
Il s’agit d’une mécanique d’UX redoutable. C’est aussi, selon Google lui-même, la première cause de problèmes d’over-crawling signalés par les propriétaires de sites. Dans la plupart des cas, ces problèmes auraient pu être évités en suivant quelques bonnes pratiques.
Lesquelles ? Je vais justement vous en parler ici !
L’over-crawling, c’est quand les robots des moteurs de recherche (comme Google) explorent beaucoup trop de pages d’un même site. La grande majorité de ces pages est parfaitement inutile pour eux, ce qui mène à un gros gaspillage de budget de crawl. J’en parle plus en détail ci-dessous.
La recherche à facettes (aussi appelée navigation à facettes) est un système de filtres qu’on trouve sur les pages catégorie de sites avec beaucoup d’éléments à parcourir. Elle aide l’utilisateur à trouver rapidement ce qu’il cherche en croisant plusieurs attributs.
Vous la rencontrez tous les jours sur :
- les sites e-commerce comme Cdiscount, Fnac, Decathlon, La Redoute, Sephora, Veepee…
- les marketplaces comme Vinted, Backmarket, Leboncoin, Amazon, Etsy…
- les sites d’annonces comme Indeed, Welcome to the Jungle, Hellowork, SeLoger…
- les sites de réservation comme Booking, Airbnb, Trainline, Skyscanner…
Les attributs filtrés varient selon le secteur, on peut donc trouver des critères comme :
- le prix,
- la marque,
- la couleur,
- la taille,
- le poids,
- la classe énergie,
- la ville,
- les dates,
- la durée,
- le salaire…
Vous l’aurez compris, on peut quasiment TOUT filtrer avec !
Quand un utilisateur applique le filtre de son choix, plusieurs choses se passent côté technique. Et c’est là que le SEO entre en jeu.
Une fois qu’un filtre est appliqué, il existe 4 comportements possibles :
- La liste se met à jour instantanément, sans rechargement, via du JavaScript
- La page se recharge entièrement et la liste est mise à jour côté serveur
- Rien ne se passe tant que l’utilisateur ne clique pas sur « Appliquer », puis la liste se met à jour en JavaScript
- Une nouvelle page est chargée quand l’utilisateur valide les filtres
L’UX choisie dépend du nombre de filtres que vos utilisateurs ont tendance à empiler. S’ils en cumulent souvent plusieurs, il est plus logique de tout appliquer en une fois après un clic sur un bouton « Valider ».
Une fois les filtres appliqués, l’URL peut évoluer (ou pas). Et c’est là que tout se joue pour le SEO ! Là encore, il y a 4 cas possibles :
- L’URL ne change pas du tout. La liste se met à jour, mais l’URL reste celle de la catégorie parente.
- Le site ajoute un paramètre à l’URL : ?couleur=bleu&marque=samsung
- Le site ajoute un fragment (hash) à l’URL : #couleur=bleu. Attention car Google ignore généralement tout ce qui suit le #.
- Une nouvelle URL statique est créée : /jeans/bleu/slim/
Quand vous mettez en place la recherche à facettes, vous pouvez rencontrer 4 types de problèmes : le contenu dupliqué, un gonflement de l’index, un gaspillage du budget de crawl et une dilution du PageRank. On regarde ça en détail.
Contenu dupliqué
Une page filtrée est, le plus souvent, une copie très proche de la page non filtrée. Elle contient les mêmes blocs de contenu en bas, le même bandeau de catégorie, les mêmes éléments de navigation… Concrètement, seule la liste qu’elle affiche va changer.
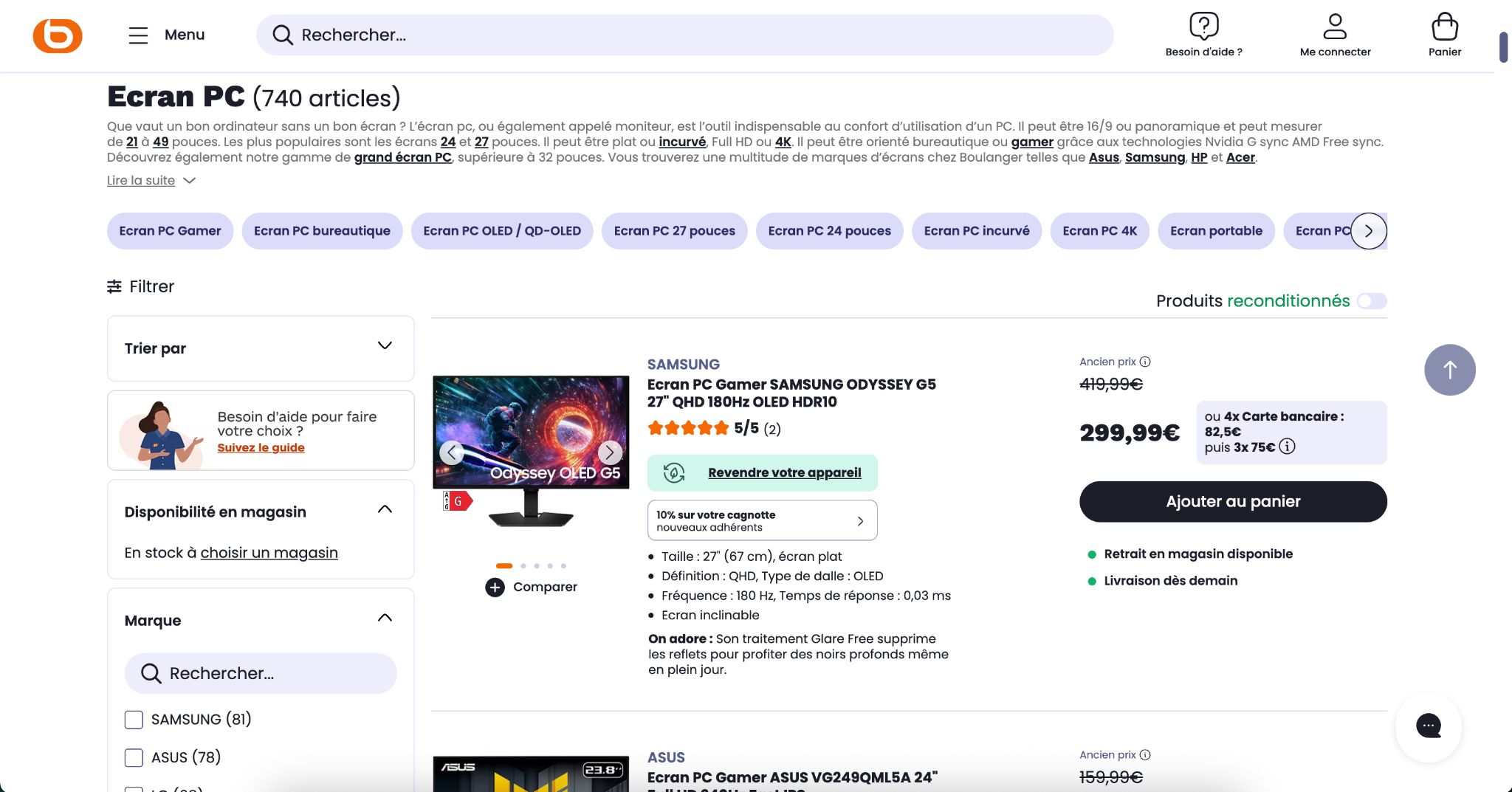
Je vais prendre l’exemple d’une grande enseigne d’électroménager française qui ne vous est peut-être pas inconnue. Sur sa page dédiée aux « Écrans PC », vous verrez une liste de produits et un texte SEO juste en-dessous de la balise H1.
Quand l’utilisateur va appliquer le filtre de son choix, par exemple ici « Samsung » (pour uniquement avoir les écrans PC Samsung), la liste va changer.
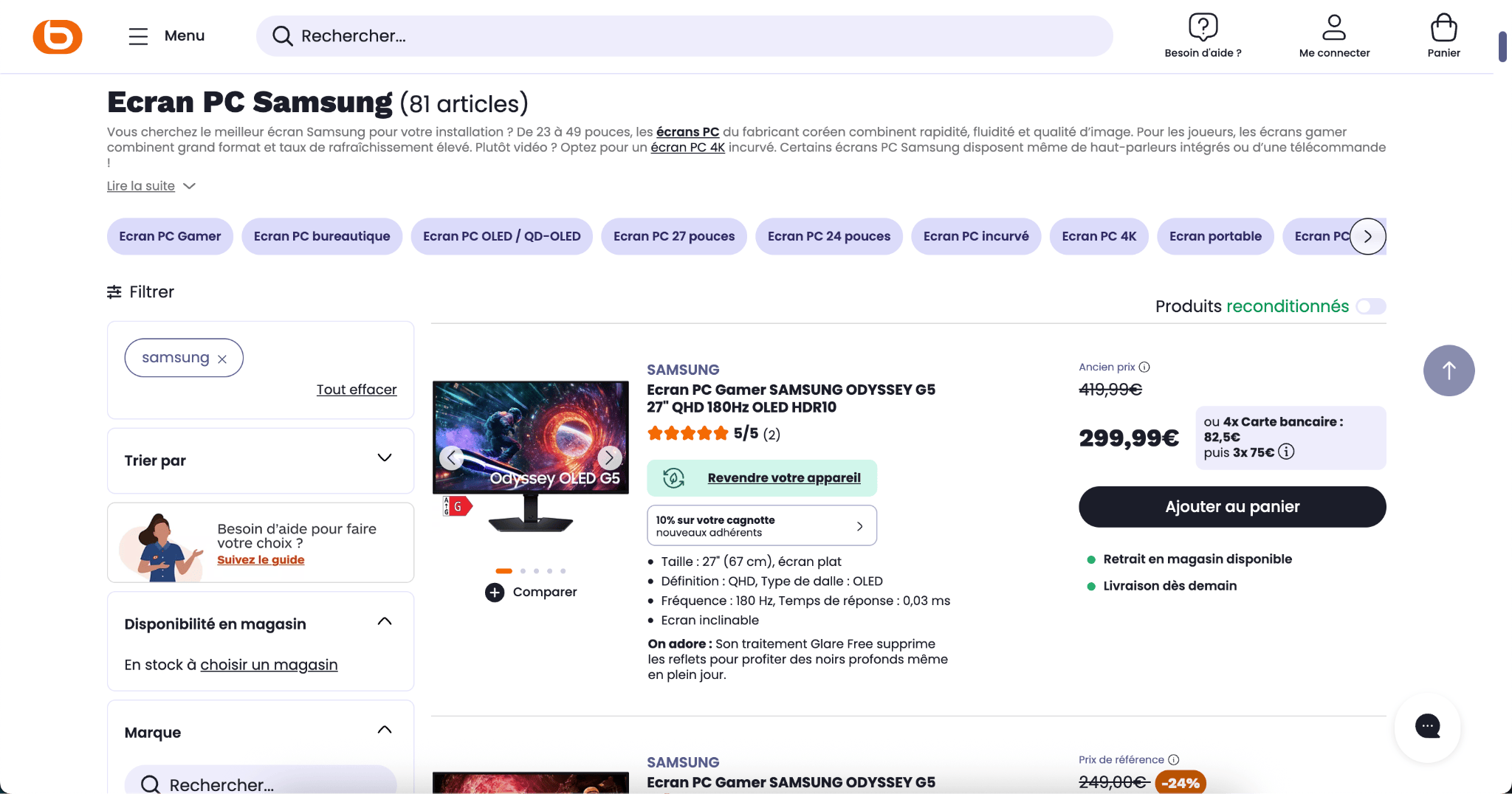
Tout de suite, on remarque aussi que le H1 ET le texte SEO ont changé. C’est super !
Cependant, ce n’est pas le cas de toutes les marques. Parfois, le H1 peut se mettre à jour tandis que le bloc de texte SEO reste le même. On se retrouve alors face à une forme de duplicate content. Démultipliez ça par tous les filtres possibles et vous obtenez des milliers de pages dupliquées que Google doit consolider.
Le contenu dupliqué (duplicate content) n’est pas un facteur de classement négatif en soi, mais il peut provoquer une cannibalisation de mots-clés et une dilution des signaux de ranking entre plusieurs URL (au lieu de consolider une même page).
Gonflement de l’index (index bloat)
Le gonflement de l’index, c’est quand Google indexe des pages de votre site qui n’ont aucune valeur de recherche. C’est exactement ce que produit une navigation à facettes mal cadrée.
Je vais prendre un autre exemple avec un grand distributeur français qui propose des lave-linges. Sur son site, on peut les filtrer par marque, capacité, couleur, fonctionnalité et classe énergie. Ce qui fait qu’un utilisateur peut arriver depuis Google sur « Lave-linge Samsung grande capacité métallique avec lavage rapide classe A ».
Oui, techniquement, cette page existe. Mais combien de Français tapent vraiment cette requête dans Google ? En jetant un coup d’œil via un outil comme Keywords Explorer d’Ahrefs, vous verrez que dans 99 % des cas, le volume est de 0.
Avoir des milliers de pages comme celle-ci, c’est-à-dire des pages qui ont été indexées sans demande de recherche, c’est ce que Google appelle l’index bloat. Ce phénomène peut avoir des conséquences négatives sur la perception de votre site.
Gaspillage de budget de crawl
Pour explorer votre site, Google ne consacre qu’une quantité précise de ressources. C’est le budget de crawl.
Si vous gérez « seulement » quelques centaines de produits, vous vous dites sûrement que ce sujet ne vous concerne pas. Erreur ! En effet, certaines recherches à facettes créent un lien explorable pour chaque combinaison possible. Vous pouvez donc très vite passer de quelques centaines à des milliers, voire des millions d’URL.
Concrètement, Google envoie son crawler explorer toutes ces variantes. Mais chaque seconde passée sur une page filtrée qui n’a aucune valeur, c’est une seconde qui aurait pu être utilisée sur vos nouvelles fiches produits, sur vos nouvelles catégories, sur vos nouveaux articles de blog… Bref, c’est du temps perdu pour valoriser ce qui compte vraiment pour votre stratégie !
Dilution du PageRank
Le PageRank est un algorithme Google qui mesure la popularité d’une page ou d’un site. Il se mesure principalement en fonction des liens qui pointent vers la page donnée. Plus la quantité et la qualité de ces liens sont élevées, plus le PageRank monte.
Quel rapport avec la recherche à facettes ? Eh bien, c’est très simple : puisque la recherche à facettes génère beaucoup de liens internes, cela va « diluer » le PageRank. Au lieu de concentrer tout le poids sur vos produits et vos catégories, il va aussi prendre en compte des combinaisons de filtres qui, dans la grande majorité des cas, n’ont aucune valeur.
Vous pensez que votre recherche à facettes nuit au SEO ? Voici comment mener l’enquête !
1. Commencez par une recherche site:
Je pense que l’opérateur de recherche site: est un excellent premier réflexe à avoir, en plus d’être très simple à utiliser ! Il va vous aider à voir quelles sont les pages indexées par Google sur votre site. Tapez dans la barre de recherche Google :
site:votredomaine.fr
Vous verrez alors des pages s’afficher. Si vous remarquez que plein de pages renvoient vers des combinaisons de filtres qui n’ont aucune valeur SEO, il est fort probable que vous soyez face à de l’index bloat.
2. Confirmez avec le rapport « Pages » de la Search Console
Allez jeter un coup d’œil à la Google Search Console dans le menu « Indexation » > « Pages ». Le rapport vous montrera :
- les pages indexées (en vert),
- les pages non indexées (en gris).
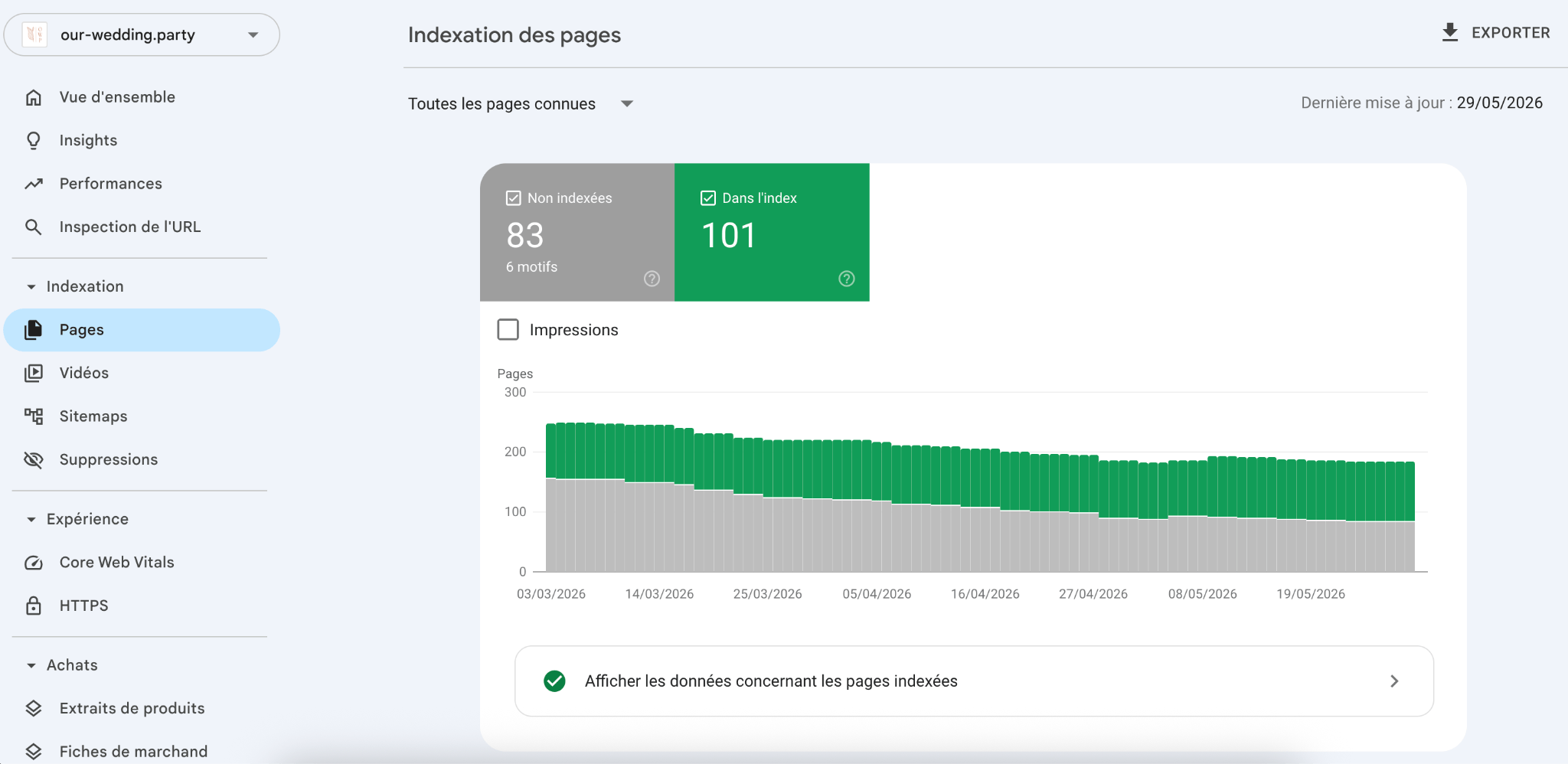
Si le nombre de pages indexées vous semble excessif (ou s’il a subitement explosé avec la mise en ligne d’une recherche à facettes), je pense que cela confirme quasiment l’index bloat !
Mais comment s’en assurer à 100 % ? En allant vérifier votre sitemap.
- Si des URL sont indexées MAIS ne sont pas sur le sitemap : il est fort probable que ce soit des URL créées via la recherche à facettes (et dont vous ne voulez pas !).
- Si des URL sont indexées ET sur le sitemap : rien à signaler.
Pour comprendre pourquoi certaines de vos pages sont non indexées, je vous recommande vivement d’aller voir quels sont les motifs récurrents. Une page peut être :
- « Explorée, actuellement non indexée » : Google a découvert l’URL mais a décidé de ne pas l’indexer (souvent un signal de basse qualité).
- « Détectée, actuellement non indexée » : Google connaît l’existence de l’URL mais ne l’a pas encore explorée (souvent un problème de budget de crawl).
- « Bloquée par le fichier robots.txt » : votre robots.txt bloque cette URL (ce qui peut être voulu mais peut aussi cacher une erreur !).
Là encore, vous pourrez dénicher des URL générées par la recherche à facettes. Je trouve ça vraiment intéressant d’aussi creuser dans ce sens, cela permet de bien comprendre comment Google perçoit votre site !
3. Obtenez plus de données avec un audit de site
Même si la GSC est très rapide et pratique, elle a aussi ses limites. Pour avoir une vraie cartographie de votre site, je vous conseille d’utiliser Site Audit d’Ahrefs. Cet outil vous donnera une vue complète des URL découvertes lors du crawl.
Pour repérer un problème de facettes en quelques clics :
- Lancez un crawl complet de votre site
- Allez dans le rapport Indexability dans la barre de gauche
- Regardez le ratio entre URL indexables et non indexables
Si votre site est bien construit, vous devriez apercevoir un bon ratio entre ce qui est indexable et ce qui ne l’est pas (à peu près 50/50 si vous avez un gros site). Mais si votre site a des problèmes avec sa recherche à facettes, deux cas de figures peuvent se présenter.
1er cas de figure : vous avez énormément d’URL non indexables, c’est-à-dire 30, 40 ou 50x plus que vos URL indexables.
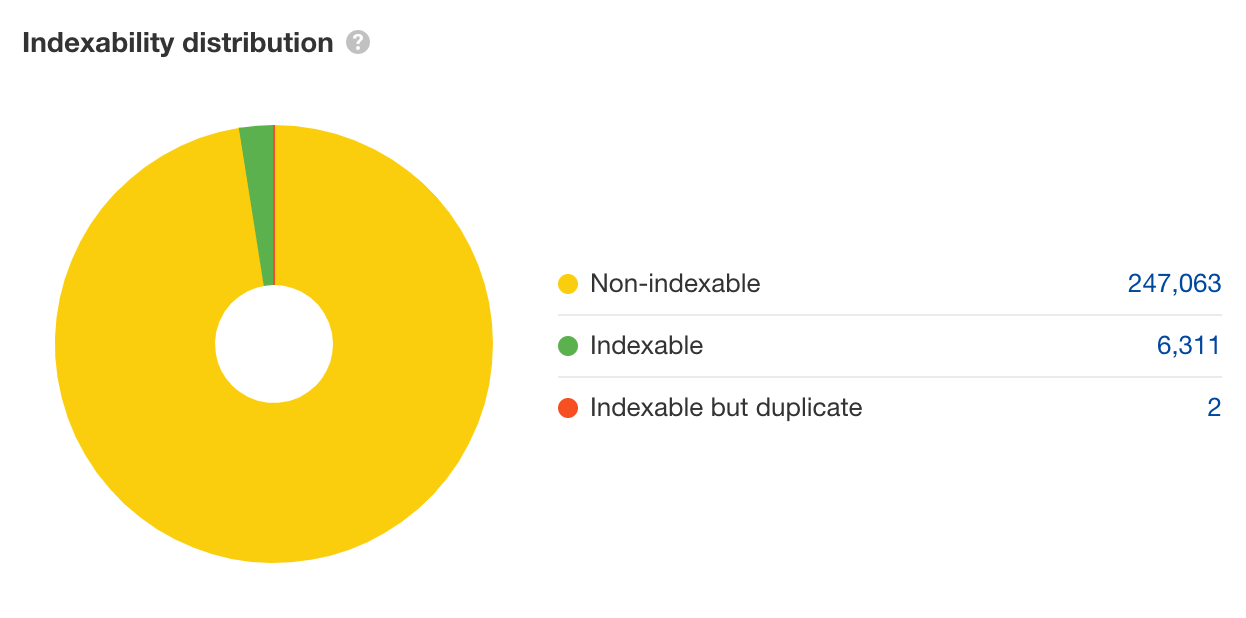
Ici, on remarque tout de suite un immense gâchis du budget de crawl. Les URL vont se démultiplier et les bots vont les explorer inutilement.
2e cas de figure : vous avez énormément de pages indiquées comme indexables et très peu de pages non indexables.

Là, on est plutôt sur de l’index bloat. Le site pris en exemple a-t-il vraiment besoin de ses quelque 232 521 URL ? Sont-elles toutes importantes et optimisées pour le SEO ? … Il y a de fortes chances pour que ce ne soit pas le cas.
Pour confirmer si la recherche à facettes est vraiment derrière tout ça, cliquez sur le jaune du graphique (non indexable) et jetez un coup d’œil au tableau qui s’affiche.
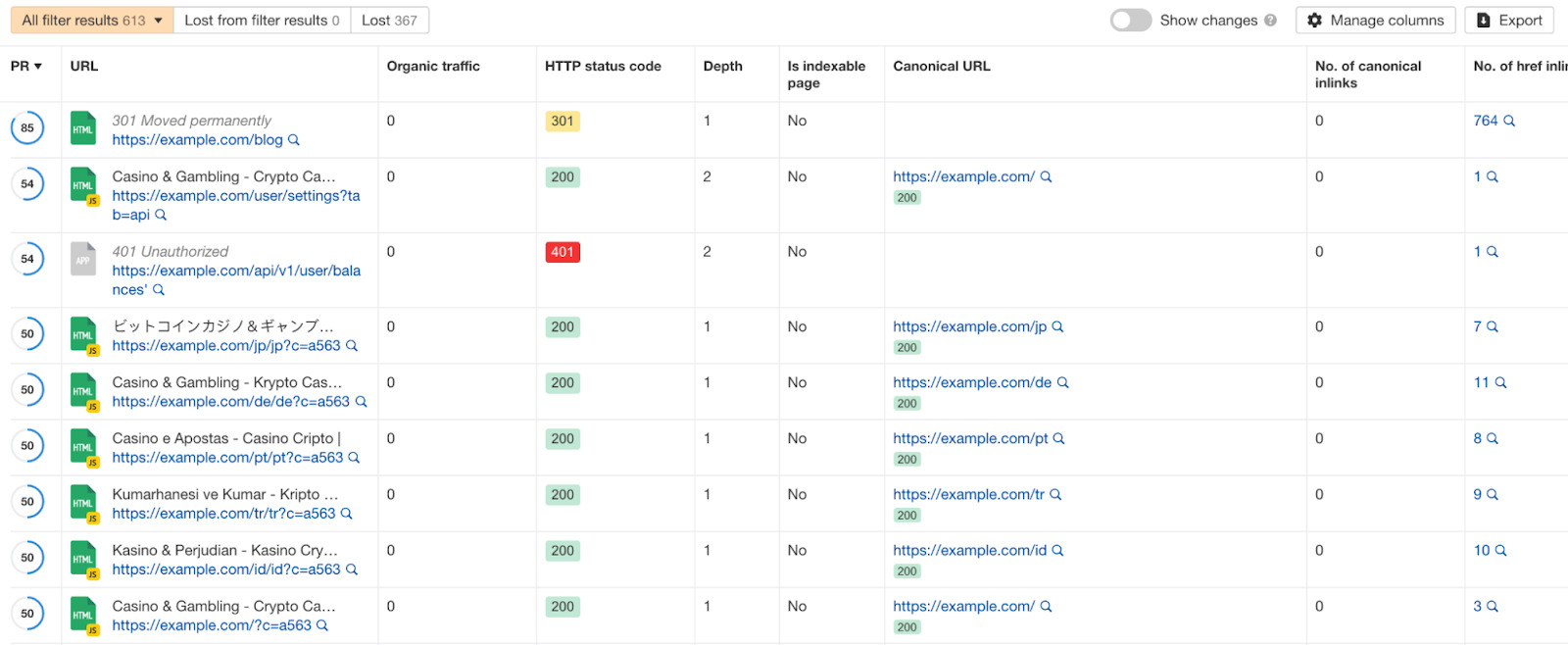
Est-ce que ces URL sont issues de filtres ? Dans ce cas, oui, il s’agit bel et bien d’un problème de recherche à facettes.
Vous vous retrouvez dans l’un des exemples cités ? Pas de panique : je vais vous montrer quelques solutions à mettre en place pour dire adieu aux problèmes liés à la recherche à facettes.
La balise canonique : pour consolider les signaux
Si vous avez surtout un problème d’indexation (mais pas de budget de crawl), la balise canonique pourrait bien vous sauver la mise.
Comment l’utiliser ?
Sur chaque URL filtrée, il suffit d’indiquer à Google quelle est l’URL canonique à retenir. Comme ça, les moteurs de recherche vont renvoyer les signaux des pages filtrées sur la page de catégorie associée.
Je vais vous donner un exemple. On va dire que l’URL d’une de vos catégories est :
https://exemple.fr/lave-linge/samsung/
Et votre URL filtrée :
https://exemple.fr/lave-linge/samsung/?capacite=10kg&couleur=metallique
Il vous suffit d’ajouter sur la page filtrée :
<link rel="canonical" href="https://exemple.fr/lave-linge/samsung/" />
Ou d’ajouter ceci via les en-têtes HTTP :
Link: <https://exemple.fr/lave-linge/samsung/>; rel="canonical"
Les balises canoniques sont simplement des suggestions pour Google. Ce ne sont pas des ordres qu’il va suivre. Donc Google peut décider de les ignorer si vos pages filtrées sont jugées trop différentes (au niveau du contenu et/ou des titres) ou si elles reçoivent beaucoup de liens internes.
Le fichier robots.txt : pour bloquer le crawl
Quand vous n’avez pas besoin que les URL filtrées soient indexées, passez directement par le robots.txt. C’est même ce que Google conseille pour aller plus vite !
Pour ce faire, ajoutez une règle Disallow dans votre robots.txt :
User-agent: * Disallow: *?couleur=* Disallow: *?taille=* Disallow: *?capacite=*
Si votre navigation à facettes utilise des segments de path plutôt que des paramètres, écrivez :
User-agent: * Disallow: */couleur/* Disallow: */taille/*
Même si elle est pratique et rapide, cette technique a ses limites :
- Bloquer le crawl ne garantit pas la désindexation. Si des liens internes ou externes pointent fortement vers ces URL, elles peuvent rester dans l’index.
- Vous ne pouvez pas faire d’exception et autoriser certaines facettes utiles. Enfin, techniquement si, mais cela risque de grandement complexifier les choses ! Par exemple, si vous voulez que le critère « couleur » puisse être crawlé pour la catégorie « Robes » mais bloqué pour « Sous-vêtements », vous allez devoir jongler entre des règles « Allow » et « Disallow » et vous risquez rapidement de vous mélanger les pinceaux.
Les fragments d’URL (#) : la méthode recommandée pour les filtres non indexables
Dans sa documentation publiée en décembre 2024, Google met explicitement en avant les fragments d’URL comme LA méthode de prédilection pour les filtres que vous ne voulez pas indexer.
Au lieu de :
https://exemple.fr/jeans/?taille=38&couleur=bleu
Utilisez plutôt :
https://exemple.fr/jeans/#taille=38&couleur=bleu
Avez-vous trouvé la différence entre les deux ? Je vous donne la réponse tout de suite : au lieu de placer un « ? » avant le filtre, vous utilisez un « # ». Et tout ce qui suit ce # est ignoré par les moteurs de recherche. Donc plus de problème d’over-crawling pour ces variantes !
La refonte risque d’être un peu lourde côté technique (il faut que votre JavaScript gère bien les changements de filtres avec le dièse), mais c’est probablement la solution la plus propre sur le long terme.
Les liens internes en nofollow
Si vous voulez décourager le crawl sans toucher au robots.txt, vous pouvez passer les liens de votre navigation à facettes en rel=“nofollow”. Mais attention à la précision de Google ! Toujours dans sa documentation de 2024, il indique :
« Utiliser rel=“nofollow” sur les liens de filtre peut dissuader l’exploration, mais doit être appliqué de manière cohérente. En d’autres termes, chaque lien pointant vers ces pages, interne et externe, doit comporter un attribut rel=“nofollow”. »
Il faut donc faire preuve d’une grande rigueur et ne louper aucun lien !
Cependant, et Google appuie là-dessus dans sa documentation dédiée à la gestion des URL de navigation à facettes, cette méthode n’est malheureusement pas des plus efficaces sur le long terme.
La balise noindex : la solution radicale
Si toutes les astuces précédentes ont échoué, il ne vous reste plus qu’une solution. Elle est extrême, certes, mais au moins, vous êtes sûr(e) qu’elle fonctionnera. Je parle bien sûr de la balise « noindex ».
Vous l’ajoutez dans le <head> de votre URL filtrée :
<meta name="robots" content="noindex">
Ou dans le header HTTP :
X-Robots-Tag: noindex
Ensuite, vous devez retirer tout blocage de crawl sur ces URL (robots.txt notamment). Sinon, Google ne verra jamais la directive « noindex » et la page restera dans l’index.
Attention : sur le long terme, Google peut arrêter d’explorer les liens internes des pages noindex, ce qui peut bloquer la circulation des signaux. À utiliser avec modération, donc.
Il y a encore quelques années, on pouvait entendre parler de l’outil de paramètres d’URL de Google Search Console pour gérer ce type de souci. Cependant, Google a annoncé son abandon dès avril 2022. La raison ? Ses algorithmes seraient devenus suffisamment bons pour gérer automatiquement ces paramètres dans la majorité des cas.
Si vous voulez mettre en place une recherche à facettes ou réaliser une refonte, voici la méthode que je vous conseille de suivre.
1. Utilisez AJAX et évitez les liens <a href>
Construisez TOUTE votre navigation à facettes en utilisant AJAX, sans ajouter les fameux liens <a href=…> dans le fichier HTML. Quand l’utilisateur va appliquer un filtre, c’est du JavaScript qui va mettre à jour la liste. Cela ne va donc pas créer de lien crawlable.
Résultat :
- Google ne voit pas de lien interne vers les pages filtrées,
- pas d’exploration des variantes,
- pas d’indexation non désirée,
- pas de dilution de PageRank.
2. Rendez les URL partageables
Après avoir appliqué des filtres, il arrive qu’un utilisateur veuille partager l’URL. Par exemple, s’il veut montrer les robes longues et rouges qu’il vient de dénicher à son entourage, ou s’il veut les mettre en favori pour un futur achat. La meilleure manière de rendre cela possible (tout en restant SEO-friendly), c’est d’utiliser le fameux dièse (#) dont je vous parlais un peu plus tôt :
https://exemple.fr/robe/#coupe=longue&couleur=rouge
Comme je l’ai mentionné, puisque Google ignore tout ce qui suit le #, l’URL ne va pas être indexée. Mais elle pourra toujours être partageable et parfaitement fonctionnelle !
3. Créez des « crawl paths » alternatifs pour les pages stratégiques
Dans certains cas, la version filtrée d’une page renferme un vrai potentiel SEO. Par exemple, chez Decathlon, vous trouverez la page catégorie « vélo » qui est très populaire sur ce mot-clé. Mais quid de « vélo femme » ou « vélo enfant » ? Ce sont aussi des requêtes très fréquentes sur Google !
La méthode : créer une vraie sous-catégorie statique pour ces variations à fort potentiel, avec une URL propre du type :
/velo/route/femme/
Plutôt que :
/velo/route/?genre=femme
Comme ça, vous gardez le bénéfice de la navigation à facettes pour les combinaisons aléatoires ET vous créez des pages indexables, optimisées et structurées pour les combinaisons qui ont un intérêt SEO.
Pour identifier les filtres qui méritent leur propre page indexable, utilisez Keywords Explorer et entrez le nom de votre catégorie principale. Allez dans le rapport « Termes correspondants » et triez par sujet parent. Vous verrez tout de suite quelles combinaisons ont un volume suffisant pour justifier une page dédiée !
Jusqu’ici, j’ai surtout parlé des risques de la navigation à facettes pour le SEO. Mais si vous la gérez correctement, vous pouvez parfaitement la changer en avantage pour le référencement naturel ! C’est même un excellent moyen d’enrichir votre stratégie de mots-clés longue traîne.
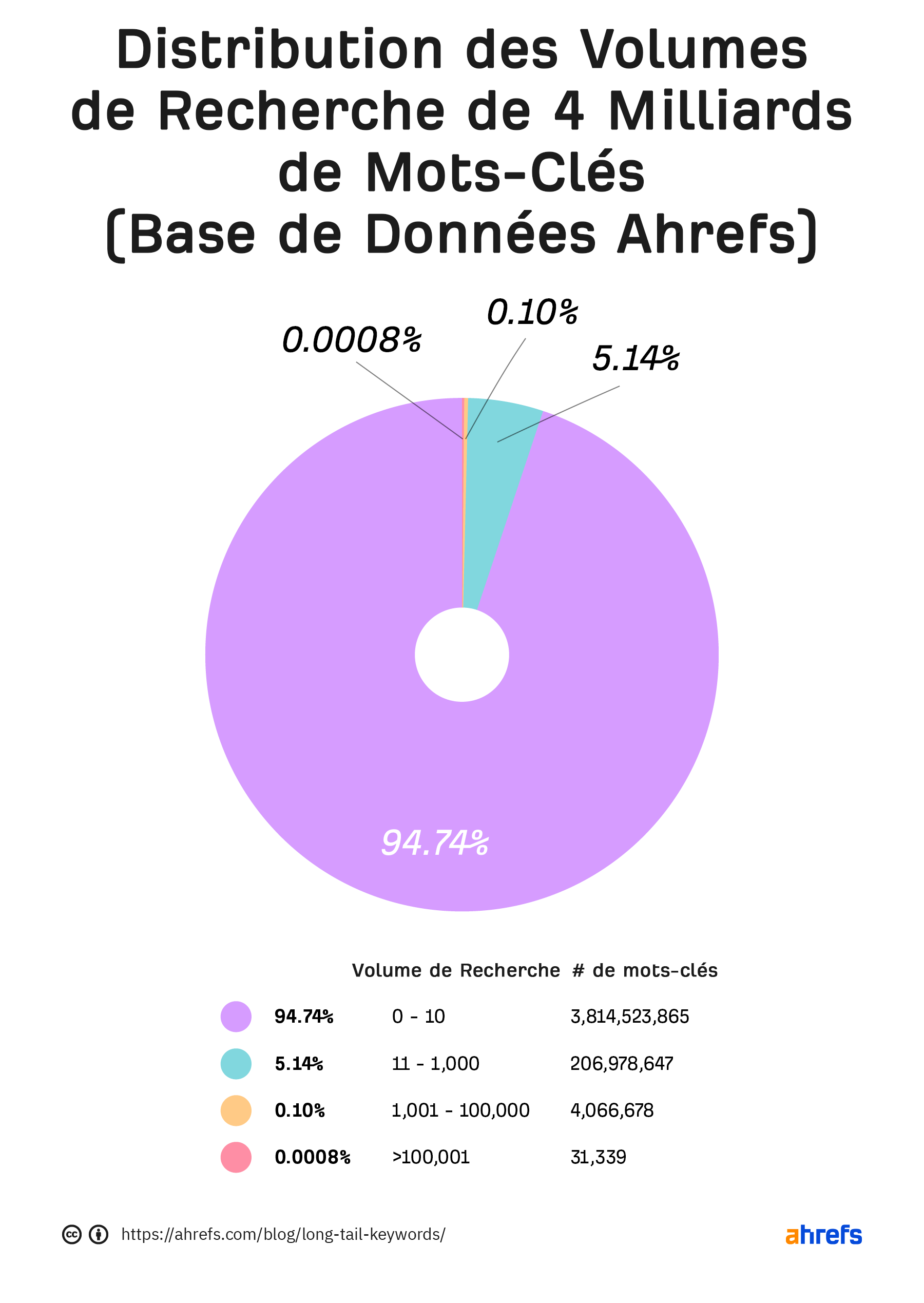
Selon les données Ahrefs, environ 99,88 % des mots-clés reçoivent moins de 1 000 recherches par mois. Parmi eux, on retrouve surtout de la longue traîne. Or, sachez que les requêtes de longue traîne représentent près de 70 % du trafic global. C’est énorme ! Et c’est parce qu’elles représentent la majorité de l’usage que font les utilisateurs de Google.
Plutôt que d’écrire “voiture” ou “manteau”, les utilisateurs recherchent :
- « voiture d’occasion peugeot pas cher »
- « manteau hiver enfant 3 ans »
- « robe rouge mariage invitée bohème »
Et ce sont typiquement les candidates parfaites pour mettre en place une recherche à facettes !
Je vais vous guider rapidement sur la démarche à suivre avec Keywords Explorer, l’explorateur de mots-clés Ahrefs.
1. Identifier les variations longue traîne
Rendez-vous sur la page de Keywords Explorer puis :
- Entrez le nom de votre catégorie, par exemple « jeans taille haute »
- Allez dans le rapport « Termes correspondants »
- Basculez sur l’onglet « Sujet parent »
- Analysez les regroupements pour repérer les combinaisons à fort potentiel
2. Rendre les pages identifiées indexables
Une fois votre liste prête, vous devez vous assurer que les pages correspondantes sont explorables et indexables. Concrètement, pour chaque URL prioritaire :
- la balise canonique pointe vers elle-même (self-reference),
- la balise noindex est retirée si elle existait,
- les éventuelles règles Disallow ont été retirées du robots.txt,
- les attributs nofollow ont été retirés des liens internes vers cette page,
- la page est ajoutée au sitemap XML.
3. Optimiser les URL pour le SEO
Alors oui, c’est la base, mais cela ne fait jamais de mal de le rappeler ! Assurez-vous d’avoir :
- des URL lisibles et stables,
- des balises title, meta description et H1 optimisées sur la requête cible,
- un contenu rédactionnel unique sur chaque page (ou au moins quelques phrases différentes),
- un maillage interne de qualité depuis la catégorie parente et depuis les autres sous-catégories pertinentes.
A lire aussi : Comment créer des URLs SEO friendly ?
4. Surveiller les performances avec Brand Radar
Une fois vos pages facettées indexées et optimisées, le travail ne s’arrête pas là. Passez sur Brand Radar pour monitorer :
- les mentions de votre marque associées à des termes spécifiques (combinaisons de produit, recherches précises),
- la part de voix sur ces requêtes longue traîne dans votre secteur,
- les citations de vos pages dans les réponses des IA génératives (ChatGPT, Claude, Perplexity, Google AI Overviews).
La recherche à facettes peut aussi bien être un piège qu’un atout pour le SEO. Si vous ne deviez en retenir que l’essentiel :
- C’est la première cause d’over-crawling selon Google. Si vous avez un site e-commerce de plus de quelques milliers d’URL, c’est un sujet à prioriser.
- Les fragments d’URL (#) sont la méthode recommandée par Google pour les filtres que vous ne voulez pas indexer.
- Le robots.txt reste valide mais doit être utilisé avec discernement et ne désindexe pas forcément les pages déjà connues.
- La balise canonique est utile mais n’est qu’une suggestion. Google peut l’ignorer si le contenu des pages filtrées diffère trop.
- Utiliser AJAX et non <a href> (HTML) est une excellente approche si vous mettez en place une nouvelle recherche à facettes.
- Identifiez les filtres à potentiel de recherche avec Keywords Explorer et créez des sous-catégories indexables pour eux. C’est là que se trouve la vraie opportunité business.
- Surveillez la perception de votre marque sur ces requêtes longue traîne avec Brand Radar pour mesurer l’impact réel de votre travail.
Le saviez-vous ? Selon les chiffres du e-commerce 2025 de la Fevad, l’e-commerce français pesait 175,3 milliards d’euros en 2024. Pour 2026, le cap des 200 milliards doit désormais être franchi. C’est un secteur qui fonctionne (très) bien, et pour vraiment percer dans le milieu, vous devez absolument maîtriser votre catalogue et votre SEO. Veillez donc à ce que votre recherche à facettes soit votre alliée plutôt que votre ennemie !
Des questions sur votre architecture de site ou votre stratégie e-commerce SEO ? Retrouvez-nous sur LinkedIn.

