
La navigazione a faccette (o multidimensionale) è ampiamente accettata a livello di UX per aiutare gli utenti a trovare quello che cercano, velocemente. Il lato negativo è che, questo genere di navigazione, può portare a molte complicazioni SEO che dovrai imparare a mitigare.
In questa guida imparerai:
- Cos’è la navigazione a faccette
- Come funziona la navigazione a faccette
- Problemi SEO causati dalla navigazione a faccette
- Come analizzare la presenza di problemi con la navigazione a faccette
- Come risolvere i problemi legati alla navigazione a faccette
- Come prevenire problemi legati alla navigazione a faccette
- Come sfruttare la navigazione a faccette per ottenere più traffico
La navigazione a faccette (o ricerca a faccette o navigazione multidimensionale) è una tipologia di navigazione che si trova spesso all’interno di categorie/archivi di siti che gestiscono molti annunci. Il suo scopo è di aiutare gli utenti a trovare quello che cercano più facilmente permettendo di applicare diversi filtri per i vari annunci.
Molte persone si riferiscono alla navigazione a faccette chiamandola semplicemente ‘navigazione con i filtri’.
Principalmente, troverai questa tipologia di navigazione all’interno delle pagine categoria di:
- Siti di ecommerce come AO.com.
- Piattaforme di annunci di lavori come Total Jobs.
- Siti di viaggi/prenotazioni come Google Flights o Airbnb.
Ma è possibile anche trovarla all’interno di grandi siti di altre tipologie.
La navigazione a faccette funziona filtrando gli annunci all’interno delle pagine categoria in base ai loro attributi. Come detto prima, solitamente si tratta di:
- Lavori
- Prodotti
- Hotel/voli
Gli attributi variano in base al sito web e servizio, ma alcuni esempi comuni includono:
- Prezzo
- Colore
- Brand
- Peso
- Tempo di volo
- Stipendio
- Quantità
- Tempi di spedizione
Una volta che gli amministratori del sito hanno inserito i vari attributi sugli annunci, il sito li mostra all’utente in una lista:
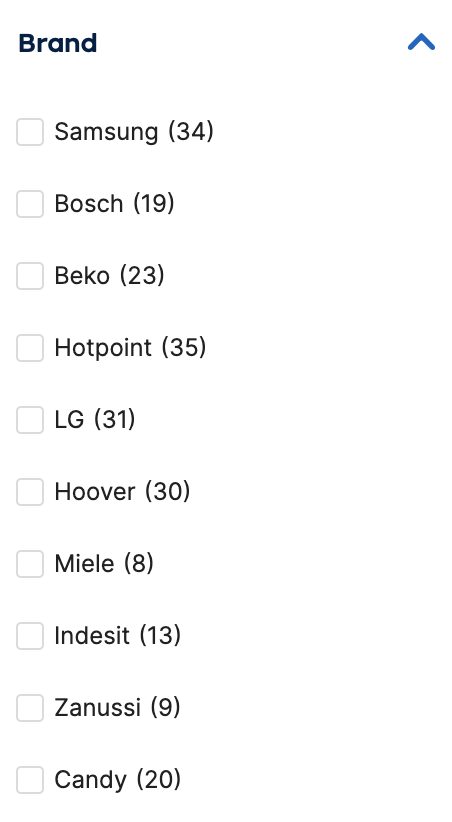
Quello che succede quando un utente clicca su di un filtro è variabile, ma solitamente è riassumibile in una delle condizioni che trovi qui sotto:
- Gli annunci vengono aggiornati immediatamente per riflettere la selezione senza ricaricare la pagina (utilizzando JavaScript).
- La pagina si ricarica e gli annunci riflettono la selezione (senza JavaScript).
- Quando l’utente seleziona un elemento dalla lista non succede nulla finchè non si clicca sul pulsante ‘Applica’. Una volta premuto il pulsante, il sito web aggiorna gli annunci per riflettere la selezione (utilizzando JavaScript).
- Quando l’utente applica dei filtri viene caricata una nuova pagina.
Le prime due soluzioni hanno un UX pattern simile ma differente dalla terza opzione.
Quale pattern UX utilizzare dipende dalla probabilità che un utente utilizzi più di un filtro. Se gli utenti tendono ad applicare filtri multipli, ha senso lasciarli applicare e aggiornare gli annunci solo una volta che tutti i filtri sono stati selezionati.
Una volta che i filtri sono stati applicati, l’URL può opzionalmente essere aggiornata per riflettere la selezione. Anche quello che succede all’URL può variare:
- Non succede nulla. Gli annunci vengono aggiornati senza che l’URL venga modificato.
- Il sito aggiunge dei parametri all’ URL come ‘?colore=blu&brand=samsung’.
- Il sito aggiunge all’URL degli hash identificando i filtri applicati, es., #colore=blue
- Viene creato un nuovo URL statico come /jeans/blu/ (in questo esempio l’utente ha selezionato l’opzione “colore = blu”).
I problemi SEO causati dalla navigazione a faccette che dovrai prevenire o sistemare includono:
- Contenuti duplicati
- Index bloat
- Crawling
Sfortunatamente, la navigazione a faccette può creare un numero quasi infinito di combinazioni e URL indicizzabili. Se hai problemi con uno qualunque tra questi, l’impatto SEO tende ad essere importante.
Qui sotto, sono presenti alcuni esempi di come questi problemi si verificano e qual è il loro impatto sulla SEO del tuo sito.
Contenuti duplicati
I contenuti duplicati sono quelli per cui lo stesso contenuto o uno molto simile è accessibile da diversi URL. I filtri sono ben noti per creare URL con contenuti duplicati in massa. La duplicazione avviene principalmente perché le pagine filtrate sono copie dell’originale che si distinguono solamente per i diversi annunci mostrati.
Nonostante i contenuti duplicati non siano necessariamente un segnale di posizionamento negativo, possono portare problemi con la:
- Cannibalizzazione delle parole chiave
- Diluizione dei segnali di ranking tra diversi URL (invece che consolidare tutto in un URL che risulterà più forte nel posizionamento)
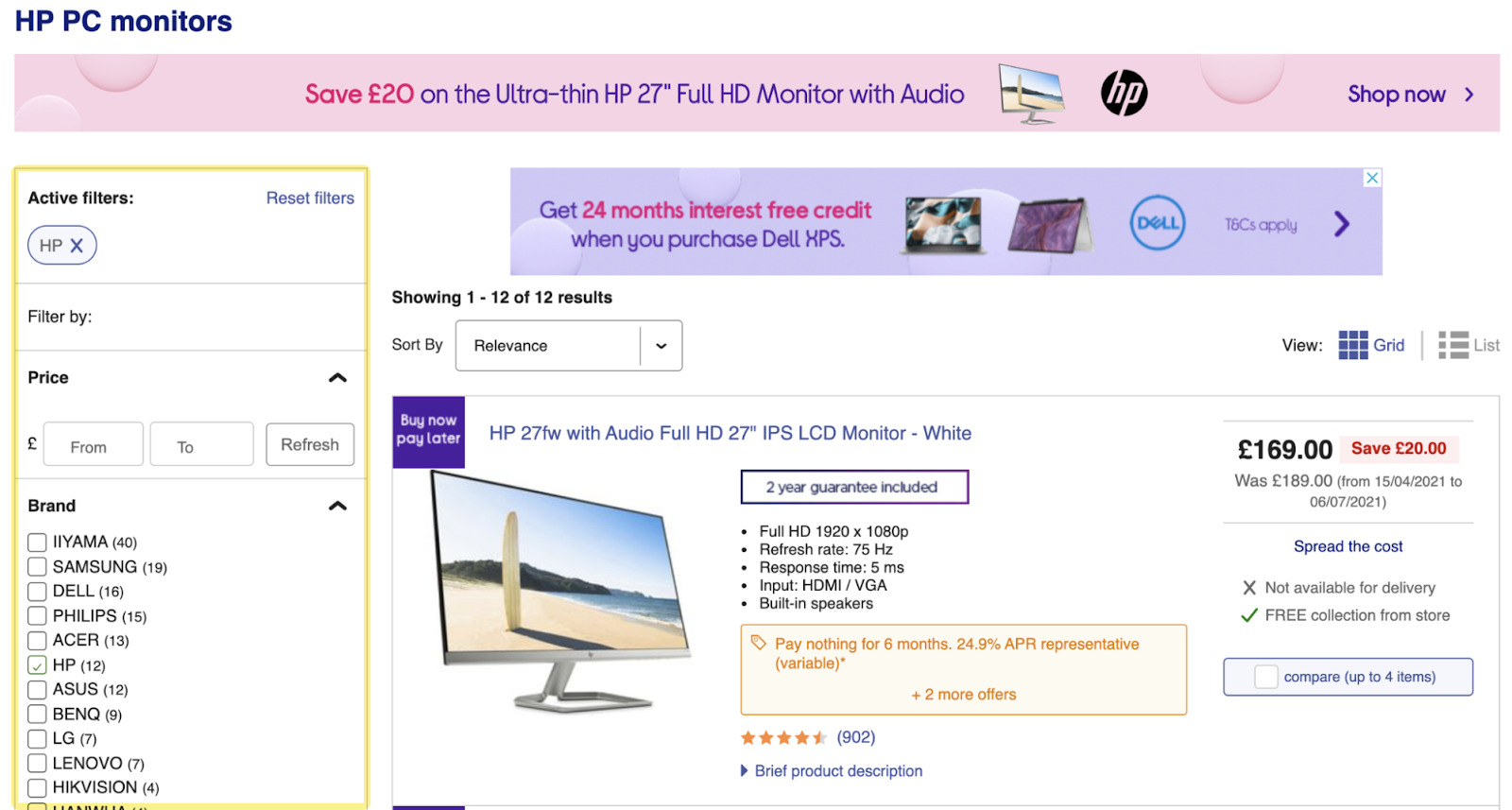
Prendiamo come esempio l’ecommerce currys.co.uk. Iniziamo dalla loro pagine relativa ai monitor HP. È ragionevole per un sito di ecommerce avere un layout standard composto da header, annunci e navigazione a faccette above the fold:
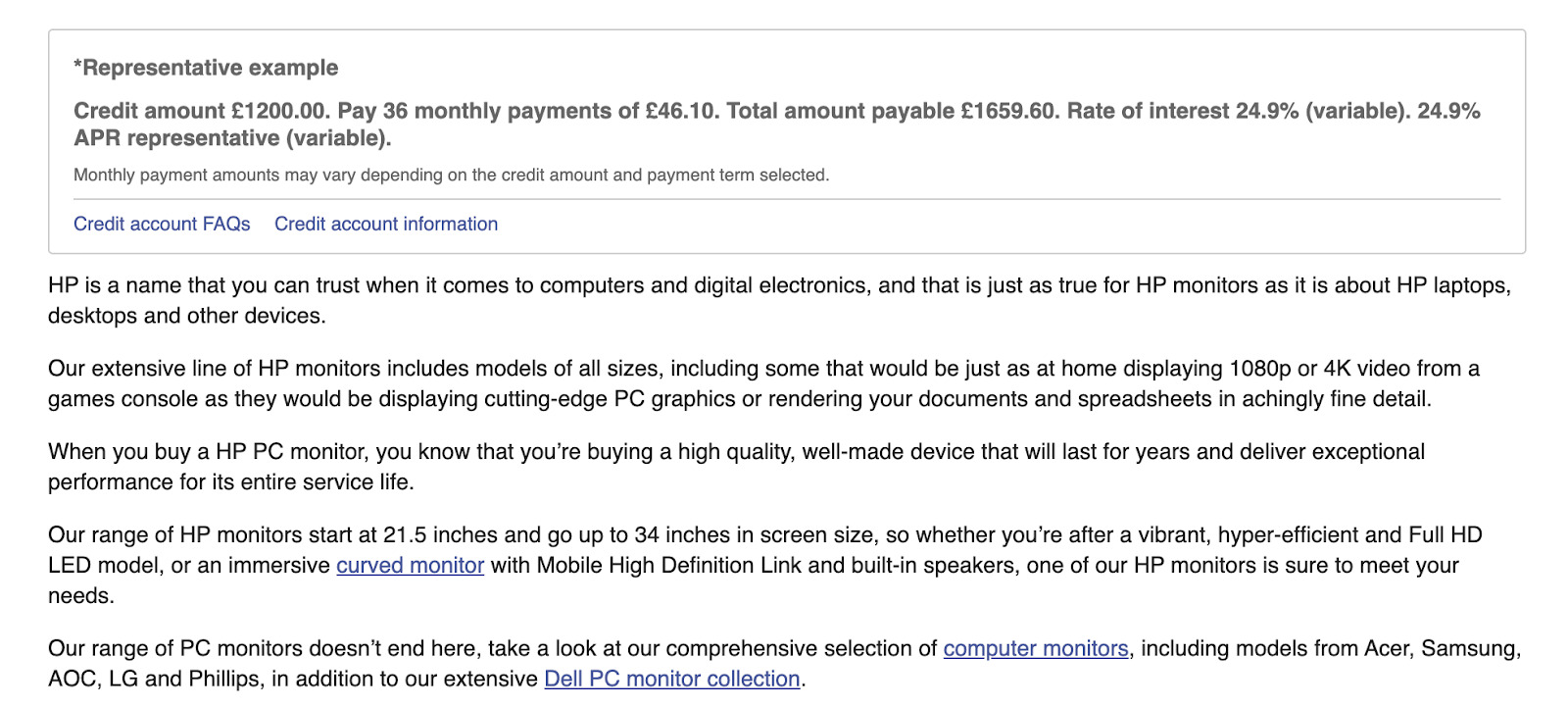
Sotto agli annunci, viene poi mostrato il contenuto riguardo i monitor HP:
Ora applichiamo il filtro per ‘4k monitors’.
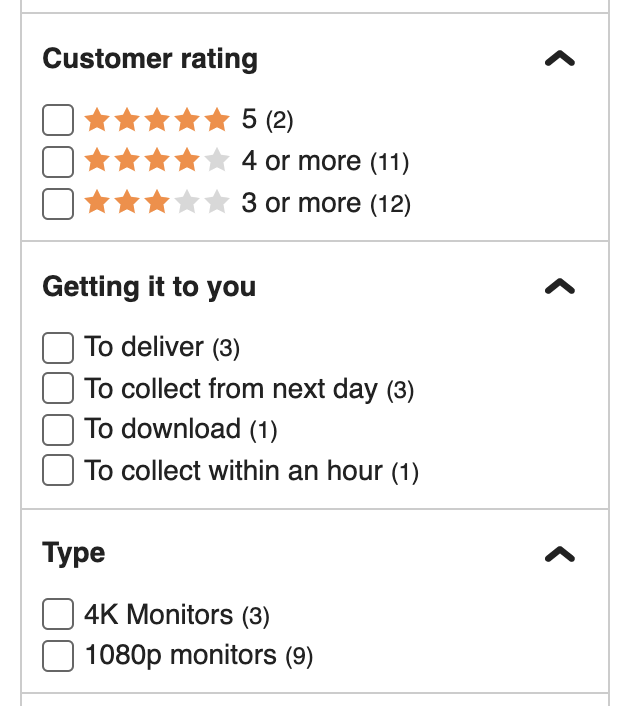
Gli annunci sulla pagina vengono aggiornati, il tag H1 cambia e l’URL si modifica da questo:
/hp-computing/pc-monitors/pc-monitors/354_3057_30059_16_xx/xx-criteria.html
A questo:
/hp-4k-monitors/pc-monitors/pc-monitors/354_3057_30059_16_ba00012894-bv00311096/xx-criteria.html
Se però torni nuovamente in fondo alla pagina noterai che lo stesso blocco di contenuto è presente al di sotto degli annunci.
Questo è solo un esempio di duplicazione del sito. Scala questo per ogni filtro possibile, e ti ritroverai in men che non si dica ad avere milioni di pagine duplicate che Google tenterà di consolidare in un’unica pagina canonica.
Index bloat
L’index bloat è il fenomeno che accade quando i motori di ricerca indicizzano pagine del tuo sito che non hanno valore di ricerca.
Consentire a Google di indicizzare solo pagine di valore è critico, in quanto avere molte pagine di bassa qualità indicizzate può avere un impatto sulla visibilità generale del tuo sito, come spiegato da John Mueller in questo video.
La navigazione a faccette può potenzialmente creare milioni di URL indicizzabili senza contenuti unici. Può anche creare varianti di pagine che non forniscono alcun valore agli utenti che utilizzano i motori di ricerca.
Eccone un esempio:
AO.com ha una pagina di categoria dedicata alla lavatrici non incassate:
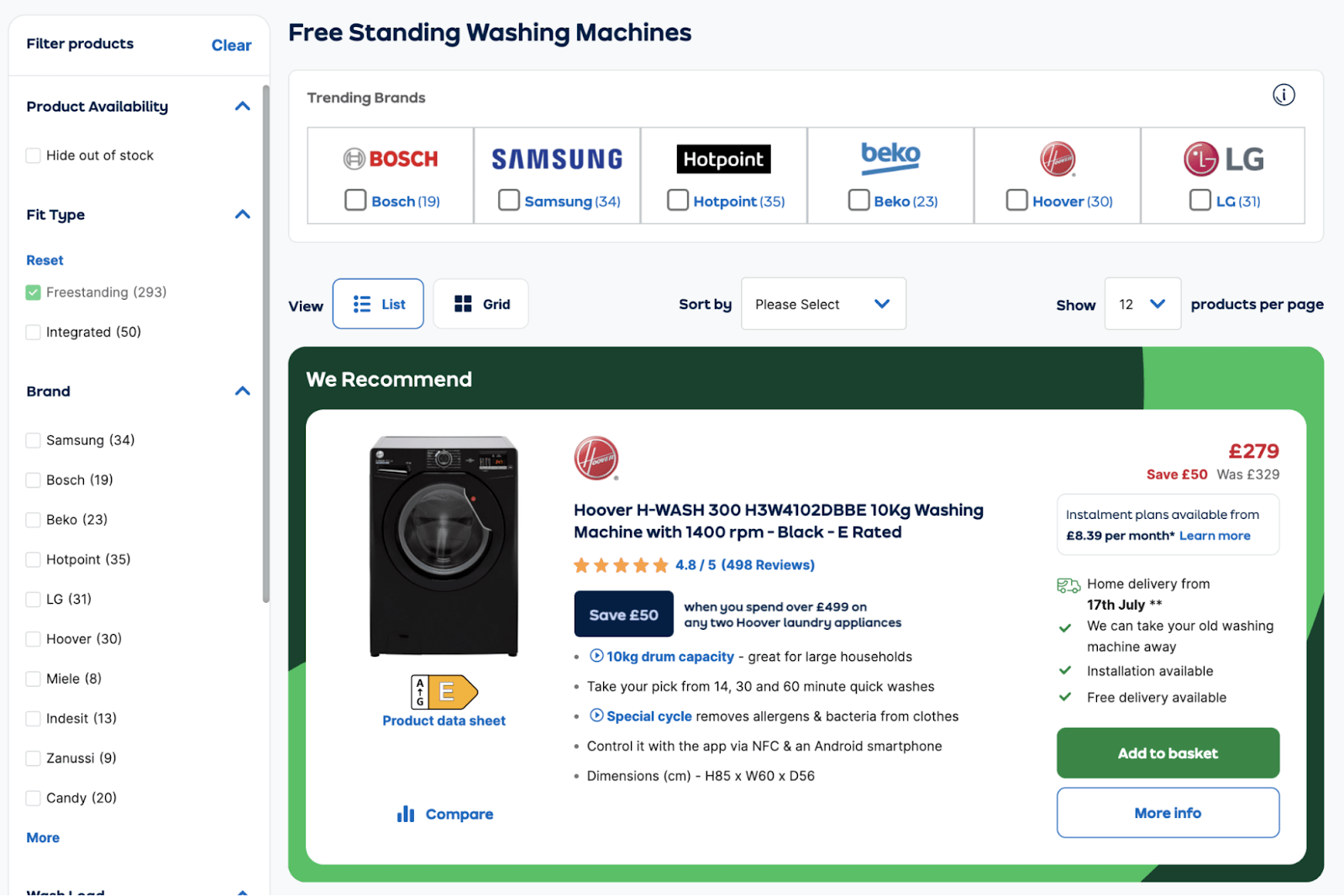
Un utente potrebbe visitare la pagine e decidere di filtrare per:
- Brand: Samsung
- Capacità di Carico: Alta
- Colore: Grigio
- Capacità di Lavaggio: Alta
- Funzionalità: Lavaggio Rapido
- Energy Rating: A
Grazie a questi filtri, il sito ha restituito la lavatrice perfetta per le esigenze dell’utente.
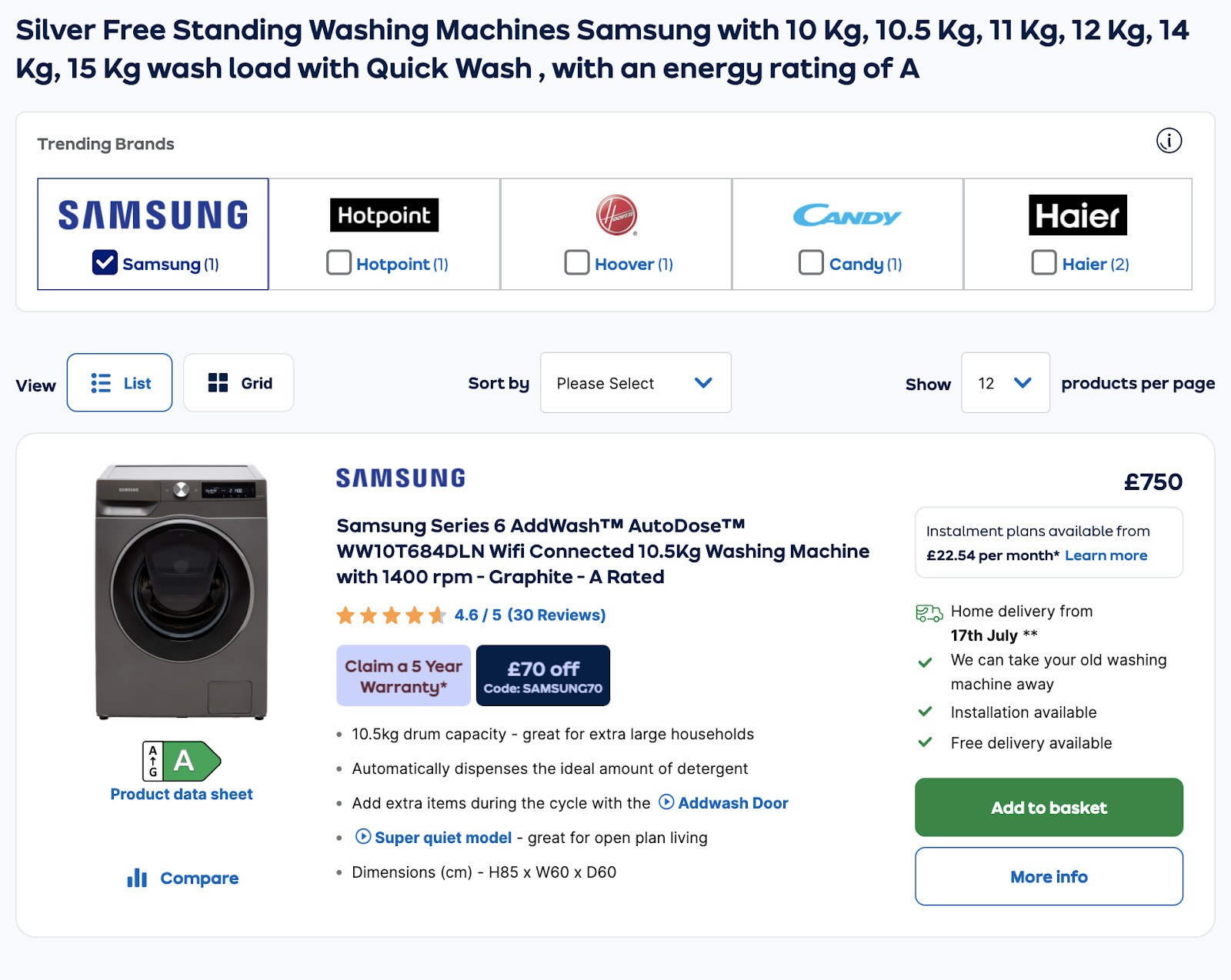
Ma un utente potrebbe cercare qualcosa di così specifico all’interno di Google?
La risposta è no.
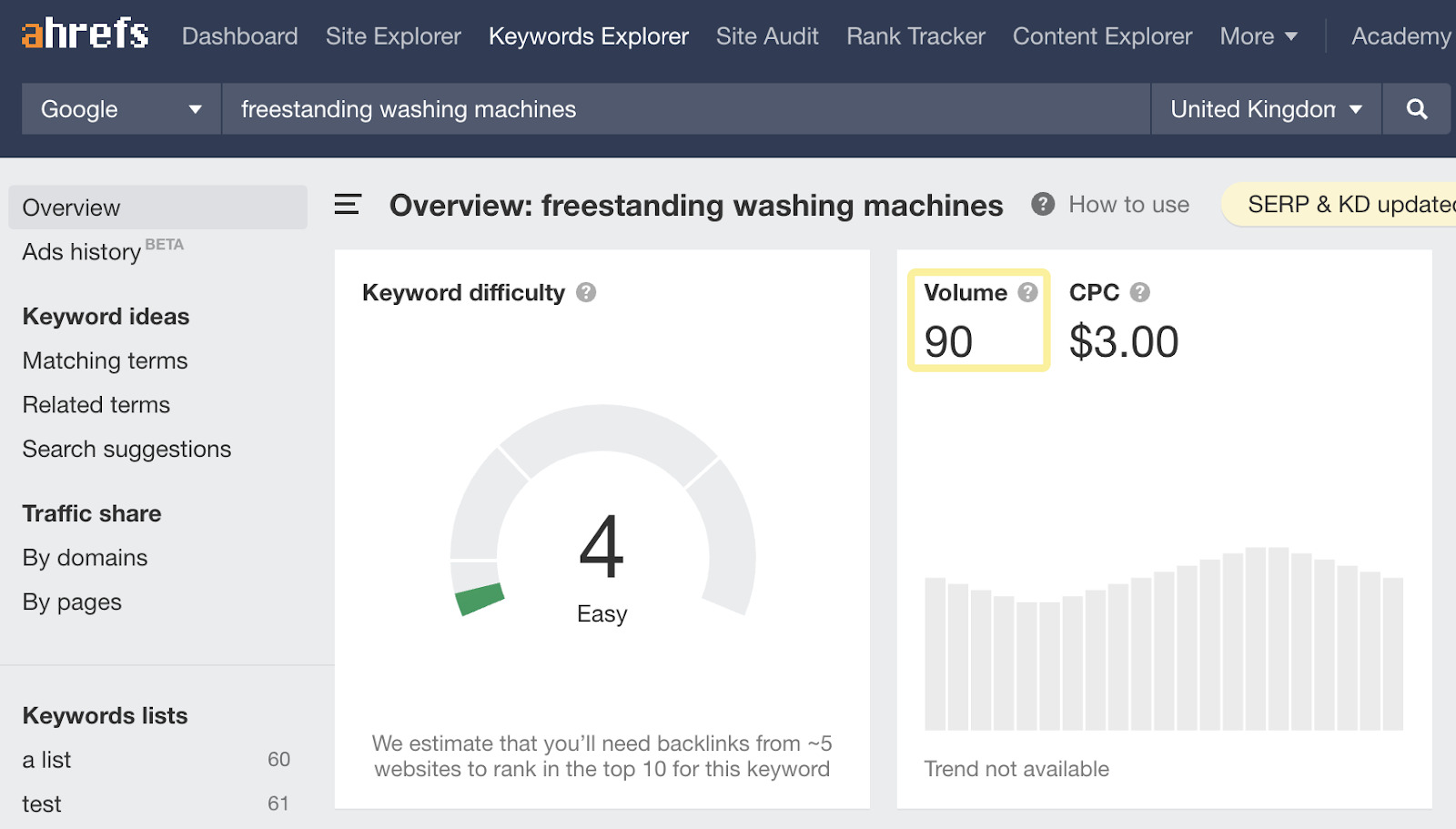
Lo sappiamo perché ci sono circa 90 ricerche al mese per ‘lavatrice non incassata’ nel Regno Unito, quindi è altamente improbabile che ci saranno delle ricerche per qualcosa di ancora più specifico come ‘lavatrice con alta capacità di carico grigia non incassata di marca Samsung con lavaggio rapido e energy rating A’.
Avere pagine di bassa qualità (come quella mostrata) indicizzate senza intercettare domande di ricerca possono mettere il tuo sito a rischio di essere impattato negativamente da un algoritmo.
Spreco di crawl budget
Google può dedicare solo una quantità finita di risorse per scansionare le pagine del tuo sito. Questo prende il nome di crawl budget.
Gestire il crawl budget non è prioritario per Google, a meno che tu non abbia un grosso sito (1M+ pagine uniche) o medio (10k+ pagine uniche) con contenuti che cambiano frequentemente.

Visto il consiglio fornito, se hai solo qualche migliaio di categorie e prodotti, potresti credere di non doverti preoccupare di gestire il crawl budget.
E questo sarebbe un grosso errore.
Alcune implementazioni di navigazione a faccette creano un link scansionabile per ogni combinazione disponibile.
Ignorare i potenziali problemi di index bloat potrebbe significare lasciare a Google milioni di URL generati da scansionare, rendendo la gestione del crawl budget un problema.
Puoi trovare un esempio di ciò sul sito next.co.uk:
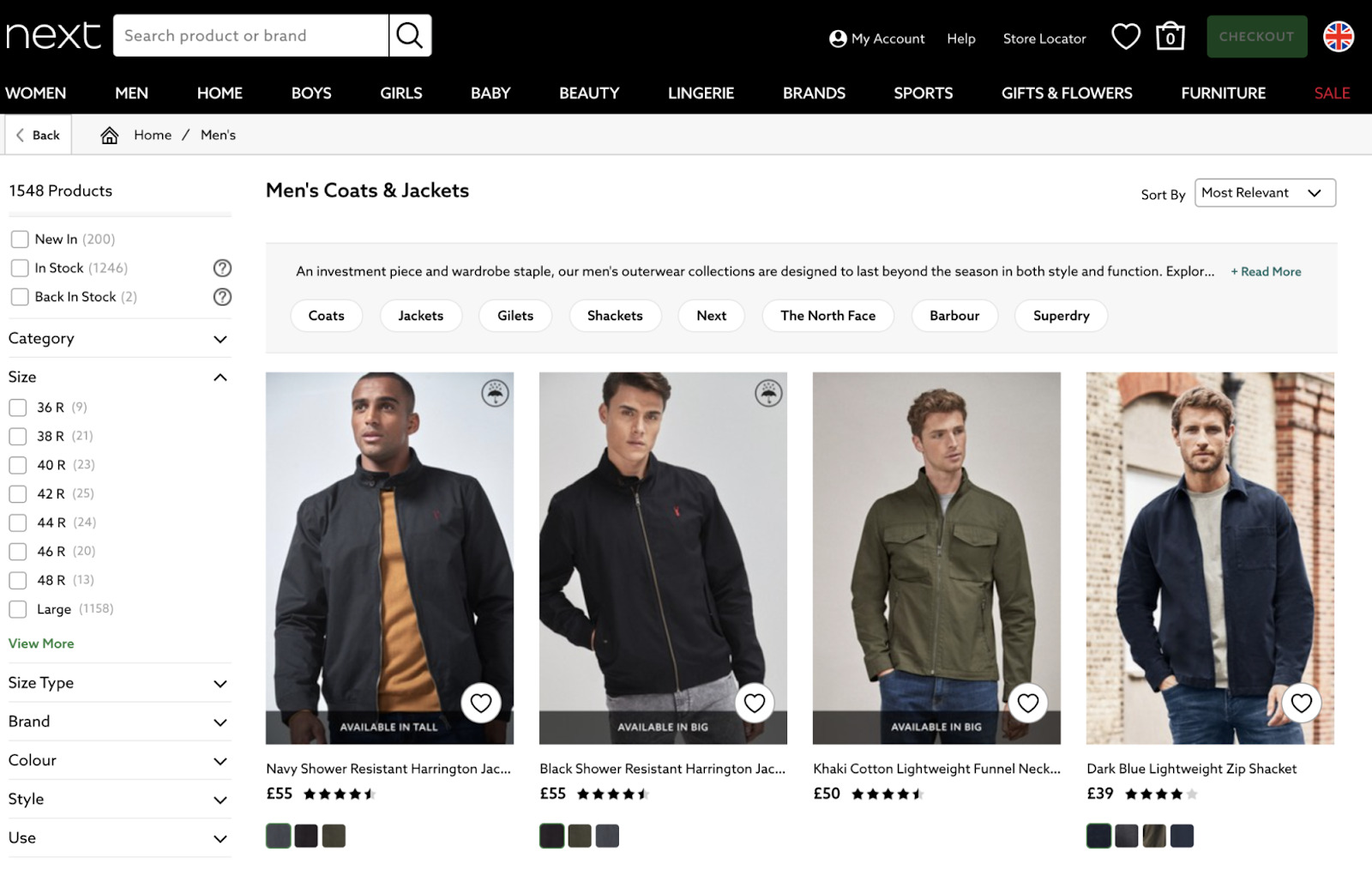
Quando ispezioni l’HTML di una faccetta, vedrai un link all’interno dell’HTML:

Se segui il link, puoi controllare l’HTML di un’altra faccetta come quella per il colore blu:

Puoi notare come le faccette si combinano fra di loro per creare un URL completamente nuovo da scansionare.
Ora prova a pensare a tutte le potenziali combinazioni fra i vari filtri. Puoi immaginare come scansionare un sito con problemi legati alla navigazione a faccette possa causare problemi per un motore di ricerca.
Diluizione del PageRank
La navigazione a faccette può anche diluire il PageRank.
Questo avviene in quanto il PageRank viene diviso per il numero totale di link presenti su una pagina. Questo presenta un chiaro problema con la navigazione a faccette, in quanto genera un ampio numero di link interni.
Il PageRank fluisce quindi verso i link presenti all’interno dei tuoi filtri invece che alle pagine prodotto o categoria più importanti, e questo solitamente non aiuta a migliorare il traffico di ricerca.
Lettura consigliata: Google PageRank NON è Morto: Ecco Perché è Importante
Ci sono sempre dei modi per identificare i problemi legati alla navigazione a faccette; ecco alcuni passaggi per aiutarti a capire se i tuoi filtri stanno avendo un impatto sulla SEO.
1. Inizia con una ricerca
Un’ottima tattica per identificare segnali di index bloat velocemente è utilizzare l’operatore di ricerca site:. Nonostante non sia il modo più accurato, è comunque semplice e veloce da fare.
Consiste semplicemente nell’inserire ‘site:’ prima del tuo dominio, come nell’esempio qui sotto.
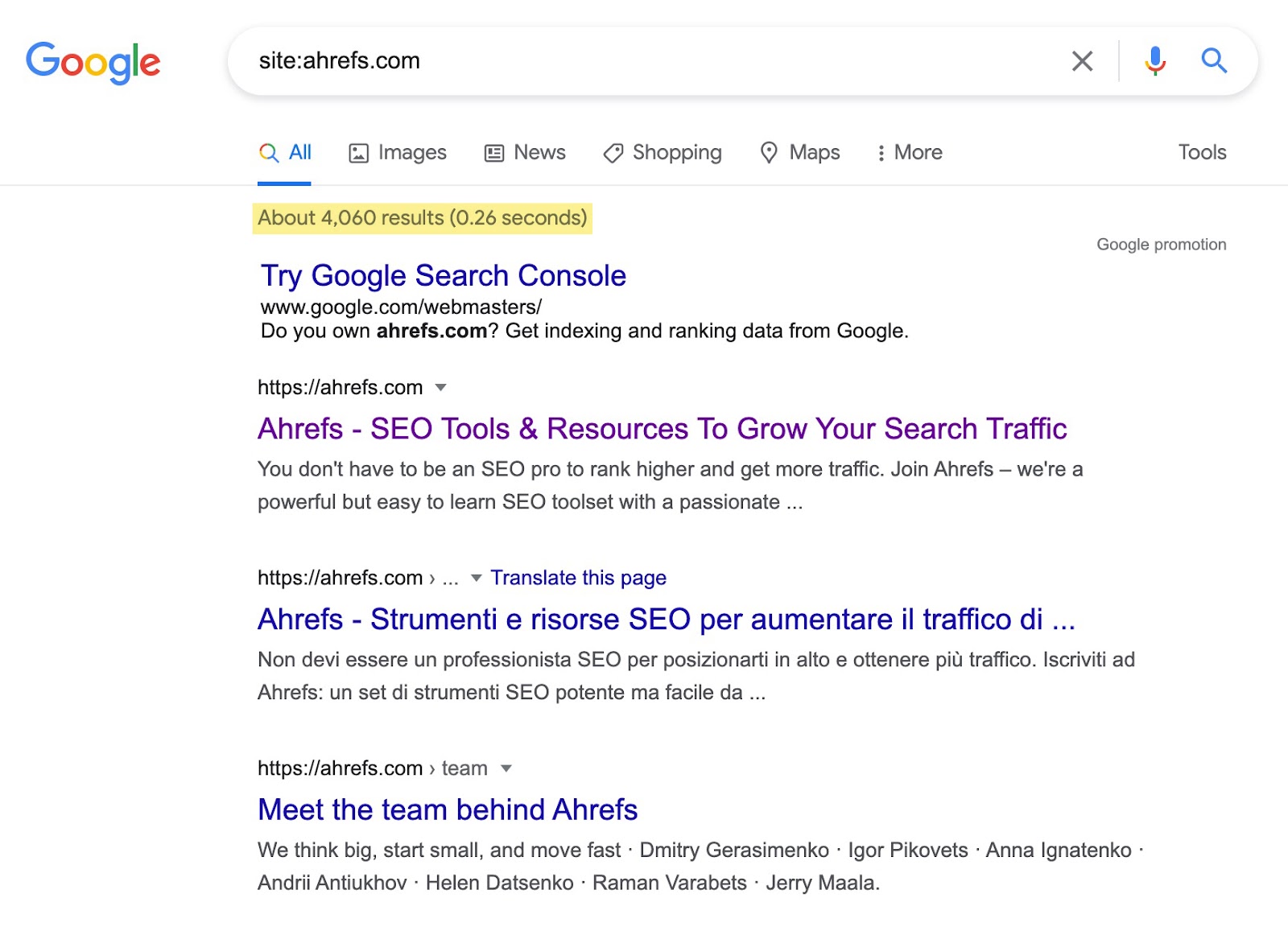
Prendi nota del numero di risultati che Google restituisce. Il numero è maggiore degli URL del tuo sito?
Se lo è, questo potrebbe essere il primo segnale di un index bloat.
2. Valida gli URL utilizzando i report di copertura di Google Search Console (GSC)
Il report copertura di GSC è un altro grande metodo per trovare velocemente problematiche legate alla scansione e all’indicizzazione.
Recati sul report ‘Copertura’ all’interno di GSC e seleziona “‘Valide” sul grafico per ottenere un dato accurato del numero di pagine che Google ha indicizzato:
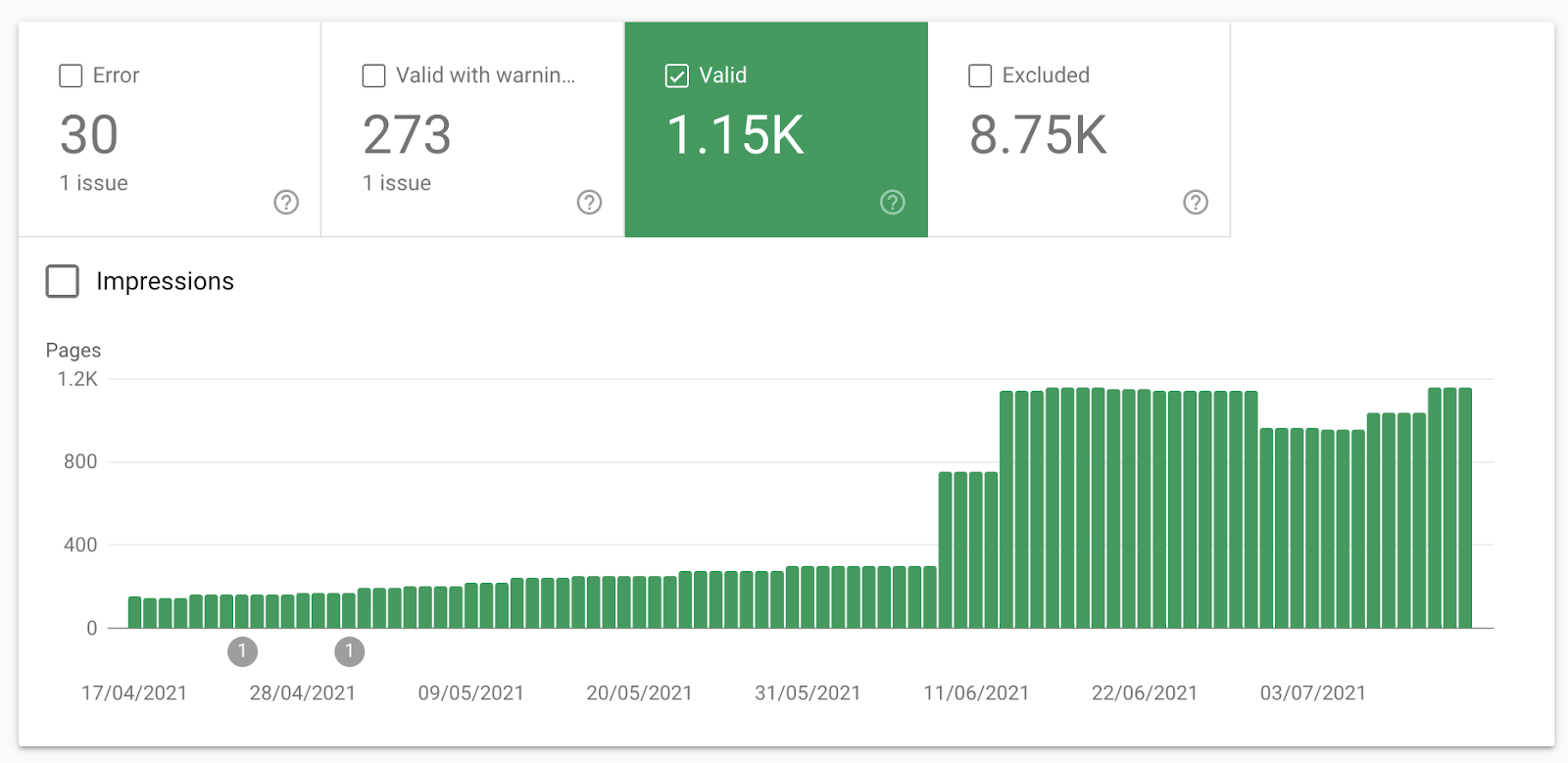
Se ti sembra troppo alto, o hai implementato di recente la navigazione a faccette e questo numero è schizzato alle stelle, potrebbe trattarsi di un segnale di index bloat come menzionato prima.
Ma come facciamo a sapere se questo problema è stato causato dai filtri?
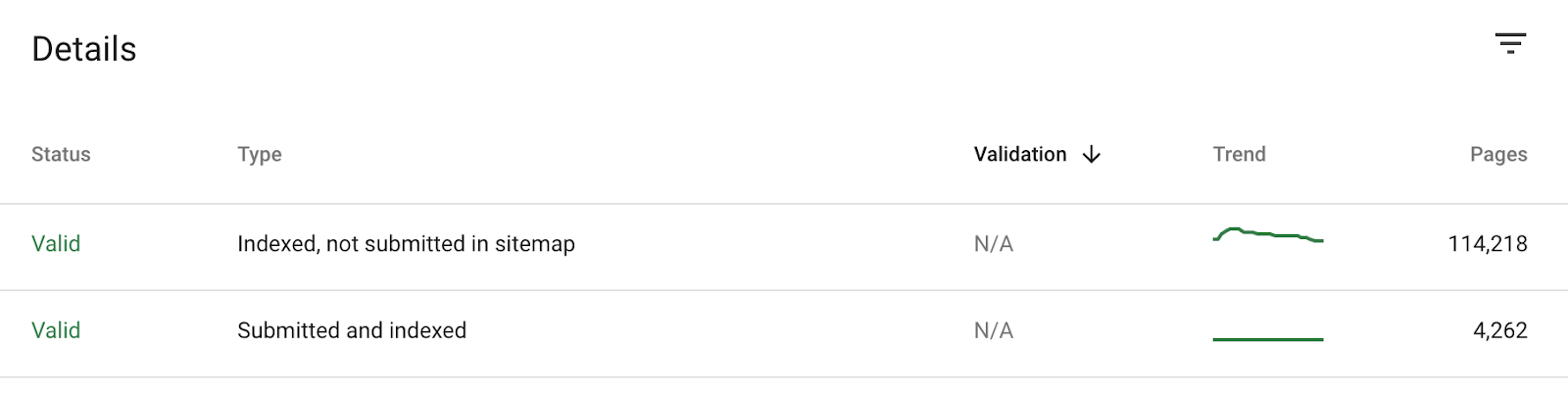
Avere delle sitemap XML accurate aiuta a fare una diagnosi. Se le hai caricate su GSC, la tabella sotto al grafico dividerà le URL indicizzate in:
- Indicizzata, ma non inviata tramite la Sitemap
- Inviata e indicizzata
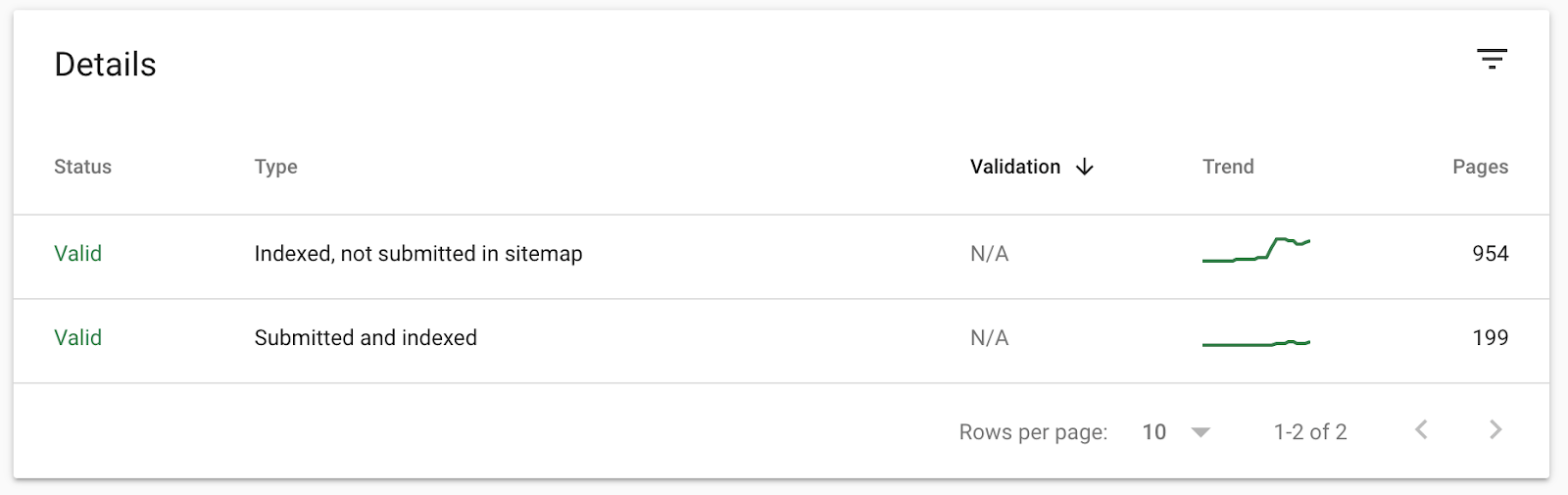
Questo significa che possiamo analizzare le pagine presenti in “Indicizzata, ma non inviata tramite la Sitemap” per identificare pagine non volute che Google sta indicizzando:
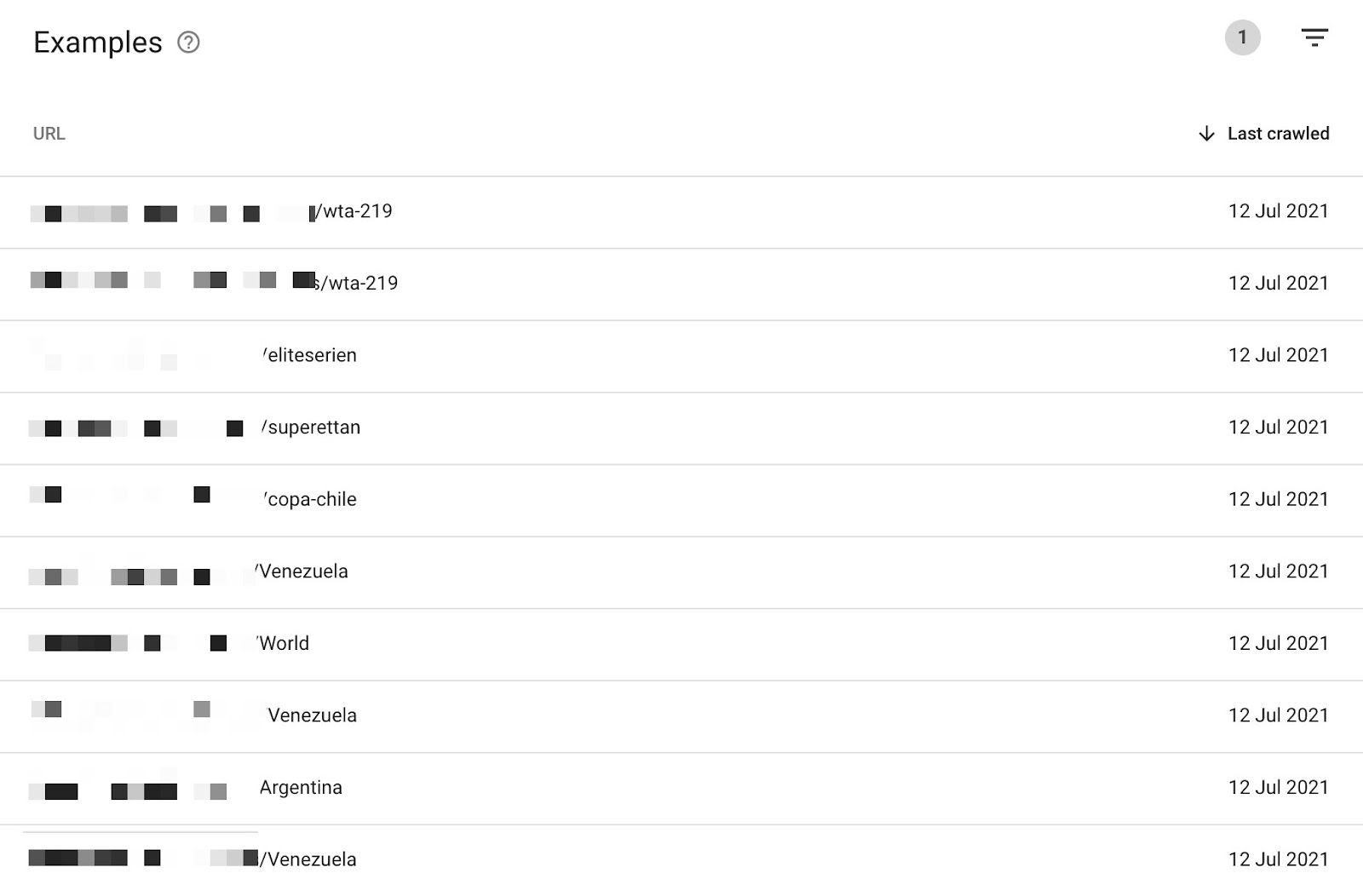
Questo esempio è per un sito di scommesse che permette di filtrare per località e tornei. Possiamo vedere come Google stia indicizzando URL non voluti.
Un altro modo molto utile per scoprire potenziali problemi è filtrare per URL ‘Esclusi’:
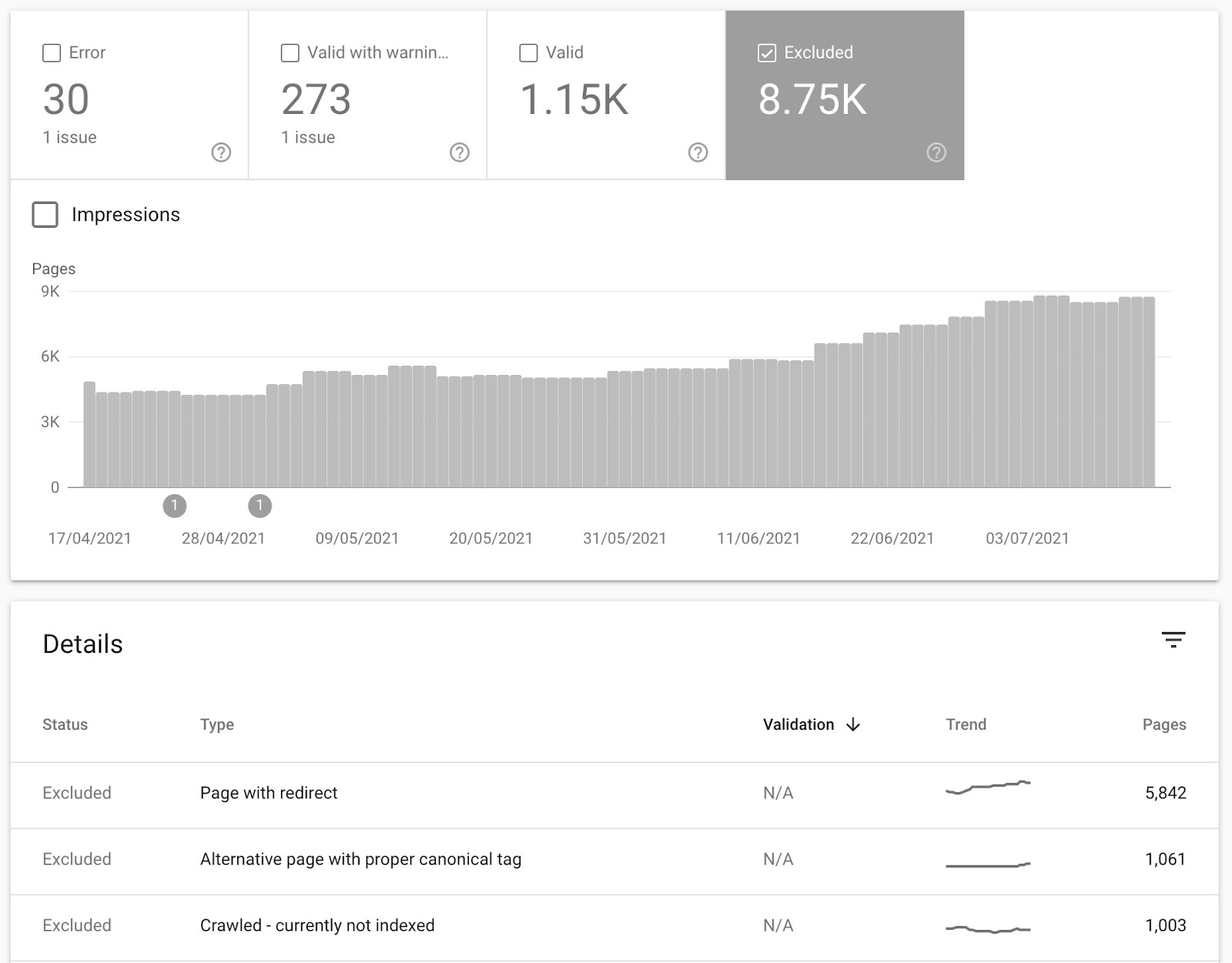
Analizzare gli URL “Pagina scansionata, ma attualmente non indicizzata” può darti dettagli riguardo alle pagine che Google sta trovando ma che ha deciso di non indicizzare.
Google non indicizza tutto quello che scansiona. Se la pagina è di bassa qualità, com’è il caso per molte di quelle a faccette, potrebbe decidere di non indicizzarla.
In questo esempio, sappiamo che ci sono 1,000 URL aggiuntivi che Google ha scoperto e che potrebbe indicizzare in futuro. Puoi anche vedere l’URL nella tabella per capire se sono presenti quelli in cui è presente la navigazione a faccette.
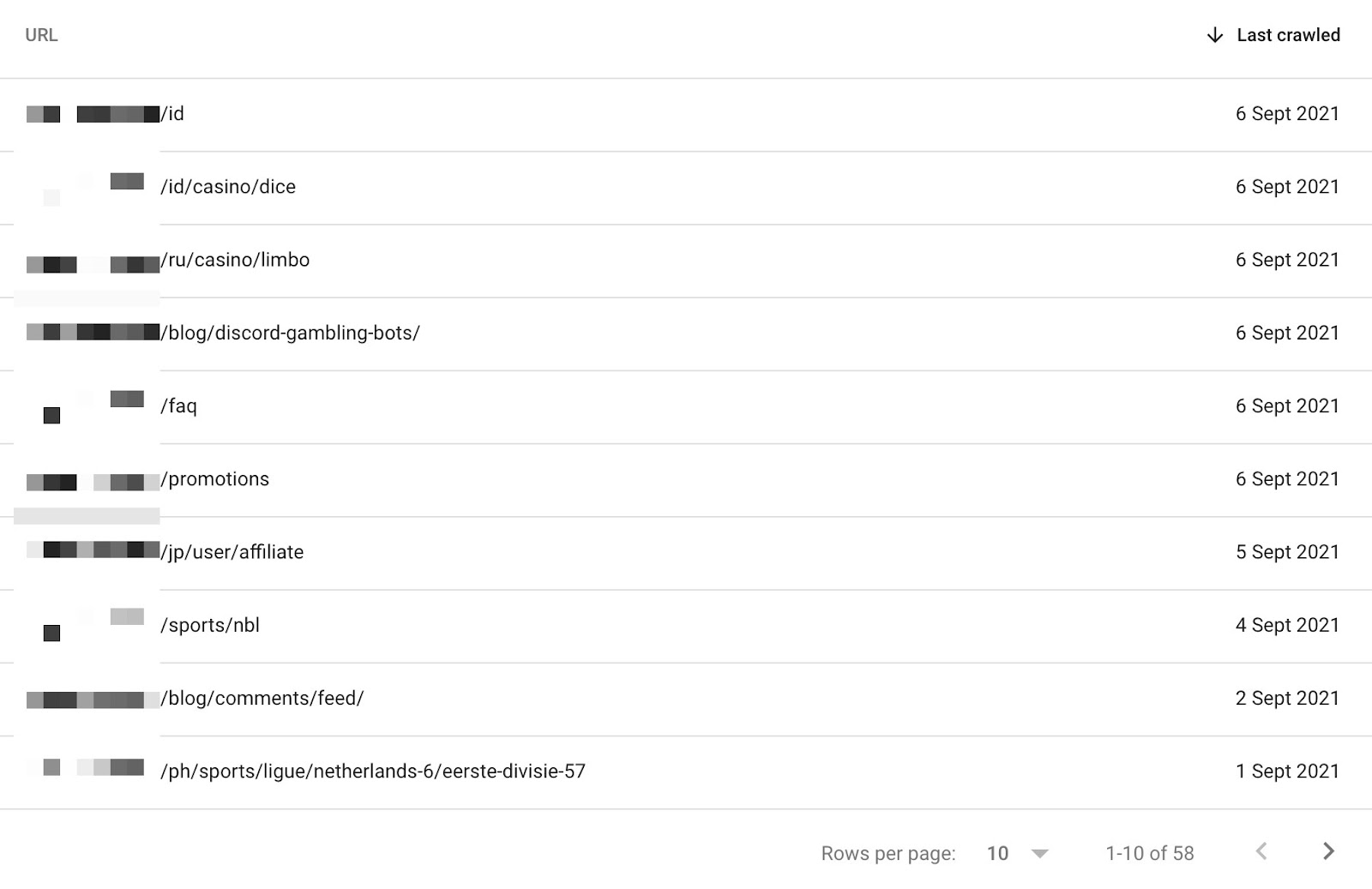
Quello mostrato qui sopra è un problema non troppo grave legato alla navigazione a faccette ed è evidenziato da GSC. Nel corso del tempo, questi problemi possono crescere e portare alla scoperta da parte di Google di centinaia di migliaia di URL scoperti ma non indicizzati (mostrando problemi legati quindi alla scansione):

O potenzialmente centinaia di migliaia di URL che vengono indicizzati ma non dovrebbero esserlo:
3. Raccogli più dati con un site auditor
Utilizzare la ricerca e GSC è un ottimo modo per ottenere velocemente dati riguardo un problema, ma nessuno dei due analizzerà a fondo tutti gli URL indicizzati/indicizzabili, rendendo arduo identificare dei trend e comprendere la portata del problema.
Tool per il site audit come il Site Audit di Ahrefs possono porre rimedio fornendo informazioni dettagliate riguardo gli URL scoperti scansionando il sito.
Quello qui sotto è l’esempio di un sito con problemi derivanti dalla navigazione a faccette che spreca crawl budget, e che puoi identificare attraverso un paio di clic.
Prima di tutto recati nel report Indexability nella sidebar a sinistra.
Poi dai uno sguardo al grafico chiamato ‘Indexability distribution’, in modo da vedere se qualcosa non torna.
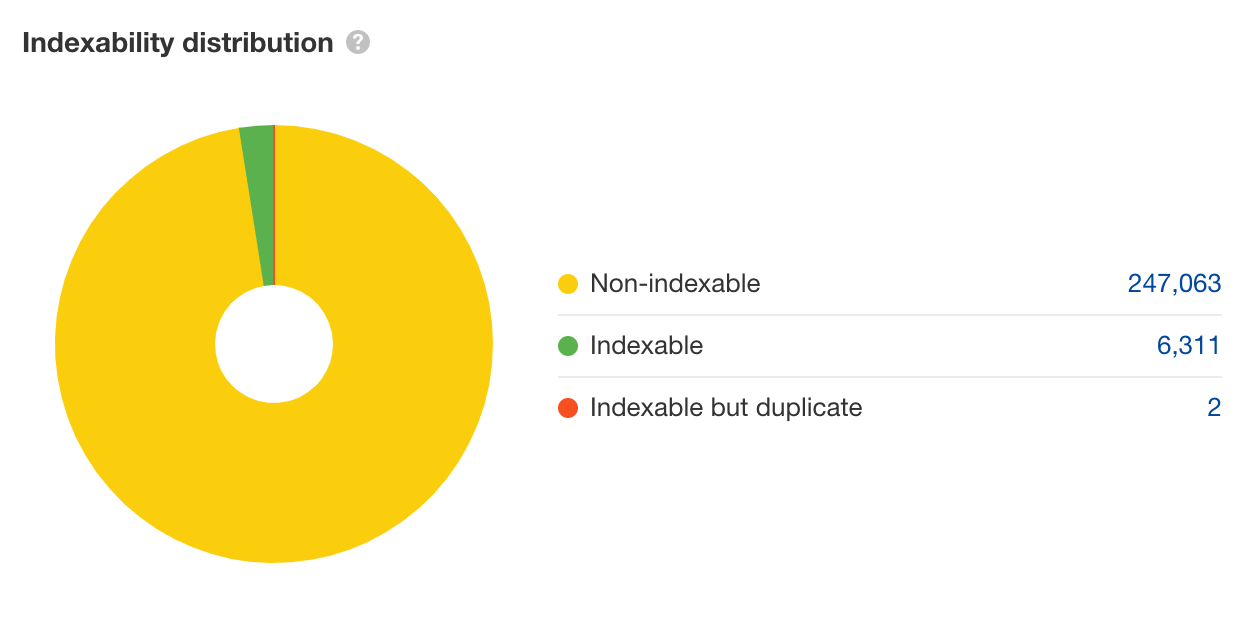
Da una scansione parziale, il Site Audit ha già trovato 39 URL non indicizzabili per ogni URL che lo è. Dato che non si tratta nemmeno di una scansione completa del sito, potremmo aspettarci che il rapporto fra URL indicizzabili e non indicizzabili peggiori man mano che la scansione prosegue.
Quello qui sopra segnala un tremendo spreco di crawl budget, e costituisce anche un ottimo esempio di crawler trap—dove i problemi tecnici causano un infinito numero di URL non rilevanti che i bot dovranno scansionare.
Se la tua navigazione a faccette sta causando un index bloat, il grafico qui sopra sarà leggermente differente. Invece che vedere un gran numero di URL non indicizzabili, vedrai un ampio numero di URL indicizzabili, come nel grafico qui sotto.
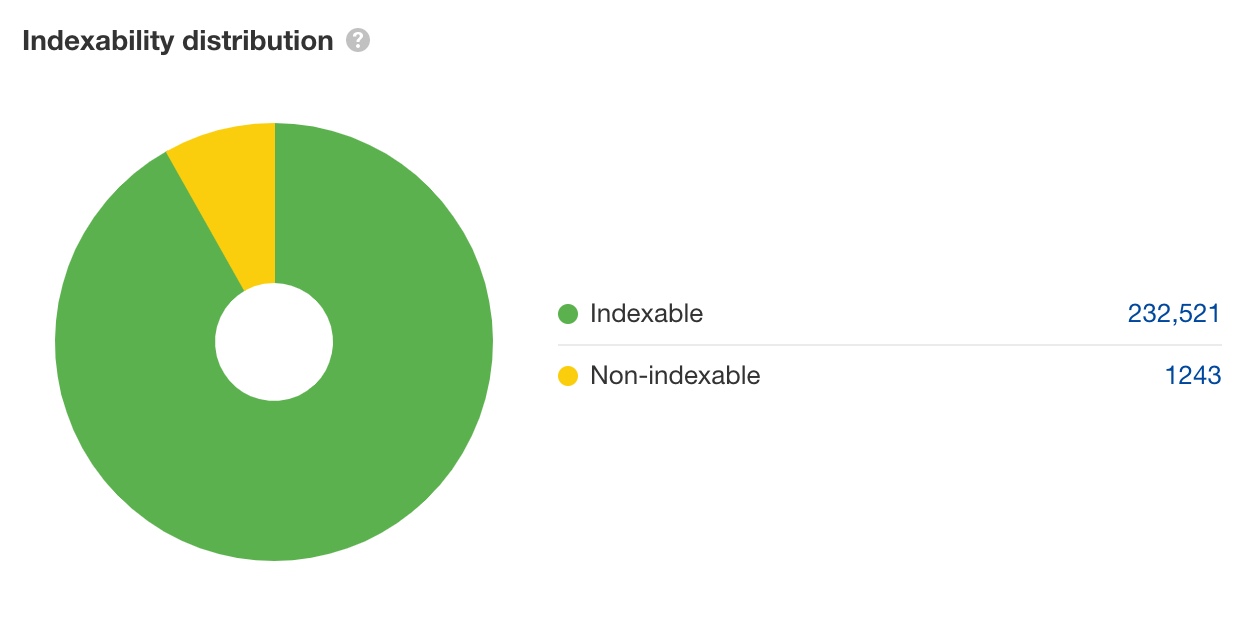
Per confermare che si tratta di un problema legato alla navigazione a faccette, seleziona la porzione non indicizzabile dal grafico e scorri la lista. Vedrai una tabella di tutte le pagine non indicizzabili che sono state scansionate.
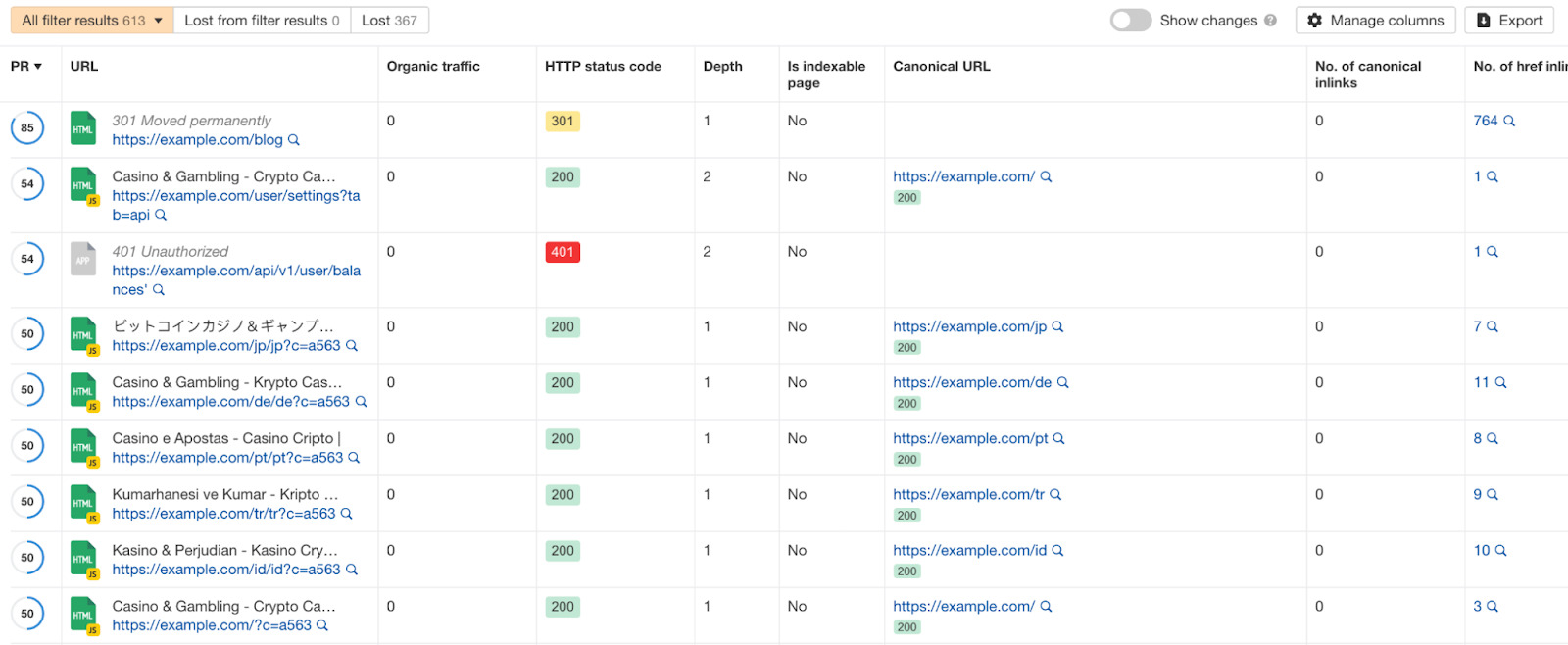
Qui dovresti identificare i pattern.
Cosa sta causando tutte queste pagine non indicizzabili trovate dai crawler?
Se la maggior parte degli URL restituiti nella tabella sono URL dove è presente la navigazione a faccette, hai identificato un problema legato a questa tipologia di navigazione.
Ora che sai come identificare i problemi legati alla navigazione a faccette, è giunto il momento di sistemarli.
1. Sistemare l’indicizzazione con un tag canonical
Se hai problemi legati all’indicizzazione non causati dalle problematiche di crawl budget (e non hai un sito enorme) la migliore soluzione è utilizzare il tag canonical. Questo tag consolida i segnali dei link per le pagine simili/duplicate verso l’URL specificata come canonica.
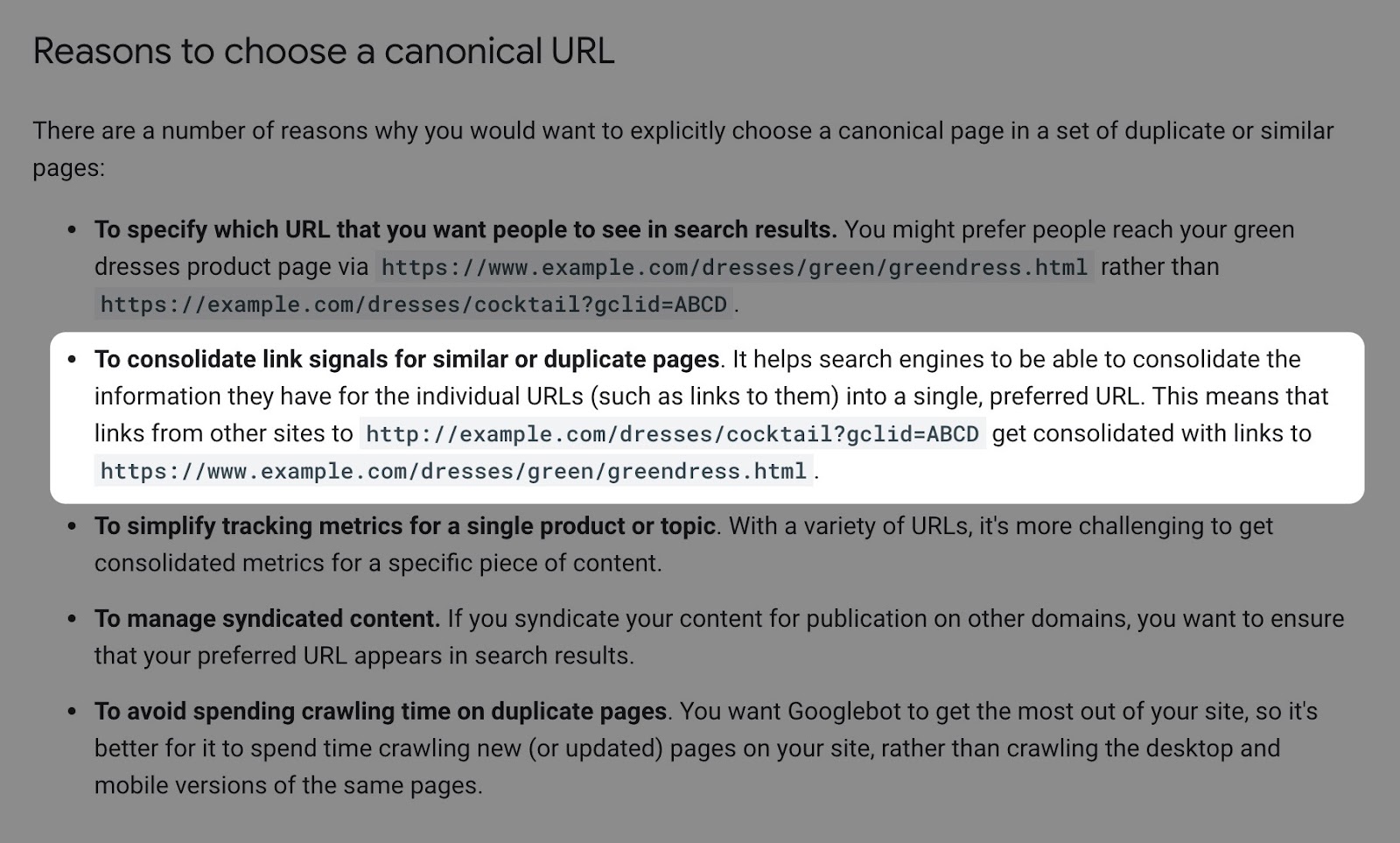
I vantaggi?
Se hai link verso delle pagine con navigazione a faccette, per le quali la versione non a faccette diventa la canonica, questi segnali provenienti dai link non vengono persi, e i motori di ricerca li passeranno alla pagine di categoria, il che potrebbe aiutare nel posizionamento.
Ecco un esempio su come implementare questa soluzione…
Poniamo caso che questo sia l’URL della tua pagina di categoria:
https://esempio.com/lavatrici/samsung/
Il tuo URL a faccette lavora con i parametri, quindi quando qualcuno applica un filtro, l’URL diventa molto simile a questo:
https://esempio.com/lavatrici/samsung/?dimensionecestello=16kg&colore=grigio&energyrating=A
All’interno dell’URL qui sopra, devi semplicemente inserire il tag canonical che punta nuovamente verso la pagina di categoria, in modo che il tag canonical diventi simile a questo:
<link rel="canonical" href="https://esempio.com/lavatrici/samsung/" />
E fai così all’interno dei tuoi header HTTTP:
Link: <https://esempio.com/lavatrici/samsung/>; rel="canonical"
Nonostante questa possa sembrare una soluzione semplice, come sempre, ci sono dei potenziali rischi. Google potrebbe infatti ignorare il tag canonical.
Infatti, i tag canonical vengono presi come “consigli” dai motori di ricerca e non come “direttive”. Quindi, se Google, per qualche motivo, crede che tu non abbia implementato il tag canonical correttamente, potrebbe decidere di ignorarlo.
I motivi più comuni per cui Google potrebbe decidere di ignorare il tuo tag canonical sono:
- Le pagine non sono duplicate.Se le tue pagine a faccette cambiano in maniera significativa quando applichi un filtro, Google crederà che non siano duplicate fra di loro. Ad esempio, se contenuti, titoli e header cambiano, Google potrebbe confondersi.
- Hai link interni verso le pagine con la navigazione a faccette.Se hai molti link interni verso pagine a faccette canonizzate, Google potrebbe fraintendere l’importanza della pagina e ignorare il tag canonical.
Se non vedi decrescere il numero di URL validi all’interno del report copertura di search console dopo aver implementato i tag canonical, vai al passaggio qui sotto.
2. Utilizza il report Parametri degli URL all’interno di Search Console
Se la canonizzazione non ha risolto i problemi legati all’indicizzazione, il report Parametri degli URL in GSC è probabilmente il modo migliore per ottimizzare la tua scansione. Questo report ti consente di dire a Google come gestire i parametri nei tuoi URL e lo aiuta a scansionarli più efficientemente.
Per contro, questo metodo funziona solo se la navigazione a faccette sfrutta degli URL parametrici (se non è il tuo caso vai al passaggio numero tre).
Utilizzare il report per gli URL parametrici è piuttosto semplice. Aggiungi un parametro per poi comunicare a Google in che modo questo influisce sul contenuto della pagina e se ci sono delle eccezioni alla regola che dovrebbe seguire.
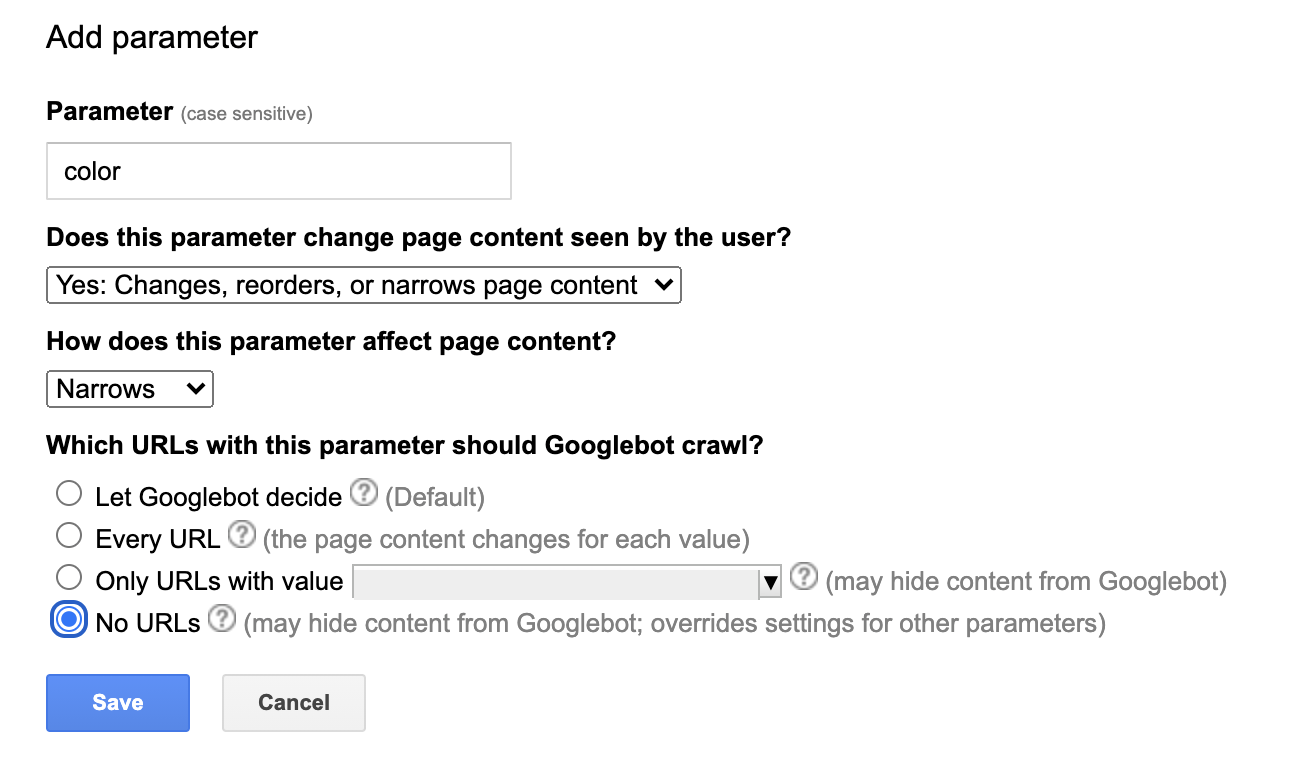
3. Sistema la scansione con il file robots.txt
Se stai affrontando un problema relativo al crawl budget e non hai bisogno di consolidare particolari segnali, potresti utilizzare il file robots.txt per far sì che Google non scansioni gli URL con navigazione a faccette.
Per bloccare Google e fare in modo che non scansioni degli URL all’interno del file robots.txt, puoi inserire una regola disallow come quella qui sotto:
User-agent: *
Disallow: *dimensione=*
In questo esempio, ho aggiunto due wildcard (*) al parametro. Se la tua navigazione a faccette funziona aggiungendo parametri alle directory, la tua regola dovrebbe invece essere resa in questo modo:
User-agent: *
Disallow: */dimensione/*
Ci sono due casi nei quali il file robots.txt non rappresenta una buona soluzione:
- Non ci sono pattern identificabili all’interno degli URL che puoi mettere in disallow. Questo potrebbe accadere quando ogni pagina ha dei parametri specifici o delle faccette che lavorano sulle cartelle.
- Vuoi consentire la scansione di alcuni URL e bloccarne altri. Ad esempio, vuoi che la cartella /colore/ sia scansionabile per la categoria delle t‑shirt (in quanto fornisce valore a chi ricerca), ma vuoi bloccarla per la categoria dell’intimo. Anche se in teoria potresti farlo mischiando delle regole di ‘Allow’ e ‘Disallow’ all’interno del robots.txt, questo comportamento potrebbe portare ad una difficile gestione su siti di larga scala.
Dovresti anche essere a conoscenza del fatto che bloccare la scansione non significa necessariamente che Google non indicizzerà gli URL bloccati. Parlando in maniera generica, Google farà in modo di rimuovere gli URL bloccati dall’indice—ma solo se questi non ricevono backlink o link interni di tipo follow. In altre parole, fintanto che non esistono segnali che possano far pensare a Google che quelle pagine siano importanti.
4. Nofollow e/o rimuovere link interni dalle URL a faccette
Se bloccare la scansione non elimina completamente i problemi relativi all’indicizzazione causati dalla navigazione a faccette, inserire l’attributo nofollow ai link interni che portano verso questi URL potrebbe risolvere il problema.
Esistono principalmente due fonti dalle quali provengono questi link:
- Link delle faccette di ricerca. Ovvero i link che provengono dalla tua navigazione a faccette.
- Link in altri punti del sito. Ad esempio articoli di blog, ecc..
Per i link delle faccette di ricerca, inserire un attributo nofollow è semplice. Questa però non è probabilmente la migliore idea se hai dei tag canonical sulle URL con navigazione a faccette e/o URL simili che vuoi indicizzare. Il motivo è che se Google finisce con il non scansionare questi link perché sono nofollow, potresti avere dei problemi di indicizzazione.
L’alternativa è quella di selezionare e scegliere quali faccette mettere in nofollow. Questo è un po’ più complicato da implementare da un punto di vista tecnico, ma può valere la pena farlo se vuoi intercettare parole chiave a coda lunda con la ricerca a faccette (ne parleremo più avanti).
Il problema principale di questo approccio è che non è particolarmente utile dopo che Google ha iniziato a interpretare rel=’nofollow’ come un suggerimento, nel senso che non è una direttiva come per il robots.txt.
In ogni caso, Google considera comunque un nofollow interno come segnale per capire che la URL all’interno dell’attributo href non è particolarmente importante e non dovrebbe avere priorità sulle altre.
È stato John Mueller a confermare questo:
[…] continueremo a utilizzare i link interni nofollow come segnale che ci comunica:
- Che tali pagine non sono interessanti.
- Google non ha bisogno di scansionarle.
- Non devono essere utilizzate per il posizionamento o l’indicizzazione.

Per quanto riguarda invece i link in altre parti del tuo sito, la soluzione migliore è semplicemente rimuoverli.
Puoi identificare link interni che portano a problemi a livello di faccette attraverso il Site Explorer di Ahrefs:
- Inserisci l’URL della navigazione a faccette che sta causando il problema.
- Vai sul report Backlink Interni.
- Filtra per tipologia Dofollow.
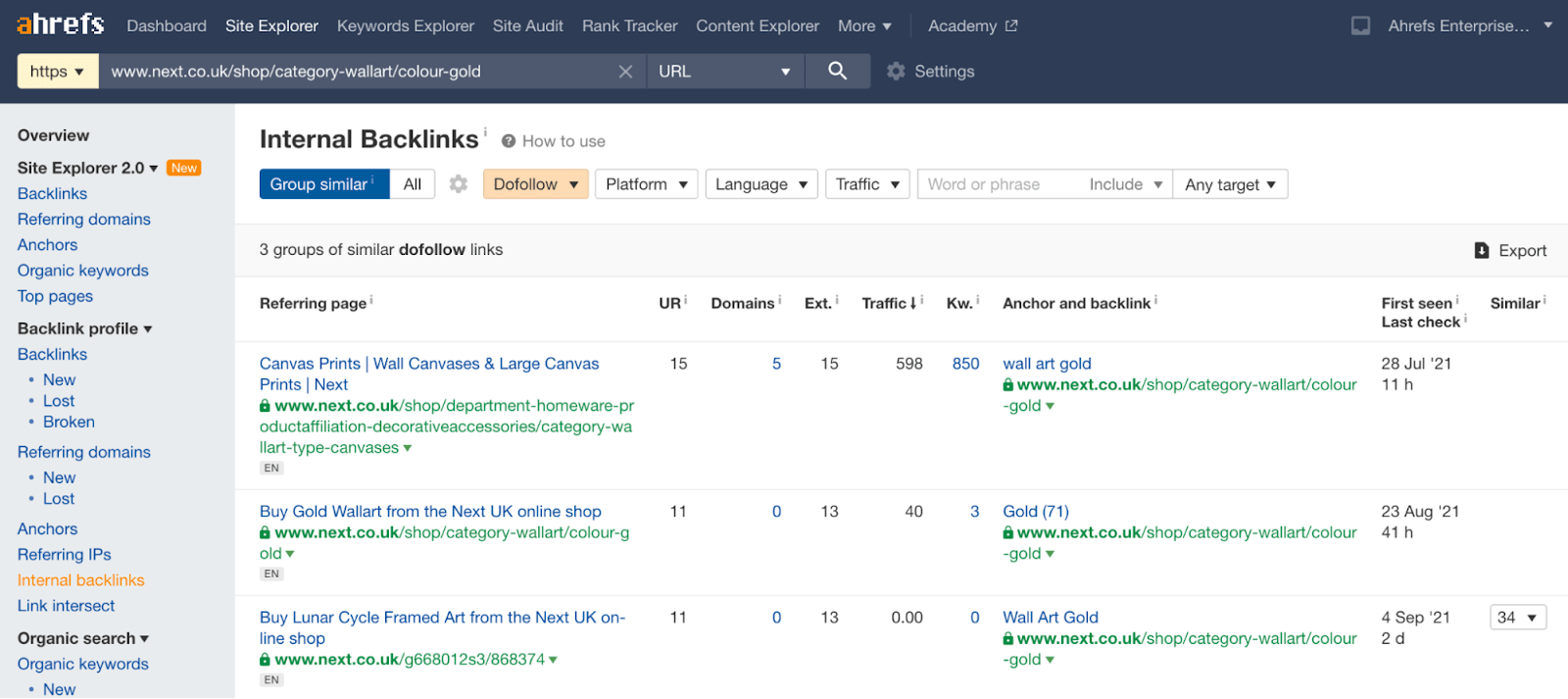
A questo punto puoi semplicemente identificare i link ‘follow’ in altre parti del tuo sito e rimuoverli.
5. Sistemare in maniera definitiva i problemi legati all’indicizzazione attraverso il tag noindex
Se stai ancora riscontrando problemi legati all’indicizzazione nonostante i passaggi che ti ho mostrato qui sopra, la tua ultima speranza è utilizzare il il tag noindex.
Il vantaggio del tag noindex è che si tratta di un modo certo per prevenire l’indicizzazione delle pagine con navigazione a faccette. Di contro, non puoi consolidare i segnali di posizionamento e, nel tempo, Google potrebbe smettere di scansionare i link su di una pagina non indicizzata, il che significa che questa non passerebbe nessun segnale di beneficio per il posizionamento.
Ma si tratta comunque di un buon modo per rimuovere delle URL con navigazione a faccette dall’indice di Google se tutto il resto non funziona.
Per implementare quello che ti ho appena detto, devi semplicemente aggiungere un meta tag robots nella sezione <head> dell’ URL interessata:
<meta name="robots" content="noindex">
O un header X‑Robots all’interno dei tuoi header HTTP per quella pagina:
X-Robots-Tag: noindex
Devi rimuovere/correggere qualsiasi blocco di scansione che possa prevenire l’URL dall’essere scansionato presente nel file robots.txt o nel tool per i Parametri degli URL. Se non fai questo, Google potrebbe non vedere la direttiva noindex—e quindi la pagina persisterebbe all’interno dell’indice.
Lettura consigliata: Robots Meta Tag & X‑Robots-Tag: Tutto Quello Che Devi Sapere
Dalla precedente sezione, dovresti esserti reso conto che correggere potenziali errori causati dalla navigazione a faccette non è un compito semplice.
Ognuna delle possibili soluzioni per sistemare la scansione e l’indicizzazione ha alcuni contro o delle complicazioni.
Ma esiste un miglior modo di fare le cose.
Poniamo caso che tu voglia implementare una nuova navigazione a faccette o crearne una per la prima volta. In questo caso, puoi aggirare tutte le problematiche qui sopra mantenendo tutti i benefici lato UX.
Ecco come:
1. Utilizza AJAX per evitare i link interni
Prima di tutto, costruisci la navigazione a faccette tramite AJAX e non aggiungere nessun link interno con il tag <a href=…>.
Facendo così gli utenti si godono un’ottima esperienza sulla pagina, ma Google non vedrà alcun link interno alle pagine con faccette, e quindi:
- Non le scansionerà
- Di conseguenza Google non le indicizzerà
- Tutto questo rimuoverà potenziali problemi legati al PageRank.
Ecco un esempio.
Ho implementato la navigazione a faccette utilizzando il plugin per WordPress WP Grid Builder su una risorsa che ho creato chiamata SEO Toolbelt.
Ecco il risultato:
Quando clicchi con il tasto destro per ispezionare l’elemento delle varie checkbox per applicare un filtro, vedrai che queste non includono un link <a href=…>, in modo da non permettere a Google di scansionare URL aggiuntivi.
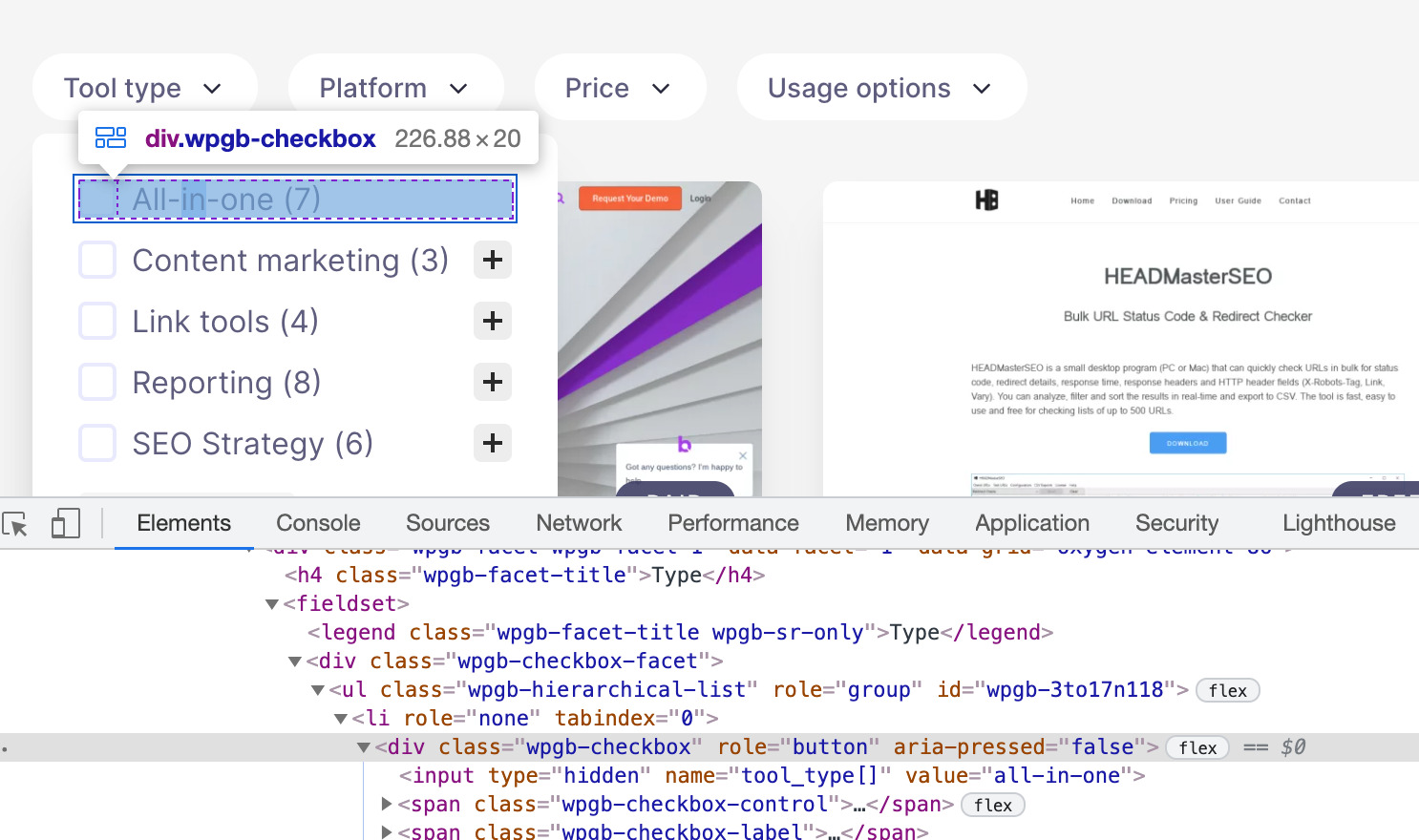
Grazie a questo, ho aggirato il problema senza dover pensare a sprechi di crawl budget derivanti dalla navigazione a faccette.
2. Assicurati che l’URL sia comunque condivisibile
In secondo luogo, dobbiamo assicurarci che quando un utente clicca su un filtro, l’URL venga aggiornato.
Consiglio di farlo in quanto effettivamente abbiamo variato il contenuto della pagina e, idealmente, se un utente salva la pagina tra i preferiti o la condivide con un amico, il contenuto dell’URL rifletterà comunque quanto applicato dal filtro dopo aver salvato/condiviso/linkato alla pagina.
Esistono due modi per farlo:
- Parametri degli URL (?)
- Hash degli URL (#)
La soluzione migliore sono gli hash, in quanto Google tende ad ignorare qualsiasi cosa si trovi a seguito di un hash in un URL.
WP Grid Builder utilizza i parametri, quindi dopo aver applicato un filtro, l’URL cambia diventando qualcosa di molto simile a questo:
https://seotoolbelt.co/tools/auditing/?_tool_type=browser-extension
Se provi ad accedere a quell’URL, troverai una griglia già filtrata.
In questo caso, dato che sto utilizzando dei parametri, devo anche creare un tag canonical verso la versione dell’URL senza parametri, quindi nell’esempio precedente:
https://seotoolbelt.co/tools/auditing/
Dato che queste versioni parametriche degli URL non hanno link interni ed è difficile che ne ricevano di esterni da altri siti (questo è fra l’altro l’unico modo in cui Google potrebbe scoprirne l’esistenza), corriamo pochi rischi.
3. Fornisci percorsi di scansione alternativi verso le pagine importanti per la ricerca
In alcune istanze, la versione filtrata di un URL potrebbe essere utile nella ricerca.
Ad esempio, esistono filtri per ‘Firefox’ e ‘Chrome’ all’interno della mia pagina dedicata alle estensioni SEO per browser. Entrambe queste pagine hanno potenziale di ricerca.
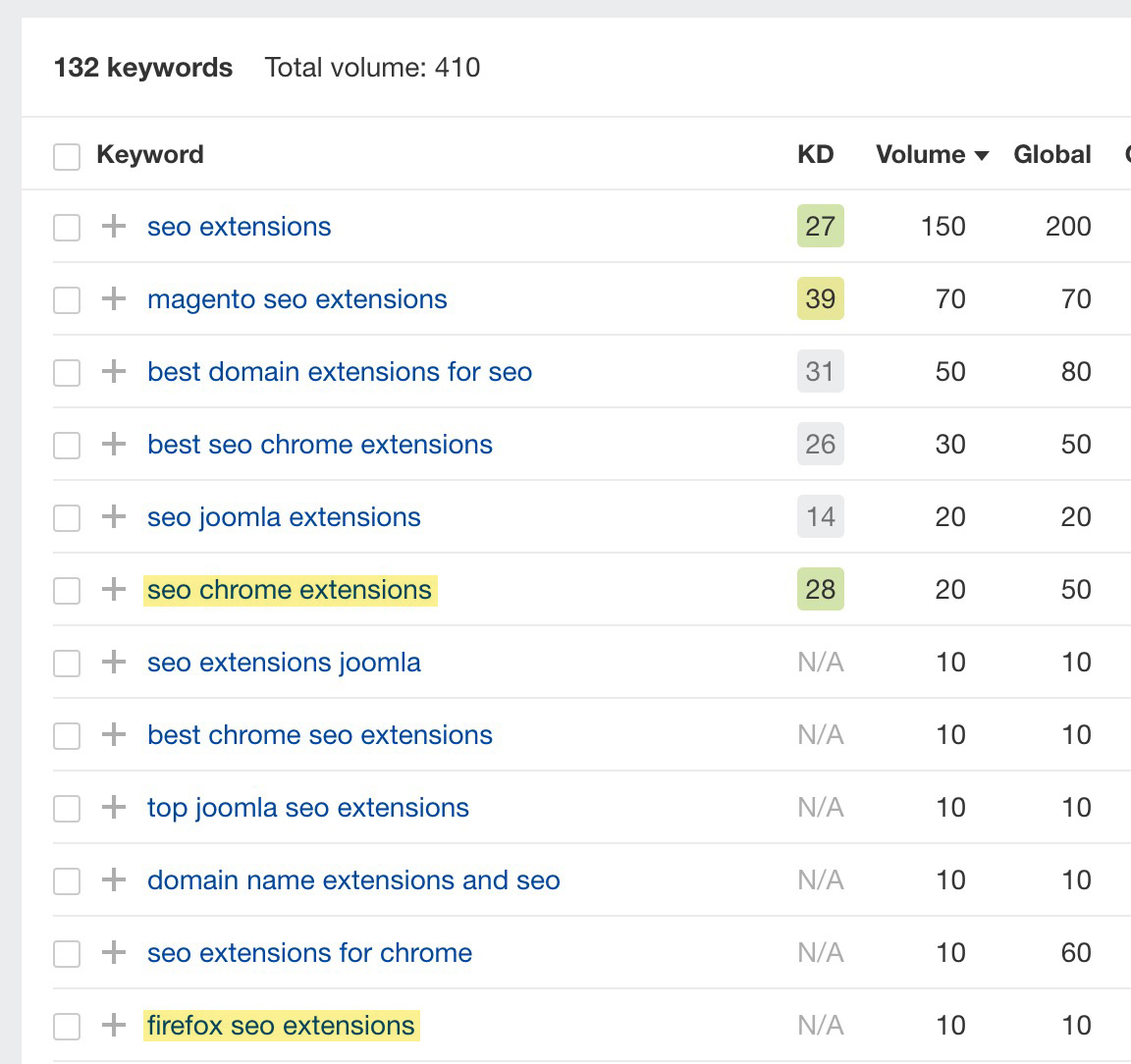
È quindi importante assicurarci che queste pagine abbiano un URL indicizzabile. Il modo migliore per farlo è assicurandosi di avere dei percorsi di scansione alternativi per queste pagine. Io l’ho fatto aggiungendo in cima alla pagina dei link di navigazione le versioni indicizzabili di queste pagine filtrate.

Queste sotto-collezioni sono generate secondo gli stessi attributi utilizzati per creare le versioni a faccette della pagine, ma ho espressamente deciso di renderle visibili.
Questa implementazione ha raggiunto diversi risultati:
- Ho prevenuto sprechi di crawl budget, in quanto la navigazione a faccette non contiene link interni.
- Le pagine con le faccette sono comunque condivisibili, risultano buone per la UX.
- Se una pagina con faccette ha potenziale di ricerca, posso effettuare modifiche editoriali per renderla indicizzabile.
Come puoi vedere questo trucco semplifica sensibilmente la gestione lato SEO e non ha punti deboli.
Finora, ho parlato della navigazione a faccette come un elemento che causa esclusivamente complicazioni lato SEO. Invece, puoi anche utilizzare la navigazione a faccette per ottenere più traffico, combinandola con una strategia per parole chiave a coda lunga.
Non posso esprimere quanti benefici può portare tutto questo se fatto nel modo corretto. I dati di Ahrefs mostrano come il 99.48% delle parole chiave riceve meno di 1,000 ricerche mensili, costituendo il 39.33% delle ricerche totali.
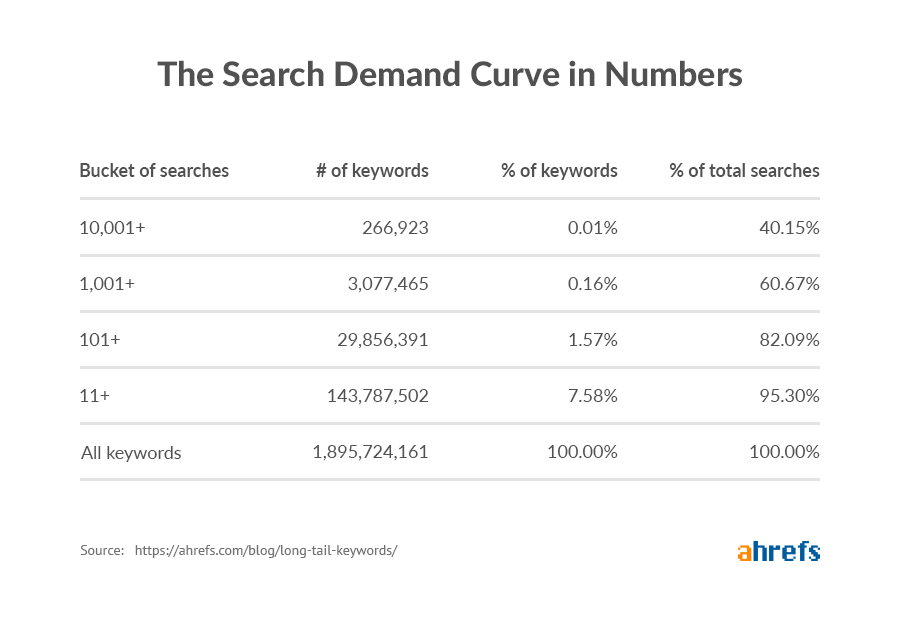
L’url della navigazione a faccette sono ideali per catturare il traffico delle code lunghe, in quanto creano delle versioni più specifiche delle pagine che solitamente intercettano query più ampie.
Per prima cosa, ti guiderò attraverso i passaggi per identificare le opportunità per cogliere più traffico a coda lunga con la navigazione a faccette; poi, farò delle considerazioni sulla loro implementazione.
1. Identifica le variazioni a coda lunga delle parole chiave
Per cominciare, identifica le opportunità in termini di parole chiave attraverso il Keyword Explorer di Ahrefs. Fare questo è incredibilmente facile.
Inserisci il nome di una categoria che hai già sul tuo sito, come ad esempio ‘jeans a vita alta’ (o ‘high rise jeans’ in inglese).
Vai poi sul report chiamato ‘Matching Terms’.
Utilizza la sidebar per spostarti su ‘Parent Topics.’
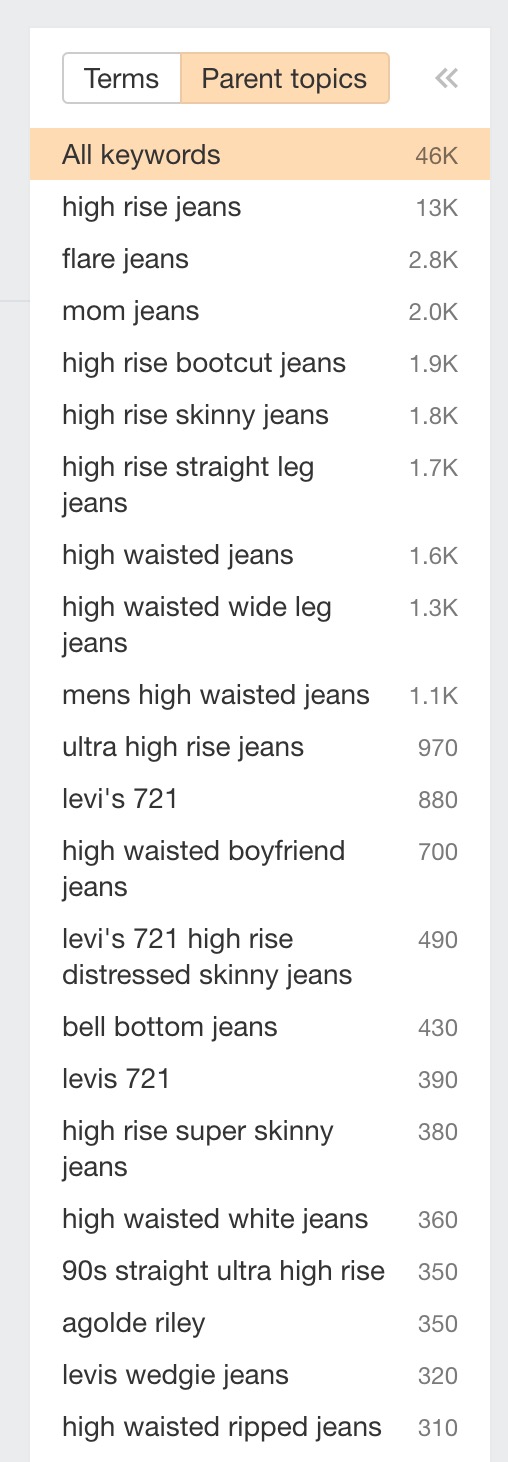
Facendo così, il tool raggrupperà automaticamente le parole chiave con una SERP simile. Successivamente potrai analizzare la lista per identificare potenziali pagine a faccette che vale la pena rendere indicizzabili. Ecco alcune di quelle che ho identificato rispetto allo screenshot qui sopra:
- high rise bootcut jeans (1,900 ricerche)
- high rise skinny jeans (1,800 ricerche)
- high rise wide leg jeans (1,300 ricerche)
- ultra high rise jeans (970 ricerche)
- high waisted boyfriend jeans (700 ricerche)
- high rise super skinny jeans 380 ricerche)
- high waisted white jeans (360 ricerche)
2. Rendi le pagine indicizzabili
In secondo luogo, dobbiamo dare a Google la possibilità di scansionare e indicizzare queste pagine.
Questo può essere fatto in diversi modi, a seconda della tipologia della tua navigazione a faccette.
Navigazione a faccette con link interni
Se hai implementato la navigazione a faccette nel modo non ideale con dei link interni, dovrai assicurarti che per l’URL da indicizzare:
- Il tag canonical sia autoreferenziale
- Il tag noindex venga rimosso (se presente)
- Tutte le regole correlate di disallow all’interno del robots.txt vengano rimosse (o che venga aggiunta una regola allow).
- Gli attributi nofollow dei link interni verso tali pagine vengano rimossi (se presenti)
Quello che devi fare, tra quanto indicato nei punti elencati, dipende dalla tua implementazione, ma il concetto importante è che i motori di ricerca devono essere in grado sia di scansionare e di indicizzare queste pagine.
Navigazione a faccette AJAX senza link
Dovrai creare una pagina di sotto-categoria per questo setup come menzionato nella sezione precedente.
La navigazione a faccette, infatti, non genera link interni, e non puoi quindi utilizzarla per creare queste pagine.
La maggior parte delle piattaforme di ecommerce supporta la creazione di sotto-pagine, ma idealmente dovresti avere delle funzionalità aggiuntive che ti permettano di basare le sottocategorie dei prodotti su una versione filtrata della categoria genitore, principalmente per evitare di dover creare ogni sottocategoria manualmente. In questo modo, otterrai i benefici del poter generare velocemente pagine come la navigazione a faccette, ma evitando complicazioni lato SEO.
Ad esempio, se stessimo creando la sottocategoria ‘jeans a vita alta skinny”, dovremmo ereditare i prodotti dalla categoria genitore ‘jeans a vita alta’, mostrando però solo quelli con l’attributo skinny.
3. Ottimizza gli URL per la ricerca
Questo consiglio è piuttosto ovvio, ma dovresti condurre delle ottimizzazioni fondamentali lato SEO, come:
- Avere degli URL semplici e leggibili. Ad esempio, il tuo URL dovrebbe idealmente essere
/jeans/vita-alta/skinny/, e non/jeans/vita-alta/?fit_variant=skinny - Ottimizzare tag title, meta description e header.
- Avere contenuti unici.
- Aggiungere gli URL alla sitemap.
La complicazione principale in questo caso è data dal fatto che stai impostando una pagina con navigazione a faccette su impostazioni di scansione e indicizzazione diverse da quelle di default.
Questo avviene perché, a livello tecnico, le pagine con navigazione a faccette sono dinamiche e non sono equiparabili a una sottocategoria.
Avrai la necessità di alcune funzionalità personalizzate per far sì che le ottimizzazioni on-page critiche e necessarie siano possibili per gli URL con la navigazione a faccette.
Conclusione
Spero che ora tu abbia compreso non solo i possibili rischi SEO derivanti dalla navigazione a faccette, ma anche le opportunità che questa presenta per l’ottimizzazione delle parole chiave a coda lunga.
Domande sulla navigazione a faccette? Tweettami.

