
In den meisten Fällen ist die Sache klar: Du hast das Crawling in deiner robots.txt-Datei blockiert. Es gibt jedoch auch einige weitere Bedingungen, die das Problem hervorrufen können. Gehen wir also den folgenden Prozess der Fehlerbehebung durch, um die Probleme bestmöglich diagnostizieren und beheben zu können:
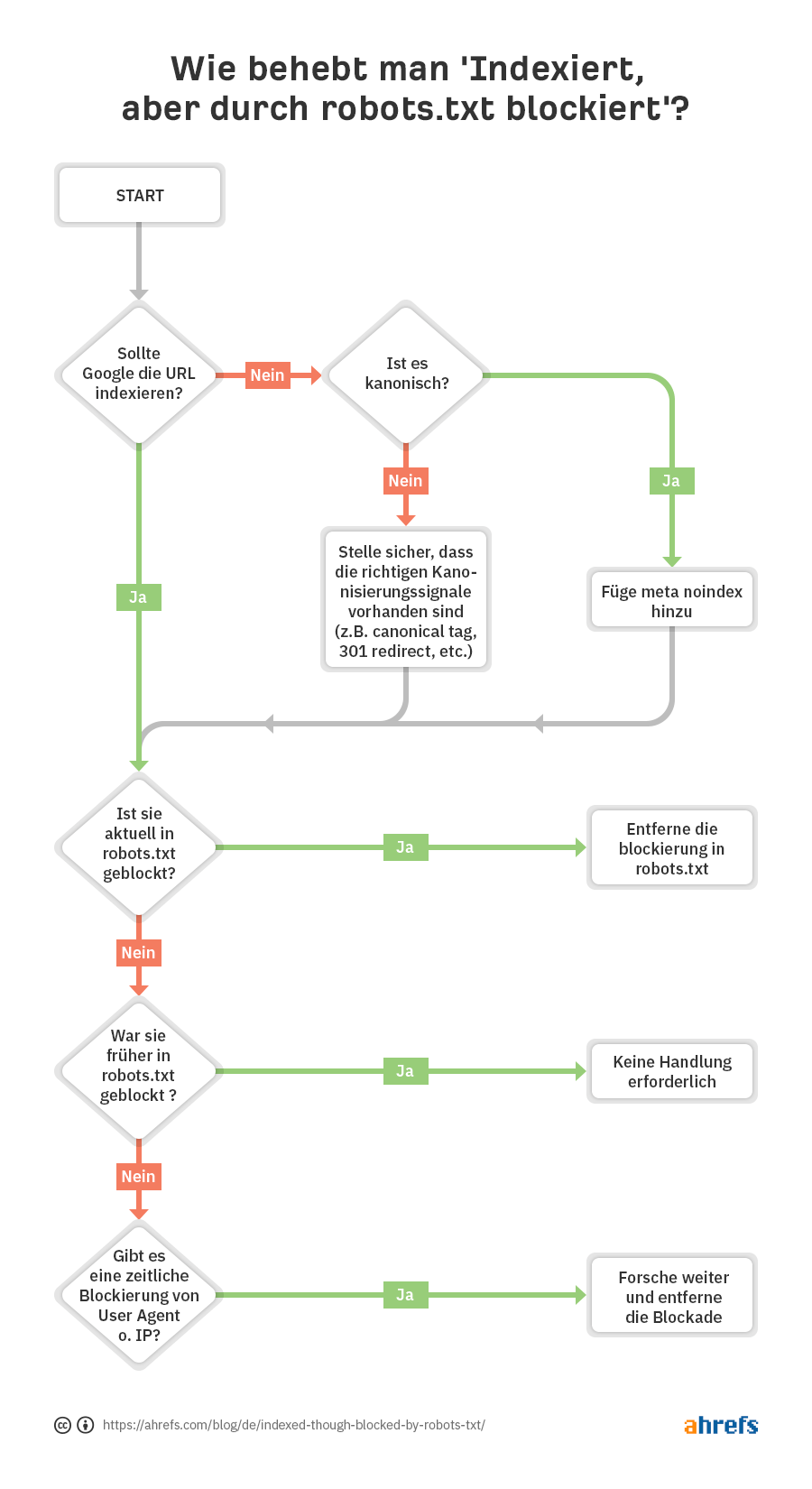
Wie du siehst, besteht der erste Schritt darin, sich zu fragen, ob Google die URL indexieren soll.
Wenn du nicht möchtest, dass die URL indexiert wird…
Füge einfach ein noindex Meta Robots Tag hinzu und stelle sicher, dass das Crawling erlaubt ist — vorausgesetzt, es ist kanonisch.
Wenn du eine Seite für das Crawling blockierst, kann Google sie trotzdem indexieren, weil Crawlen und Indexieren zwei verschiedene Dinge sind. Wenn Google eine Seite nicht crawlen kann, erfasst es das noindex Meta Tag auch nicht und indexiert die Seite möglicherweise trotzdem, weil sie Links enthält.
Wenn die URL auf eine andere Seite kanonisiert wird, solltest du kein noindex Meta Robots Tag hinzufügen. Stelle einfach sicher, dass die richtigen Kanonisierungssignale vorhanden sind, einschließlich eines Canonical Tags (kanonischer Tag) auf der kanonischen Seite, und erlaube das Crawling, damit die Signale durchgelassen und korrekt konsolidiert werden.
Wenn du möchtest, dass die URL indexiert wird…
Du musst herausfinden, warum Google die URL nicht crawlen kann und die Blockierung aufheben.
Die wahrscheinlichste Ursache ist eine Crawling-Blockierung in der robots.txt-Datei. Es gibt allerdings noch ein paar andere Fälle, in denen Meldungen angezeigt werden können, die angeben, dass du blockiert wirst. Im Folgenden gehen wir diese in der Reihenfolge durch, in der du auch wahrscheinlich nach ihnen suchen solltest.
- Überprüfe, ob eine Crawling-Blockierung in der robots.txt-Datei vorliegt
- Überprüfe, ob intermittierende Blockierungen vorliegen
- Überprüfe, ob eine User-Agent-Blockierung vorliegt
- Überprüfe, ob eine IP-Blockierung vorliegt
Überprüfe, ob eine Crawling-Blockierung in der robots.txt-Datei vorliegt
Am einfachsten lässt sich das Problem mit dem robots.txt-Tester in der GSC erkennen, der die Blockierungsregel anzeigt.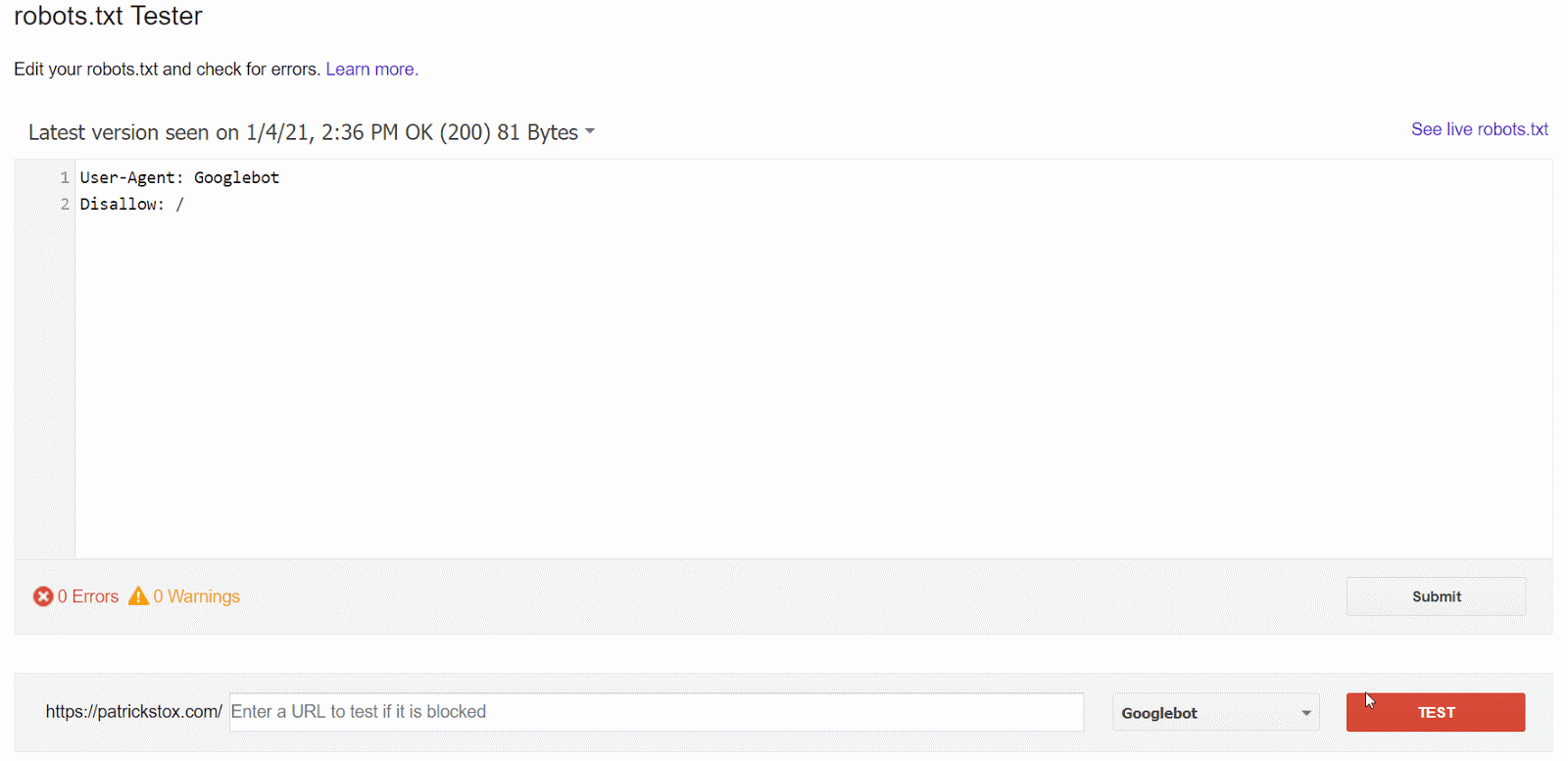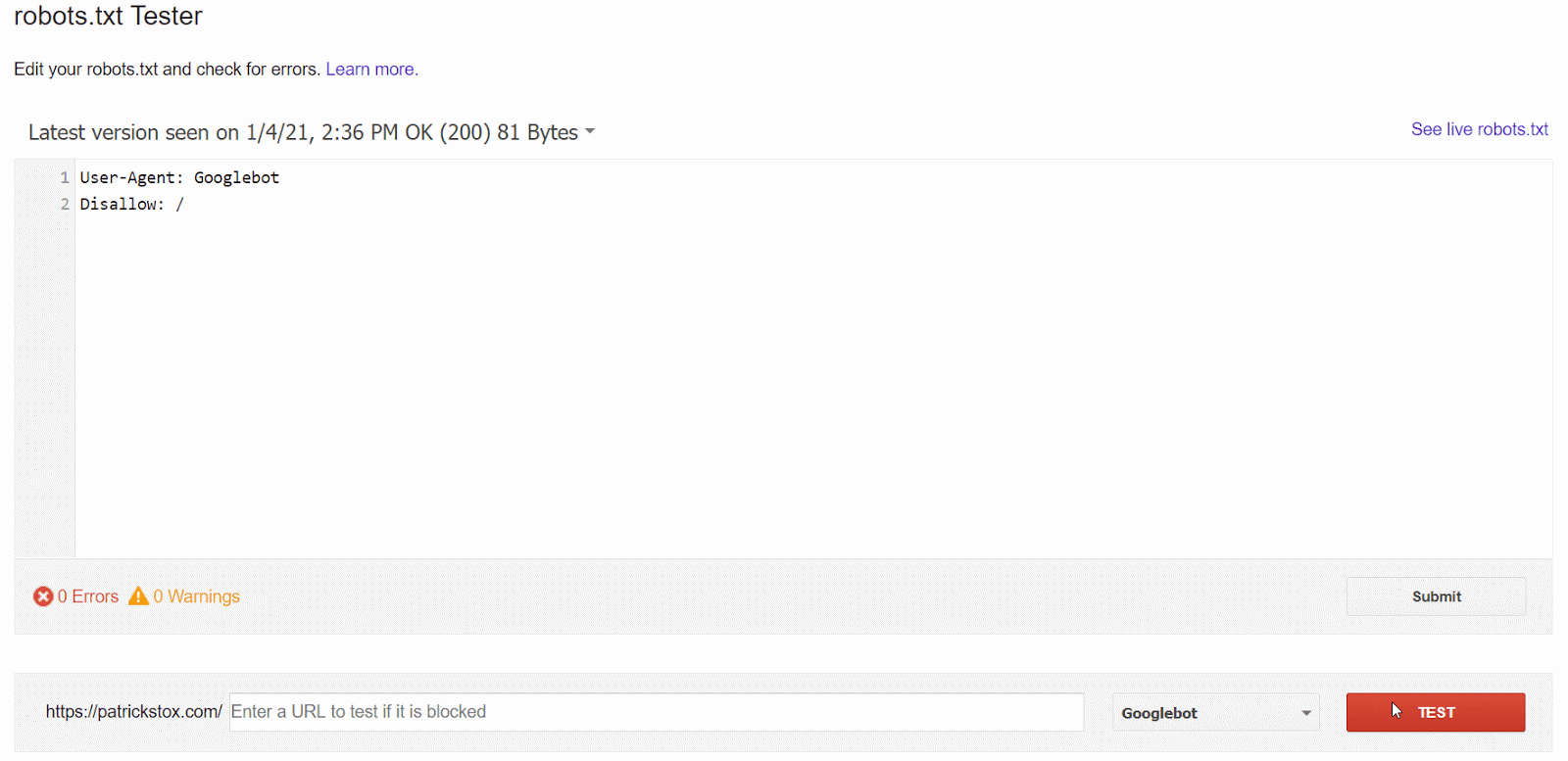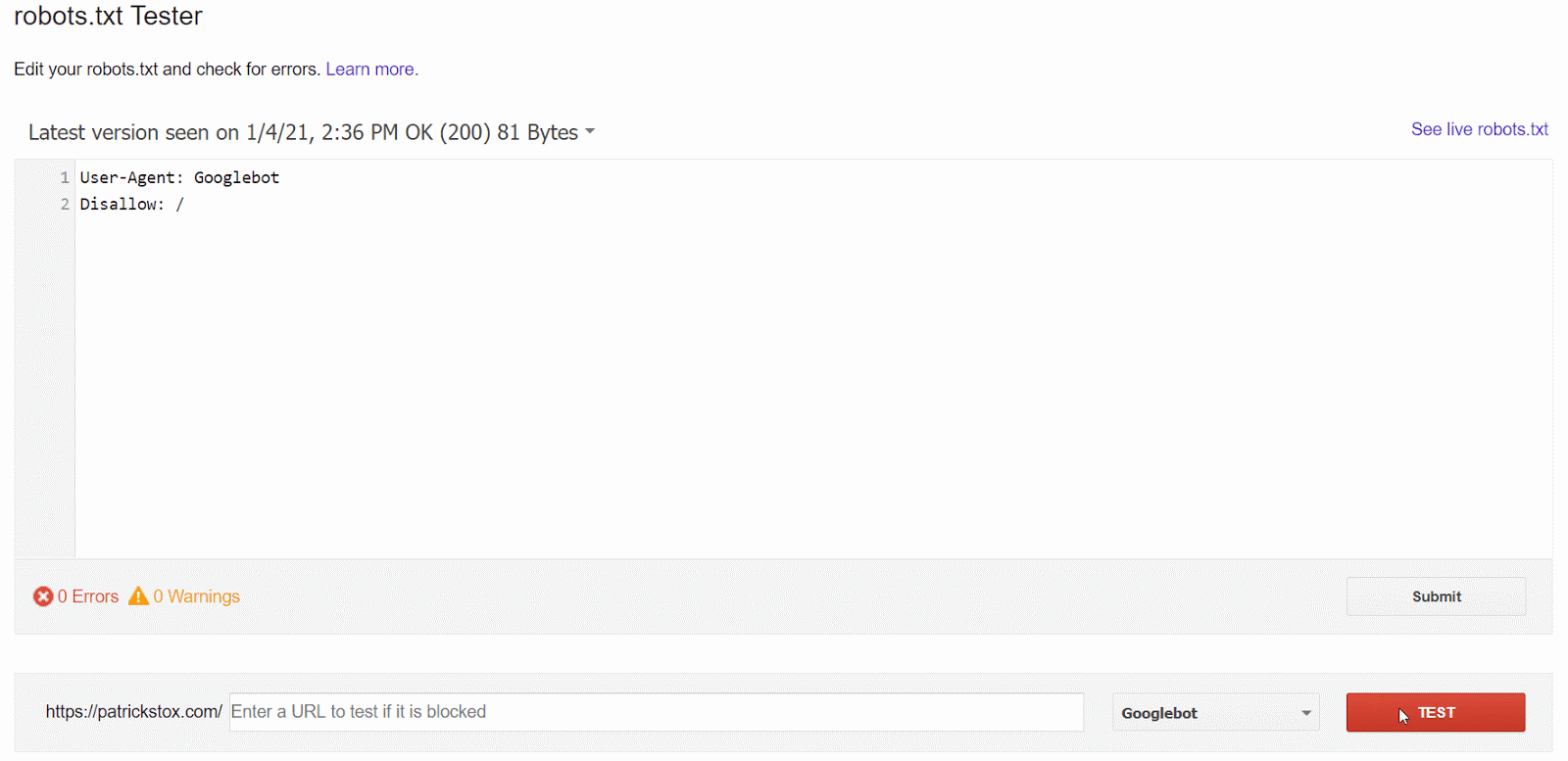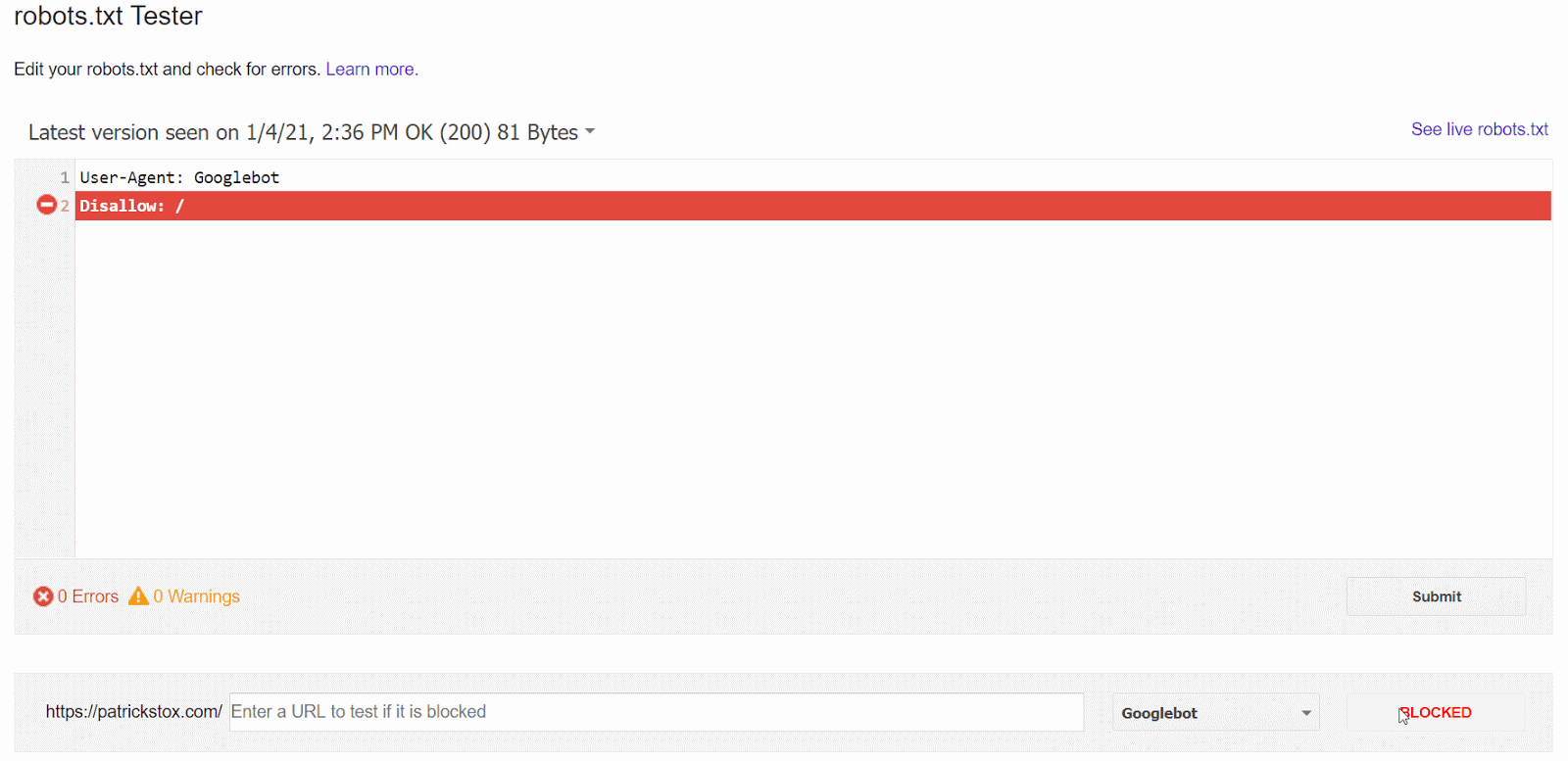
Wenn du keinen Zugang zur GSC hast oder bereits genau weißt, wonach du suchst, kannst du direkt zu domain.com/robots.txt navigieren, um die Datei zu finden. Mehr Informationen dazu findest du in unserem Blogartikel zum Thema robots.txt, aber vermutlich suchst du nach einer Disallow-Anweisung wie:
Disallow: /
Es kann sein, dass ein bestimmter User-Agent erwähnt oder jeder blockiert wird. Wenn deine Seite neu ist oder erst vor kurzem gelauncht wurde, solltest du danach suchen:
User-agent: *
Disallow: /
Es ist durchaus möglich, dass jemand die robots.txt-Blockierung bereits aufgehoben und das Problem gelöst hat, bevor du es in Angriff nehmen wolltest. Das wäre natürlich das beste Szenario. Wenn das Problem jedoch behoben zu sein scheint, aber kurz darauf erneut auftritt, liegt möglicherweise eineintermittierende Blockierung vor.
Wie du dieses Problem beheben kannst
Du musst die Disallow-Anweisung, welche die Blockierung verursacht, entfernen. Wie du dabei vorgehst, hängt von dem System ab, das du verwendest.
WordPress
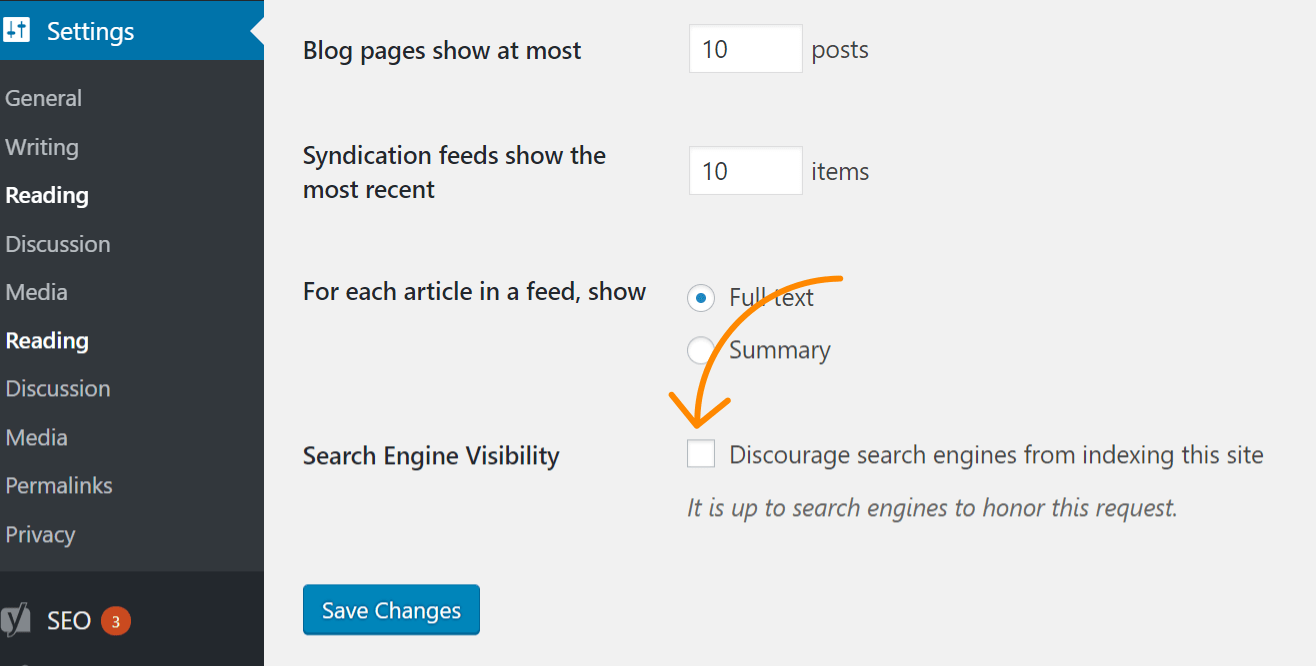
Wenn sich das Problem auf deine gesamte Website auswirkt, ist die wahrscheinlichste Ursache, dass du eine Einstellung in WordPress aktiviert hast, welche die Indexierung verbietet. Dieser Fehler tritt häufig bei neuen Websites und nach Website-Migrationen auf. Führe am besten die folgenden Schritte durch, um das Problem zu beheben:
- Klicke auf “Einstellungen” (‘Settings’)
- Klicke auf “Lesen” (‘Reading’)
- Stelle sicher, dass die Funktion “Sichtbarkeit für Suchmaschinen” (‘Search Engine Visibility’) nicht aktiviert ist.
WordPress mit Yoast
Wenn du das Yoast SEO Plugin verwendest, kannst du direkt die robots.txt-Datei bearbeiten, um die Anweisung für die Blockierung zu entfernen.
- Klicke auf ‘Yoast SEO’
- Klicke auf ‘Tools’
- Klicke auf “Datei-Editor” (‘File editor’)
WordPress mit Rank Math
Ähnlich wie bei Yoast kannst du bei Rank Math die robots.txt-Datei direkt bearbeiten.
- Klicke auf ‘Rank Math’
- Klicke auf “Allgemeine Einstellungen” (‘General Settings’)
- Klicke auf “robots.txt bearbeiten” (‘Edit robots.txt’)
FTP oder Hosting
Wenn du einen FTP-Zugriff auf die Website hast, kannst du die robots.txt-Datei direkt bearbeiten, um die Disallow-Anweisung zu entfernen, die das Problem verursacht. Möglicherweise erhältst du von deinem Hosting-Provider auch Zugriff auf einen Dateimanager (‘File Manager’), mit dem du direkt auf die robots.txt-Datei zugreifen kannst.
Überprüfe, ob intermittierende Blockierungen vorliegen
Intermittierende Probleme können schwieriger zu beheben sein, da die Ursachen bzw. Gegebenheiten für die Blockierung nicht immer ersichtlich sind.
Ich würde dir empfehlen, den Verlauf deiner robots.txt-Datei zu überprüfen. Wenn du beispielsweise im GSC robots.txt-Testerauf das Dropdown-Feld klickst, siehst du frühere Versionen der Datei. Diese kannst du anklicken, und sehen, was sie enthielten.

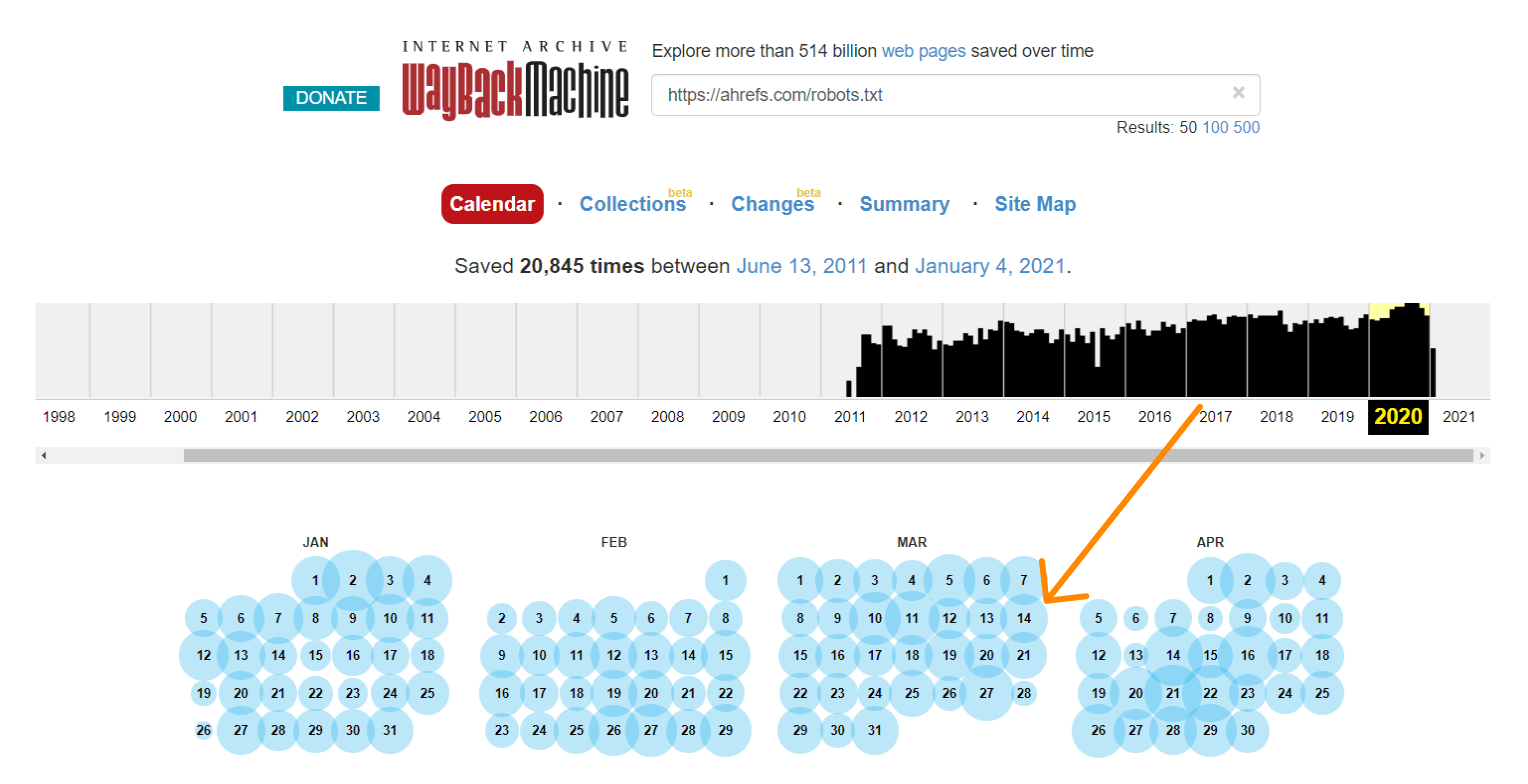
Die Wayback Machine auf archive.org verfügt ebenso über einen Verlauf der robots.txt-Dateien für all die Websites, die sie crawlen. Du kannst auf ein beliebiges Datum klicken, wofür sie die Daten haben, und sehen, was die Datei an diesem bestimmten Tag enthielt.
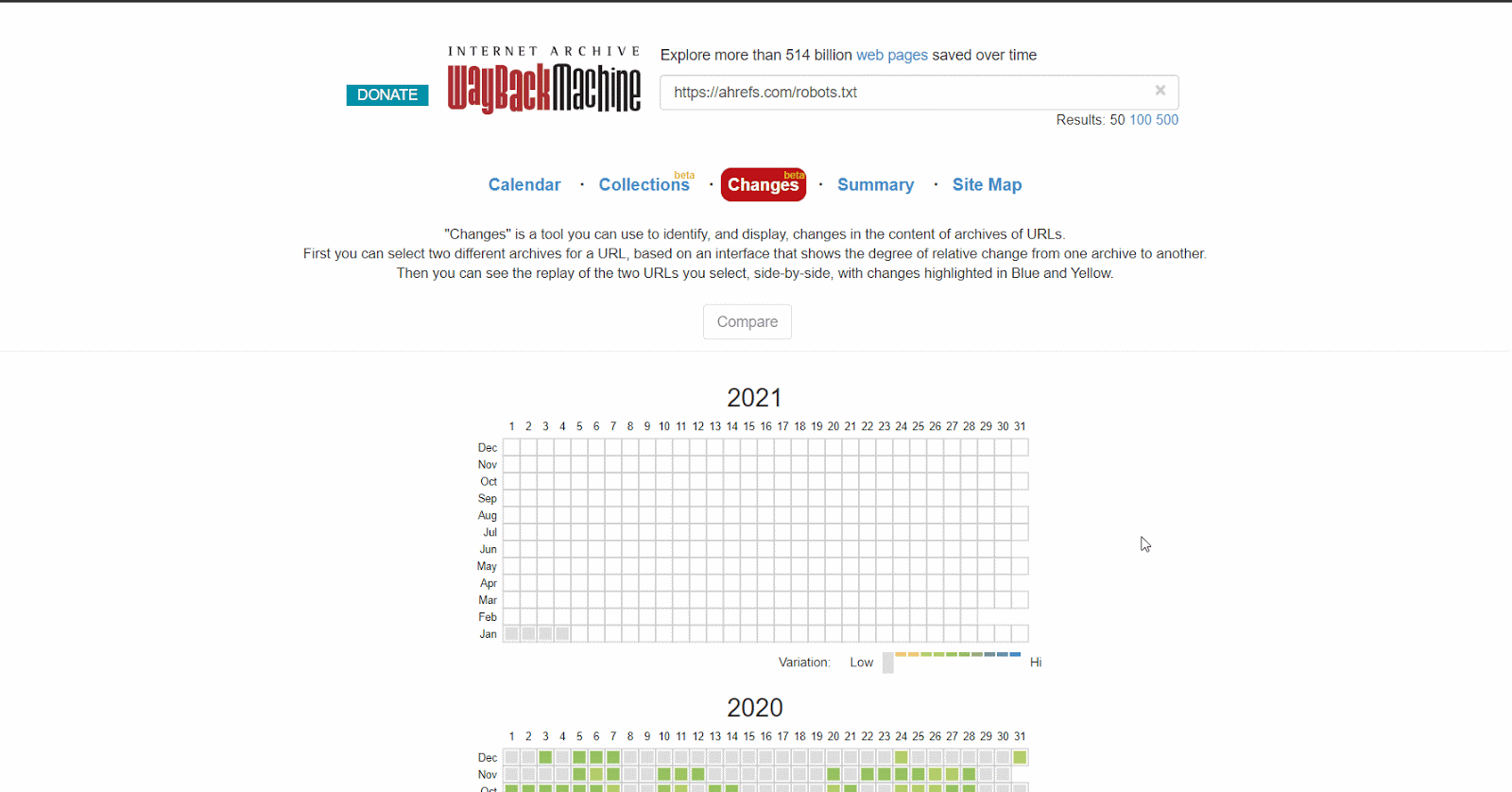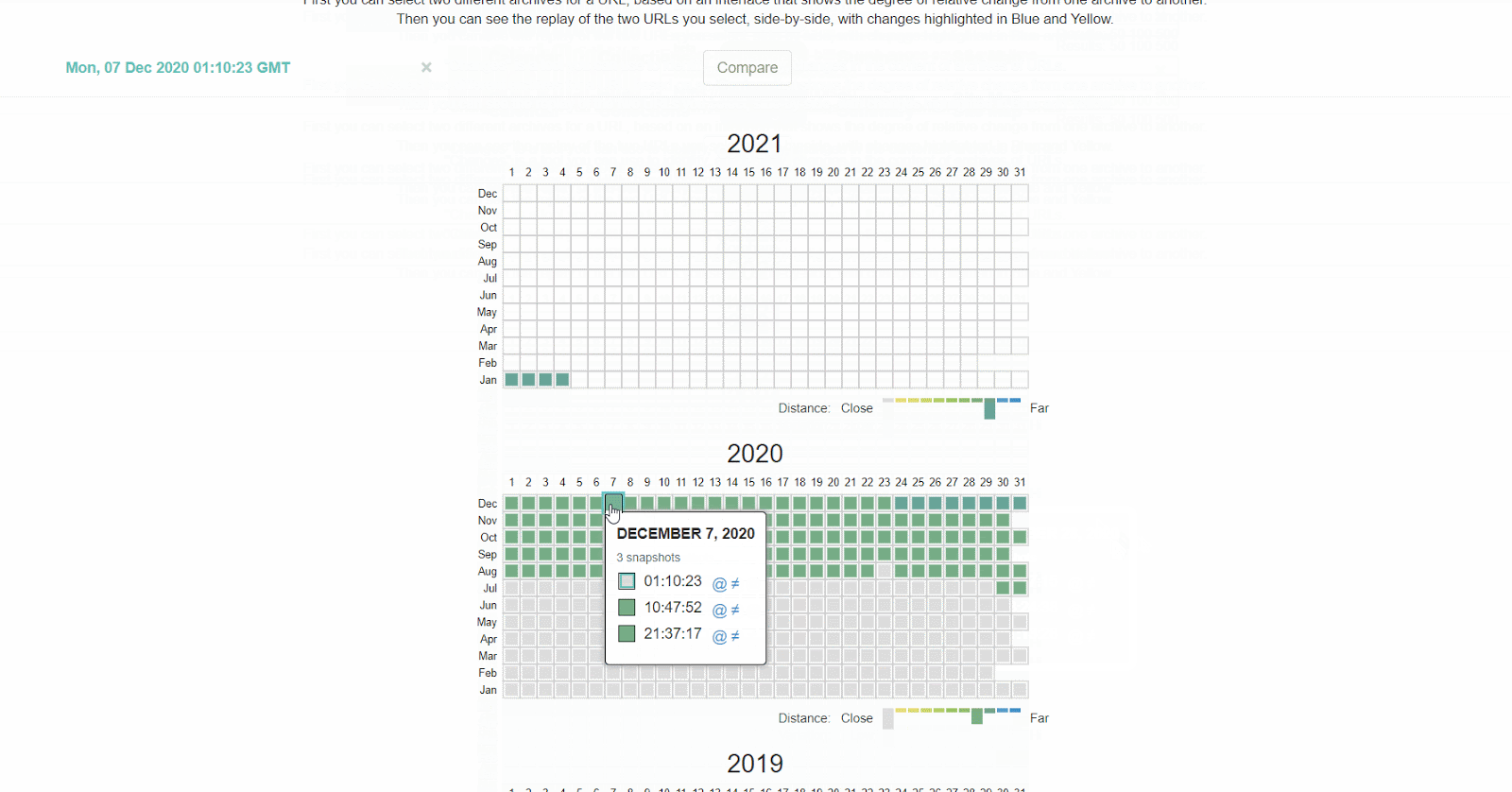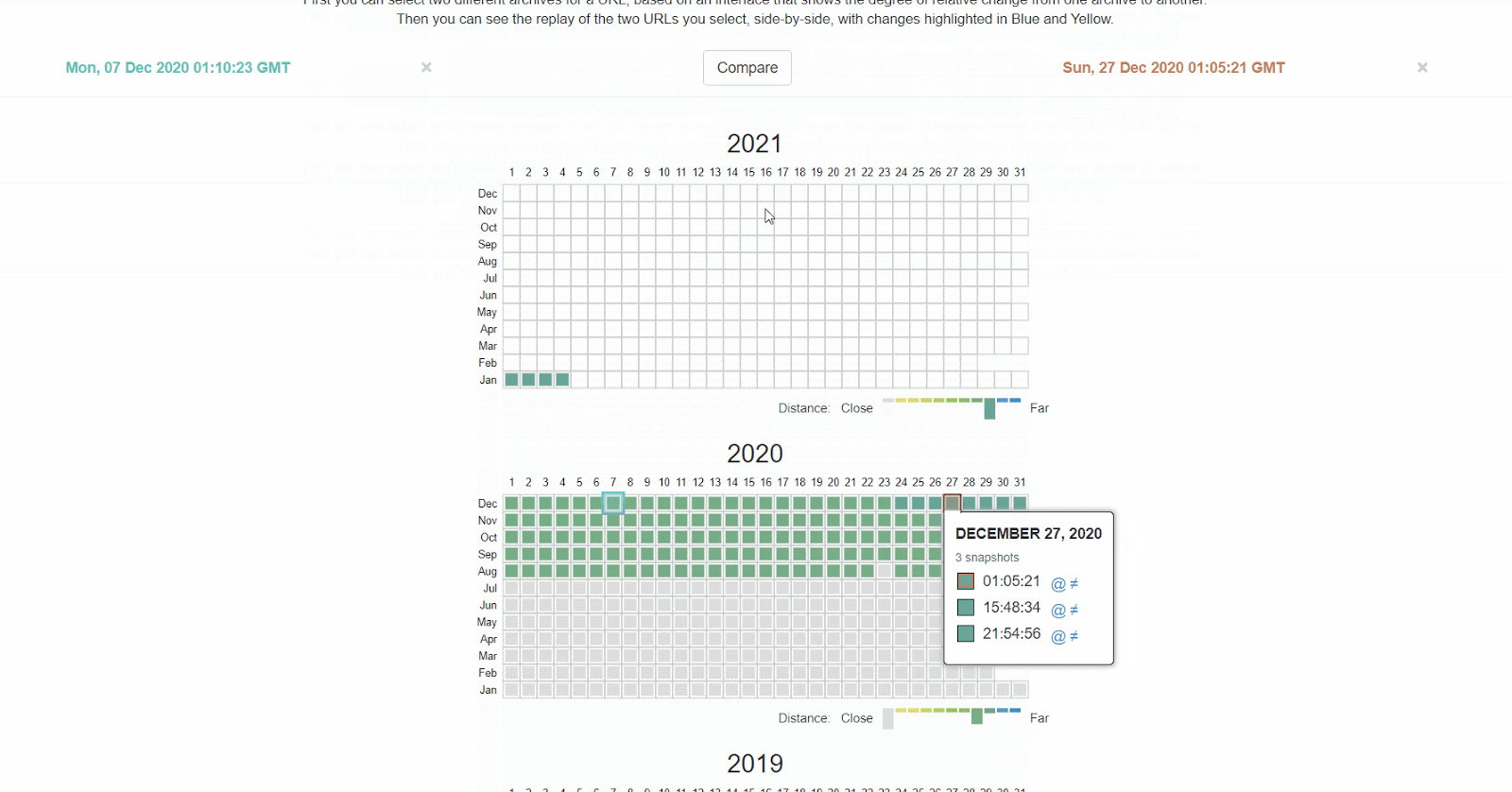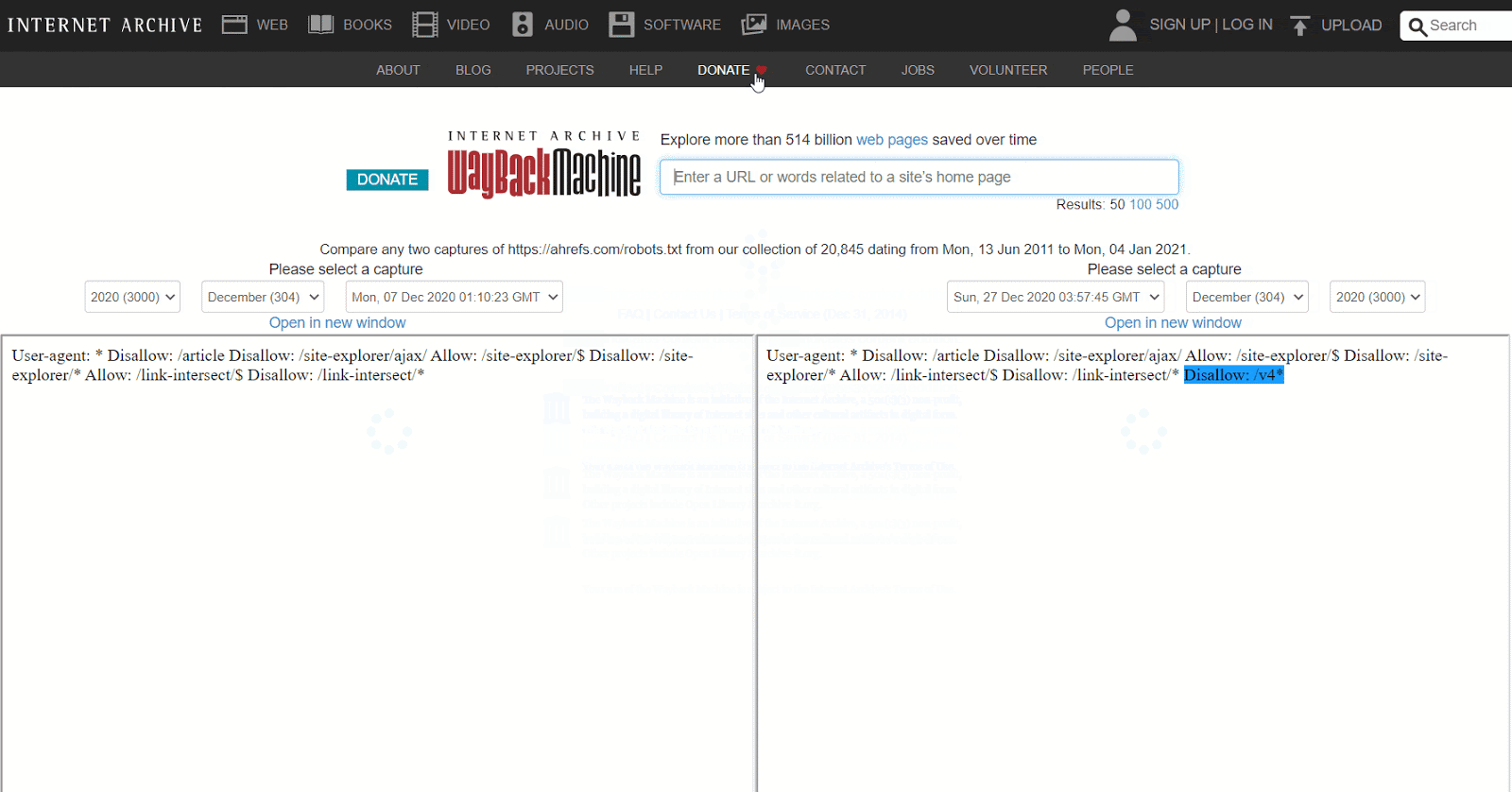
Oder du verwendest die Beta-Version des Änderungsberichts (‘Changes Report’), wo du ganz einfach inhaltliche Änderungen zwischen zwei verschiedenen Versionen einsehen kannst.
Wie du dieses Problem beheben kannst
Die Vorgehensweise bei der Behebung von intermittierenden Blockierungen hängt von der Ursache des Problems ab. Eine mögliche Ursache ist zum Beispiel ein von einer Test- und einer Live-Umgebung gemeinsam genutzter Cache. Wenn der Cache der Testumgebung aktiv ist, kann die robots.txt-Datei eine Anweisung zur Blockierung enthalten. Wenn der Cache der Live-Umgebung aktiv ist, kann die Seite gecrawlt werden. In diesem Fall solltest du den Cache aufteilen oder eventuell .txt-Dateien aus dem Cache in der Testumgebung ausschließen.
Überprüfe, ob eine User-Agent-Blockierung vorliegt
User-Agent-Blockierungen liegen vor, wenn eine Website einen bestimmten User-Agent wie Googlebot oder AhrefsBot blockiert. Mit anderen Worten: Die Website erkennt einen bestimmten Bot und blockiert den entsprechenden User-Agent.
Wenn du eine Seite in deinem regulären Browser problemlos anzeigen kannst, aber blockiert wirst, nachdem du deinen User-Agent geändert hast, bedeutet dies, dass der spezifische User-Agent, den du eingegeben hast, blockiert wird.
Du kannst einen bestimmten User-Agent mit den Chrome Devtools festlegen. Eine weitere Möglichkeit ist die Verwendung einer Browser-Erweiterung zum Ändern von User-Agents wie dieser hier.
Alternativ dazu kannst du auch mit einem cURL-Befehl überprüfen, ob User-Agent-Blockierungen vorliegen. Bei Windows funktioniert dies wie folgt:
- Drücke Windows+R, um das Feld “Ausführen” zu öffnen.
- Gib “cmd” ein und klicke dann auf “OK.”
- Gib einen cURL-Befehl ein — wie diesen:
curl -A “user-agent-name-here” -Lv [URL]
curl -A “Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)” -Lv https://ahrefs.com
Wie du dieses Problem beheben kannst
Wie man dieses Problem löst, hängt auch leider in diesem Fall davon ab, wo die Blockierung gefunden wird. Viele verschiedene Systeme können einen Bot blockieren, einschließlich .htaccess, Serverkonfiguration, Firewalls, CDN oder sogar solche, die du vielleicht nicht sehen kannst und die dein Hosting-Provider steuert. Am besten wendest du dich an deinen Hosting-Provider oder dein CDN und fragst, woher die Blockierung kommt und wie du sie aufheben kannst.
Hier sind zum Beispiel zwei verschiedene Möglichkeiten, einen User-Agent in .htaccess zu blockieren, nach denen du möglicherweise suchen musst.
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Googlebot [NC]
RewriteRule .* - [F,L]
Oder…
BrowserMatchNoCase "Googlebot" bots
Order Allow,Deny
Allow from ALL
Deny from env=bots
Überprüfe, ob eine IP-Blockierung vorliegt
Wenn du sichergestellt hast, dass du nicht von robots.txt blockiert wirst und User-Agent-Blockierungen ausgeschlossen sind, dann handelt es sich wahrscheinlich um eine IP-Blockierung.
Wie du dieses Problem lösen kannst
IP-Blockierungen sind schwierig ausfindig zu machen. Wie bei User-Agent-Blockierungen ist es am besten, wenn du deinen Hosting-Provider oder dein CDN kontaktierst und fragst, woher die Blockierung kommt und wie du sie aufheben kannst.
Hier ist ein Beispiel für etwas, wonach du in .htaccess suchen könntest:
deny from 123.123.123.123
Fazit
In den meisten Fällen resultiert die Fehlermeldung “indexiert, obwohl durch robots.txt-Datei blockiert” aus einer robots.txt-Blockierung. Wir hoffen, dass dir unser Leitfaden dabei geholfen hat, das Problem zu finden und zu beheben.
Hast du noch Fragen? Schreib mir auf Twitter.


