Nos habíamos conocido trabajando juntos en el departamento de marketing de un banco. Ella seguía en el sector y me preguntaba por la metodología del análisis:
Mi respuesta no se hizo esperar (he tenido que censurar partes, porque a veces me tomo demasiadas confianzas, y no pensé que esta conversación fuera a salir en un artículo nueve meses después):

Lo que no me esperaba es que lo que me dijo después se convirtiera en una profecía:

La situación se ha venido repitiendo, de distintas formas y con distintas personas en cada análisis publicado. Ya sea analizando coches o seguros de salud, siempre hay alguien que me dice: “mis datos son distintos”.
La última vez, hace apenas un par de semanas con el análisis del sector hotelero:

De hecho, casi a la vez que publicábamos ese análisis, muchos de los resultados de este otro informe eran bastante distintos.
Aunque he tratado el tema parcialmente en los propios análisis, creo que este tema merece una reflexión propia.
Un artículo que pueda reenviar y referenciar cada vez que alguien me diga “estos datos no coinciden” o que tú, querido lector o lectora, puedas reenviar a tu responsable si te pregunta: ¿por qué nuestros datos son distintos?
Así que voy a explicar los 4 motivos por los que los datos de visibilidad en IA con los que trabajas no coinciden con los de otras herramientas, consultoras, artículos de blog o los de otro departamento.
Cuando acabes de leer no solo entenderás por qué no coinciden. También habrás aprendido en qué tienes que fijarte, cómo funcionan las herramientas de visibilidad en IA y todo lo necesario para elegir una herramienta y proceso que mejoren tus resultados.
Vamos allá.
Cuando hacemos nuestro análisis, sea en Brand Radar de Ahrefs o en otra herramienta, lo primero que nos encontramos es el reparto del porcentaje de visibilidad de nuestra marca frente a sus competidoras.
Por ejemplo, aquí tenemos una comparativa de visibilidad en IA de los principales bancos españoles:
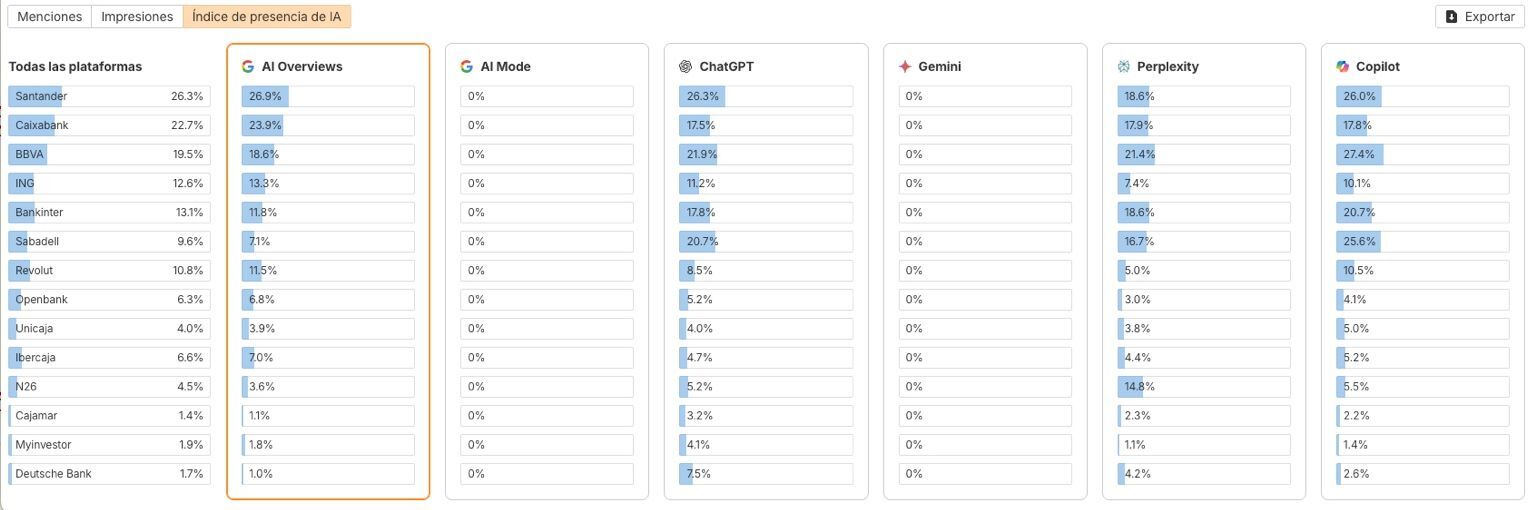
Estos datos nos muestran la visibilidad en distintas plataformas (AI Overviews, ChatGPT, Copilot…) y agregadas de estas marcas.
Pero, ¿de dónde salen?
En el caso de Brand Radar, ya se están monitorizando 243 millones de prompts.
Y aquí es donde merece la pena parar para hacer una aclaración rápida: ninguna herramienta, ninguna, tiene acceso a los prompts reales que se están escribiendo en ChatGPT, Claude o Gemini.
Entonces, ¿de dónde salen los datos?
De una muestra de prompts. Lo que hacen las herramientas es enviar prompts a los distintos chatbots (Gemini, ChatGPT, Grok, etc.) y guardar la respuesta, para analizarla.
Simplificando mucho, es como si tú cogieras una hoja de cálculo, escribieras el prompt, la fecha y hora, lo copiaras y pegaras en ChatGPT y guardaras la respuesta.
Y, básicamente, esto es lo que hacen todas las herramientas: lanzar los prompts a las distintas plataformas, guardar el resultado, y trabajar sobre esto (soy consciente de que simplifico, pero la idea de base es esa).
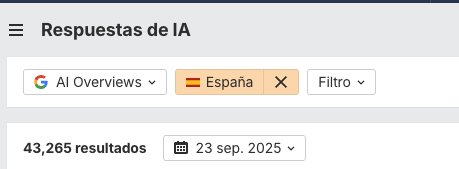
Por ejemplo, en el análisis de banca de octubre de 2025 trabajamos con 43.265 prompts en AI Overviews:
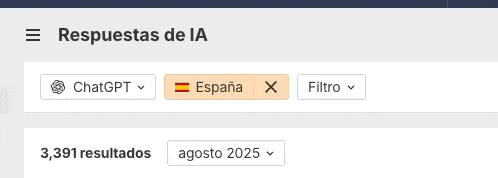
Y con más de 3.300 en ChatGPT o Perplexity y unas 2.900 en Copilot:
Pero… ¿De dónde salieron estos miles de prompts con sus respuestas? ¿Los metimos a mano?
Aquí viene la principal diferencia entre las herramientas.
Algunas dependen completamente de los prompts que tú les proporciones. En el caso de Brand Radar, como decíamos, ya se rastrean 243 millones de prompts al mes.
Cuando empiezas tu análisis y pones las marcas que quieres analizar, lo que pasa es que de entre los 243 millones de prompts, se filtran aquellos en los que hay alguna mención a cualquiera de las marcas (o páginas o variaciones del nombre de marca) que hayas elegido. Si, además, eliges una ubicación o aplicas otro filtro, la cantidad se reduce aún más.
Por ejemplo, si queremos ver cuáles son los prompts que se están monitorizando en España, ponemos un filtro de ubicación o país y vemos el dato:
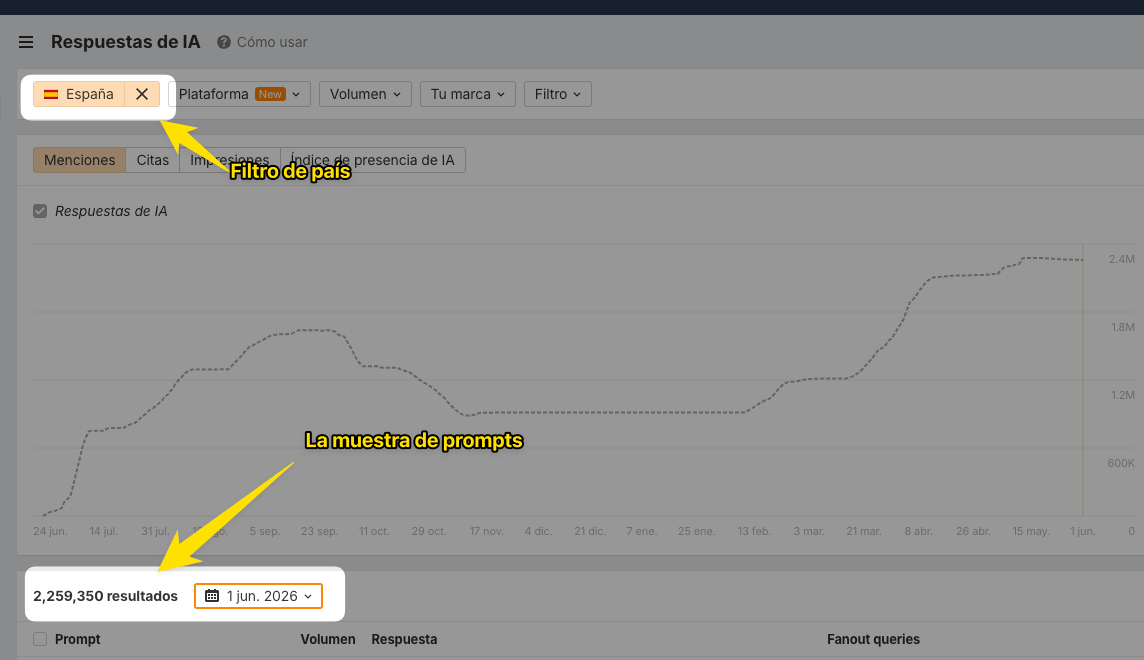
Bastante más de 2 millones.
Si ahora queremos analizar la visibilidad de dos marcas, por ejemplo, Nike y Adidas, simplemente ponemos sus nombres:
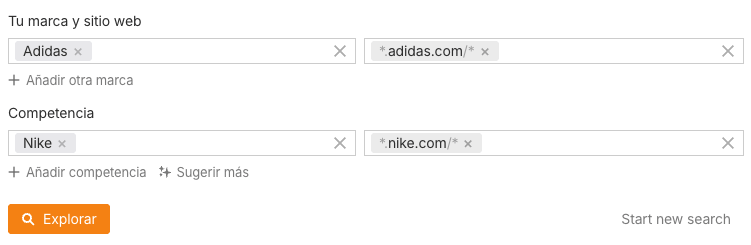
Y vemos cómo la muestra se reduce a 50.667, que son las respuestas a prompts que mencionan al menos a Nike o a Adidas:

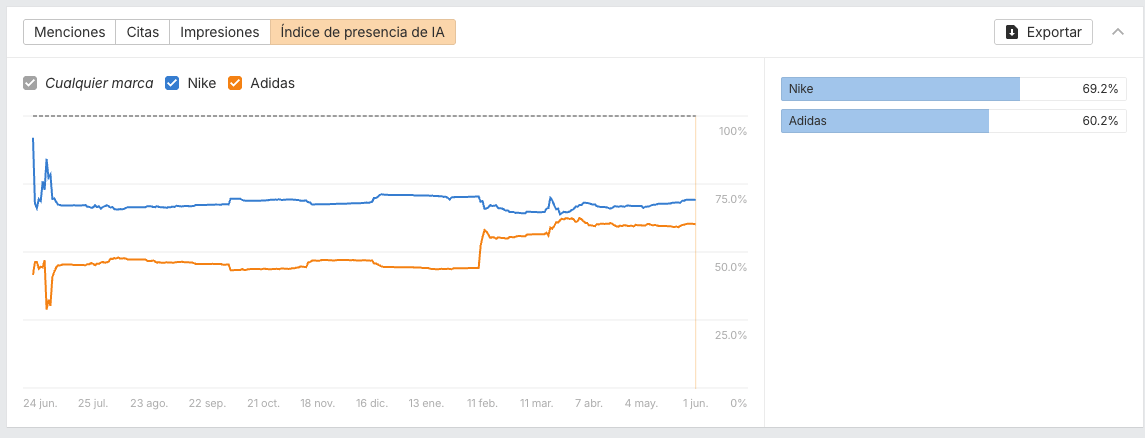
La visibilidad (agregada) en IA queda así:
- Nike: 69,2%
- Adidas: 60,2%
Es decir, de esos 50.667 prompts en España, el 69,2% menciona a Nike y el 60,2% a Adidas.
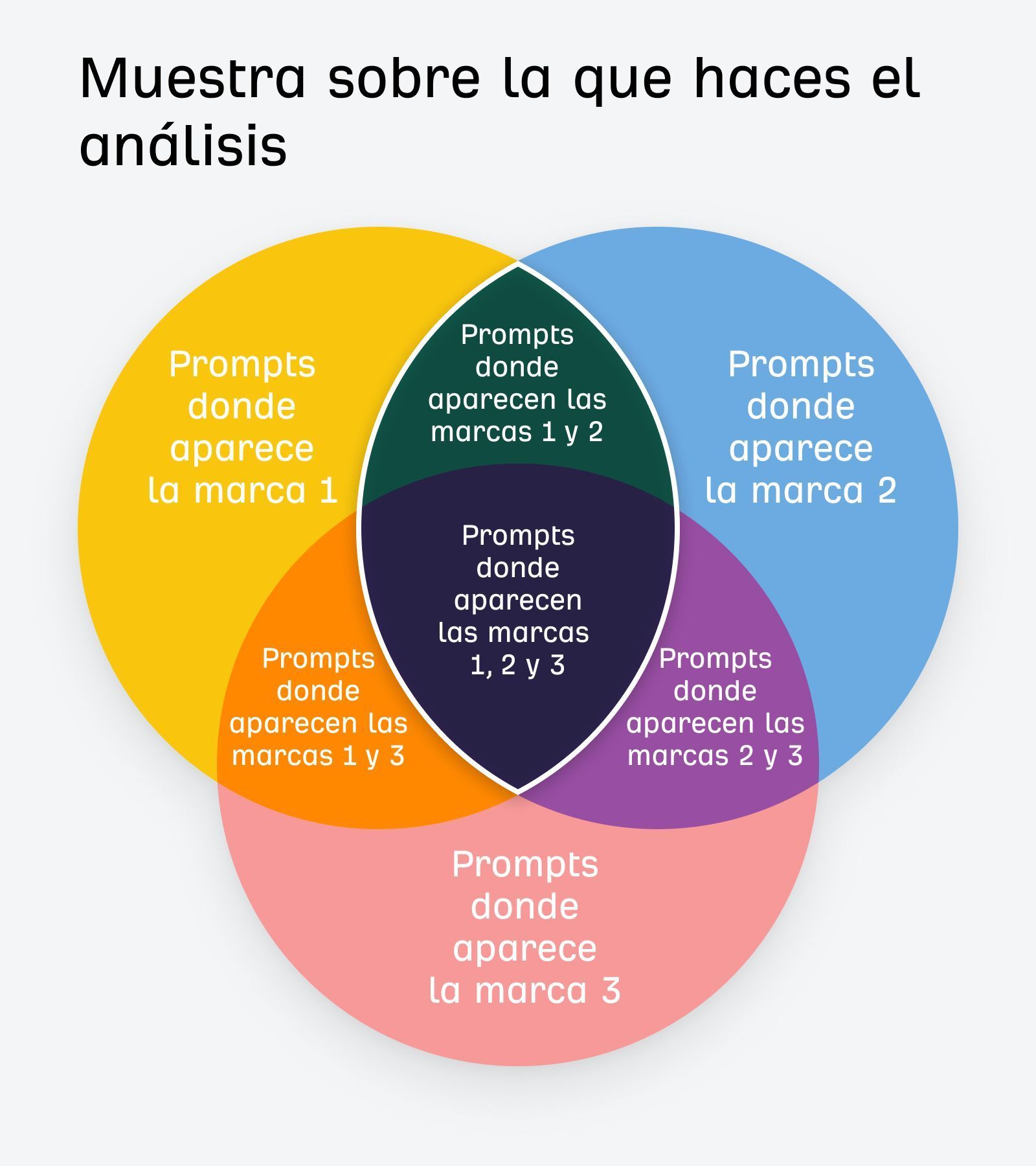
En este gráfico lo resumimos muy bien:
Aquí no tienes que configurar nada.
Los prompts vienen, en su mayor parte, de “otras preguntas de los usuarios”.
Y, como te decía, aquí es donde viene la principal diferencia entre herramientas.
Cuando empiezas a usar una plataforma de prompt tracking que te ayude a medir tu visibilidad en IA, normalmente pasas primero por un proceso de configuración.
En ese proceso, entre otras cosas, lo que haces es elegir los prompts a los que quieres hacer seguimiento.
¿Qué quiere decir esto? Pues que tú solo monitorizas la muestra que subas o elijas.
Y, dependiendo de lo que pagues, serán más o menos prompts.
Por ejemplo, esto es una captura de pantalla de una herramienta de visibilidad en IA que funciona solo con los prompts que tú le das:
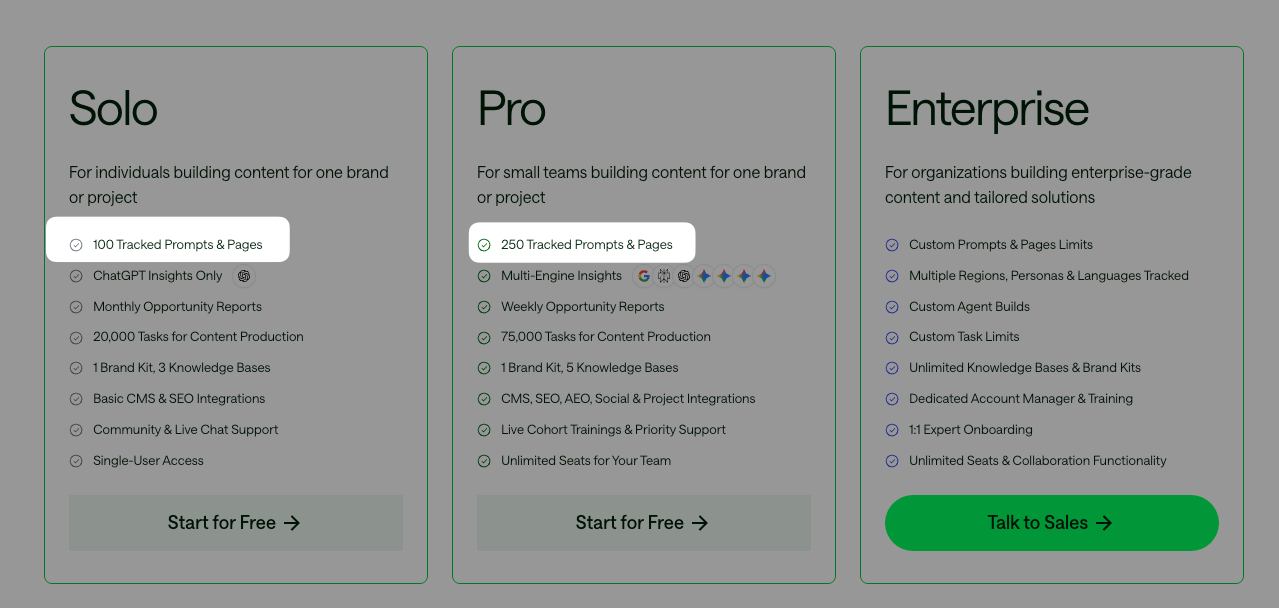
El precio se fija en función del número de prompts al que haces seguimiento.
En la mayoría de casos, unos pocos cientos (o menos).
Así que si calculáramos la visibilidad en IA de Nike y Adidas:
- Primero tendríamos que “subir” esos prompts (depende de cada herramienta, muchas te los sugieren directamente).
- Después, la herramienta haría las llamadas a ChatGPT, Perplexity, Gemini o el asistente que sea (depende del plan de pagos y lo que configures) y entonces tendrías tus datos.
Estarías trabajando sobre una muestra de ¿100? ¿250? prompts elegidos.
Aun suponiendo que la IA siempre diera la misma respuesta (que no lo hace), los datos serían, necesariamente, distintos.
Cuando ves datos de visibilidad de distintas marcas, temas, etc. lo que estás viendo son las respuestas que dan los distintos modelos a una serie de prompts que o bien eliges tú o bien se están monitorizando.
Algunos coincidirán, otros no.
El segundo motivo que más influye es que las respuestas están personalizadas en función del contexto y memoria que tiene cada herramienta del usuario.
Por ejemplo, si yo le pregunto a ChatGPT por ideas para irme de vacaciones en agosto, en un chat temporal (es decir, sin acceso a memoria), me responde esto:

Sin embargo, cuando le pregunto con mi sesión normal, lo primero que hace es recordar conversaciones:
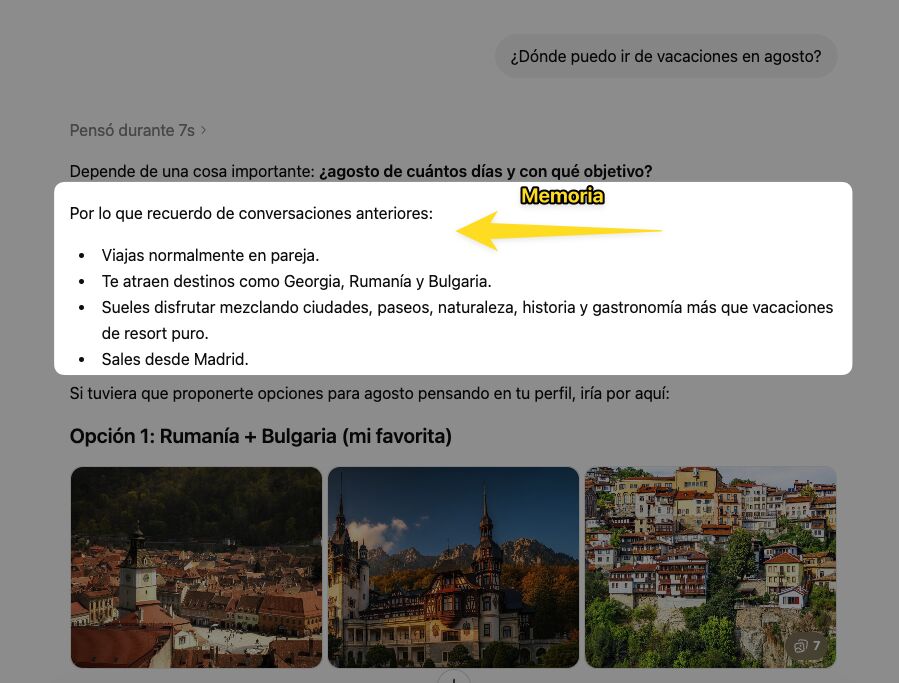
El prompt es el mismo, la ubicación es la misma, el momento es el mismo. Pero las respuestas no tienen nada que ver: porque están matizadas por lo que el asistente que uses en tu día a día sepa de ti.
A medida que hablas con cualquier asistente de IA, va aprendiendo datos sobre ti. Eso hace que las respuestas sean cada vez más personalizadas: porque guardan información sobre tus intereses o gustos.
Por ejemplo, esto responde ChatGPT cuando le pregunto sobre lo que tiene en su memoria sobre mí:

En ciertas consultas, el modelo busca en Internet para tener contenido y datos más recientes. Es lo que se conoce como grounding.
Básicamente, busca en buscadores (Google, Brave, Bing…), recoge los resultados y usa esas fuentes para elaborar la respuesta. Lo contamos más a fondo aquí, pero esa es básicamente la idea: en ciertas consultas, el modelo busca fuera para complementar sus datos de entrenamiento:

Normalmente, en este proceso, el prompt escrito por el usuario se descompone en varias búsquedas relacionadas, en lo que se conoce como query fan-out.
Lógicamente, los resultados que obtiene al buscar cambian con el tiempo: aparecen páginas nuevas, los resultados de búsqueda no son exactamente los mismos, cambia el contenido de las páginas… Y, como el contenido de estas páginas es parte de lo que usa la IA para elaborar su respuesta, lo que nos dice, también cambia.
Es decir, cuando le pregunto a ChatGPT por zapatillas de CrossFit, parte de lo que hace es:
- Usar sus datos de entrenamiento.
- Usar su memoria y conocimientos sobre mí.
- Buscar en internet para tener contenido actualizado (esto no tiene por qué hacerlo siempre, pero sí es habitual).
Que ChatGPT (o cualquier otra IA) use una página no quiere decir que la cite (de hecho, ocurre solo la mitad de las veces), pero igualmente, esas páginas no citadas sí podrían ser parte de lo que influya en la respuesta que dé el modelo.
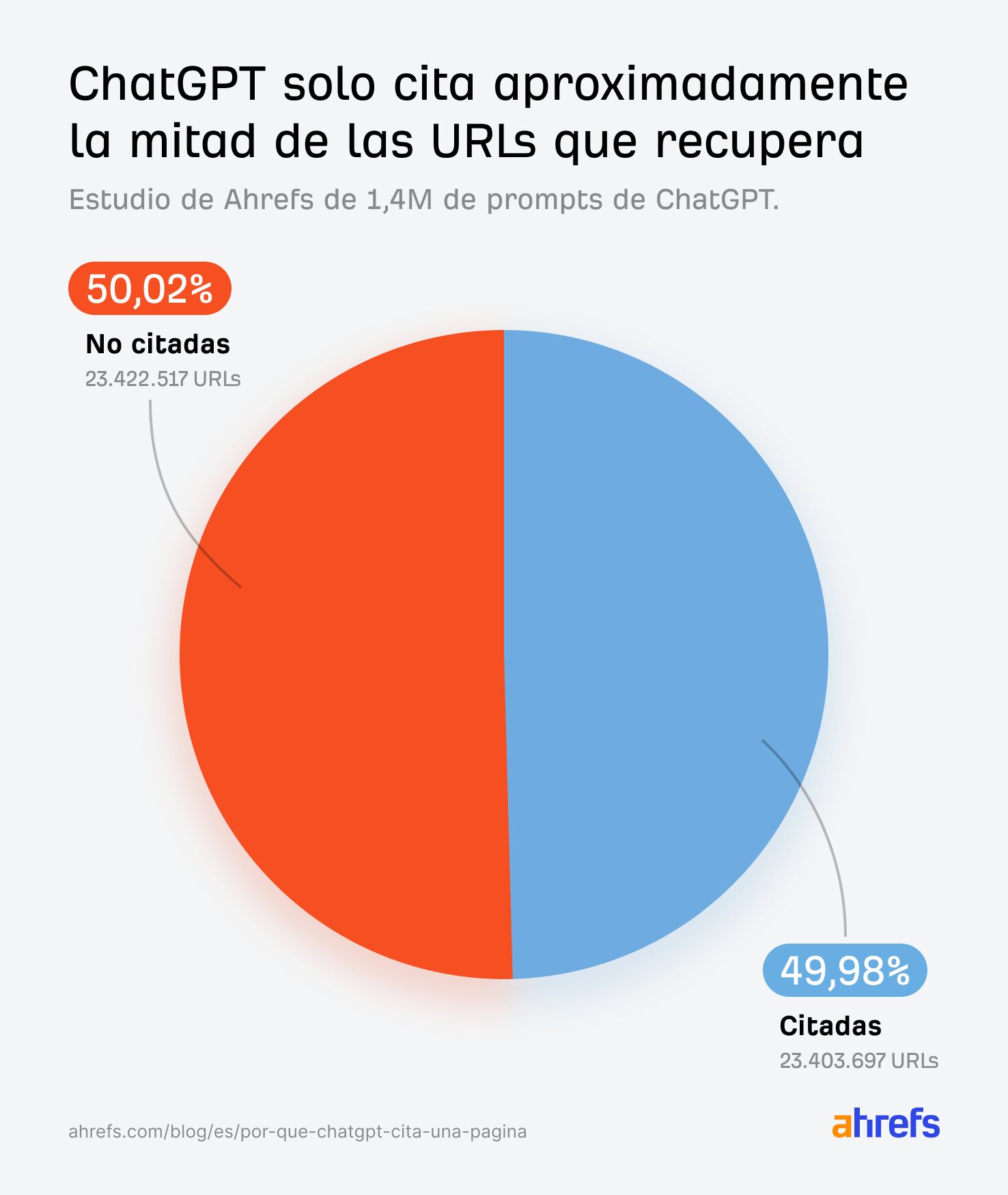
Las plataformas de IA buscan en Internet contenido que les sirva para enriquecer o mejorar sus respuestas. Este contenido influye de forma directa en las respuestas. Al cambiar (nuevas páginas, contenido actualizado o cualquier motivo), la respuesta cambia.
Y, casi para acabar, vamos al cuarto motivo, que es el más obvio y el que más se cita.
Las respuestas que dan los modelos se generan cada vez. De hecho, siguiendo con el ejemplo de las vacaciones, haciendo la misma pregunta a ChatGPT en chat temporal, con apenas unos segundos de diferencia, tenemos resultados distintos:

Este es el motivo más manido y que todo el mundo repite.
Es cierto, pero el punto de este artículo era ir más allá.
Y es que, aunque las respuestas fueran deterministas, los resultados seguirían siendo distintos: porque tenemos muestras distintas de prompts, respuestas que en realidad dependen de la memoria y contexto del usuario y, además, páginas que sirven como fuente que pueden cambiar.
Este resumen es breve: las respuestas son generativas. Así que cambian cada vez. Aquí, podríamos añadir que en la mayoría de casos son conversaciones iterativas que se desarrollan en varios turnos, no consultas de una sola vez, pero esa, es otra historia.
Si tu responsable, jefa o jefe de departamento o tu cliente te ha dicho algo como mis datos no coinciden con los tuyos, puedes copiar y pegar esto:
- No se usan los mismos prompts. Los universos sobre los que se hace el análisis son distintos. Ninguna herramienta tiene acceso a los prompts reales. Se usan simulaciones que o bien se suben a la herramienta o son bases de datos de prompts.
- Las respuestas a esos prompts están muy personalizadas por el contexto del usuario y la memoria que tiene el modelo sobre ese usuario.
- Las páginas que complementan el conocimiento del modelo pueden cambiar, alterando información que sirve de base en la elaboración de la respuesta.
- Aun manteniendo todo lo anterior fijo, la propia naturaleza de los LLM es que son máquinas generativas. Las respuestas no serán exactamente las mismas.
Y, teniendo esto tan claro, ¿tiene sentido medir la visibilidad en IA?
Yo creo que tiene todo el sentido del mundo, pero siendo conscientes de sus limitaciones y de cómo funciona.
Lo que no podemos prometer es:
- Conocer con precisión “lo que se habla en ChatGPT / Grok / Gemini /…”
- Tener la medida objetiva de “la marca más presente en IA”.
Pero:
- Con una base sólida de prompts, tenemos una muestra sobre la que trabajar y entender en qué contextos es más o menos visible nuestra marca, respecto a las de nuestros competidores.
- Podemos analizar la dirección y evolución en el tiempo, si hacemos el análisis en distintos momentos o consultamos el histórico, podemos ver si ganamos o perdemos visibilidad.
- Podemos entender qué factores influyen para que nuestra marca sea citada o mencionada en las respuestas de IA.
- Podemos añadir una muestra de prompts relevantes para complementar la base de datos. Si tienes dudas de cómo hacer esto, este artículo te puede ayudar.
Como nos decía Glen Allsopp en sus recomendaciones para elegir prompts que monitorizar:
En Ahrefs, entendemos que no trabajamos con datos perfectos, pero creemos que hay insights en las respuestas que podemos aprovechar.

No te enfoques en los resultados de prompts sueltos, agrupa los que sean similares y analiza las tendencias y coincidencias. No olvides que el análisis de visibilidad en IA, AEO o LLMO o como quieras llamarlo (todo tiene matices, lo sé, pero me gusta simplificar) no funciona igual que la búsqueda tradicional, y complementa tu análisis con otras fuentes, como el tráfico que te llega desde LLMs o encuestas a cliente.
La visibilidad en IA tiene sus limitaciones, pero que no sepamos exactamente qué pasa dentro de la caja negra de la IA no es motivo para ignorarla.
Al fin y al cabo, de eso ha ido el marketing a lo largo de toda la historia: de entender qué pasa dentro de esa caja negra que es la cabeza de las personas, donde toman sus decisiones.
Nuestro trabajo siempre ha sido el mismo: entender cómo toman esas decisiones para ser capaces de influir en ellas. Este es otro paso más, en el que tenemos datos imperfectos con los que hay que trabajar.
Llevo un año repitiendo de una forma u otra los argumentos que acabas de leer. Espero que este artículo me ahorre ese trabajo, y que también te sirva a ti la próxima vez que tengas que explicar por qué los datos de tu informe no coinciden con los de otro.
Si tienes alguna duda o quieres contarnos tu historia, te esperamos en LinkedIn o X.

