
既然你在这里,相信你已经知道这件事情了。因此,让我们直接开始进入话题。
本文会教你如何解决以下这三个问题:
- 你的整个站点没有被索引;
- 一部分页面有索引,而其他的没有;
- 新发布的页面并没有呗即时索引。
但是首先,请确保我们保持一致,并充分理解索引的意义。
Google通过抓取来发现新的网页,然后将这些网页添加到索引中。他们使用称为Googlebot的网络爬虫来进行此操作。
很困惑?让我们来对一些名词做一些解释:
- 抓取:在网页上跟踪超链接以发现新内容的过程。
- 索引:将网页存储在庞大的数据库中的过程。
- 网络爬虫:一种执行抓取的程序。
- Googlebot:谷歌的网络爬虫。
这里是一个谷歌的视频,也讲述了这些过程中的细节:
当你在Google搜索内容时,其实是在要求Google返回其索引中的所有相关页面。 由于通常有成千上万的网页符合要求,因此Google的排名算法会尽力对网页进行排序,以便你会首先看到最好的和最相关的结果。
我这里要阐述的一个要点是,索引和排名是两个不同的事情。
索引为了是参与,而排名是为了获胜。
如果你都没有参与是不可能获得获胜的。
进入谷歌,然后进行如下搜索 site:你的网址.com
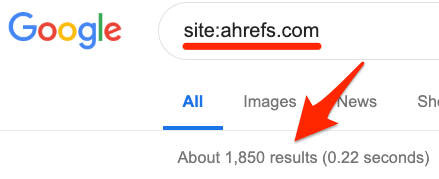
这里的数字显示的是谷歌大致的索引页面数量。
如果你想检查某个具体的页面是否被索引的话,同样也可以进行这样的操作site:详细的网址 运算符。
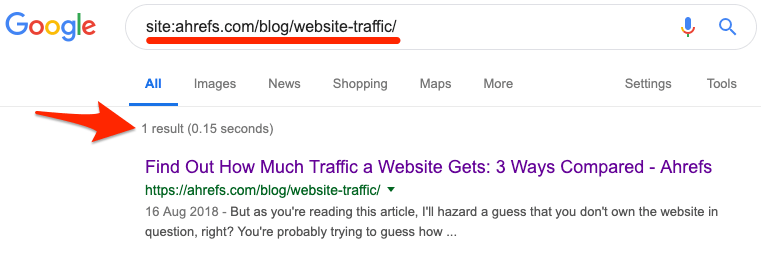
如果没有任何结果的话,就说明页面没有被索引。
如果你是Google Search Console的用户的话,你只需要查看覆盖率额报告就可以找到精准的索引数据。你只需要进入:
Google Search Console > Index > Coverage
Google Search Console > 索引 > 覆盖率
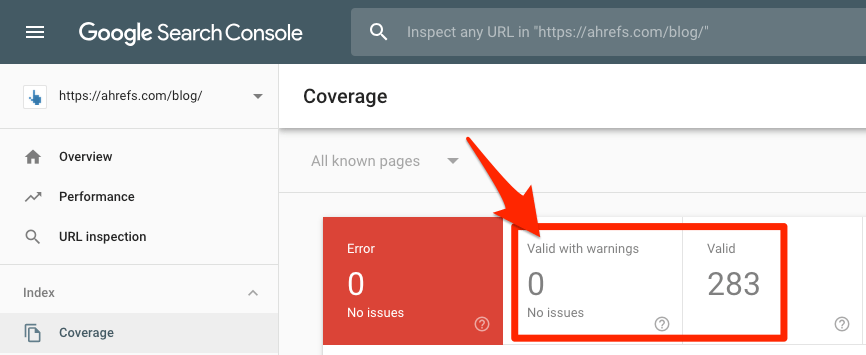
查看有效页面的数量(包括警告页面数量)。
如果这两个数字的总和不是零,那么Google至少会将你网站上的某些页面编入索引。 如果没有,那么你可能遇到严重的问题,因为你的网页均未被索引。
你可以使用Google Search Console来检测特定页面是否被索引。你只需要将页面URL放入URL检测工具中。
如果页面被索引,那么会显示“URL is on Google(URL在谷歌中)”。
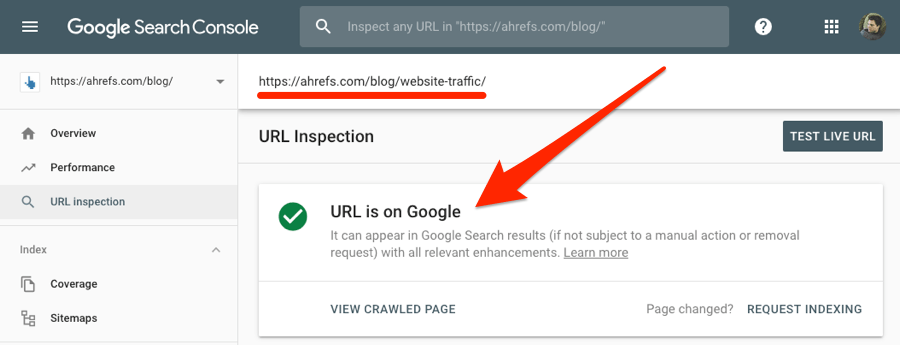
如果页面没有被索引,那么这里会显示“URL is not on Google(URL不在谷歌中)”
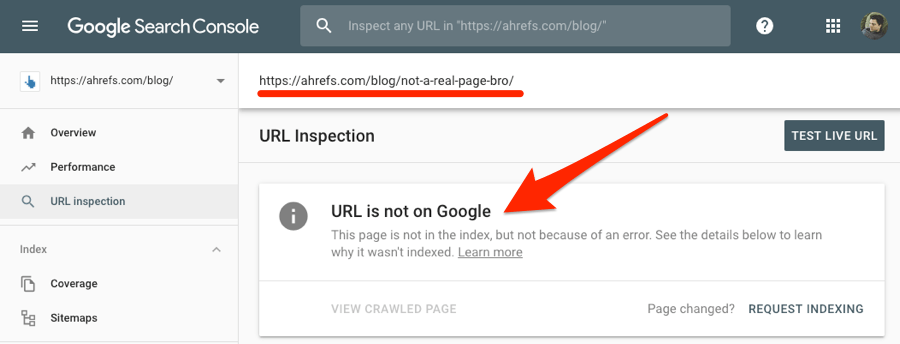
你的网站或者页面没有被谷歌索引?试下这些:
- 进入Google Search Console。
- 进入URL检测工具。
- 将需要索引的URL粘贴到搜索框中。
- 等待谷歌检测URL。
- 点击“请求编入索引”按钮。
当你发布新帖子或页面时,最好这么操作。你实际上是在告诉Google,你已经在网站上添加了一些新内容,它们应该去看看。
但是,请求编入索引不太可能解决旧页面的索引问题。 如果是这种情况,请按照下面的清单进行诊断并解决问题。
下方是一些解决方法的快速访问链接,你可能已经试过其中一些:
- 去除Robots.txt中的抓取阻碍
- 去除不必要的noindex标签
- 将需要索引的页面包含在网站地图中
- 去除不必要的canonical标签
- 检查页面是否是孤岛页面
- 修复不必要的内部nofollow链接
- 在“强力”页面中加入内部链接
- 确保页面独特并且有价值
- 去除低质量页面 (优化“抓取预算”)
- 建立高质量的外链
1) 去除Robots.txt中的抓取阻碍
Google没有索引整个网站?这可能是由于robots.txt文件存在抓取阻碍导致的。
进入yourdomain.com/robots.txt检查详细的问题。
检查是否右下方的这两段中的任意一个代码:
User-agent: Googlebot Disallow: /
User-agent: * Disallow: /
这两个都告诉Googlebot,不允许它们抓取网站上的任何页面。要解决此问题,你只需要删除它们,就这么简单。
如果Google没有为单个网页编制索引,也有可能是robots.txt中的某个代码导致的。要检查是否存在这种情况,请将URL粘贴到Google Search Console中的URL检测工具中。点击覆盖率板块以显示更多详细信息,然后查找“是否允许抓取? 否:被robots.txt阻止”错误。
这就代表,页面被robots.txt阻止了。
如果是这种情况,请重新检查你的robots.txt文件中是否有与该页面或相关目录有关的“禁止”规则。

在需要的情况下移除这段代码即可。
2) 去除不必要的noindex标签
如果你告诉谷歌不索引某个网页,谷歌是不会为其编制索引的。这可以让一部分页面保持隐秘。有两种方法可以做到这一点:
方法1:meta标签
在页面的<head> 中如果出现如下任意代码,则不会被谷歌索引:
<meta name=“robots” content=“noindex”>
<meta name=“googlebot” content=“noindex”>
这是一个针对爬虫的meta标记,它告诉搜索引擎它们是否可以为该页面编制索引。
如果你想找到网上所有拥有noindex meta标签的页面,你只需要使用 Ahrefs’ Site Audit(网站诊断)做个检测即可。然后进入Indexability (可索引性
)报告。寻找“Noindex page(不索引页面)“提示。
点击后查看所有被屏蔽的页面。删除那些需要索引页面的noindex meta标签。
方法2:X‑Robots-Tag
网络爬虫遵循X-Robots-Tag的HTTP响应标头。你可以使用服务器端脚本语言(例如PHP)、. htaccess文件中的内容或通过更改服务器配置来实现此效果。
Google Search Console中的URL检查工具可告诉你,是否是由于此标头而阻止Google抓取页面。只需输入URL,然后查找“允许索引?否:在“ X‑Robots-Tag” http标头中检测到“ noindex”标记。

如果你想检测整个站点是否存在这样的问题,那么可以使用Ahrefs’ Site Audit tool(网站诊断)工具,并且在Page Explorer (页面分析)筛选框中选择“Robots information in HTTP header(检查HTTP表头的Robots信息)”进行查看:
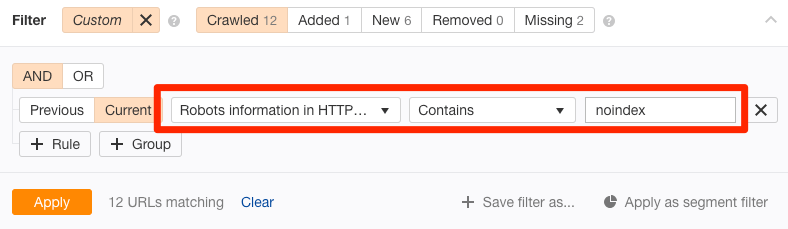
同时,告诉网站开发者,修改需要要索引的页面的表头。
推荐阅读: 使用X-Robots-Tag HTTP表头进行特定的SEO:技巧和窍门
3) 将需要索引的页面包含在网站地图中
网站地图会告诉Google网站上的哪些页面很重要,哪些不重要。它同时也可以为谷歌的抓取频率做一些指导。
Google应该能够在你的网站上找到网页,无论它们是否在站点地图中,但将它们包括在网站地图内仍然是一种很好的做法。毕竟,没必要让谷歌进行毫无意义的抓取。
要检查网页是否在你的站点地图中,请使用Google Search Console中的URL检查工具。如果你看到“URL不在Google上”和“站点地图:不适用”,则表明该URL不在你的站点地图中或未建立索引。
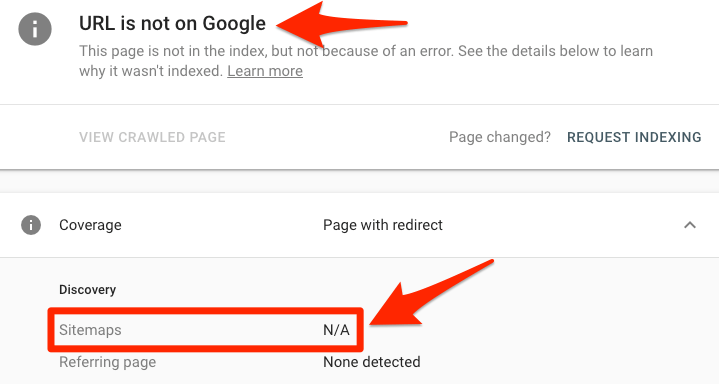
没有使用Google Search Console?进入你的网站地图,通常是这个地址:yourdomain.com/sitemap.xml,然后搜索这个页面的URL。

或者,你想找到所有的不在网站地图中,但有需要索引的页面,你只需要使用你Ahrefs’ Site Audit(网站诊断)。进入Page Explorer (页面分析),并进行如下筛选:
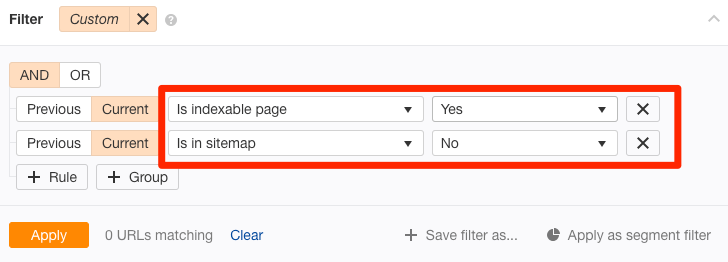
这些页面应该在你的网站地图中,所以添加进去。添加后,通过下方的Ping方法告诉谷歌你已经更新了这个网站地图。
http://www.google.com/ping?sitemap=<完整的网站地图地址>
将后方的提示换成你的网站地图地址,你应该可以收到下方这样的消息:

这样可以让谷歌加速索引你的页面。
4) 去除不必要的canonical标签
Canonical标签会告诉Google哪个是页面的首选版本。它看起来像这样:
<link rel=“canonical” href=“/page.html”/>
大多数页面没有canonical标签,也就是所谓的自引用的canonical标签。这就告诉Google该页面本身就是首选版本,同时可能是唯一的版本。换句话说,你希望对该页面建立索引。
但是,如果你的页面有不规范的canonical标签,那么有可能在告诉Google错误的首选版本。在这种情况下,你的页面将不会被索引。
检测canonical标签,你只需要使用谷歌的URL检测工具。如果你的页面的canonical标签指向了另外一个页面被,你看可以看到“具有Canonical标签的备用页面”的提示。
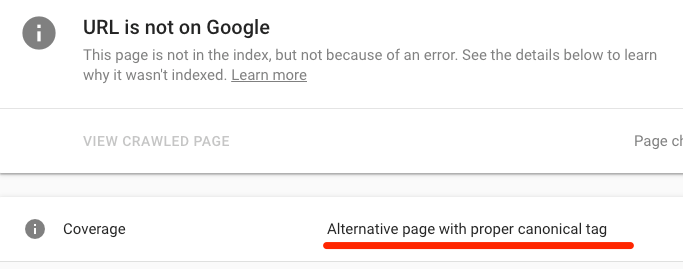
如果这个不应该出现,你希望当前页面被索引,那么只需要去除该页面的canonical标签即可。
请注意,canonical标签并不总是不好的。带有这些标签的大多数页面都会有它们的原因。如果你看到你的页面具有canonical标签,请检查对应的页面。如果确实是该页面的首选版本,并且也无需索引该页面,则应该保留canonical标记。
如果你想快速找到整个站点上有问题的canonical标签,可以使用Ahrefs’ Site Audit(网站诊断)工具进行检测,进入Page Explorer (页面分析)并使用以下设置:
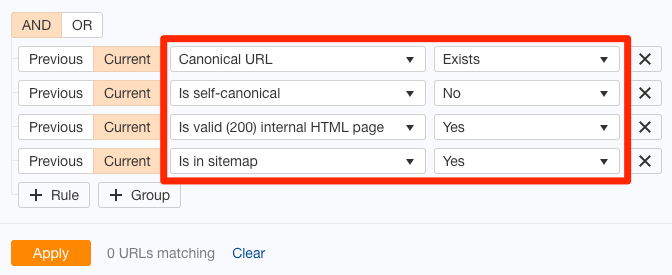
这会在站点地图中查找带有非自引用canonical标签的页面。几乎可以肯定的是,你希望对站点地图中的页面建立索引,因此,如果此过滤器返回任何结果,则你需要进一步进行排查。
这些页面很可能具有错误的canonical标签,或者一开始就不应该放在你的网站地图中。
5) 检查页面是否是孤岛页面
孤岛页面指的是那些没有内部链接支撑的页面。
由于Google通过抓取链接发现新内容,因此他们无法通过该过程发现孤岛页面。网站访客也将无法找到这些内容。
为了检测孤岛页面,尝试使用Ahrefs’ Site Audit(网站诊断)工具。然后点击 Links(链接)报告,并查看“孤岛页面 (没有任何指向链接)”错误:

这会显示出所有可索引、在站点地图中显示的、但没有内部指向链接的所有页面。
这个只有在下方两种情况下才能够正常检测出结果:
- 所有需要索引的页面都在你的网站地图中。
- 在Ahrefs的Site Audit(网站诊断)最开始,将选择使用网站地图中的页面选项打勾。
不确定要索引的所有页面都在站点地图中吗?尝试这个:
- 下载你网站上的所有页面 (可以通过你的CMS来实现)
- 抓取你的整个站点 (使用像Ahrefs Site Audit(网站诊断)这样的工具)
- 对比两组URL。
任何没有在抓取时找到的URL都属于孤岛页面
你可以通过以下两种中任意一个方法解决孤岛问题:
- 如果页面不重要,那么将它删除,并移出网站地图。
- 如果页面和重要,将他放到你的内链结构中去。
6) 修复不必要的内部nofollow链接
Nofollow链接指的是那些有着 rel=“nofollow” 标记的链接。它们会组织 PageRank 的传递。同时谷歌并不会抓取Nofollow链接。
这里是谷歌针对这个做的说明:
本质上,使用nofollow会导致我们从抓取目录中删除目标链接。但是,如果其他网站在不使用nofollow的情况下链接到目标页面,或者这些URL是在站点地图中提交给Google的,则目标页面仍可能会出现在我们的索引中。
简而言之,你需要确保指向索引页面的链接是follow状态的。
为此,请使用Ahrefs的Site Audit(网站诊断)工具对网站进行抓取。检查Links(链接)报告中是否出现“Page has nofollow incoming internal links only(页面仅具有nofollow的指向链接)”的错误:

假设你要Google索引该页面,请从这些指向链接中删除nofollow标记。如果不是,请删除该页面或对该页面进行noindex处理。
推荐阅读: Nofollow链接 VS Follow链接:所有你需要了解的知识
7) 在“强力”页面中加入内部链接
Google通过抓取你的网站来发现新内容。如果你忽略了内部链接到相关页面,则它可能找不到这个页面。
解决此问题的一种简单方法是在网站中添加一些内部链接。你可以在建立索引的任何网页上执行此操作。但是,如果你希望Google尽可能快地为页面建立索引,则可以在一些“强力的”页面上建立一些内部链接。
为什么?因为相比于一些不太重要的页面,Google会更快地抓取此类页面。
做法就是,进入Ahrefs Site Explorer(网站分析),输入你的域名,并查看 Best by links(最佳链接)报告。
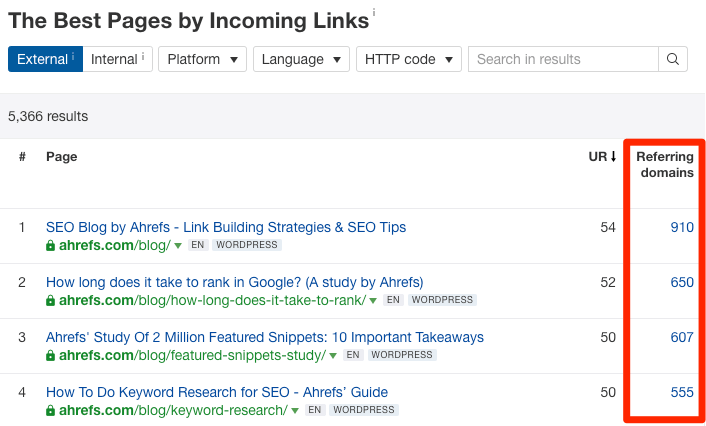
这将显示网站上的所有页面,按URL Rating(网址评分)进行排序。换句话说,它首先显示的是权重最高的页面。
查看列表并查找相关页面,可以在这些页面上添加一些目标页面的内部链接。
例如,如果我们希望对客座博客指南文章进行内链的制作,那么链接建设指南这个页面就可以提供一个相关的内部链接。该页面恰好是我们博客上第11个最权威的页面:

然后,当Google下次重新抓取页面时,就会看到并抓取该链接。
在你添加完内部链接之后,将该页面粘贴到Google的URL检查工具中。点击“请求编入索引”按钮,以使Google知道页面上的某些内容已更改,它需要尽快对其进行重新抓取。这可以加快Google发现内部链接并因此发现你要索引的页面的进程。
8) 确保页面独特并且有价值
Google不太可能将低质量的网页编入索引,因为它们对用户没有任何价值。以下是Google的John Mueller对2018年建立索引的看法:
We never index all known URLs, that’s pretty normal. I’d focus on making the site awesome and inspiring, then things usually work out better.
— 🍌 John 🍌 (@JohnMu) January 3, 2018
他暗示,如果你希望Google将网站或网页编入索引,则它必须“有价值并且有意义”。
如果你的页面已经排除了技术问题但还是不索引,那么可能就是页面的价值不足。因此,你需要重新审视页面并问自己:这个页面真的有价值吗?如果用户从搜索结果中点击该页面,会在该页面找到有用的内容吗?
如果对上述两个问题的回答均为否,那么你就需要改进你的内容。
你可以通过 Ahrefs Site Audit tool(网站诊断)工具以及 URL Profiler 工具来找到那些低质量的页面。 进入Ahrefs的Site Audit(网站诊断)中的Page Explorer (页面分析)板块,并且进行如下设置:
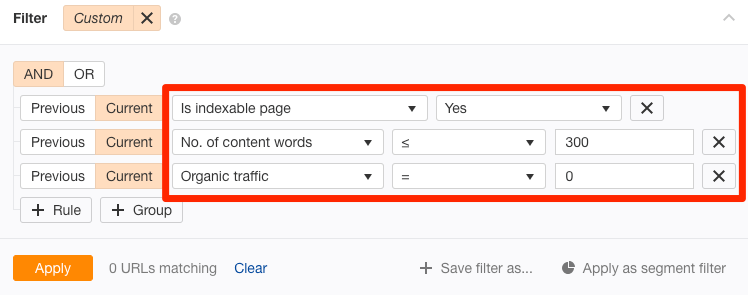
这个可以反馈那些内容比较单薄的页面,当前这些页面也没有自然流量。换句话说,它们没有被索引的可能性很大。
将报告导出后,将所有的链接站跳到URL Profiler工具中,并且做一个谷歌索引检测。
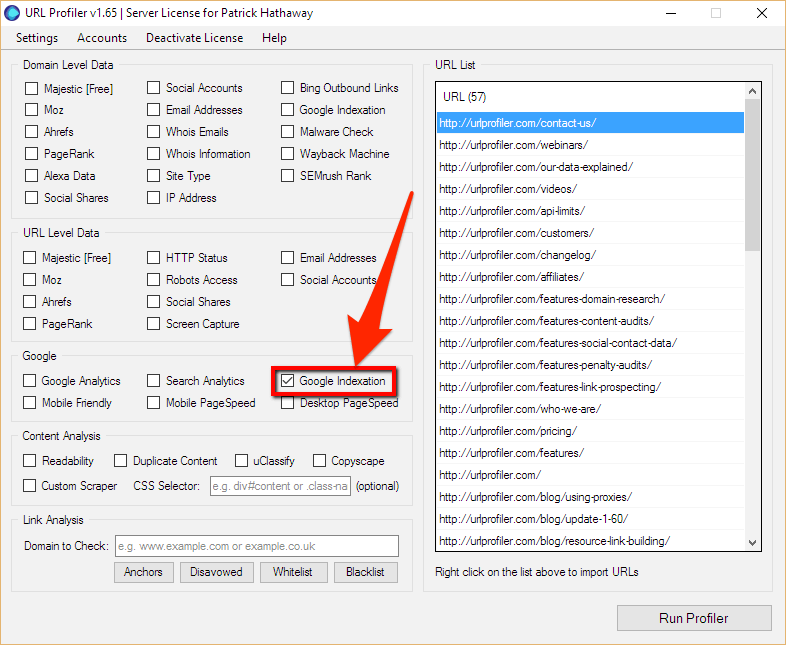
如果你要对很多页面(即超过100个页面)进行此操作,建议使用代理。否则,你将面临被Google禁止使用IP的风险。如果你无法这么做,那么另一种选择是在Google上搜索“free bulk Google indexation checker(免费批量Google索引检查器)”。有一些这样的工具存在,但大多数一次只能限制在25页以下。
检查所有未编入索引的页面是否存在质量问题。进行必要的改进,然后在Google Search Console中请求重新请求编入索引。
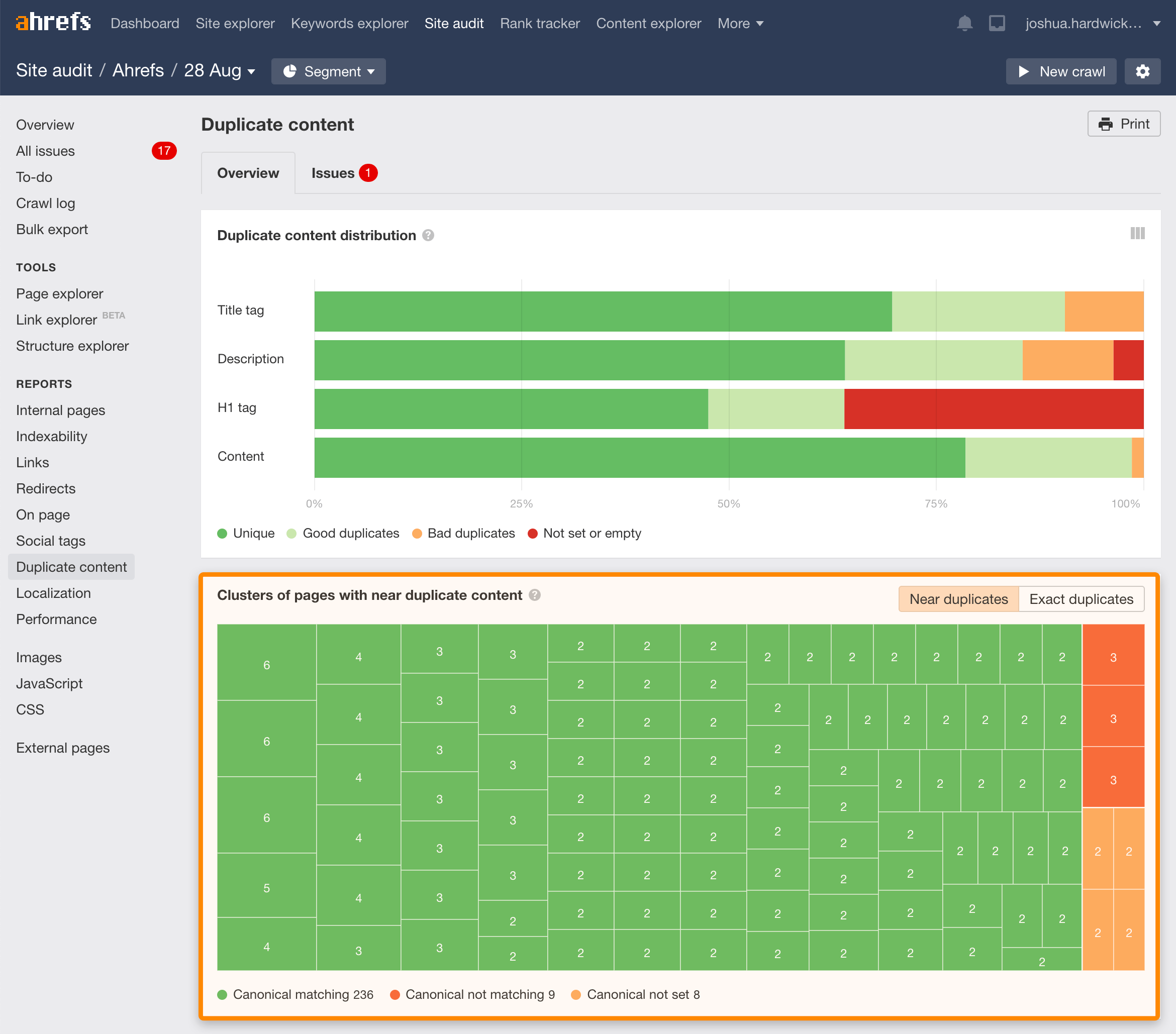
同时你也需要注意重复内容的问题。 Google不太可能索引重复或几乎重复的页面。使用Site Audit(网站诊断)中的 Duplicate content(重复内容)报告来检查这些问题。
9) 去除低质量页面 (优化“抓取预算”)
网站上的劣质页面过多,会浪费谷歌的抓取预算。
这里是 谷歌对此做的说明:
在低价值页面上浪费服务器资源,会使抓取有价值内容的频率下降,这可能会导致在站点上发现大量新内容时出现延迟。
可以将其视为导师在给论文进行评分,其中一个就是你的论文。如果他们要审阅10篇论文,那么他们很快就会看到你的论文。如果他们要审阅一百个,那将花费更长的时间。如果有成千上万的话,那么他们的工作量就太高了,他们可能永远也无法对你的内容进行打分。
Google确实指出:抓取预算[…]并不是大多数站长都需要担心的事情,并且“如果网站的页面少于几千个”,则都可以对其进行有效的抓取。
不过,从你的网站上删除低质量的页面绝不是一件坏事。它只会产生积极影响。
你可以用我们的内容检测模板来检测那些有问题、不相关并可以删除的页面。
10) 建立高质量的外链
外链告诉Google这个页面很重要。毕竟,如果有人链接到它,则它必须具有一定的价值。这些是Google想要索引的页面。
Google不仅会索引带有外链的网页。有很多(上亿的)没有外链的页面也编入了索引。但是,由于Google认为具有高质量链接的页面更为重要,因此与不具有高质量链接的页面相比,它们抓取和重新抓取的速度可能更快。这会使得索引边的更快。
我们的博客中有很多关于如何获得高质量外链的做法。
看看下面一些外链的指南:
索引 ≠ 排名
在Google上获得索引,并不代表你能获得排名或者是流量。
这是两个不同的东西。
索引意味着谷歌已经看到了你的网站,但是并不意味着你的内容值得谷歌对特定关键词进行排序。
这就是SEO需要做的——优化网页以针对特定关键词进行排名的艺术。
简单的来说,SEO包含:
- 找到你的用户在搜索什么;
- 围绕话题创作内容;
- 针对目标关键词进行优化;
- 外链建设;
- 对页面内容进行更新,保持“新鲜”。
这里有一个视频可以让你开始进行SEO:
… 以及一些文章:
最后
Google不索引你网站或页面的原因只有两个:
- 技术性问题导致它无法索引;
- 它认为你的内容没有价值,不值得被索引。
这两个问题很可能同时存在。但是,我想说技术问题要普遍得多。技术问题还可能导致低质量内容的自动生成(例如,分页问题)。
尽管如此,通过上面的检查表多数是可以解决索引问题的。
只要记住索引≠排名即可。如果你想对任何有价值的关键词进行排名,并吸引源源不断的自然流量,那么SEO就是至关重要的。
译者,Park Cheng,魔贝课凡联合创始人。


