
Plus d’exploration ne veut pas dire que vous serez mieux positionné, mais si vos pages ne sont pas explorées et indexées elles ne pourront pas ranker.
Pour la plupart des sites, il n’y a pas besoin de s’inquiéter du budget de crawl, mais pour certains cas, il va falloir y jeter un œil. Voyons certains d’entre eux.
- Quand doit-on s’inquiéter du budget de crawl ?
- Comment vérifier l’activité de crawl ?
- Qu’est ce qui compte dans le budget de crawl ?
- Comment Google ajuste sa manière d’explorer ?
- Je veux que Google explore plus vite
- Je veux que Google explore plus lentement
En règle générale, il n’est pas nécessaire de s’inquiéter du budget de crawl pour les pages les plus populaires. Les pages qui ne sont pas souvent explorées sont les plus récentes, celles qui ne reçoivent pas beaucoup de liens ou qui ne connaissent pas beaucoup de changement.
Le budget de crawl peut être une question à examiner pour les sites les plus récents, surtout s’ils ont beaucoup de pages. Votre serveur est peut-être en mesure de supporter beaucoup d’exploration, mais comme votre site est nouveau et n’est sans doute pas populaire pour le moment, un moteur de recherche pourrait ne pas vouloir faire beaucoup de crawl dessus. C’est souvent décevant : vous voulez que vos pages soient explorées et indexées mais Google ne sait pas si cela vaut le coup d’indexer vos pages et ne va pas autant explorer votre site que vous le voudriez.
Le budget de crawl peut aussi être problématique pour de gros sites avec des millions de pages ou bien qui sont fréquemment mis à jour. Si vous avez beaucoup de pages qui ne sont pas explorées ou dont l’indexation n’est pas mise à jour autant que vous le voudriez, il va falloir trouver des moyens d’accélérer le crawl. Nous allons en parler plus loin dans cet article.
Si vous souhaitez un aperçu de l’activité de crawl de Google et des éventuels problèmes qu’il aurait identifiés, le meilleur endroit pour vérifier cela est le rapport de statistiques de crawl dans la Google Search Console.
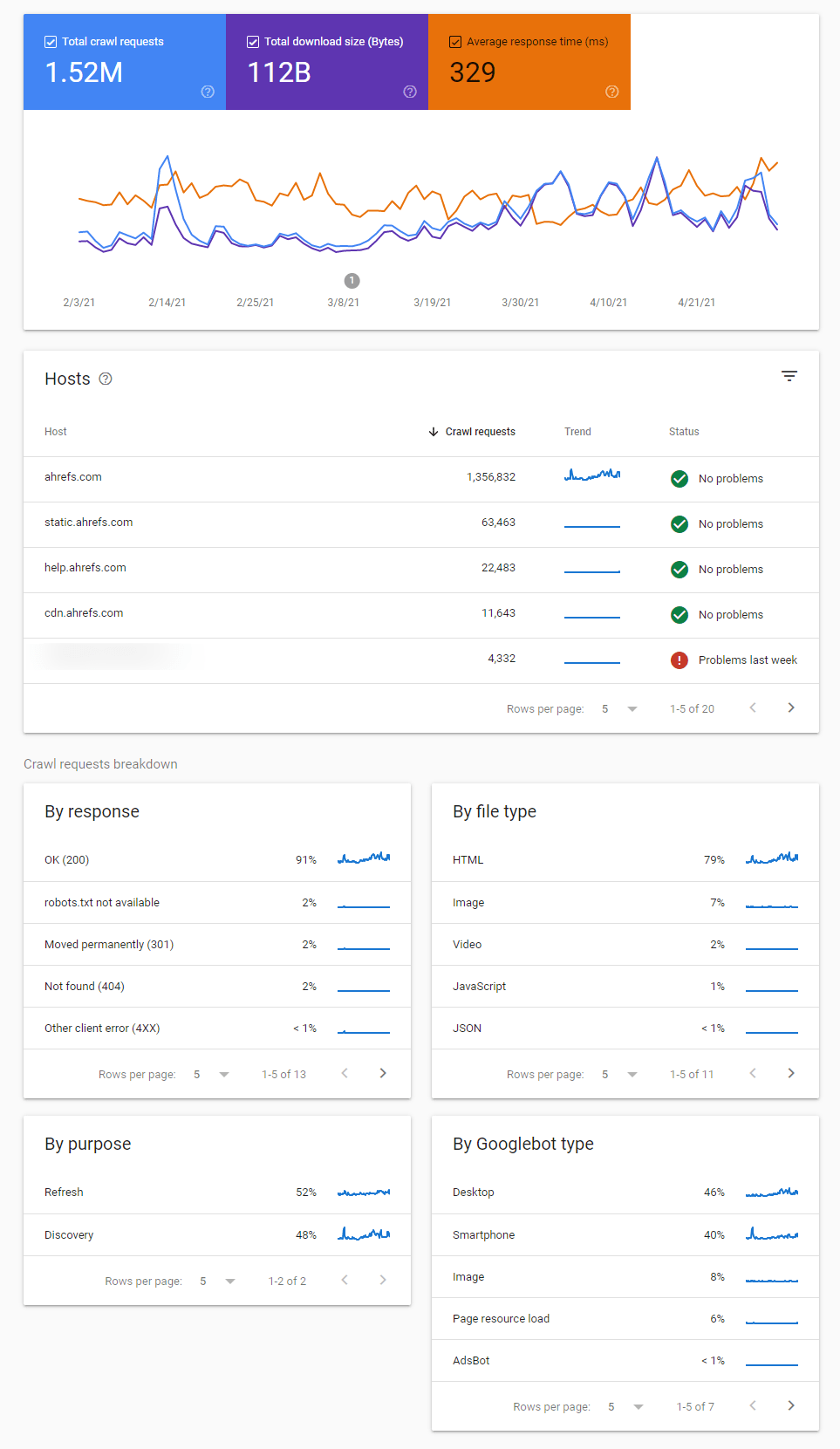
Il existe plusieurs rapports qui peuvent vous aider à identifier les changements dans les comportements d’exploration, les problèmes de crawling et vous y obtiendrez plus d’informations sur la manière dont Google explore votre site.
Il faut impérativement vérifier les codes de réponse d’explorations comme ceux montrés ici :

Vous verrez également les dates auxquelles les pages ont été explorées la dernière fois.
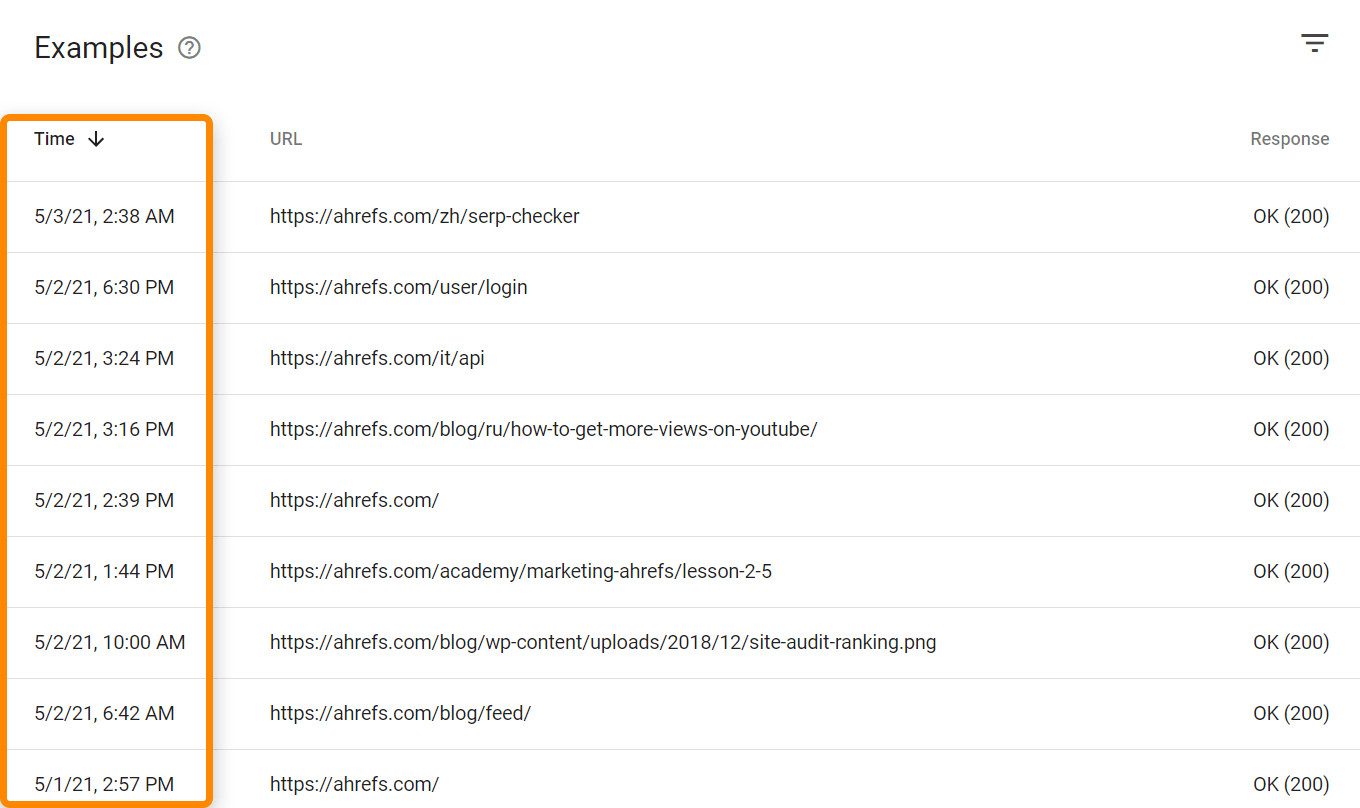
Si vous voulez voir les traces de tous les bots et utilisateurs, il va vous falloir un accès aux logs. En fonction de votre hébergement et paramétrages, vous allez peut-être y avoir accès via des outils comme Awstats ou Webalizer comme vous pouvez le voir ici, ou bien avec un cPanel sur un hébergement mutualisé. Ces outils vont vous montrer quelques données agrégées de votre fichier log.

Sur des systèmes plus complexes, vous allez avoir besoin d’accéder à des fichiers logs bruts et de les stocker, le tout sans doute de sources différentes. Il vous faudra également des outils spécialisés pour les projets les plus importants, comme le stack ELK (elasticsearch, logstash, kibana) qui va vous permettre de stocker, traiter et visualiser les données. Il existe aussi des outils d’analyse de log comme Splunk.
Toutes les requêtes et URLs comptent dans le budget de crawl. Cela prend en compte les URLs alternatives comme l’AMP ou les pages m-dot, hreflang, CSS et le JavaScript, dont les requêtes XHR.
Les URLs peuvent être trouvées pendant l’exploration et l’analyse des pages ou via d’autres sources comme les sitemaps, les flux RSS, la soumission d’URL pour indexation dans la Google Search Console ou encore via l’API d’indexation.
Il existe de plus de multiples Googlebots qui vont partager un budget de crawl. Vous pouvez trouver la liste des divers Googlebots qui explorent votre site dans le rapport de statistiques de crawl dans la GSC.
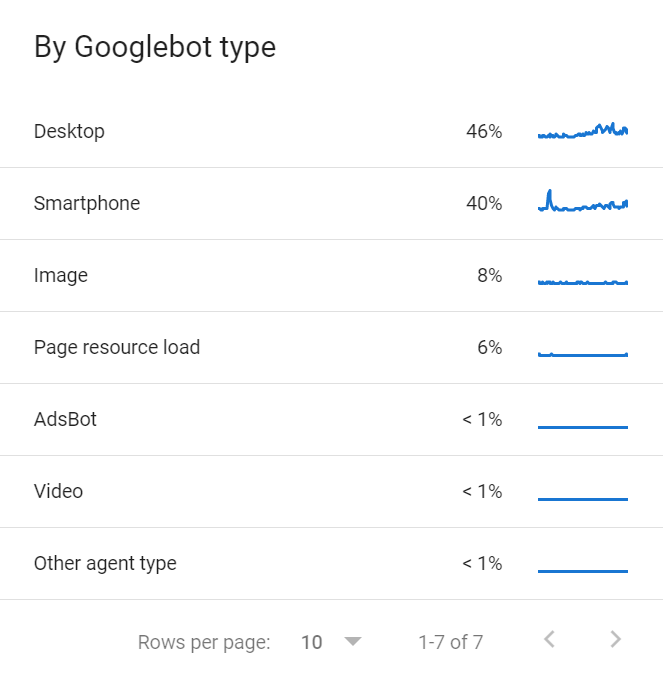
Chaque site va se voir octroyer différents budgets de crawl selon quelques critères spécifiques.
Demande de crawl
La demande de crawl, c’est tout simplement à quel point Google va vouloir explorer votre site. Les pages les plus populaires et celles qui sont régulièrement modifiées en profondeur seront plus souvent explorées.
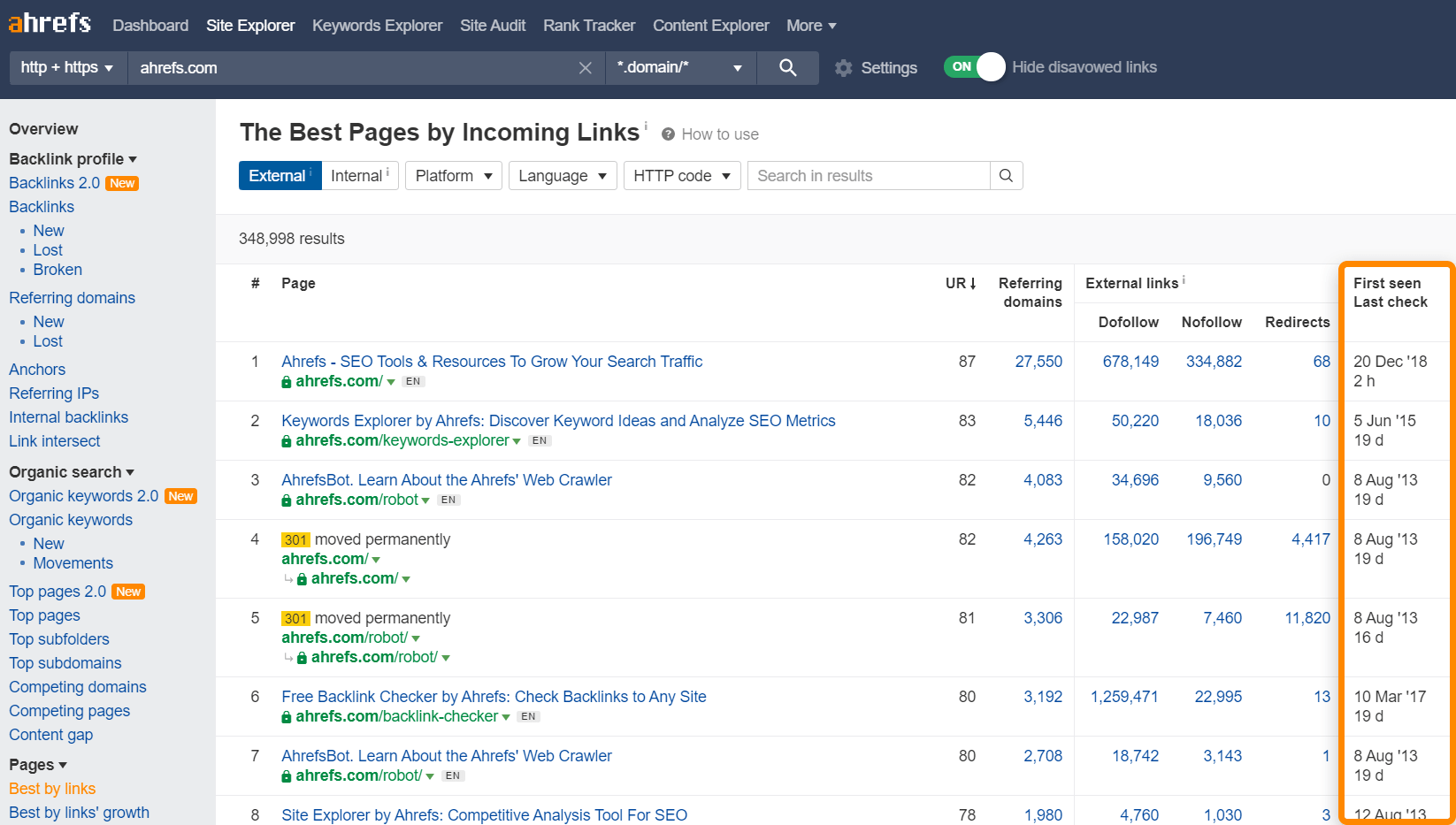
Les pages populaires, ou celles qui ont le plus de liens entrants vont généralement avoir la priorité sur les autres. Souvenez-vous que Google doit bien choisir un ordre de priorité d’une manière ou d’une autre, les liens entrants sont une méthode simple pour déterminer la popularité des pages d’un site. Pas que pour votre site d’ailleurs, toutes les pages de tous les sites du web doivent être classées par ordre de priorité.
Vous pouvez utiliser le rapport Meilleure par lien de l’Explorateur de site pour avoir une indication des pages qui vont avoir le plus de chance d’être explorées souvent. Cela va aussi vous montrer quand Ahrefs a exploré votre site la dernière fois.
Il y a également la question de l’immobilisme. Si Google voit qu’une page ne change pas, il va l’explorer moins souvent. Par exemple, s’il explore une page et ne voit aucun changement au bout d’une journée, il va peut-être attendre trois jours avant de l’explorer à nouveau. Puis 10 jours la fois suivante, puis 30, puis 100 etc. Il n’y a pas vraiment de “timing” défini entre les crawls, mais ils vont être de moins en moins fréquents au fil du temps. Cela dit, si Google voit des changements importants à l’échelle de tout le site, il va généralement augmenter sa fréquence d’exploration, au moins temporairement.
Limite de vitesse d’exploration
La limite de vitesse d’exploration est la quantité de crawl que votre site peut supporter. Les sites peuvent soutenir une certaine quantité d’exploration avant de rencontrer des problèmes de stabilité serveur comme des ralentissements ou des erreurs. La plupart des crawlers vont cesser leur exploration s’ils commencent à voir ce genre de problèmes afin de ne pas nuire au site.
Google va ajuster sa vitesse selon la santé du site. Si ce dernier supporte plus d’exploration, la limite va augmenter, s’il rencontre des problèmes, Google va ralentir sa vitesse d’exploration.
Il y a quelques éléments sur lesquels vous pouvez avoir une influence afin que votre site puisse supporter plus d’exploration et augmenter la demande de crawl. Voyons ces options
Accélérez votre serveur / améliorez les ressources
La manière dont Google explore les pages est globalement de télécharger toutes les ressources d’une page et de les traiter de son côté. La vitesse de page (page speed) perçue par votre utilisateur n’est pas la même chose. Ce qui va avoir un impact sur le budget de crawl est la vitesse avec laquelle Google va pouvoir se connecter à vos ressources et à la télécharger, et c’est donc une question de serveur et de ressources.
Plus de liens, externes & internes
Souvenez-vous que la demande de crawl est généralement basée sur la popularité ou les liens ; vous pouvez améliorer votre budget en augmentant le nombre de liens externes (backlinks) et/ou vos liens internes. Ajouter des liens internes est bien plus facile car vous avez le contrôle de votre site. Vous pouvez trouver des suggestions d’ajout de lien interne dans le rapport d’Opportunité de liens de l’Audit de site, qui contient d’ailleurs un tutoriel pour expliquer son fonctionnement.
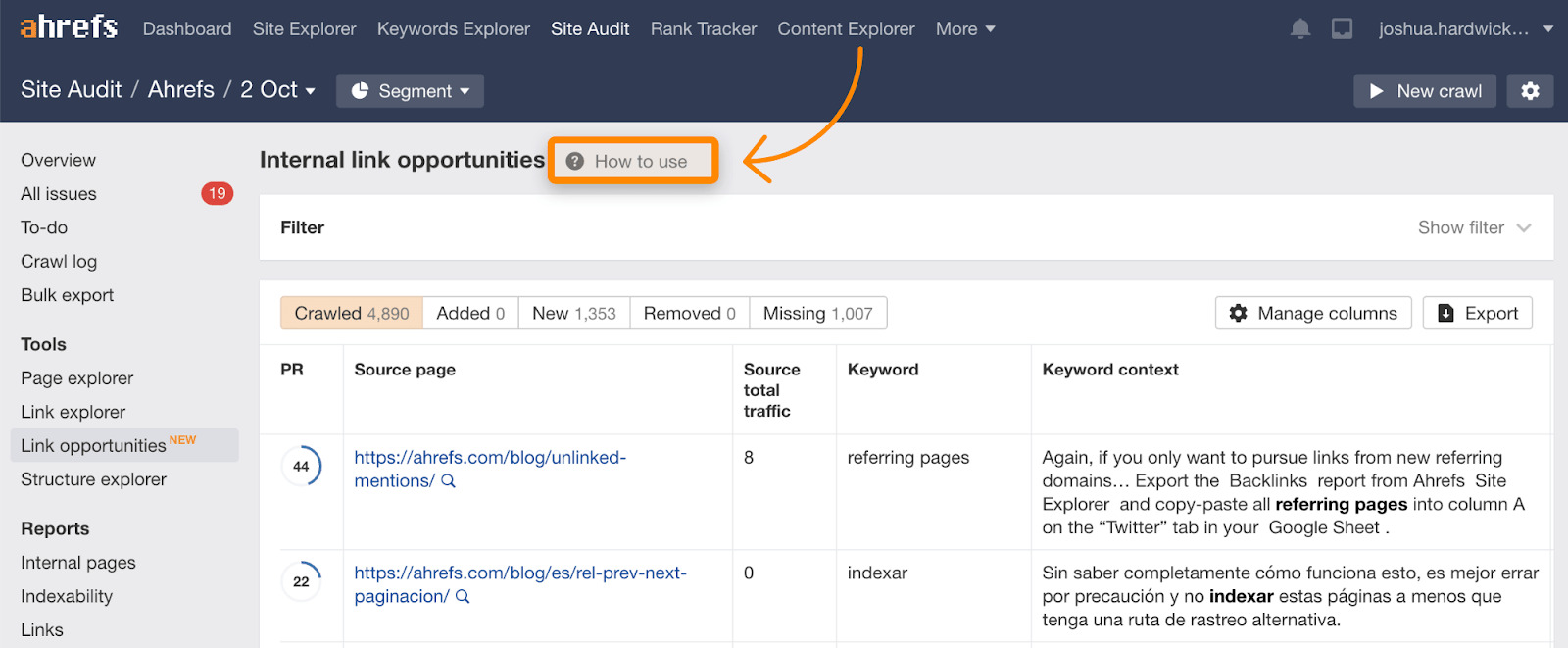
Corrigez les liens cassés et les redirections
Conserver des liens cassés ou redirigés vers des pages de votre site va avoir un léger impact sur le budget de crawl. Généralement, les pages qui reçoivent ces liens vont avoir une priorité basse car elles n’ont sans doute pas changé depuis longtemps. Mais corriger tous ces petits problèmes va améliorer votre site dans sa globalité et légèrement aider votre budget de crawl.
Vous pouvez trouver liens cassé (4xx) ou redirigés (3xx) de votre site facilement avec le rapport Pages internes de l’Audit de site.
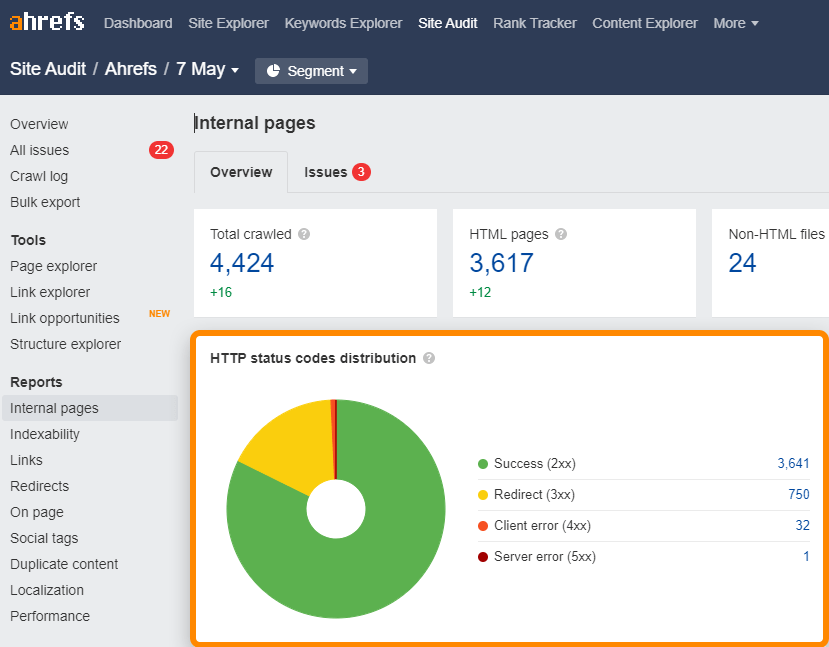
Pour trouver des liens cassés ou redirigés dans le sitemap, vérifiez le rapport tous les problèmes à la recherche de “3xx redirection dans le sitemap” et “pages 4xx dans le sitemap”.
Utilisez le GET plutôt que le POST quand vous le pouvez.
Ceci est un petit peu plus technique et implique des méthodes de requête HTTP. N’utilisez pas les requêtes POST là où des requêtes GET peuvent fonctionner. Le principe est GET (pull) contre POST (push). Les requêtes POST ne sont pas mises en cache donc vont avoir un impact sur le budget de crawl, les requêtes GET peuvent être mises en cache.
Utilisez une API d’indexation
Si vous avez besoin que vos pages soient explorées plus vite, vérifiez si votre site est éligible à l’API d’indexation de Google. Ce n’est pour le moment disponible que pour certains cas comme des annonces d’emploi ou des vidéos live.
Bing propose aussi une API d’indexation ouverte à tout le monde.
Ce qui ne va pas marcher
Certains essayent parfois des astuces qui n’auront pourtant aucun impact sur le budget de crawl
- Petits changements sur le site. Faire de petits changements sur les pages comme mettre à jour les dates, modifier les espaces ou la ponctuation dans l’espoir d’augmenter la fréquence de crawl. Google est plutôt doué pour déterminer si les changements sur une page sont d’importance ou non. Ces petites modifications ne vont pas avoir d’impact sur le budget de crawl.
- Directives de retardement de crawl dans robots.txt. Cette directive va ralentir beaucoup de bots, mais Googlebot n’en tient pas compte et cela n’aura donc pas d’impact. Notre bot Ahrefs respecte par contre cette directive, si vous avez un jour besoin de ralentir notre vitesse de crawl vous pouvez le faire via votre fichier robots.txt.
- Retirer des scripts tiers. Les scripts tiers n’entrent pas en compte dans le budget de crawl, les retirer n’aidera pas.
- Nofollow. Bon, celui-ci est un peu spécial, par le passé les liens nofollow n’auraient pas utilisé de budget de crawl. Aujourd’hui le nofollow est plutôt considéré comme une indication à Google qui peut tout de même choisir d’aller explorer ces liens.
Il y a une bonne méthode pour ralentir l’exploration de Google. Il existe encore d’autres ajustements qui pourraient techniquement ralentir votre site, mais je ne vous le recommande pas.
Ajustement lent, mais garanti
Le principal contrôle que Google nous donne pour ralentir son exploration est le réglage de fréquence d’exploration au sein de la Google Search Console. Vous pouvez ralentir la fréquence de crawl avec cet outil mais il peut se passer jusqu’à deux jours pour que ce soit pris en compte.
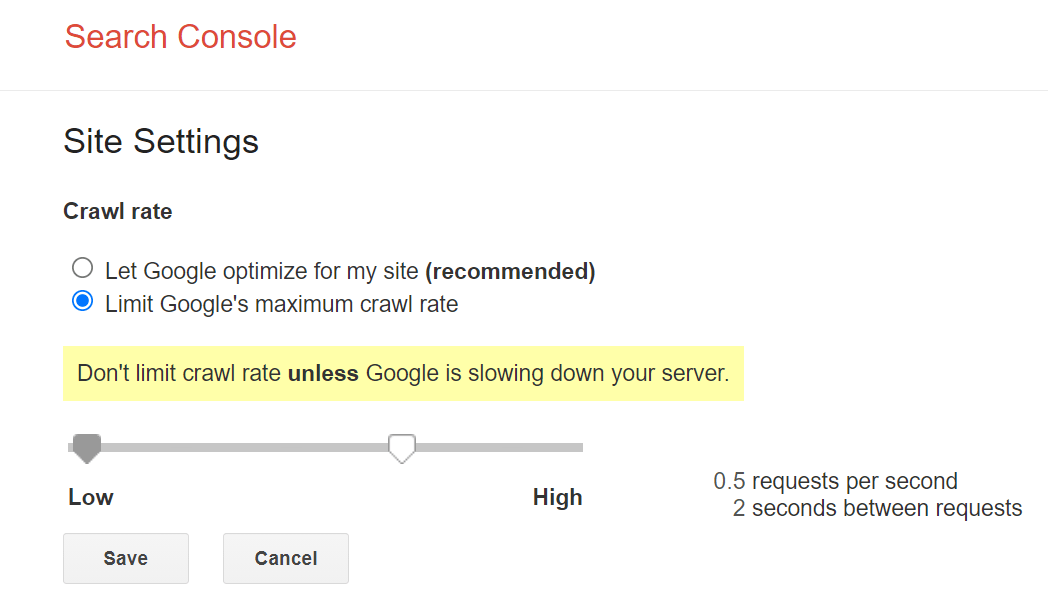
Ajustement rapide, mais avec des risques
Si vous avez besoin d’une solution immédiate, vous pouvez tirer parti des ajustements de la vitesse d’exploration en lien avec la santé de votre site. Si vous donnez à Google une erreur “503 Service Unavailable” ou “429 Too Many Request” sur certaines pages, le bot va ralentir son exploration voir l’interrompre temporairement. En revanche, ne faites pas cela plus de quelques jours, sinon vos pages vont finir par perdre leurs places dans l’index.
Conclusion
Je voudrais le répéter encore une fois : pour la plus grande partie des gens, le budget de crawl ne devrait pas être une inquiétude. Si vous aviez des questions sur le sujet, j’espère que ce guide vous a aidé.
Je ne m’en inquiète réellement que lorsque j’ai des pages qui ne sont pas explorées ou indexées, quand je dois expliquer à quelqu’un pourquoi il n’a pas à s’en inquiéter ou si je vois quelque chose d’étrange dans le rapport d’exploration de la Google Search Console.
Vous avez des questions ? Dites-le-moi sur Twitter.


