
En la mayor parte de casos, esto será un problema directo, en el que has bloqueado el rastreo en tu archivo robots.txt. Pero hay algunas condiciones adicionales que pueden desencadenar este problema, así que vamos a ver el siguiente proceso de resolución de problemas para diagnosticar y arreglar las cosas de la forma más eficiente posible:
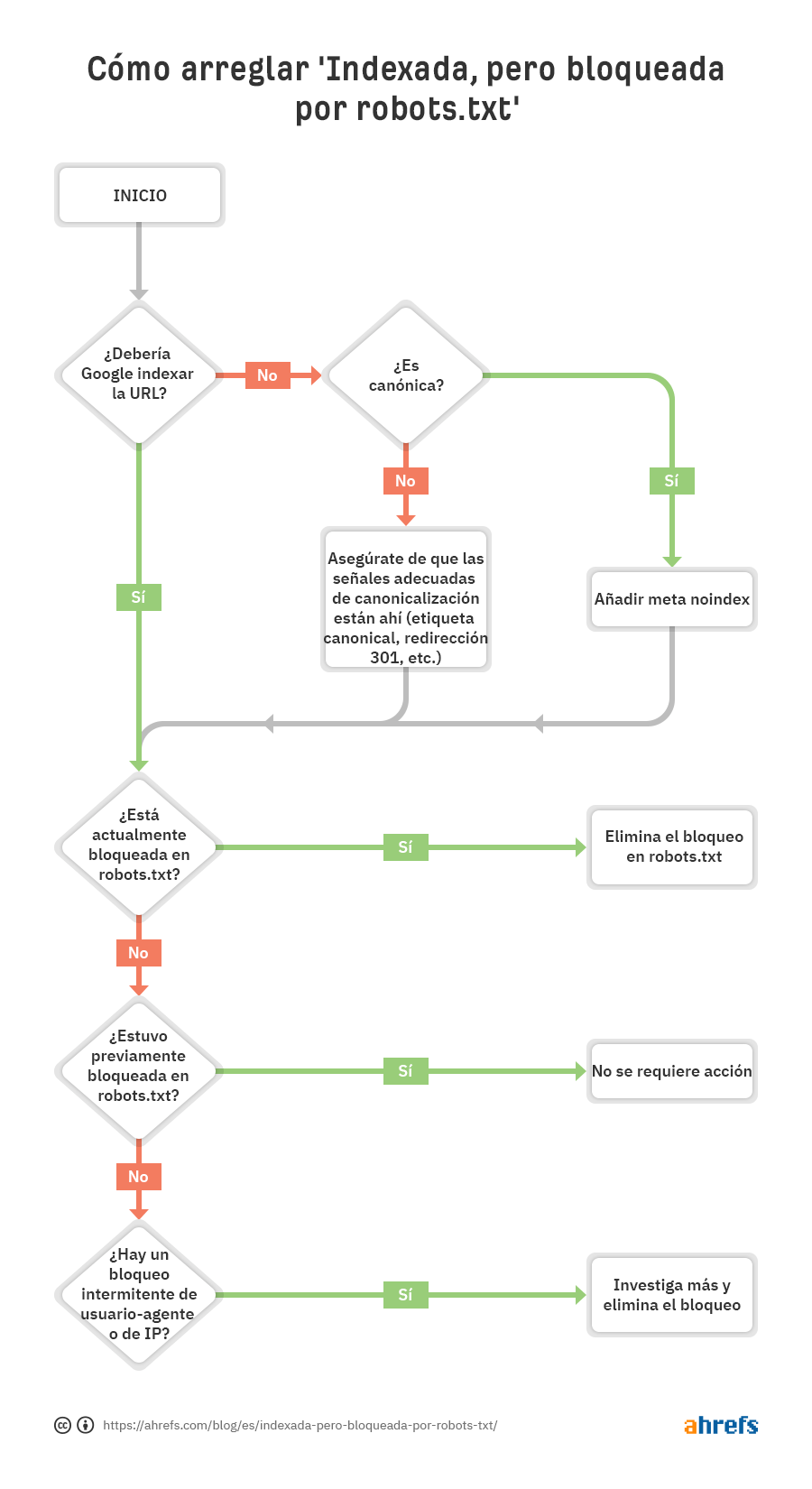
Puedes ver que el primer paso es preguntarte a ti mismo si quieres o no que Google indexe la URL.
Si no quieres que la URL se indexe…
Simplemente añade una etiqueta noindex meta robots y asegúrate de que permites el rastreo—asumiendo que es canonical.
Si bloqueas una página para que no sea rastreada, puede que a pesar de eso Google la indexe, porque rastrear e indexar son dos cosas distintas. A menos que Google pueda rastrear una página, no verán la meta etiqueta noindex y puede que a pesar de todo la indexe porque tiene enlaces.
Si la URL canonicaliza a otra página, no añadas una etiqueta noindex meta robots. Simplemente asegúrate de que las señales correctas de canonicalización están incluidas, incluyendo una etiqueta canonical en la página canonical, y de permitir el rastreo para que las señales se pasen y consoliden correctamente.
Si quieres que la URL sea indexada…
Necesitas averiguar por qué Google no puede rastrear la URL y eliminar el bloqueo.
La causa más probable es un bloqueo de rastreo en robots.txt Pero hay algunos escenarios en los que puedes ver mensajes de que estás bloqueado. Vamos a verlos en el orden en que probablemente deberías buscarlos.
- Comprueba un bloqueo de rastreo en robots.txt
- Comprueba bloqueos intermitentes
- Comprueba bloqueos de usuario-agente
- Comprueba bloqueos de IP
Comprueba un bloqueo de rastreo en robots.txt
La manera más fácil de ver el problema es con el comprobador de robots.txt en GSC, que avisará de la regla que provoca el bloqueo.
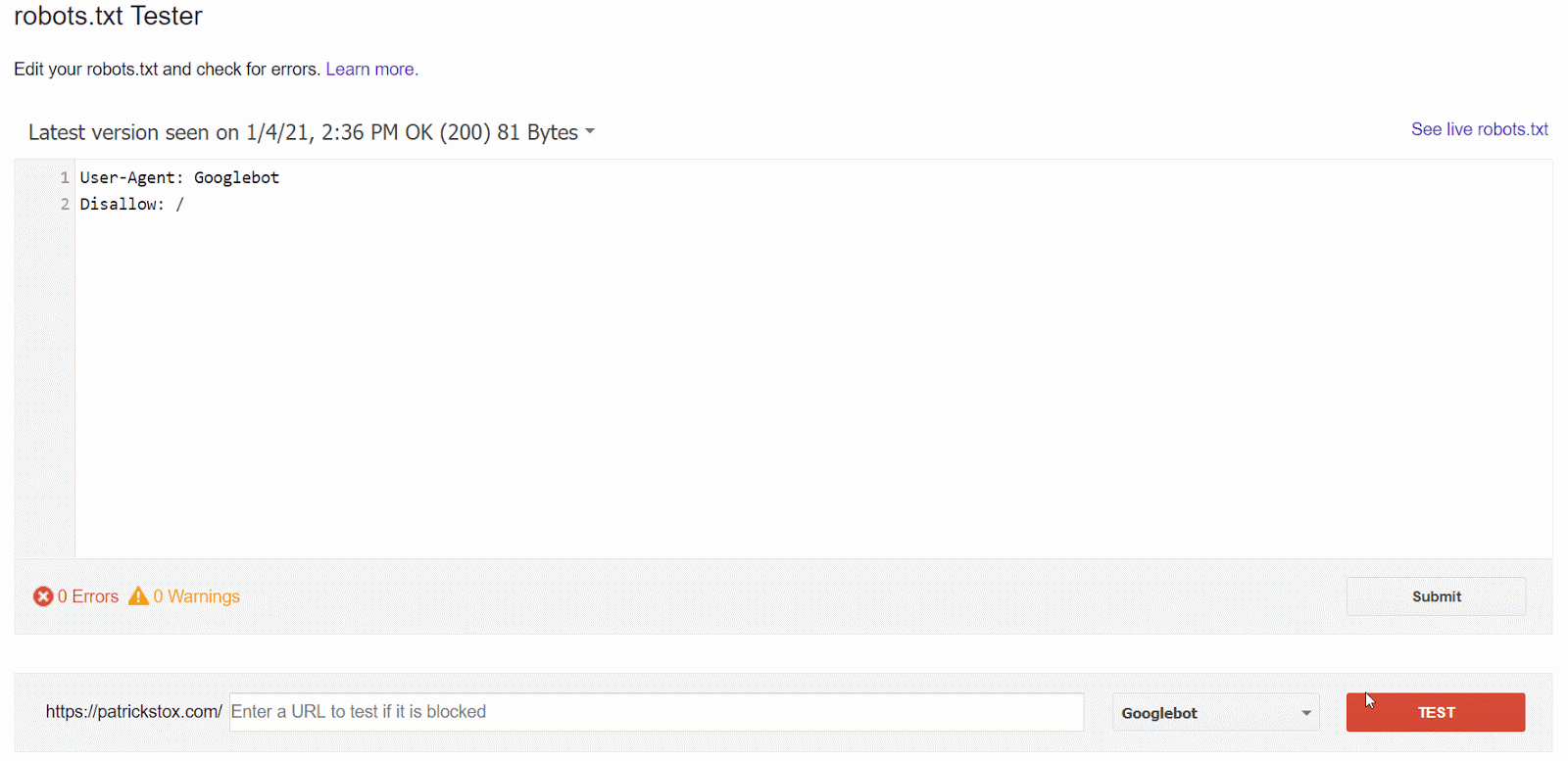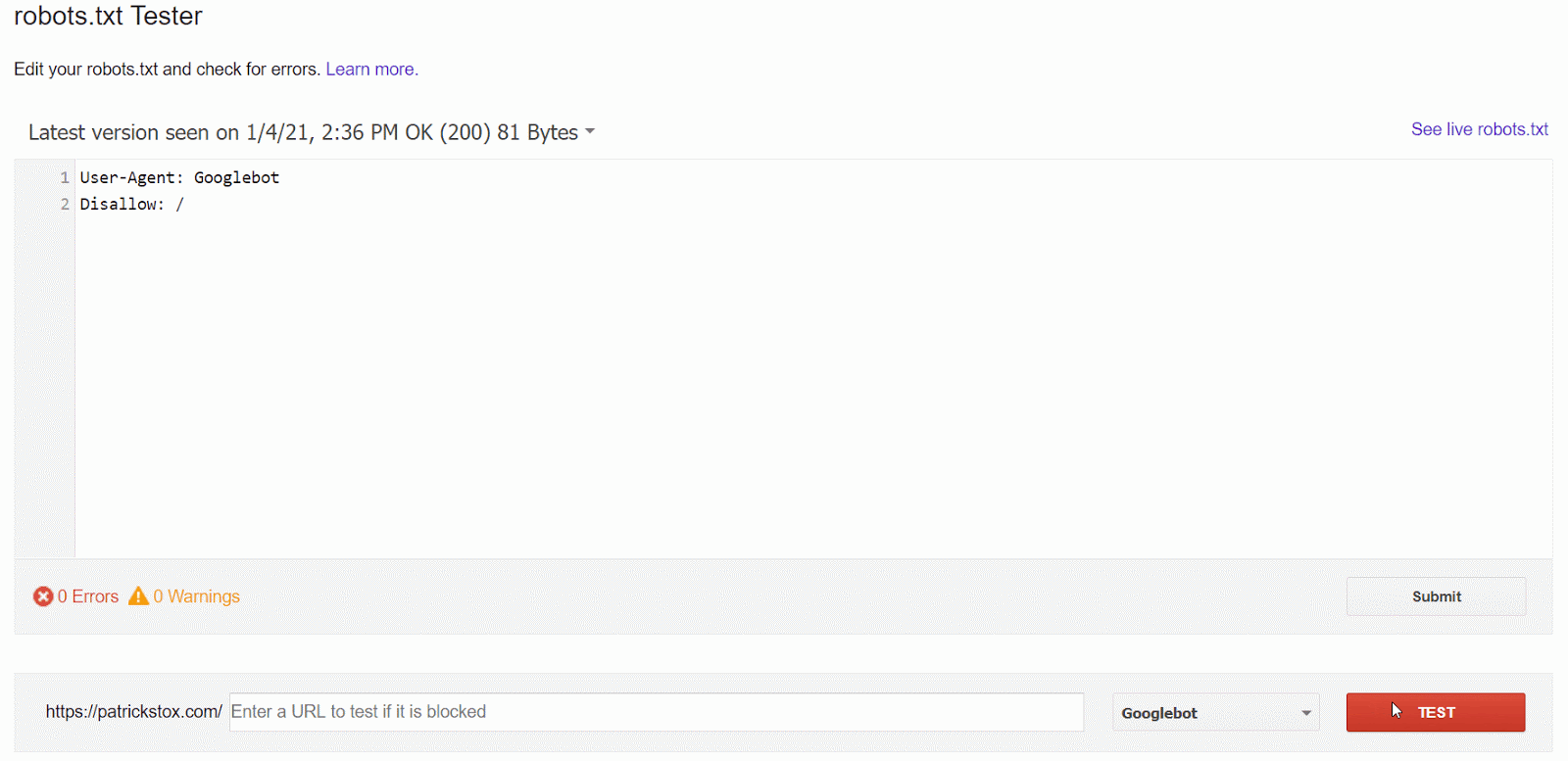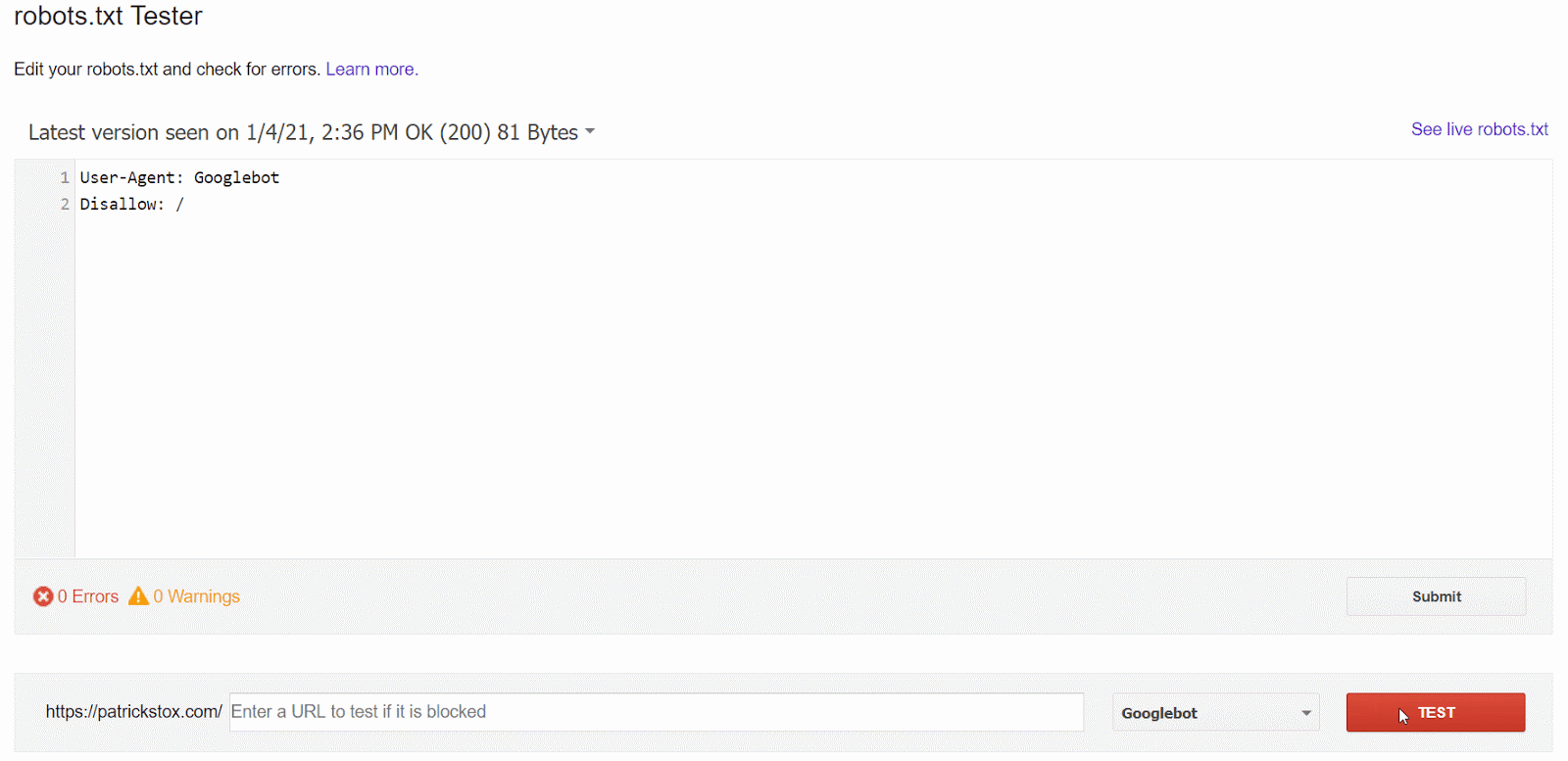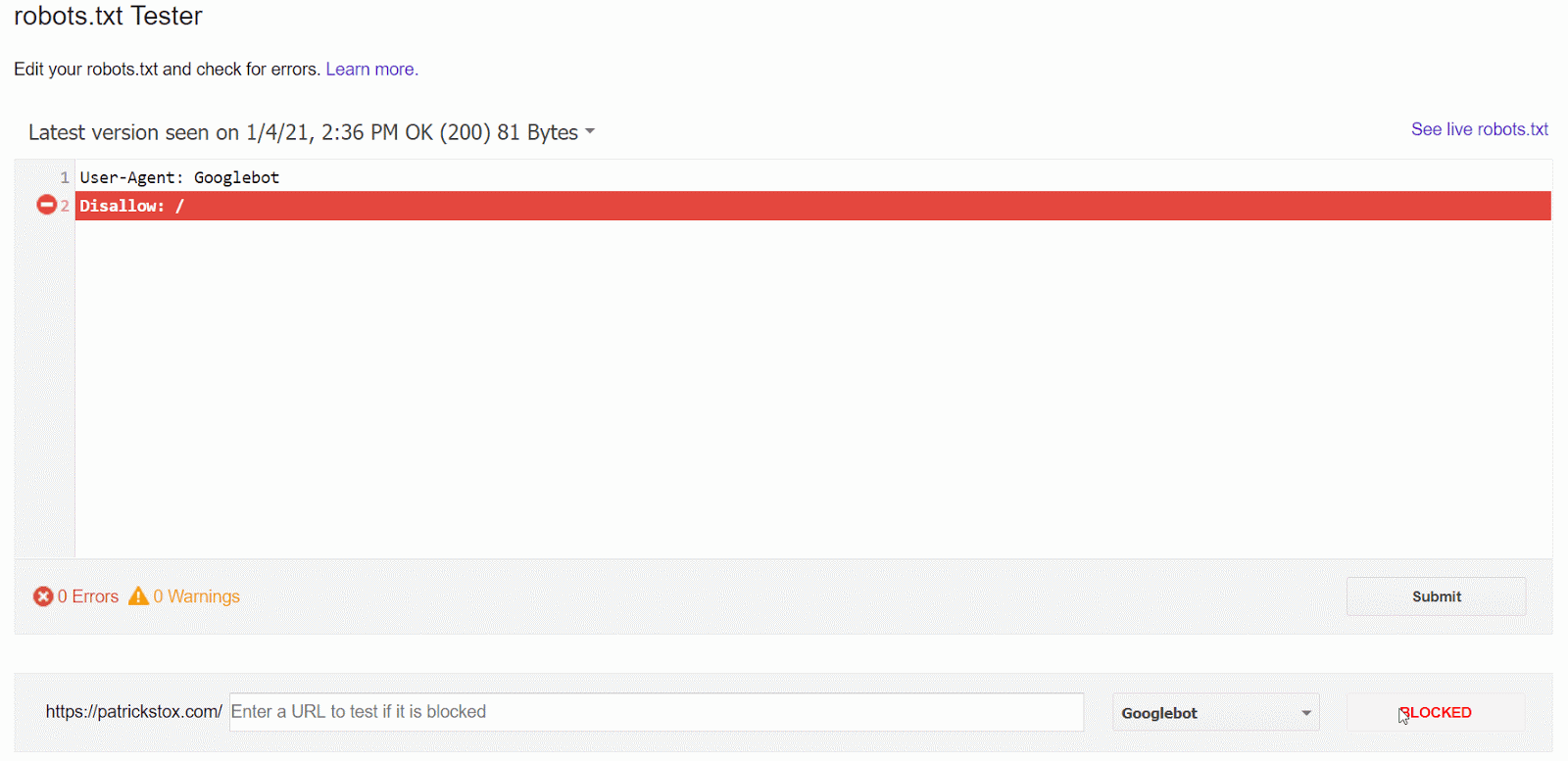
Si sabes lo que estás buscando o no tienes acceso a GSC, puedes ir a dominio.com/robots.txt para encontrar el archivo. Tenemos más información en nuestro artículo de robots.txt, pero es probable que encuentres una declaración de disallow (no permitir) como:
Disallow: /
Puede haber un usuario-agente específico mencionado o puede que todos estén bloqueados. Si tu sitio es nuevo o acaba de lanzarse, puedes buscar algo como esto:
User-agent: *
Disallow: /
Es posible que alguien ya haya arreglado el bloqueo en robots.txt y resuelto el problema antes de que lo empieces a comprobar. Este es el mejor caso posible. Sin embargo, si el problema parece resuelto pero reaparece de nuevo poco después, puede que tengas un bloqueo intermitente.
Cómo arreglarlo
Querrás eliminar la declaración de disallow que causa el bloqueo. La forma de hacerlo cambia en función de la tecnología que uses.
WordPress
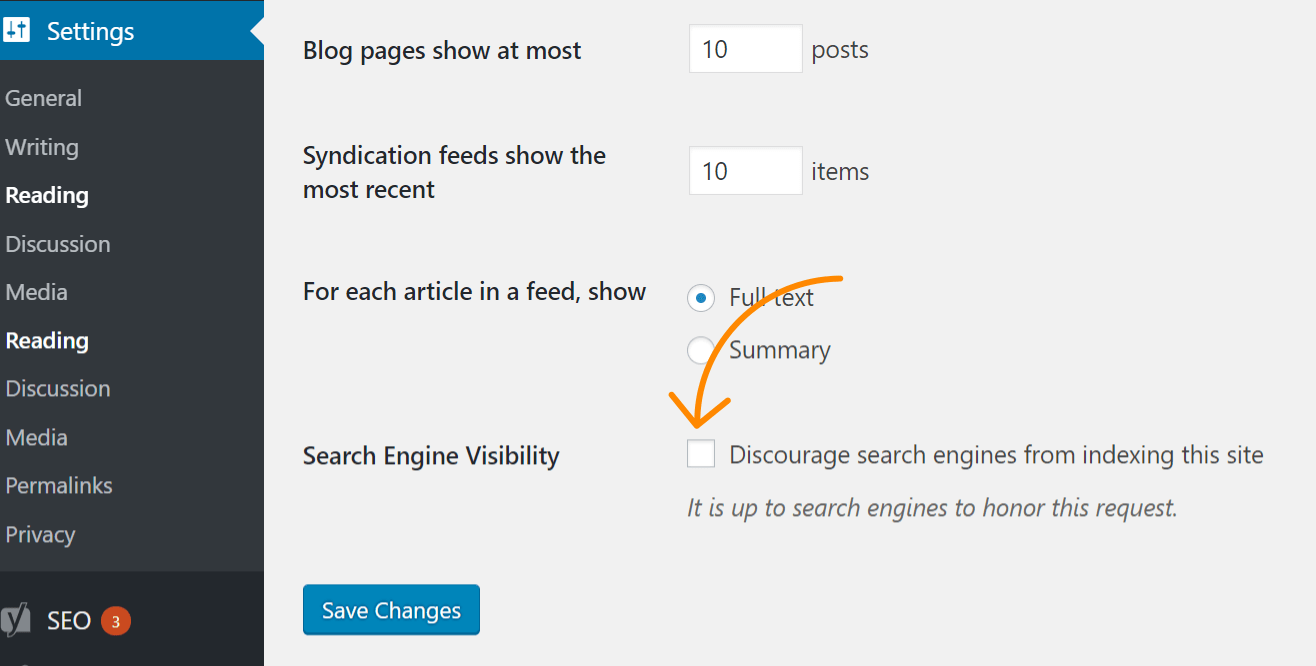
Si el problema afecta a toda tu web, la causa más probable es haber activado una opción de la configuración de WordPress que desactiva la indexación. Este error es común en webs nuevas y después de migraciones. Sigue estos pasos para comprobarlo:
- Haz clic en “Ajustes”
- Haz clic en “Lectura”
- Asegúrate de que la casilla “Visibilidad de Motores de Búsqueda” está sin marcar.
WordPress con Yoast
Si usas el plugin SEO de Yoast, puedes editar directamente el archivo robots.txt para eliminar la declaración de bloqueo.
- Haz clic en “Yoast SEO”
- Haz clic en “herramientas”
- Haz clic en “Editor de archivos”
WordPress con Rank Math
Parecido a Yoast, Rank Math te permite editar el archivo robots.txt directamente.
- Haz clic en “Rank Math”
- Haz clic en “Ajustes Generales”
- Haz clic en en “Editar robots.txt”
FTP o hosting
Si tienes acceso por FTP al sitio, puedes editar directamente el archivo robots.txt para eliminar la declaración disallow que causa el problema. Tu proveedor de hosting puede darte acceso al gestor de archivos para acceder al archivo robots.txt de forma directa.
Comprueba bloqueos intermitentes
Los problemas intermitentes pueden ser más difíciles de solucionar porque las condiciones que causan el bloqueo puede que no siempre estén presentes.
Lo que recomendaría es comprobar el historial de tu archivo robots.txt. Por ejemplo, en el comprobador de robots.txt de GSC, si haces click en el desplegable, verás versiones anteriores del archivo, donde puedes hacer clic para ver qué contenían.

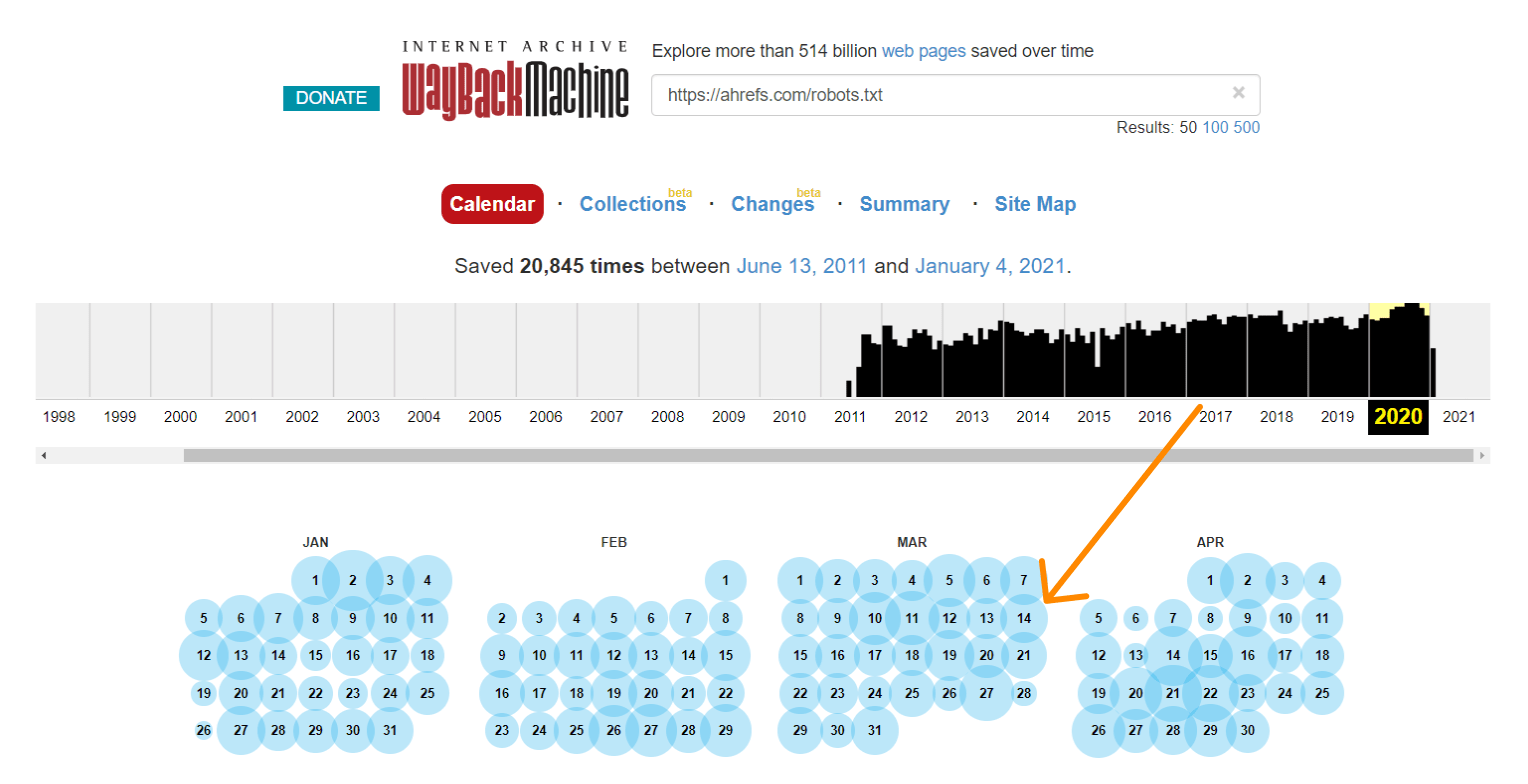
La Wayback Machine en archive.org tiene un histórico de los archivos robots.txt que rastrean. Puedes hacer click en cualquiera de las fechas donde tienen datos y ver qué incluía el archivo en ese día en concreto.
O usar la versión beta del informe de Cambios, que te permite ver fácilmente los cambios en el contenido entre dos versiones distintas.
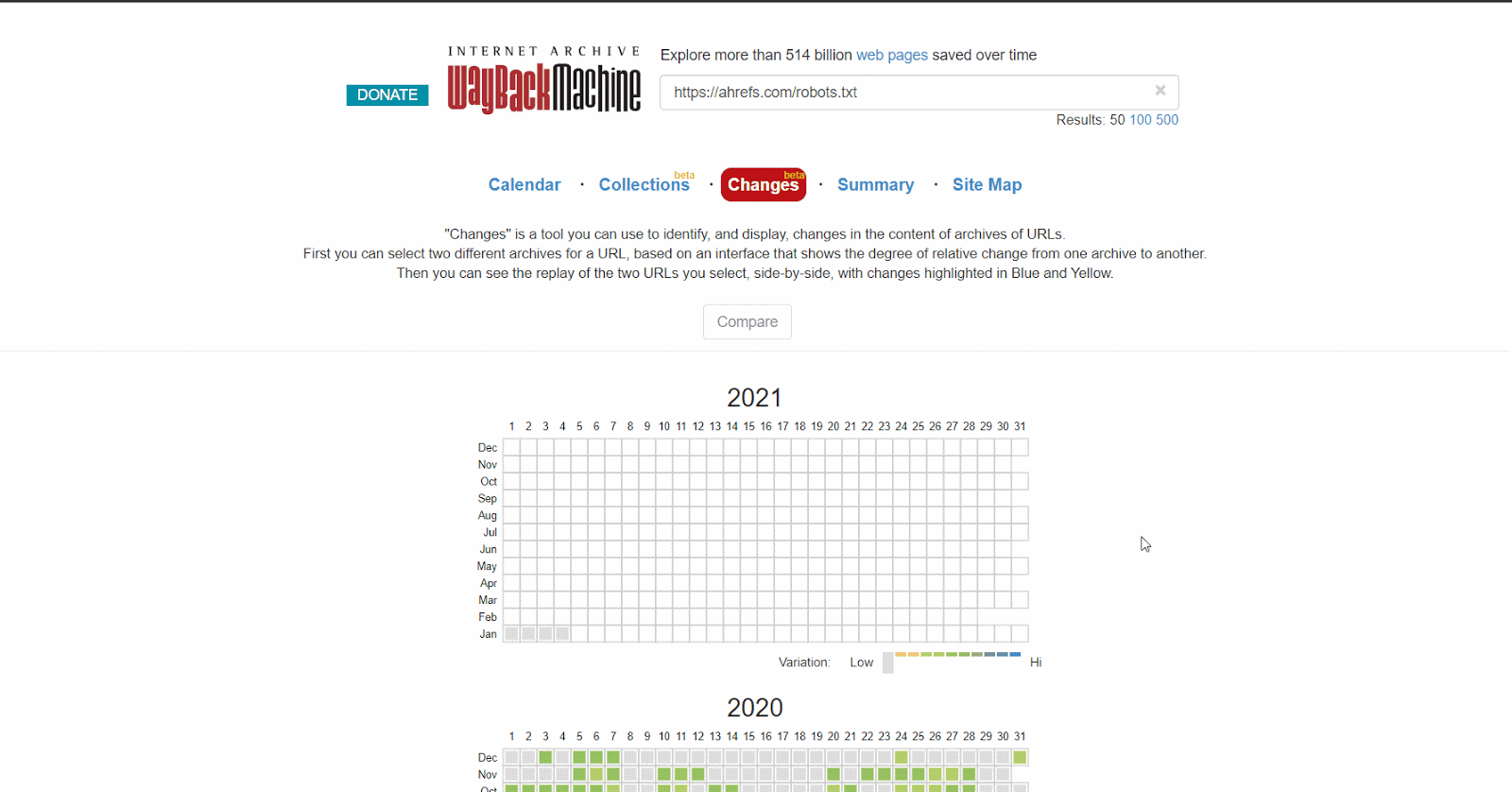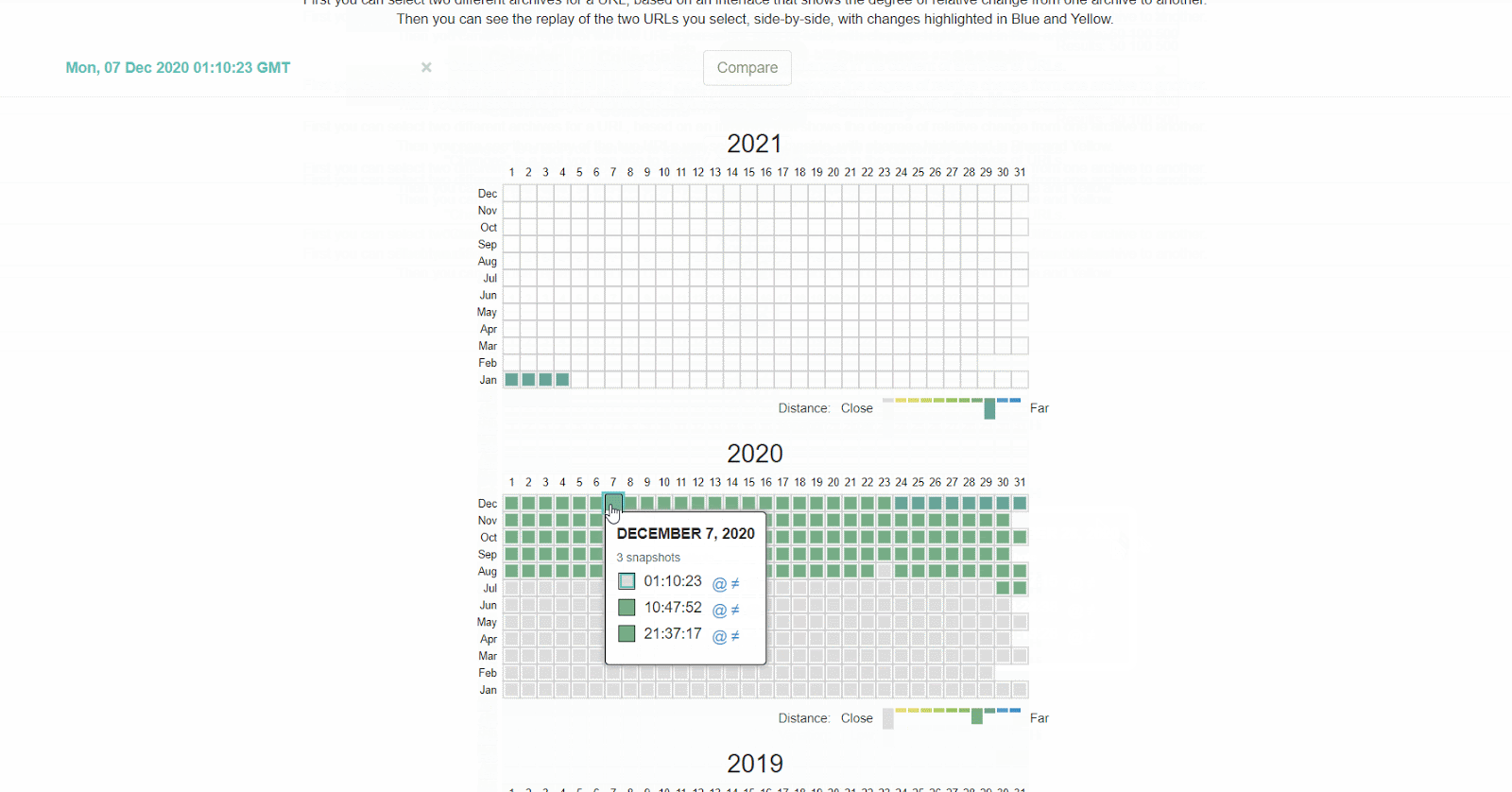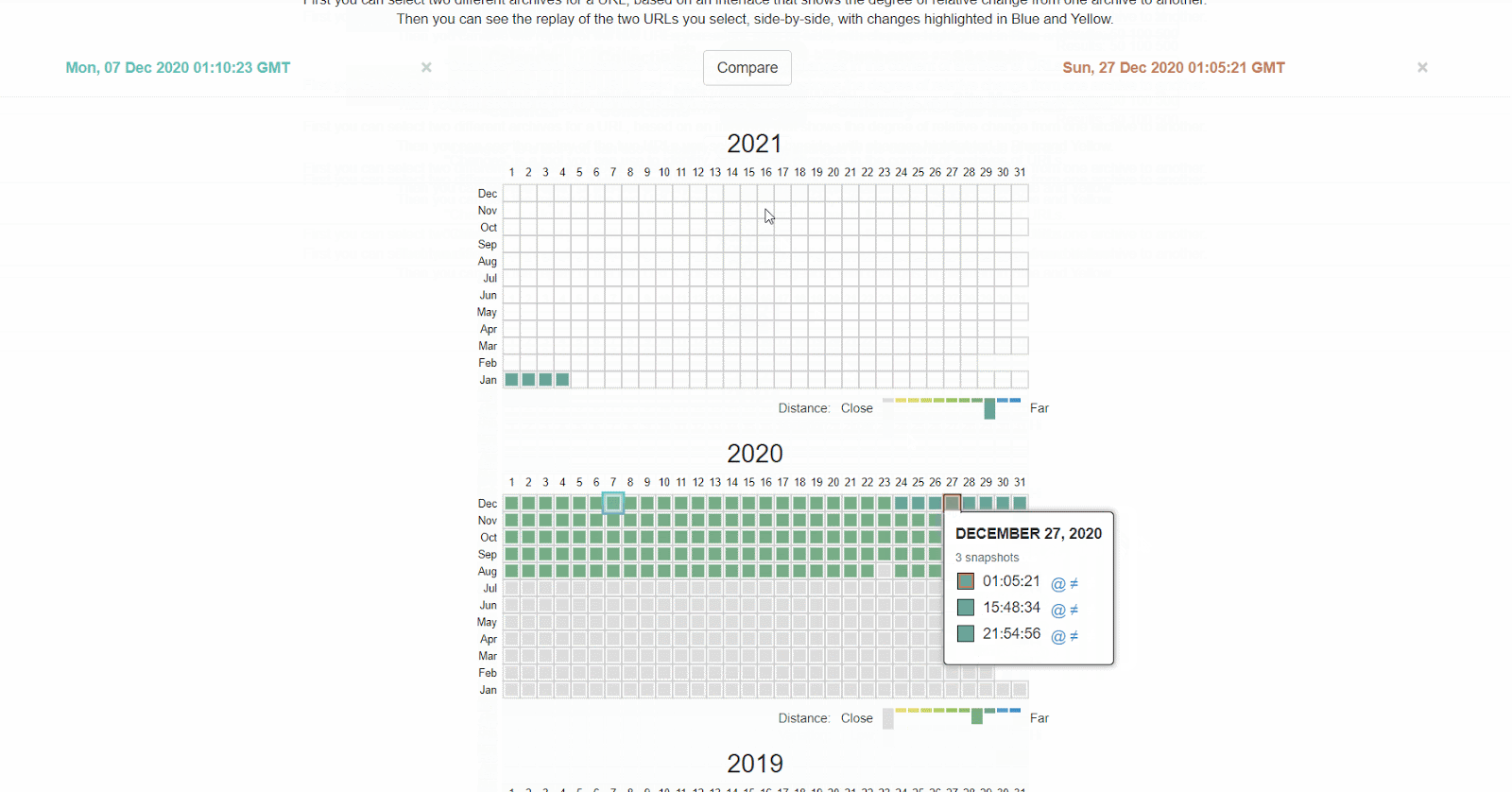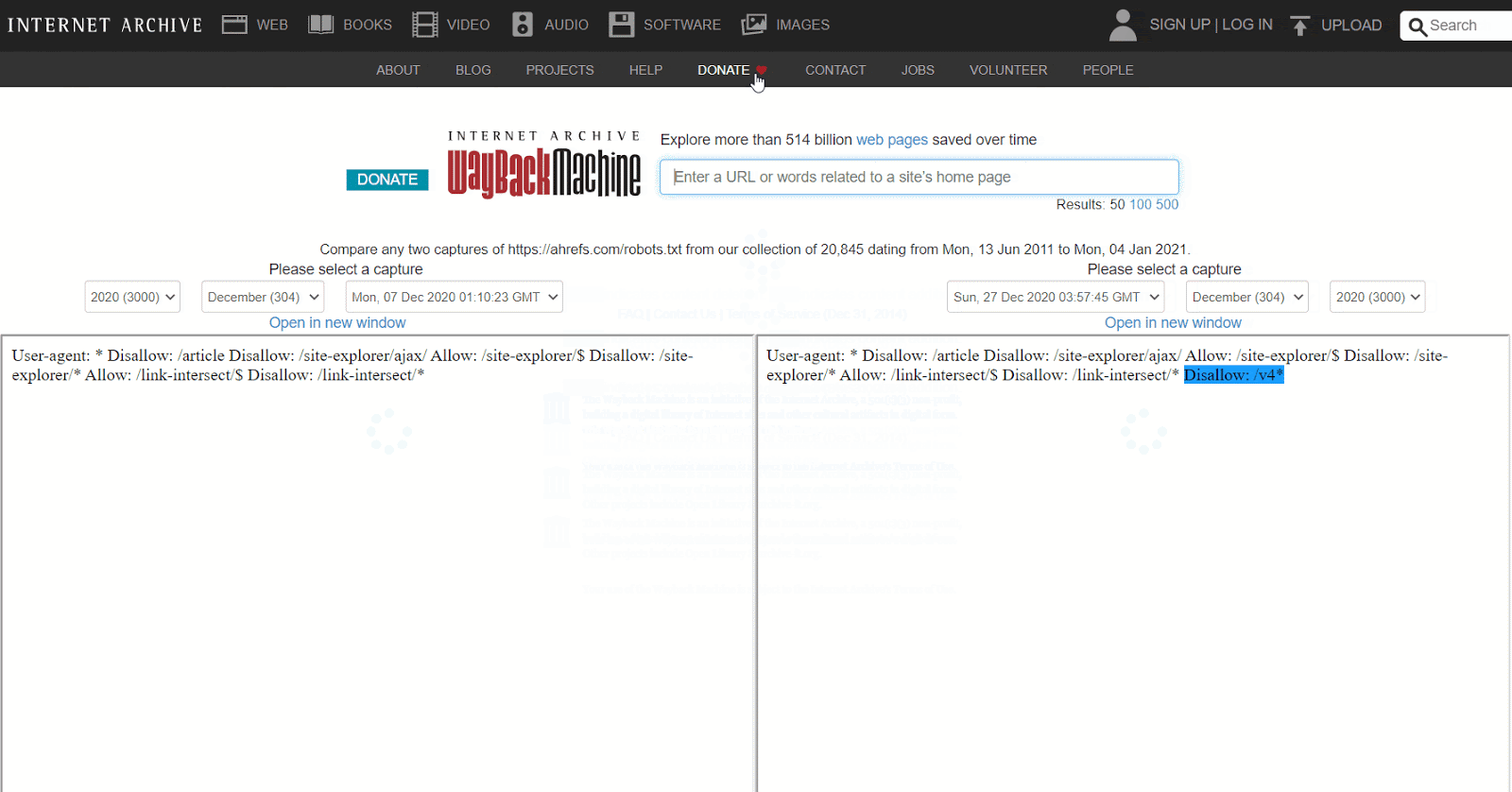
Cómo arreglarlo
El proceso de arreglar bloqueos intermitentes dependerá de cuál sea la causa del problema. Por ejemplo, una posible causa sería una caché compartida entre un entorno de pruebas y un entorno de producción. Cuando la caché del entorno de pruebas está activa, el archivo robots.txt puede incluir una directiva de bloqueo. Y cuando la caché del entorno de producción esté activa, el sitio puede ser rastreado. En este caso, querrías dividir la caché o quizá excluir archivos .txt de la caché en el entorno de pruebas.
Comprueba bloqueos de usuario-agente
Los bloqueos de usuario-agente (user-agent en inglés) se producen cuando un sitio bloquea a un usuario-agente específico. Como Googlebot o AhrefsBot. En otras palabras, el sitio detecta un bot específico y bloquea al correspondiente usuario-agente.
Si puedes ver bien una página en tu navegador habitual pero te bloquean después de cambiar tu usuario-agente, quiere decir que el usuario-agente específico que has introducido está bloqueado.
Puedes especificar un usuario agente particular usando las herramientas para desarrolladores de Chrome. Otra opción es usar una extensión del navegador para cambiar de usuario como esta.
De forma alternativa, puedes comprobar los bloqueos de usuario-agente con un comando cURL. Aquí está cómo hacerlo en Windows:
- Presiona la tecla Windows+R para abrir una caja de “Ejecutar”.
- Escribe “cmd” y después dale clic a “OK”.
- Introduce un comando cURL como este:
curl -A “user-agent-name-here” -Lv [URL]
curl -A “Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)” -Lv https://ahrefs.com
Cómo arreglarlo
Por desgracia, este es otro de esos problemas donde saber cómo arreglarlo dependerá de dónde encuentres el bloqueo. Muchos sistemas diferentes pueden bloquear un bot, incluyendo .htaccess, la configuración del servidor, firewalls, CDN o incluso algo que no puedas ver y que tu proveedor de hosting controla. Lo mejor que puedes hacer es contactar a tu proveedor de hosting o CDN y preguntarles de dónde proviene el bloqueo y cómo puedes resolverlo.
Por ejemplo, aquí hay dos formas diferentes de bloquear un usuario-agente en .htaccess que puede que tengas que buscar.
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} Googlebot [NC]
RewriteRule .* - [F,L]
O…
BrowserMatchNoCase "Googlebot" bots
Order Allow,Deny
Allow from ALL
Deny from env=bots
Comprueba bloqueos de IP
Si has confirmado que no estás bloqueado por robots.txt y descartado bloqueos de usuario-agente, es probablemente un bloqueo de IP.
Cómo arreglarlo
Los bloqueos por IP son problemas difíciles de rastrear. Como ocurre con los bloqueos de usuario-agente, lo mejor que puedes hacer es contactar con el proveedor de hosting o CDN y preguntarles de dónde proviene el bloqueo y cómo puede resolverse.
Aquí hay un ejemplo de algo que puedes buscar en .htaccess:
deny from 123.123.123.123
Reflexiones finales
La mayor parte del tiempo, las advertencias de “indexada, pero bloqueada por robots.txt” provienen de un bloqueo en el robots.txt. Con suerte, esta guía ha sido una ayuda para encontrar y arreglar el problema en caso de que ese no fuera el caso.
¿Tienes preguntas? Cuéntamelas en Twitter.
Traducido por Iván Fanego, que en sus ratos libres analiza herramientas y tendencias en marketing y software y que acaba de lanzar el primer directorio de herramientas de WhatsApp Marketing.


