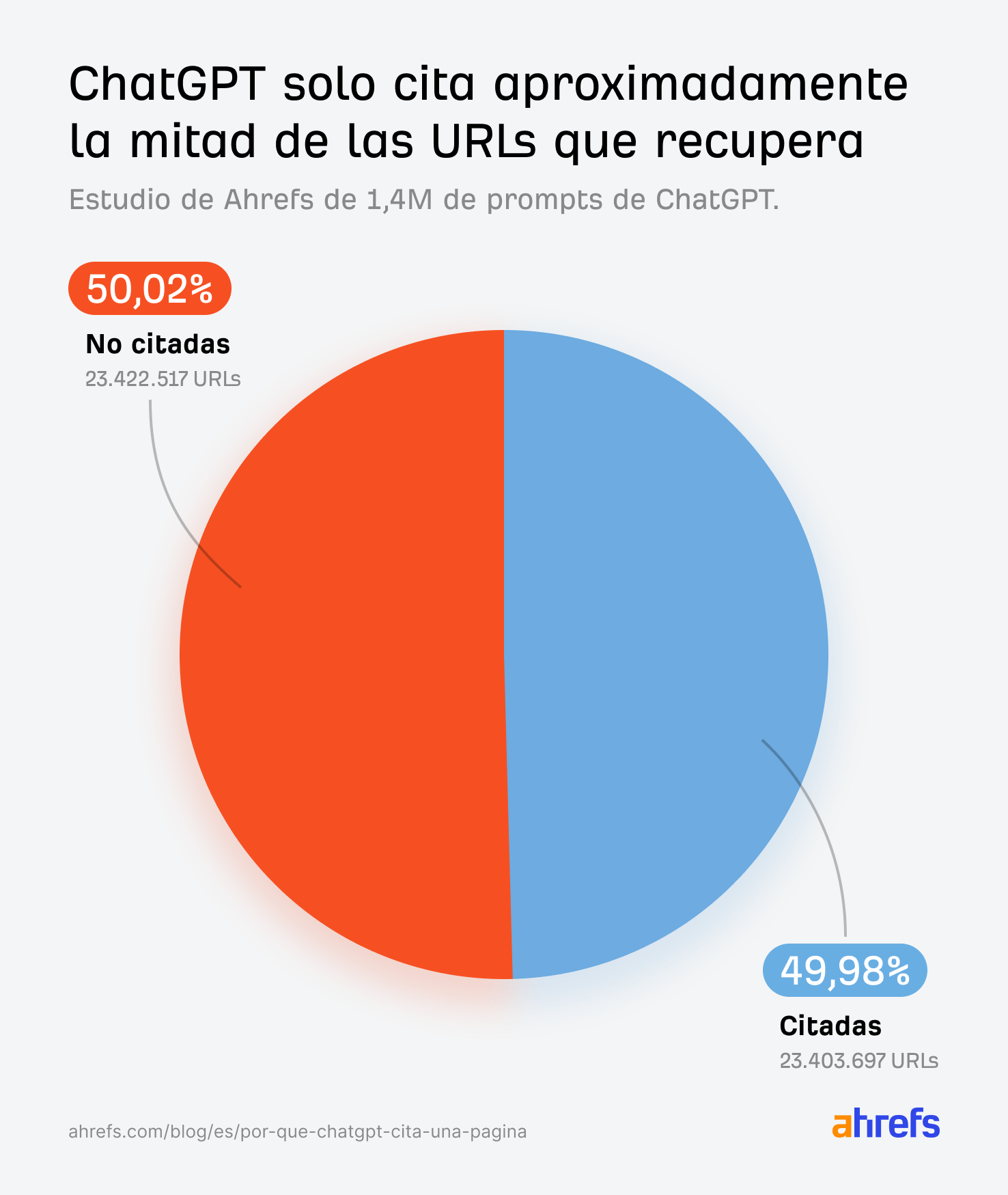
Pero, aunque ChatGPT rastrea decenas de páginas para responder a una sola consulta, según nuestra investigación, solo termina citando alrededor del 50 % de ellas.
¿Por qué una página se lleva el mérito mientras que otra, que la IA claramente recuperó, no obtiene nada?
Según estudios del experto en IA Dan Petrovic, cuando ChatGPT recupera resultados, cada uno vuelve con el título de la página, un breve fragmento o resumen, la URL y un número de identificación.

ChatGPT usa estos datos para decidir qué páginas vale la pena abrir y, finalmente, citar en su respuesta.
Eso significa que hay una capa de control antes de que ChatGPT abra y lea cualquier contenido real de tu página. El título, el fragmento y la URL hacen el trabajo pesado en esa decisión inicial.
Así que queríamos saber: ¿qué influye realmente en esa decisión? ¿Una mayor similitud semántica entre los datos recuperados de una página y la consulta del usuario aumenta la probabilidad de cita? ¿Qué campos importan más? ¿Las URL legibles para humanos superan a las opacas?
Para averiguarlo, analizamos 1,4 millones de prompts de ChatGPT 5.2 de febrero de 2025 (ordenador) con la ayuda de la científica de datos de Ahrefs, Xibeijia Guan.
Pero antes de entrar en los hallazgos, necesitas entender cómo ChatGPT recopila realmente sus fuentes, porque no todas las URL entran al sistema de la misma manera.
Cuando ChatGPT recupera resultados, categoriza las fuentes utilizando un campo interno llamado ref_type, esencialmente una etiqueta para el canal de recuperación a través del cual llegó la URL.
Descubrimos cinco categorías: búsqueda (search), noticias (news), reddit, youtube y academia.
Las tasas de citación entre ellas son tremendamente desiguales:
| ref_type | % de citas | Total de puntos de datos |
|---|---|---|
| search | 88,46 % | 25.563.589 |
| news | 12,01 % | 3.940.537 |
| 1,93 % | 16.182.976 | |
| youtube | 0,51 % | 953.693 |
| academia | 0,40 % | 185.337 |
El índice general de “búsqueda” domina —tanto en volumen como en tasa de citación— y el 88 % de las URL que terminan siendo citadas por ChatGPT se toman directamente de la búsqueda.
Si quieres ser citado por ChatGPT, necesitas estar en ese grupo de selección de búsqueda, lo que significa que tu contenido necesita posicionar.
Esta no es información nueva. A estas alturas, la mayoría de las personas ya son conscientes de que el posicionamiento juega un papel, pero es bueno tener más datos para respaldarlo.
Los nichos especializados como YouTube (por ejemplo, youtube.com) y Academia (por ejemplo, arXiv.org), por otro lado, se extraen a escala pero casi nunca afloran como citas reales.
ref_type de “búsqueda” (“search”) también incluye resultados de Reddit y YouTube; cualquier página de Reddit o YouTube que devuelva una búsqueda web estándar aparecerá allí.Los ref_types separados de “Reddit” y “YouTube” probablemente representan resultados adicionales —es decir, aquellos extraídos a través de integraciones de API dedicadas— además de lo que la búsqueda web ya haya devuelto.
Es por eso que el volumen en esos canales es tan alto; ChatGPT está complementando sus resultados de búsqueda con un feed separado de contenido de Reddit y YouTube.
Esto importa mucho para interpretar el resto del análisis.
De media, ChatGPT extrae ~16,57 URL citadas y ~16,58 URL no citadas por prompt.
Pero debido a que Reddit constituye el 67,8 % del grupo no citado, cualquier comparación agregada de “citadas frente a no citadas” es realmente comparar los resultados de búsqueda con la salida de la API de Reddit. No es una comparación justa.
Así que a lo largo de esta investigación, hemos aislado el análisis por ref_type siempre que ha sido posible para evitar esa distorsión.
Este es probablemente el hallazgo más sorprendente en el conjunto de datos.
Reddit tiene su propio ref_type dedicado en el sistema de recuperación de ChatGPT, con más de 16 millones de puntos de datos en nuestro conjunto de datos.
Sin embargo, se cita a una tasa de solo el 1,93 %.
Mientras tanto, el 67,8 % de todas las URL no citadas provienen de Reddit.
En otras palabras: ChatGPT utiliza Reddit ampliamente para comprender temas, medir el consenso y construir contexto, pero casi nunca le da el crédito a Reddit.
Aprende de la multitud y luego cita a otra institución.
Como hemos cubierto brevemente, cuando ChatGPT recupera resultados de búsqueda, cada uno vuelve con un conjunto de campos que incluyen un título, URL y, a veces, un fragmento, un extracto breve del contenido de la página almacenado en los datos de recuperación de ChatGPT.
Esperábamos que tener más de estos campos completados se correlacionara con tasas de citación más altas.
A primera vista, los datos agregados parecían contar una historia diferente: las páginas no citadas en realidad tienen más campos completados en los datos de recuperación de ChatGPT que las citadas.
Las URL no citadas tenían fragmentos el 14,81 % de las veces frente al 4,36 % de las URL citadas, y eran mucho más propensas a llevar una fecha de publicación (92,72 % frente a 35,98 %).
Casi nos quedamos con eso como hallazgo, pero me alegro de no haberlo hecho.
Cuando profundizamos en ello, la discrepancia resultó ser casi en su totalidad un artefacto de composición, impulsado por Reddit y la mecánica del proceso de recuperación de ChatGPT.
Debido a que el grupo no citado es abrumadoramente Reddit (67,8 %) y el contenido de Reddit extraído a través de la API lleva naturalmente metadatos de pub_date, la cifra del 92,72 % es un artefacto de Reddit, no una señal sobre cómo ChatGPT evalúa las páginas web en general.
La brecha del fragmento se explica de manera diferente. Según la investigación de David McSweeney sobre el proceso de recuperación de ChatGPT, el modelo en realidad abandona el campo del fragmento (el breve extracto de contenido) una vez que ha decidido citar una URL, y abre la página completa en su lugar.
Por lo tanto, no se trata de que ChatGPT prefiera páginas sin fragmentos. El bajo porcentaje de fragmentos para las páginas citadas es probablemente un subproducto de cómo funciona el proceso.
Cuando aislamos los datos solo para el ref_type de “búsqueda”, eliminando Reddit, noticias, YouTube y el resto, el panorama quedó mucho más claro:
| ref_type de búsqueda | Tiene fragmento | Tiene pub_date | Total de URLs |
|---|---|---|---|
| Citadas | 2,52 % | 33,79 % | 22.612.529 |
| No citadas | 0,09 % | 49,00 % | 2.951.060 |
Los datos de los fragmentos son básicamente inexistentes para ambos grupos dentro del vertical de búsqueda; no es una señal utilizable. Y los porcentajes de fecha de publicación están más cerca, pero las páginas de búsqueda no citadas todavía tienen una probabilidad ligeramente mayor de llevar un pub_date (49 %) que las citadas (33,79 %).
Las diferencias que vimos inicialmente entre las URL citadas y no citadas parecen haber sido distorsionadas por la composición de los datos y la mecánica de recuperación. Cualquier señal —si es que la hay— está enterrada bajo el ruido.
La conclusión honesta: no podemos sacar conclusiones firmes sobre si los campos de fragmento o fecha de publicación juegan un papel significativo en la citación a partir de estos datos.
Los datos de este estudio te dicen qué valora ChatGPT. Brand Radar te dice dónde te estás quedando corto.
Abre Brand Radar, configura tu marca y a tus competidores, y dirígete directamente al informe de Páginas citadas.
Luego, filtra por las respuestas donde se cita a los competidores y a ti no.
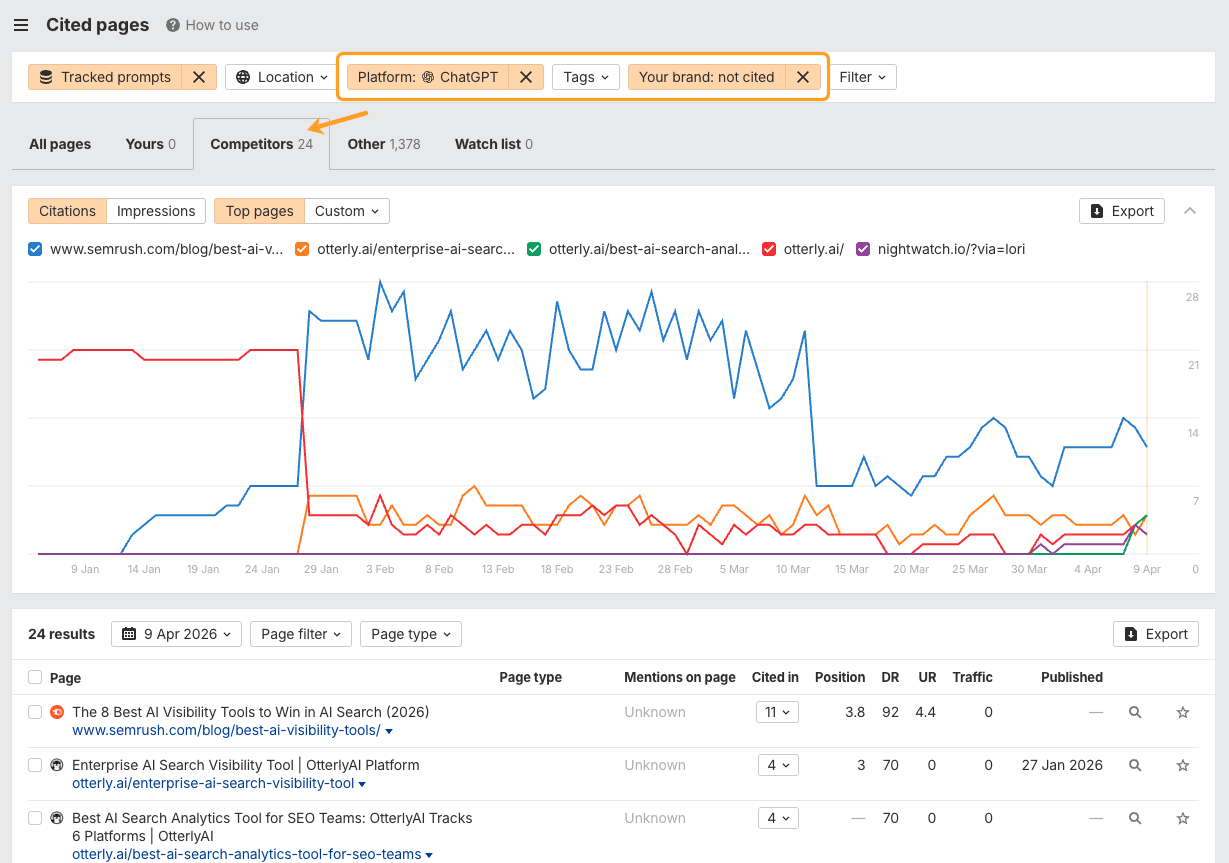
Ese análisis de brechas te da una lista concreta de contenido para crear, actualizar o reestructurar.
Para averiguar qué es “citable”, ChatGPT estima la relevancia, en un proceso a veces descrito como “puntuación semántica”, para juzgar si un artículo y una consulta están relacionados.
Dado que ChatGPT es un modelo de código cerrado, no tenemos visibilidad sobre cómo determina exactamente la relevancia internamente.
Por lo tanto, en este estudio, utilizamos la similitud del coseno calculada a partir de incrustaciones generadas por modelos de código abierto, para cuantificar y aproximar cómo podría funcionar ChatGPT.
ChatGPT hace coincidir las URL con sus propias “consultas fan-out”, las subpreguntas que genera internamente (a partir del prompt inicial de un usuario) para buscar hechos específicos.
Los datos confirman que la relevancia del título para las consultas fan-out es un factor importante en la citación:
- Prompt frente al título de la URL citada: 0,602
- Prompt frente al título de la URL no citada: 0,484
- Consulta fan-out frente al título de la URL citada (coincidencia máxima*): 0,656
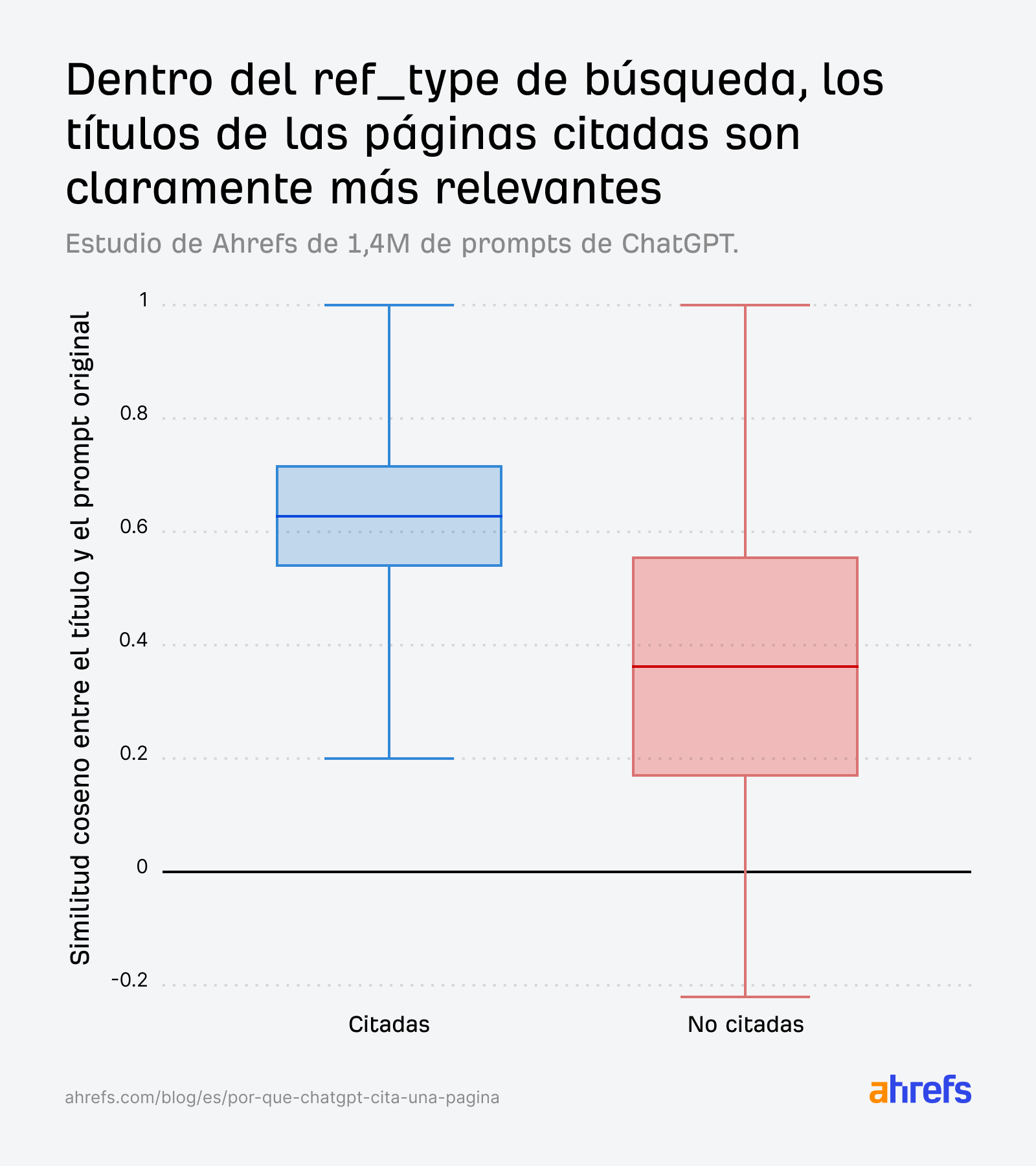
Los diagramas de caja cuentan la historia claramente. En todos los ref_types, las URL citadas tienen consistentemente una mayor similitud entre su título y el prompt original:
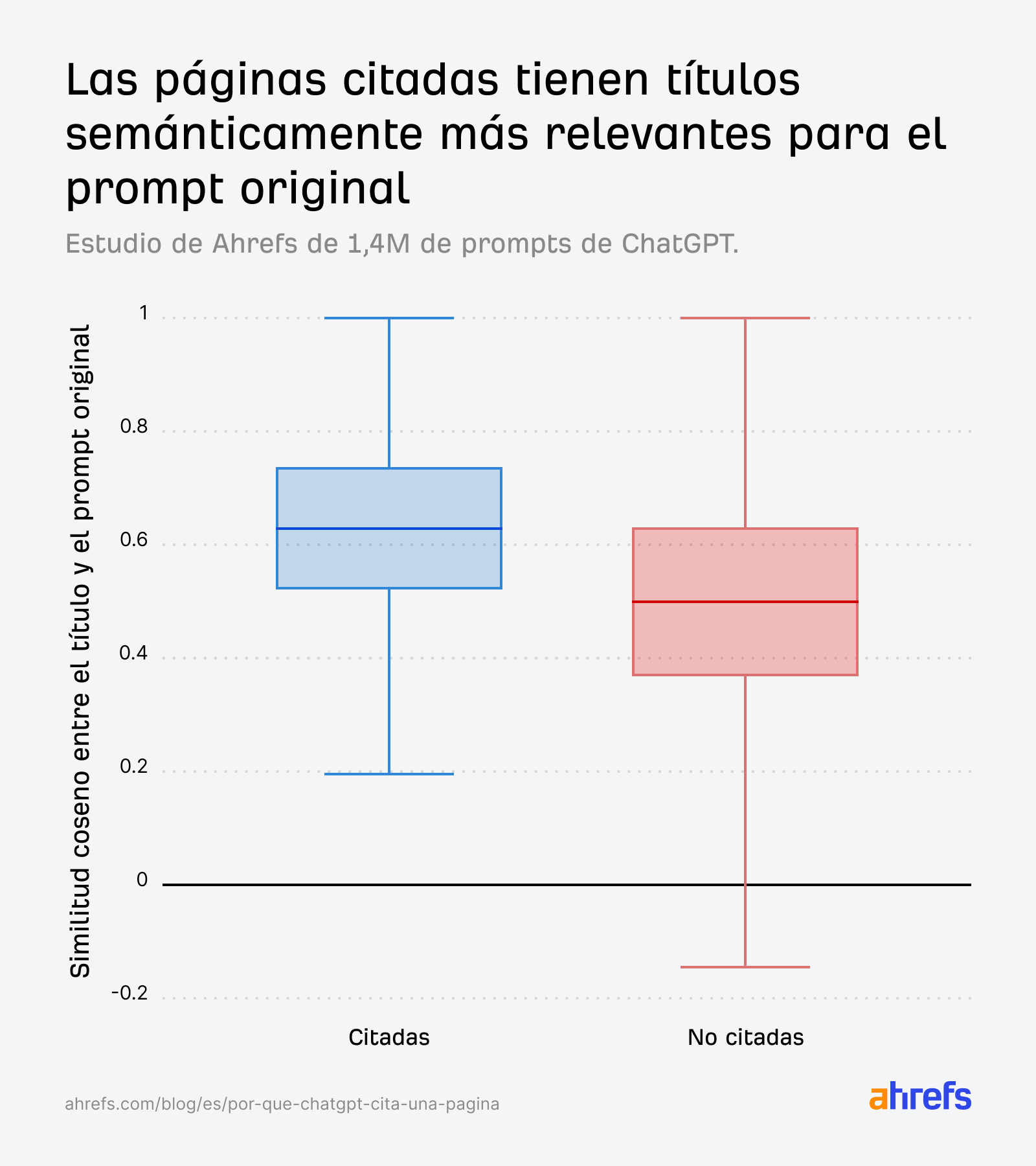
La brecha se amplía aún más cuando comparamos con las consultas fan-out en lugar del prompt original, lo que refuerza que crear contenido relevante para las subpreguntas internas de ChatGPT es lo que realmente impulsa la selección:
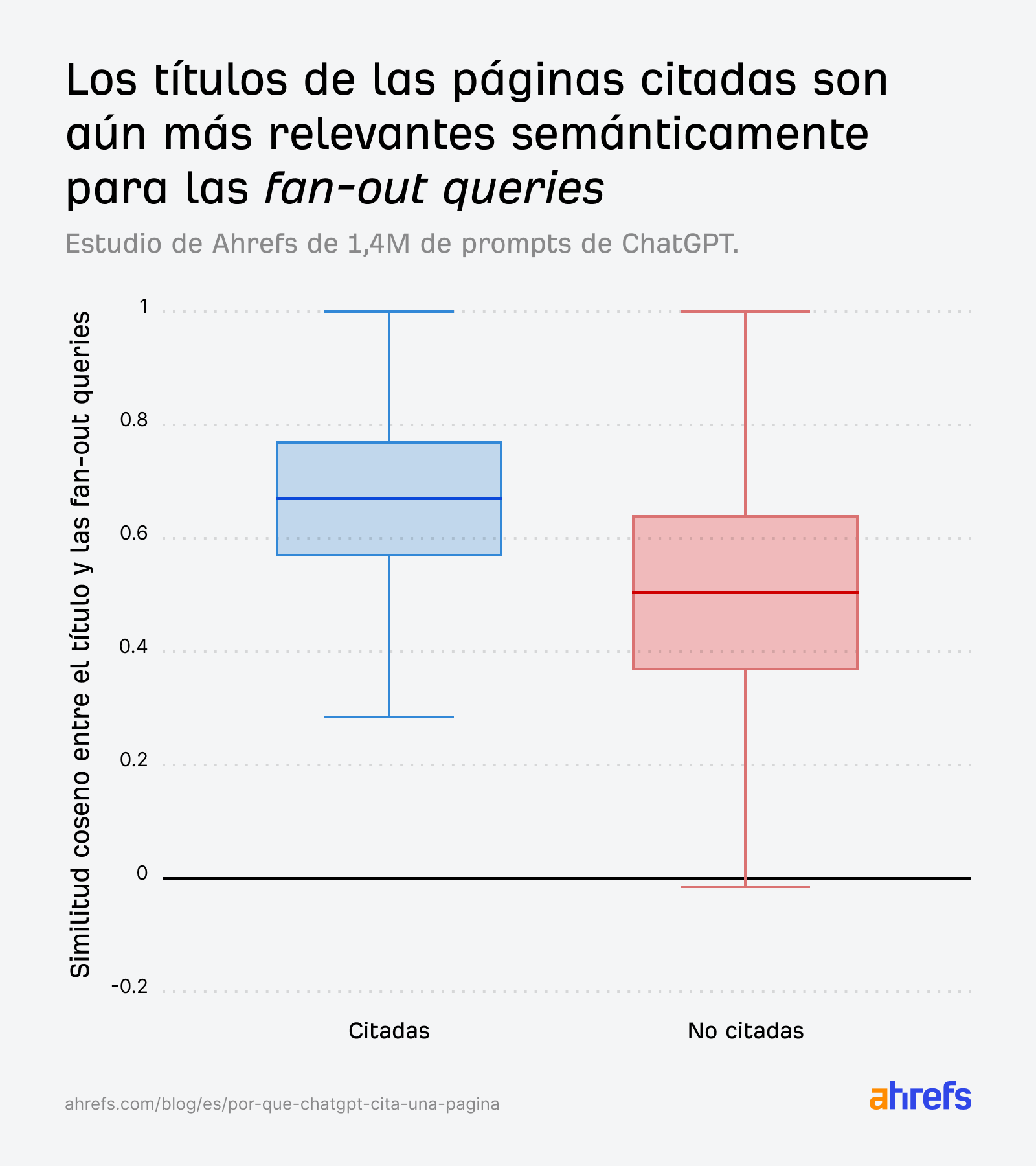
Cuando aislamos específicamente el ref_type de búsqueda, el patrón se vuelve aún más nítido. Las páginas citadas son claramente más relevantes y la distribución de las no citadas cae significativamente:
También descubrimos que los resultados de búsqueda con slugs de URL en lenguaje natural tenían una tasa de citación del 89,78 %, en comparación con el 81,11 % de aquellos que no los tenían.
En última instancia, si tu URL y título no se alinean semánticamente con las consultas fan-out internas de la IA, es menos probable que te citen.
Puedes estudiar las consultas fan-out directamente dentro de Brand Radar. Dirígete al informe de Respuestas de IA, elige cualquier prompt y verás las consultas fan-out que generó ChatGPT junto a las URL citadas.
Este es el conjunto real de subpreguntas que tu contenido necesita responder.
A partir de ahí, usa AI Content Helper para comprobar qué tan bien cubre tu página los temas que abordan esas consultas fan-out. Mide la similitud del coseno entre tu contenido y los temas que las SERP o la respuesta de IA intentan cubrir, y te da un resaltado en color a medida que escribes, mostrando qué vacíos quedan.

Si la página de un competidor está siendo citada para una consulta en la que la tuya no, esta es una de las formas más rápidas de diagnosticar el porqué.
Es de conocimiento público que el contenido más reciente es más citado por la IA y, de hecho, nuestro propio estudio de 17 millones de citas lo respalda. Descubrimos que ChatGPT citó URL que eran 458 días más recientes que los resultados orgánicos de Google: la preferencia de frescura más fuerte de cualquier plataforma que probamos.
Este estudio no contradice esa narrativa, pero sí añade una capa adicional de matiz.
Por ejemplo, cuando observamos el índice de búsqueda, las páginas citadas abarcan una amplia gama de edades: la mediana ronda los 500 días (~1,3 años de antigüedad), con algunas páginas citadas de más de 2700 días de antigüedad (~7,4 años).
La edad mediana es en realidad mucho menor que la de nuestro estudio de frescura inicial enlazado arriba (958 días en julio frente a 500 días en este conjunto de datos), lo que sugiere que ChatGPT se está inclinando hacia contenido aún más reciente en sus preferencias de citación.
Dicho esto, también descubrimos que las páginas no citadas son abrumadoramente muy jóvenes.
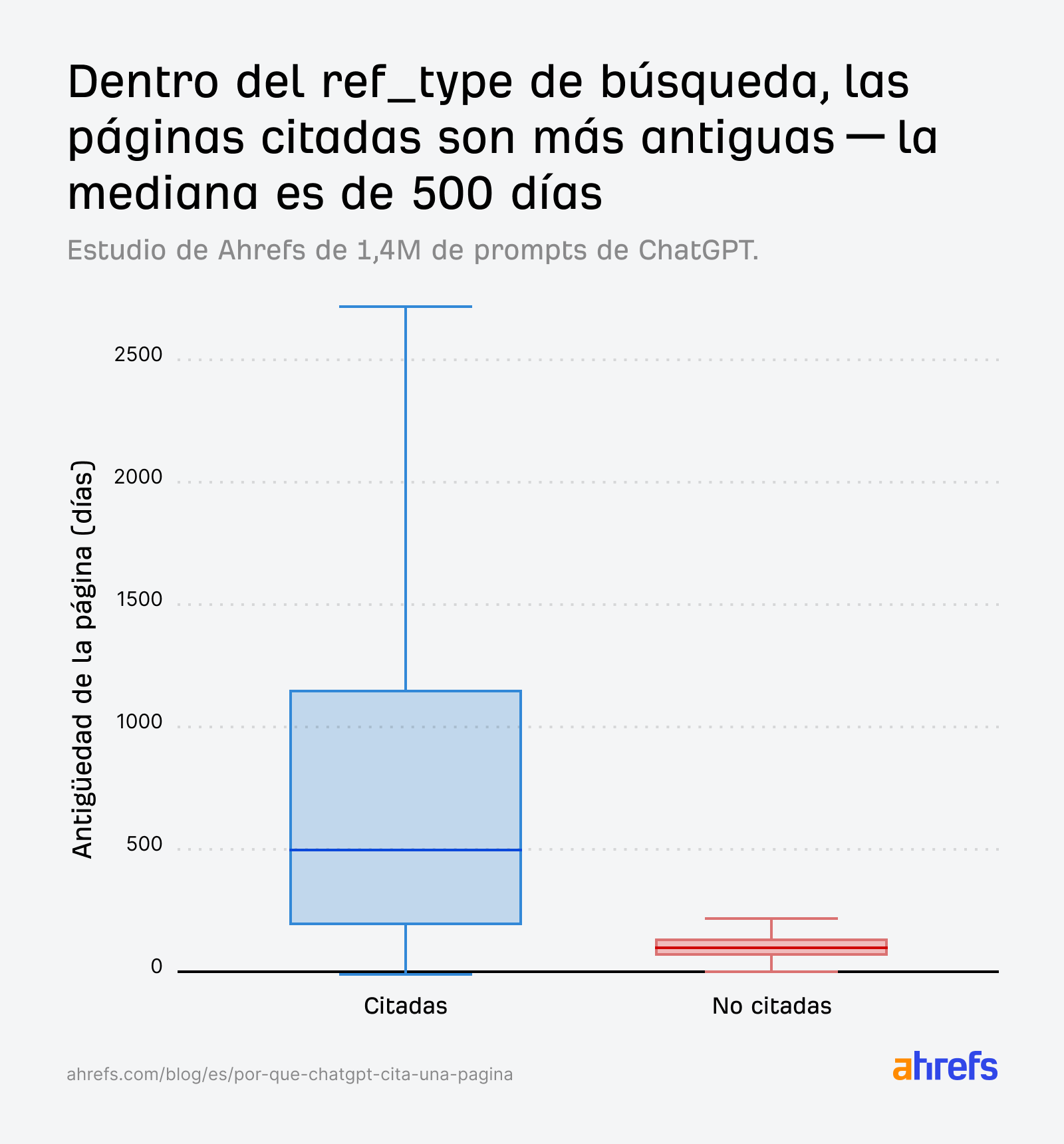
Así que dentro del conjunto de recuperación de un solo prompt, son las páginas más antiguas y consolidadas las que tienden a ser citadas, y el contenido más fresco el que tiende a ser descartado.
En otras palabras, ChatGPT prefiere contenido fresco, pero tiende a citar contenido comparativamente “más antiguo” con mayor frecuencia. Eso suena contradictorio, pero ambas cosas pueden ser ciertas al mismo tiempo.
En la población más amplia de citas de IA, ChatGPT se inclina hacia contenido más reciente cuando se compara con los resultados de Google, e incluso con sus propias preferencias de citación de hace solo un año.
Pero dentro de un conjunto de recuperación dado, la frescura por sí sola no es suficiente. La relevancia sigue haciendo el trabajo pesado.
Una página nueva que coincida bien con las consultas fan-out será citada. Una página nueva que no lo haga será recuperada, pero ignorada.
También vale la pena señalar que el grupo de páginas no citadas (~3M) en todo el ref_type de búsqueda es mucho más pequeño que el grupo citado (~23M), lo que limita la confianza con la que podemos interpretar la brecha de edad.
Donde la frescura importa más es en las “noticias”.
En esta categoría, las puntuaciones de relevancia del título para las páginas citadas y no citadas son casi idénticas:
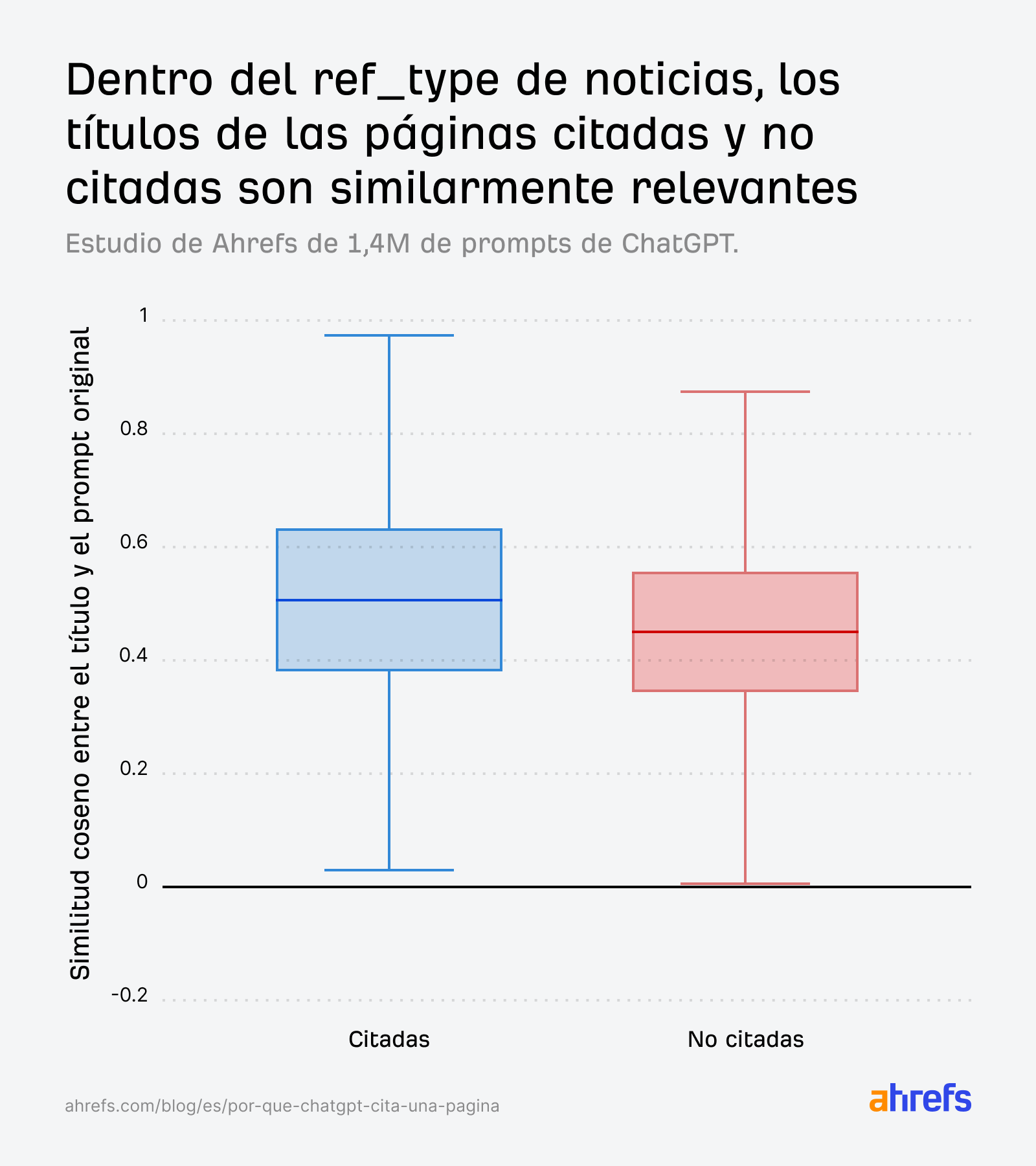
La IA no puede decidir basándose únicamente en la relevancia, por lo que recurre a un desempate temporal: la antigüedad de la página. Las páginas de noticias citadas tienden a ser más jóvenes:
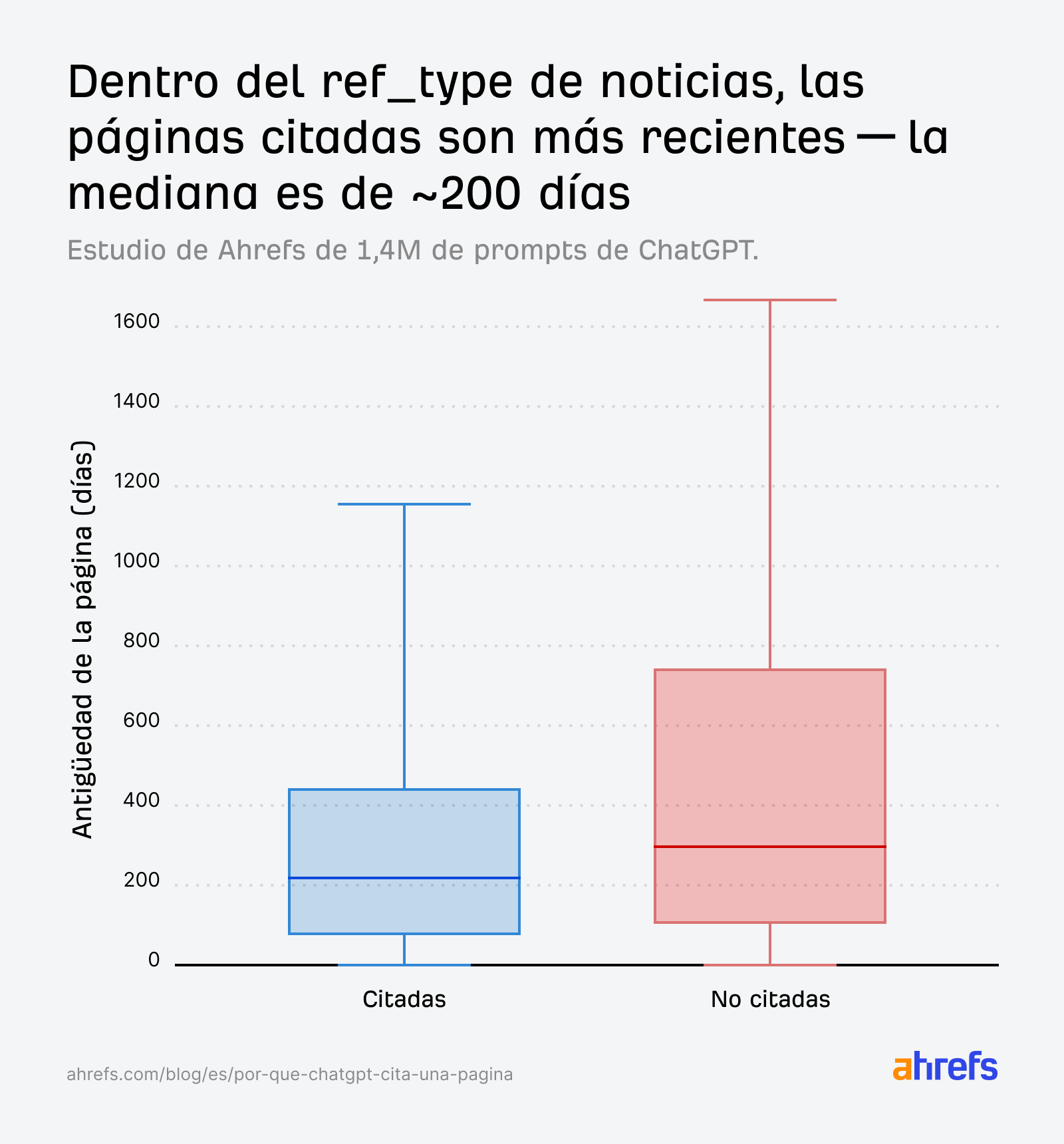
Para las consultas de noticias, las páginas más jóvenes tienen una clara ventaja, incluso cuando las puntuaciones de relevancia entre las páginas citadas y las no citadas son similares.
Si publicas noticias o contenido sensible al tiempo, la frescura no es negociable.
Sé el primero en dar la noticia de ciertas historias usando Firehose de Ahrefs: nuestra API de monitoreo web en tiempo real que te brinda un flujo de datos continuo desde nuestra enorme infraestructura de rastreo.
Por ejemplo, si trabajas en periodismo SaaS, puedes rastrear los cambios de contenido en páginas como el blog oficial de Google, para que puedas ser el primero en cubrir una nueva actualización de Google tan pronto como se publique.
Luego, usa el historial de menciones de Brand Radar en el informe de Respuestas de IA para rastrear si tu visibilidad en ChatGPT se dispara después de la publicación.
Los 1,4 millones de prompts pintan un panorama bastante claro. ChatGPT es un editor agresivo. Favorece su índice de búsqueda general, utiliza la similitud semántica para seleccionar y citar fuentes, y trata a Reddit como un libro de texto que le da vergüenza admitir que leyó.
Pero los datos también nos enseñaron una lección de precaución analítica.
Las comparaciones agregadas entre las URL “citadas” y “no citadas” pueden ser engañosas si el grupo no citado está dominado por un solo tipo de fuente con su propia mecánica de recuperación.
Lo que inicialmente parecía una paradoja —las páginas menos optimizadas siendo más citadas— resultó ser una cuestión de la composición del conjunto de datos.
Nos habríamos equivocado mucho en eso si no hubiéramos aislado por ref_type.
En última instancia, las páginas que se citan son aquellas cuyos títulos y contenido coinciden con las preguntas que ChatGPT está haciendo en segundo plano, y que afloran a través del canal de recuperación correcto.
¿Tienes preguntas? Estamos en LinkedIn y en X.

