
Quando costruiscono un indice del web, le aziende che operano in questo settore devono prendere delle decisioni in merito a concetti come crawling, parsing e dati indicizzati. Anche se probabilmente esiste molto terreno in comune fra i diversi indici, saranno anche presenti alcune differenze in base alle decisioni prese da ciascuna azienda.
Per essere il più trasparenti possibile, ci piacerebbe mostrare alle persone come funziona l’indice dei link di Ahrefs.
- Cos’è un link
- Quali link vengono indicizzati?
- Quali domini vengono indicizzati?
- Perché non possiamo vedere tutti i link
I link portano gli utenti da una pagina all’altra quando vengono cliccati. Esistono molti modi per crearne uno, ma quello più classico ed utilizzato è l’elemento HTML <a> con un attributo href.
<a href="url">link text</a>
È però possibile creare link con altri elementi, inclusi:
- Onclick
- Bottoni
- Ng-click
- Option/value
- E molti altri…
In un mondo ideale, tutto ciò che funziona come un link sarebbe salvato nel nostro indice. Purtroppo però, non viviamo in un mondo ideale. Né Ahrefs né Google salvano tutte le tipologie di link, in quanto caricare una pagina e fare click ogni link presente su di essa rappresenta un processo non particolarmente efficace. Questo è esattamente quello che dovresti fare anche tu se volessi trovare tutti i link funzionanti per gli utenti.
Quello che fanno i crawler, invece, è recuperare le pagine, effettuarne possibilmente il rendering, e poi estrarre e memorizzare le varie tipologie di link. Ogni crawler funziona in maniera diversa, vediamo quindi come funziona quello di Ahrefs.
Link che memorizziamo
Ecco alcune tipologie di link che memorizziamo all’interno del nostro indice.
Link esterni
I link da un sito web ad un altro, creati utilizzando il classico tag HTML <a> con un attributo href.
Link interni
I link che portano da una pagina a un’altra sullo stesso sito web. Ci sono 22,21 trilioni di backlink interni presenti nel nostro indice. Questi sono molti più rispetto al link esterni presenti. Siamo l’unico strumento SEO che ti permette di avere accesso a questi dati senza dover fare un crawl (o scansione) apposita. Utilizziamo i dati sui link interni per calcolare l’URL Rating (UR), in maniera simile a come Google li utilizzerebbe per il calcolo del PageRank.
Se vuoi vedere quando abbiamo scansionato una URL per la prima e l’ultima volta, puoi analizzare il report chiamato “Migliore per Link” all’interno del Site Explorer. All’interno troverai delle schede per visualizzare sia i link Esterni che Interni.
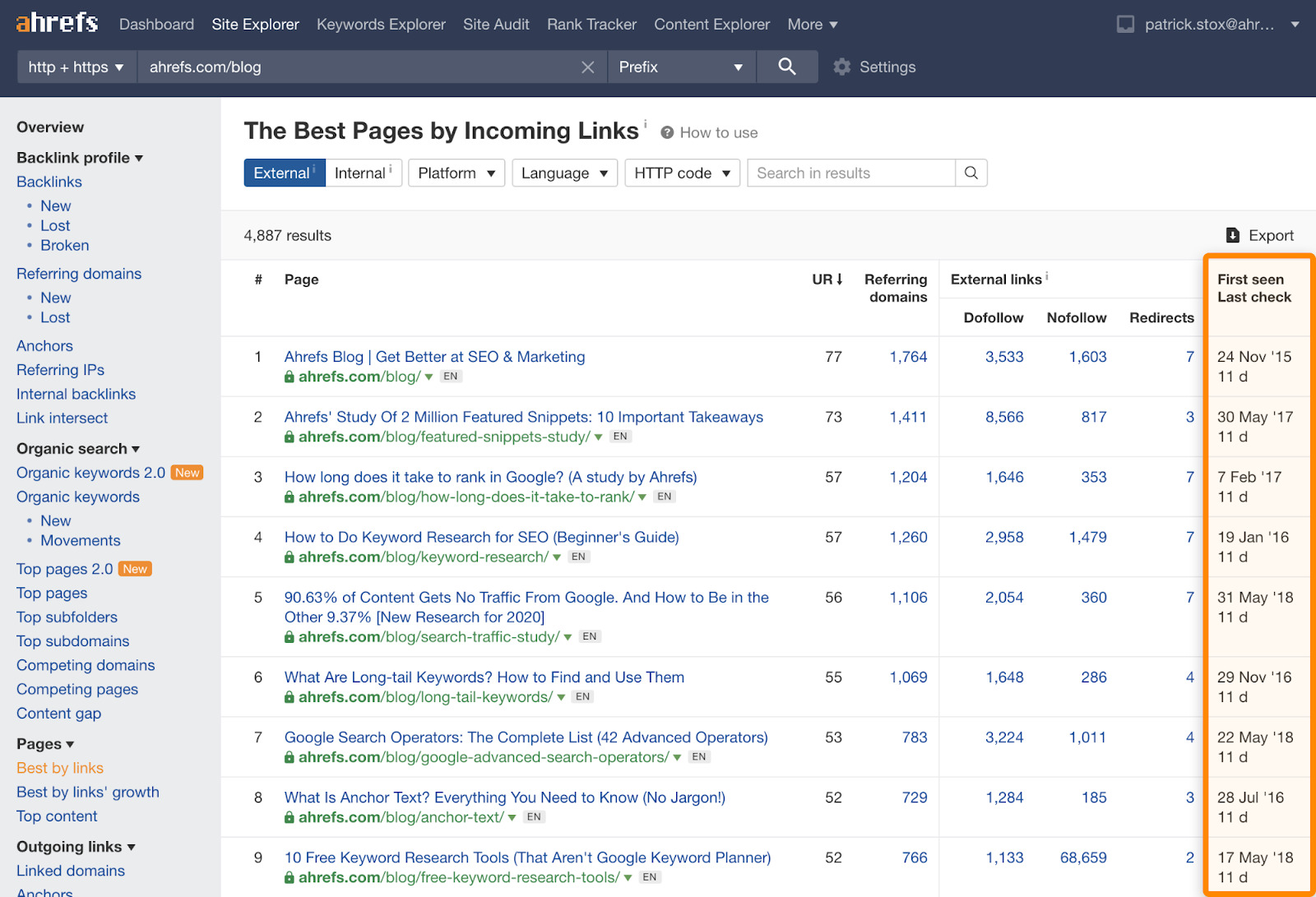
Link che potremmo memorizzare
Ecco alcuni link che memorizziamo solo in determinate circostanze.
Link inseriti tramite JavaScript
Dato che Google renderizza tutte le pagine, riesce a contare anche i link inseriti attraverso JavaScript e che non sono presenti nel codice HTML. Fare dei rendering così su larga scala consuma molte risorse rispetto al download del solo codice HTML delle pagine. Ad Ahrefs, eseguiamo il render di circa 80 milioni di pagine al giorno. Questo è il motivo per cui abbiamo nel nostro indice alcuni di questi link inseriti tramite JavaScript, ma non tutti. Al momento siamo l’unico strumento che effettua il rendering delle pagine durante il processo di crawl del web, ed abbiamo quindi dei dati che non sono a disposizione degli altri strumenti.
In ogni caso, ci limitiamo a contare i link inseriti tramite JavaScript solo se sono in formato HTML, rappresentati quindi da un tag <a> e con un attributo href. Questa tipologia di link viene evidenziata nel nostro report con il tag “JS”, in questo modo:

Link da pagine con parametri all’interno della URL
I parametri sono delle aggiunte che vengono fatte ad una URL, come ?tag=qualcosa. Potresti vedere alcune di queste URL all’interno del nostro indice, ma si tratta solitamente di parametri che mostrano contenuti diversi. In molto casi infatti, le pagine che contengono parametri all’interno della URL hanno lo stesso contenuto. Noi abbiamo molti sistemi integrati nel nostro strumento che consolidano le URL alla versione canonica e aggiungono ulteriori protezioni contro cicli infiniti di scansione. Gli altri strumenti non hanno solitamente un sistema di protezione del genere. Questo significa che potrebbero contare lo stesso link più di una volta.
Link che proviamo a non memorizzare
Ecco le tipologie di link che cerchiamo di non memorizzare.
Link da pagine con parametri all’interno della URL
Come menzionato qui sopra, ci sono buoni e cattivi tipi di parametri. Noi cerchiamo di non memorizzare quelli che sono duplicati.
Link da pagine che possono creare infiniti percorsi di scansione
Questi percorsi creano un numero di possibili URL potenzialmente infinito. I parametri sono una possibile forma, ma esistono anche i filtri, i contenuti dinamici e i famosi broken link. Come detto in precedenza, abbiamo molti sistemi di protezione per far sì che i link di questa tipologia non vengano presentati all’interno dei nostri report. Rispettare la canonicalizzazione e prioritizzare determinate pagine sono solamente due di questi sistemi di protezione. Ogni indice deve confrontarsi con questa tipologia di link, con il rischio quindi di gonfiare e distorcere il conteggio dei link stessi.
Link che non memorizziamo
Ecco i link che non memorizziamo mai.
Link nei PDF o in altri documenti
Google converte molti formati di documenti in HTML, in modo da poterli indicizzare come farebbe con ogni altra pagina. Questo significa che conteggiano anche i link presenti in questi documenti. Non credo che esistano strumenti SEO che memorizzano tale tipologia di link al momento, ma non sarebbe una cattiva idea farlo. Un giorno probabilmente lo faremo anche noi, ma sono preoccupato che lo sforzo e le risorse richieste non ne giustificherebbero il fine. Secondo quanto detto da John Mueller, Webmaster Trend Analyst per Google, i link all’interno dei PDF non hanno praticamente nessun effetto sui risultati di ricerca.
Link all’interno di iframe
Gli iframe consentono di mostrare una pagina all’interno di un’altra pagina. Proprio per questo motivo, non prendiamo in considerazione i link all’interno degli iframe. Questi vengono comunque mostrati agli utenti, di conseguenza alcuni strumenti potrebbero tenerne conto, anche se tecnicamente appartengono ad una pagina diversa. Non sappiamo se Google conti o no questi link.
Link da pagine non indicizzate
Questi link li ignoriamo. Esistono informazioni differenti e contrastanti che gli impiegati di Google ci hanno fornito in merito al loro ruolo nel calcolo dei link. Ogni strumento prende diverse posizioni in merito.
something with noindex will never reach the serving index, but we will have the fetched copy for things like link graph calculation.
— Gary 鯨理/경리 Illyes (@methode) December 17, 2020
“Un qualcosa in noindex non raggiungerà mai l’indice, ma terremo comunque una copia della pagina per cose come il calcolo del grafico dei link.”
Stesso link da IP multipli
Una cosa divertente del web è che i siti potrebbero servire la stessa pagina da diversi indirizzi IP. Se questo è il caso, un indice potrebbe contenere conteggi multipli dello stesso link. Noi non facciamo questo. Associamo infatti i link alla pagina sulla quale sono presenti.
Link multipli verso una pagina provenienti dalla stessa pagina
Al momento, teniamo conto solo di una versione di un link presente più volte su una pagina. Se è infatti presente un link ad una pagina che parte dal menù, e poi questo è ripetuto anche all’interno del contenuto della pagina stessa, conteremo uno solo di questi link. In futuro queste circostanze potrebbero cambiare, in modo da dare agli utenti un maggior numero di informazioni e dati. Google tiene conto di tutte le versione di un link per passare il PageRank, ma utilizza solo una versione del testo di ancoraggio.
Altri fattori relativi ai link che hanno un impatto sull’indice
Comprendere come contiamo i link è una cosa, ma ci sono molti altri motivi per cui un link potrebbe o non potrebbe venir conteggiato.
Numero di link per pagina
Non credo abbiamo un limite per il numero di link che contiamo su di una pagina, ma abbiamo un limite di dimensione che in ultima analisi può impattare il numero di link che vediamo. Google consiglia di non avere più di qualche migliaio di link per pagina.
Redirect e canonical
Ad Ahrefs, diamo per buoni tutti i redirect e i canonical, consolidando i link nel modo in cui un sito ci dice di farlo. Google potrebbe avere un processo più complicato di questo, in quanto hanno a disposizioni molti segnali per determinare quale pagina è la versione canonica. Noi manteniamo le cose semplici, in quanto è impossibile capire come Google veda una specifica situazione, e se trattassimo i canonical ed i redirect in maniera diversa ogni volta, non faremmo altro che confondere gli utenti.
Questi link vengono taggati nel nostro report con “301”, “302”, o “Canonical”:
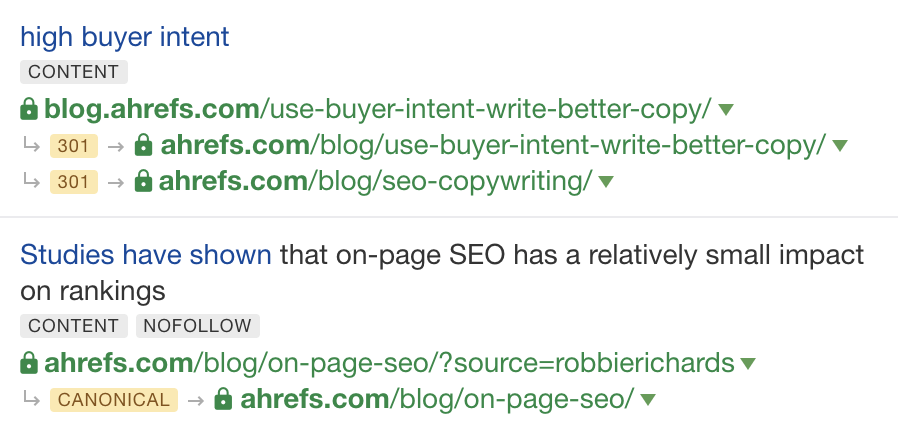
Link canonici e 301 all’interno del Site Explorer di Ahrefs.
Su Ahrefs, abbiamo un report chiamato Domini Referral che mostra tutti i domini che hanno dei link ad uno specifico sito o pagina web.
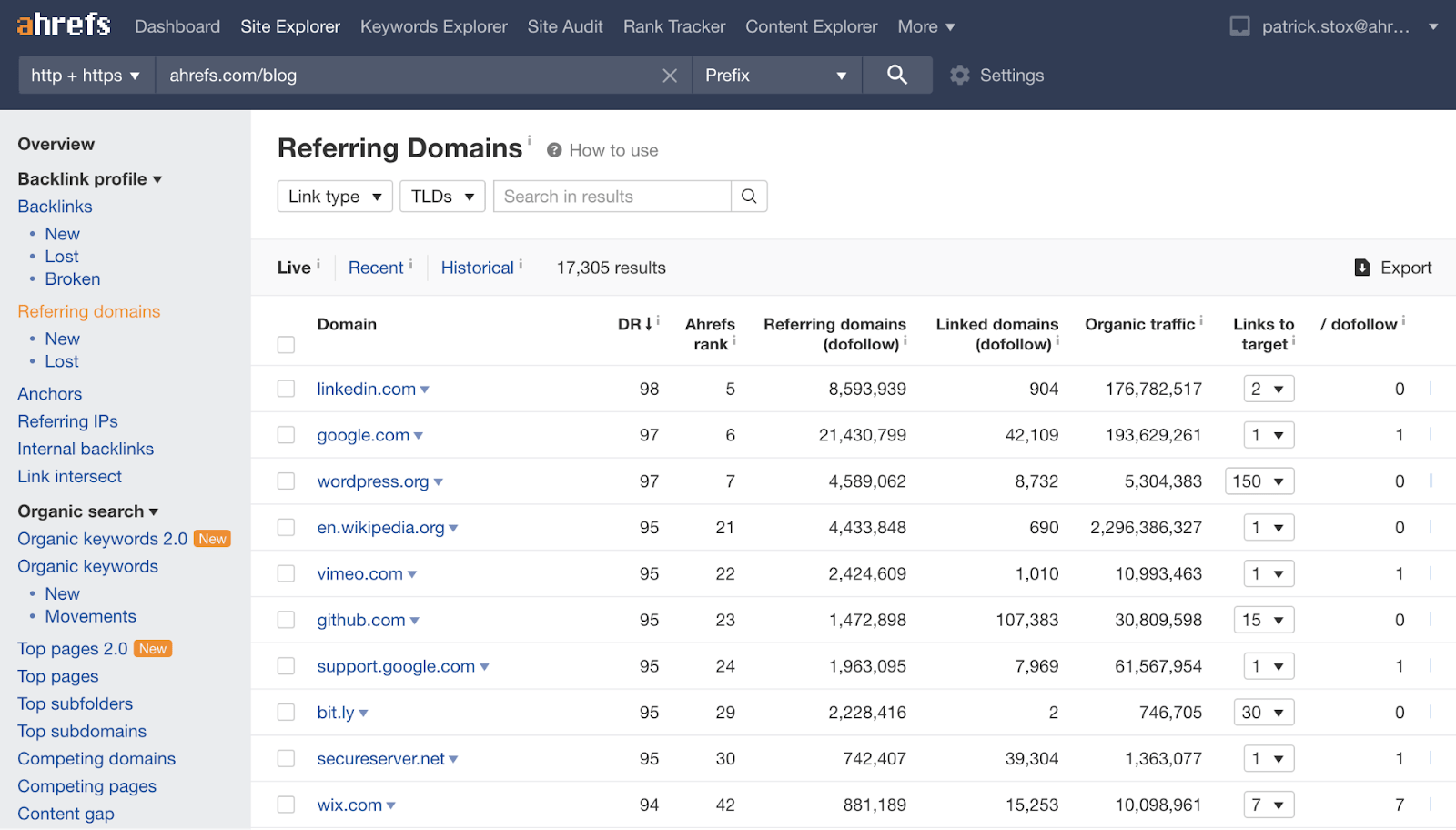
Il report Domini Referral all’interno del Site Explorer di Ahrefs.
In che modo contiamo i domini?
Potresti pensare che si tratta di una domanda che prevede di una semplice risposta. Dopotutto, si tratta solo di dominio.com, giusto? Sfortunatamente le cose sono più complesse, in quanto esistono diversi modi per contare i domini. Un’opzione è quella di trattare ogni dominio registrato come un singolo dominio—e questo sembra essere il modo in cui Google aggrega i domini all’interno di Google Search Console. Un’altro modo consiste nel trattare ogni sotto-dominio come un dominio differente. In alternativa potresti anche aggregare alcune sezioni di un sito e non altre (come fa Google), o decidere di valutare ogni sezione di un sito in base alle tecnologie utilizzate, ecc.. Insomma, esistono molte opzioni.
Su Ahrefs, abbiamo ~175 milioni di domini verificati. Il processo di verifica e valutazione include la rimozione dei domini che contengono spam e la divisione di alcuni sotto-domini dove abbiamo stabilito che diversi utenti controllano diverse aree. Abbiamo una lista personalizzata per questo scopo, ma è molto simile a quella pubblica che è possibile trovare su https://publicsuffix.org/list/.
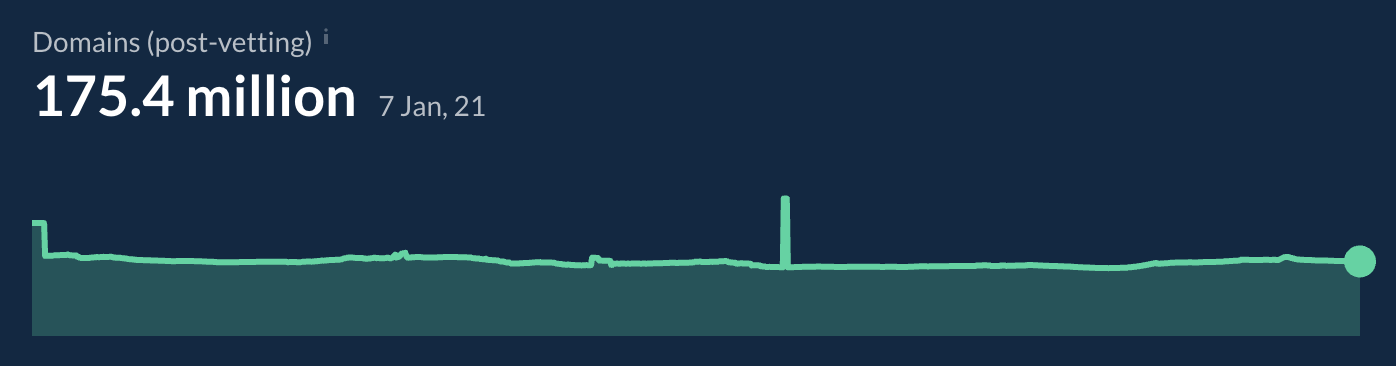
È importante notare che il modo in cui i domini vengono definiti si riflette anche nel modo in cui i domini referral vengono conteggiati. Ecco alcuni esempi di cosa alcuni strumenti, ma non Ahrefs, potrebbero contare come domini separati:
- Versioni mobile dei sottodomini (m.dominio.com, mobile.dominio.com, ecc.)
- Sottodomini relativi a Paesi/Lingue(en.dominio.com, fr.dominio.com, de.dominio.com, jp.dominio.com, ecc). Potrebbero esserci eccezioni relative a questo aspetto nel nostro indice, come wikipedia.org, ma non è la nostra pratica standard.
- Sottodomini casuali (supporto.dominio.com, immagini.dominio.com, ecc.)
Un’altra decisione che gli strumenti relativi all’analisi dei backlink devono prendere, è se conteggiare alcune sottocartelle come domini differenti. Ad esempio, credo che la maggior parte degli indici conteggi i diversi blog presenti sulle piattaforme più famose (es. utente1.blogger.com, utente2.blogger.com) come domini differenti, in quanto diversi utenti hanno il controllo su quello specifico sottodominio. Ma perchè non fare lo stesso per siti come medium.com/utente1 o githubcom/utente1? Su Ahrefs, al momento, non facciamo questo, ma esiste una possibilità che potremmo farlo in futuro lì dove diversi utenti hanno il controllo su una specifica sottocartella all’interno di un sito.
Il punto è che esistono davvero tanti modi per conteggiare i domini. Questo è ancora più evidente se si analizzano le figure riportate dalle aziende che si occupano di contare il numero di siti presenti su internet. Secondo Verisign, sono stati registrati 370,7 milioni di domini durante il Q3 del 2020 tenendo conto di tutti i TLD. Secondo Netcraft, esistono 1.229.948.224 siti ospitati su 263.787.870 domini unici con 193,8 milioni di siti attivi nel Novembre 2020. Internet Live Stats sostiene invece che ci siano un totale di 1,8 miliardi di siti, di cui meno di 200 milioni attualmente attivi. Ogni azienda ha chiaramente un metodo diverso per conteggiare i domini.
Per riassumere, quello che facciamo ad Ahrefs è prendere tutti i siti di cui siamo a conoscenza, rimuovendo poi i domini che contengono spam, quelli inattivi, e aggiungendo poi alcuni sottodomini per i siti come blogspot.com. Questo è il modo in cui abbiamo ottenuto il numero di circa ~175 milioni di siti. Altri indici potrebbero compiere questa operazione in maniera diversa ed ottenere un conteggio finale differente.
Man mano che scansionando il web identifichiamo tutti i vari link, ma siamo abilitati a scansionare solo i siti dove ci è consentito farlo. Se il proprietario di un sito blocca l’accesso al bot di Ahrefs (AhrefsBot) all’interno del file robots.txt, non possiamo scansionare il sito. Se ad esempio ottieni un link da sitoweb.com e quello blocca AhrefsBot, non possiamo accedere al sito e di conseguenza il backlink non verrà conteggiato nel nostro indice. Blocchi a livello di IP, user-agent da specifici server (diverso dal blocco tramite robots.txt), timeout del server, bot protection e molte altre cose possono influenzare la nostra capacità di scansionare alcuni siti. Scansionare il web su larga scala non è semplice.
Abbiamo diversi indici per i link
Ogni strumento deve prendere decisioni su come immagazzinare e recuperare i dati. Su Ahrefs, questi dati vengono divisi tra vari indici.
- Live — i link che vediamo ancora attivi sul web. Questo rappresenta al meglio lo stato attuale del web ed è quello che la maggior parte degli utenti reputa particolarmente utile.
- Recent — link che abbiamo visto attivi sul web negli scorsi 3–4 mesi.
- Historical — tutti i link che abbiamo mai incontrato. Questa è la lista più comprensiva, ma molti link potrebbero non essere più esistenti.
Puoi selezionare l’indice che preferisci all’interno dei report relativi ai backlink e ai domini referral.
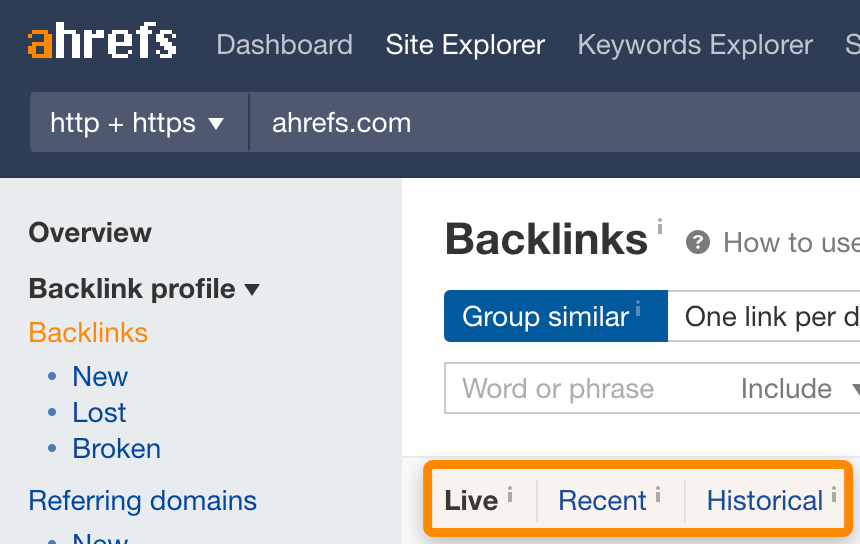
Altri indici potrebbero scegliere di mostrare tutti i dati che hanno a disposizione e, nonostante questo possa tradursi nel mostrare molti più link, molti di questi potrebbe non esistere più.
Conclusioni
Ci tenevamo a condividere con voi, i nostri utenti, più informazioni sul nostro indice, in modo che possiate prendere delle decisioni informate. Ci piacerebbe anche sapere se credete che dobbiamo cambiare qualcosa, e perchè dovremmo farlo.
Se ti trovi a confrontare indici di link, o hai domande relative ai nostri dati, sentiti libero di contattarci e porci delle domande.
Tradotto da Matteo Ginnetti, Consulente Digital Marketing.


