Sadly, this happens all the time.
Here’s a screenshot of a link to Ahrefs’ Content Explorer in an article by Copy.ai:

This is a nice link from a page on a site with a Domain Rating (DR) of 93.
But take a look at that article now. The link is no more. It’s gone.

That would sure be a nice link to reclaim, right?
Yes. It would. The same goes for the hundreds of other links we’ve lost in the past couple of months. Which is where link reclamation comes in.
Link reclamation is the process of reclaiming lost links. You had a link. You lost it. You want it back. So you take steps to try to reclaim it.
What steps, I hear you ask?
It depends why you lost the link in the first place.
Here are four common reasons for link losses:
- Link removed. The author removes your link from the linking page
- Linking page deleted. The linking page no longer exists (404 error)
- Linking page redirected. The linking page gets (301) redirected
- Linking page noindexed. The linking page is no longer indexed in Google*
I’ve starred (*) that last reason because it’s not technically a lost link. It still exists. But because the page isn’t indexed, it probably isn’t going to be as valuable.
Understanding the nuances associated with each “reason” is the key to taking action to reclaim the links. Keep reading to learn how.
Link reclamation vs. claiming unlinked brand mentions
Here is an unlinked mention:

Ahrefs is cited, but there’s no link.
You could argue that this should be a link. In which case, attempting to convert this to a linked mention would be a form of link reclamation, right?
Before I started writing the original version of this guide back in 2018, I made this exact point to Tim (my boss), to which he responded:

Mind. Blown.

You can’t reclaim a link you never had in the first place.
So this guide is all about reclaiming lost backlinks.
But…
If this post by Antonio Gabric is to be believed, the answer is yes—and very well. He says he reclaimed 31 backlinks from just 166 outreach emails. That’s an 18.67% conversion rate, which is pretty much unheard of in link outreach these days.
But the reality is that results can differ by industry, brand, and how you built or earned the links in the first place.
In fact, I think Antonio got such good results because he was clearly attempting to reclaim links built through “win win collaborations.” In other words, they were either paid backlinks or ones acquired through shady tactics like link exchanges:
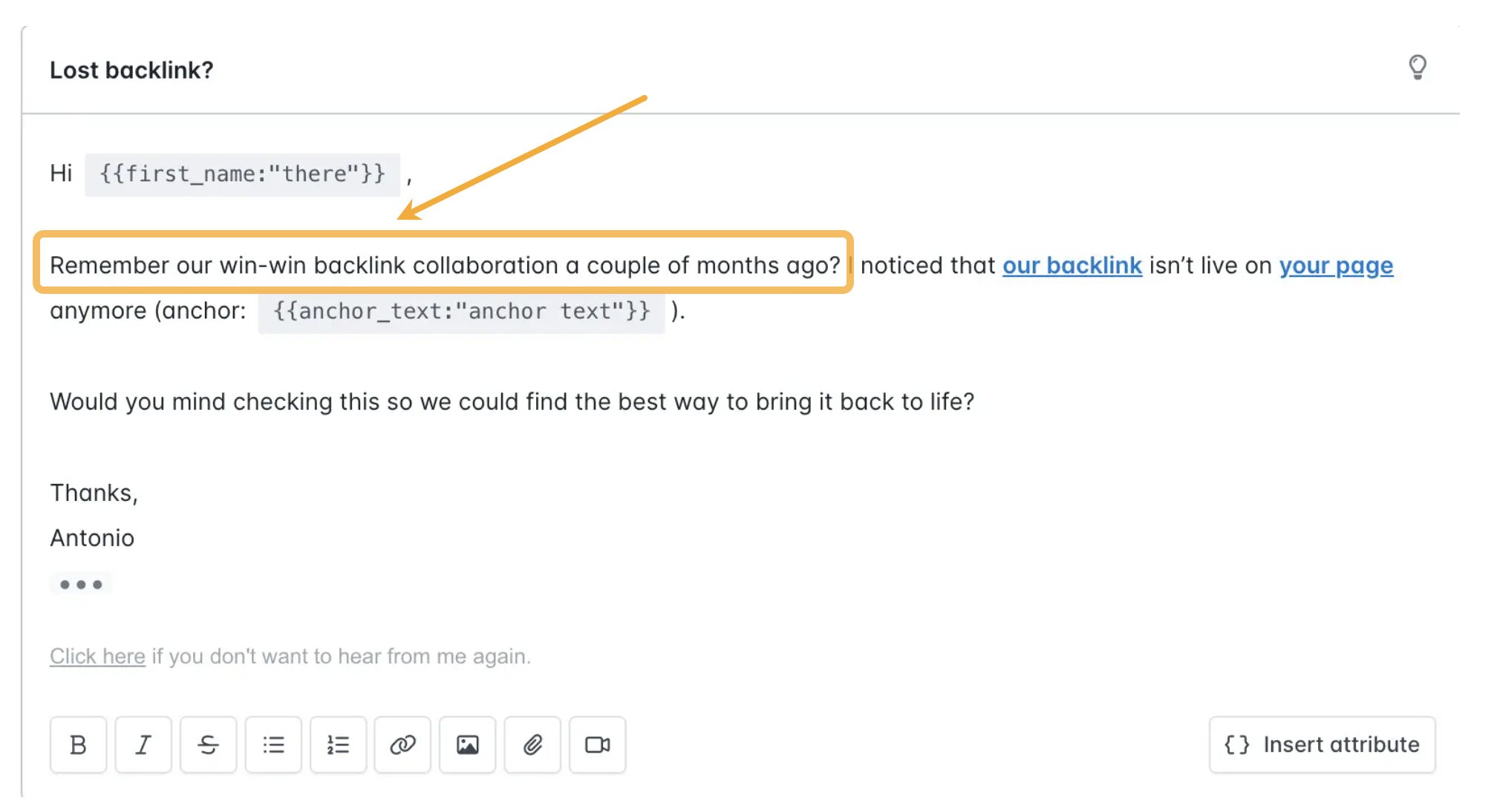
It makes sense to expect the other party to hold up their end of the bargain when a deal is made, so this likely explains Antonio’s stellar results.
Still, link reclamation is a simple tactic that’s rarely a big time investment once you have things set up. This can make it well worth doing even if conversation rates are relatively low.
Bottom line? As with all link building tactics, you won’t know how well link reclamation works for you until you try it.
Follow these two simple steps.
1. Find lost links with Site Explorer
Site Explorer > enter your domain > Backlinks > Lost
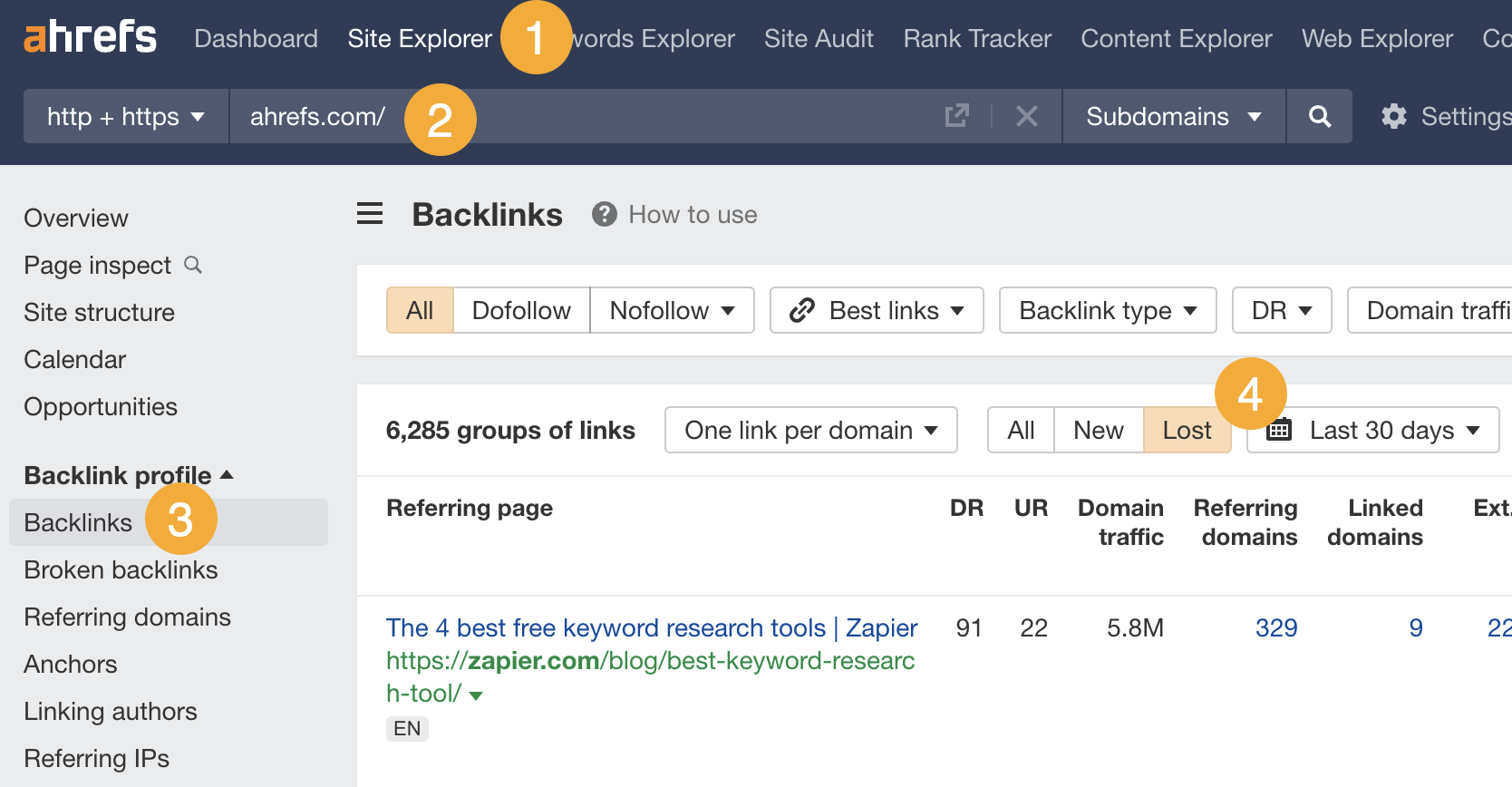
Here you will see all the backlinks you’ve lost during the past 30 days.
For ahrefs.com, I see 6,285 lost links.

But the reality is that most of those links won’t be worth trying to reclaim. Many will just be junk that weren’t helping you to rank anyway.
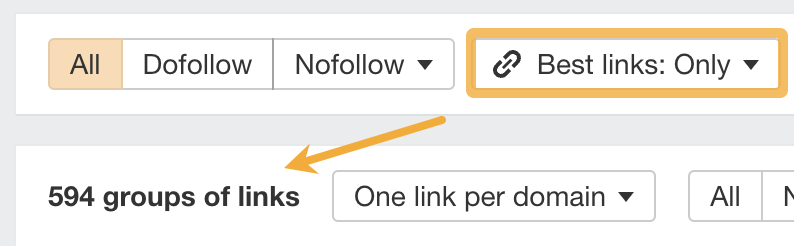
To find links worth reclaiming, set the “Best links” filter to “Show best links only.”
If we do this for Ahrefs.com, 6,285 immediately drops to 594.
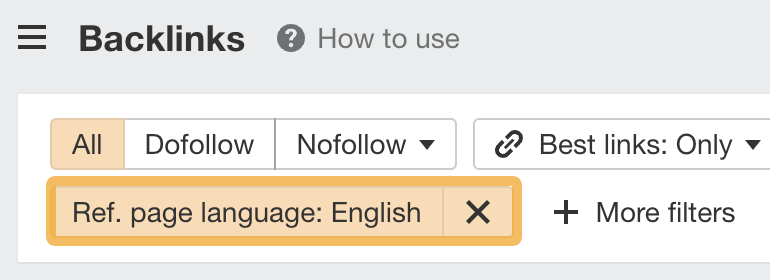
If you’ll only be doing link outreach in a particular language, it’s worth filtering for links from pages in that language too.
2. Pick the best opportunities
How you approach reclaiming a lost link will depend on the reason for its loss. Some may not even be worth trying to reclaim at all (more on that in a moment).
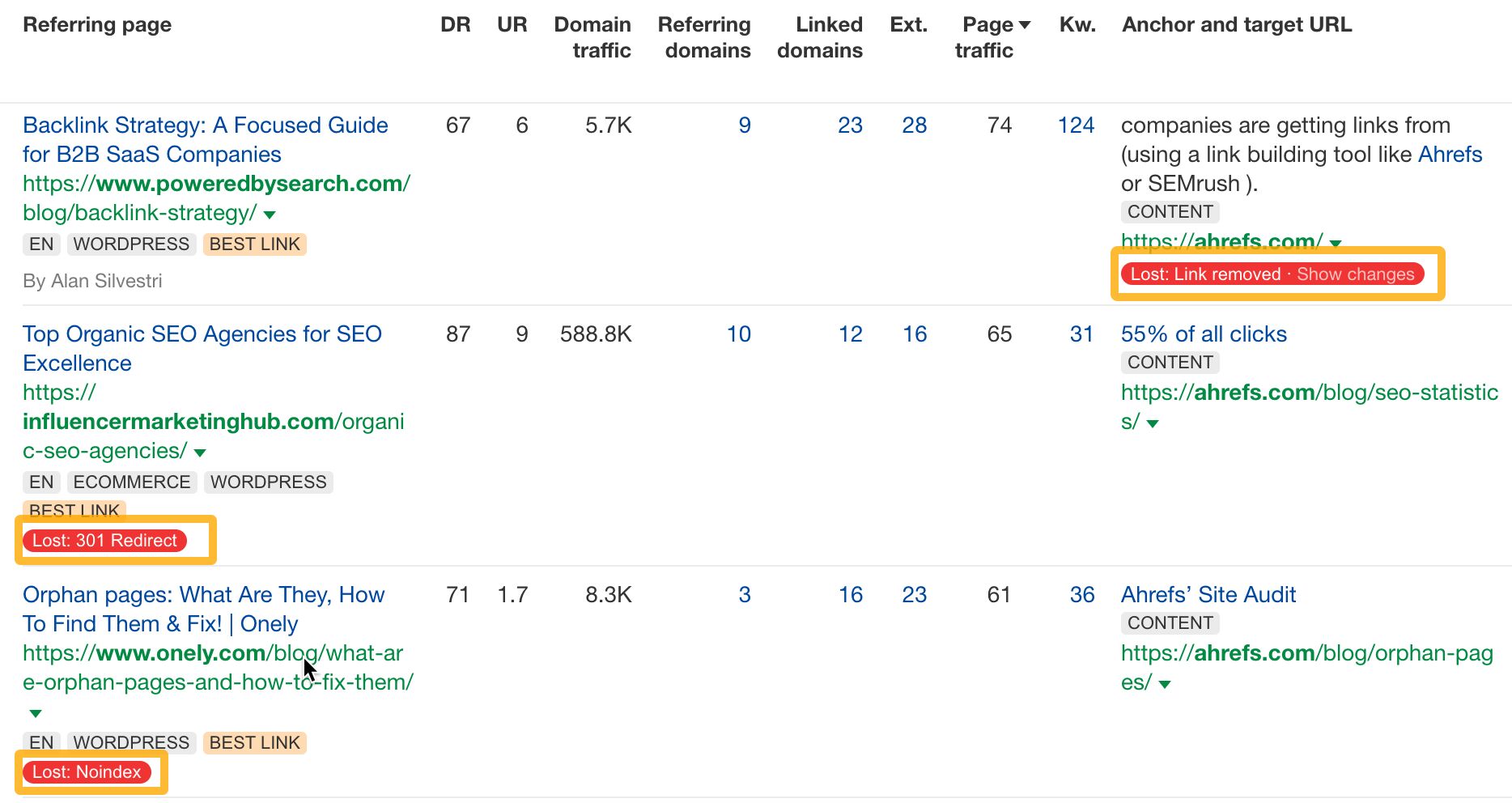
In Ahrefs, we label every link with a link loss reason:
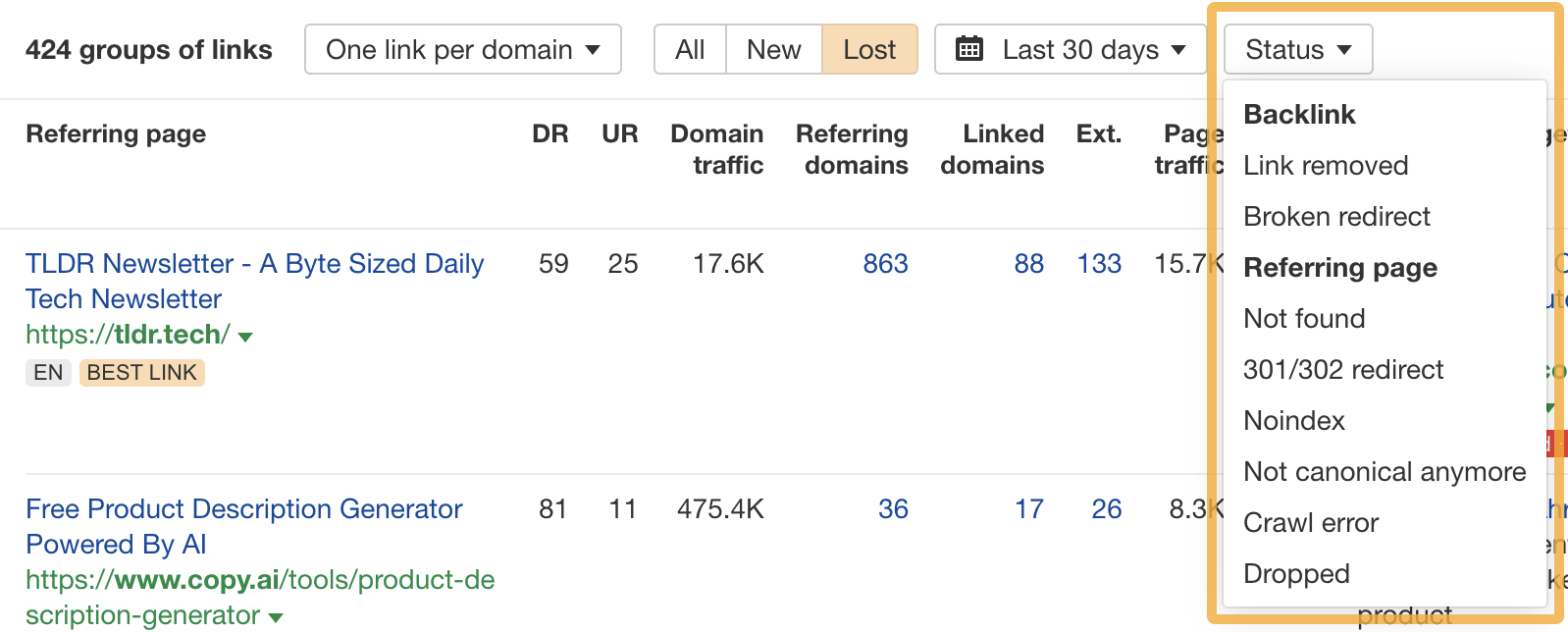
You can also filter by link loss reason:
Let’s tackle if and how to handle each reason for link loss.
Link removed — Often worth pursuing
This means the link disappeared from the linking page.
Here are three common reasons this can happen:
- They refreshed their content, removing some external links in the process.
- They replaced your link with something better.
- They implemented a policy banning external links.
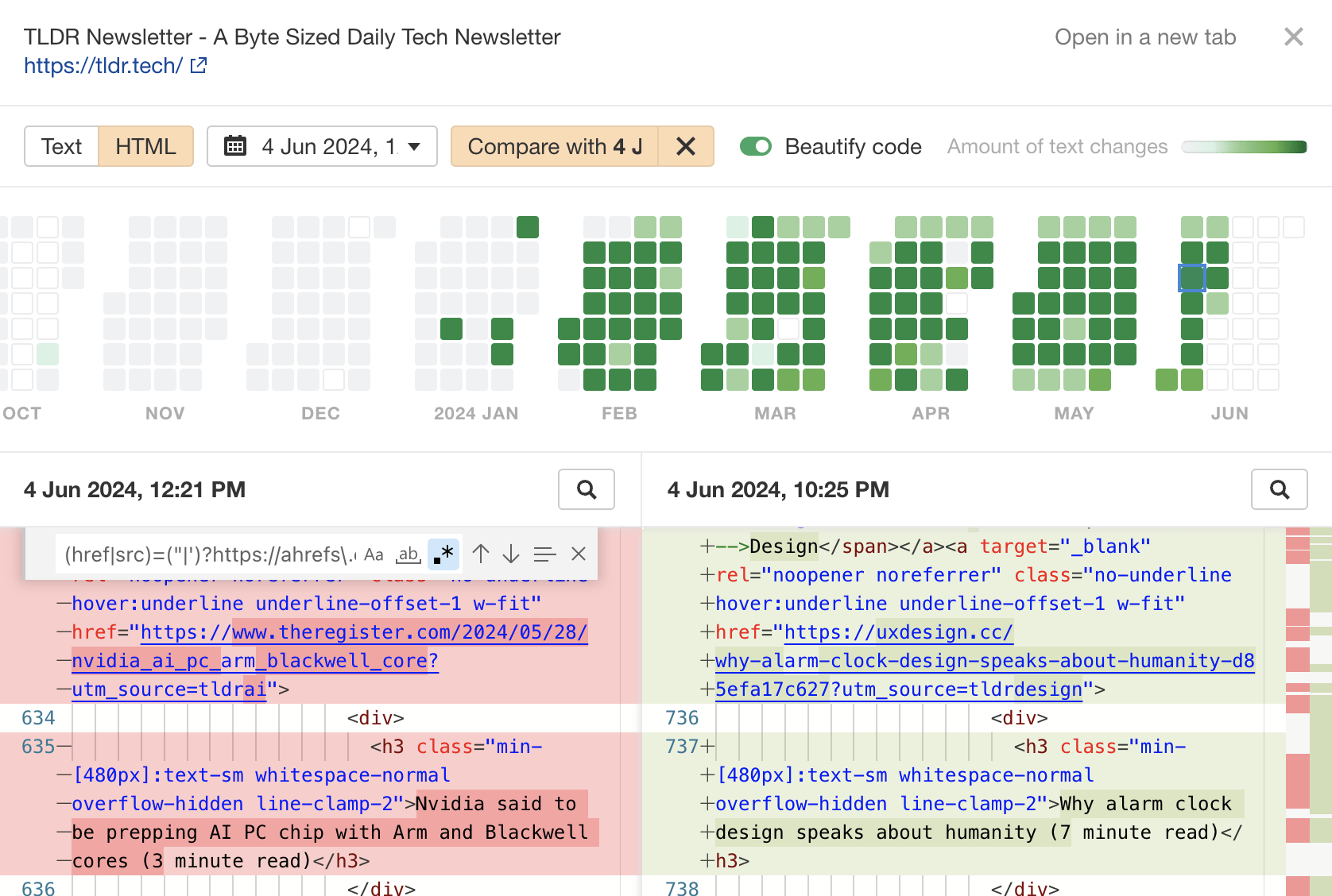
You can use the Page Inspect feature in Ahrefs to figure out which reason it is. Hit “Show changes” next to the link loss reason to bring it up.

You should see the HTML of the page before and after the link was removed. Removed sections are highlighted red, and new sections are highlighted green.
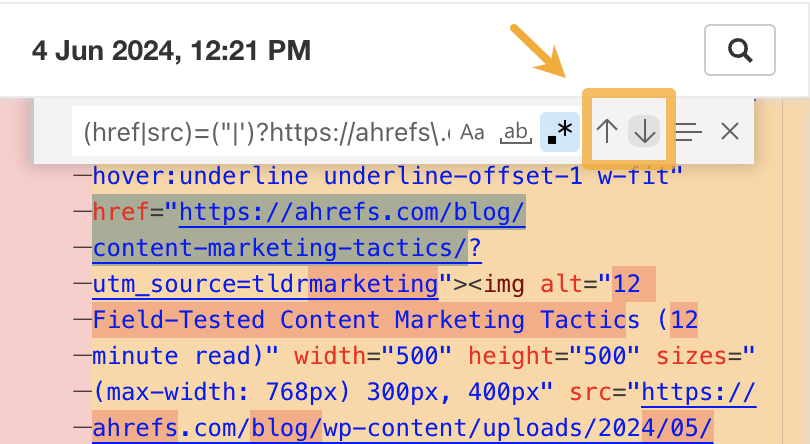
To quickly scroll to links you may have lost, use the up/down arrows in the search box on the left:
For example, here’s a link to our website that was replaced:

Here’s how to figure out the reason for the link loss:
- If the content is completely different, it’s probably a content update. Seeing lots of red and green in Page Inspect is a telltale sign of this. Check if your link would add value to the refreshed content and if so, pitch them.
- If your link has been replaced, they probably because they found a better resource. Reach and ask why they replaced it. Get feedback, improve. This will prevent more link losses. They may even reinstate your link if you improve your content.
- If your link has been removed along with many others, they probably have a new external links policy. Don’t pitch. There’s not much you can do about this.
Not found — Sometimes worth pursuing
This means the linking page couldn’t be found during our last crawl.
There are three reasons this can happen:
- The site owner deleted the page intentionally
- The site owner deleted the page accidentally
- For some reason we couldn’t access the page when crawling. This might be because the site was temporarily down.
I would only recommend pursuing these opportunities if you think the page got deleted accidentally.
To check if the page was deleted, click to visit the referring page.
Here’s one that no longer exists from WPShout:
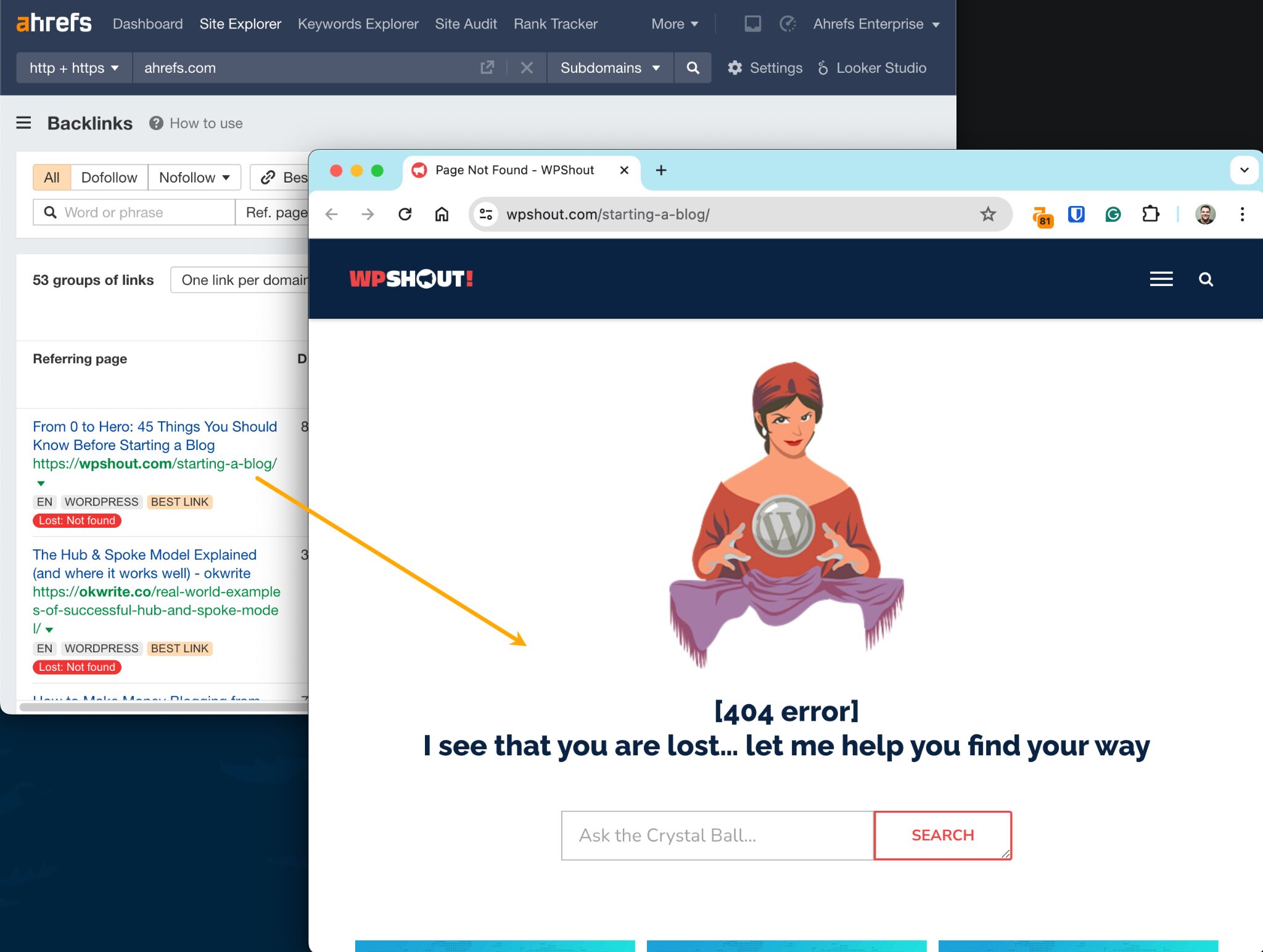
There’s no way of knowing for sure if it was deleted accidentally, but the page having lots of backlinks is usually a sign of this. After all, no sane SEO-savvy website owner would delete such a page without redirecting it.
To see how many links the referring page has, hit the caret next to the URL:
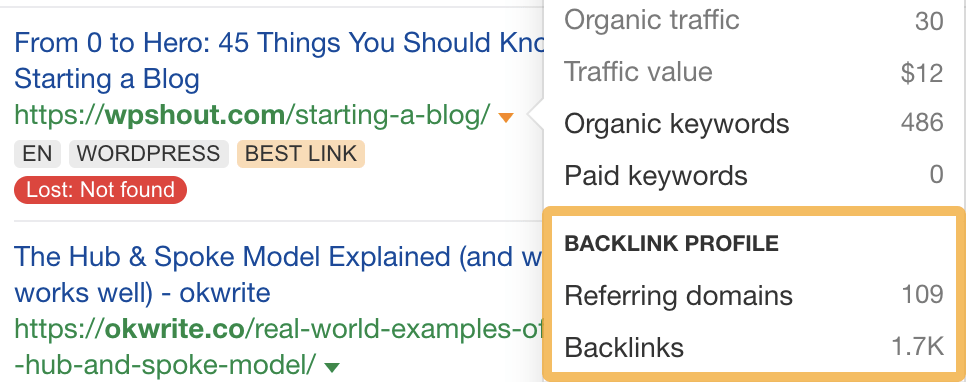
In this case, the page has backlinks from 109 websites.
That’s quite a lot, so it may be worth sending a quick “Hey, Just noticed that your page about ____ is broken. Did you mean to delete it?” email.
Give broken link building a shot. This is where you create a similar page, then reach out to everyone linking to the dead resource and suggest they replace it with yours. It can work very well if you find a dead page with a lot of good backlinks.
Broken redirect — Sometimes worth pursuing
This means the linked redirecting URL couldn’t be followed to its “destination” page during the most recent crawl.
There are a few reasons this can happen:
- Not redirected anymore: Linked URL (or one of the links in the redirect chain) is no longer redirecting.
- Not canonicalized anymore: Linked URL’s declared canonical changed.
- Destination changed: Linked URL now redirects to a different location.
Unless any of these things happened by mistake, there’s no link reclamation opportunity to pursue here. These links are reported as lost because of changes made on your website.
For example, we recently moved our API documentation. In doing so, we redirected the old URL to the new one. This then gets reported as a lost link.

Here’s another example:
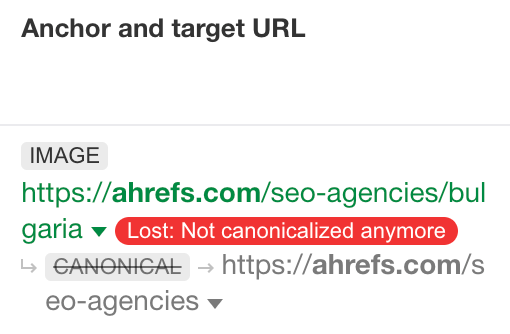
This time, the declared canonical changed. Our list of SEO agencies in Bulgaria previously canonicalized to the homepage of our SEO agencies directory. I’m not close to this project, but I’m guessing this was because there were no agencies listed in this section so we didn’t want it indexed.
Now there are three agencies, so it makes sense to remove the canonical that pointed to the main page and have Google index the actual page:
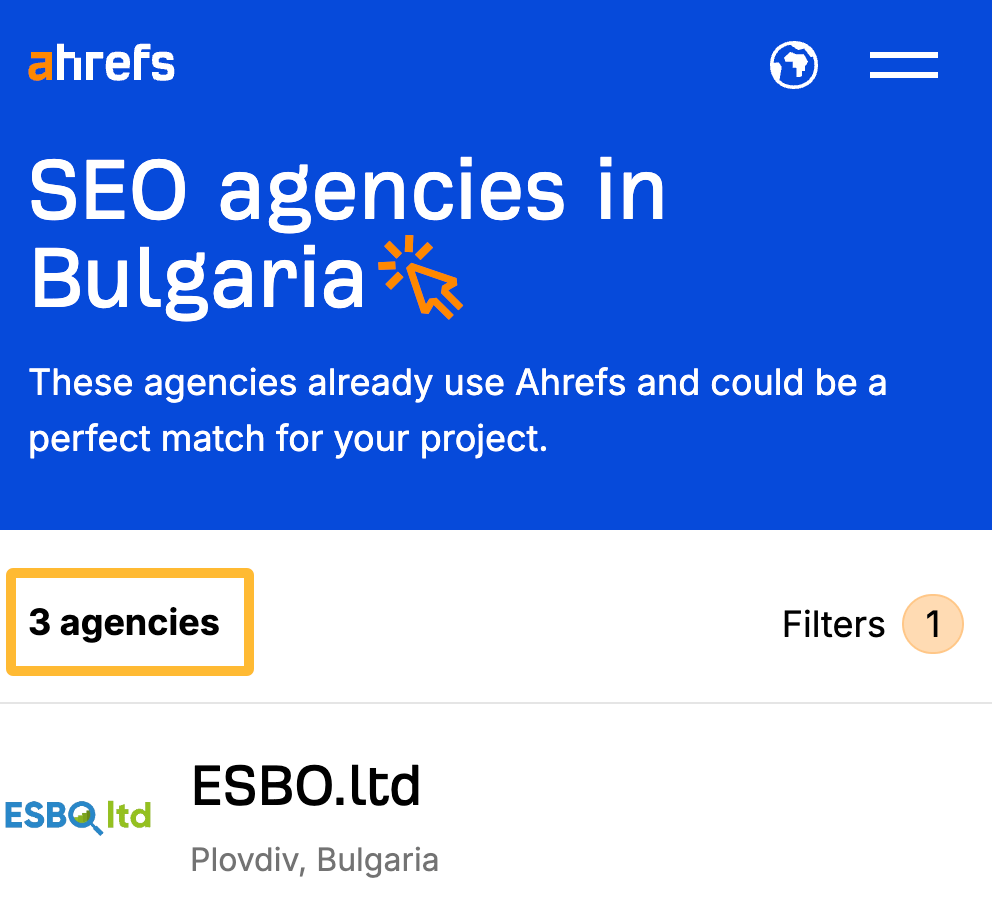
In both of these cases, there’s no link reclamation opportunity because they’re the result of changes we intended to make.
The only time there might be a link reclamation opportunity is when redirects are removed by mistake, leading to 404s with backlinks. But, to be honest, it’s much easier to spot these opportunities by filtering the Best by Links report for the most linked dead pages. You can then just redirect them to wherever makes sense.
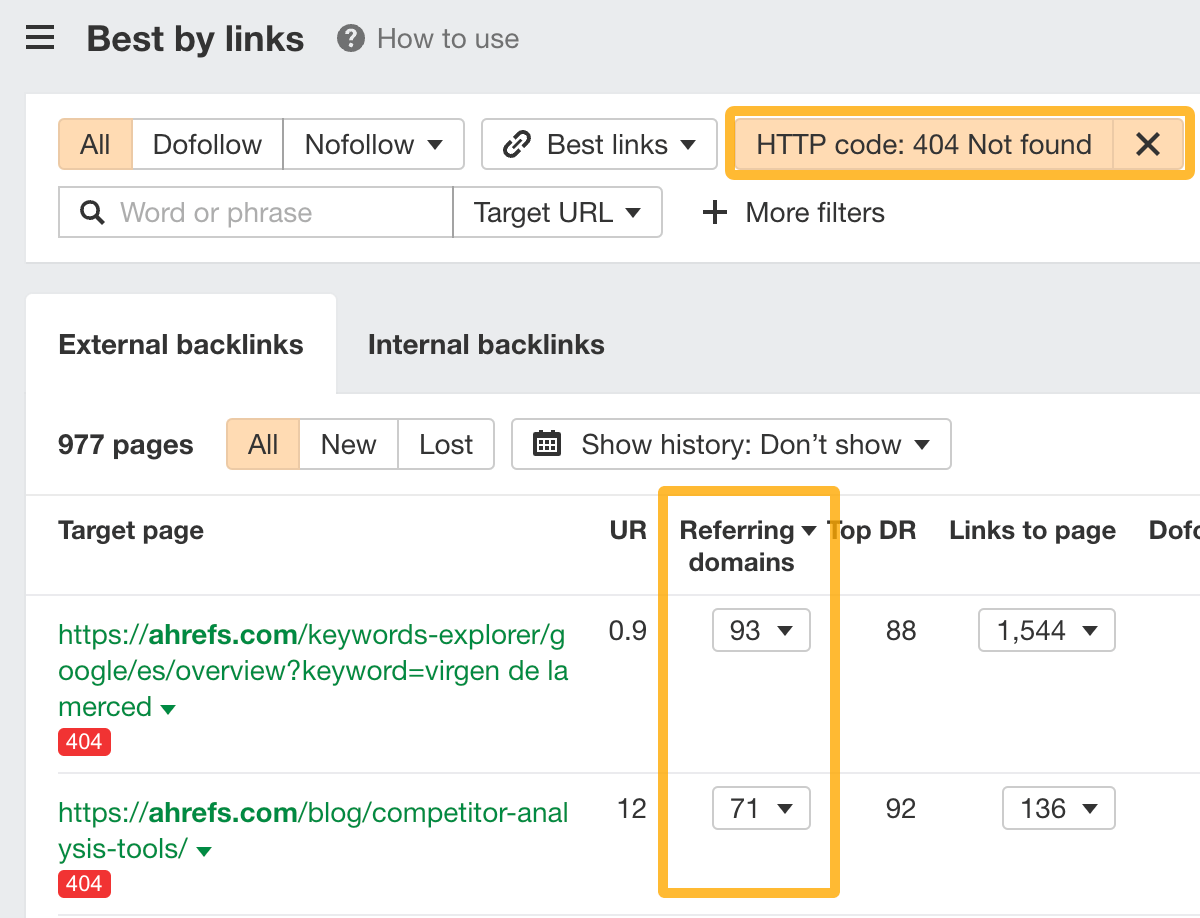
Noindex — Probably not worth pursuing
This means the linking page was noindexed since the last crawl.
You can verify the presence of this tag with the Ahrefs SEO Toolbar:
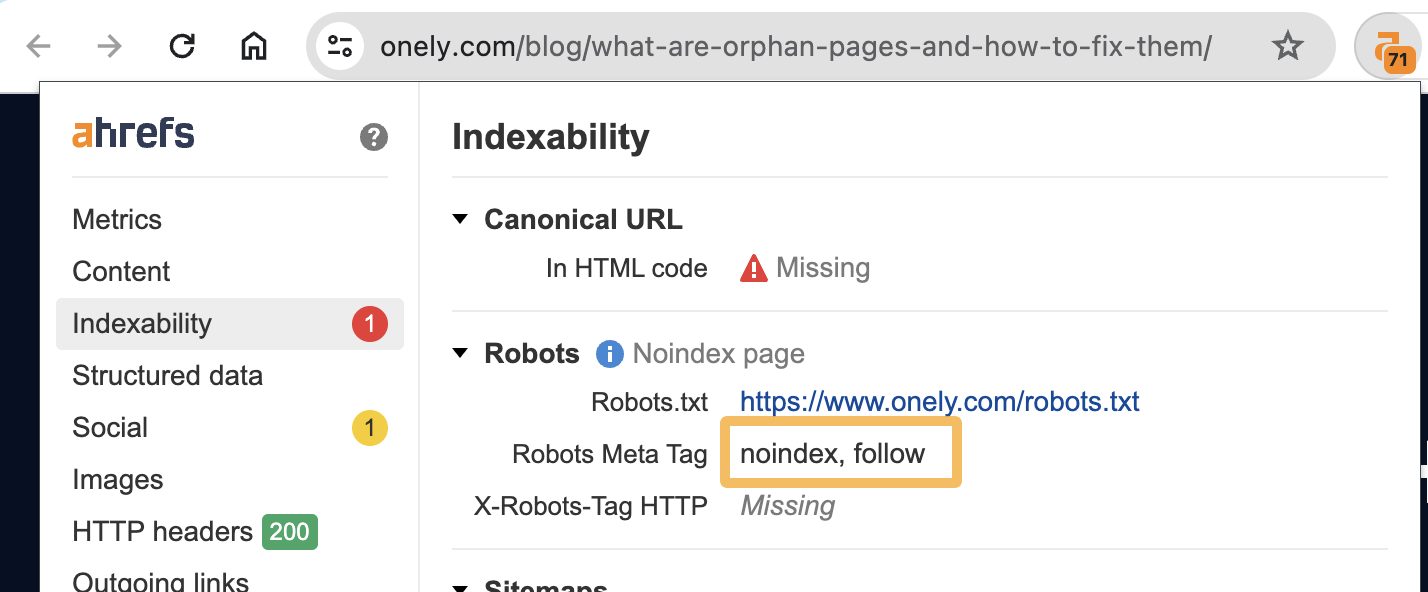
This is a strange case because your link is probably still on the page itself. It’s just that Google may not count it due to the page being noindexed.
If the site owner meant to noindex the page, there’s not much you can do about this.
But a lot of people noindex pages by accident. In which case, you might want to reach out and give them a heads up. This can be something as simple as:
Hey, Just spotted a “noindex” tag on your page about _______. Not sure if you did this on purpose but if not, you might want to fix it. Adding this tag removes the page from Google. 🙁
Here are two ways to spot accidental noindexing:
- Check if their homepage also has a “noindex” tag: Nobody in their right mind wants to de-index their homepage. The presence of a noindex” tag here almost always indicates that they’ve added a sitewide noindex tag by accident.
- Look out for signs of SEO: Nobody would optimize a page they planned to “noindex.” If the page shows any signs of optimization (e.g., targeting a high-volume keyword), the likeliness of an accidental “noindex” is high.
The reason I say you only might want to reach out is because they’ll probably realize their mistake and fix it eventually without your input. Reaching out may just waste your time.
Not canonical anymore — Probably not worth pursuing
This means the linking page is now specifying another resource as its canonical.
You can see the declared canonical using Ahrefs SEO Toolbar:

9 times out of 10, these are nothing to worry about. Common reasons for canonicals include:
- Canonicalization to HTTPs (from HTTP)
- Canonicalization to a standardized version of the URL (e.g., with/without trailing slash)
- Canonicalization to the same content at a different URL
In all of these instances, your link will still exist (and “count”) at the canonicalized version of the URL.
But sometimes, canonicals are indicative of a mistake…
For example, the URL this referring page declares as its canonical gives a security warning:
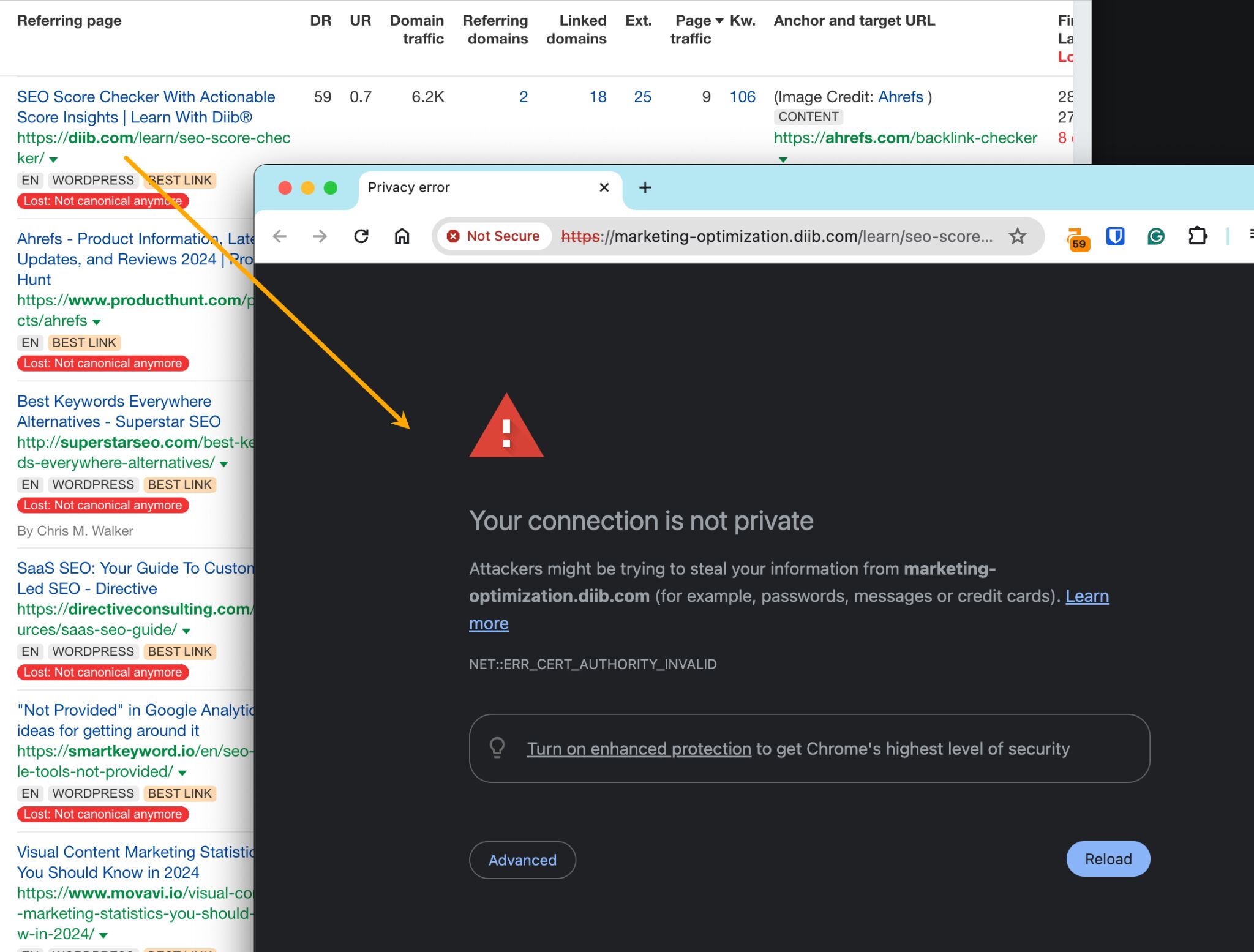
That doesn’t look right at all.
But here’s the thing: in cases like these, Google is smart enough to realize that it probably shouldn’t respect the canonical. In which case, it will still index the linking page and the link won’t technically be lost. Therefore, there’s rarely any opportunity here.
301/302 redirect — Probably not worth pursuing
This means the linking page redirected to a different URL during the most recent crawl.
Much like canonicals, redirects are rarely worth pursuing. Common reasons for them include:
- Redirect from HTTP to HTTPs
- Redirect to standardized version of the URL (e.g., with/without trailing slash)
- Redirect to new location of page (e.g., blog.ahrefs.com to ahrefs.com/blog/)
In each of these cases, the redirected URL will usually still link back to your site.
But sometimes, pages are deleted and redirected elsewhere. This often leads to a true lost backlink. You can easily check whether this is the case by searching the source code of the final destination URL for yourdomain.com.

No results? The redirected page doesn’t link back to you.
I would only recommend pursuing these opportunities if:
- The redirected page contains an unlinked mention: This is rare but if it happens, you can treat it as an unlinked mention opportunity.
- There’s a clear link opportunity on the redirected page: If a link to a resource of yours would add value to the page, reach out and suggest it.
In all other cases where the redirect is irrelevant (e.g., an old blog post redirected to the site homepage), leave it and cut your losses.
Want an easy way to check whether the 301/302 redirected pages link back to you?
Make a copy of this Google Sheet, then filter the Backlinks report in Ahrefs’ Site Explorer for links lost with the 301/302 redirect status. Next, enter your domain in cell A1 of the sheet labelled “Settings,” then paste the referring pages (from the report export) into column A in the sheet labelled “Redirects.” It will show whether each final redirected URL contains a link back to your site.

Further investigate any with the label “Link lost :(”
NOTE. This sheet is an edited version of the one created by The Tech SEO here.
Crawl error — Not worth pursuing
This means we couldn’t crawl the referring page during our last attempt.
Crawl errors can occur for all kinds of reasons. Usually they’re not worth worrying about and the links will reappear during the next successful scheduled crawl.
Dropped — Not worth pursuing
This means we dropped the referring page from our database.
It’s very likely that the link is still on the page. We only count them as lost because we’re no longer able to see whether it’s there or not.
Here are a few reasons why we might drop a page from our index:
- We crawled a “better” page with the same content.
- The page was disallowed by robots.txt for at least 2 months.
- The domain does not exist anymore.
- The page has a low URL Rating (UR).
Final thoughts
Link reclamation isn’t a one-time process. You will lose links all the time for many different reasons. It pays to regularly check for lost links and reclaim any that you can.
It may even be wise to re-allocate some of your resources away from link building and towards link reclamation. This is because reclaiming lost links can often be easier, less time-consuming, and ultimately less costly than building new links.
My final piece of advice? Pick your battles wisely. Don’t try to reclaim links that were lost for good reason. Pursue those you stand a good chance of reclaiming.
For more link building tactics that don’t require new content, check out our list of link building strategies.



