
PageRank 的稀释
分面导航还会稀释在你网站上传递的 PageRank。
这是因为 PageRank 均分到页面上的每个链接上。这也是分面导航的固有问题,因为其中生成了大量的内部链接。
因此,PageRank 不会传递到重要的产品或类别页面,而是传递到过滤器中的那些组合链接上,这在大多数情况下是无助于提高搜索流量。
推荐阅读:谷歌 PageRank 没有死:为什么它仍然很重要
分面导航问题表象其实很明显;这里有一些步骤可以发现你的分面导航是否会影响你的 SEO。
1. 从网站搜索开始
快速检查索引虚高迹象的一个很好的策略是使用 site: 搜索运算符。虽然不是最准确的方法,但它快速简便。
你只需要在你的域名之前简单地添加 “site:”,如下所示。
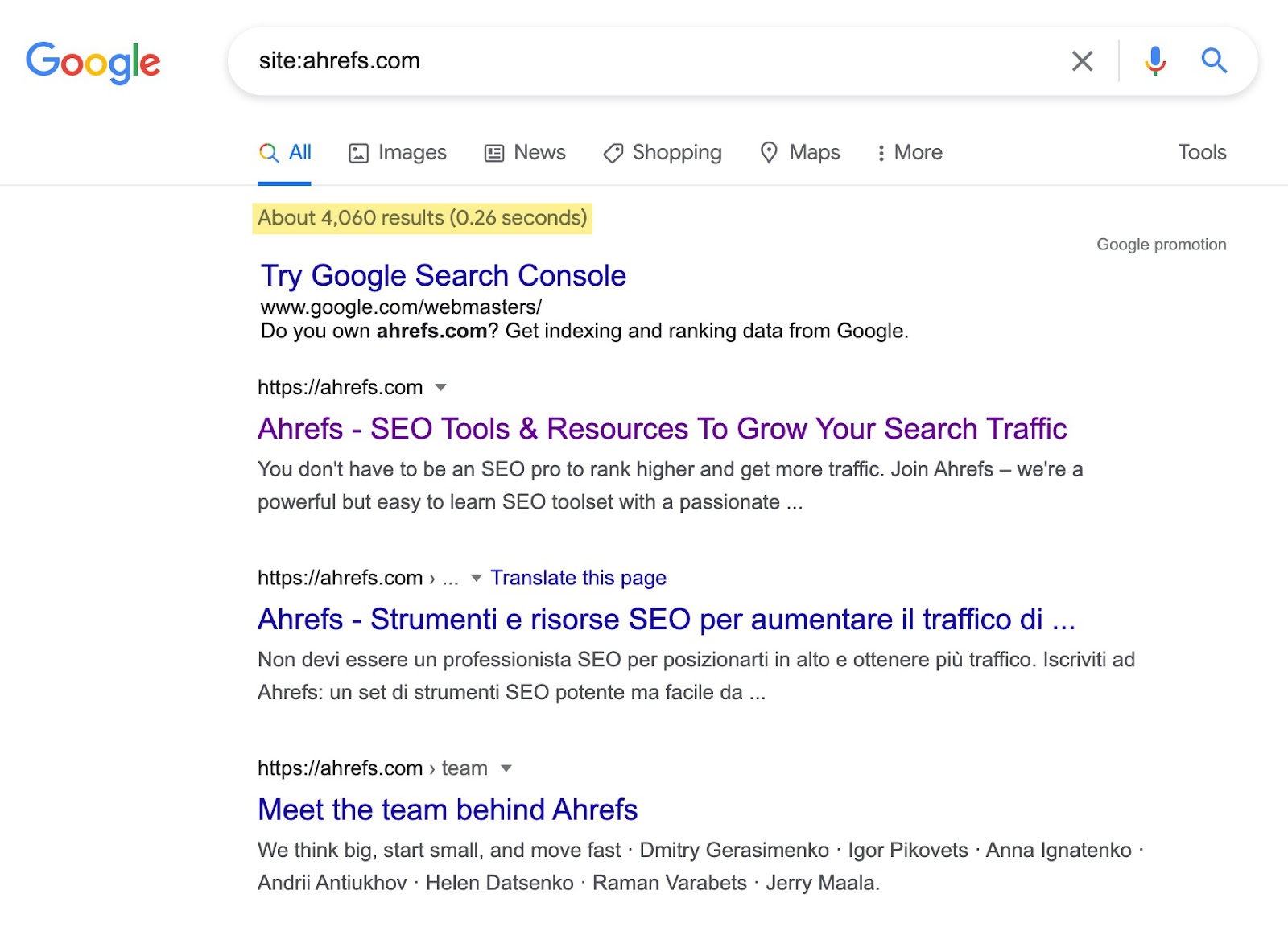
记下 Google 返回的结果数量。思考一下这个数字是否比真实的页面数量多很多?
如果是,那么你有可能会遇到索引虚高的问题。
2. 使用 Google Search Console (GSC) 覆盖率报告进行验证
GSC 的覆盖率报告是另一种快速发现抓取和索引问题的好方法。
只需前往 GSC 中的 “覆盖范围” 报告,然后在图表上选择 “有效”,即可获得更准确的谷歌索引数据:
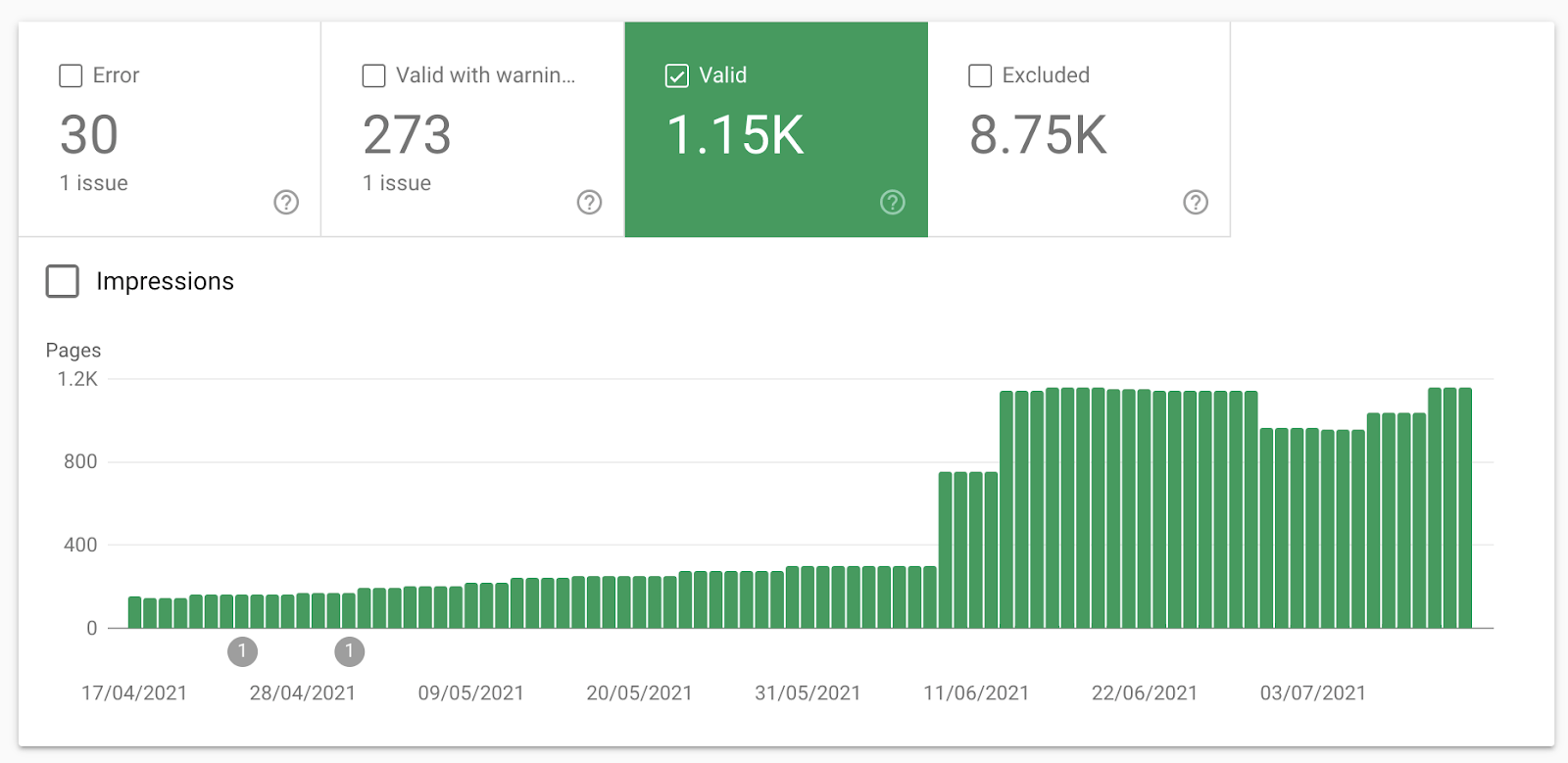
如果这看起来很高,或者你最近实施了分面搜索,又产生了数值飙升,这表你有可能有索引虚高的问题。
但是我们怎么知道是不是过滤器造成的呢?
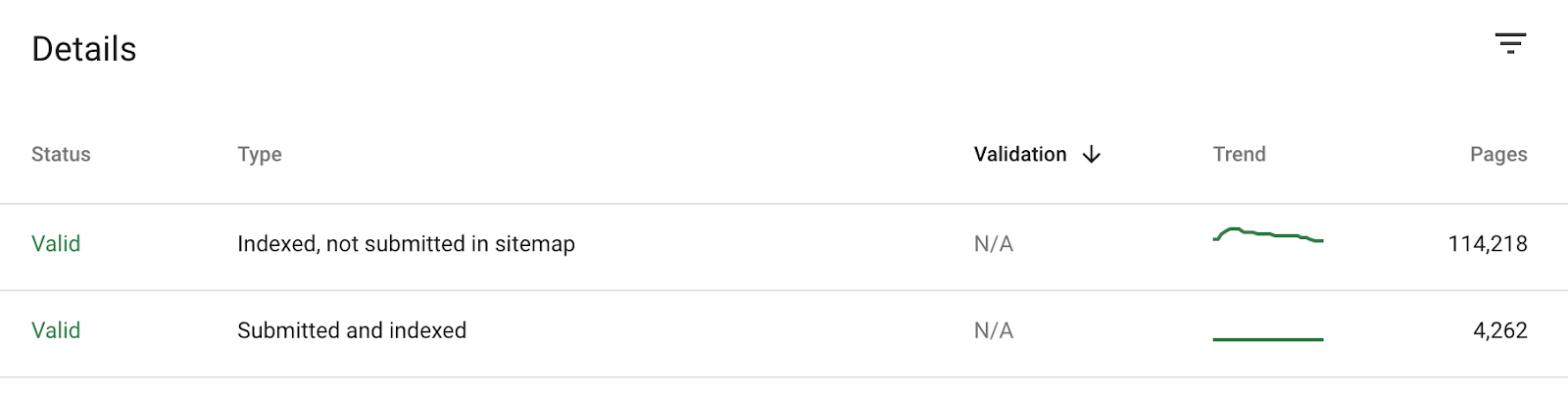
准确的 XML 站点地图有助于诊断此处的问题。如果你已将它们上传到 GSC,则图表下方的表格会将索引 URL 拆分为:
- 已编入索引,未在站点地图中提交
- 已提交,并编入索引
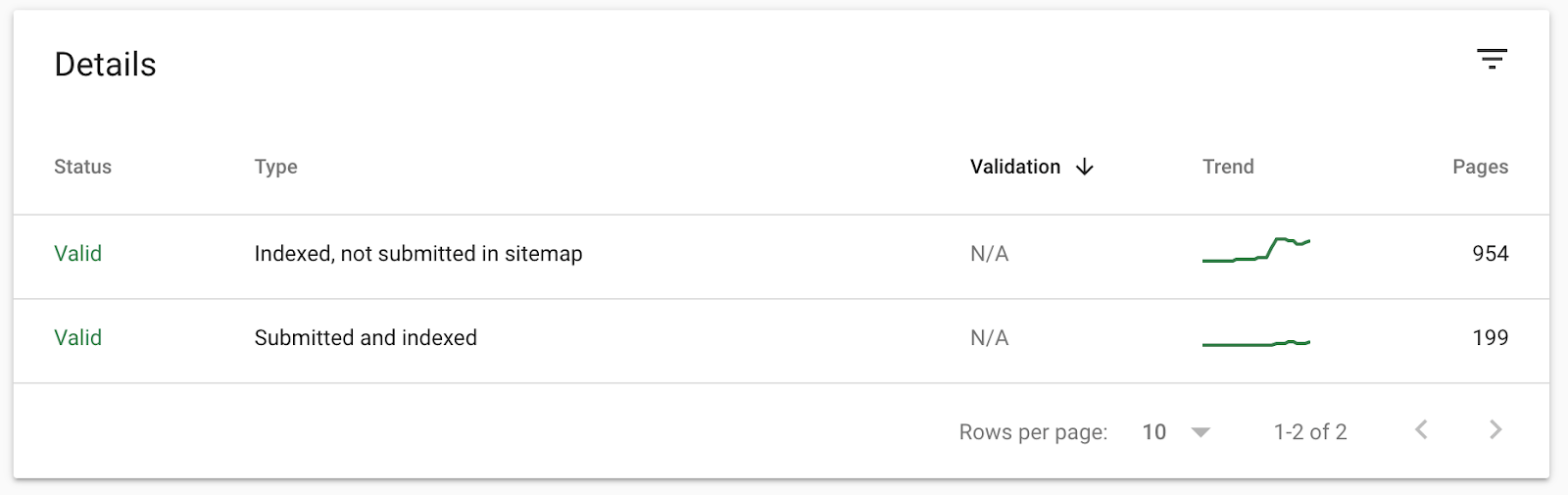
这意味着我们可以查看 “已编入索引,未在站点地图中提交” 中的页面,以查看 Google 正在编入索引的是否是我们不需要的页面:
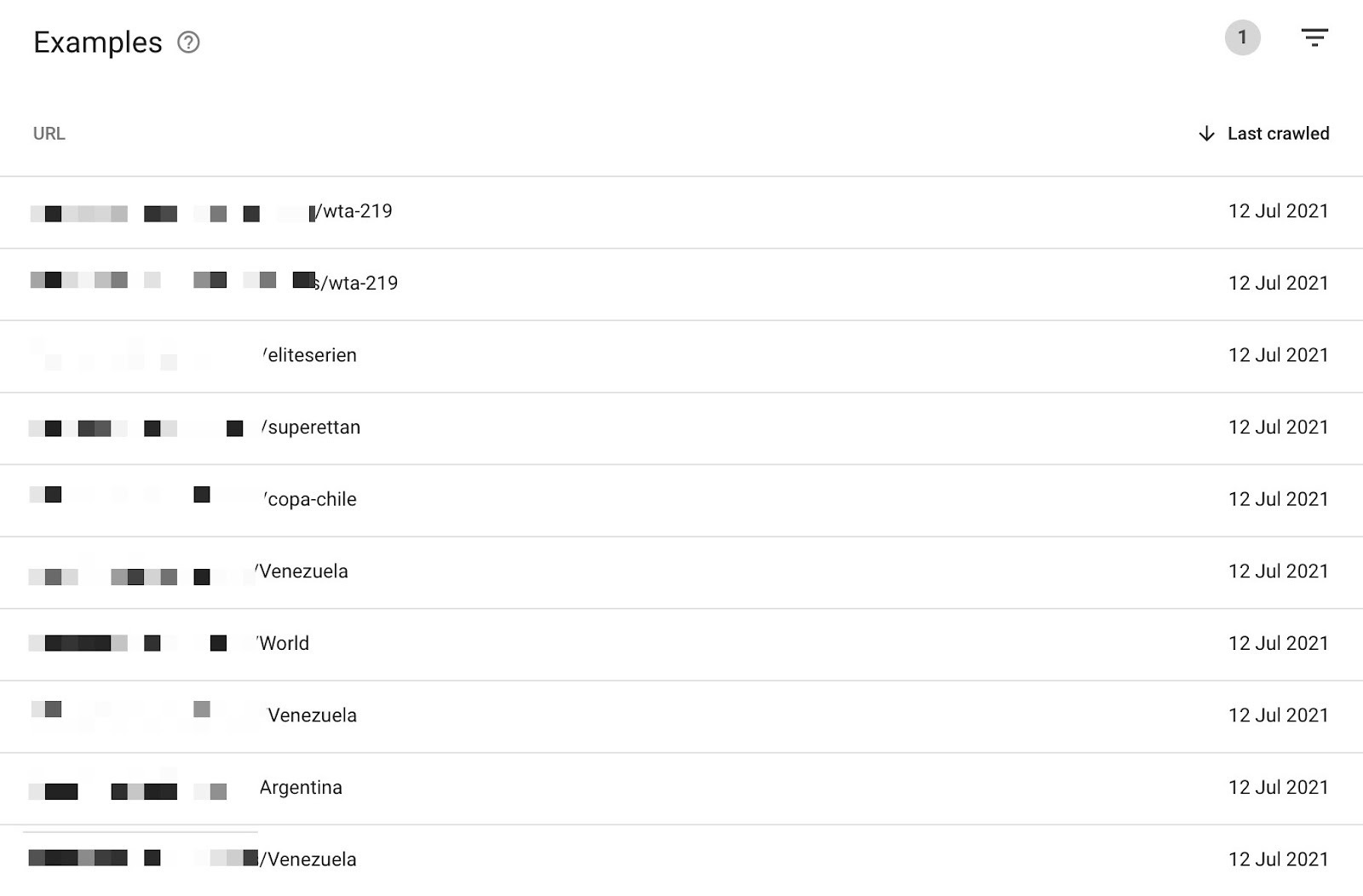
上面是锦标赛的博彩网站示例,有地点和赛事的筛选。我们可以在这里看到 Google 正在将不需要的 URL 编入索引。
发现潜在问题的另一种有用方法是查看 “已排除” 报告:
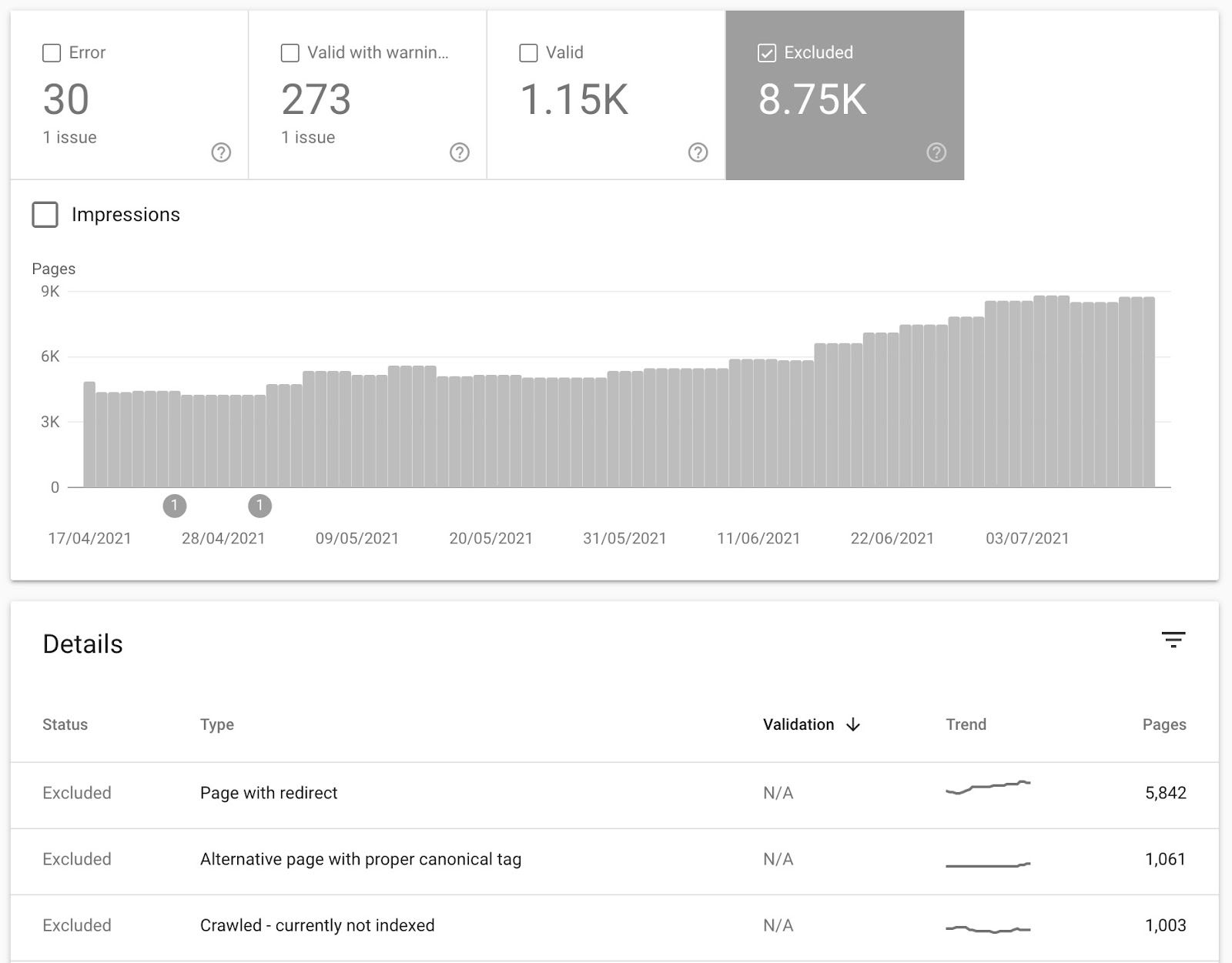
查看 “已抓取 — 当前未编入索引” 的 URL 可以让你深入了解 Google 正在发现但已决定不编入索引的页面。
谷歌不会将他们抓取的所有内容编入索引。如果页面像许多分面页面一样质量低下,他们可能会决定不将其编入索引。
在上面的例子中,我们知道 Google 发现了 1,000 多个额外的页面,它们将来可能会编入索引。你可以通过单击此报告来查看具体的 URL ,查看是否是分面导航的 URL。
上面是 GSC 中显示分面导航问题的一个相对温和的示例。但随着时间的推移,这些问题可能会扩展到数十万个被发现但未编入索引的 URL上(导致潜在的抓取问题):

或者导致成千上万的 URL 在不应该被索引时被索引:
3. 使用网站诊断工具收集更多数据
使用站点搜索,和 GSC 是快速获取问题数据的好方法,但两者都不会显示所有可索引/已索引的 URL,因此很难发现趋势和了解问题的规模。
使用类似 Ahrefs Site Audit(网站诊断) 工具,可以快速抓取你的网站,并及时的向你反馈这些问题。
下面就是一个具有分面导航问题的网站,例如查看抓取预算浪费的问题,你只需点击几下即可发现。
首先进入左侧的 Indexability(可索引性)报告:
接下来,看右侧的 “Indexability distribution(可索引性分布)” 图表,你就会看到是否有异常情况。
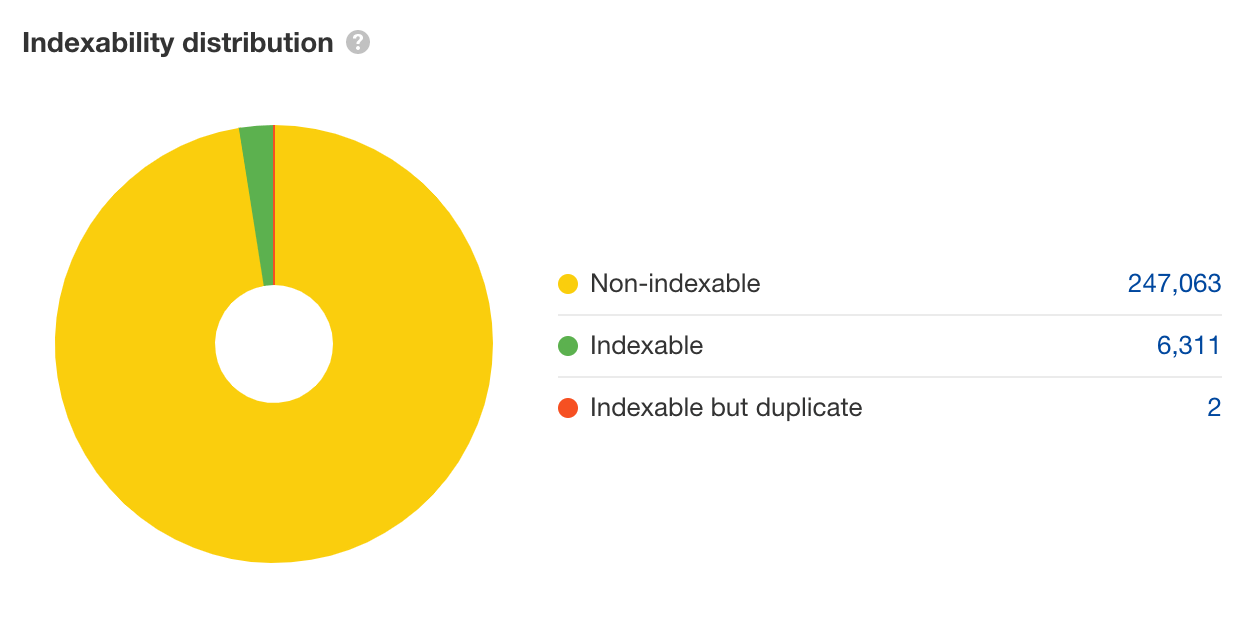
通过部分抓取,Site Audit(网站诊断)发现每索引一个页面,就会多出 39 个不索引的页面。鉴于这不是完整抓取,我们可以预期,随着抓取的继续,可编入索引与不可编入索引的 URL 的比率可能会恶化。
上面的示例有可能会导致大量的抓取预算的浪费,它也是爬虫陷阱的一个典型的示例 — 技术问题导致网站为蜘蛛的抓取的创建了几乎无限数量的 URL。
如果你的分面导航导致索引虚高,你在此处看到的图表看起来会有所不同。你将在图表上看到大量可索引的 URL,而不是大量不可索引的 URL,如下所示。
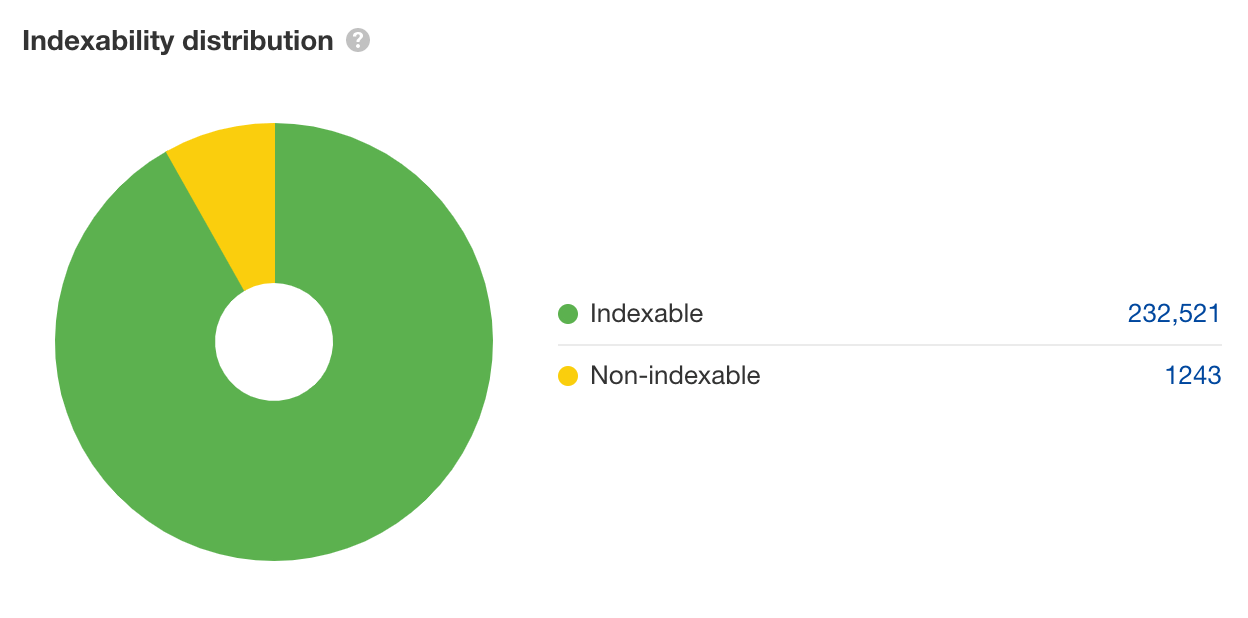
要确认这是否是一个分面导航问题,请选择图表的不可索引部分并查看列表。你会看到一个包含所有已爬取的不可索引页面的表格。
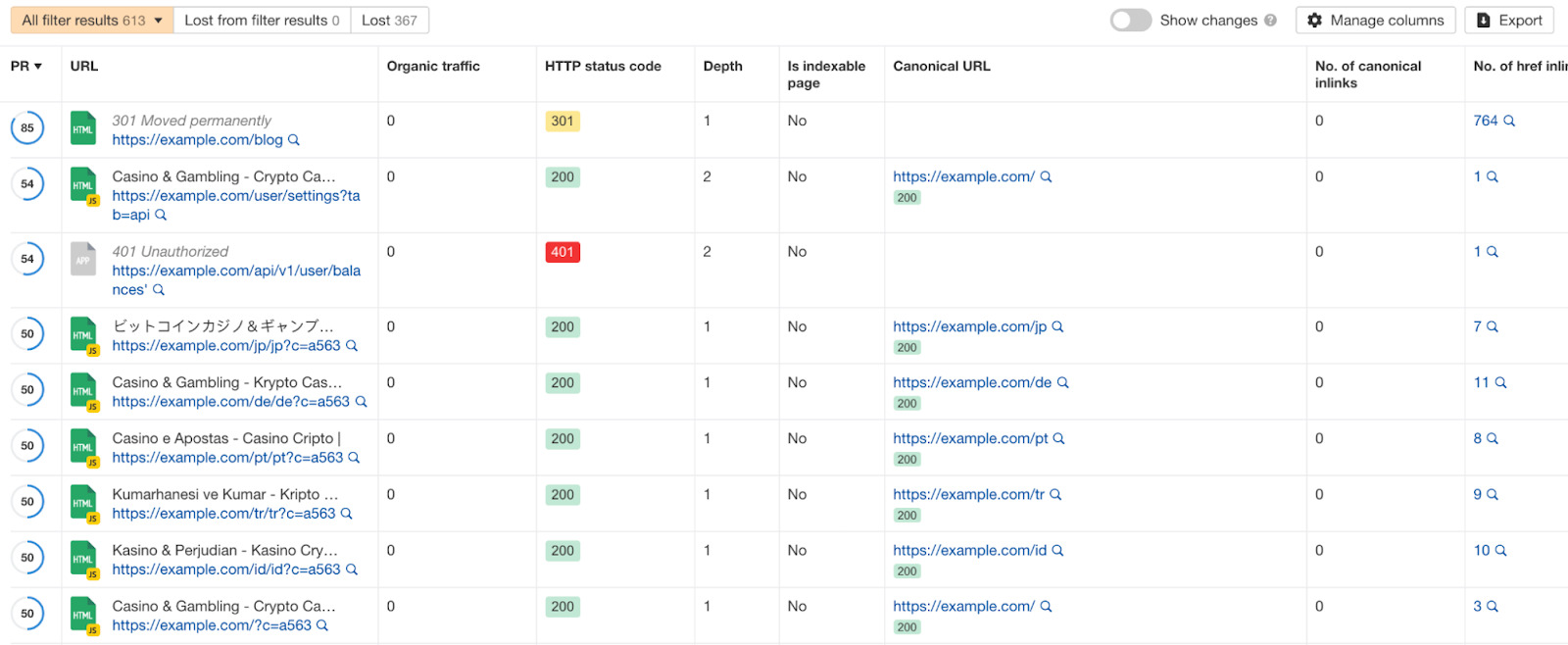
这是你需要寻找规律的地方。
是什么导致爬虫找到所有这些不可索引的页面?
如果表中返回的绝大多数 URL 是分面导航 URL,你就会知道自己存在分面导航问题。
现在你知道如何检查分面导航的潜在问题,下面是修复它们的方法。
1. 使用规范标签修复索引
如果你面临索引问题,但没有令人担忧的抓取预算问题(没有庞大的网站),则最好的解决方案就是使用规范标签。它将 “相似/重复页面” 的链接权重合并到指定为规范的 URL 中。
好处?
如果你有指向分面页面的链接,这些链接权重并不会丢失;搜索引擎会将它们传递到你指定的规范页面上,这也有助于其排名。
下面是一个如何实现这个的示例…
假设这是你的分类页面的 URL:
https://example.com/washing-machines/samsung/
你的分面页面 URL 使用参数,因此当有人应用某些过滤器时,URL 如下所示:
https://example.com/washing-machines/samsung/?drumsize=16kg&color=silver&energyrating=A
在上面的分面 URL 上,你只需添加一个指向类别页面的规范标签,像下方这样:
<link rel="canonical" href="https://example.com/washing-machines/samsung/" />
或者,在你的 HTTP 头中像这样设置:
Link: <https://example.com/washing-machines/samsung/>; rel="canonical"
虽然这对于严重的 SEO 问题似乎是一个很好且简单的解决方案。但依然会存在一些潜在问题,主要问题是 Google 有可能会忽略你的规范标签。
这仅仅是因为规范标签是对搜索引擎的建议,而不是指令。因此,如果 Google 出于某种原因认为你未正确实施标签,他们可能会决定忽略它。
Google 决定忽略你的规范标签建议的常见原因是:
- 页面不是重复的。如果你在应用过滤器时分面页面发生了显着变化,Google 可能会认为它们不是彼此重复的。例如,内容、标题、H 标签发生变化,Google 可能会误判。
- 你在内部链接到分面页面。如果你有许多指向分面页面的内部链接,Google 可能会误解该页面的重要性并忽略你的规范标签。
如果你在实施规范标签后没有看到覆盖率报告中的有效 URL 数量减少,请转到第二步。
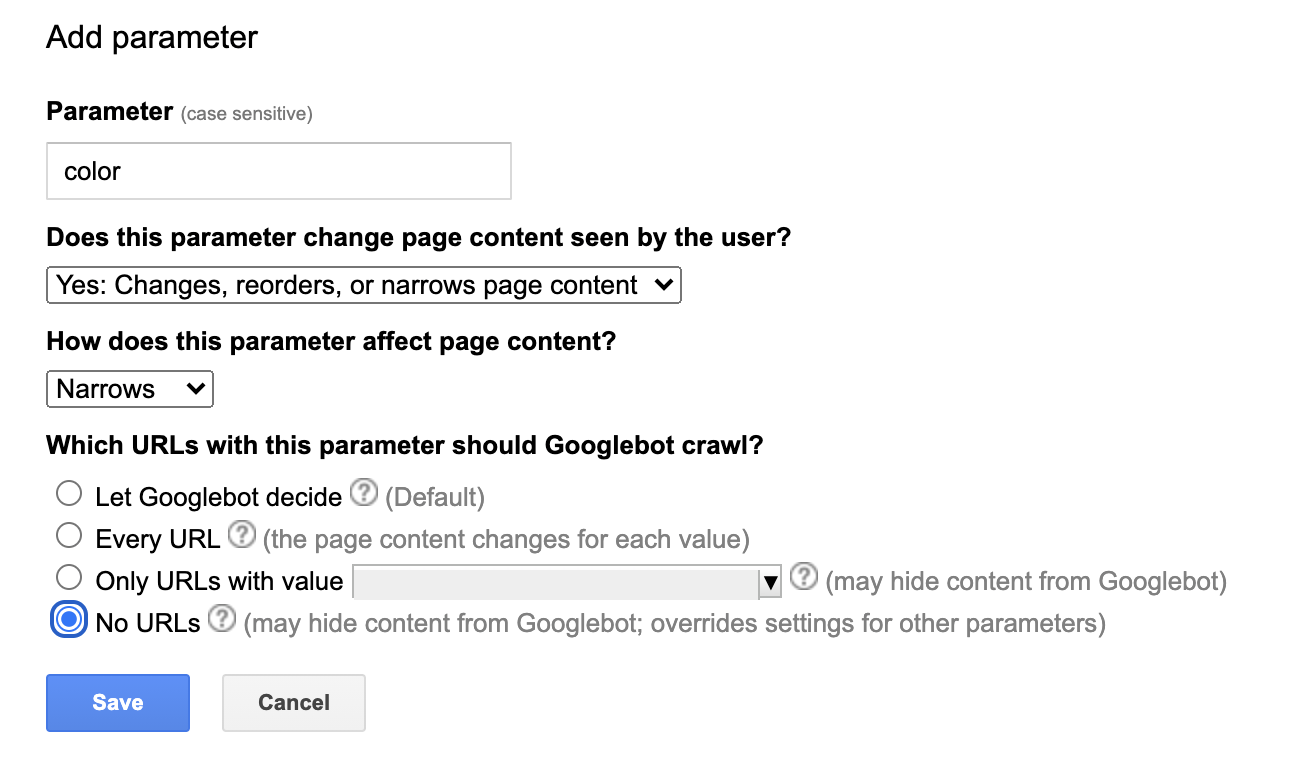
2. 使用 Search Console 中的网址参数报告
如果规范化没有解决索引问题,那么 GSC 中的 URL 参数报告可以说是优化抓取的最佳方式。它可以让你告诉 Google 如何处理你网址中的参数并帮助它们更有效地抓取。
缺点是此方法仅在分面导航使用 URL 参数时才有效。 (如果你不是这种情况,请转到第三步)。
使用 URL 参数报告非常简单。只需添加一个参数,然后告诉谷歌它如何影响页面内容,以及他们应该抓取的规则是否有任何例外。
3. 使用 robots.txt 修复抓取
如果你面临抓取预算问题,并且不需要整合权重,你可以使用 robots.txt 阻止 Google 抓取分面 URL。
要使用 robots.txt 阻止抓取,请添加如下禁止规则:
User-agent: *
Disallow: *size=*
在上面的示例中,我在参数周围添加了两个通配符 (*)。如果你的分面导航是目录的格式,你的规则将如下所示:
User-agent: *
Disallow: */size/*
robots.txt 不能正常工作有两种情况:
- 你 URL 中没有可识别的规律。这可能是因为每个页面都被赋予了独特的参数或分面目录。
- 你希望允许抓取某些模式的 URL 并阻止其他模式。例如,你希望针对 T 恤类别抓取 /color/ 目录(因为它提供了搜索价值),但希望针对内衣类别阻止该目录。虽然你可以通过在 robots.txt 中混合 “允许” 和 “禁止” 规则来解决这个问题,但在大型网站上这很快就会变得难以管理。
你还应该知道,阻止抓取并不一定会阻止 Google 将被阻止的 URL 编入索引。一般来说,谷歌会从索引中删除被阻止的 URL——但前提是它们没有外链或内链指向它们。换句话说,只要没有其他东西向 Google 发出信号,通常是不会被索引的。
4. Nofollow 或删除分面 URL 的内部链接
如果阻止抓取不能完全消除由分面搜索引起的索引问题,则 nofollow 这些链接可能会解决这个问题。
这些链接通常有两个来源:
- 分面搜索链接。即,分面导航中的链接。
- 你网站上其他地方的链接。例如,来自博客文章等。
对于分面导航链接,只需进行一些基本编码即可轻松应用全面的 nofollow。但是,如果你希望 Google 索引分面 URL 和/或分面 URL 上有规范标签,这可能不是最好的主意。因为,如果 Google 最终因为没有跟随这些链接而没有抓取它们,则可能会导致其他索引问题。
另一种方法是挑选出不需要的分面链接,并设置为 nofollow。从技术角度来看,这有点难以实现,但如果你想使用分面搜索来定位长尾查询,这可能是值得的(稍后会详细介绍)。
这种方法的主要缺点是,在 Google 开始将 rel=‘nofollow’ 视为链接信号提示后,它就没那么有用了,这意味着它不像 robots.txt 那样是一个指令。
但是,Google 会将使用 nofollow 链接理解为 URL 不是那么重要,所以 Google 不应该优先抓取它。
John Mueller 也 证实了这一点:
[…] 我们将继续使用这些内部 nofollow 链接作为你告诉我们的信号:
- 这些页面没有那么有趣。
- Google 不需要抓取它们。
- 它们不需要用于排名和索引。

对于你网站上其他地方的链接,最好的办法是删除它们。
你可以通过 Ahrefs Site Explorer(网站分析)找到指向分面页面的内链:
- 输入有问题的分面页面 URL。
- 进入 Internal Backlinks(内部反链)报告
- 筛选 Dofollow 链接
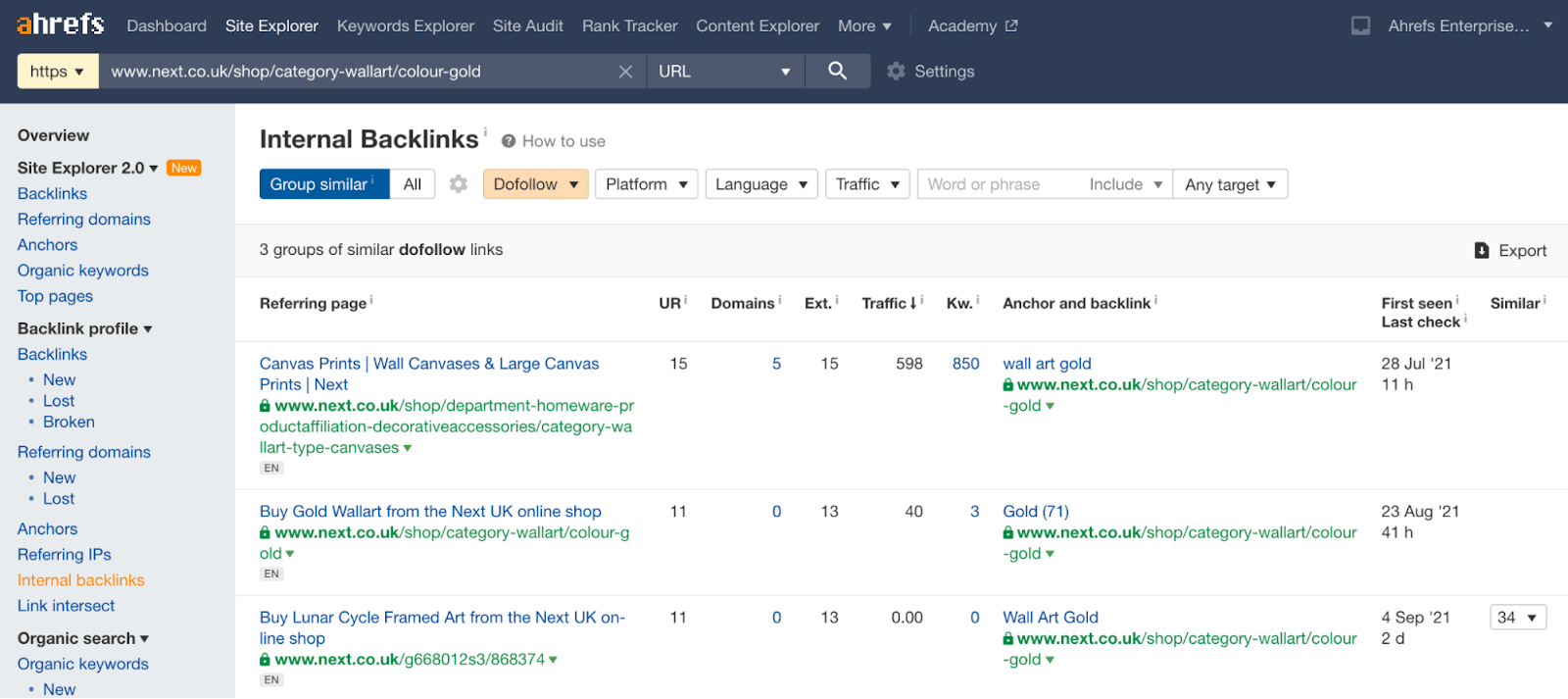
然后,你可以简单地在你网站的其他地方找到 dofollow 的内部链接并将其删除。
5. 使用 noindex 标签彻底修复索引
如果你在执行上述步骤后仍然面临索引问题,那么你的最后一个方法是 noindex 标签。
noindex 标签的好处是它是防止分面页面索引的可靠方法。缺点是你没有整合权重,随着时间的推移,谷歌可能会停止在没有索引的页面上抓取内部链接,这意味着没有权重的传递。
尽管如此,如果所有其他方法都失败了,这是从 Google 索引中排除分面 URL 的好方法。
要实现这一点,只需在分面 URL 的 <head> 中添加一个meat robots 标记:
<meta name="robots" content="noindex">
或者分面 URL 的 HTTP 标头中添加 X‑Robots 标记:
X-Robots-Tag: noindex
然后,你需要在 robots.txt 或 URL 参数工具中删除/调整对应 URL 的指令。如果不这样做,Google 将永远不会看到 noindex 指令——这意味着该页面将保持索引状态。
推荐阅读:Robots Meta Tag 和 X‑Robots-Tag:你需要知道的一切
从上一节中,你会意识到修复分面导航导致的问题并不容易。
修复索引和抓取的每种方法都有一些缺点或复杂性。
但是有更好的方法。
假设你正在实施一个新的分面导航配置、或是准备创建一个。在这种情况下,你可以规避上述所有问题,同时仍能充分利用 UX 优势。
下面是怎么做。
1. 使用 AJAX 并避免内部链接
首先,使用 AJAX 构建分面导航,不要添加任何 <a href=…> 内部链接。
这么做用户会获得很好的体验,因为他们在过滤时不会重新加载页面,而且 Google 不会看到任何指向分面页面的内部链接,这意味着:
- 不会抓取到链接
- 导致 Google 不会将它们编入索引
- 同时还消除了 PageRank 的稀释
下面是一个示例:
我在我的名为 SEO Toolbelt 的网站上使用 WP Grid Builder WordPress 插件实现了分面导航。
它看起来像这样:
当你右键单击并检查任何复选框上的元素以应用过滤器时,你会看到它们不包含 <a href=…> 链接,从而阻止 Google 抓取任何分面的 URL。
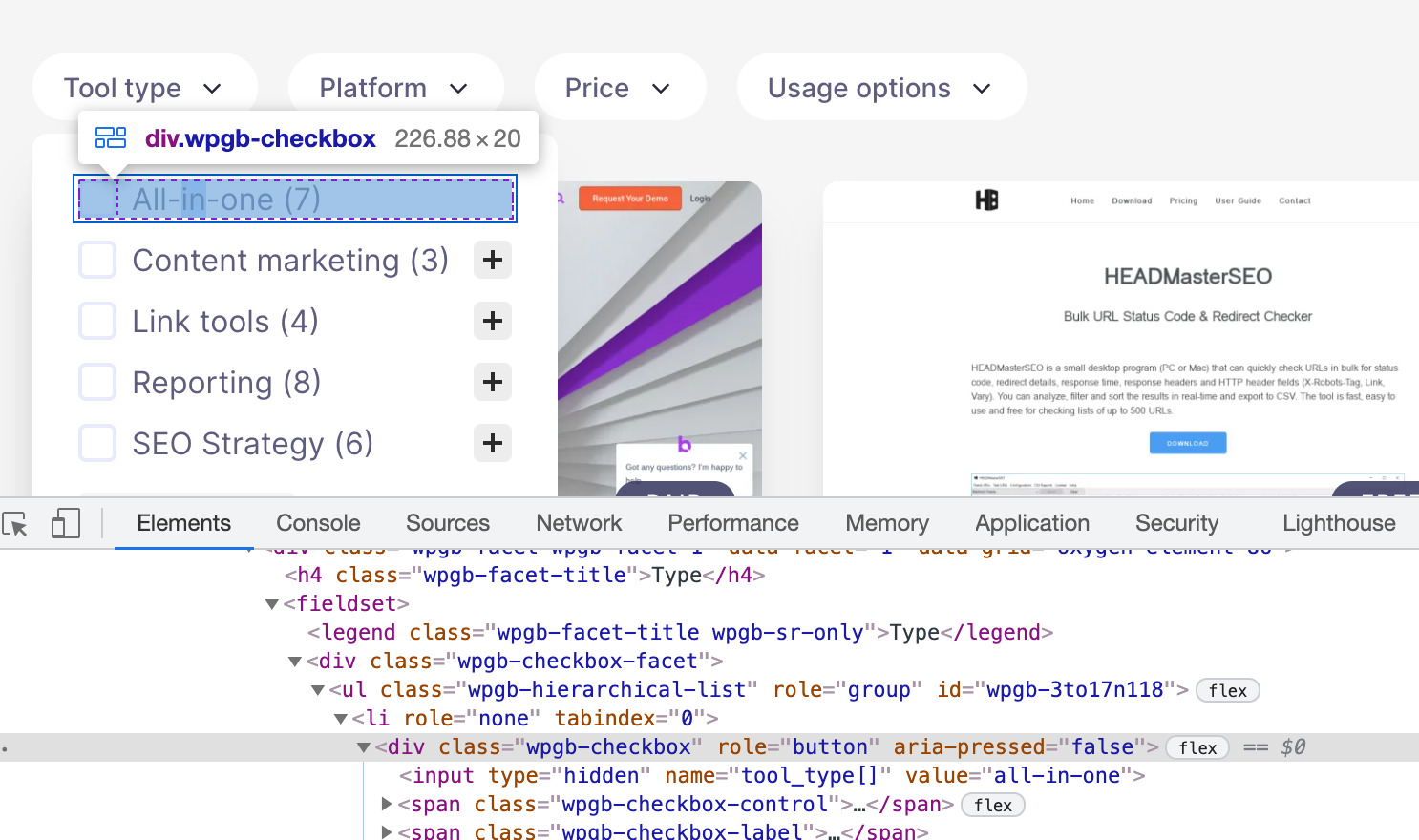
因此,我都不用考虑分面导航造成的抓取预算浪费。
2. 确保 URL 可变
接下来,我们需要确保当用户单击过滤器时,URL 会发生变化。
我建议这样做,因为我们已经实质性地更改了页面的内容,理想情况下,如果用户添加书签、链接到页面或与朋友共享 URL,则 URL 的内容仍将反映对应的分面页面的内容。
有两种方法可以做到这一点:
- URL 参数 (?)
- URL 哈希符号 (#)
最好的解决方案是使用 URL 哈希符号,因为谷歌倾向于忽略 URL 中 “#” 之后的任何内容。
WP Grid Builder 会使用参数,因此应用过滤器后,URL 会如下所示:
https://seotoolbelt.co/tools/auditing/?_tool_type=browser-extension
如果你访问该 URL,你将看到已筛选的后的工具列表。
由于我使用的是 URL 参数,因此我还需要添加不带参数的 URL 规范标签,就是下方这个 URL:
https://seotoolbelt.co/tools/auditing/
鉴于 URL 的这些参数版本没有内部链接,并且不太可能从其他站点接收外部链接(这是 Google 发现它们的唯一方式),所以被 Google 看到的概率很低。
3. 提供重要页面的备用抓取路径以方便用户搜索
在某些情况下,页面的筛选版本可能有助于搜索。
例如,在我的 SEO 浏览器扩展页面上有 “Firefox” 和 “Chrome” 两个过滤器。这两个页面都有一定的搜索潜力。
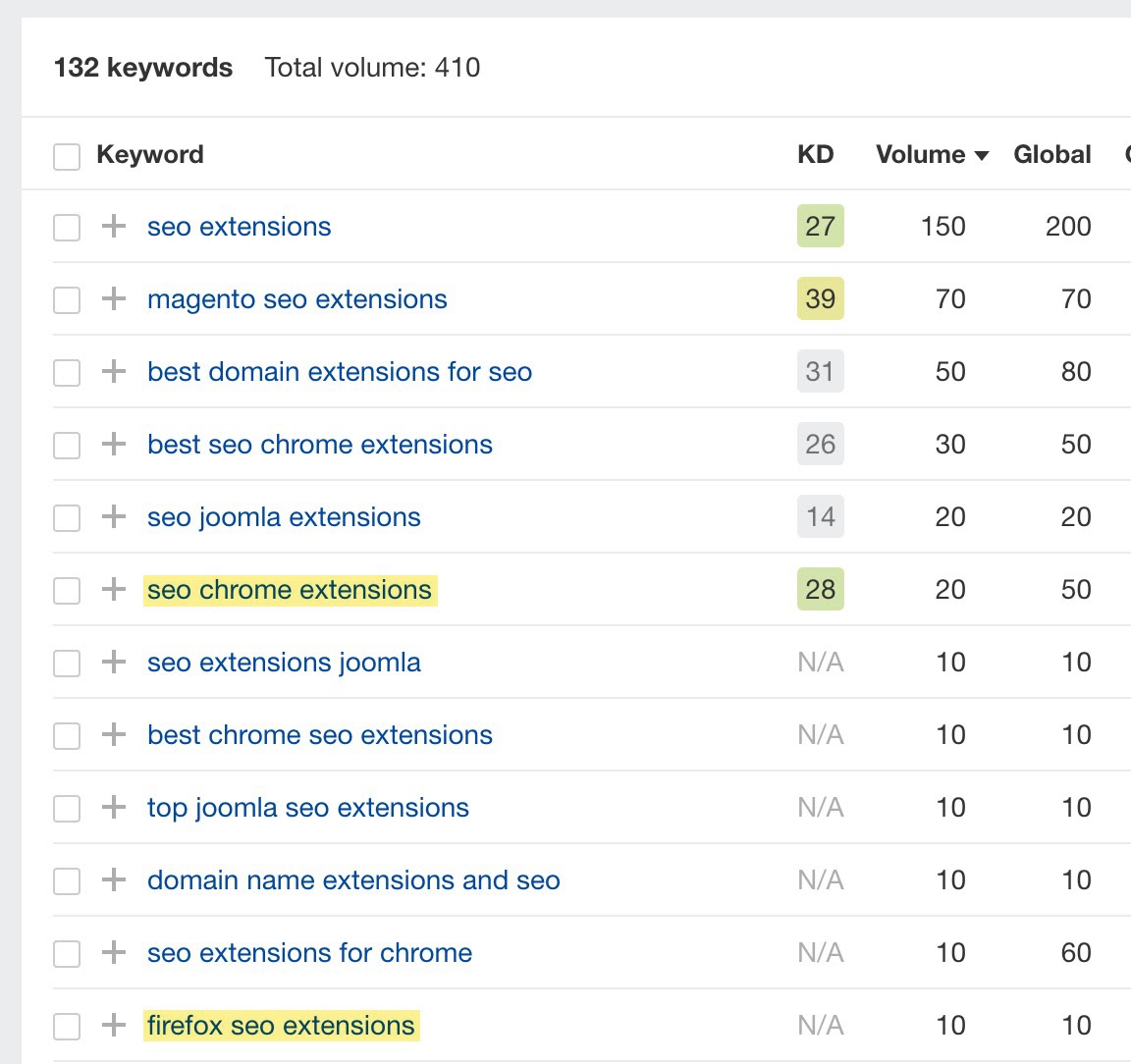
所以我们要确保他们创建了可索引的 URL。最好的方法是确保你有到这些页面的备用抓取路径。我通过在页面顶部添加子导航,并链接到这些页面来做到这一点。

这些页面是基于原有页面不同分面版本生成的,所以我们需要手动的 “植入” 进页面中。
这个这样的植入可以实现以下几点:
- 我已经防止了抓取预算的浪费,因为我的分面页面没有自动进行内链。
- 分面页面 URL 保持了可被分享的属性,利于用户体验。
- 如果分面页面具有搜索潜力,我可以通过手动编辑的方式允许 Google 将此页面编入索引。
如你所见,这在管理 SEO 方面要简单得多,并且没有缺点。
到目前为止,我已经将分面导航定位为只会导致 SEO 复杂化的东西。但是,你也可以将分面导航与长尾关键词策略搭配使用,从而获得更多流量。
不要低估获得这一方案的好处。 Ahrefs 数据显示,99.84% 的关键词每月搜索量低于 1,000,占总搜索需求的 39.33%:
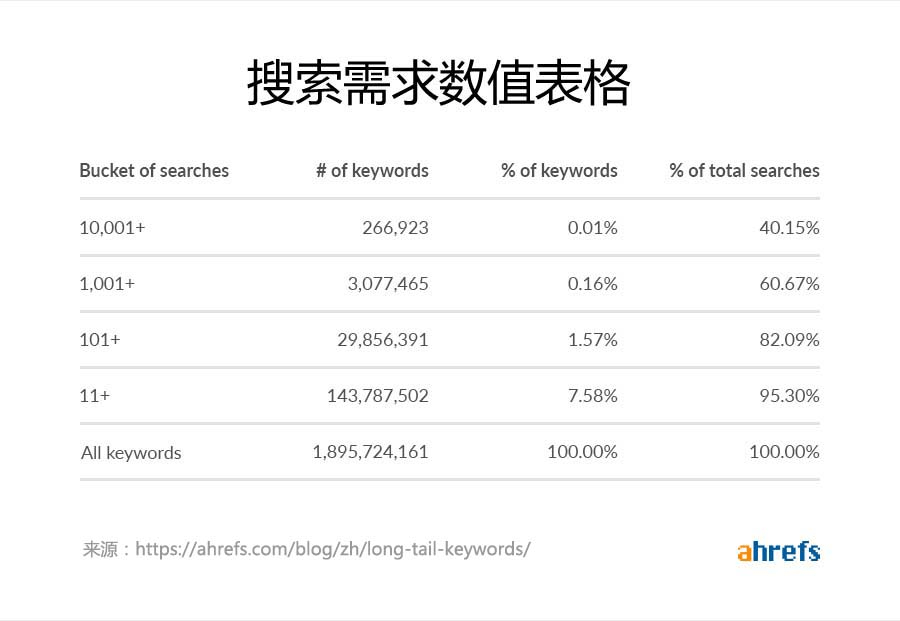
考虑到分面页面可以创建针对精确搜素生程更具体的页面版本,分面 URL 是获取长尾流量的理想选择。
首先,我会引导你完成各个步骤,以发现用分面导航获取更多长尾流量的机会;然后,我将解释一些操作时的注意事项。
1. 识别长尾关键词变体
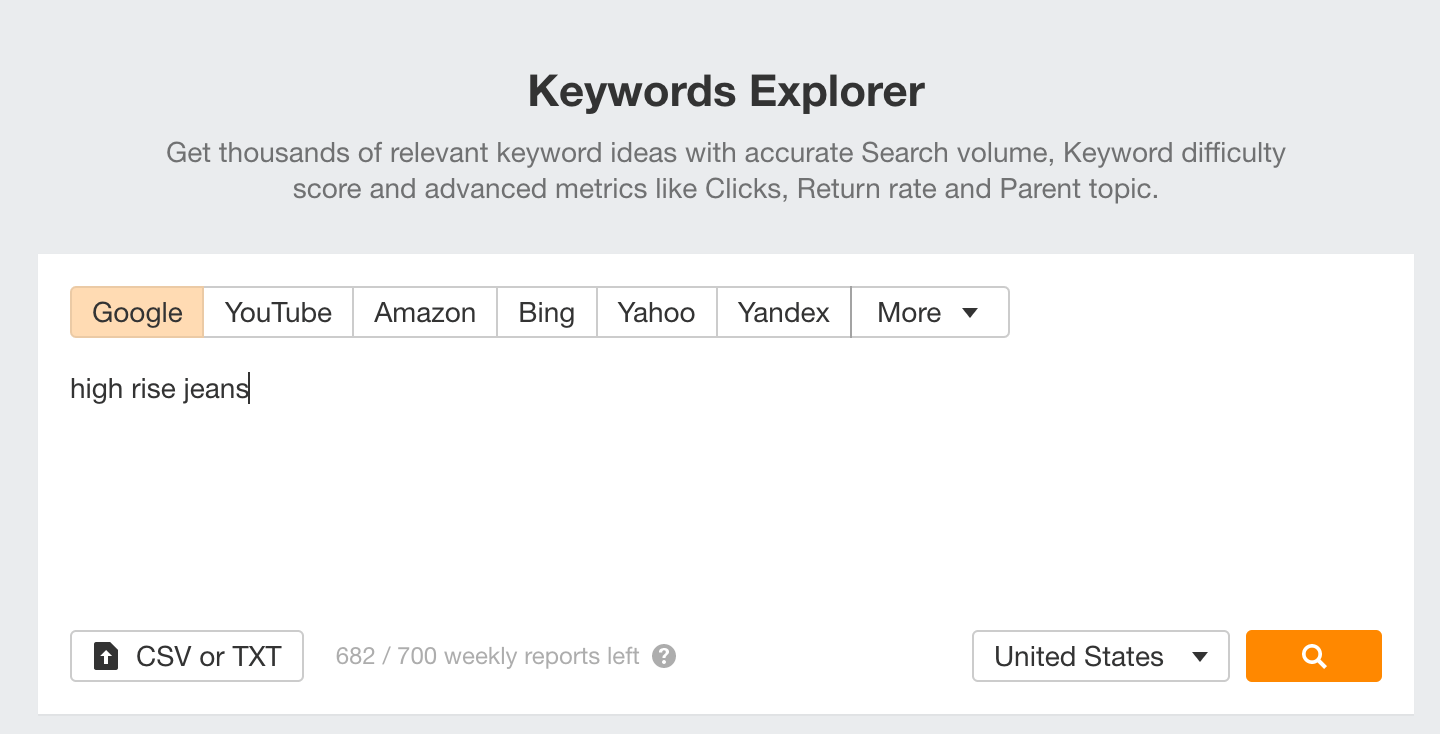
首先,你需要使用 Ahrefs Keyword Explorer(关键词分析)识别关键词机会。做到这一点非常容易。
输入你网站上已有的类别名称,例如 “high rise jeans”。
进入 ‘Matching Terms(词匹配)’ 报告。
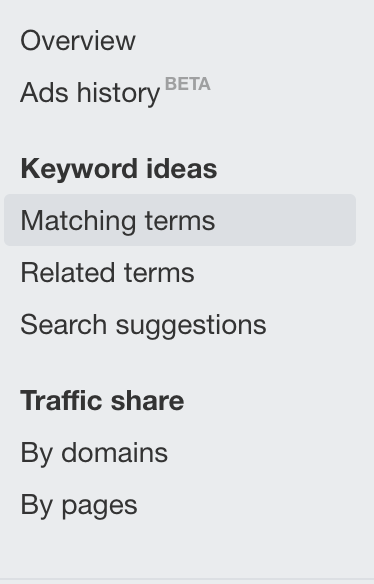
左侧边栏选择 ‘Parent Topics(父话题)’
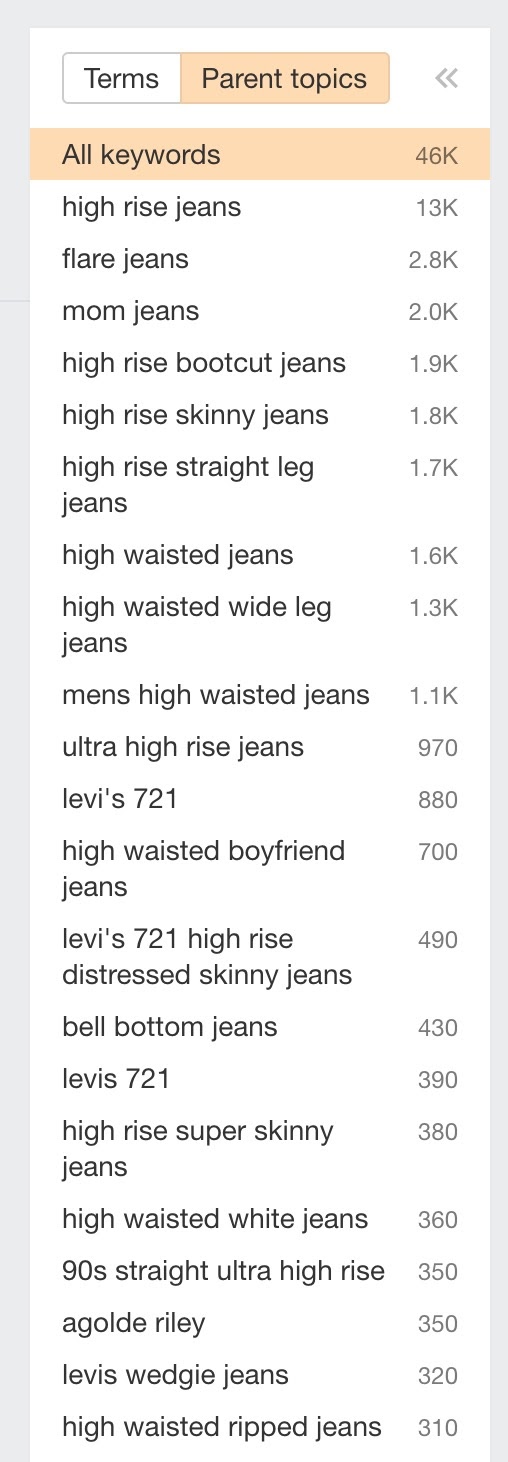
该工具会将具有相似 SERP 的所有关键词组合在一起。然后,你可以查看此列表并挑选出值得编入索引的潜在分面页面。以下是我通过查看上面的屏幕截图发现的一些内容:
- high rise bootcut jeans (1,900 搜索量)
- high rise skinny jeans (1,800 搜索量)
- high rise wide leg jeans (1,300 搜索量)
- ultra high rise jeans (970 搜索量)
- high waisted boyfriend jeans (700 搜索量)
- high rise super skinny jeans (380 搜索量)
- high waisted white jeans (360 搜索量)
2. 让这些页面可被索引
接下来,我们需要使这些页面既可抓取,又可被 Google 索引。
这可以以几种不同的方式来操作,具体取决于你的分面导航类型。
带有内部链接的分面导航
如果你实施的分面导航不是理想的设置,并且确实有指向每个分面的内部链接,那么对于这些 URL,你需要确保:
- 规范标签是自引用的(即引用的是当前页面的 URL)。
- 删除了 noindex 标签(如果可以)。
- 删除 robots.txt 中的所有相关禁止规则(或者你添加了允许规则)
- 删除内部链接上的 nofollow 属性(如果可以)
确切地说,你需要在上面做什么取决于实际情况,重要的是搜索引擎可以对这些页面进行抓取和索引。
没有内部链接的 AJAX 分面导航
你需要为上一节中提到的理想分面导航设置创建一个子类别页面。
你需要这样做,因为分面导航不会自动生成内部链接。
大多数电子商务平台都支持创建子类别。但理想情况下,你需要额外的功能来将子类别产品设置为父类的过滤版本,这主要是为了避免手动去设置每个子类别。通过这种方式,你可以获得像分面导航那样快速生成页面的好处,同时仍能规避 SEO 的复杂性。
例如,如果我们要创建 “high rise skinny jeans” 的子类别,我们希望继承 “high rise jeans” 产品列表,但只显示 “skinny” 属性的产品。
3. 优化网址便于搜素
这是显而易见的,你需要进行基本的 SEO 优化,例如:
- 拥有简单易读的 URL。例如,理想情况下,你的 URL 应该是
/jeans/high-rise/skinny/,而不是/jeans/high-rise/?fit_variant=skinny - 优化标题标签、元描述和 H 标签。
- 独特的内容。
- 将 URL 添加到 XML 站点地图。
这里的配置会复杂一些,毕竟你从默认的索引和抓取配置中单独设置了一个分面页面。
毕竟从技术上讲,分面页面本质上是动态的,与创建新的子类别不同。
重点是,你要知道该自定义功能是用来确保可以用分面页面 URL 进行 SEO 优化的。
最后
希望现在你不仅已经完全了解 SEO 分面导航的固有风险,而且还了解它为优化长尾关键词带来的机会。
译者,Park Cheng,歪猫出海创始人。

